目錄
- 一、介紹
- 1.1特點
- 1.2使用原因
- 1.3結構圖
- 1.4工作流程
- 二、安裝部署
- 2.1下載
- 2.2啟動
- 2.3監控日志文件
- 2.4自定義字段
- 三、連接Elasticsearch
- 四、工作原理
一、介紹
Filebeat是一個輕量級的日志和文件數據收集器,屬于Elastic Stack(ELK Stack)中的一個組件。它的主要作用是搜集、傳輸和轉發各種類型的日志和事件數據,將這些數據發送到中央的Elasticsearch集群或者Logstash進行處理和存儲。以下是Filebeat的一些關鍵特性和使用原因:
Filebeat的官網網址如下:https://www.elastic.co/cn/beats/filebeat
1.1特點
- 輕量級: Filebeat是一個小型的、輕量級的代理,對系統資源的消耗相對較低。
- 易于配置: Filebeat的配置相對簡單,可以通過YAML文件輕松配置日志路徑、數據輸入、輸出等。
- 多數據輸入: 支持多種輸入源,包括文件、日志文件、系統日志等。
- 多數據輸出: 可以將數據發送到Elasticsearch、Logstash等多個目標。
- 模塊化: 支持模塊化的配置,可輕松集成到Elastic Stack中。
- 實時性: 提供近實時的數據傳輸,支持快速檢測和響應。
1.2使用原因
- 集中日志管理: Filebeat幫助組織集中管理日志數據,通過將日志數據發送到Elasticsearch中,用戶可以使用Kibana等工具來輕松搜索和分析數據。
- 實時監控: Filebeat的實時數據傳輸能力使得用戶能夠迅速監測系統中發生的事件,幫助實現實時監控和警報。
- 日志數據分析: Filebeat能夠解析和發送各種日志格式,包括結構化和非結構化的數據,以便進行更深入的分析。
- 簡化數據流程: Filebeat通過將數據發送到Elasticsearch或Logstash,使得整個數據流程更為簡單和靈活。
