
文章目錄
- -
- Abstract
- 1 Introduction
- 2 Related work
- former work
- 3 Method
- 3.1 Cross Stage Partial Network
- 3.2 Exact Fusion Model
- 4 Experiments
- 5 Conclusion
原文鏈接
源代碼
-
梯度信息重用(有別于冗余的梯度信息)可以減少計算量和內存占用提高效率,但會降低精度(可能是因為重用梯度信息帶來的近似誤差)
Abstract
神經網絡使最先進的方法在計算機視覺任務(如物體檢測)上取得了令人難以置信的結果。然而,這種成功在很大程度上依賴于昂貴的計算資源,這阻礙了擁有廉價設備的人們欣賞先進技術。在本文中,我們提出了跨階段部分網絡(CSPNet),以緩解以往的工作需要從網絡架構的角度進行大量推理計算的問題。我們將此問題歸因于網絡優化中梯度信息的重復。所提出的網絡通過集成網絡階段開始和結束的特征映射來尊重梯度的可變性,在我們的實驗中,在ImageNet數據集上以同等甚至更高的精度減少了20%的計算量,并且在MS COCO目標檢測數據集上的AP 50方面顯著優于最先進的方法。CSPNet很容易實現,并且足夠通用,可以處理基于ResNet、ResNeXt和DenseNet的架構
1 Introduction
當神經網絡變得更深[7,39,11]和更寬[40]時,神經網絡表現得尤為強大。然而,擴展神經網絡的架構通常會帶來更多的計算量,這使得像目標檢測這樣的計算量很大的任務對大多數人來說是負擔不起的。由于實際應用通常需要在小型設備上進行較短的推理時間,因此輕量化計算逐漸受到越來越多的關注,這對計算機視覺算法提出了嚴峻的挑戰。盡管一些方法是專門為移動CPU設計的[9,31,8,33,43,24],但它們采用的深度可分離卷積技術與工業IC設計(如邊緣計算系統的專用集成電路(ASIC))不兼容
