1, 概述
cuda lib 線程安全的幾個多線程的情景:
單卡多線程;
多卡多線程-每卡單線程;
多卡多線程-每卡多線程;
需要考慮的問題:
每個 cublasHandle_t 只能有一個stream么?
每個cusolverHandle_t 只能有一個 stream么?
每個cusolverHandle_t只能有要給cublasHandle_t么?
多個線程同時跑在多個或一個gpu上,需要使用多個stream么?都是NULL 默認stream的話,不會影響效率吧?
2, 多線程示例
從如下代碼思考開去,這個多線程場景是使用了openmp自動劃分任務,也可以使用pthread來七分任務,這里對這個示例進行了注釋:
https://github.com/NVIDIA/cuda-samples/blob/v11.4/Samples/cudaOpenMP/cudaOpenMP.cu
/** Multi-GPU sample using OpenMP for threading on the CPU side* needs a compiler that supports OpenMP 2.0*/
//使用openmp時包含其頭文件
#include <omp.h>
#include <stdio.h> // stdio functions are used since C++ streams aren't necessarily thread safe
//#include <helper_cuda.h>#define checkCudaErrors(val) valusing namespace std;// a simple kernel that simply increments each array element by b
__global__ void kernelAddConstant(int *g_a, const int b)
{int idx = blockIdx.x * blockDim.x + threadIdx.x;g_a[idx] += b;
}// a predicate that checks whether each array element is set to its index plus b
int correctResult(int *data, const int n, const int b)
{for (int i = 0; i < n; i++)if (data[i] != i + b)return 0;return 1;
}int main(int argc, char *argv[])
{int num_gpus = 0; // number of CUDA GPUsprintf("%s Starting...\n\n", argv[0]);/// determine the number of CUDA capable GPUs//cudaGetDeviceCount(&num_gpus);if (num_gpus < 1){printf("no CUDA capable devices were detected\n");return 1;}/// display CPU and GPU configuration//printf("number of host CPUs:\t%d\n", omp_get_num_procs());printf("number of CUDA devices:\t%d\n", num_gpus);for (int i = 0; i < num_gpus; i++){cudaDeviceProp dprop;cudaGetDeviceProperties(&dprop, i);printf(" %d: %s\n", i, dprop.name);}printf("---------------------------\n");/// initialize data//unsigned int n = num_gpus * 8192;unsigned int nbytes = n * sizeof(int);// nbytes = num_gpus * [8192*sizeof(int)]printf("nbytes=%u\n", nbytes);int *a = 0; // pointer to data on the CPUint b = 3; // value by which the array is incrementeda = (int *)malloc(nbytes);if (0 == a){printf("couldn't allocate CPU memory\n");return 1;}
//這里如果使用 #pragma omp parallel for 的話,會不會影響下面的線程數?for (unsigned int i = 0; i < n; i++)a[i] = i;// run as many CPU threads as there are CUDA devices// each CPU thread controls a different device, processing its// portion of the data. It's possible to use more CPU threads// than there are CUDA devices, in which case several CPU// threads will be allocating resources and launching kernels// on the same device. For example, try omp_set_num_threads(2*num_gpus);// Recall that all variables declared inside an "omp parallel" scope are// local to each CPU thread//// 