68、VQVAE預訓練模型的論文原理及PyTorch代碼逐行講解_嗶哩嗶哩_bilibili本期視頻主要講解大規模無監督預訓練模型之VQVAE的論文原理以及PyTorch代碼逐行講解,希望對大家理解VQVAE以及圖像生成有幫助。, 視頻播放量 9920、彈幕量 80、點贊數 485、投硬幣枚數 322、收藏人數 413、轉發人數 51, 視頻作者 deep_thoughts, 作者簡介 在有限的生命里怎么樣把握住時間專注做點自己喜歡做的同時對別人也有價值的事情,是我們應該時常自查反省的(純公益分享不接任何廣告或合作),相關視頻:【授權】李宏毅2023春機器學習課程,語音合成超簡潔訓練代碼框架,[論文簡析]VQ-VAE:Neural discrete representation learning[1711.00937],圖神經網絡系列講解及代碼實現-異質圖卷積網絡RGCN 2,GPT-4寫代碼是真的強👍,技術培訓-婁曉-手把手教Diffusion_VAE_VQVAE_UNet-附github代碼,33、完整講解PyTorch多GPU分布式訓練代碼編寫,[pytorch] 深入理解 nn.KLDivLoss(kl 散度) 與 nn.CrossEntropyLoss(交叉熵),GPT,GPT-2,GPT-3 論文精讀【論文精讀】,[論文簡析]VAE: Auto-encoding Variational Bayes[1312.6114]![]() https://www.bilibili.com/video/BV14Y4y1X7wb/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
https://www.bilibili.com/video/BV14Y4y1X7wb/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
