1.研究背景與意義
項目參考AAAI Association for the Advancement of Artificial Intelligence
研究背景與意義
隨著油氣管道設備的廣泛應用,油氣泄露問題已經成為一個嚴重的環境和安全隱患。油氣泄露不僅會造成環境污染,還可能引發火災、爆炸等嚴重事故,對人們的生命財產安全造成威脅。因此,開發一種高效準確的油氣管道設備泄露檢測系統具有重要的現實意義。
目前,深度學習在計算機視覺領域取得了巨大的成功,特別是目標檢測方面。YOLO(You Only Look Once)是一種非常流行的實時目標檢測算法,其快速準確的特點使其在許多應用中得到廣泛應用。然而,YOLO算法在處理小目標和密集目標時存在一定的困難,這在油氣管道設備泄露檢測中尤為突出。
為了解決這個問題,本研究提出了一種改進的YOLOv8算法,該算法融合了可變形大核注意力D-LKA-Attention。可變形大核注意力是一種新穎的注意力機制,可以自適應地調整感受野的大小和形狀,從而更好地適應不同大小和形狀的目標。通過引入D-LKA-Attention,改進的YOLOv8算法可以更好地處理小目標和密集目標,提高油氣管道設備泄露檢測的準確性和效率。
本研究的意義主要體現在以下幾個方面:
首先,改進的YOLOv8算法能夠提高油氣管道設備泄露檢測的準確性。傳統的YOLO算法在處理小目標和密集目標時容易出現漏檢和誤檢的問題,而引入D-LKA-Attention后,改進的算法可以更好地適應不同大小和形狀的目標,提高檢測的準確性。
其次,改進的YOLOv8算法能夠提高油氣管道設備泄露檢測的效率。由于油氣管道設備泄露檢測需要實時性,因此算法的速度至關重要。改進的算法通過引入可變形大核注意力,可以更好地適應不同大小和形狀的目標,減少不必要的計算量,提高檢測的速度。
此外,改進的YOLOv8算法還具有較強的泛化能力和適應性。油氣管道設備泄露檢測場景復雜多變,目標的大小和形狀各異,傳統的目標檢測算法往往難以適應。而改進的算法通過引入可變形大核注意力,可以自適應地調整感受野的大小和形狀,更好地適應不同場景下的目標檢測需求。
綜上所述,改進的YOLOv8算法融合可變形大核注意力D-LKA-Attention的油氣管道設備泄露檢測系統具有重要的現實意義。它可以提高油氣管道設備泄露檢測的準確性和效率,具有較強的泛化能力和適應性,對保障人們的生命財產安全具有重要的意義。
2.圖片演示



3.視頻演示
【改進YOLOv8】融合可變形大核注意力D-LKA-Attention的油氣管道設備泄露檢測系統_嗶哩嗶哩_bilibili
4.數據集的采集&標注和整理
圖片的收集
首先,我們需要收集所需的圖片。這可以通過不同的方式來實現,例如使用現有的公開數據集OilDatasets。

labelImg是一個圖形化的圖像注釋工具,支持VOC和YOLO格式。以下是使用labelImg將圖片標注為VOC格式的步驟:
(1)下載并安裝labelImg。
(2)打開labelImg并選擇“Open Dir”來選擇你的圖片目錄。
(3)為你的目標對象設置標簽名稱。
(4)在圖片上繪制矩形框,選擇對應的標簽。
(5)保存標注信息,這將在圖片目錄下生成一個與圖片同名的XML文件。
(6)重復此過程,直到所有的圖片都標注完畢。
由于YOLO使用的是txt格式的標注,我們需要將VOC格式轉換為YOLO格式。可以使用各種轉換工具或腳本來實現。
下面是一個簡單的方法是使用Python腳本,該腳本讀取XML文件,然后將其轉換為YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-import xml.etree.ElementTree as ET
import osclasses = [] # 初始化為空列表CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:classes.append(cls) # 如果類別不存在,添加到classes列表中cls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')xml_path = os.path.join(CURRENT_DIR, './label_xml/')# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:label_name = img_xml.split('.')[0]print(label_name)convert_annotation(label_name)print("Classes:") # 打印最終的classes列表
print(classes) # 打印最終的classes列表整理數據文件夾結構
我們需要將數據集整理為以下結構:
-----data|-----train| |-----images| |-----labels||-----valid| |-----images| |-----labels||-----test|-----images|-----labels確保以下幾點:
所有的訓練圖片都位于data/train/images目錄下,相應的標注文件位于data/train/labels目錄下。
所有的驗證圖片都位于data/valid/images目錄下,相應的標注文件位于data/valid/labels目錄下。
所有的測試圖片都位于data/test/images目錄下,相應的標注文件位于data/test/labels目錄下。
這樣的結構使得數據的管理和模型的訓練、驗證和測試變得非常方便。
模型訓練
Epoch gpu_mem box obj cls labels img_size1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代碼講解
5.2 predict.py
