文章鏈接:Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts
發表期刊(會議): NeurIPS 2022
目錄
- 1.背景介紹
- 稀疏模型
- 2.內容摘要
- Sparse Mixture-of-Experts Models
- Contrastive Learning
- Experiment Analysis
- 3.文章總結
1.背景介紹
在實際應用中,多模態數據通常是高維度的,處理這樣的數據可能會導致計算和存儲開銷巨大。稀疏模型可以幫助緩解這種問題,因為它們具有較少的參數,可以有效地處理高維數據。因此,將稀疏性考慮到多模態學習中,可以在減少計算和存儲成本的同時,提高模型的性能和效率。
一些研究工作和實際應用嘗試將多模態數據與稀疏模型相結合,以更好地處理來自不同傳感器或數據源的信息。這種結合可能涉及將多模態數據轉換為稀疏表示形式,或者在多模態模型的構建中引入稀疏性,以提高處理效率和性能。這種融合可以幫助解決處理大規模多模態數據時的挑戰,并提供更高效的解決方案。稀疏模型可以作為處理多模態數據的一種方式,以降低計算和存儲開銷,并提高模型的效率和性能。在多模態學習的背景下,引入稀疏性可以是處理復雜數據的有效策略之一。
同時(多任務)或順序(持續學習)學習許多不同任務的密集模型(dense model)通常會受到負面干擾:過多的任務多樣性意味著最好為每個任務訓練一個模型,災難性遺忘意味著模型在早期任務中會隨著新任務的添加而變得更差。
稀疏模型
稀疏模型(Sparse models)在深度學習未來最有前途的方法中脫穎而出。 采用條件計算的 Sparse models 不是模型的每個部分都處理每個輸入(“dense” modeling),而是學習將各個輸入 “route” 到潛在龐大網絡中的不同 “experts” 。這有很多好處。
- 模型大小可以增加,同時保持計算成本不變。這是一種有效且更環保的模型縮放方式,也是高性能的關鍵。
- 稀疏性也自然地劃分了神經網絡。 稀疏模型有助于避免這兩種現象通過不將整個模型應用于所有輸入,模型中的“專家”可以專注于不同的任務或數據類型,同時仍然利用模型的共享部分。
Google Reaserch團隊長期以來一直致力于稀疏性的研究。 今天的人工智能模型通常只接受訓練做一件事。 Pathways 將使人們能夠訓練單個模型來完成數千或數百萬件事情。Pathways 總結了構建一個大型模型的研究愿景,該模型可以勤奮地處理數千個任務和眾多數據模式。

到目前為止,語言(Switch、Task-MoE、GLaM)和計算機視覺(Vision MoE)的稀疏單峰模型已經取得了相當大的進展。目前,谷歌團隊通過研究大型稀疏模型,通過與模態無關的 “Router” 同時處理圖像和文本,朝著 Pathways 愿景邁出了重要一步。 他們提出了多模態對比學習,它需要對圖像和文本都有深入的理解,以便將圖片與其正確的文本描述對齊。 迄今為止,解決此任務的最強大模型依賴于每種模式的獨立網絡(“two-tower”方法)。
2.內容摘要
本文提出了第一個使用MoE組合的大規模多模式架構
LIMoE。 它同時處理圖像和文本,但使用稀疏激活的自然專業專家。 在零樣本圖像分類方面,LIMoE 的性能優于可比較的密集多模態模型和雙塔方法。 最大的 LIMoE 零樣本 ImageNet 準確率達到 84.1%,與更昂貴的 state-of-the-art 模型相當。 稀疏性使 LIMoE 能夠優雅地擴展規模,并學會處理截然不同的輸入,從而解決多面手和專才之間的緊張關系。

LIMoE 架構包含許多“專家”,“Router” 決定將哪些 token(圖像或句子的一部分)發送給哪些專家。 經過專家層(灰色)和共享dense layer(棕色)處理后,最終輸出層計算圖像或文本的單個向量表示。
Sparse Mixture-of-Experts Models
Transformers 將數據表示為向量(或標記)序列。 雖然最初是為文本開發的,但它們可以應用于大多數可表示為標記序列的事物,例如圖像、視頻和音頻。 最近的大規模 MoE 模型在 Transformer 架構中添加了專家層(例如自然語言處理中的 gShard 和 ST-MoE,以及用于視覺任務的 Vision MoE)。
標準 Transformer 由許多“塊”組成,每個“塊”包含各種不同的層。 其中一層是前饋網絡 (FFN)。 對于 LIMoE 和上面引用的作品,這個單個 FFN 被包含許多并行 FFN 的專家層取代,每個 FFN 都是一個專家。 給定要處理的 token 序列,簡單的 Router 會學習預測哪些專家應該處理哪些 token 。 每個 token 僅激活少量專家,這意味著雖然模型容量由于擁有如此多的專家而顯著增加,但實際的計算成本是通過稀疏使用它們來控制的。 如果只激活一名專家,該模型的成本大致相當于標準Transformer 模型。
LIMoE 正是這樣做的,每個示例激活一名專家,從而匹配密集基線的計算成本。 不同的是LIMoE Router 可能會看到圖像或文本數據的標記。
當 MoE 模型嘗試將所有 token 發送給同一位專家時,會出現一種獨特的 failure。 通常,這是通過輔助損失和鼓勵平衡專家使用的額外培訓目標來解決的。 處理多種模式與稀疏性相互作用會導致現有輔助損失無法解決的新故障。 為了克服這個問題,本文開發了新的輔助損失(更多詳細信息見論文)并在訓練期間使用 Router 優先級(BPR),這兩項創新產生了穩定且高性能的多模態模型。

