前言:Hello大家好,我是Dream。 今天來學習一下機器學習中一個非常經典的案例:預測波士頓房價,在此過程中也會補充很多重要的知識點,歡迎大家一起前來探討學習~
一、導入數據
在這個項目中,我們利用馬薩諸塞州波士頓郊區的房屋信息數據訓練和測試一個模型,并對模型的性能和預測能力進行測試。此項目的數據集來自UCI機器學習知識庫。波士頓房屋這些數據于1978年開始統計,共506個數據點,涵蓋了麻省波士頓不同郊區房屋14種特征的信息。
通過該數據訓練后的好的模型可以被用來對房屋做特定預測—尤其是對房屋的價值。對于房地產經紀等人的日常工作來說,這樣的預測模型被證明非常有價值。
本項目對原始數據集做了以下處理:
- 有16個
'MEDV'值為50.0的數據點被移除。 這很可能是由于這些數據點包含遺失或看不到的值。 - 有1個數據點的
'RM'值為8.78. 這是一個異常值,已經被移除。 - 對于本項目,房屋的
'RM','LSTAT','PTRATIO'以及'MEDV'特征是必要的,其余不相關特征已經被移除。 'MEDV'特征的值已經過必要的數學轉換,可以反映35年來市場的通貨膨脹效應。
import numpy as np
import pandas as pd
from sklearn.model_selection import ShuffleSplit
import visuals as vs
%matplotlib inline# Load the Boston housing dataset
data = pd.read_csv('housing.csv')
prices = data['MEDV']
features = data.drop('MEDV', axis = 1)
data.head(5)
二、分析數據
在項目的第一個部分,會對波士頓房地產數據進行初步的觀察,通過對數據的探索來熟悉數據可以讓你更好地理解和解釋你的結果。
由于這個項目的最終目標是建立一個預測房屋價值的模型,我們需要將數據集分為特征(features)和目標變量(target variable)。
- 特征
'RM','LSTAT',和'PTRATIO',給我們提供了每個數據點的數量相關的信息。 - 目標變量:
'MEDV',是我們希望預測的變量。
他們分別被存在 features 和 prices 兩個變量名中。
基礎統計運算
- 計算
prices中的'MEDV'的最小值、最大值、均值、中值和標準差; - 將運算結果儲存在相應的變量中。
# TODO: Minimum price of the data
minimum_price = np.min(prices)# TODO: Maximum price of the data
maximum_price = np.max(prices)# TODO: Mean price of the data
mean_price =np.mean(prices)# TODO: Median price of the data
median_price = np.median(prices)# TODO: Standard deviation of prices of the data
std_price = np.std(prices)# Show the calculated statistics
print("Statistics for Boston housing dataset:\n")
print("Minimum price: ${:.2f}".format(minimum_price))
print("Maximum price: ${:.2f}".format(maximum_price))
print("Mean price: ${:.2f}".format(mean_price))
print("Median price ${:.2f}".format(median_price))
print("Standard deviation of prices: ${:.2f}".format(std_price))
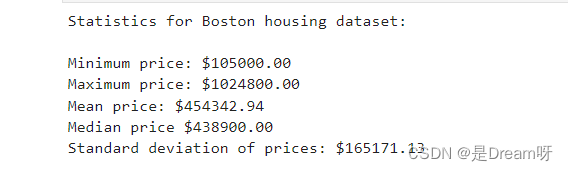
特征觀察
如前文所述,本項目中我們關注的是其中三個值:'RM'、'LSTAT' 和'PTRATIO',對每一個數據點:
'RM'是該地區中每個房屋的平均房間數量;'LSTAT'是指該地區有多少百分比的業主屬于是低收入階層(有工作但收入微薄);'PTRATIO'是該地區的中學和小學里,學生和老師的數目比(學生/老師)。
憑直覺,上述三個特征中對每一個來說,你認為增大該特征的數值,'MEDV'的值會是增大還是減小呢?