在這項工作中,我們研究了最先進的方法(如ResNet, ResNeXt和DenseNet)的計算負擔,我們進一步開發計算效率高的組件,使上述網絡能夠同時部署在cpu和移動gpu上,而不會犧牲性能
在本研究中,我們介紹了跨階段部分網絡(CSPNet)。設計CSPNet的主要目的是使該體系結構能夠實現更豐富的梯度組合,同時減少計算量。這一目標是通過將基礎層的特征映射劃分為兩個部分,然后通過提出的跨階段層次結構將它們合并來實現的。我們的主要概念是通過拆分梯度流,使梯度流在不同的網絡路徑上傳播。通過這種方式,我們證實了通過切換拼接和轉換步驟,傳播的梯度信息可以有很大的相關差異。此外,CSPNet可以大大減少計算量,提高推理速度和精度,如圖1所示
提出的CSPNet可以應用于ResNet[7]、ResNeXt[39]、DenseNet[11]等。它不僅降低了網絡的計算成本和內存占用,而且有利于提高推理速度和準確性
本文提出的基于CSPNet的目標檢測器解決了以下三個問題:
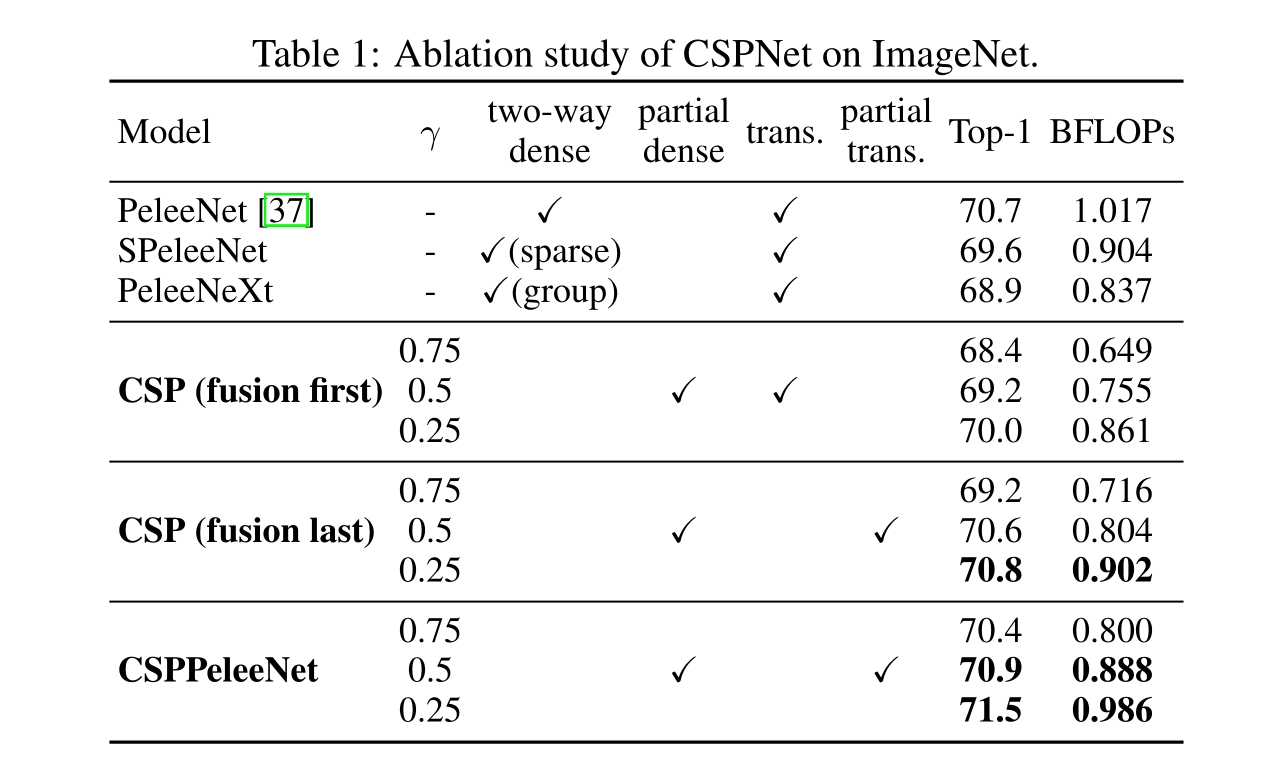
1)加強CNN的學習能力:現有的CNN在輕量化后精度大大降低,所以我們希望加強CNN的學習能力,使其在輕量化的同時保持足夠的精度。所提出的CSPNet可以很容易地應用于ResNet、ResNeXt和DenseNet。在上述網絡上應用CSPNet后,計算量可以從10%減少到20%,但在ImageNet[2]上進行圖像分類任務時,其準確率優于ResNet[7]、ResNeXt[39]、DenseNet[11]、HarDNet[1]、Elastic[36]和Res2Net[5]
2)消除計算瓶頸:過高的計算瓶頸將導致更多的周期來完成推理過程,或者一些算術單元經常會閑置。因此,我們希望能夠將CNN的計算量均勻地分布在每一層,這樣可以有效地提升每個計算單元的利用率,從而減少不必要的能耗。值得注意的是,提出的CSPNet使PeleeNet[37]的計算瓶頸減半。此外,在基于MS COCO[18]數據集的目標檢測實驗中,我們提出的模型在基于yolov3的模型上進行測試時,可以有效減少80%的計算瓶頸
