REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
- 前言
- ABSTRACT
- 1 INTRODUCTION
- 2 REACT: SYNERGIZING REASONING + ACTING
- 3 KNOWLEDGE-INTENSIVE REASONING TASKS
- 3.1 SETUP
- 3.2 METHODS
- 3.3 RESULTS AND OBSERVATIONS
- 4 DECISION MAKING TASKS
- 5 RELATED WORK
- 6 CONCLUSION
- 閱讀總結
前言
一篇來自ICLR 2023的文章,可以稱得上是當今火爆全網的Agent的鼻祖工作了,它提出了基于LLM初始的Agent的范式,在問答任務和決策任務上都取得了不錯的結果,但是受限于LLM的能力,導致與人類的SOTA相距甚遠。
| Paper | https://arxiv.org/pdf/2210.03629.pdf |
|---|---|
| Code | https://github.com/ysymyth/ReAct |
| From | ICLR 2023 |
ABSTRACT
LLMs在語言理解和交互決策上表現出令人印象深刻的性能,其推理能力也作為了一個單獨研究的主題。本文探索使用交互的方式生成推理任務特定動作,使二者具有更大的協同性。推理幫助模型歸納、跟蹤和更新計劃以及處理異常,動作則允許與外部接口相連并收集額外的信息。本文的ReAct方法可以應用于多語言決策任務,在最新的基線上證明了其有效性、人類可解釋性和可信度。具體來說,在問答和事實驗證方面,ReAct與簡單的維基百科API交互,生成了類似人類解決任務的軌跡,克服了CoT中廣泛存在的幻覺和錯誤累積問題。此外在兩個交互式決策benchmark上,ReAct在只有一兩個上下文示例的情況下優于模仿學習和強化學習的方法。
1 INTRODUCTION
人類智能的一個特點是可以做到言行一致,在對自我調節、制定策略以及維護工作記憶有著重要作用。最近的工作暗示了在自動系統中,語言推理和交互式決策的結合是可能的。首先,LLM展現出其強大的推理能力,比如CoT推理,但是其CoT能力只能對自身使用,可以理解為一個黑盒,這種無法與外界交互的方式會帶來幻覺和錯誤累積的問題。其次,最近有工作利用預訓練的語言模型在交互式環境中進行規劃和行動,雖然加入了多模態的信息以文本形式引入,但是它們只能根據當前的狀態解決現有的問題,無法解決更抽象的高級目標(需要多步推理交互式執行)。目前還沒有研究將推理和行動結合起來解決一般的問題,是否能夠帶來系統性的提升還有待商榷。

