文本嵌入,也稱為詞嵌入,是文本數據的高維、密集向量表示,可以測量不同文本之間的語義和句法相似性。它們通常是通過在大量文本數據上訓練 Word2Vec、GloVe 或 BERT 等機器學習模型來創建的。這些模型能夠捕獲單詞和短語之間的復雜關系,包括語義、上下文,甚至語法的某些方面。這些嵌入可用于語義搜索等任務,其中文本片段根據含義或上下文的相似性進行排名,以及其他自然語言處理任務,如情感分析、文本分類和機器翻譯。
嵌入 API 的演變和出現
在自然語言處理(NLP)領域,文本嵌入從根本上改變了我們理解和處理語言數據的方式。通過將文本信息轉換為數字數據,文本嵌入促進了復雜的機器學習算法的開發,該算法能夠進行語義理解、上下文識別和更多基于語言的任務。在本文[1]中,我們探討了文本嵌入的進展并討論了嵌入 API 的出現。
文本嵌入的起源
在NLP的早期階段,使用了one-hot編碼和詞袋(BoW)等簡單技術。然而,這些方法未能捕捉語言的上下文和語義的復雜性。每個單詞都被視為一個孤立的單元,不了解它與其他單詞的關系或其在不同上下文中的用法。
Word2Vec

2013 年 Google 推出的 Word2Vec 標志著 NLP 領域的重大飛躍。 Word2Vec 是一種使用神經網絡從大型文本語料庫中學習單詞關聯的算法。因此,它生成單詞的密集向量表示或嵌入,捕獲大量語義和句法信息。單詞的上下文含義可以通過高維空間中向量的接近程度來確定。
GloVe:用于單詞表示的全局向量
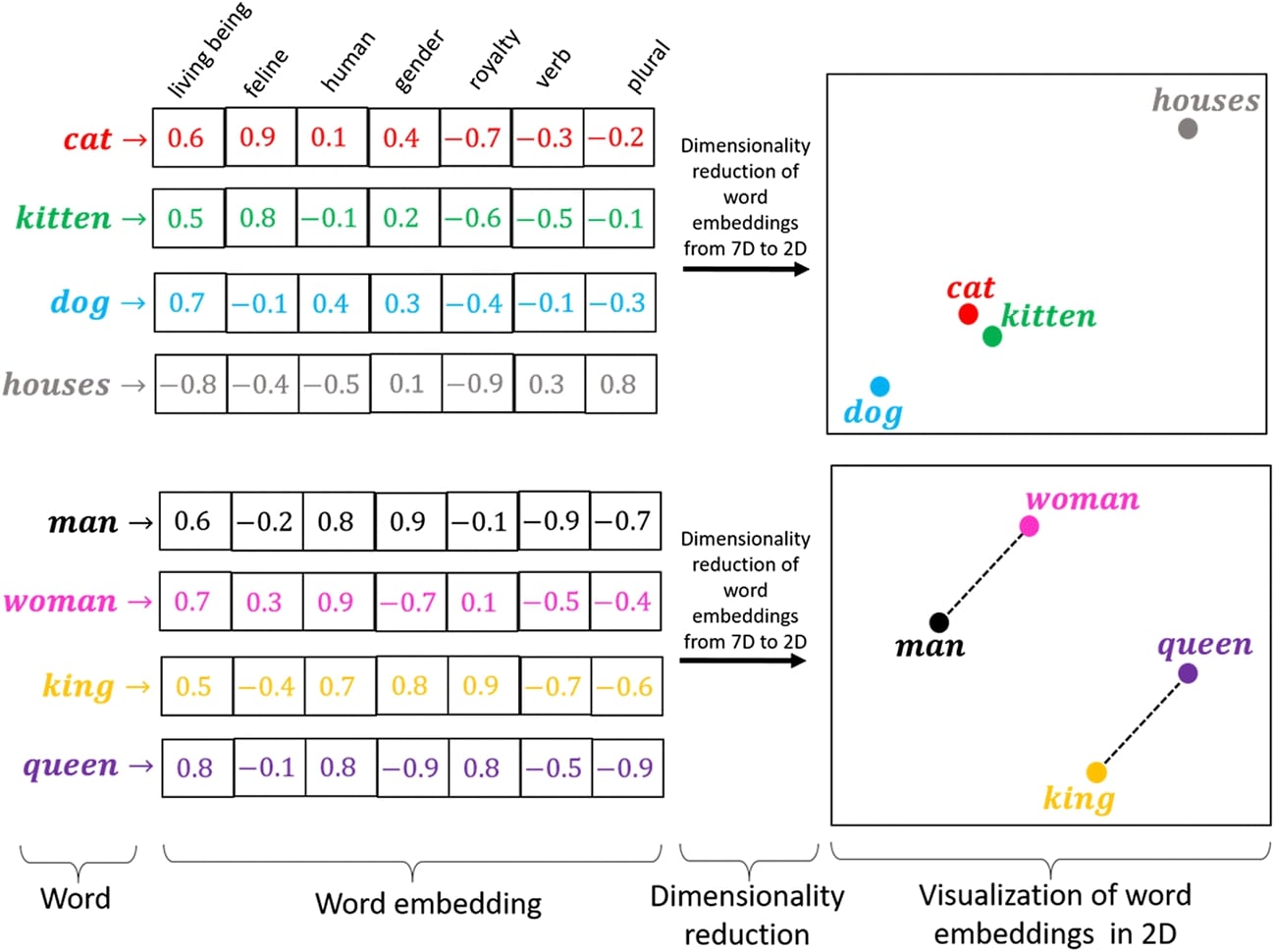
斯坦福大學的研究人員在 2014 年推出了 GloVe,進一步推進了詞嵌入的概念。GloVe 通過在整個語料庫中更全面地檢查統計信息來創建詞向量,從而在 Word2Vec 的基礎上進行了改進。通過考慮本地上下文窗口和全局語料庫統計數據,它可以實現更細致的語義理解。
基于 Transformer 的嵌入:BERT 及其變體