3)降低內存成本:動態隨機存取存儲器(DRAM)的晶圓制造成本非常昂貴,并且占用大量空間。如果能有效降低內存成本,就能大大降低ASIC的成本。此外,小面積晶圓可用于各種邊緣計算設備。為了減少內存的使用,我們在特征金字塔生成過程中采用了跨通道池化[6]來壓縮特征映射。這樣,在生成特征金字塔時,使用目標檢測器的CSPNet可以減少PeleeNet 75%的內存使用
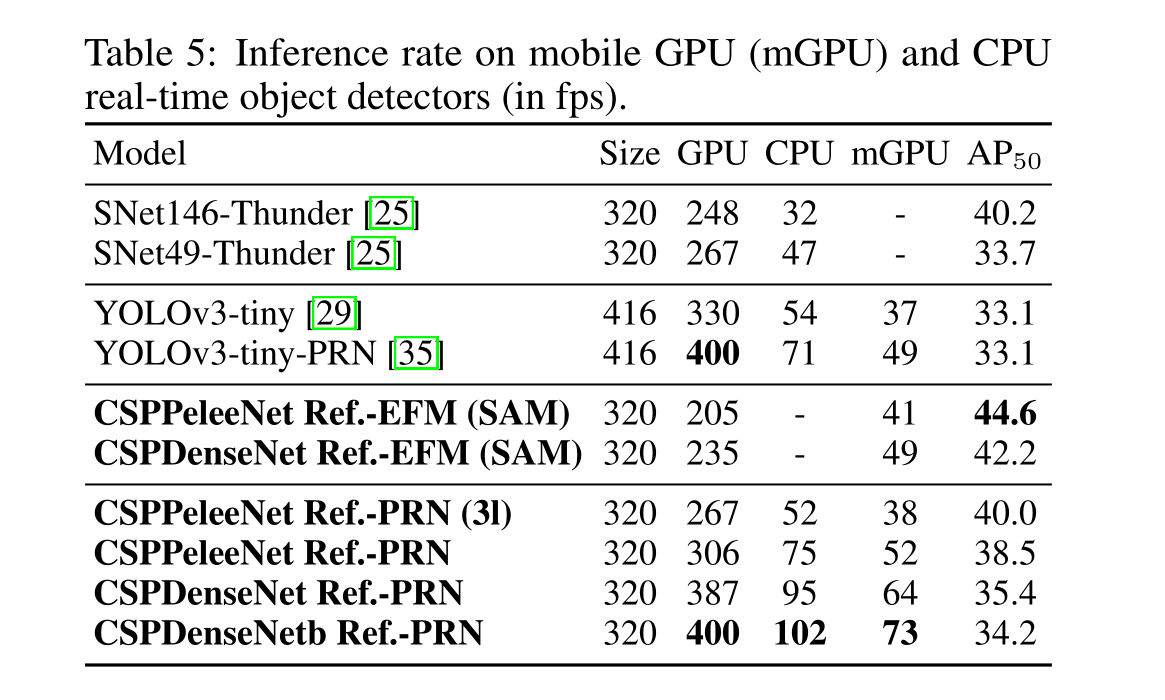
由于CSPNet能夠提高CNN的學習能力,因此我們使用更小的模型來獲得更好的精度。我們提出的模型可以在GTX 1080ti上以109 fps的速度實現50%的COCO AP 50。由于CSPNet可以有效地減少大量的內存流量,我們提出的方法可以在英特爾酷睿i9-9900K上以52 fps的速度實現40%的COCO AP 50。此外,由于CSPNet可以顯著降低計算瓶頸和精確融合模型(EFM)可以有效降低所需的內存帶寬,我們提出的方法可以在Nvidia Jetson TX2上以49 fps的速度實現42%的COCO AP 50
2 Related work
former work
CNN architectures design. :在ResNeXt[39]中,Xie等人首先證明了基數可以比寬度和深度的維度更有效。DenseNet[11]由于采用大量重用特征的策略,可以顯著減少參數和計算的數量。它將前面所有層的輸出特征連接起來作為下一個輸入,這可以被認為是最大化基數的方法。SparseNet[46]將密集連接調整為指數間隔連接,可以有效提高參數利用率,從而獲得更好的結果。Wang等人通過梯度組合的概念進一步解釋了為什么高基數和稀疏連接可以提高網絡的學習能力,并開發了partial ResNet (PRN)[35]。為了提高CNN的推理速度,Ma等[24]引入了四條需要遵循的準則,并設計了ShuffleNet-v2。Chao等人[1]提出了一種低內存流量CNN,稱為Harmonic DenseNet (HarDNet)和一種度量卷積輸入/輸出(CIO),它是與實際DRAM流量測量成比例的近似DRAM流量