‘1’: ‘RM’ 是該地區中每個房屋的平均房間數量:
- ‘回答:’ 'RM’增加,意味著房子的總面積會增加,所以價值會更高。
‘2’: ‘LSTAT’ 是指該地區有多少百分比的業主屬于是低收入階層(有工作但收入微薄);_
- ‘回答:’ 'LSTAT’占比增加,低收入階層增加,可支配消費能力就會不多,房屋的價值不會更高。
‘3’: ‘PTRATIO’ 是該地區的中學和小學里,學生和老師的數目比(學生/老師)
- ‘回答:’ 'PTRATIO’增加,說明學生/老師數目比增加,優質教育程度下降,政府配額不足,學位房優勢不明顯,價值會下降。
三、 建立模型
定義衡量標準
如果不能對模型的訓練和測試的表現進行量化地評估,我們就很難衡量模型的好壞。通常我們會定義一些衡量標準,這些標準可以通過對某些誤差或者擬合程度的計算來得到。我們通過運算[決定系數] R 2 R^2 R2 來量化模型的表現。模型的決定系數是回歸分析中十分常用的統計信息,經常被當作衡量模型預測能力好壞的標準。
R 2 R^2 R2 的數值范圍從0至1,表示目標變量的預測值和實際值之間的相關程度平方的百分比。一個模型的 R 2 R^2 R2 值為0還不如直接用平均值來預測效果好;而一個 R 2 R^2 R2 值為1的模型則可以對目標變量進行完美的預測。從0至1之間的數值,則表示該模型中目標變量中有百分之多少能夠用特征來解釋。模型也可能出現負值的 R 2 R^2 R2,這種情況下模型所做預測有時會比直接計算目標變量的平均值差很多。
在下方代碼的 performance_metric 函數中,我們實現:
- 使用
sklearn.metrics中的r2_score來計算y_true和y_predict的 R 2 R^2 R2 值,作為對其表現的評判。 - 將他們的表現評分儲存到
score變量中。
# TODO: Import 'r2_score'
from sklearn.metrics import r2_score
def performance_metric(y_true, y_predict):score= r2_score(y_true,y_predict)# Return the scorereturn score
擬合程度
假設一個數據集有五個數據且一個模型做出下列目標變量的預測:
| 真實數值 | 預測數值 |
|---|---|
| 3.0 | 2.5 |
| -0.5 | 0.0 |
| 2.0 | 2.1 |
| 7.0 | 7.8 |
| 4.2 | 5.3 |
| 你覺得這個模型已成功地描述了目標變量的變化嗎?如果成功,請解釋為什么,如果沒有,也請給出原因。 |
提示1:運行下方的代碼,使用 performance_metric 函數來計算 y_true 和 y_predict 的決定系數。
提示2: R 2 R^2 R2 分數是指可以從自變量中預測的因變量的方差比例。 換一種說法:
- R 2 R^2 R2 為0意味著因變量不能從自變量預測。
- R 2 R^2 R2 為1意味著可以從自變量預測因變量。
- R 2 R^2 R2 在0到1之間表示因變量可預測的程度。
- R 2 R^2 R2 為0.40意味著 Y 中40%的方差可以從 X 預測。
# Calculate the performance of this model
score = performance_metric([3, -0.5, 2, 7, 4.2], [2.5, 0.0, 2.1, 7.8, 5.3])
print("Model has a coefficient of determination, R^2, of {:.3f}.".format(score))
Model has a coefficient of determination, R^2, of 0.923.
R^2=0.923,決定系數接近1,說明已經成功的描述了目標變量的變化.
數據分割與重排
接下來,我們需要把波士頓房屋數據集分成訓練和測試兩個子集。通常在這個過程中,數據也會被重排列,以消除數據集中由于順序而產生的偏差。
- 使用
sklearn.model_selection中的train_test_split, 將features和prices的數據都分成用于訓練的數據子集和用于測試的數據子集。- 分割比例為:80%的數據用于訓練,20%用于測試;
- 選定一個數值以設定
train_test_split中的random_state,這會確保結果的一致性;
- 將分割后的訓練集與測試集分配給
X_train,X_test,y_train和y_test。
# TODO: Import 'train_test_split'
from sklearn.model_selection import train_test_split# X_train:訓練輸入數據
# X_test:測試輸入數據
# y_train:訓練標簽
# y_test:測試標簽X = np.array(features)
Y = np.array(prices)# TODO: Shuffle and split the data into training and testing subsets
X_train, X_test, y_train, y_test =train_test_split(X, Y, test_size = 0.2,random_state=30)# Success
print("Training and testing split was successful.")