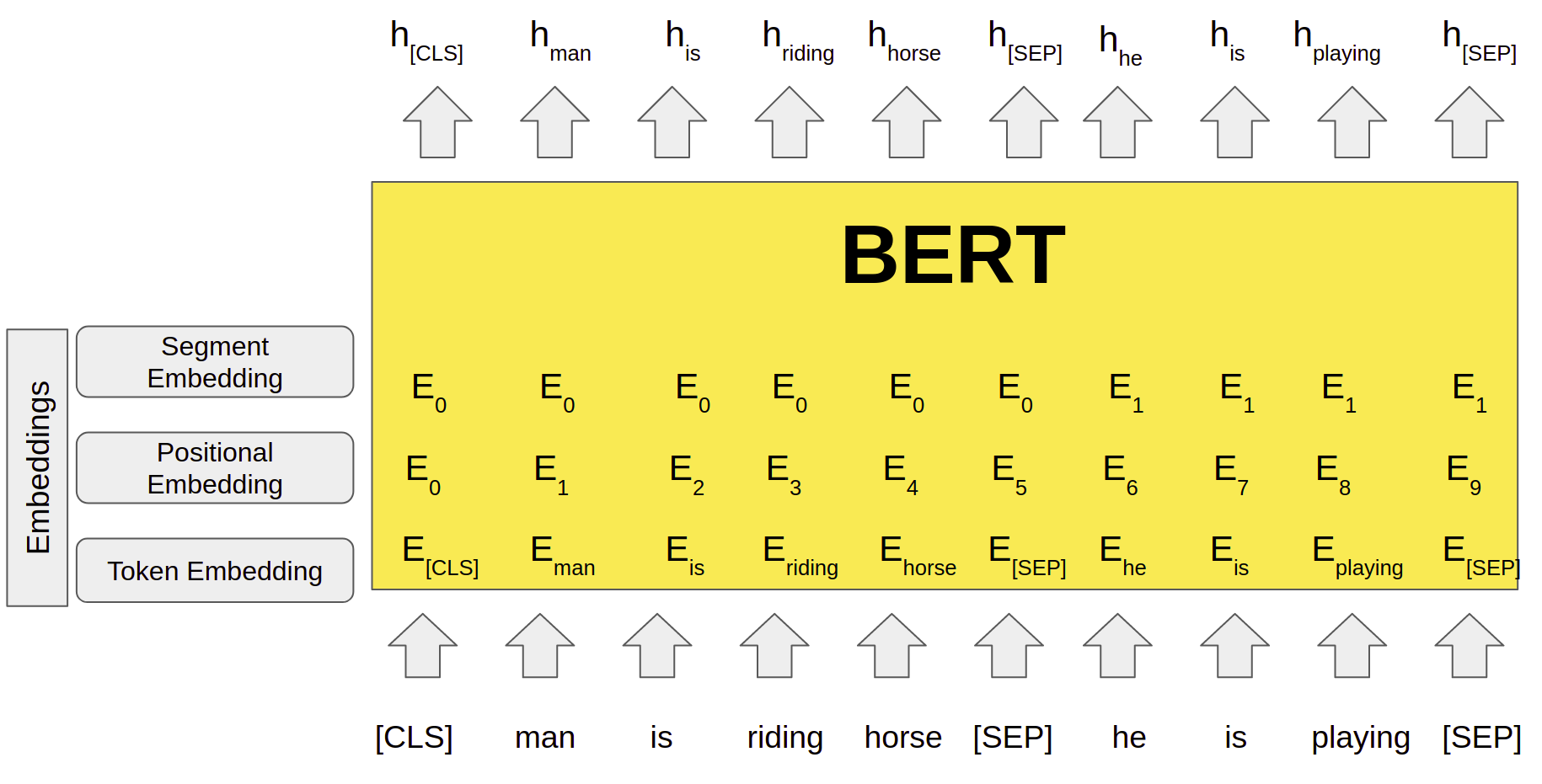
2017 年推出的 Transformer 架構通過引入注意力機制的概念,徹底改變了 NLP。隨后,谷歌于 2018 年發布的 BERT(來自 Transformers 的雙向編碼器表示)提供了上下文相關的詞嵌入。 BERT 通過查看單詞前后的單詞來考慮單詞的完整上下文,這與上下文無關模型的 Word2Vec 和 GloVe 不同。自 BERT 發布以來,已經開發了多種變體和改進,例如 RoBERTa、GPT(生成式預訓練變壓器)等。
嵌入 API 的出現
最近,機器學習應用程序的增長推動了提供預訓練詞嵌入的 API(應用程序編程接口)的開發。這些 API 簡化了獲取詞嵌入的任務,讓開發人員能夠專注于構建應用程序。
例如 Google 的 TensorFlow Hub,它提供可以生成嵌入的預訓練模型。這些模型包括多種選項,從 Word2Vec 和 GloVe 到基于轉換器的模型(如 BERT)。同樣,Hugging Face 的 Transformers 庫提供了一種獲取預訓練 Transformer 嵌入的簡單方法。
此類 API 極大地民主化了最先進的 NLP 技術的獲取。開發人員可以將這些 API 集成到他們的應用程序中,以執行語義搜索、情感分析、文本分類等任務,而不需要廣泛的機器學習專業知識或訓練此類模型的資源。
因此,我們可以總結說 Embedding API 是一種機器學習 API,提供對預先訓練的詞嵌入的訪問。詞嵌入是詞的向量表示,捕獲詞的含義以及與其他詞的關系。它們允許實現 (NLP) 任務,例如語義搜索、情感分析和文本分類。
嵌入 API 很重要,因為它們使開發人員可以輕松訪問最先進的 NLP 技術。過去,想要使用詞嵌入的開發人員必須訓練自己的模型。這是一個耗時且資源密集的過程。嵌入 API 使開發人員能夠快速輕松地開始 NLP 任務,而無需擁有豐富的機器學習專業知識。
有許多可用的嵌入 API,包括:
-
Google’s PaLM 2, textembedding-gecko@latest -
Google’s TensorFlow Hub -
Hugging Face’s Transformers library -
Stanford’s GloVe library -
CoVe (Contextual Vectors) -
FastText -
ELMo
這些 API 提供各種預先訓練的詞嵌入,包括 Word2Vec、GloVe 和基于 Transformer 的模型(如 BERT)。
當開發人員使用嵌入 API 時,他們首先需要選擇他們想要使用的預訓練模型。然后,API 將返回輸入文本中每個單詞的向量表示。然后可以使用向量表示來執行 NLP 任務。
使用嵌入 API 的好處
-
易于使用:嵌入 API 使開發人員可以輕松開始 NLP 任務。他們不需要任何機器學習方面的專業知識或資源來訓練自己的模型。 -
準確性:嵌入 API 為各種 NLP 任務提供高精度。這是因為他們接受了大型文本和代碼數據集的訓練。 -
可擴展性:嵌入 API 是可擴展的,因此它們可用于處理大量文本。
嵌入 API 是 NLP 任務的強大工具。它們使開發人員可以輕松訪問最先進的 NLP 技術并執行語義搜索、情感分析和文本分類等任務。隨著 NLP 領域的不斷發展,嵌入 API 將變得更加重要。
總結
自 NLP 出現以來,文本嵌入經歷了重大演變,每一次進步都讓我們更接近于有效模仿人類對語言的理解。隨著嵌入 API 的出現,這些強大的工具可供廣大開發人員使用,進一步加速了 NLP 應用程序的進步。
Reference
Source: https://dr-arsanjani.medium.com/the-evolution-of-text-embeddings-75431139133d
本文由 mdnice 多平臺發布



多邊形方法)


:轉義符)



)








