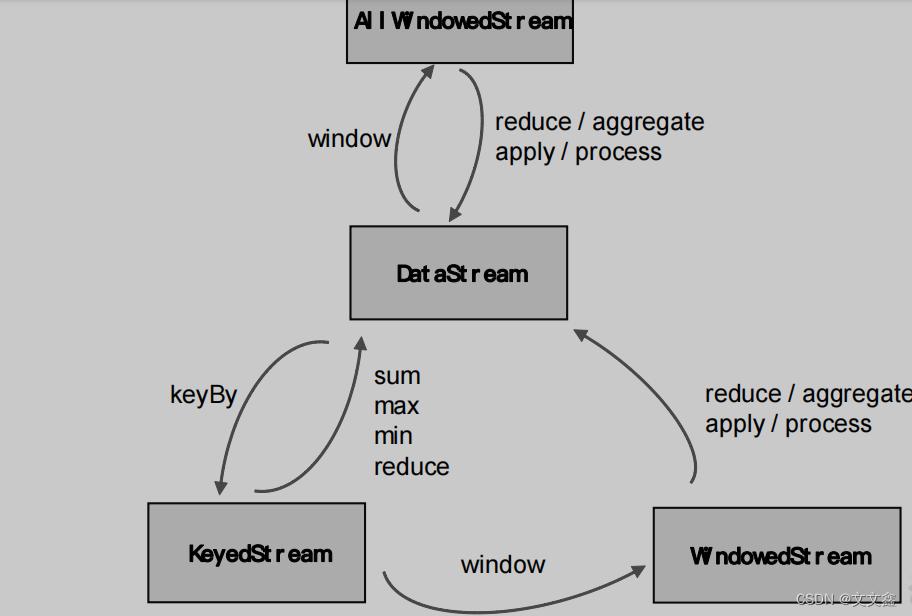
一、什么是增量聚合函數
在Flink Window中定義了窗口分配器,我們只是知道了數據屬于哪個窗口,可以將數據收集起來了;至于收集起來到底要做什么,其實還完全沒有頭緒,這也就是窗口函數所需要做的事情。所以在窗口分配器之后,我們還要再接上一個定義窗口如何進行計算的操作,這就是所謂的“窗口函數”(window functions)。
窗口可以將數據收集起來,最基本的處理操作當然就是基于窗口內的數據進行聚合。
我們可以每來一個數據就在之前結果上聚合一次,這就是“增量聚合”。
典型的增量聚合函數有兩個:ReduceFunction 和 AggregateFunction。
二、ReduceFunction
源碼解析
@FunctionalInterface
@Public
public interface ReduceFunction<T> extends Function, Serializable {T reduce(T var1, T var2) throws Exception;
}
實際案例
在Flink中,使用socket模擬實時的數據流DataStream,通過定義一個滾動窗口,窗口的大小為10s,按照id分區,使用reduce聚合函數實現value的累加統計
package com.flink.DataStream.WindowFunctions;import com.flink.POJOs.WaterSensor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class FlinkWindowReduceFunction {public static void main(String[] args) throws Exception {StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();streamExecutionEnvironment.setParallelism(1);DataStreamSource<String> streamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);// 注意這里為什么返回的是KeyedStream(建控流/分區流),而不是DataStreamKeyedStream<WaterSensor, String> keyedStream = streamSource// 使用map函數將輸入的string轉為一個WaterSensor類.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {// 這里寫的很詳細,如何把string轉為的WaterSensor類String[] strings = s.split(",");String id = strings[0];Long ts = Long.valueOf(strings[1]);Integer vc = Integer.valueOf(strings[2]);WaterSensor waterSensor = new WaterSensor();waterSensor.setId(id);waterSensor.setTs(ts);waterSensor.setVc(vc);return waterSensor;//return new WaterSensor(strings[0],Long.valueOf(strings[1]),Integer.valueOf(strings[2])}})// 按照id做keyBy分區(提問:KeyBy是如何實現分區的?).keyBy(new KeySelector<WaterSensor, String>() {// 也可以直接使用lamda表達式更簡單@Overridepublic String getKey(WaterSensor waterSensor) throws Exception {// getId()方法就是return的waterSensor.idreturn waterSensor.getId();}});/*** 窗口操作主要有兩個部分:窗口分配器(Window