- 集成到Elastic Stack: 作為Elastic Stack的一部分,Filebeat無縫集成到Elasticsearch、Logstash、Kibana等組件中,為日志和事件處理提供了完整的解決方案。
總體而言,Filebeat是一個強大的工具,使得日志和事件數據的搜集和處理變得更為簡單和高效。通過與其他Elastic Stack組件配合使用,用戶可以建立一個強大的實時日志分析和監控系統。
1.3結構圖

1.4工作流程
Filebeat的工作流程可以總結為以下幾個步驟:
- Input 輸入: 在Filebeat的配置中,可以指定多個數據輸入源,這些源可以是文件、日志文件、系統日志等。用戶可以使用通配符指定多個源,以便匹配到相應的日志文件。
- Harvester 收割機: 一旦Filebeat匹配到日志文件,就會啟動一個稱為Harvester的組件。Harvester負責從日志文件中源源不斷地讀取數據,確保Filebeat可以實時地捕捉到新的日志事件。
- Spooler 卷軸: Harvester將收割到的日志數據傳遞給Spooler,這是Filebeat內部的一個組件。Spooler的作用是將接收到的數據進行緩沖和處理,并將它們傳遞到后續的輸出目標。
- Output 輸出: Filebeat支持將數據發送到多個輸出目標,其中最常見的是Elasticsearch和Logstash。數據可以通過輸出插件配置,靈活地傳遞到用戶指定的目標,從而實現集中式存儲、分析和可視化。
整個流程中,Filebeat保證了日志數據的實時性,從而滿足了用戶對于快速響應和實時監控的需求。通過將Filebeat與Elasticsearch、Logstash等組件結合使用,用戶可以輕松地構建強大的實時日志處理和分析系統。
二、安裝部署
2.1下載
機器是直接wget下載
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.11.1-linux-x86_64.tar.gz