VQ-VAE解讀 - 知乎VAEVAE (variational autoencoder)是一種強大的生成模型. 我們可以從AE的角度去理解, 即有一個Encoder把數據編碼到隱空間 ( z = Ecd(x) ), 然后又用一個Decoder把數據從隱空間中重建回來( x=Dcd(z) ). 而對于VAE, …![]() https://zhuanlan.zhihu.com/p/91434658輕松理解 VQ-VAE:首個提出 codebook 機制的生成模型 - 知乎近兩年,有許多圖像生成類任務的前沿工作都使用了一種叫做"codebook"的機制。追溯起來,codebook機制最早是在VQ-VAE論文中提出的。相比于普通的VAE,VQ-VAE能利用codebook機制把圖像編碼成離散向量,為圖…
https://zhuanlan.zhihu.com/p/91434658輕松理解 VQ-VAE:首個提出 codebook 機制的生成模型 - 知乎近兩年,有許多圖像生成類任務的前沿工作都使用了一種叫做"codebook"的機制。追溯起來,codebook機制最早是在VQ-VAE論文中提出的。相比于普通的VAE,VQ-VAE能利用codebook機制把圖像編碼成離散向量,為圖…![]() https://zhuanlan.zhihu.com/p/633744455文本天然是一種離散的符號,圖像和音頻的特征高維和稀疏,如果想對圖片和音頻進行多模態預訓練,可以對它們進行信息壓縮,不在圖像像素空間或者語音的信號點空間上建模,而是可以將他們壓縮一個隱空間中,它的特征就更加緊湊,然后對隱空間進行建模取生成。
https://zhuanlan.zhihu.com/p/633744455文本天然是一種離散的符號,圖像和音頻的特征高維和稀疏,如果想對圖片和音頻進行多模態預訓練,可以對它們進行信息壓縮,不在圖像像素空間或者語音的信號點空間上建模,而是可以將他們壓縮一個隱空間中,它的特征就更加緊湊,然后對隱空間進行建模取生成。
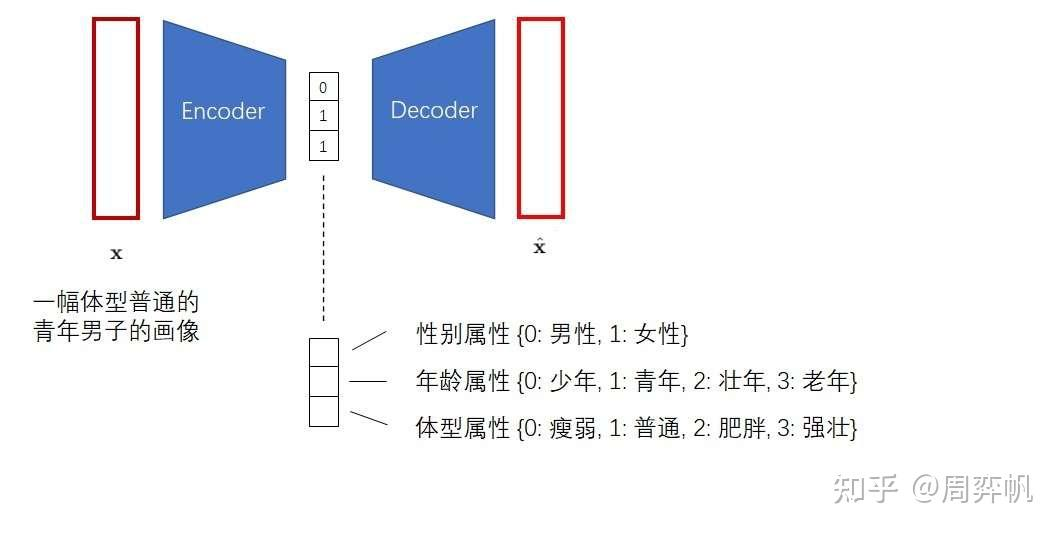
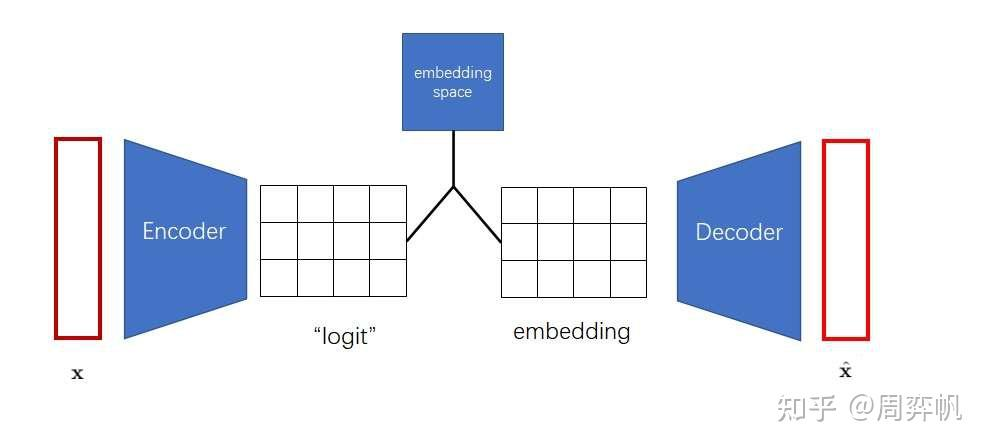