class DetectionPredictor(BasePredictor):def postprocess(self, preds, img, orig_imgs):preds = ops.non_max_suppression(preds,self.args.conf,self.args.iou,agnostic=self.args.agnostic_nms,max_det=self.args.max_det,classes=self.args.classes)if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = []for i, pred in enumerate(preds):orig_img = orig_imgs[i]pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i]results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results
這個程序文件是一個名為predict.py的文件,它是一個用于預測基于檢測模型的類DetectionPredictor的定義。這個類繼承自BasePredictor類,用于基于檢測模型進行預測。
這個文件使用了Ultralytics YOLO庫,它是一個基于AGPL-3.0許可的開源項目。
這個文件中的DetectionPredictor類有一個postprocess方法,用于對預測結果進行后處理,并返回一個Results對象的列表。在postprocess方法中,預測結果經過了非最大抑制(non_max_suppression)處理,同時進行了一些其他的處理操作,如將預測框的坐標進行縮放等。
這個文件還包含了一個示例代碼,展示了如何使用DetectionPredictor類進行預測。示例代碼中使用了yolov8n.pt模型,并指定了輸入數據的來源。
總之,這個程序文件是一個用于預測基于檢測模型的類DetectionPredictor的定義,它使用了Ultralytics YOLO庫,并提供了一個示例代碼來演示如何使用這個類進行預測。
5.3 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_firstclass DetectionTrainer(BaseTrainer):def build_dataset(self, img_path, mode='train', batch=None):gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):assert mode in ['train', 'val']with torch_distributed_zero_first(rank):dataset = self.build_dataset(dataset_path, mode, batch_size)shuffle = mode == 'train'if getattr(dataset, 'rect', False) and shuffle:LOGGER.warning("WARNING ?? 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")shuffle = Falseworkers = 0return build_dataloader(dataset, batch_size, workers, shuffle, rank)def preprocess_batch(self, batch):batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255return batchdef set_model_attributes(self):self.model.nc = self.data['nc']self.model.names = self.data['names']self.model.args = self.argsdef get_model(self, cfg=None, weights=None, verbose=True):model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return modeldef get_validator(self):self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))def label_loss_items(self, loss_items=None, prefix='train'):keys = [f'{prefix}/{x}' for x in self.loss_names]if loss_items is not None:loss_items = [round(float(x), 5) for x in loss_items]return dict(zip(keys, loss_items))else:return keysdef progress_string(self):return ('\n' + '%11s' *(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')def plot_training_samples(self, batch, ni):plot_images(images=batch['img'],batch_idx=batch['batch_idx'],cls=batch['cls'].squeeze(-1),bboxes=batch['bboxes'],paths=batch['im_file'],fname=self.save_dir / f'train_batch{ni}.jpg',on_plot=self.on_plot)def plot_metrics(self):plot_results(file=self.csv, on_plot=self.on_plot)def plot_training_labels(self):boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