也可以去官網上下載 https://www.elastic.co/cn/downloads/beats/filebeat


下載完成后,就是解壓操作了
tar -zxvf filebeat-8.11.1-linux-x86_64.tar.gz
重命名
mv filebeat-8.11.1-linux-x86_64 filebeat
進入到filebeat目錄下,進行操作(需要新建一個.yml文件)
vim hmiyuan.yml
在文件輸入下面的內容
filebeat.inputs: # filebeat input輸入
- type: stdin # 標準輸入enabled: true # 啟用標準輸入
setup.template.settings: index.number_of_shards: 3 # 指定下載數
output.console: # 控制臺輸出pretty: true # 啟用美化功能enable: true
filebeat.inputs: 定義Filebeat的輸入源。在這里,您配置了一個stdin輸入,表示通過標準輸入讀取日志。setup.template.settings: 配置模板的一些設置。在這里,您指定了索引的分片數為 3。output.console: 配置Filebeat的輸出目的地。在這里,您將日志輸出到控制臺,并啟用了美化功能。
2.2啟動
./filebeat -e -c hmiyuan.yml
./filebeat -e -c hmiyuan.yml命令是在以hmiyuan.yml為配置文件運行 Filebeat,-e標志表示在啟動時顯示調試信息。
啟動成功畫面
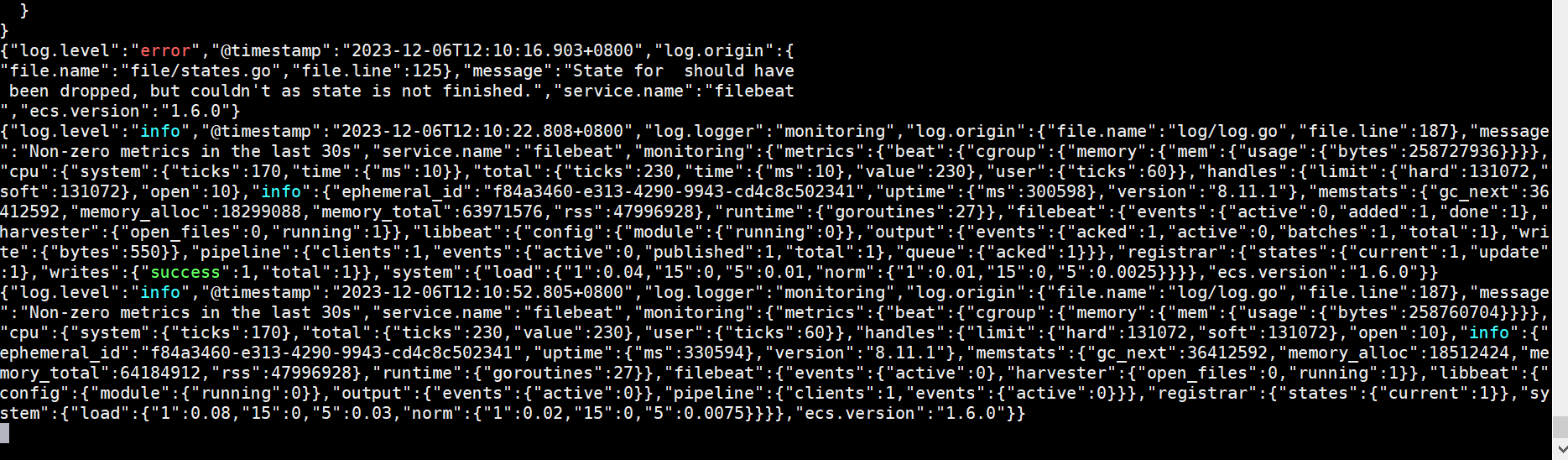
然后我們在控制臺輸入信息
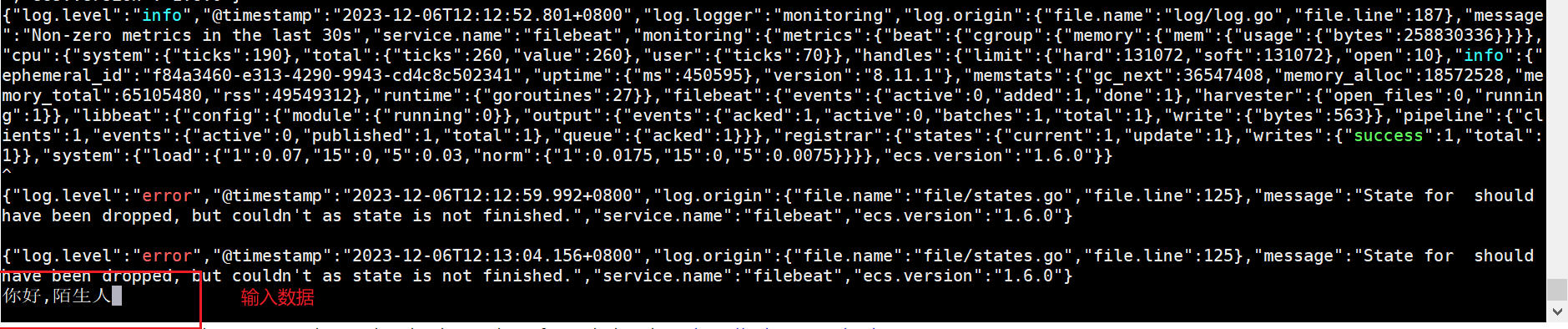
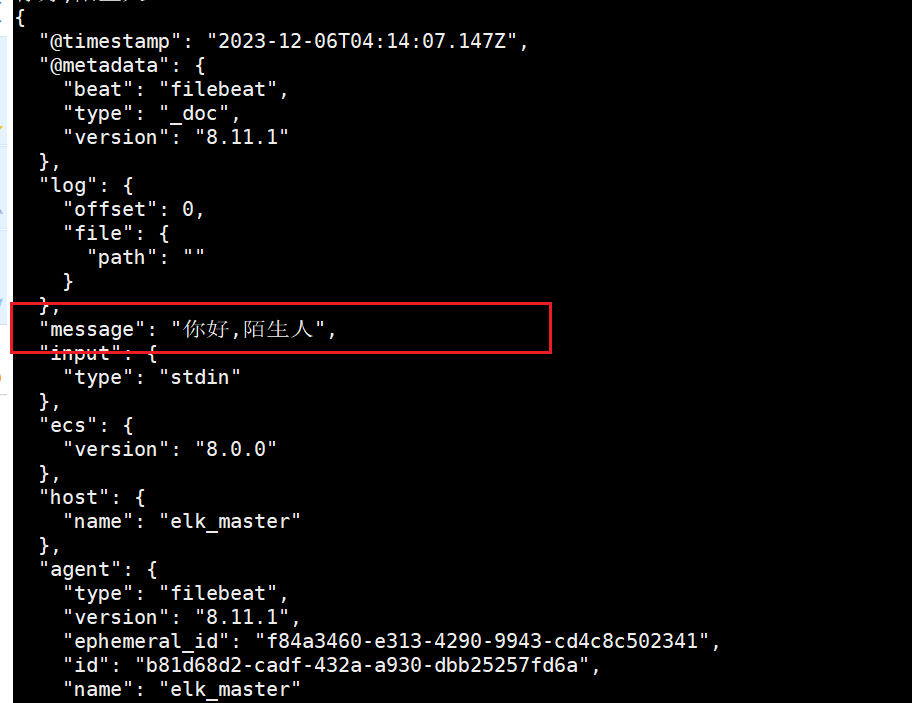
隨后我們在控制臺可以看到一個json格式的輸出,內容如下
 、