本文提出ReAct,一個將推理和動作與語言模型相結合的通用范式,用于解決不同語言推理和決策任務。ReAct提示LLMs以交錯的方式生成與任務相關的語言推理軌跡和動作,讓模型動態推理去創建、維護和調整行動的計劃,同時也與外部環境交互來引入外部的知識。
作者在四個不同的benchmarks上對ReAct進行了評估,包括問答(HotPotQA)、事實驗證(Fever)、基于文本的游戲(ALFWorld)以及網頁瀏覽(WebShop)。對于前兩個數據集,ReAct+CoT方法的效果是最好的,在后兩個數據集上,兩次甚至一次ReAct提示就能將成功率分別提高34%和10%。此外,作者還展示了相對于僅采用動作的優勢,證明了稀疏多功能推理在決策中的重要性。推理和動作的結合提高了模型的可解釋性和可信度,與人類的行為對齊。
總的來說,本文的貢獻如下:
- 提出ReAct,一個新穎的基于prompt的范式,在語言模型中協同推理和動作來解決一般問題。
- 在多個benchmarks上驗證ReAct的性能與優勢。
- 系統的消融分析,了解推理任務中動作以及交互任務中推理的重要性。
- ReAct在進一步微調下可以提升性能。與強化學習結合可以進一步釋放LLM的潛力。
2 REACT: SYNERGIZING REASONING + ACTING
考慮到智能體與環境交互以解決問題的一般場景,在時間步 t t t時,一個智能體獲得當前環境的觀察 o t ∈ O o_t \in \mathcal{O} ot?∈O,然后遵循策略 π ( a t ∣ c t ) \pi (a_t|c_t) π(at?∣ct?)選擇動作 a t ∈ A a_t \in \mathcal{A} at?∈A,其中 c t = ( o 1 , a 1 , . . . , o t ? 1 , a t ? 1 , o t ) c_t = (o_1,a_1,...,o_{t-1},a_{t-1},o_t) ct?=(o1?,a1?,...,ot?1?,at?1?,ot?),即歷史觀察動作上下文。當歷史上下文與動作的映射很不清晰時,學習一個策略是具有挑戰的。
