1 注意力機制概述
1.1 定義
注意力機制(Attention Mechanism)是深度學習領域中的一種重要技術,特別是在序列模型如自然語言處理(NLP)和計算機視覺中。它使模型能夠聚焦于輸入數據的重要部分,從而提高整體性能和效率。
1.2 基本原理
-
聚焦關鍵信息: 注意力機制模仿人類的注意力過程,使模型能夠集中處理輸入數據中的關鍵信息,同時忽略不太相關的部分。
-
權重分配: 通過為輸入數據的不同部分分配不同的權重(或注意力分數),模型能夠識別最重要的信息。
1.3 應用領域
-
自然語言處理(NLP): 在機器翻譯、文本摘要、情感分析等任務中,注意力機制幫助模型關注文本的關鍵部分。
-
計算機視覺: 在圖像分類、目標檢測和圖像字幕生成等任務中,注意力機制使模型能夠專注于圖像的關鍵區域。
-
語音識別: 注意力機制幫助模型關注語音信號的重要部分,提高語音識別的準確性。
1.4 優勢
-
提高性能: 通過集中處理重要信息,注意力機制可以提高模型的準確性和效率。
-
提供可解釋性: 注意力權重可以用來解釋模型的決策過程,增加模型的透明度。
-
靈活性強: 可以與多種模型結構結合,如循環神經網絡(RNN)、卷積神經網絡(CNN)和Transformer。
2 注意力機制分析
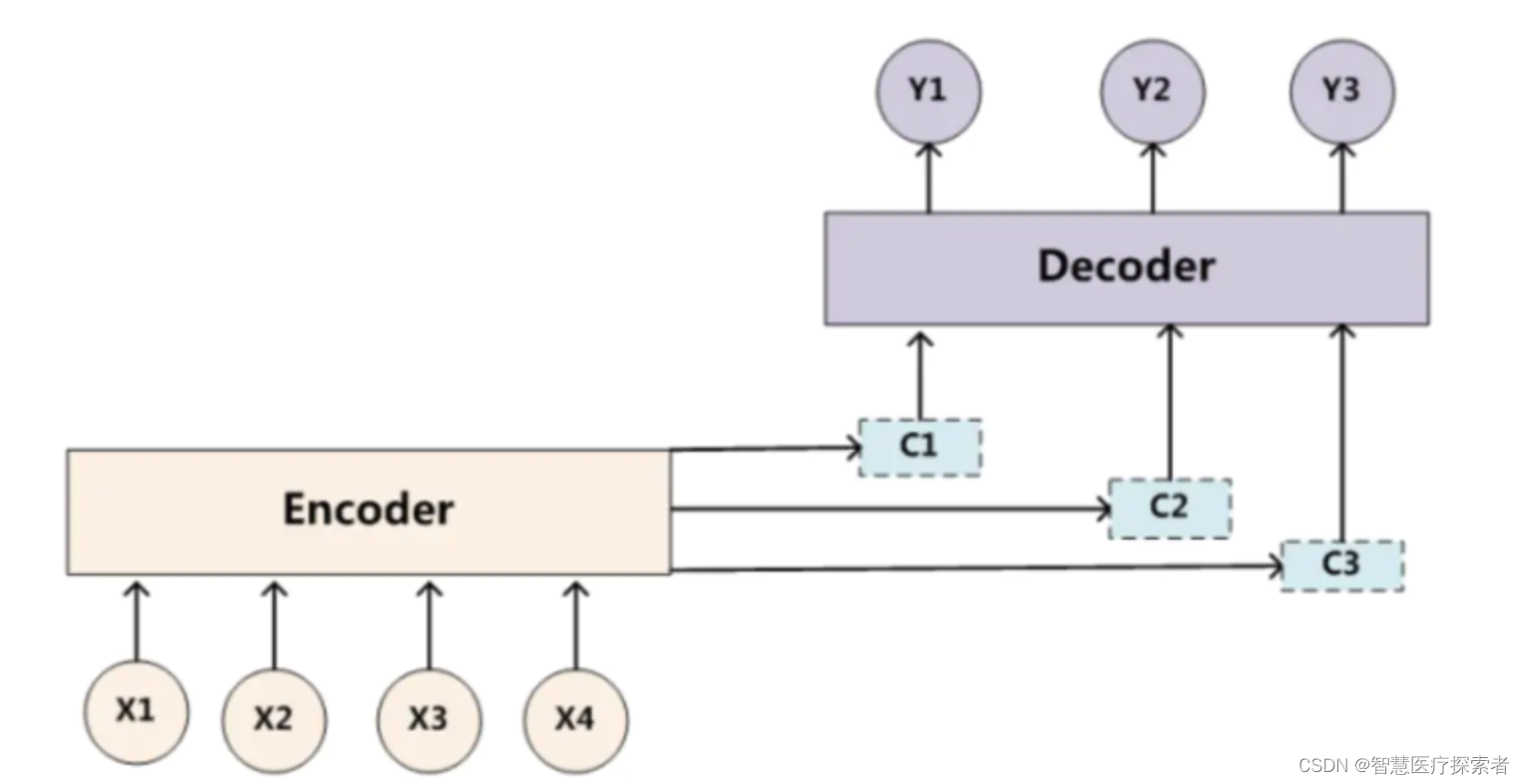
2.1 Encoder-Decoder框架
下面基于Encoder-Decoder框架對注意力機制深入分析,Encoder-Decoder框架的原理如下:
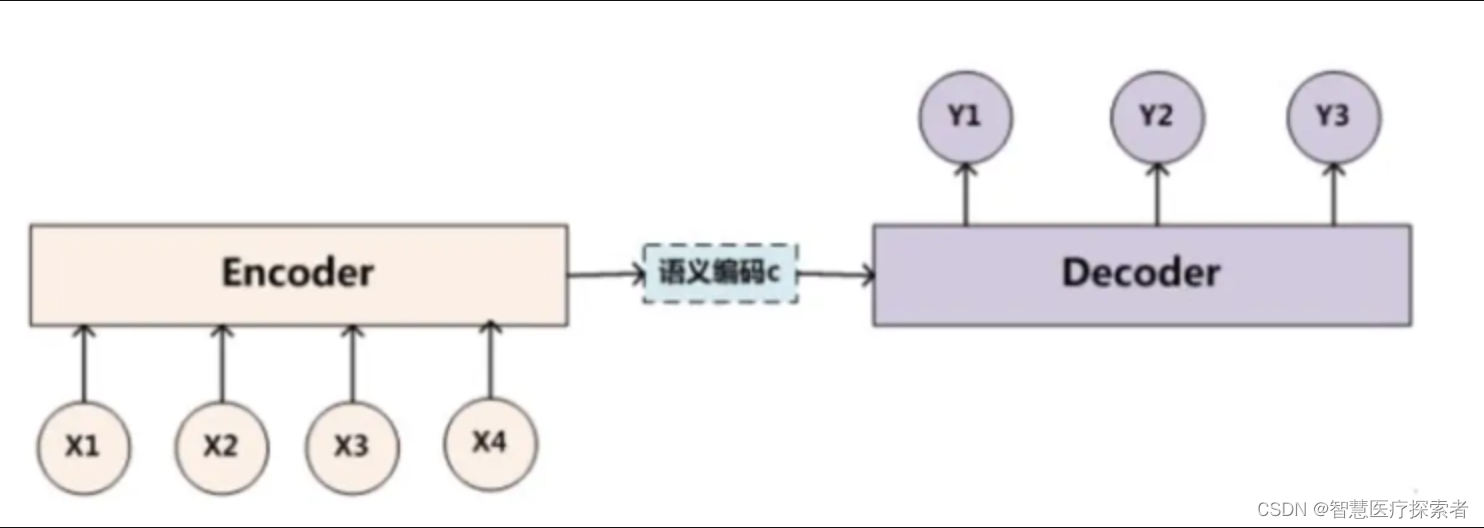
對于句子對<source,target>:
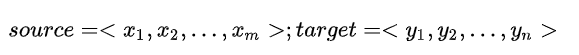
編碼器對輸入source進行編碼,轉換成中間語義向量C:
?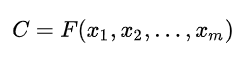
對于解碼器Decoder,根據中間語義向量C和當前已生成的歷史信息來生成下一時刻要生成的單詞:
?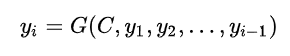
基本的Encoder-Decoder框架沒有體現出注意力機制
把Decoder生成拆開來看:
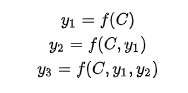
f是非線性變換函數,在生成目標單詞時,使用的語義向量C都是一樣的,所以,source中任意單詞對某個單詞y_i來說,影響力都是相同的。
如果輸入句子比較短,對于輸出影響不是很大,但如果輸入句子很長,這時所有的語義都通過一個語義向量C來表示,單詞自身的信息會消失,很多細節信息會被丟失,最終的輸出也會受到影響,所以要引入注意力機制。
2.2 經典注意力機制
在機器翻譯中,比如輸入source為Tom chase Jerry。輸出想得到中文:湯姆 追逐 杰瑞。在翻譯Jerry這個單詞時,在普通Encoder-Decoder模型中,source里的每個單詞對“杰瑞”貢獻是相同的,但這樣明顯和實際不是很相符,在翻譯“杰瑞”的時候,我們更關注的應該是"Jerry",對于另外兩個單詞,關注的會少一些。
引入Attention模型后,在生成“杰瑞“的時候,會體現出輸入source的不同影響程度,比如:
![]()
每個概率代表了翻譯當前單詞“杰瑞”時注意力分配模型分配給不同英文單詞的注意力大小。
在注意力機制中,對于target中每個單詞都有一個對應source中單詞的注意力概率。
由于注意力模型的加入,原來在生成target單詞時候的中間語義C就不再是固定的,而是會根據注意力概率變化的,加入了注意力模型的Encoder-Decoder框架如下:
?生成target的過程就變成了如下形式:
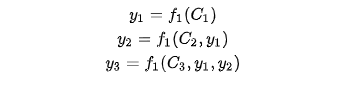
每個可能對應著不同的注意力分配概率分布,比如對于上面的英漢翻譯來說,其對應的信息可能如下:
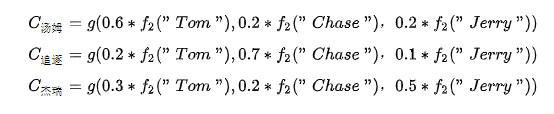
其中,表示Encoder對輸入英文單詞的某種變換函數,?比如如果Encoder是用RNN模型的話,這個
函數的結果往往是某個時刻輸入后隱層節點的狀態值。g代表Encoder根據單詞的中間表示合成整個句子中間語義表示的變換函數,一般g函數就是對構成元素的加權求和:
?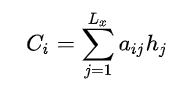
?其中,代表輸入句子Source的長度,a_i_j代表在Target輸出第i個單詞時,Source輸入第j個單詞的注意力分配系數;