Real-time object detector.最著名的兩種實時目標檢測器是YOLOv3[29]和SSD[21]。基于SSD的LRF[38]和RFBNet[19]可以在GPU上實現最先進的實時目標檢測性能。近年來,基于無錨點的目標檢測器[3,45,13,14,42]已成為主流的目標檢測系統。這種類型的兩個對象檢測器是CenterNet[45]和CornerNet-Lite[14],它們在效率和功效方面都表現得非常好。對于CPU或移動GPU上的實時目標檢測,基于ssd的Pelee[37]、基于yolov3的PRN[35]和基于Light-Head RCNN[17]的ThunderNet[25]在目標檢測方面都有很好的表現。
3 Method
3.1 Cross Stage Partial Network
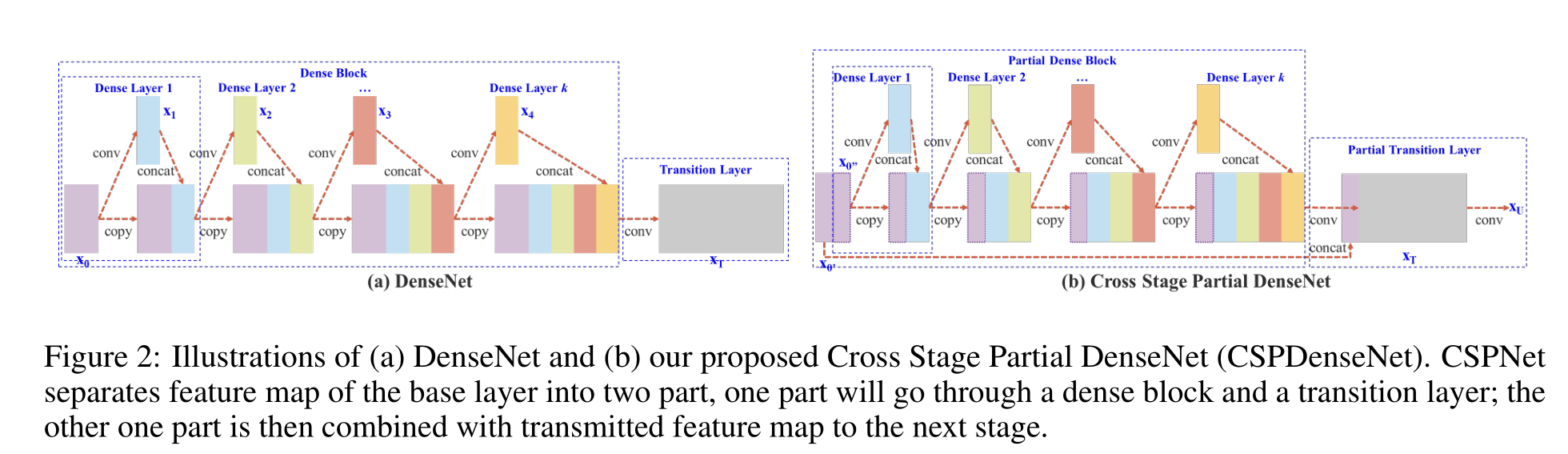
DenseNet.
圖2 (a)顯示了Huang等人[11]提出的DenseNet的一級詳細結構。DenseNet的每個階段包含一個密集塊和一個過渡層,每個密集塊由k個密集層組成。第i個密集層的輸出將與第i個密集層的輸入進行連接,連接后的結果將成為第(i + 1)個密集層的輸入。表示上述機理的方程可表示為:
其中*表示卷積算子,[x 0,x 1,…]表示連接x 0,x 1,…, w I和x I分別是第I層的權值和輸出
如果使用反向傳播算法更新權值,則權值更新方程為:
式中,f為權值更新函數,gI表示傳播到第I層的梯度。我們可以發現,在更新不同密度層的權重時,大量的梯度信息被重用。這將導致不同的密集層反復學習復制的梯度信息
Cross Stage Partial DenseNet.