ReAct的思想很簡單,它將智能體的動作空間增強為 A ^ = A ∪ L \mathcal{\hat{A}}=\mathcal{A} \cup \mathcal{L} A^=A∪L,其中 L \mathcal{L} L是語言空間。動作 a ^ t ∈ L \hat{a}_t \in \mathcal{L} a^t?∈L在語言空間中,稱之為思想或者推理痕跡,它不會影響外部環境,通過上下文信息進行推理來支持接下來的動作。
然而,語言空間是無限的,在這個空間中學習是困難的,需要很強的先驗。而LLM只需要借助少量的示例先驗進行提示,就可以生成解決任務的語言思維。對于推理重要的任務,ReAct交替產生思維和動作,這樣解決問題的軌跡就由多步思想-動作-觀察步驟組成。
由于決策和推理的能力已經集成到LLM中,ReAct具有一些獨特的功能:
- 符合直覺,易于設計。
- 通用且靈活。ReAct適用于具有不同動作空間和推理需求的多種任務。
- 高性能且穩健。對新任務展現出強大的泛化能力。
- 和人類對齊且可控。ReAct決策和推理過程具有可解釋性,并且人類可以通過編輯思想來控制或糾正智能體的行為。
3 KNOWLEDGE-INTENSIVE REASONING TASKS
對于推理任務,ReAct通過與維基百科API交互,能夠檢索信息支持推理。
3.1 SETUP
作者在HotPotQA和FEVER兩個數據集上來驗證ReAct的知識檢索與推理能力。前者是多跳問答benchmark,需要對兩個或多個維基百科片段進行推理,后者是事實驗證benchmark,每個聲明都基于維基百科中存在的片段而標注為支持、反對或者信息不足。ReAct將只接收問題和聲明,依靠自己的內部知識和外部API交互來回答。
在動作空間上,作者設計了一個簡單的維基百科API,它具有三種類型的動作來支持交互式信息的檢索:
- search[entity]。返回相應實體前五個句子或者前五個近似的實體。
- lookup[string]。檢索出包含特定string的下一個句子。
- finish[answer]。完成任務給出答案。模擬人類的檢索過程。
3.2 METHODS
作者從訓練集中隨機選擇6個和3個示例,并手動編寫ReAct格式的軌跡用于小樣本的示例。類似于圖1中的1(d),每個軌跡都由多個思想-動作-觀察步驟組成。
在baseline部分,作者系統地消融了ReAct軌跡以構建多個baseline的prompt。
- 標準prompt。移除了軌跡中的思想,動作和觀察。
- CoT。移除了動作和觀察,只做推理。其中CoT-SC(多CoT投票)能持續提高CoT的性能。
- Acting-only prompt。移除了思想的過程。