代表Source輸入句子中第j個單詞的語義編碼。舉例輸出湯姆如下:
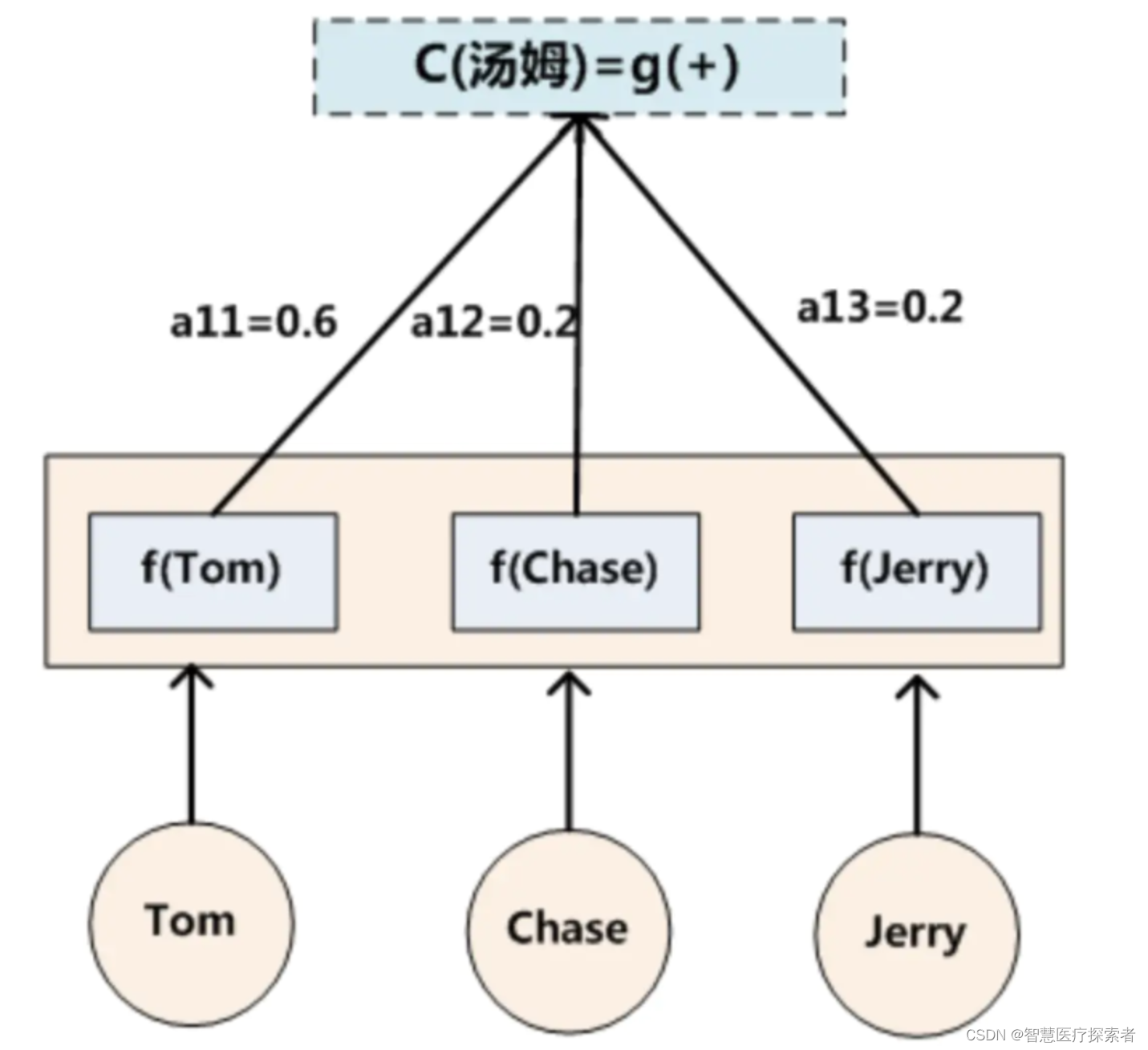
2.3 注意力分布
注意力分布α就是判斷什么信息重要,什么信息不重要,分別賦予不同的權重。
如何計算α:
用X表示輸入當輸入 N 個向量 :[x1,...,xN],想要從中選出對于目標而言比較重要的信息,需要引入目標任務的表示,稱為 查詢向量(query vector),此時問題可以轉換為考察輸入的不同內容和查詢向量之間的相關度,也就是對不同內容進行打分,賦予 與當前任務比較相關的部分 更大的權重,再通過一個softmax層得到分布,也就是輸入信息的不同部分的權重。
注意力變量z∈[1, N]來表示被選擇信息的索引位置,即z=i來表示選擇了第i個輸入信息,然后計算在給定了q和X的情況下,選擇第i個輸入信息的概率αi:
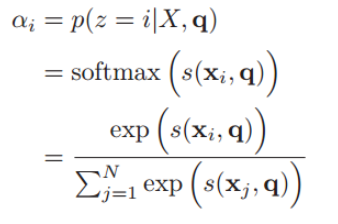
