今天分享的AI系列深度研究報告:《AI大規模專題報告:大規模語言模型從理論到實踐》。
(報告出品方:光大證券)
報告共計:25頁



大規模語言模型基本概念
語言是人類與其他動物最重要的區別,而人類的多種智能也與此密切相關。邏輯思維以語言的形式表達,大量的知識也以文字的形式記錄和傳播。如今,互聯網上已經擁有數萬億網頁資源.其中大部分信息都是用自然語言描述。因此,如果人工智能算法想要獲取知識,就必須懂得如何理解人類所使用的不太精確、可能有歧義并且甚至有些混亂的語言。語言模型 (Language Model, LM)目標就是建模自然語言的概率分布。詞匯表V 上的語言模型,由函數 P(ww..wm)表示,可以形式化地構建為詞序列 wwwm 的概率分布,表示詞序列 ww2...wm 作為一個子出現的可能性大小。由于聯合概率 P(ww2...wm) 的參數量十分巨大,直接計算 P(ww2...wm) 非常困難7。按照《現代漢語詞典 (第七版)》包含約 7 萬單詞,句子長度按照 20 個詞計算,語言模型參數量達到 7.9792 x 109 的天文數字。中文的書面語中,超過 100 個單詞的句子也并不罕見,如果要將所有可能性都納入考慮,語言模型的復雜度還會進一步急劇增加,以目前的計算手段無法進行存儲和運算。
深度神經網絡需要采用有監督方法,使用標注數據進行訓練,因此,語言模型的訓練過程也不可避免需要構造訓練語料。但是由于訓練目標可以通過無標注文本直接獲得,從而使得模型的訓練僅需要大規模無標注文本即可。語言模型也成為了典型的自監督學習 (Self-supervised Learning任務。互聯網的發展,使得大規模文本非常容易獲取,因此訓練超大規模的基于神經網絡的語言模型也成為了可能。
受到計算機視覺領域采用 ImageNetlt3] 對模型進行一次預訓練,使得模型可以通過海量圖像充分學習如何提取特征,然后再根據任務目標進行模型精調的預訓練范式影響,自然語言處理領域基于預訓練語言模型的方法也逐漸成為主流。以 ELMo3] 為代表的動態詞向量模型開啟了語言模型預訓練的大門,此后以 GPT14 和 BERT 為代表的基于 Transformer 模型] 的大規模預訓練語言模型的出現,使得自然語言處理全面進入了預訓練微調范式新時代。將預訓練模型應用于下游任務時,不需要了解太多的任務細節,不需要設計特定的神經網絡結構,只需要“微調”預訓練模型,使用具體任務的標注數據在預訓練語言模型上進行監督訓練,就可以取得顯著的性能提升。這類方法通常稱為預訓練語言模型 (Pre-trained Language Models,PLM)。



大規模語言模型發展歷程
大規模語言模型的發展歷程雖然只有短短不到五年的時間,但是發展速度相當驚人,截止 2023年 6月,國內外有超過百種大模型相繼發布。中國人民大學趙鑫教授團隊在文獻181按照時間線給出 2019 年至 2023 年 5 月比較有影響力并且模型參數量超過 100 億的大規模語言模型,如圖1.2所示。大規模語言模型的發展可以粗略的分為如下三個階段:基礎模型、能力探索、突破發展。
基礎模型階段主要集中于 2018 年至 2021 年,2017 年 Vaswani 等人提出了 Transformerl2] 架構,在機器翻譯任務上取得了突破性進展。2018 年 Google 和 Open AI分別提出了 BERTI和GPT]間 模型,開啟了預訓練語言模型時代。BERT-Base 版本參數量為 1.1 億,BERT-Large 的參數量為 3.4 億,GPT-1 的參數量 1.17 億。這在當時,相比其它深度神經網絡的參數量已經是有數量級上提升。2019 年 Open AI 又發布了 GPT-24),其參數量達到了 15 億。此后,Google 也發布了參數規模為 110 億的 T5[19 模型。2020 年 Open AI 進一步將語言模型參數量擴展到 1750 億,發布了GPT-3S]。此后,國內也相繼推出了一系列的大規模語言模型,包括清華大學 ERNIE(THU)20百度 ERNIE(Baidu)21]、華為盤古-a[22] 等。這個階段研究主要集中語言模型本身,包括僅編碼器Encoder Only)、編碼器-解碼器 (Encoder-Decoder)、僅解碼器(Decoder Only) 等各種類型的模型結構都有相應的研究。模型大小與 BERT 相類似的算法,通常采用預訓練微調范式,針對不同下游任務進行微調。但是模型參數量在 10 億以上時,由于微調的計算量很高,這類模型的影響力在當時相較 BERT 類模型有不小的差距。
能力探索階段集中于 2019 年至 2022 年,由于大規模語言模型很難針對特定任務進行微調研究人員們開始探索在不針對單一任務進行微調的情況下如何能夠發揮大規模語言模型的能力.2019 年 Radford 等人在文獻[4] 就使用 GPT-2 模型究了大規模語言模型在零樣本情況下的任務處理能力。在此基礎上,Brown 等人在 GPT-3S] 模型上研究了通過語境學習(In-Context Learning進行少樣本學習的方法。將不同任務的少量有標注的實例拼接到待分析的樣本之前輸入語言模型使用語言模型根據實例理解任務并給出正確結果。在包括 TriviaQA、WebOS、CoQA 等評測集臺都展示出了非常強的能力,在有些任務中甚至超過了此前的有監督方法。上述方法不需要修改語言模型的參數,模型在處理不同任務時無需花費的大量計算資源進行模型微調。但是僅依賴基于語言模型本身,其性能在很多任務上仍然很難達到有監督學習效果,因此研究人員們提出了指令微調(Instruction Tuning)[23] 方案,將大量各類型任務,統一為生成式自然語言理解框架,并構造訓練語料進行微調。大規模語言模型一次性學習數千種任務,并在未知任務上展現出了很好的泛化能力。2022 年 Ouyang 等人提出了使用有監督微調再結合強化學習方法,使用少量數據有監督就可以使得大規模語言模型服從人類指令的 InstructGPT 算法24]。Nakano 等人則探索了結合搜索引擎的問題回答算法 WebGPT[25 。這些方法從直接利用大規模語言模型進行零樣本和少樣本學習的基礎上,逐漸擴展到利用生成式框架針對大量任務進行有監督微調的方法,有效提升了模型的性能。