通過獲知GPU的數量來設定下面參與工作的線程數量omp_set_num_threads(num_gpus); // create as many CPU threads as there are CUDA devices//omp_set_num_threads(2*num_gpus);// create twice as many CPU threads as there are CUDA devices//自動創建 num_gpus 個線程#pragma omp parallel{//每個線程獲得自己的線程號,從0開始計數unsigned int cpu_thread_id = omp_get_thread_num();//獲取 openmp 自動創建的總的線程數unsigned int num_cpu_threads = omp_get_num_threads();printf("cpu_thread_id=%u num_cpu_threads=%u\n", cpu_thread_id, num_cpu_threads);// set and check the CUDA device for this CPU threadint gpu_id = -1;//兩個或以上的線程,可以同時使用同一個 gpu 設備;cudaSetDevice(id) 會使得本線程鎖定這個 id-th gpu 設備,接下來發生的cudaXXX,都是在這個gpu上發生的。checkCudaErrors(cudaSetDevice(cpu_thread_id % num_gpus)); // "% num_gpus" allows more CPU threads than GPU devicescheckCudaErrors(cudaGetDevice(&gpu_id));//這個函數僅僅返回本線程鎖定的gpu的id。printf("CPU thread %d (of %d) uses CUDA device %d, set id=%d, get id = %d\n", cpu_thread_id, num_cpu_threads, gpu_id, cpu_thread_id%num_gpus, gpu_id);int *d_a = 0; // pointer to memory on the device associated with this CPU thread//下面找到本線程需要處理的數據起始地址int *sub_a = a + cpu_thread_id * n / num_cpu_threads; // pointer to this CPU thread's portion of dataunsigned int nbytes_per_kernel = nbytes / num_cpu_threads;//其中的 nbytes = num_gpus * [8192*sizeof(int)], 是整除關系;得到每個線程需要分配的顯存字節數dim3 gpu_threads(128); // 128 threads per blockdim3 gpu_blocks(n / (gpu_threads.x * num_cpu_threads));// n = num_gpus * 8192; 其中 8192 是128的整數倍, num_cpu_threads 是 num_gpus 的小小的整數倍; // 這樣每個block含128個線程; 每個線程需要幾個block呢 = n/(gpu_threads.x * num_cpu_threads)checkCudaErrors(cudaMalloc((void **)&d_a, nbytes_per_kernel));//在本線程所setDevice的gpu上cudaMalloc顯存空間;checkCudaErrors(cudaMemset(d_a, 0, nbytes_per_kernel));//將分的的空間刷0// 將本線程需要處理的數據塊拷貝的本線程所cudaMalloc的顯存中;checkCudaErrors(cudaMemcpy(d_a, sub_a, nbytes_per_kernel, cudaMemcpyHostToDevice));//本線程啟動kernel,處理自己的顯存的數據;kernelAddConstant<<<gpu_blocks, gpu_threads>>>(d_a, b);// 本線程將處理好的數據拷貝到本線程負責的系統內存塊中checkCudaErrors(cudaMemcpy(sub_a, d_a, nbytes_per_kernel, cudaMemcpyDeviceToHost));//釋放顯存checkCudaErrors(cudaFree(d_a));}printf("---------------------------\n");if (cudaSuccess != cudaGetLastError())printf("%s\n", cudaGetErrorString(cudaGetLastError()));// check the result//對計算結果進行對比bool bResult = correctResult(a, n, b);if (a)free(a); // free CPU memoryexit(bResult ? EXIT_SUCCESS : EXIT_FAILURE);
}
運行效果:
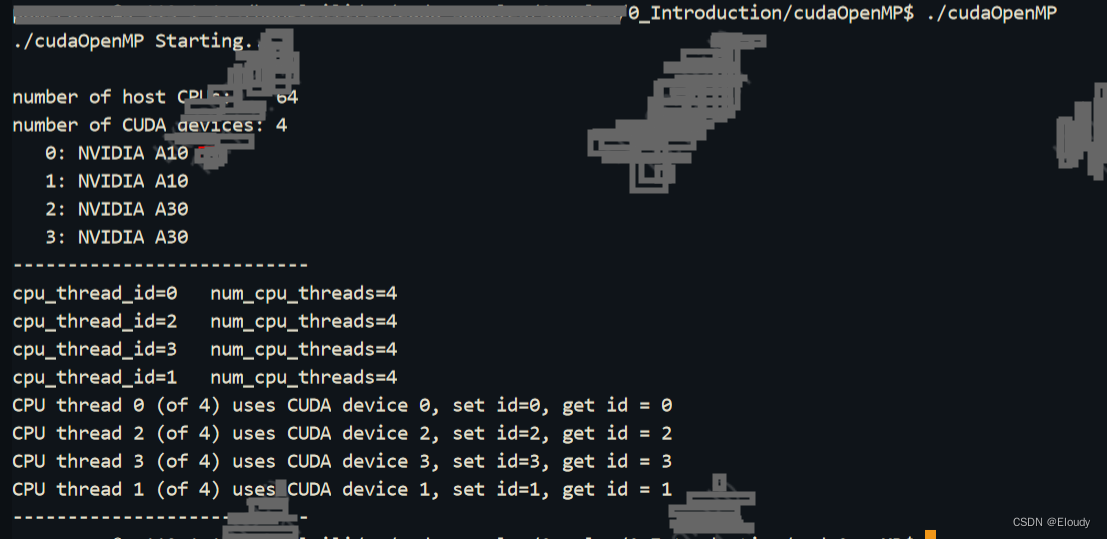
要保證cuda lib的線程安全,首先確定cuda driver cuda runtime 都是線程安全的,這個其實是沒有問題的,也就是說多個線程多塊顯卡同時運行的場景是不會引發cuda runtime的線程安全問題的,這點可以放心;













![【算法每日一練]-結構優化(保姆級教程 篇4 樹狀數組,線段樹,分塊模板篇)](http://pic.xiahunao.cn/【算法每日一練]-結構優化(保姆級教程 篇4 樹狀數組,線段樹,分塊模板篇))