其中αi構成的概率向量就稱為注意力分布(Attention Distribution)。s(xi , q)是注意力打分函數,有以下幾種形式:
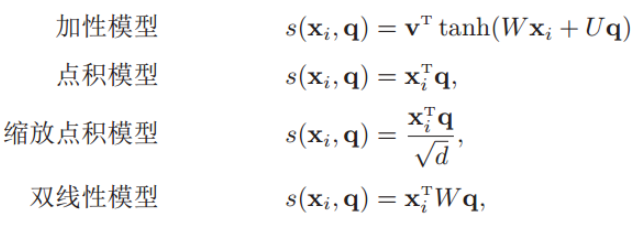
其中W、U和v是可學習的網絡參數,d是輸入信息的維度
加性模型引入了可學習的參數,將查詢向量 q 和原始輸入向量 h 映射到不同的向量空間后進行計算打分,顯然相較于加性模型,點積模型具有更好的計算效率。
另外,當輸入向量的維度比較高的時候,點積模型通常有比較大的方差,從而導致Softmax函數的梯度會比較小。因此縮放點積模型通過除以一個平方根項來平滑分數數值,也相當于平滑最終的注意力分布,緩解這個問題。
最后,雙線性模型可以重塑為,即分別對查詢向量 q 和原始輸入向量 h 進行線性變換之后,再計算點積。相比點積模型,雙線性模型在計算相似度時引入了非對稱性。
形象表示打分函數:

如果Encoder-Decoder都采用RNN,框架如下:
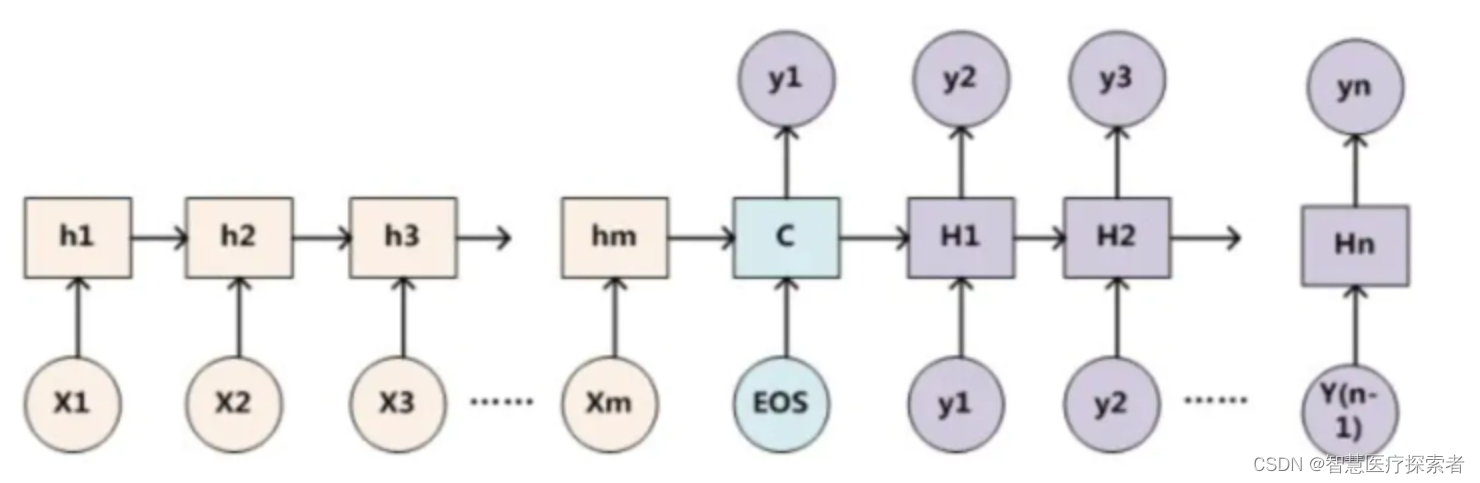 那計算注意力分布概率值的過程如下:
那計算注意力分布概率值的過程如下:
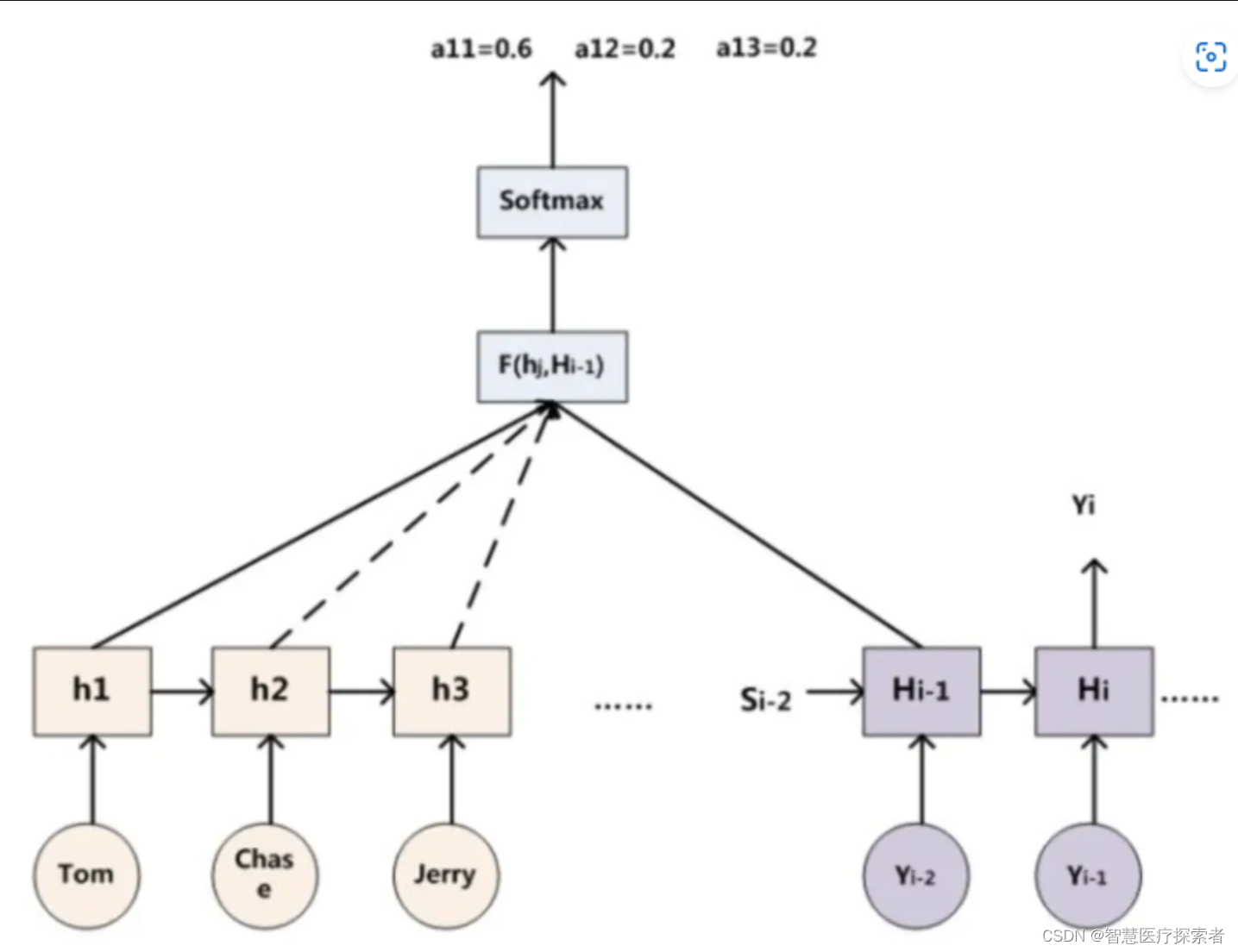
表示Source中單詞 j 對應的隱層節點狀態,
表示Target中單詞 i 的隱層節點狀態,注意力計算的是Target中單詞 i 對Source中每個單詞對齊可能性
,即打分函數。
?計算α,不只是編碼器的隱藏狀態作為輸入,解碼器的隱藏狀態也要作為輸入
可以結合下圖理解:
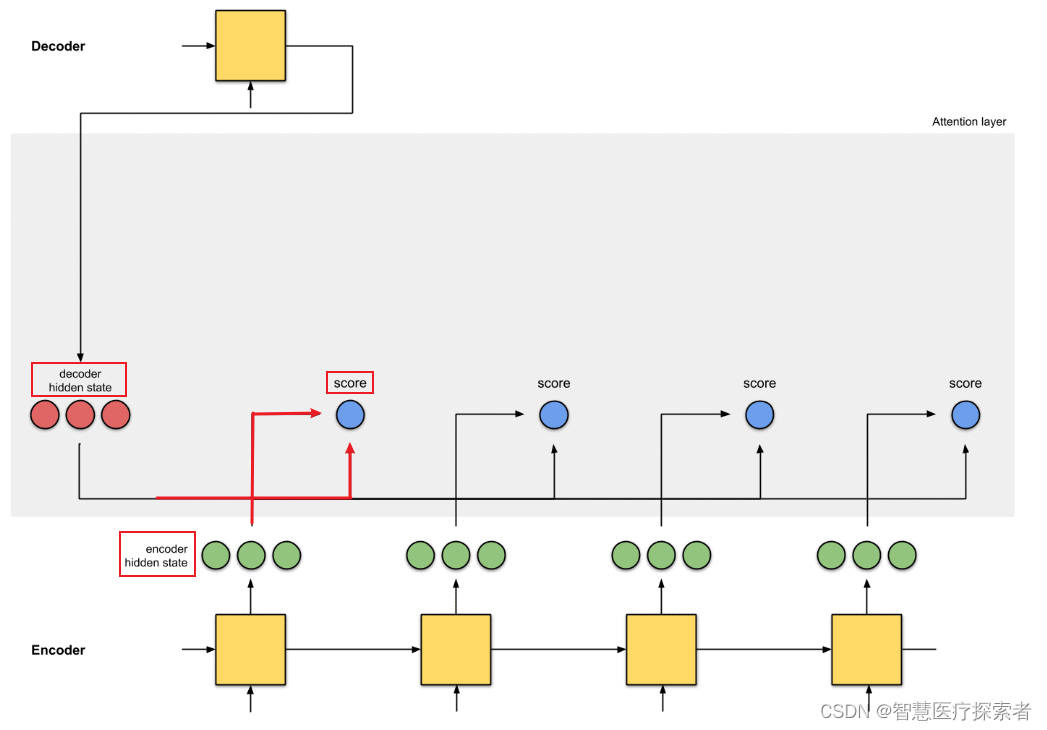
2.4 加權分布?
對于軟性注意力機制,就是每一個輸入按各自權重加權平均,即把每個編碼器隱狀態xi 和對應的注意力分布相乘求和
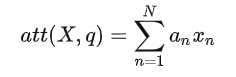
用圖像形象表示:
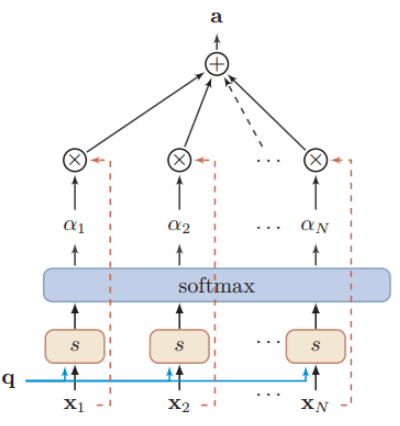
求和之和算出來的就是引入注意力機制的語義向量,再將其輸入到解碼器中。
結合下圖理解:

?這樣Decoder的最終輸出就會有選擇性地關注應該關注的地方。

)
)
)


數據異常檢測)




:Tair介紹)






)
---基礎知識篇)