、
2.3監控日志文件
在filebeat目錄下創建一個“hmiyuan-log.yml”文件,文件內容如下:
filebeat.inputs:
- type: logenabled: truepaths:- /opt/elk/logs/*.log
setup.template.settings:index.number_of_shards: 3
output.console:pretty: trueenable: true
filebeat.inputs: 定義 Filebeat 的輸入配置,這里指定了一個日志輸入。
type: log: 表示輸入類型是日志文件。enabled: true: 啟用該輸入。paths: 指定要監視的日志文件路徑。在這個例子中,它監視/opt/elk/logs/目錄下所有以.log結尾的文件。
setup.template.settings: 用于設置模板相關的配置。
index.number_of_shards: 3: 設置 Elasticsearch 索引的分片數量為
output.console: 配置輸出到控制臺的設置。
pretty: true: 啟用漂亮的輸出,使日志更易讀。enable: true: 啟用控制臺輸出。
文件創建好了之后,我們需要創建上文中的path中文件了。
mkdir -p /opt/elk/logs
上面的配置完成后,我們就可以進行測試看是否配置完成了。
echo "hello world" >> /opt/elk/logs/test.log
重啟啟動filebeat并指定配置文件
./filebeat -e -c hmiyuan-log.yml
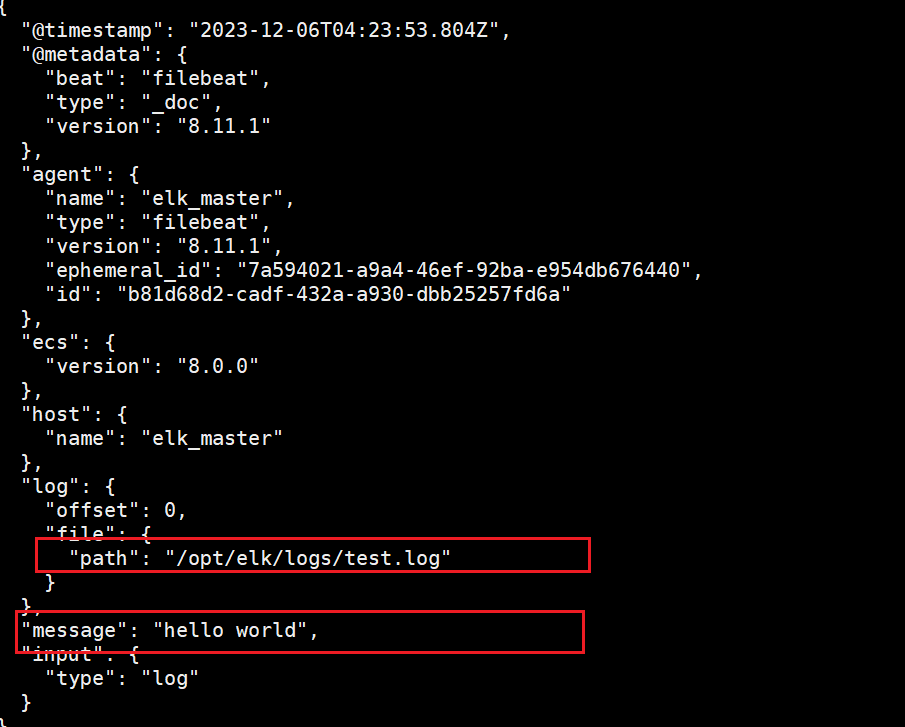
可以看到文件中的內容以及被filebeat讀取出來了
追加數據
echo "你好,陌生人" >> test.log
可以看到新增的數據也成功被收集了

在"/opt/elk/log"中的添加新文件,同時添加數據