這個程序文件是一個用于訓練檢測模型的程序。它使用了Ultralytics YOLO庫,并繼承了BaseTrainer類。以下是該程序文件的主要功能:
- 導入所需的庫和模塊。
- 定義了一個名為DetectionTrainer的類,繼承自BaseTrainer類,用于訓練基于檢測模型的任務。
- 實現了構建YOLO數據集的方法,根據傳入的參數構建訓練集或驗證集的數據集。
- 實現了構建數據加載器的方法,根據傳入的參數構建訓練集或驗證集的數據加載器。
- 實現了對批量圖像進行預處理的方法,將圖像進行縮放和轉換為浮點數。
- 設置了模型的屬性,包括類別數量、類別名稱和超參數等。
- 實現了獲取YOLO檢測模型的方法,根據傳入的配置文件和權重文件返回一個YOLO檢測模型。
- 實現了獲取檢測模型驗證器的方法,返回一個用于驗證YOLO模型的檢測驗證器。
- 實現了將訓練損失項進行標記的方法,返回一個帶有標記的訓練損失項字典。
- 實現了獲取訓練進度的方法,返回一個格式化的訓練進度字符串。
- 實現了繪制訓練樣本的方法,將訓練樣本及其注釋繪制成圖像。
- 實現了繪制指標的方法,從CSV文件中繪制指標圖。
- 實現了繪制訓練標簽的方法,創建一個帶有標簽的訓練繪圖。
在主程序中,首先定義了一些參數,然后創建了一個DetectionTrainer對象,并調用其train方法進行模型訓練。
5.5 backbone\convnextv2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPathclass LayerNorm(nn.Module):def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedError self.normalized_shape = (normalized_shape, )def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass GRN(nn.Module):def __init__(self, dim):super().__init__()self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))def forward(self, x):Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)return self.gamma * (x * Nx) + self.beta + xclass Block(nn.Module):def __init__(self, dim, drop_path=0.):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)self.norm = LayerNorm(dim, eps=1e-6)self.pwconv1 = nn.Linear(dim, 4 * dim)self.act = nn.GELU()self.grn = GRN(4 * dim)self.pwconv2 = nn.Linear(4 * dim, dim)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):input = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1)x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.grn(x)x = self.pwconv2(x)x = x.permute(0, 3, 1, 2)x = input + self.drop_path(x)return xclass ConvNeXtV2(nn.Module):def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0., head_init_scale=1.):super().__init__()self.depths = depthsself.downsample_layers = nn.ModuleList()stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList()dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] cur = 0for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6)self.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):trunc_normal_(m.weight, std=.02)nn.init.constant_(m.bias, 0)def forward(self, x):res = []for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)res.append(x)return res
該程序文件是一個用于構建ConvNeXt V2模型的Python代碼文件。該文件定義了多個類和函數,用于構建不同規模的ConvNeXt V2模型。
文件中定義的類和函數包括:
- LayerNorm類:支持兩種數據格式(channels_last和channels_first)的LayerNorm層。
- GRN類:全局響應歸一化(Global Response Normalization)層。
- Block類:ConvNeXtV2模型的基本塊。
- ConvNeXtV2類:ConvNeXt V2模型的主體部分。
- update_weight函數:用于更新模型權重。