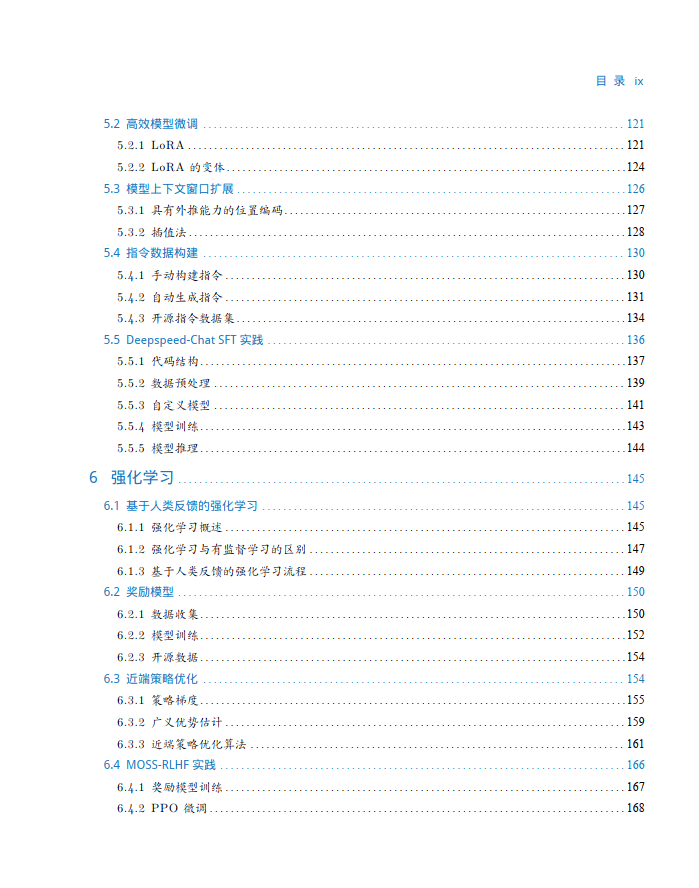
大規模語言模型構建流程
根據 OpenAI 聯合創始人 Andrej Karpathy 在微軟 Build 2023 大會上所公開的信息,OpenAI 所 使用的大規模語言模型構建流程如圖1.3所示。主要包含四個階段:預訓練、有監督微調、獎勵建 模、強化學習。這四個階段都需要不同規模數據集合以及不同類型的算法,會產出不同類型的模 型,同時所需要的資源也有非常大的差別。
預訓練(Pretraining)階段需要利用海量的訓練數據,包括互聯網網頁、維基百科、書籍、GitHub、 論文、問答網站等,構建包含數千億甚至數萬億單詞的具有多樣性的內容。利用由數千塊高性能 GPU 和高速網絡組成超級計算機,花費數十天完成深度神經網絡參數訓練,構建基礎語言模型 (Base Model)。基礎大模型構建了長文本的建模能力,使得模型具有語言生成能力,根據輸入的 提示詞(Prompt),模型可以生成文本補全句子。也有部分研究人員認為,語言模型建模過程中 也隱含的構建了包括事實性知識(Factual Knowledge)和常識知識(Commonsense)在內的世界知 識(World Knowledge)。根據文獻 [46] 介紹,GPT-3 完成一次訓練的總計算量是 3640PFlops,按照 NVIDIA A100 80G 和平均利用率達到 50% 計算,需要花費近一個月時間使用 1000 塊 GPU 完成。