Assigners)和窗口函數(WindowFunctions)* .window()方法需要傳入一個窗口分配器,它指明了窗口的類型* */SingleOutputStreamOperator<WaterSensor> outputStreamOperator = keyedStream// 設置滾動窗口的大小(10秒).window(TumblingProcessingTimeWindows.of(Time.seconds(10)))// 使用匿名函數實現增量聚合函數ReduceFunction.reduce(new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor waterSensor1, WaterSensor waterSensor2) throws Exception {System.out.println("調用reduce方法,之前的結果:" + waterSensor1 + ",現在來的數據:" + waterSensor2);return new WaterSensor(waterSensor1.getId(), System.currentTimeMillis(), waterSensor1.getVc() + waterSensor2.getVc());}});outputStreamOperator.print();streamExecutionEnvironment.execute();}
}
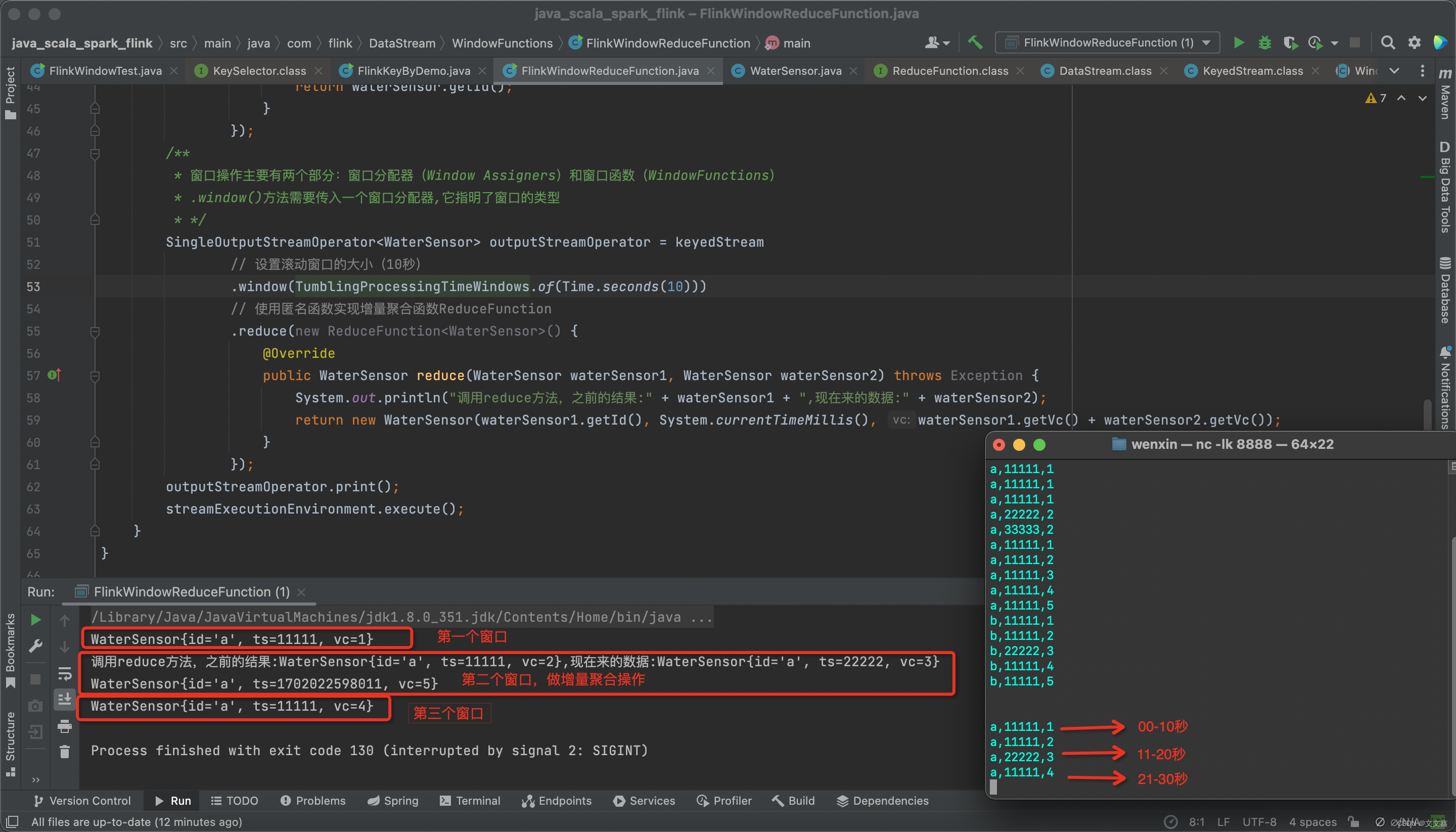
啟動Flink程序,啟動nc,模擬輸入
nc -lk 8888
# 00-10秒輸入
a,11111,1
# 11-20秒輸入
a,11111,2
a,22222,3
# 21-30秒輸入
a,11111,4
查看控制臺打印結果
WaterSensor{id='a', ts=11111, vc=1}
調用reduce方法,之前的結果:WaterSensor{id='a', ts=11111, vc=2},現在來的數據:WaterSensor{id='a', ts=22222, vc=3}
WaterSensor{id='a', ts=1702022598011, vc=5}
WaterSensor{id='a', ts=11111, vc=4}
三、AggregateFunction
雖然ReduceFunction 可以解決大多數歸約聚合的問題,但是我們通過上述案例可以發現:這個接口有一個限制,就是聚合狀態的類型、輸出結果的類型都必須和輸入數據類型一樣。
Flink Window API 中的 aggregate 就突破了這個限制,可以定義更加靈活的窗口聚合操作。這個方法需要傳入一個 AggregateFunction 的實現類作為參數。AggregateFunction 可以看作是 ReduceFunction 的通用版本,這里有三種類型:輸入類型(IN)、累加器類型(ACC)和輸出類型(OUT)。輸入類型 IN 就是輸入流中元素的數據類型;累加器類型 ACC 則是我們進行聚合的中間狀態類型;而輸出類型當然就是最終計算結果的類型了。
@PublicEvolving
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {ACC createAccumulator();ACC add(IN var1, ACC var2);OUT getResult(ACC var1);ACC merge(ACC var1, ACC var2);
}
接口中有四個方法:
1.createAccumulator()
創建一個累加器,這就是為聚合創建了一個初始狀態,每個聚合任務只會調用一次。
2.add()
將輸入的元素添加到累加器中。
3.getResult()
從累加器中提取聚合的輸出結果。
4.merge()
合并兩個累加器,并將合并后的狀態作為一個累加器返回。
所以可以看到,AggregateFunction 的工作原理是:首先調用 createAccumulator()為任務初始化一個狀態(累加器);而后每來一個數據就調用一次 add()方法,對數據進行聚合,得到的結果保存在狀態中;等到了窗口需要輸出時,再調用 getResult()方法得到計算結果。很明顯,與 ReduceFunction 相同,AggregateFunction 也是增量式的聚合;而由于輸入、中間狀態、輸出的類型可以不同,使得應用更加靈活方便。
)


存儲技術專家成長路線)