- convnextv2_atto函數:構建ConvNeXt V2的atto規模模型。
- convnextv2_femto函數:構建ConvNeXt V2的femto規模模型。
- convnextv2_pico函數:構建ConvNeXt V2的pico規模模型。
- convnextv2_nano函數:構建ConvNeXt V2的nano規模模型。
- convnextv2_tiny函數:構建ConvNeXt V2的tiny規模模型。
- convnextv2_base函數:構建ConvNeXt V2的base規模模型。
- convnextv2_large函數:構建ConvNeXt V2的large規模模型。
- convnextv2_huge函數:構建ConvNeXt V2的huge規模模型。
這些類和函數的具體實現細節可以參考代碼文件中的注釋。
5.6 backbone\CSwomTramsformer.py
class CSWinTransformer(nn.Module):def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm):super().__init__()self.num_classes = num_classesself.depths = depthsself.num_features = self.embed_dim = embed_dimself.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)self.pos_drop = nn.Dropout(p=drop_rate)dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay ruleself.blocks = nn.ModuleList([CSWinBlock(dim=embed_dim, reso=img_size // patch_size, num_heads=num_heads[i], mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])], norm_layer=norm_layer,last_stage=(i == len(depths) - 1))for i in range(len(depths))])self.norm = norm_layer(embed_dim)self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()trunc_normal_(self.head.weight, std=.02)self.head.bias.data.fill_(0.)def get_classifier(self):return self.headdef reset_classifier(self, num_classes, global_pool=''):self.num_classes = num_classesself.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):x = self.patch_embed(x)x = self.pos_drop(x)for blk in self.blocks:x = blk(x)x = self.norm(x) # B L Creturn xdef forward(self, x):x = self.forward_features(x)x = x[:, 0] # B Cx = self.head(x)return x
這個程序文件是一個用于圖像分類的CSWin Transformer模型。它定義了CSWinBlock類和Mlp類,以及一些輔助函數。CSWinBlock類是CSWin Transformer的基本構建塊,它包含了多頭注意力機制和多層感知機。Mlp類是多層感知機的實現。這個程序文件還定義了一些輔助函數,如img2windows和windows2img,用于圖像的分割和合并。最后,還定義了一個Merge_Block類,用于將圖像特征映射到較低維度的特征。
6.系統整體結構
根據以上分析,對程序的整體功能和構架進行概括如下:
該油氣管道設備泄露檢測系統使用了多種深度學習模型和算法,包括可變形大核注意力D-LKA-Attention、ConvNeXt V2、EfficientFormerV2、EfficientViT、Fasternet、LSKNet、RepVIT、RevCol、SwinTransformer、VanillaNet等。程序包含了訓練、預測、導出模型、用戶界面等功能。
下表整理了每個文件的功能:
| 文件 | 功能 |
|---|---|
| export.py | 導出模型的腳本 |
| predict.py | 模型預測的腳本 |
| train.py | 模型訓練的腳本 |
| ui.py | 圖形用戶界面的腳本 |
| backbone\convnextv2.py | ConvNeXt V2模型的構建 |
| backbone\CSwomTramsformer.py | CSwomTramsformer模型的構建 |
| backbone\EfficientFormerV2.py | EfficientFormerV2模型的構建 |
| backbone\efficientViT.py | EfficientViT模型的構建 |
| backbone\fasternet.py | Fasternet模型的構建 |
| backbone\lsknet.py | LSKNet模型的構建 |
| backbone\repvit.py | RepVIT模型的構建 |
| backbone\revcol.py | RevCol模型的構建 |
| backbone\SwinTransformer.py | SwinTransformer模型的構建 |
| backbone\VanillaNet.py | VanillaNet模型的構建 |