echo "a new directory" >> one.log
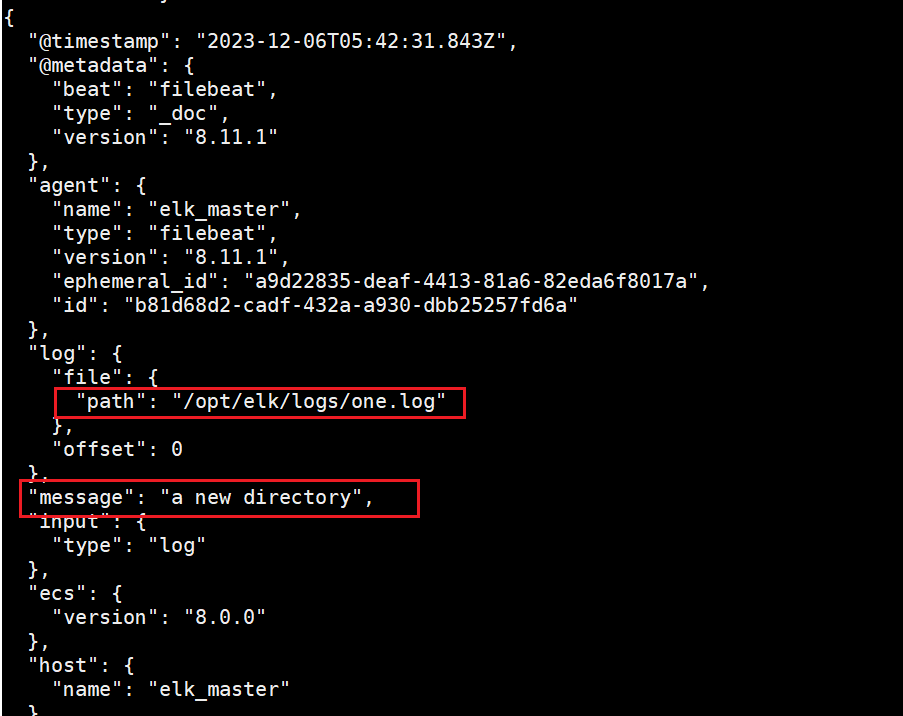
2.4自定義字段
當我們的元數據沒辦法支撐我們的業務時,我們還可以自定義添加一些字段.
修改"filebeat-log.yml"文件的內容。
filebeat.inputs:
- type: logenabled: truepaths:- /opt/elk/logs/*.logtags: ["web", "test"] fields: from: web-testfields_under_root: true
setup.template.settings:index.number_of_shards: 3
output.console:pretty: trueenable: true
新添加部分解析
Tags(標簽):
tags: ["web", "test"]這里通過
tags字段為事件添加了兩個標簽,即 “web” 和 “test”。標簽是一種用于標識事件的方式,它可以在后續的處理中用于過濾或分類事件。Fields(字段):
fields:from: web-test通過
fields字段添加了一個自定義字段,即from: web-test。這是一種為事件添加額外信息的方式,您可以根據需要添加不同的字段。在這個例子中,為事件指定了來源是 “web-test”。Fields Under Root(添加到根節點):
fields_under_root: true
fields_under_root設置為true,這表示將自定義字段添加到事件的根節點,而不是作為子節點。這樣,添加的字段會直接位于事件的頂層,而不是嵌套在其他字段中。這些配置的添加使您能夠在 Filebeat 采集的日志事件中附加額外的信息,以便更好地進行后續處理和分析。
修改完成后,重啟filebeat
./filebeat -e -c hmiyuan-log.yml
添加數據到“/opt/elk/logs/test.log”中