Transformer 模型
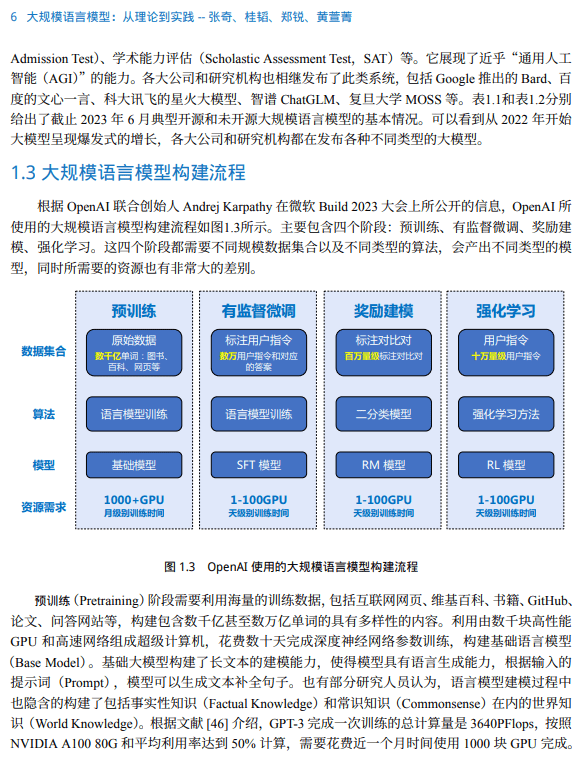
Transformer 模型是由谷歌在 2017 年提出并首先應用于機器翻譯的神經網絡模型結構。機 器翻譯的目標是從源語言(Source Language)轉換到目標語言(Target Language)。Transformer 結 構完全通過注意力機制完成對源語言序列和目標語言序列全局依賴的建模。當前幾乎全部大語言 模型都是基于 Transformer 結構,本節以應用于機器翻譯的基于 Transformer 的編碼器和解碼器介紹該模型。
基于 Transformer 結構的編碼器和解碼器結構如圖2.1所示,左側和右側分別對應著編碼器(Encoder)和解碼器(Decoder)結構。它們均由若干個基本的 Transformer 塊(Block)組成(對應著圖 中的灰色框)。這里 N× 表示進行了 N 次堆疊。每個 Transformer 塊都接收一個向量序列 {xi} t i=1 作為輸入,并輸出一個等長的向量序列作為輸出 {yi} t i=1。這里的 xi 和 yi 分別對應著文本序列 中的一個單詞的表示。而 yi 是當前 Transformer 塊對輸入 xi 進一步整合其上下文語義后對應的輸 出。

生成式預訓練語言模型 GPT
受到計算機視覺領域采用 ImageNet對模型進行一次預訓練,使得模型可以通過海量圖像充分學習如何提取特征,然后再根據任務目標進行模型微調的范式影響,自然語言處理領域基于預訓練語言模型的方法也逐漸成為主流。以 ELMo] 為代表的動態詞向量模型開啟了語言模型預訓練的大門,此后以 GPT4 和 BERT 為代表的基于 Transformer 的大規模預訓練語言模型的出現,使得自然語言處理全面進入了預訓練微調范式新時代。利用豐富的訓練語料、自監督的預訓練任務以及 Transformer 等深度神經網絡結構,預訓練語言模型具備了通用且強大的自然語言表示能力,能夠有效地學習到詞匯、語法和語義信息。將預訓練模型應用于下游任務時,不需要了解太多的任務細節,不需要設計特定的神經網絡結構,只需要“微調”預訓練模型,即使用具體任務的標注數據在預訓練語言模型上進行監督訓練,就可以取得顯著的性能提升。
OpenAI公司在 2018 年提出的生成式預訓練語言模型(Generative Pre-Training,GPT) 4 是典型的生成式預訓練語言模型之一。GPT 模型結構由多層 Transformer 組成的單向語言模型,主要分為輸入層,編碼層和輸出層三部分。


語言模型訓練數據
大語言模型訓練需要數萬億的各類型數據。如何構造海量“高質量”數據對于大語言模型的訓練具有至關重要的作用。雖然,截止到 2023 年9 月為止,還沒有非常好的大模型的理論分析和解釋,也缺乏對語言模型訓練數據的嚴格說明和定義。但是,大多數研究人員都普遍認為訓練數據是影響大語言模型效果以及樣本泛化能力的關鍵因素之一。從此前的研究來看,預訓練數據需要涵蓋各種類型。包括網絡數據、圖書、論文、百科和社交媒體等,還需要覆蓋盡可能多的領域語言、文化和視角,從而提高大語言模型的泛化能力和適應性。


報告共計:25頁








多邊形方法)


:轉義符)



)