| extra_modules\afpn.py | AFPN模塊的實現 |
| extra_modules\attention.py | 注意力模塊的實現 |
| extra_modules\block.py | 基礎塊模塊的實現 |
| extra_modules\dynamic_snake_conv.py | 動態蛇卷積模塊的實現 |
| extra_modules\head.py | 模型頭部模塊的實現 |
| extra_modules\kernel_warehouse.py | 卷積核倉庫模塊的實現 |
| extra_modules\orepa.py | OREPA模塊的實現 |
| extra_modules\rep_block.py | RepBlock模塊的實現 |
| extra_modules\RFAConv.py | RFAConv模塊的實現 |
| models\common.py | 通用模型的實現 |
| models\experimental.py | 實驗性模型的實現 |
| models\tf.py | TensorFlow模型的實現 |
| models\yolo.py | YOLO模型的實現 |
| ultralytics… | Ultralytics庫的實現 |
| utils… | 工具 |
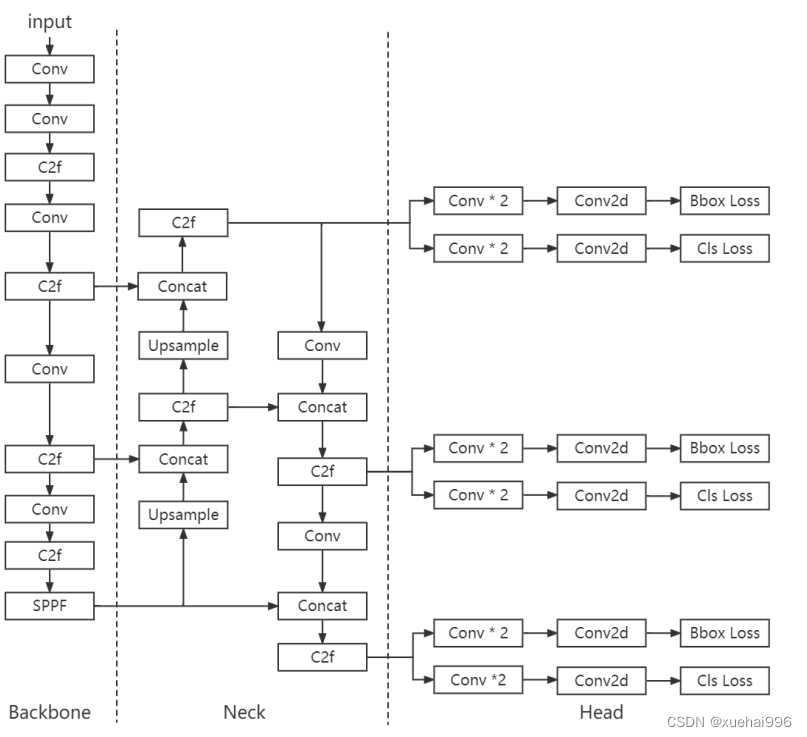
7.YOLOv8簡介
YOLOv8是一種最新的SOTA算法,提供了N/S/M/L/X尺度的不同大小模型,以滿足不同場景的需求。本章對算法網絡的新特性進行簡要介紹。
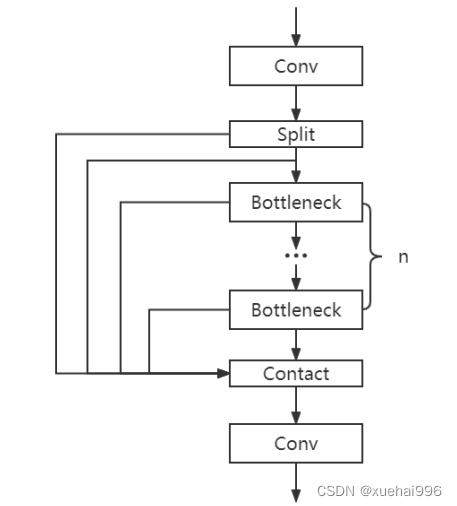
1)骨干網絡和Neck
開發者設計了C2f模塊對CSPDarkNet 53和PAFPN進行改造。相比C3模塊,C2f模塊擁有更多的分支跨層鏈接,使模型的梯度流更加豐富,顯著增強了模型的特征提取能力。
2)Head部分
Head部分采用無錨框設計,將分類任務和回歸任務進行了解耦,獨立的分支將更加專注于其所負責的特征信息。
3)損失計算
模型使用CIOU Loss作為誤差損失函數,并通過最小化DFL進一步提升邊界框的回歸精度。同時模型采用了TaskAlignedAssigner樣本分配策略,以分類得分和IOU的高階組合作為指標指導正負樣本選擇,實現了高分類得分和高IOU的對齊,有效地提升了模型的檢測精度。
8.D-LKA Attention簡介
自2010年代中期以來,卷積神經網絡(CNNs)已成為許多計算機視覺應用的首選技術。它們能夠從原始數據中自動提取復雜的特征表示,無需手動進行特征工程,這引起了醫學圖像分析社區的極大興趣。許多成功的CNN架構,如U-Net、全卷積網絡、DeepLab或SegCaps(分割膠囊),已經被開發出來。這些架構在語義分割任務中取得了巨大成功,先前的最新方法已經被超越。
在計算機視覺研究中,不同尺度下的目標識別是一個關鍵問題。在CNN中,可檢測目標的大小與相應網絡層的感受野尺寸密切相關。如果一個目標擴展到超出這個感受野的邊界,這可能會導致欠分割結果。相反,與目標實際大小相比使用過大的感受野可能會限制識別,因為背景信息可能會對預測產生不必要的影響。
解決這個問題的一個有希望的方法涉及在并行使用具有不同尺寸的多個Kernel,類似于Inception塊的機制。然而,由于參數和計算要求的指數增長,將Kernel大小增加以容納更大的目標在實踐中受到限制。因此,出現了各種策略,包括金字塔池化技術和不同尺度的擴張卷積,以捕獲多尺度的上下文信息。
另一個直觀的概念涉及將多尺度圖像金字塔或它們的相關特征表示直接納入網絡架構。然而,這種方法存在挑戰,特別是在管理訓練和推理時間方面的可行性方面存在挑戰。在這個背景下,使用編碼器-解碼器網絡,如U-Net,已被證明是有利的。這樣的網絡在較淺的層中編碼外觀和位置,而在更深的層中,通過神經元的更廣泛的感受野捕獲更高的語義信息和上下文信息。
一些方法將來自不同層的特征組合在一起,或者預測來自不同尺寸的層的特征以使用多尺度的信息。此外,出現了從不同尺度的層中預測特征的方法,有效地實現了跨多個尺度的見解整合。然而,大多數編碼器-解碼器結構面臨一個挑戰:它們經常無法在不同尺度之間保持一致的特征,并主要使用最后一個解碼器層生成分割結果。
語義分割是一項任務,涉及根據預定義的標簽集為圖像中的每個像素預測語義類別。這項任務要求提取高級特征同時保留初始的空間分辨率。CNNs非常適合捕獲局部細節和低級信息,盡管以忽略全局上下文為代價。視覺Transformer(ViT)架構已經成為解決處理全局信息的視覺任務的關鍵,包括語義分割,取得了顯著的成功。
ViT的基礎是注意力機制,它有助于在整個輸入序列上聚合信息。這種能力使網絡能夠合并遠程的上下文提示,超越了CNN的有限感受野尺寸。然而,這種策略通常會限制ViT有效建模局部信息的能力。這種局限可能會妨礙它們檢測局部紋理的能力,這對于各種診斷和預測任務至關重要。這種缺乏局部表示可以歸因于ViT模型處理圖像的特定方式。
ViT模型將圖像分成一系列Patch,并使用自注意力機制來模擬它們之間的依賴關系。這種方法可能不如CNN模型中的卷積操作對感受野內提取局部特征有效。ViT和CNN模型之間的這種圖像處理方法的差異可能解釋了CNN模型在局部特征提取方面表現出色的原因。
近年來,已經開發出創新性方法來解決Transformer模型內部局部紋理不足的問題。其中一種方法是通過互補方法將CNN和ViT特征結合起來,以結合它們的優勢并減輕局部表示的不足。TransUNet是這種方法的早期示例,它在CNN的瓶頸中集成了Transformer層,以模擬局部和全局依賴關系。HiFormer提出了一種解決方案,將Swin Transformer模塊和基于CNN的編碼器結合起來,生成兩個多尺度特征表示,通過Double-Level Fusion模塊集成。UNETR使用基于Transformer的編碼器和CNN解碼器進行3D醫學圖像分割。CoTr和TransBTS通過Transformer在低分辨率階段增強分割性能,將CNN編碼器和解碼器連接在一起。