CSPDenseNet的一級架構如圖2 (b)所示。CSPDenseNet的一級由部分密集塊和部分過渡層組成。在部分密集塊中,通過通道x 0 = [x0’,x0’']將一個階段中底層的特征映射分成兩部分。在x0’和x0‘’之間,前者直接連接到關卡的終點,而后者則會經過一個密密麻麻的街區。部分過渡層所涉及的所有步驟如下:首先,密集層的輸出,[x‘’0,x 1,…,x k],將經歷一個過渡層。其次,這個過渡層的輸出,x T,將與x ‘’0,再經過一個過渡層,然后產生輸出x U。CSPDenseNet的前饋傳遞和權值更新方程分別如式3和式4所示
我們可以看到,來自密集層的梯度是單獨積分的。另一方面,未經過密集層的特征映射x 0′也單獨積分。對于更新權值的梯度信息,兩邊不包含屬于其他邊的重復梯度信息。
總的來說,提出的CSPDenseNet保留了DenseNet的特征重用特性的優點,同時通過截斷梯度流防止了過多的重復梯度信息。該思想通過設計分層特征融合策略實現,并應用于局部過渡層
Partial Dense Block.
設計部分密集塊的目的是:1)增加梯度路徑:通過拆分合并策略,可以使梯度路徑的數量增加一倍。由于跨階段策略,可以減輕使用顯式特征映射復制進行連接所帶來的缺點
2)每層的平衡計算:通常,DenseNet的基礎層通道數遠大于增長率。由于局部密集塊中涉及密集層操作的基礎層通道僅占原始數量的一半,因此可以有效解決近一半的計算瓶頸
3.)減少內存流量:假設DenseNet中一個密集塊的基本特征圖大小為w × h × c,增長率為d,總共有m個密集層。則該密集塊的CIO為**(c × m) + ((m^2 + m) × d)/2**,部分密集塊的CIO為**((c × m) + (m 2 + m) × d)/2**。m和d通常遠小于c,部分密集塊最多可以節省網絡內存流量的一半