訓練及測試
測試數據集通過未知數據來驗證算法效果。如果沒有數據來對模型進行測試,無法驗證未知數據對結果預測。
四、分析模型的表現
在項目的第四步,我們來看一下不同參數下,模型在訓練集和驗證集上的表現。這里,我們專注于一個特定的算法(帶剪枝的決策樹,但這并不是這個項目的重點),和這個算法的一個參數 'max_depth'。用全部訓練集訓練,選擇不同'max_depth' 參數,觀察這一參數的變化如何影響模型的表現。畫出模型的表現來對于分析過程十分有益。
學習曲線
下方區域內的代碼會輸出四幅圖像,它們是一個決策樹模型在不同最大深度下的表現。每一條曲線都直觀得顯示了隨著訓練數據量的增加,模型學習曲線的在訓練集評分和驗證集評分的變化,評分使用決定系數 R 2 R^2 R2。曲線的陰影區域代表的是該曲線的不確定性(用標準差衡量)。
vs.ModelLearning(features, prices)
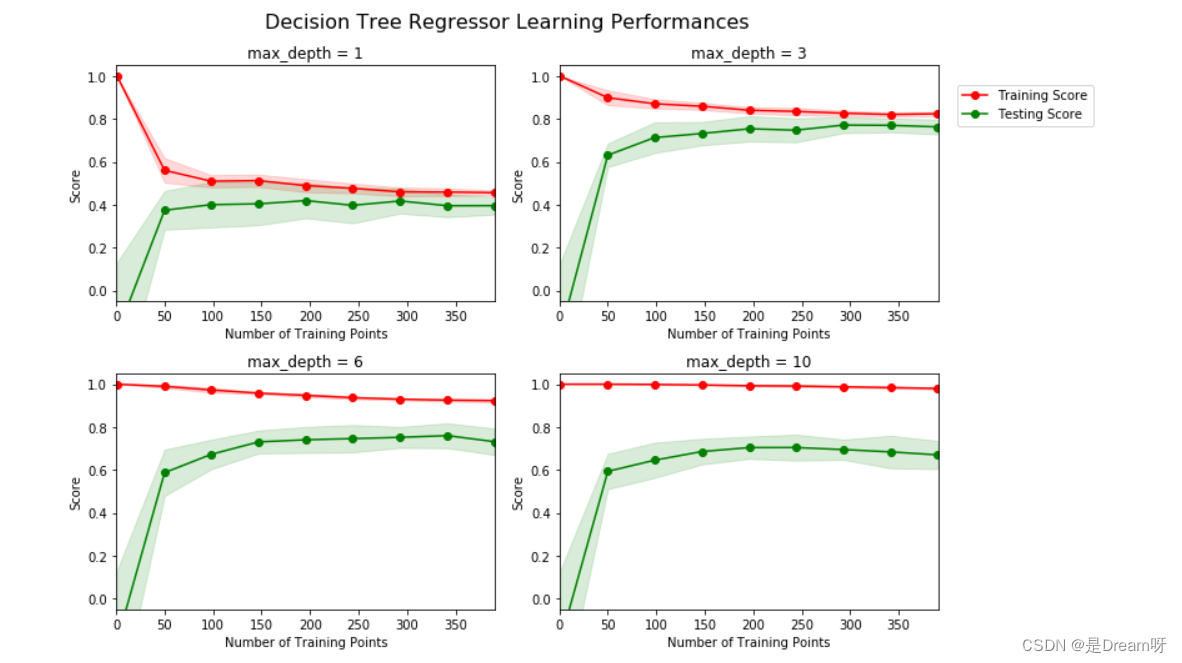
max-depth = 1 ;當訓練數據從0到50增加時,訓練集曲線的評分急速下降,驗證集曲線的評分急速增加,隨著數據量大于50再往上增加,訓練集評分逐漸緩慢0.5附近收斂,驗證集評分逐漸緩慢向0.4左右收斂,分數大于100以后,訓練集評分和驗證集評分基本趨向穩定。如果再有更多的訓練數據,也不會有效提升模型的表現。
復雜度曲線
下列代碼內的區域會輸出一幅圖像,它展示了一個已經經過訓練和驗證的決策樹模型在不同最大深度條件下的表現。這個圖形將包含兩條曲線,一個是訓練集的變化,一個是驗證集的變化。跟學習曲線相似,陰影區域代表該曲線的不確定性,模型訓練和測試部分的評分都用的 performance_metric 函數。
vs.ModelComplexity(X_train, y_train)