增強局部特征表示的另一種策略是重新設計純Transformer模型內部的自注意力機制。在這方面,Swin-Unet在U形結構中集成了一個具有線性計算復雜性的Swin Transformer塊作為多尺度 Backbone 。MISSFormer采用高效Transformer來解決視覺Transformer中的參數問題,通過在輸入塊上進行不可逆的降采樣操作。D-Former引入了一個純Transformer的管道,具有雙重注意模塊,以分段的方式捕獲細粒度的局部注意和與多元單元的交互。然而,仍然存在一些特定的限制,包括計算效率低下,如TransUNet模型所示,對CNN Backbone 的嚴重依賴,如HiFormer所觀察到的,以及對多尺度信息的忽略。
此外,目前的分割架構通常采用逐層處理3D輸入 volumetric 的方法,無意中忽視了相鄰切片之間的潛在相關性。這一疏忽限制了對 volumetric 信息的全面利用,因此損害了定位精度和上下文集成。此外,必須認識到,醫學領域的病變通常在形狀上發生變形。因此,用于醫學圖像分析的任何學習算法都必須具備捕捉和理解這些變形的能力。與此同時,該算法應保持計算效率,以便處理3D volumetric數據。
為了解決上述提到的挑戰,作者提出了一個解決方案,即可變形大卷積核注意力模塊(Deformable LKA module),它是作者網絡設計的基本構建模塊。這個模塊明確設計成在有效處理上下文信息的同時保留局部描述符。作者的架構在這兩個方面的平衡增強了實現精確語義分割的能力。
值得注意的是,參考該博客引入了一種基于數據的感受野的動態適應,不同于傳統卷積操作中的固定濾波器Mask。這種自適應方法使作者能夠克服與靜態方法相關的固有限制。這種創新方法還擴展到了D-LKA Net架構的2D和3D版本的開發。
在3D模型的情況下,D-LKA機制被量身定制以適應3D環境,從而實現在不同 volumetric 切片之間無縫信息交互。最后,作者的貢獻通過其計算效率得到進一步強調。作者通過僅依靠D-LKA概念的設計來實現這一點,在各種分割基準上取得了顯著的性能,確立了作者的方法作為一種新的SOTA方法。
在本節中,作者首先概述方法論。首先,作者回顧了由Guo等人引入的大卷積核注意力(Large Kernel Attention,LKA)的概念。然后,作者介紹了作者對可變形LKA模塊的創新探索。在此基礎上,作者介紹了用于分割任務的2D和3D網絡架構。
大卷積核提供了與自注意力機制類似的感受野。可以通過使用深度卷積、深度可擴展卷積和卷積來構建大卷積核,從而減少了參數和計算量。構建輸入維度為和通道數的卷積核的深度卷積和深度可擴展卷積的卷積核大小的方程如下:
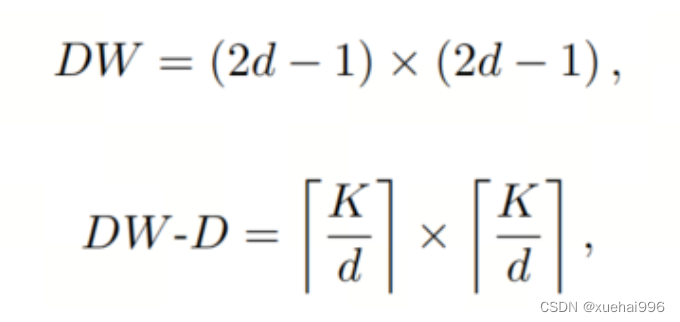
具有卷積核大小和膨脹率。參數數量和浮點運算(FLOPs)的計算如下:
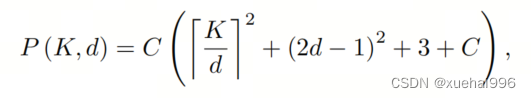
FLOPs的數量與輸入圖像的大小成線性增長。參數的數量隨通道數和卷積核大小的增加而呈二次增長。然而,由于它們通常都很小,因此它們不是限制因素。
為了最小化對于固定卷積核大小K的參數數量,可以將方程3對于膨脹率的導數設定為零:
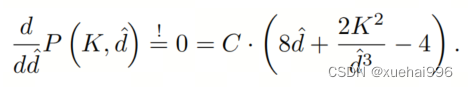
例如,當卷積核大小為時,結果是。將這些公式擴展到3D情況是直接的。對于大小為和通道數C的輸入,3D情況下參數數量和FLOPs 的方程如下:
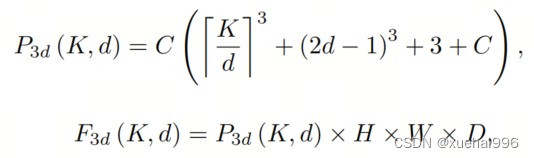
具有卷積核大小和膨脹。
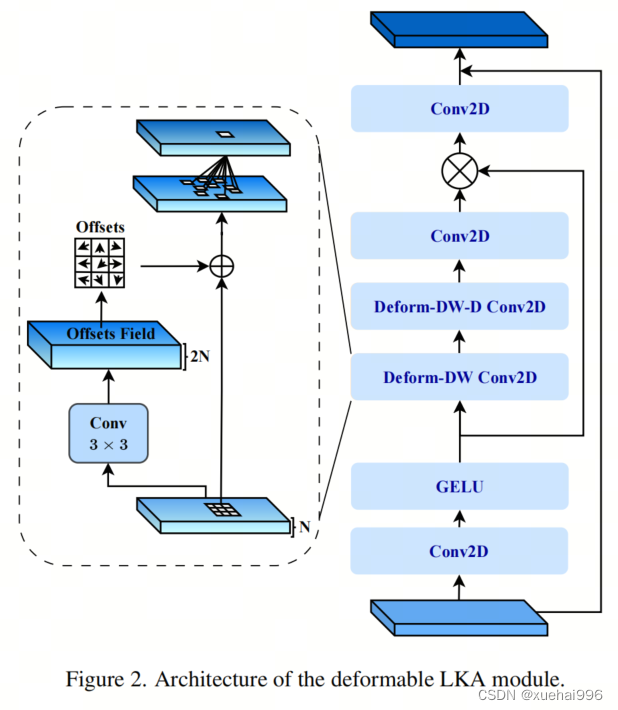
利用大卷積核進行醫學圖像分割的概念通過引入可變形卷積得以擴展。可變形卷積可以通過整數偏移自由調整采樣網格以進行自由變形。額外的卷積層從特征圖中學習出變形,從而創建一個偏移場。基于特征本身學習變形會導致自適應卷積核。這種靈活的卷積核形狀可以提高病變或器官變形的表示,從而增強了目標邊界的定義。
負責計算偏移的卷積層遵循其相應卷積層的卷積核大小和膨脹。雙線性插值用于計算不在圖像網格上的偏移的像素值。如圖2所示,D-LKA模塊可以表示為:

其中輸入特征由表示,。表示為注意力圖,其中每個值表示相應特征的相對重要性。運算符 表示逐元素乘法運算。值得注意的是,LKA不同于傳統的注意力方法,它不需要額外的規范化函數,如或。這些規范化函數往往忽視高頻信息,從而降低了基于自注意力的方法的性能。
在該方法的2D版本中,卷積層被可變形卷積所替代,因為可變形卷積能夠改善對具有不規則形狀和大小的目標的捕捉能力。這些目標在醫學圖像數據中常常出現,因此這種增強尤為重要。
然而,將可變形LKA的概念擴展到3D領域會帶來一定的挑戰。主要的約束來自于需要用于生成偏移的額外卷積層。與2D情況不同,由于輸入和輸出通道的性質,這一層無法以深度可分的方式執行。在3D環境中,輸入通道對應于特征,而輸出通道擴展到,其中是卷積核的大小。大卷積核的復雜性導致沿第3D的通道數擴展,導致參數和FLOPs大幅增加。因此,針對3D情況采用了另一種替代方法。在現有的LKA框架中,深度卷積之后引入了一個單獨的可變形卷積層。這種戰略性的設計調整旨在減輕擴展到3D領域所帶來的挑戰。
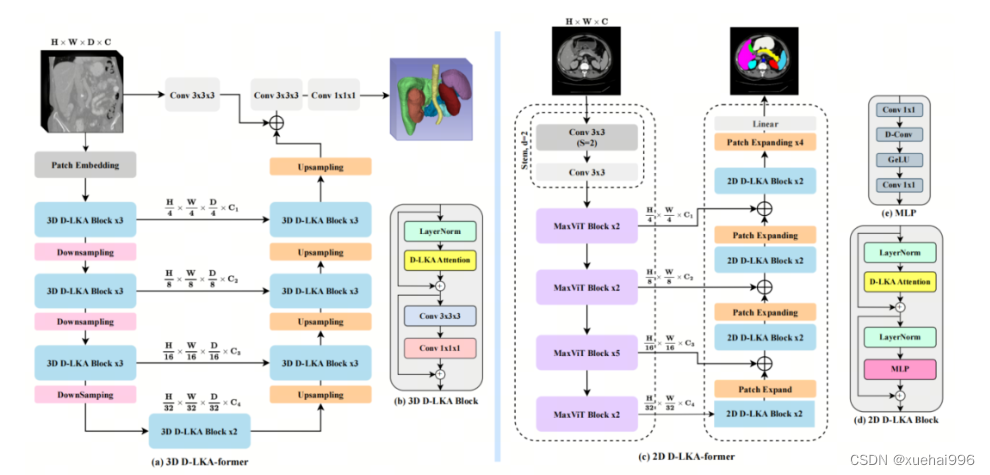
2D網絡的架構如圖1所示。第一變種使用MaxViT作為編碼器組件,用于高效特征提取,而第二變種則結合可變形LKA層進行更精細、卓越的分割。
在更正式的描述中,編碼器生成4個分層輸出表示。首先,卷積干擾將輸入圖像的維度減小到。隨后,通過4個MaxViT塊的4個階段進行特征提取,每個階段后跟隨降采樣層。隨著過程進展到解碼器,實施了4個階段的D-LKA層,每個階段包含2個D-LKA塊。然后,應用Patch擴展層以實現分辨率上采樣,同時減小通道維度。最后,線性層負責生成最終的輸出。