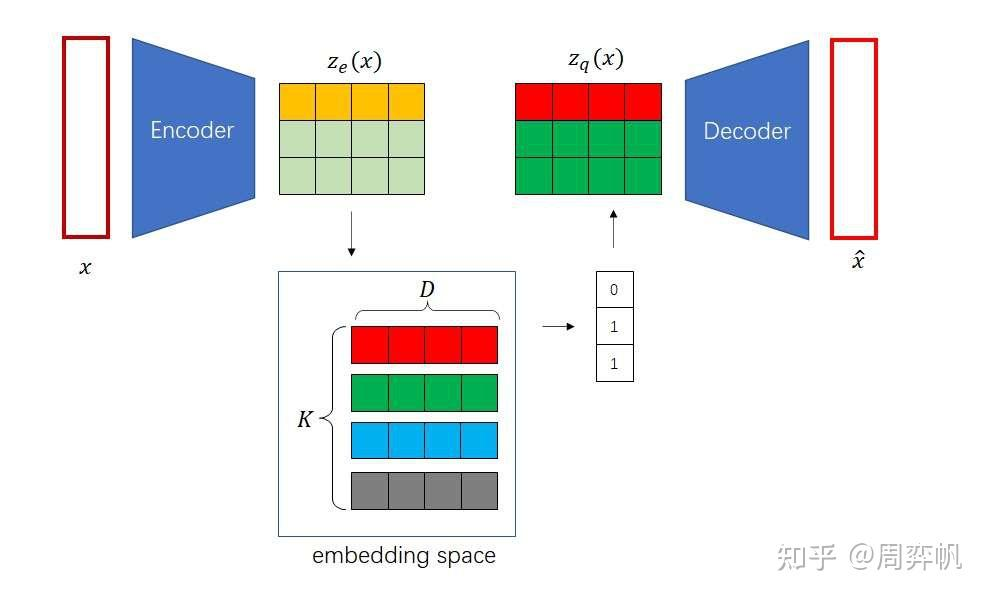
如何在無監督下去學習有用的表征?VQVAE和VAE的區別在于,1.編碼器網絡產生的是離散的編碼,而不是連續的編碼,離散就是當你訓練一個語言模型,比如word2vec時,把每個單詞建立一個單詞表,單詞表中單詞的順序就作為這個單詞的一個離散的表征,2.先驗是可學習的而不是靜態的,在VAE中通常假設先驗是一個標準分布,是一個高斯分布,在VQVAE中先驗不再是一個靜態的分布,而是模型去學到的某一個分布,是一個離散的類別分布。基于VQ的方法不存在后驗崩塌的問題,后驗崩塌指的是無論輸入的隱變量是什么,解碼器的輸出都一樣的,和GAN的模式崩塌基本一樣的。在VQVAE的基礎上,可以用一個自回歸的先驗模型去學習隱變量分布,可以用生成。
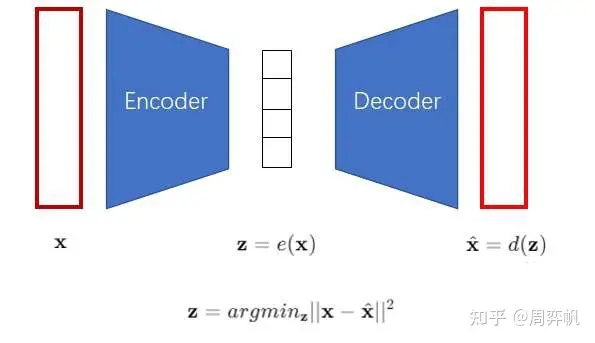
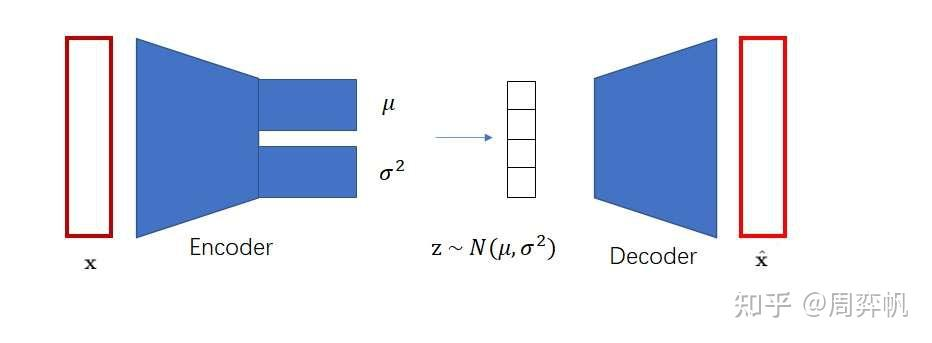
VAE中為了表征一個對象,先對對象進行一個信息壓縮,先編碼,把高維稀疏的數據壓縮到一個空間中,再通過解碼器還原。包含三個部分,后驗分布,先驗分布和解碼器。后驗分布和先驗分布通常假設成一個標準的高斯分布,通過重參數讓解碼器和編碼器的梯度可導。VQVAE中VQ,對隱變量不再讓它從一個連續的高斯分布中去生成,而是從一個離散的分布中去生成,此時的后驗分布和先驗分布都是類別分布,從類別中產生的樣本,其實就是索引,基于這個索引從embedding table中找到相應的embedding,然后讓這個embedding作為提取的z,送入到解碼器中。
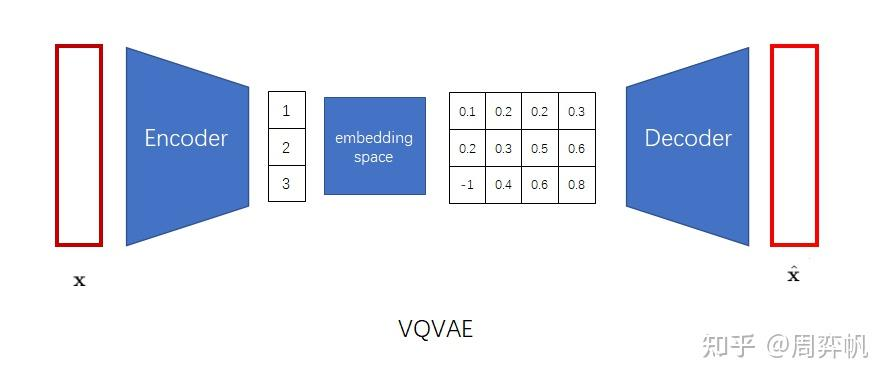
- 訓練VQ-VAE的編碼器和解碼器,使得VQ-VAE能把圖像變成「小圖像」,也能把「小圖像」變回圖像。
- 訓練PixelCNN,讓它學習怎么生成「小圖像」。
- 隨機采樣時,先用PixelCNN采樣出「小圖像」,再用VQ-VAE把「小圖像」翻譯成最終的生成圖像。

)


















與控制框架/架構)