在實驗部分,作者觀察到ReAct解決任務的過程更符合事實,CoT在推理邏輯上更準確,但容易受到幻覺的影響。因此,作者將ReAct和CoT-SC結合在一起,讓模型根據以下情形切換方法:
- ReAct未能在限定步驟給出答案,采用CoT-SC。
- 當n個CoT-SC樣本中多數答案少于一半,采用ReAct。
此外,由于手動構建推理路徑具有一定的挑戰,因此作者采用3000個有正確答案的軌跡來微調PALM-8/62B,用于軌跡的生成。
3.3 RESULTS AND OBSERVATIONS
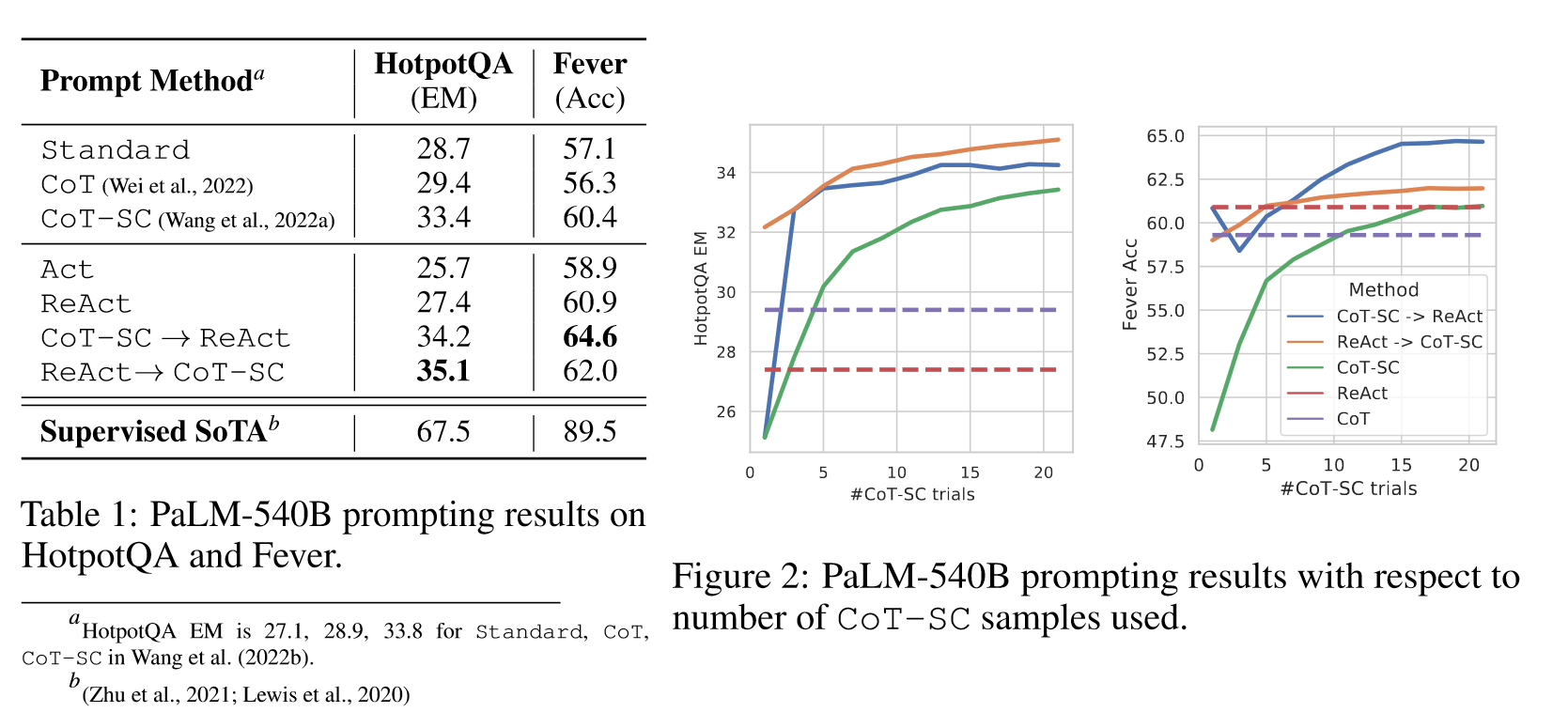
上圖顯示在兩個任務上,ReAct都要優于Act,這證明了推理對指導動作的價值。在HotPotQA數據集上,ReAct要略差于CoT,但是在Fever上要優于CoT。為了準確理解二者在HotPotQA上的差異,作者對結果進行了觀察,得到如下的分析:
- CoT中幻覺問題是個嚴重的問題。相比之下,ReAct解決問題的軌跡更值得
- 雖然推理和行動以及觀察步驟的交錯提高了ReAct的可信度,但是約束了其靈活性,導致其推理錯誤率高。
- 對于ReAct,通過搜索成功檢索出知識非常重要。
CoT-SC+ReAct的范式在兩個數據集上都得到了更好的結果,這表明正確結合模型內在知識和外在知識對模型推理具有顯著價值。
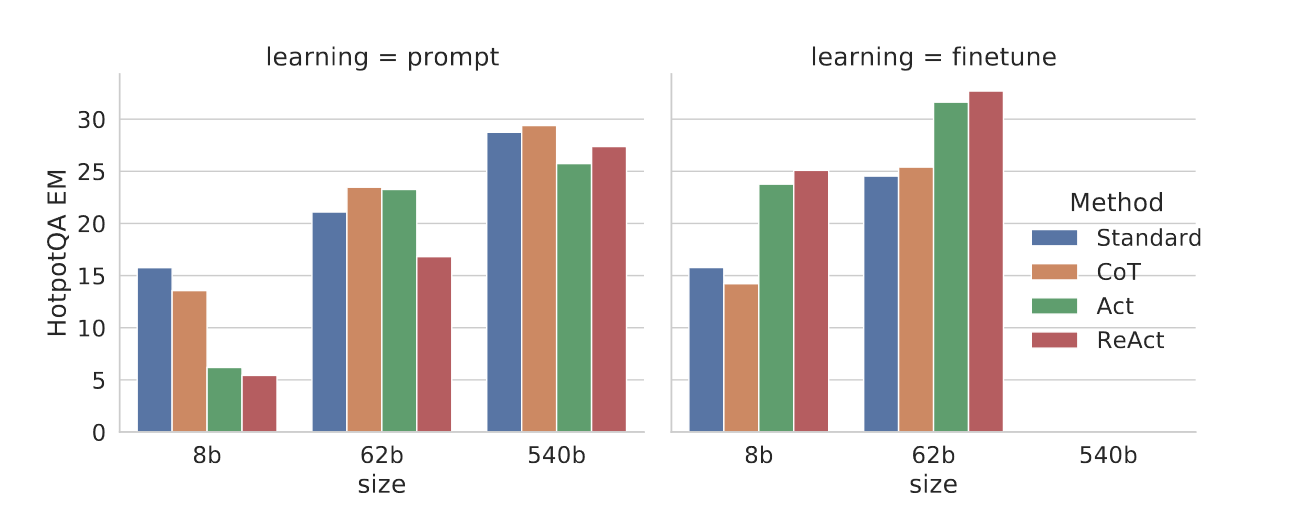
當對小模型進行微調后,8B的PaLM優于62Bprompt的PaLM,62B的PaLM優于540B的PaLM,此外,Standard和CoT與ReAct的差距拉大,原因是前者本質上是學習可能是錯誤的知識事實,而后者是教會模型如何推理和行動來訪問來自外部的知識。當然,現有的方法與特定領域的SoTA相距甚遠,作者認為精心微調會填平gap。
4 DECISION MAKING TASKS
作者還在語言交互決策任務ALFWorld和WebShop上測試了ReAct的能力。前者是一款基于合成文本的游戲,Agent需要通過文本操作與模擬家庭進行交互和導航,從而實現高級目標(6中類型任務)。特別的,ALFWorld有一個內置挑戰是你需要對常見家具的位置有一個概念。為了提示ReAct,對于每種任務類型,作者從訓練集中隨機標注了三個軌跡,每個軌跡都包括:
- 分解目標。
- 跟蹤子目標完成情況。
- 確定下一個子目標。
- 通過常識推斷下一個目標的位置以及如何操作。