Partial Transition Layer.
設計部分過渡層的目的是為了使梯度組合的差異最大化。部分過渡層是一種分層特征融合機制,采用截斷梯度流的策略,防止不同層學習到重復的梯度信息。在這里,我們設計了CSPDenseNet的兩個變體,以展示這種梯度流截斷如何影響網絡的學習能力。3 ?和3 (d)顯示了兩種不同的融合策略。CSP (fusion first)是指將兩部分生成的特征圖進行拼接,然后進行轉換操作。如果采用這種策略,將會有大量的梯度信息被重用。對于CSP (fusion last)策略,密集塊的輸出將通過過渡層,然后與來自第1部分的特征映射進行拼接。如果使用CSP(最后融合)策略,梯度信息將不會被重用,因為梯度流被截斷了。如果我們使用3中所示的四種架構進行圖像分類,相應的結果如圖4所示。可以看出,如果采用CSP (fusion last)策略進行圖像分類,計算成本明顯下降,但前1的準確率僅下降0.1%。另一方面,CSP(融合優先)策略確實有助于顯著降低計算成本,但前1名的準確率顯著下降1.5%。通過跨階段使用拆分合并策略,可以有效地減少信息集成過程中重復的可能性。從圖4的結果可以明顯看出,如果能夠有效地減少重復的梯度信息,網絡的學習能力將會大大提高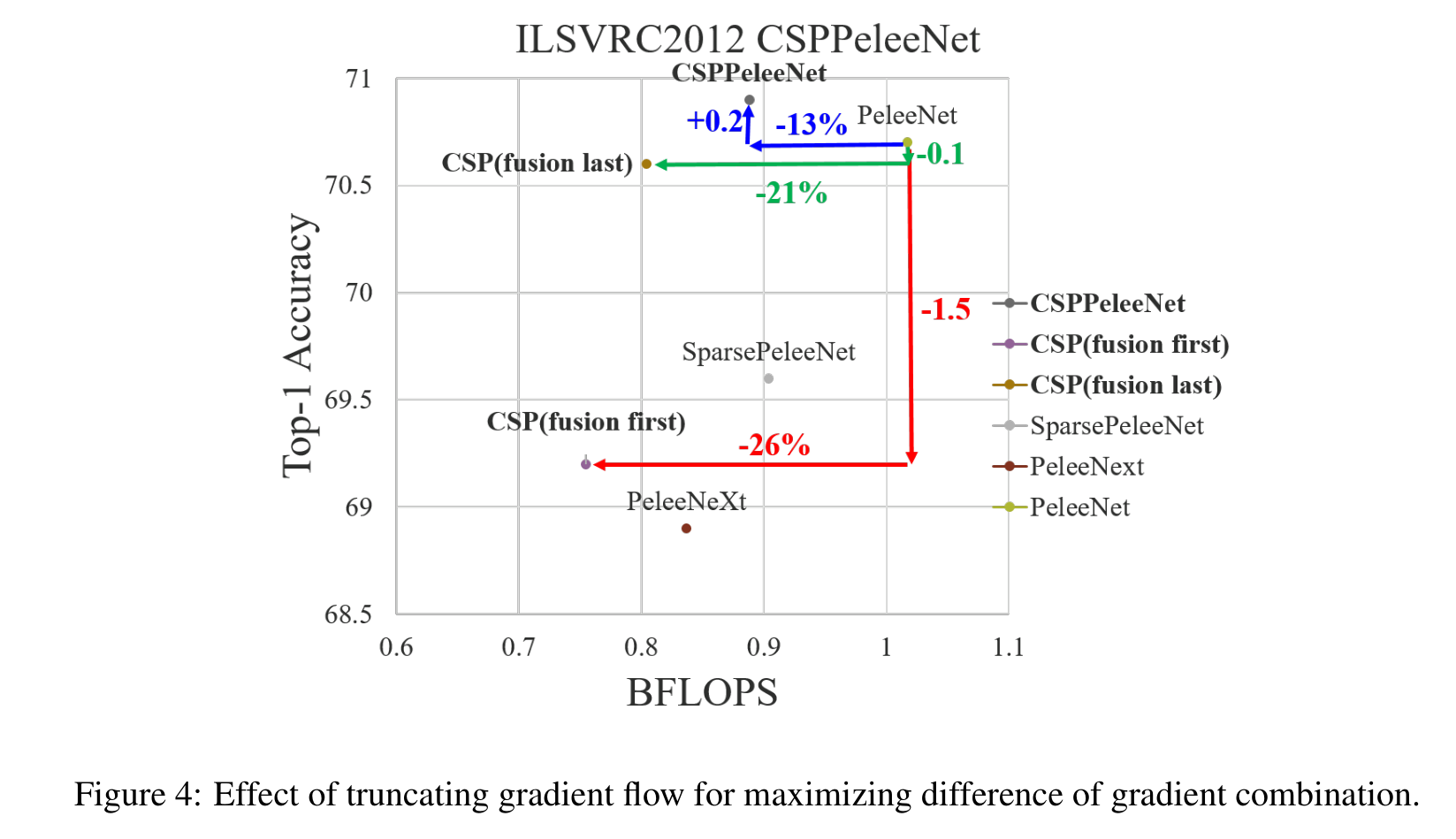
Apply CSPNet to Other Architectures.
CSPNet也可以很容易地應用于ResNet和ResNeXt,架構如圖5所示。由于只有一半的特征通道通過Res(X)塊,因此不再需要引入瓶頸層。這使得當浮點操作(FLOPs)固定時,內存訪問成本(MAC)的理論下限是固定的
3.2 Exact Fusion Model
Looking Exactly to predict perfectly.