echo "a god day" >> /opt/elk/logs/test.log
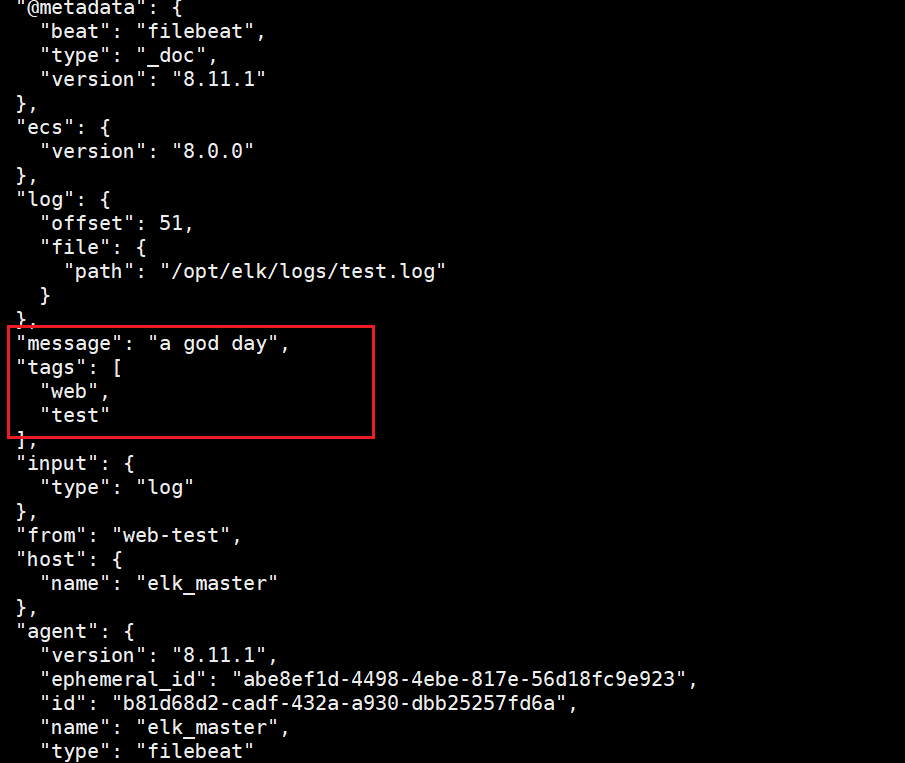
可以看到自定義字段已經成功顯示出來了。
三、連接Elasticsearch
繼續修改“hmiyuan-log.yml”文件,添加elasticsearch的ip以及暴露出來的端口號。
filebeat.inputs:
- type: logenabled: truepaths:- /opt/elk/logs/*.logtags: ["web", "test"]fields:from: web-testfields_under_root: false
setup.template.settings:index.number_of_shards: 1
output.elasticsearch:hosts: ["192.168.150.190:9200"] #這里填寫elasticsearch機器的ip以及端口,可以添加多臺機器
重啟啟動filebeat
./filebeat -e -c hmiyuan-log.yml
查看filebeat啟動的時候輸出的相關信息,可以看到已經成功連接到了190這臺機器上了,接下來繼續向"/opt/elk/log/"目錄下的文件輸入信息,查看elasticsearch是否也可以接收到數據。

向“test.log”文件追加信息。
echo "dog" >> /opt/elk/logs/test.log
在ES中,我們可以看到,多出了一個 filebeat的索引庫

然后我們瀏覽對應的數據,看看是否有插入的數據內容
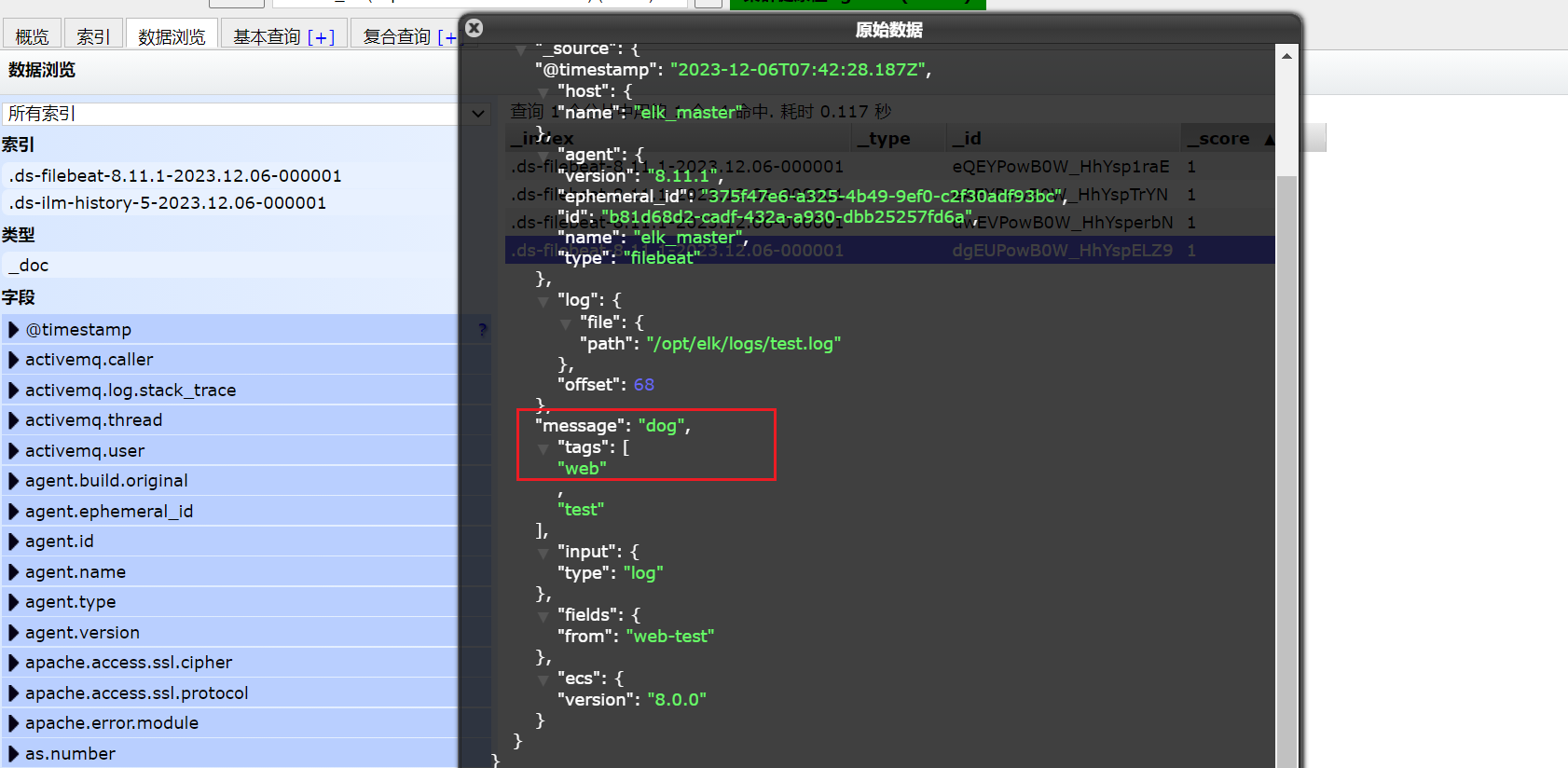
elasticsearch已經拿到了數據了,并展示到了elasticsearch-head中。
四、工作原理
Filebeat工作原理
Filebeat主要由下面幾個組件組成: harvester、prospector 、input