2D D-LKA塊的結構包括LayerNorm、可變形LKA和多層感知器(MLP)。積分殘差連接確保了有效的特征傳播,即使在更深層也是如此。這個安排可以用數學方式表示為:
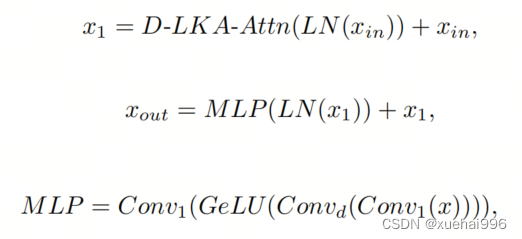
其中輸入特征,層歸一化LN,可變形LKA注意力,深度卷積,線性層和GeLU激活函數。
3D網絡架構如圖1所示,采用編碼器-解碼器設計進行分層結構化。首先,一個Patch嵌入層將輸入圖像的維度從()減小到()。在編碼器中,采用了3個D-LKA階段的序列,每個階段包含3個D-LKA塊。在每個階段之后,通過降采樣步驟將空間分辨率減半,同時將通道維度加倍。中央瓶頸包括另一組2個D-LKA塊。解碼器結構與編碼器相對稱。
為了將特征分辨率加倍,同時減少通道數,使用轉置卷積。每個解碼器階段都使用3個D-LKA塊來促進遠距離特征依賴性。最終的分割輸出由一個卷積層產生,后面跟隨一個卷積層以匹配特定類別的通道要求。
為了建立輸入圖像和分割輸出之間的直接連接,使用卷積形成了一個跳躍連接。額外的跳躍連接根據簡單的加法對來自其他階段的特征進行融合。最終的分割圖是通過和卷積層的組合產生的。
3D D-LKA塊包括層歸一化,后跟D-LKA注意力,應用了殘差連接的部分。隨后的部分采用了一個卷積層,后面跟隨一個卷積層,兩者都伴隨著殘差連接。這個整個過程可以總結如下:
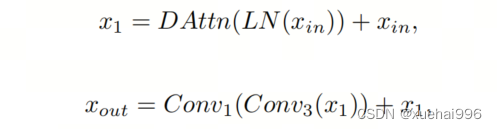
帶有輸入特征 、層歸一化 、可變形 LKA 、卷積層 和輸出特征 的公式。是指一個前饋網絡,包括2個卷積層和激活函數。
表7顯示了普通卷積和構建卷積的參數數量比較。盡管標準卷積的參數數量在通道數較多時急劇增加,但分解卷積的參數總體較低,并且增長速度不那么快。
與分解卷積相比,可變形分解卷積增加了大量參數,但仍然明顯小于標準卷積。可變形卷積的主要參數是由偏移網絡創建的。在這里,作者假設可變形深度卷積的Kernel大小為(5,5),可變形深度空洞卷積的Kernel大小為(7,7)。這導致了21×21大小的大Kernel的最佳參數數量。更高效地生成偏移量的方法將大大減少參數數量。

值得注意的是,引入可變形LKA確實會增加模型的參數數量和每秒的浮點運算次數(FLOPS)。然而,重要的是強調,這增加的計算負載不會影響作者模型的整體推理速度。
相反,對于Batch-size > 1,作者甚至觀察到推理時間的減少,如圖7所示。例如,基于作者的廣泛實驗,作者觀察到對于Batch-size為16,具有可變形卷積和沒有可變形卷積的推理時間分別為8.01毫秒和17.38毫秒。作者認為這是由于在2D中對可變形卷積的高效實現所致。為了測量時間,使用了大小為()的隨機輸入。在GPU熱身周期50次迭代之后,網絡被推斷了1000次。測量是在NVIDIA RTX 3090 GPU上進行的。
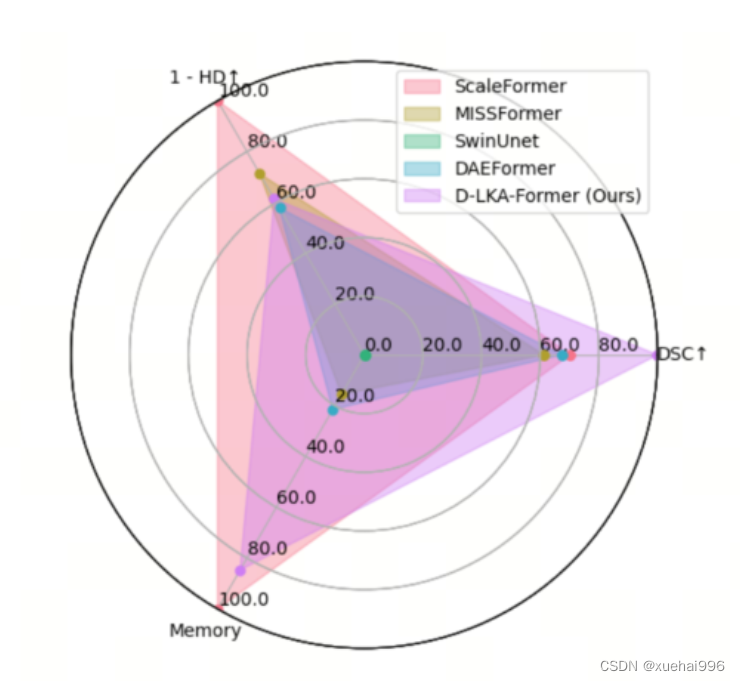
為了充分利用性能與參數之間的權衡關系,作者在圖8中可視化了在Synapse 2D數據集上報告的DSC和HD性能以及基于參數數量的內存消耗。D-LKA Net引入了相當多的參數,約為101M。這比性能第二好的方法ScaleFormer使用的111.6M參數要少。
與更輕量級的DAEFormer模型相比,作者實現了更好的性能,這證明了參數增加的合理性。大多數參數來自于MaxViT編碼器;因此,將編碼器替換為更高效的編碼器可以減少模型參數。值得注意的是,在此可視化中,作者最初將HD和內存值都歸一化到[0, 100]范圍內。隨后,作者將它們從100縮小,以增強更高值的表示。
9.訓練結果可視化分析
評價指標
訓練損失趨勢:觀察box_loss, obj_loss, cls_loss隨著epoch的變化情況,以了解模型訓練過程中損失函數的優化情況。
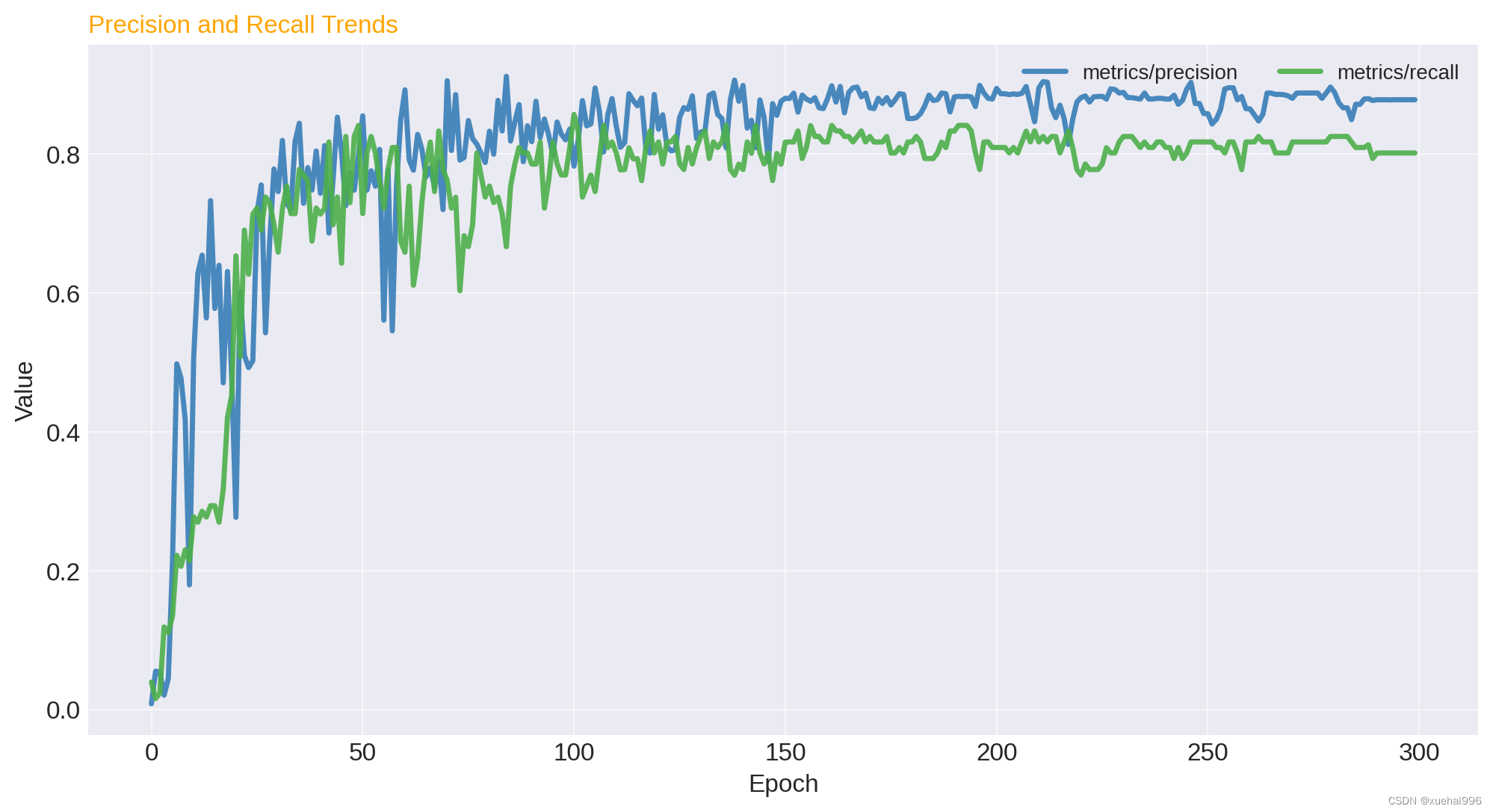
精確度和召回率:分析模型的precision和recall隨epoch的變化,以評估模型對正類樣本的檢測能力。
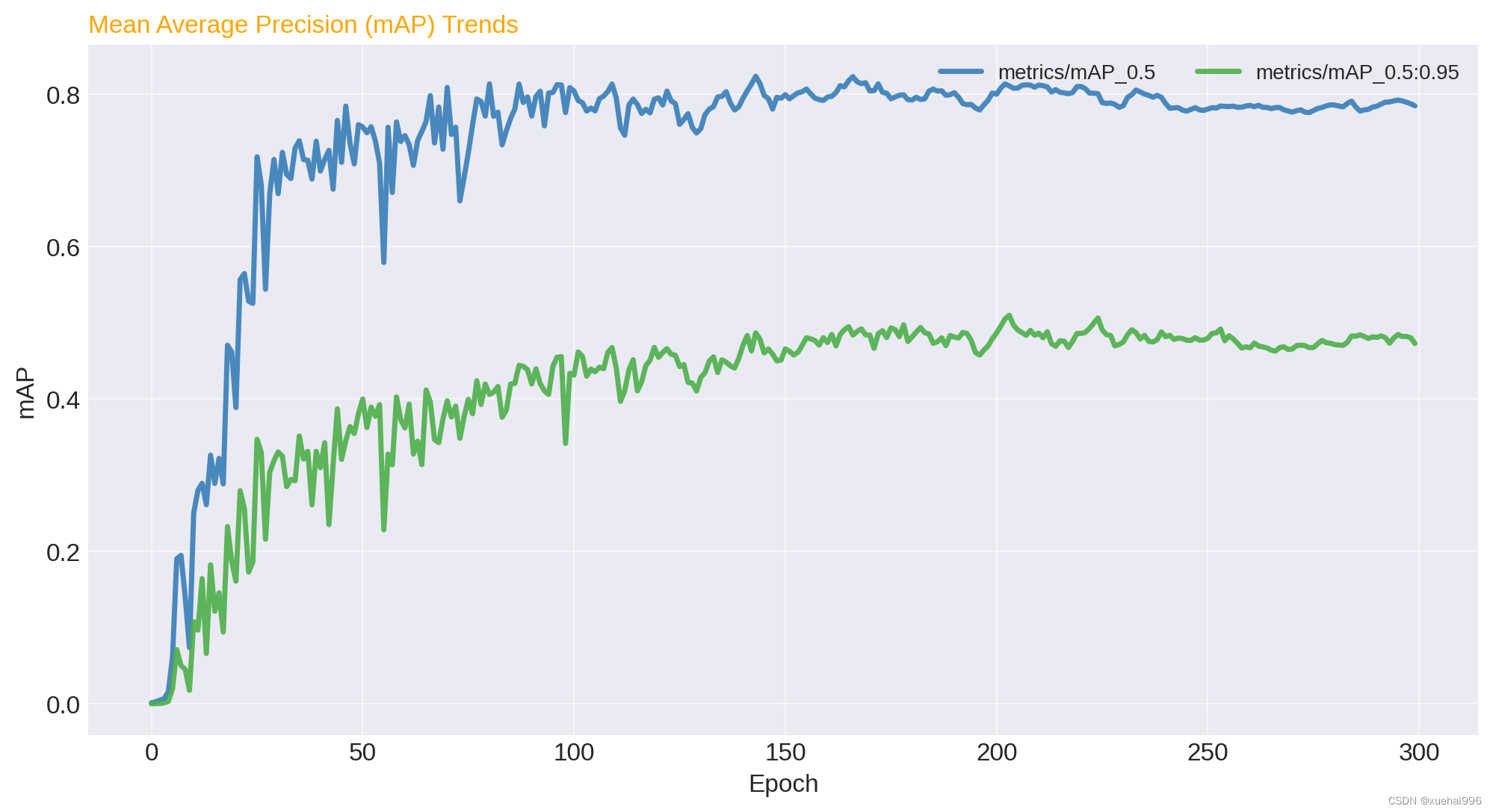
平均精度(mAP):分析mAP_0.5和mAP_0.5:0.95隨epoch的變化,這是衡量模型整體性能的關鍵指標。
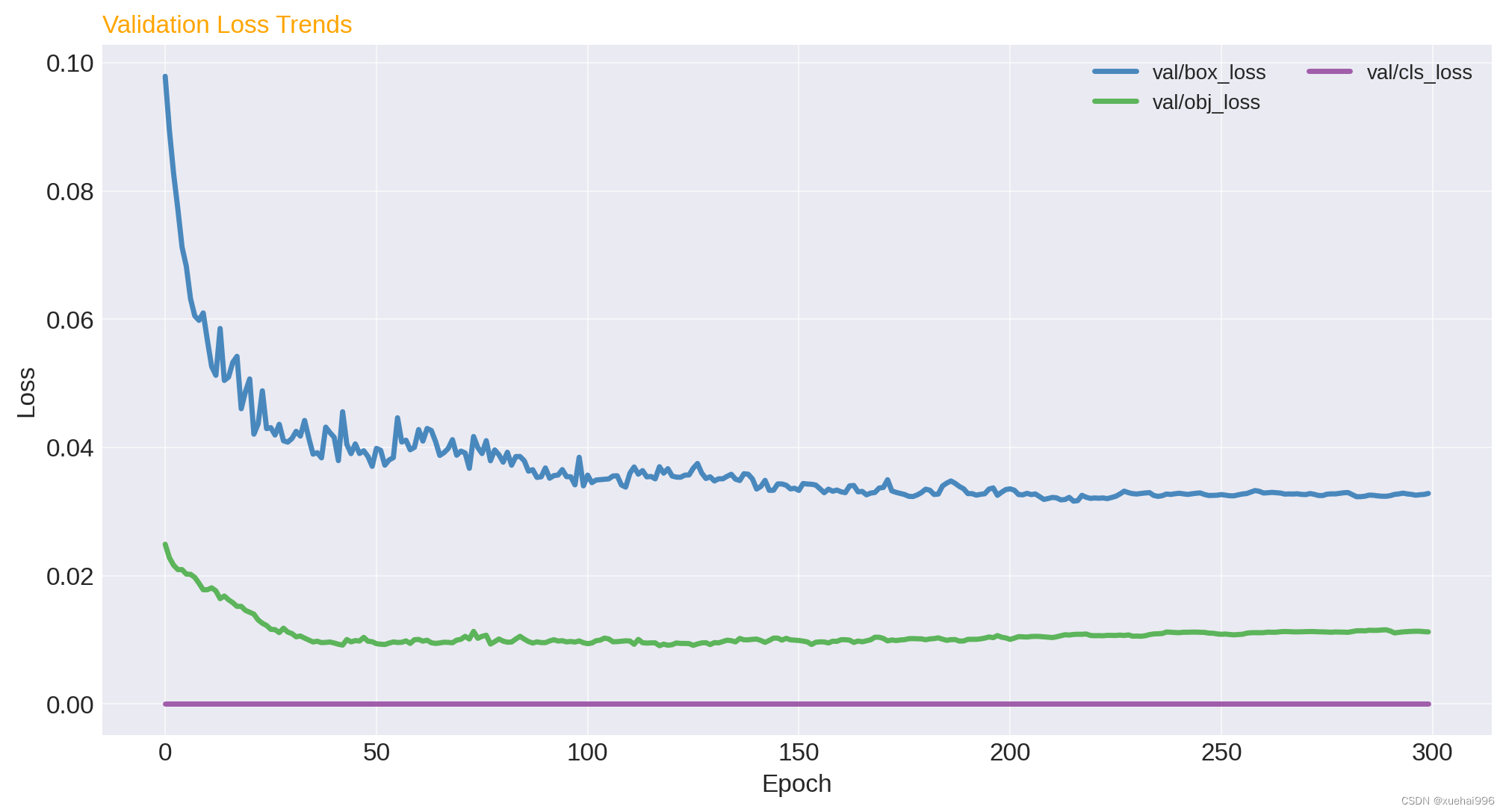
驗證損失趨勢:檢查val/box_loss, val/obj_loss, val/cls_loss的變化,以評估模型在未見數據上的泛化能力。
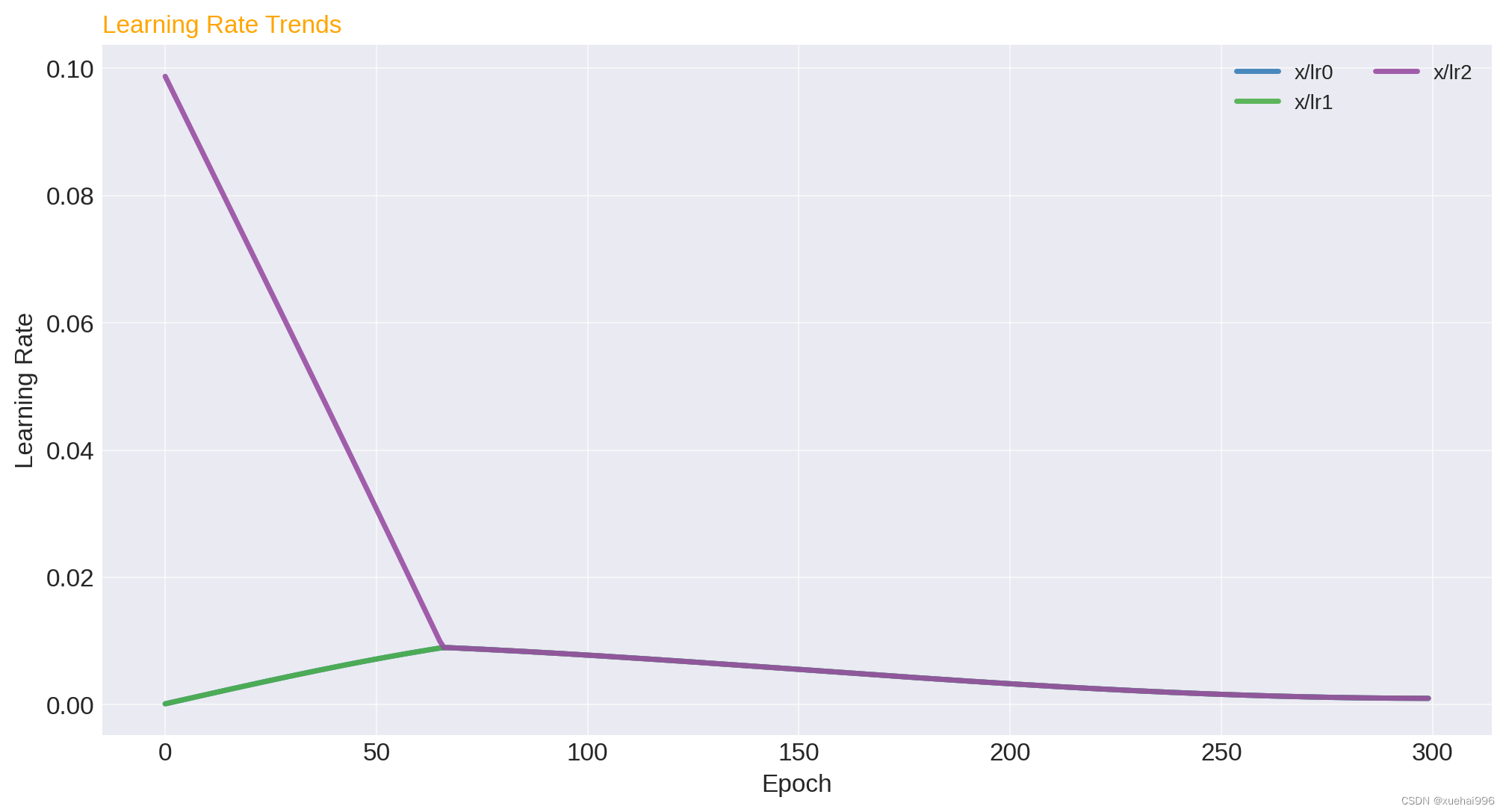
學習率變化:觀察x/lr0, x/lr1, x/lr2隨epoch的變化,理解學習率調整策略對訓練過程的影響。
現在,我將生成這些圖表并對每個部分進行簡要分析。
訓練結果可視化
import matplotlib.pyplot as plt# Setting up the plot style
plt.style.use('seaborn-darkgrid')
palette = plt.get_cmap('Set1')# Function to plot the data
def plot_data(data, columns, title, ylabel):plt.figure(figsize=(12, 6))for i, column in enumerate(columns, 1):plt.plot(data['epoch'], data[column], marker='', color=palette(i), linewidth=2.5, alpha=0.9, label=column)plt.title(title, loc='left', fontsize=12, fontweight=0, color='orange')plt.xlabel("Epoch")plt.ylabel(ylabel)plt.legend(loc='upper right', ncol=2)# Plotting Training Loss Trends