我們提出了一種捕獲每個錨點適當視野(FoV)的EFM方法,提高了單級目標檢測器的精度。對于分割任務,由于像素級標簽通常不包含全局信息,因此為了更好地檢索信息,通常更傾向于考慮更大的補丁[22]。然而,對于像圖像分類和目標檢測這樣的任務,從圖像級和邊界框級標簽中觀察到的一些關鍵信息可能是模糊的。Li等人[15]發現CNN在從圖像級標簽中學習時經常會分心,并得出結論,這是兩階段目標檢測器優于一階段目標檢測器的主要原因之一
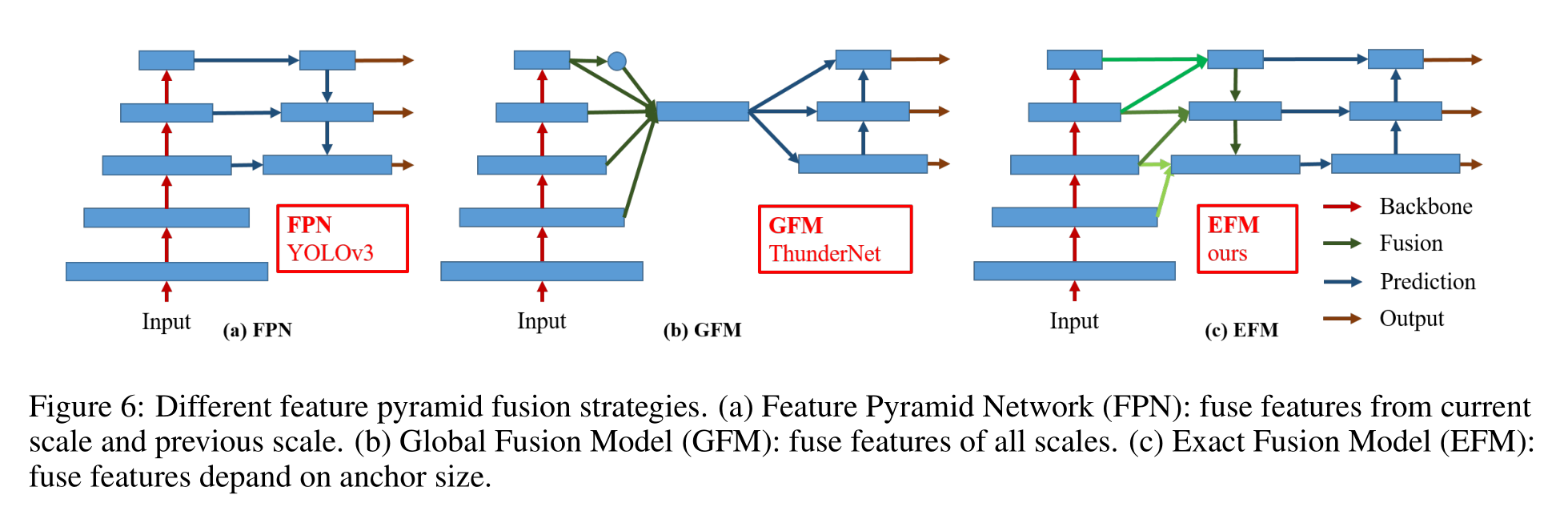
Aggregate Feature Pyramid.