harvester
負責讀取單個文件的內容
harvester逐行讀取每個文件(一行一行讀取),并把這些內容發送到輸出
每個文件啟動一個harvester,并且harvester負責打開和關閉這些文件,這就意味著harvester運行時文件描述符保持著打開的狀態。
在harvester正在讀取文件內容的時候,文件被刪除或者重命名了,那么Filebeat就會續讀這個文件,這就會造成一個問題,就是只要負責這個文件的harvester沒用關閉,那么磁盤空間就不會被釋放,默認情況下,Filebeat保存問價你打開直到close_inactive到達
prospector
prospector負責管理harvester并找到所有要讀取的文件來源
如果輸入類型為日志,則查找器將查找路徑匹配的所有文件,并為每個文件啟動一個harvester
Filebeat目前支持兩種prospector類型:log和stdin
Filebeat如何保持文件的狀態
Filebeat保存每個文件的狀態并經常將狀態刷新到磁盤上的注冊文件中
該狀態用于記住harvester正在讀取的最后偏移量,并確保發送所有日志行。
如果輸出(例如ElasticSearch或Logstash)無法訪問,Filebeat會跟蹤最后發送的行,并在輸出再次可以用時繼續讀取文件。
在Filebeat運行時,每個prospector內存中也會保存的文件狀態信息,當重新啟動Filebat時,將使用注冊文件的數量來重建文件狀態,Filebeat將每個harvester在從保存的最后偏移量繼續讀取
文件狀態記錄在data/registry文件中
input
一個input負責管理harvester,并找到所有要讀取的源
如果input類型是log,則input查找驅動器上與已定義的glob路徑匹配的所有文件,并為每個文件啟動一個harvester
每個input都在自己的Go例程中運行


)












手動編譯開發庫(ubuntu+gcc+rk3588))



迭代器模式)