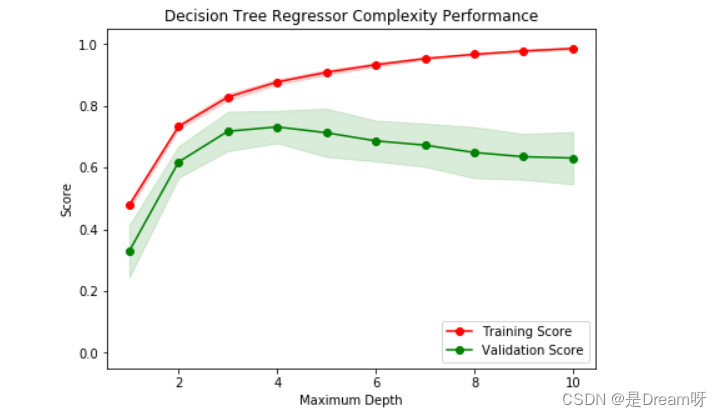
1:當模型以最大深度 1訓練時,模型的預測是出現很大的偏差還是出現了很大的方差?
- ** 回答:** 欠擬合,出現大的偏差
2:當模型以最大深度10訓練時,情形又如何呢?
- ** 回答:** 過擬合,出現大的方差
3:圖形中的哪些特征能夠支持你的結論?
- ** 回答:** 當深度=1時訓練集評分和驗證集評分比較低。深度=10時,訓練集評分和驗證集評分誤差越來越大。
五、評估模型的表現
我們使用 fit_model 中的優化模型去預測客戶特征集:
網格搜索法
1: 什么是網格搜索法?
- 回答: 通過各種訓練數據訓練一堆模型,然后通過交叉驗證數據挑選最佳模型。
2:如何用它來優化模型?
- **回答:**例如決策樹算法,通過不同深度的1,2,3,4的訓練數據模型,通過交叉驗證數據算出F1得分最高的,即最優化參數模型。
K折交叉驗證法:
1:什么是K折交叉驗證法
- 回答: 數據被按一定比例分成了訓練集和測試集,在K折交叉驗證中訓練集又被分成了K份,每一份作為驗證集。并進行K份訓練和驗證,最后求出平均分數,以此來得出最優參數和最優模型。
2:GridSearchCV 是如何結合交叉驗證來完成對最佳參數組合的選擇的?
- 回答: 可以通過輸入參數,給出最優化的結果和參數
3:GridSearchCV 中的’cv_results_'屬性能告訴我們什么?
- 回答: 通過修改 fit_model(X_train, y_train) 函數的返回值 print(pd.DataFrame(reg.cv_results_)) 可以看到顯示的是每次訓練模型的結果集
4:網格搜索為什么要使用K折交叉驗證?K折交叉驗證能夠避免什么問題?
