目錄
一、環境
二、self-attention原理
三、完整代碼
一、環境
本文使用環境為:
- Windows10
- Python 3.9.17
- torch?1.13.1+cu117
- torchvision 0.14.1+cu117
二、self-attention原理
自注意力(Self-Attention)操作是基于 Transformer 的機器翻譯模型的基本操作,在源語言的編
碼和目標語言的生成中頻繁地被使用以建模源語言、目標語言任意兩個單詞之間的依賴關系。給
定由單詞語義嵌入及其位置編碼疊加得到的輸入表示 {xi ∈ Rd},為了實現對上下文語義依賴的建模,進一步引入在自注意力機制中涉及到的三個元素:查詢 qi(Query),鍵 ki(Key),值 vi (Value)。在編碼輸入序列中每一個單詞的表示的過程中,這三個元素用于計算上下文單詞所對應的權重得分。直觀地說,這些權重反映了在編碼當前單詞的表示時,對于上下文不同部分所需要的關注程度。具體來說,如圖所示,通過三個線性變換 WQ,WK ,WV 將輸入序列中的每一個單詞表示 xi 轉換為其對應的 qi,ki ,vi? 向量。
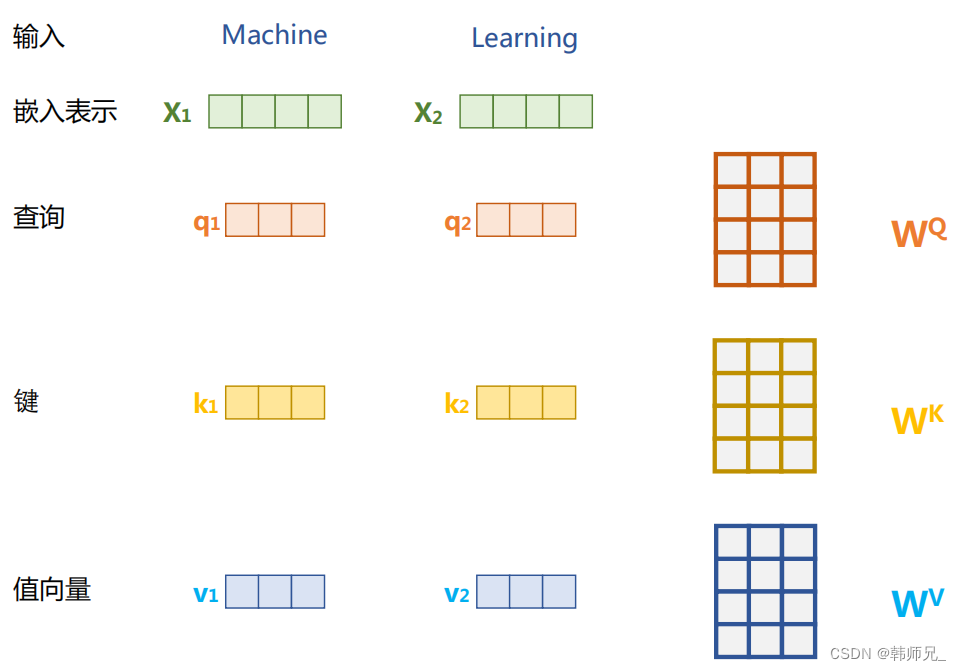
為了得到編碼單詞 xi 時所需要關注的上下文信息,通過位置 i 查詢向量與其他位置的鍵向量做點積得到匹配分數 qi · k1, qi · k2, ..., qi · kt。為了防止過大的匹配分數在后續 Softmax 計算過程中導致的梯度爆炸以及收斂效率差的問題,這些得分會除放縮因子 √d 以穩定優化。放縮后的得分經過 Softmax 歸一化為概率之后,與其他位置的值向量相乘來聚合希望關注的上下文信息,并最小化不相關信息的干擾。上述計算過程可以被形式化地表述如下:
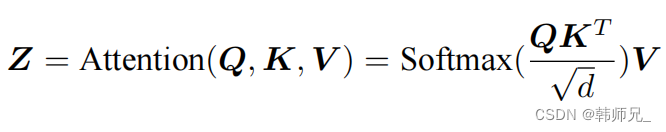
其中 Q? , K? ,V? 分別表示輸入序列中的不同單詞的 q, k, v 向量拼接組成的矩陣,L 表示序列長度,Z 表示自注意力操作的輸出。為了進一步增強自注意力機制聚合上下文信息的能力,提出了多頭自注意力(Multi-head Attention)的機制,以關注上下文的不同側面。具體來說,上下文中每一個單詞的表示 xi 經過多組線性 {WQ*WK*WV } 映射到不同的表示子空間中。公式會在不同的子空間中分別計算并得到不同的上下文相關的單詞序列表示{Zj}。最終,線性變換 WO 用于綜合不同子空間中的上下文表示并形成自注意力層最終的輸出 xi 。
三、完整代碼
import torch.nn as nn
import torch
import math
import torch.nn.functional as Fclass MultiHeadAttention(nn.Module):def __init__(self, heads, d_model, dropout = 0.1):super().__init__()self.d_model = d_modelself.d_k = d_model // heads # 512 / 8 self.h = headsself.q_linear = nn.Linear(d_model, d_model)self.v_linear = nn.Linear(d_model, d_model)self.k_linear = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)self.out = nn.Linear(d_model, d_model)def attention(self, q, k, v, d_k, mask=None, dropout=None):scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k) # self-attention公式# 掩蓋掉那些為了填補長度增加的單元,使其通過 softmax 計算后為 0if mask is not None:mask = mask.unsqueeze(1)scores = scores.masked_fill(mask == 0, -1e9)scores = F.softmax(scores, dim=-1) # self-attention公式if dropout is not None:scores = dropout(scores)output = torch.matmul(scores, v) # self-attention公式return outputdef forward(self, q, k, v, mask=None):bs = q.size(0) # 進行線性操作劃分為成 h 個頭k = self.k_linear(k).view(bs, -1, self.h, self.d_k)q = self.q_linear(q).view(bs, -1, self.h, self.d_k)v = self.v_linear(v).view(bs, -1, self.h, self.d_k)# 矩陣轉置k = k.transpose(1,2) q = q.transpose(1,2) v = v.transpose(1,2) # 計算 attentionscores = self.attention(q, k, v, self.d_k, mask, self.dropout)# 連接多個頭并輸入到最后的線性層concat = scores.transpose(1,2).contiguous().view(bs, -1, self.d_model)output = self.out(concat)return output# 準備q、k、v張量
d_model = 512
num_heads = 8
batch_size = 32
seq_len = 64q = torch.randn(batch_size, seq_len, d_model) # 64 x 512
k = torch.randn(batch_size, seq_len, d_model) # 64 x 512
v = torch.randn(batch_size, seq_len, d_model) # 64 x 512sa = MultiHeadAttention(heads = num_heads, d_model=d_model)
print(sa(q, k, v).shape) # torch.Size([32, 64, 512])
print('')



期末作業項目)









)