作者在特定任務設置下的134個未見的任務上進行評估,為了魯棒性,作者在人工標注的基礎上為每個任務構建了6個prompt。baseline采用BUTLER,一種模仿學習智能體,針對每種任務進行了訓練。
WebShop是一個在線購物環境網站,擁有118萬個真實世界的產品和12k人工指令。它包含多種結構化和非結構化文本,需要智能體根據用戶指令購買商品。該任務通過500個測試指令的平均得分和成功率來評估。ReAct的提示包括帶有推理的搜索,選擇產品,選項和購買操作。作者將ReAct與模仿學習方法以及模仿+強化學習方法進行對比。
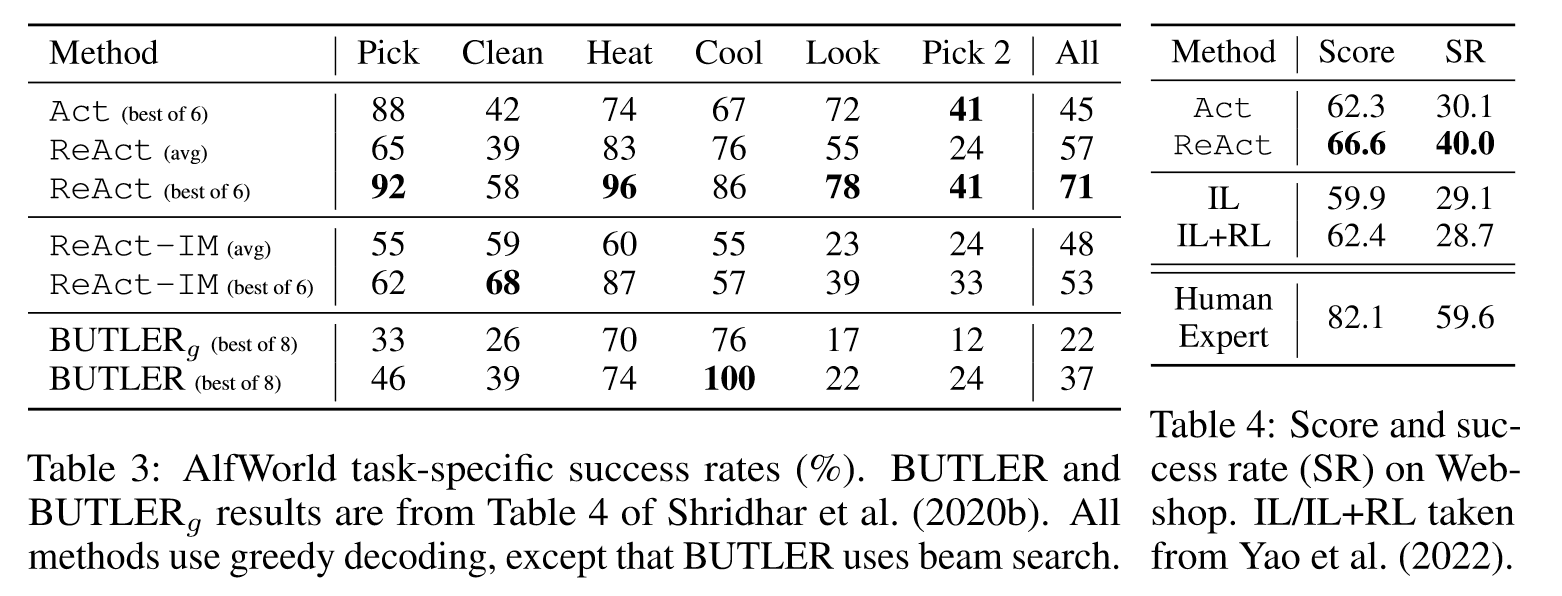
ReAct在兩個數據集上都要優于Act。在ALFWorld上,ReAct平均71%的成功率遠高于Act和BUTLER,在Webshop上,one-shot的Act已經達到了IL和IL+RL的方法。ReAct的性能更為突出,但是與人類表現仍然相去甚遠。此外,作者還和IM方法進行了消融實驗的對比,讓ReAct框架和IM結合,IM沒有采用LLM,它局限在對環境狀態進行觀察以及智能體需要完成什么才能滿足目標。由于缺少高級目標分解,ReAct-IM在該完成什么子目標的時候經常犯錯,由于缺乏常識推理,它難以定位家具的大概位置。
5 RELATED WORK
略。
6 CONCLUSION
本文提出ReAct,一個簡單有效的方法,基于LLM進行協同推理和行動。無論是在問答推理還是決策任務上都帶來了卓越的性能。盡管方法簡單,但是由于token長度的限制,在一些復雜的任務上做的不好(需要更多的演示)。雖然微調模型有效果,但是數據還是不夠。未來通過多任務訓練擴大ReAct的規模,與RL相結合,可能會產生更強大的Agent。
閱讀總結
在我看來,ReAct這篇工作可以說是2023年爆火的Agent的鼻祖,它的方法很簡單,思路很清晰,整篇工作最大的貢獻在于提出了一個初始Agent的范式,那就是推理+動作。一個真正意義上的Agent,就應該像人一樣,面對一個問題時先思考,再執行,走一步想一步,從而完成任務。當然了,Agent還得有自己的memory,有自己的技能庫,以及遇到問題時需要Planing,不過這都是后面Agent的發展了。最后,文中提到在復雜任務上,ReAct還是沒辦法做好,并且與人類的SOTA相差甚遠,其根本原因是Agent的能力不夠,當ChatGPT以及后續衍生產品的出現后,所有的這些GAP都會被填平。

















 如何忽略無意義的字符?達到更好的過濾效果?)