- 回答: 為了更好地擬合和預測,得出最優參數和最優模型。K折交叉驗證通過將訓練集分成K份,每一份依次作為驗證集,并進行K次訓練和驗證,最后求出平均分數,這樣可以減少模型表現得評分誤差,從而更準確地找到最優參數
擬合模型
我們使用決策樹算法訓練一個模型。為了得出的是一個最優模型,我們需要使用網格搜索法訓練模型,以找到最佳的 'max_depth' 參數。我們把'max_depth' 參數理解為決策樹算法在做出預測前,允許其對數據提出問題的數量。決策樹是監督學習算法中的一種。
ShuffleSplit 在 Scikit-Learn 版本0.17和0.18中有不同的參數。對于下面代碼單元格中的 fit_model 函數:
- 定義
'regressor'變量: 使用sklearn.tree中的DecisionTreeRegressor創建一個決策樹的回歸函數; - 定義
'params'變量: 為'max_depth'參數創造一個字典,它的值是從1至10的數組; - 定義
'scoring_fnc'變量: 使用sklearn.metrics中的make_scorer創建一個評分函數。將‘performance_metric’作為參數傳至這個函數中; - 定義
'grid'變量: 使用sklearn.model_selection中的GridSearchCV創建一個網格搜索對象;將變量'regressor','params','scoring_fnc'和'cross_validator'作為參數傳至這個對象構造函數中;
# TODO: Import 'make_scorer', 'DecisionTreeRegressor', and 'GridSearchCV'
from sklearn.metrics import make_scorer
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCVdef fit_model(X, y):cv_sets = ShuffleSplit(n_splits=10, test_size=0.20, random_state=0)regressor = DecisionTreeRegressor(random_state=0)params = {"max_depth":list(range(1,11))}scoring_fnc = make_scorer(performance_metric)grid = GridSearchCV(regressor,params,scoring=scoring_fnc,cv=cv_sets)grid = grid.fit(X, y)return grid
六、做出預測
當我們用數據訓練出一個模型,它現在就可用于對新的數據進行預測。在決策樹回歸函數中,模型已經學會對新輸入的數據提問,并返回對目標變量的預測值。我們可以用這個預測來獲取數據未知目標變量的信息,這些數據必須是不包含在訓練數據之內的。
# Fit the training data to the model using grid search
reg = fit_model(X_train, y_train)# clf.cv_results_ 是選擇參數的日志信息
#print(pd.DataFrame(reg.cv_results_))
# Produce the value for 'max_depth'
print("Parameter 'max_depth' is {} for the optimal model.".format(reg.best_estimator_.get_params()['max_depth']))
最優模型的最大深度是 max_depth = 4
預測銷售價格
假如我們是一個在波士頓地區的房屋經紀人,并期待使用此模型以幫助你的客戶評估他們想出售的房屋。你已經從你的三個客戶收集到以下的資訊:
| 特征 | 客戶 1 | 客戶 2 | 客戶 3 |
|---|---|---|---|
| 房屋內房間總數 | 5 間房間 | 4 間房間 | 8 間房間 |
| 社區貧困指數(%被認為是貧困階層) | 17% | 32% | 3% |
| 鄰近學校的學生-老師比例 | 15:1 | 22:1 | 12:1 |
- 你會建議每位客戶的房屋銷售的價格為多少?
- 從房屋特征的數值判斷,這樣的價格合理嗎?為什么?
運行下列的代碼區域,使用你優化的模型來為每位客戶的房屋價值做出預測。
# Produce a matrix for client data
client_data = [[5, 17, 15], # Client 1[4, 32, 22], # Client 2[8, 3, 12]] # Client 3# Show predictions
for i, price in enumerate(reg.predict(client_data)):print("Predicted selling price for Client {}'s home: ${:,.2f}".format(i+1, price))
Predicted selling price for Client 1’s home: $409,752.00
Predicted selling price for Client 2’s home: $220,886.84
Predicted selling price for Client 3’s home: $937,650.00
1: 你會建議每位客戶的房屋銷售的價格為多少?
回答:
-
客戶1建議價格:$409,752.00 理由是:5間房 社區貧困指數為17%不到1/5 學生:老師比例15:1,教育環境中等偏上,房屋宜居性良好,綜上價格合理。
-
客戶2建議價格:$220,886.84 理由是:4間房 社區貧困指數將近1/3,學生:老師比例22:1,教育環境很一般。房屋購買吸引力不是很好,所以價值低合理
-
客戶3建議價格:$937,650.00 理由是:8間房 社區貧困指數只有3%屬于富人區,老師比例12:1教育環境優,綜上該房屋屬于上游配套,房間較高合理。
2: 從房屋特征的數值判斷,這樣的價格合理嗎?為什么?