新的輔助損失(LIMoE aux) 和 Router 優先級(BPR) 穩定并提高了整體性能(左)并提高了路由行為的成功率(中和右)。 成功率低意味著路由器不會使用所有可用的專家,并且由于達到了單個專家的容量而丟棄了許多令牌,這通常表明稀疏模型學習得不好。 LIMoE 引入的組合可確保圖像和文本的高路由成功率,從而顯著提高性能。
Contrastive Learning
在多模態對比學習(Contrastive Learning)中,模型是根據成對的圖像文本數據(例如照片及其標題)進行訓練的。 通常,圖像模型提取圖像的表示,不同的文本模型提取文本的表示。 對比學習目標鼓勵圖像和文本表示對于相同的圖像-文本對接近,而對于不同對的內容則遠離。 這種具有對齊表示的模型可以適應新任務,無需額外的訓練數據(“零樣本”),例如,如果圖像的表示比單詞更接近單詞“dog”的表示,則圖像將被分類為狗 “貓”。 這個想法可以擴展到數千個類別,被稱為零樣本圖像分類。
CLIP 和 ALIGN(都是雙塔模型)擴展了這個過程,在流行的 ImageNet 數據集上實現了 76.2% 和 76.4% 的零樣本分類精度。 本文研究計算圖像和文本表示的單塔模型,發現這會降低 dense 模型的性能,可能是由于負面干擾或容量不足。 然而,計算匹配的 LIMoE 不僅比單塔密集模型有所改進,而且還優于雙塔密集模型。 本文使用與 CLIP 類似的訓練方案訓練了一系列模型。 我們的密集 L/16 模型實現了 73.5% 的零射擊精度,而 LIMoE-L/16 達到了 78.6%,甚至優于 CLIP 更昂貴的兩塔 L/14 模型 (76.2%)。 如下所示,與同等成本的密集模型相比,LIMoE 對稀疏性的使用提供了顯著的性能提升。
 對于給定的計算成本(x 軸),
對于給定的計算成本(x 軸),LIMoE 模型(圓圈、實線)明顯優于其密集基線(三角形、虛線)。 該架構指示底層Transformer的大小,從左 (S/32) 到右 (L/16) 增加。 S(小)、B(基本)和 L(大)指的是模型比例。 該數字指的是補丁大小,較小的補丁意味著較大的架構。
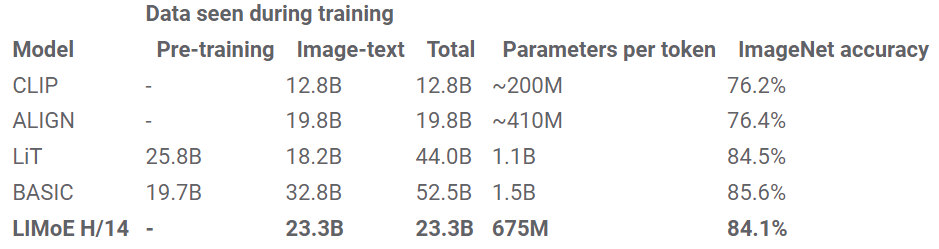
LiT 和 BASIC 將 dense two-tower model 的零樣本精度分別提高到了 84.5% 和 85.6%。 除了縮放之外,這些方法還利用了專門的預訓練方法,重新利用了已經具有極高質量的圖像模型。 LIMoE-H/14 沒有受益于任何預訓練或特定于模態的組件,但仍然從頭開始實現了可比的 84.1% 零樣本精度訓練。 這些模型的規模比較也很有趣:LiT 和 BASIC 分別是 2.1B 和 3B 參數模型。 LIMoE-H/14 總共有 5.6B 個參數,但通過稀疏性,每個 token 僅應用 675M 個參數,使其更加輕量級。
Experiment Analysis
LIMoE 的動機是稀疏條件計算使通用多模態模型仍然能夠發展擅長理解每種模態所需的專業化。 本文分析了 LIMoE 的專家層并發現了一些有趣的現象。
-
模式專門化專家的出現。在實驗的訓練設置中,圖像標記比文本標記多得多,因此所有專家都傾向于至少處理一些圖像,但有些專家要么主要處理圖像,要么主要處理文本,或兩者兼而有之。
 上圖展示了
上圖展示了 LIMoE八位專家的分配; 百分比表示專家處理的圖像標記的數量。 有一到兩名明顯專門研究文本的專家(主要由藍色專家表示),通常有兩到四名圖像專家(主要是紅色),其余的則處于中間位置。 -
圖像專家之間也存在一些清晰的定性模式。 例如,在大多數 LIMoE 模型中,都有一位專家處理所有包含文本的圖像塊。

在上面的示例中,有專家處理動物和綠色植物,也有專家處理人類雙手。LIMoE為每個token選擇一位專家。 在這里展示了 LIMoE-H/14 某一層上哪些圖像token被發送給哪些專家。 盡管沒有接受過這方面的培訓,但能觀察到專門研究植物或輪子等特定主題的語義專家的出現。
3.文章總結
處理許多任務的多模式模型是一條很有前途的前進道路,成功的關鍵因素有兩個:1.規模;2.在利用協同效應的同時避免不同任務和模式之間干擾的能力。 稀疏條件計算是實現這兩點的絕佳方法。 它支持高性能、高效的多面手模型,同時還具有出色完成單個任務所需的專業化能力和靈活性,正如 LIMoE 以更少的計算量實現的可靠性能所證明的那樣。
理解pod對象)

過大 轉不了float 用Decimal)


)

![[Linux] 基于LAMP架構安裝論壇](http://pic.xiahunao.cn/[Linux] 基于LAMP架構安裝論壇)


![[滲透測試學習] Devvortex - HackTheBox](http://pic.xiahunao.cn/[滲透測試學習] Devvortex - HackTheBox)








