本文內容來自尚硅谷B站公開教學視頻,僅做個人總結、學習、復習使用,任何對此文章的引用,應當說明源出處為尚硅谷,不得用于商業用途。
如有侵權、聯系速刪
視頻教程鏈接:【尚硅谷】Kafka3.x教程(從入門到調優,深入全面)
發送的目的就一個,將消息發到kafka集群里,整體流程如下:
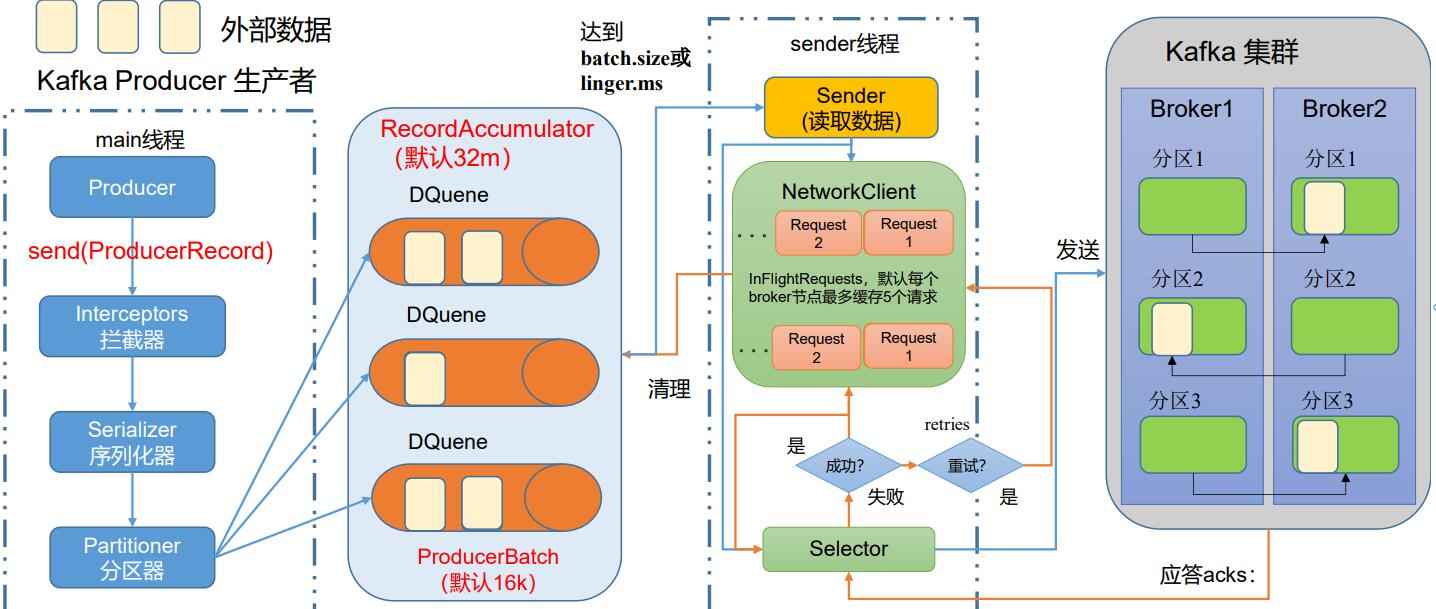
如上圖,首先要有一個發送消息的主線程,也就是main線程,然后有一個讀取數據的線程sender,所有的消息先經過攔截器(一般不用,因為大數據體系中,使用flume充當攔截器更加方便),然后抵達序列化器,最后抵達分區器,然后發送消息
為什么一般不用Java的序列化器?
Java的序列化過于笨重,一條消息要附帶很多比如安全等功能的額外信息,大數據場景下,這些額外信息的負擔太重,通常在spark、flink等框架中我們會自己實現序列化
分區器會在內存中,為每一個kafka分區創建一個雙端隊列,方便消息的管理,分區器大小為默認32M,每個隊列在數據達到16k時,由sender線程讀取,當然長時間達不到16k數據的隊列,也會每隔一段時間(默認0ms)發送一次,采用默認策略則意味著每條消息都發送,在大數據場景下,應當靈活調整
隊列數據累加上限的參數與等待發送時長的兩個參數為:batch.size,linger.ms
這里其實是創建了一個32M大小的臨時內存池,數據添加到隊列就是內存池分配內存的過程,發送成功后清理數據,就是內存回歸到內存池的過程
達到拉取條件(16k或時長)的數據,sender線程會主動從分區器內存空間中拉取數據,為每一個節點創建一個請求隊列,隊列中最多等待5個請求,發送到kafka集群,kafka給予應答回應
如果發送成功,則關閉、清理該請求,同時清理掉分區器隊列中相應的數據
如果發送失敗,則重試發送,直到重試到設定的次數為止(默認重試次數為int最大值)
應答級別分三種:
0:生產者發來的消息立即應答,不需要等到落盤
1:生產者發來的消息,等到leader收到數據后應答
-1:生產者發來的消息,等到leader和備份的所有節點都收到再應答


(沒用的方法,無法施行))
(持續更新))



覆蓋優化 - 附代碼)

到http)





(階段 : 智慧城市 - 智慧路燈))