回答: 客戶1、客戶2、客戶2的預測數據分別為:$409,752.00 、$220,886.84、 $937960;房間越多價值越高,鄰近學校的學生-老師比例越低價值越高,社區貧困 指數(%)占比越低價值越高,這三個房屋特征數據預測數來的數據我認為是比較合理的,從價值來看幾個特征衡量價值影響權重分別為:社區貧困指數 (高端生活區)> 鄰近學校的學生-老師比例 (教育資源)> 房屋內房間總數
剛剛預測了三個客戶的房子的售價。在這個練習中,我們用最優模型在整個測試數據上進行預測, 并計算相對于目標變量的決定系數 R 2 R^2 R2 的值。
# TODO Calculate the r2 score between 'y_true' and 'y_predict'
predicted = reg.predict(X_test)
r2 = performance_metric(y_test,predicted)print("Optimal model has R^2 score {:,.2f} on test data".format(r2))
Optimal model has R^2 score 0.80 on test data
R^2=0.8,說明符合變量的變化的結果.
模型健壯性
一個最優的模型不一定是一個健壯模型。有的時候模型會過于復雜或者過于簡單,以致于難以泛化新增添的數據;有的時候模型采用的學習算法并不適用于特定的數據結構;有的時候樣本本身可能有太多噪點或樣本過少,使得模型無法準確地預測目標變量。這些情況下我們會說模型是欠擬合的。模型是否足夠健壯來保證預測的一致性?
vs.PredictTrials(features, prices, fit_model, client_data)
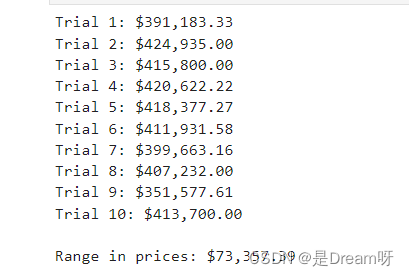
10次訓練結果除了第9次,其他基本在訓練結果數值比較穩定,說明模型相對健壯
1:1978年所采集的數據,在已考慮通貨膨脹的前提下,在今天是否仍然適用?
**回答:**不適用,數據太舊,無法體現現在的價值。
2: 數據中呈現的特征是否足夠描述一個房屋?
回答: 不足,還有很多影響房屋價格的特征:房屋的新舊程度、樓層的高低、建筑結構等等。
3: 在波士頓這樣的大都市采集的數據,能否應用在其它鄉鎮地區?
回答: 不適合
4:你覺得僅僅憑房屋所在社區的環境來判斷房屋價值合理嗎?
回答: 不合理,社區環境房屋價值的一部分,還應考慮地理位置、城市經濟因素、交通因素、教育發達程度、已經房屋本身的一些其他特征等諸多因素。
文末推薦與福利

《Python從入門到精通(微課精編版)》免費包郵送出3本!
內容介紹:
《Python從入門到精通(微課精編版)》使用通俗易懂的語言、豐富的案例,詳細介紹了Python語言的編程知識和應用技巧。全書共24章,內容包括Python開發環境、變量和數據類型、表達式、程序結構、序列、字典和集合、字符串、正則表達式、函數、類、模塊、異常處理和程序調試、進程和線程、文件操作、數據庫操作、圖形界面編程、網絡編程、Web編程、網絡爬蟲、數據處理等,還詳細介紹了多個綜合實戰項目。其中,第24章為擴展項目在線開發,是一章純線上內容。全書結構完整,知識點與示例相結合,并配有案例實戰,可操作性強,示例源代碼大都給出詳細注釋,讀者可輕松學習,快速上手。本書采用O2O教學模式,線下與線上協同,以紙質內容為基礎,同時拓展更多超值的線上內容,讀者使用手機微信掃一掃即可快速閱讀,拓展知識,開闊視野,獲取超額實戰體驗。

抽獎方式: 評論區隨機抽取3位小伙伴免費送出!
參與方式: 關注博主、點贊、收藏、評論區評論“人生苦短,我用Python!”(切記要點贊+收藏,否則抽獎無效,每個人最多評論三次!)
活動截止時間: 2023-12-12 20:00:00
當當購買鏈接: https://product.dangdang.com/29484801.html
京東購買鏈接: https://item.jd.com/13524355.html
😄😄😄名單公布方式: 下期活動開始將在評論區和私信一并公布,中獎者請三天內私信提供收貨信息😄😄😄




-源碼)


二)



)
)