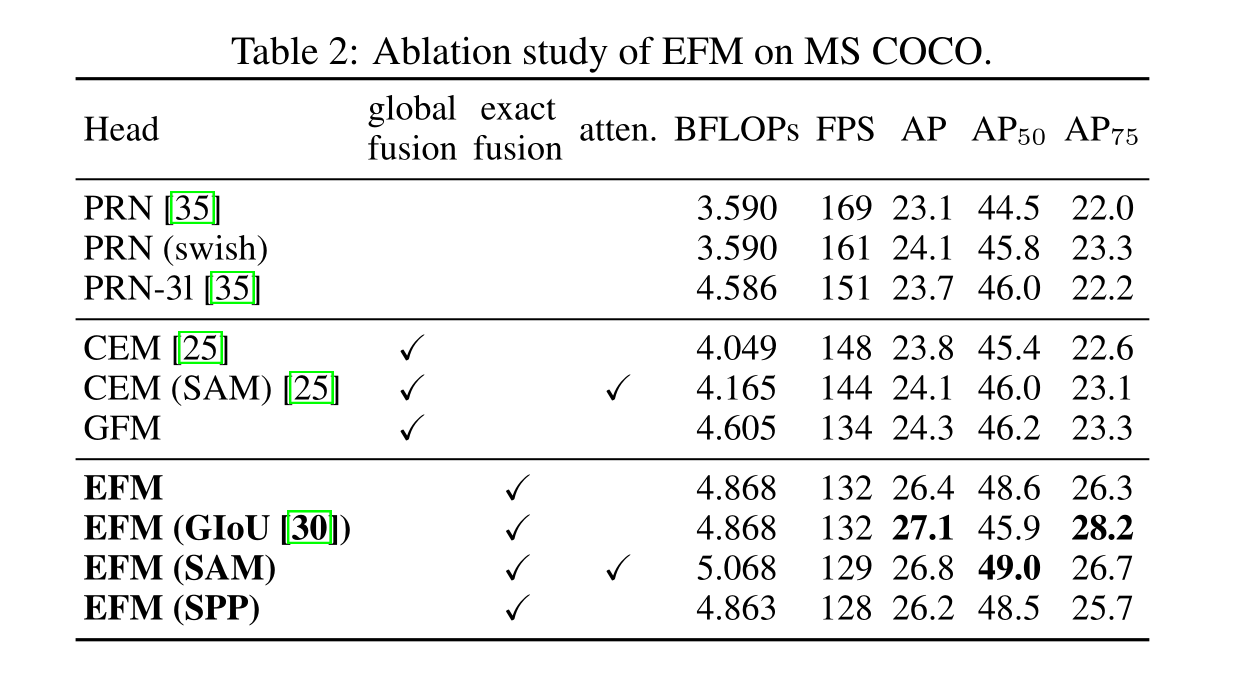
所提出的EFM能夠更好地聚合初始特征金字塔。EFM基于YOLOv3[29],它在每個基礎真值對象之前精確地分配了一個邊界框。每個接地真相邊界盒對應一個超過閾值IoU的錨定盒。如果錨框的大小等于網格單元的FoV,那么對于第s個尺度的網格單元,對應的邊界框的下界是(s - 1)個尺度,上界是(s+1)個尺度。因此,EFM集合了三個尺度的特征
Balance Computation.
由于特征金字塔中連接的特征映射是巨大的,它引入了大量的內存和計算成本。為了緩解這個問題,我們引入了Maxout技術來壓縮特征映射
4 Experiments


5 Conclusion
我們已經提出了CSPNet,使最先進的方法,如ResNet, ResNeXt和DenseNet是輕量級的移動gpu或cpu。其中一個主要的貢獻是我們已經認識到冗余的梯度信息問題,導致低效的優化和昂貴的推理計算。我們提出利用跨階段特征融合策略和截斷梯度流來增強學習到的特征在不同層內的可變性。此外,我們提出了結合Maxout操作的EFM來壓縮特征金字塔生成的特征映射,這大大降低了所需的內存帶寬,從而使推理足夠高效,可以與邊緣計算設備兼容。實驗表明,基于EFM的CSPNet在移動GPU和CPU上的實時目標檢測任務的準確率和推理率顯著優于競爭對手



)


`)

什么是模型訓練)



![[原創] FPGA的JTAG燒錄不穩定或燒錄失敗原因分析](http://pic.xiahunao.cn/[原創] FPGA的JTAG燒錄不穩定或燒錄失敗原因分析)




 的一個解)

)