plot_data(data, ['train/box_loss', 'train/obj_loss', 'train/cls_loss'], 'Training Loss Trends', 'Loss')# Plotting Precision and Recall
plot_data(data, ['metrics/precision', 'metrics/recall'], 'Precision and Recall Trends', 'Value')# Plotting Mean Average Precision (mAP)
plot_data(data, ['metrics/mAP_0.5', 'metrics/mAP_0.5:0.95'], 'Mean Average Precision (mAP) Trends', 'mAP')# Plotting Validation Loss Trends
plot_data(data, ['val/box_loss', 'val/obj_loss', 'val/cls_loss'], 'Validation Loss Trends', 'Loss')# Plotting Learning Rate Trends
plot_data(data, ['x/lr0', 'x/lr1', 'x/lr2'], 'Learning Rate Trends', 'Learning Rate')plt.show()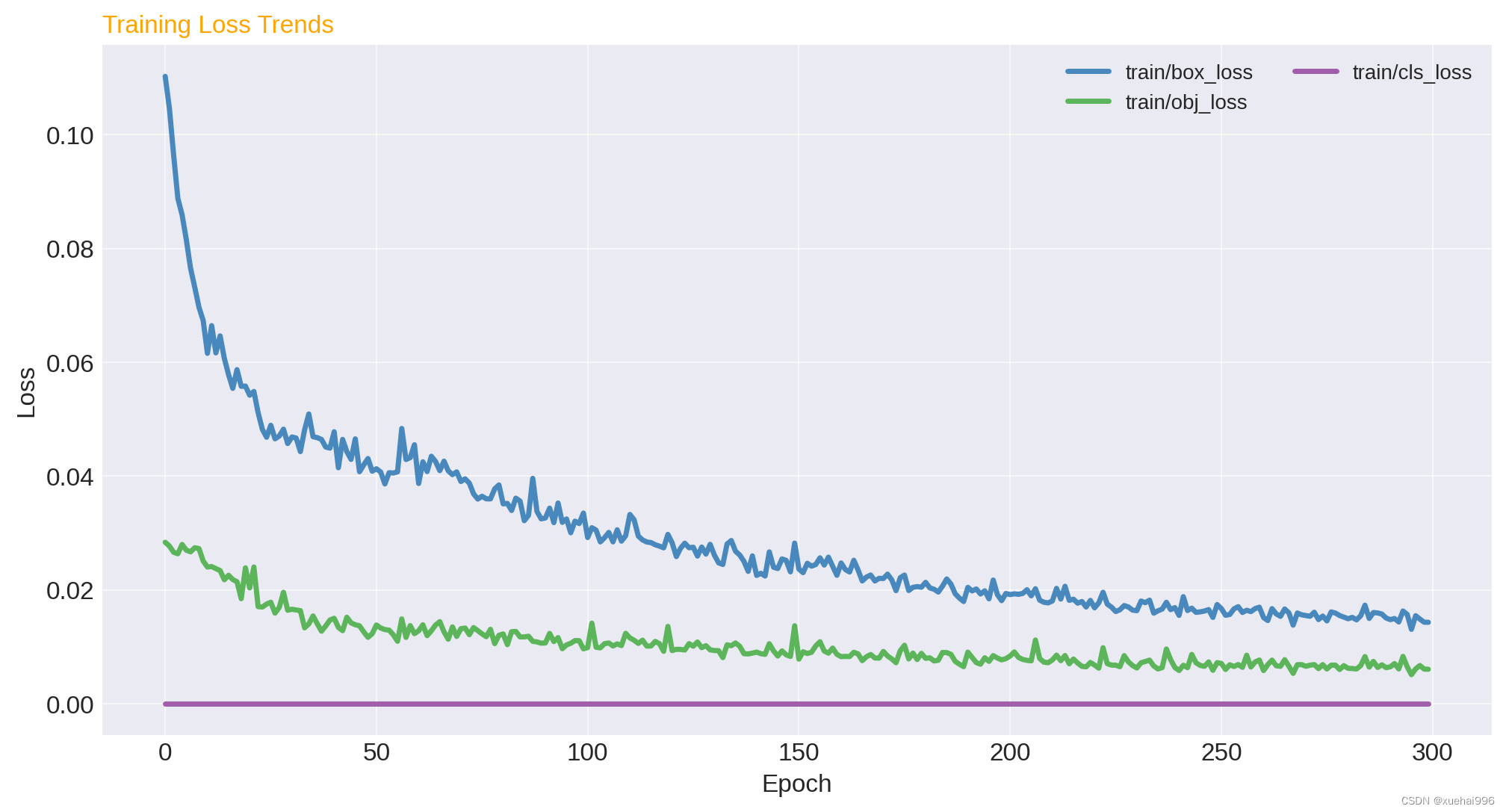
訓練結果可視化分析
訓練損失趨勢:在這張圖中,我們可以看到 box_loss、obj_loss、cls_loss 隨著訓練周期的增加而逐漸下降。這表明模型在學習過程中逐漸改善,損失函數值在減小,這是一個良好的訓練指標。
精確度和召回率:精確度(precision)和召回率(recall)是評估分類模型性能的重要指標。理想情況下,隨著訓練的進行,這兩個指標都應該提高。在您的模型中,我們可以看到這兩個指標隨著時間的推移都有所提高,盡管波動較大,這表明模型在某種程度上能夠正確識別正類樣本。
平均精度(mAP):mAP 是衡量對象檢測模型性能的關鍵指標,尤其是在不同的IoU閾值下。mAP_0.5 和 mAP_0.5:0.95 的提高表明您的模型在檢測精度方面表現良好,適應不同程度的嚴格度。
驗證損失趨勢:驗證損失(val/box_loss, val/obj_loss, val/cls_loss)的趨勢也是判斷模型泛化能力的重要指標。理想情況下,這些損失值應該隨著訓練周期的增加而減小。在您的模型中,驗證損失呈下降趨勢,這表明模型在未見數據上的表現也在提高。
學習率變化:學習率(x/lr0, x/lr1, x/lr2)的調整對模型的訓練過程有重要影響。您的模型中學習率的逐漸提高可能是采用了某種適應性學習率調整策略,以幫助模型更好地適應訓練過程。
10.系統整合
下圖完整源碼&數據集&環境部署視頻教程&自定義UI界面

參考博客《【改進YOLOv8】融合可變形大核注意力D-LKA-Attention的油氣管道設備泄露檢測系統》
11.參考文獻
[1][佟淑嬌](http
s://s.wanfangdata.com.cn/paper?q=%E4%BD%9C%E8%80%85:%22%E4%BD%9F%E6%B7%91%E5%A8%87%22),王如君,李應波,等.基于VPL的輸油管道實時泄漏檢測系統[J].中國安全生產科學技術.2017,(4).DOI:10.11731/j.issn.1673-193x.2017.04.019 .
[2]劉興華,蘇盈盈,李景哲,等.基于KICA的石油管道泄漏檢測方法研究[J].西南師范大學學報(自然科學版).2016,(6).DOI:10.13718/j.cnki.xsxb.2016.06.021 .
[3]李健,陳世利,黃新敬,等.長輸油氣管道泄漏監測與準實時檢測技術綜述[J].儀器儀表學報.2016,(8).DOI:10.3969/j.issn.0254-3087.2016.08.006 .
[4]劉煒,劉宏昭.應用模糊熵和相似度的管道泄漏檢測與定位[J].機械科學與技術.2016,(3).DOI:10.13433/j.cnki.1003-8728.2016.0320 .
[5]石崗,孫良.恒壓型邊界液體管道泄漏信號檢測仿真研究[J].計算機仿真.2016,(7).DOI:10.3969/j.issn.1006-9348.2016.07.098 .
[6]劉志勇,劉梅清,蔣勁,等.基于瞬變流頻率響應分析的輸水管道泄漏檢測[J].水利學報.2015,(11).DOI:10.13243/j.cnki.slxb.20141408 .
[7]龔駿,稅愛社,包建明,等.多工況下基于RBF神經網絡的管道泄漏檢測[J].油氣儲運.2015,(7).DOI:10.6047/j.issn.1000-8241.2015.07.017 .
[8]郝永梅,徐明,邢志祥,等.廣義回歸神經網絡在燃氣管道泄漏檢測中的應用[J].消防科學與技術.2015,(7).DOI:10.3969/j.issn.1009-0029.2015.07.035 .
[9]劉喆,周建偉,施志雄,等.塘燕復線泄漏檢測系統檢測精度改進方法[J].油氣儲運.2015,(7).DOI:10.6047/j.issn.1000-8241.2015.07.025 .
[10]楊凱,陳勇,劉煥淋.基于FBG傳感網絡的輸油管道泄漏檢測方法[J].半導體光電.2016,(5).DOI:10.16818/j.issn1001-5868.2016.05.032 .


糖果(鴿巢原理))


![[EFI]Atermiter X99 Turbo D4 E5-2630v3電腦 Hackintosh 黑蘋果efi引導文件](http://pic.xiahunao.cn/[EFI]Atermiter X99 Turbo D4 E5-2630v3電腦 Hackintosh 黑蘋果efi引導文件)

)











