一、語音合成概述
語音信號的產生分為兩個階段,信息編碼和生理控制。首先在大腦中出現某種想要表達的想法,然后由大腦將其編碼為具體的語言文字序列,及語音中可能存在的強調、重讀等韻律信息。經過語言的組織,大腦通過控制發音器官肌肉的運動,產生出相應的語音信號。其中第一階段主要涉及人腦語言處理方面,第二階段涉及語音信號產生的生理機制。
? 從濾波的角度,人體涉及發音的器官可以分為兩部分:激勵系統和聲道系統。激勵系統中,儲存于肺部的空氣源,經過胸腔的壓縮排出,經過氣管進入聲帶,根據發音單元決定是否產生振動,形成準周期的脈沖空氣激勵流或噪聲空氣激勵流。這些空氣流作為激勵,進入聲道系統,被頻率整形,形成不同的聲音。聲道系統包括咽喉、口腔(舌、唇、頜和口)組成,可能還包括鼻道。不同周期的脈沖空氣流或者噪聲空氣流,以及不同聲道器官的位置決定了產生的聲音。因此,語音合成中通常將語音的建模分解為激勵建模和聲道建模。
1.?語音合成的歷史和研究方法
語音合成系統分為兩部分,分別稱為文本前端和后端。文本前端主要負責在語言層、語法層、語義層對輸入文本進行文本分析;后端主要是從信號處理、模式識別、機器學習等角度,在語音層面上進行韻律特征建模,聲學特征建模,然后進行聲學預測或者在音庫中進行單元挑選,最終經過合成器或者波形拼接等方法合成語音。


根據語音合成研究的歷史,語音合成研究方法可以分為:機械式語音合成器、電子式語音合成器、共振峰參數合成器、基于波形拼接的語音合成(Concatenative Speech Synthesis)、統計參數語音合成(Statistical Parametric Speech Synthesis,SPSS)、以及神經網絡語音合成。
早期的語音合成方法由于模型簡單,系統復雜等原因,難以在實際場景應用。隨著計算機技術的發展,基于波形拼接的語音合成被提出。基于波形拼接的語音合成 Concatenative Speech Synthesis的基本原理是首先構建一個音庫,在合成階段,通過對合成文本的分析,按照一定的準則,從音庫中挑選出與待合成語音相似的聲學單元,對這些聲學單元進行少量調整,拼接得到合成的語音。早期的波形拼接系統受限于音庫大小、挑選算法、拼接調整的限制,合成語音質量較低。1990年,基于同步疊加的時域波形修改算法被提出,解決了聲學單元拼接處的局部不連續問題。更進一步,基于大語料庫的波形拼接語音合成方法被提出,采用更精細的挑選策略,將語音音庫極大地拓展,大幅提升了合成語音的自然度。由于直接使用發音人的原始語音,基于波形拼接的語音合成方法合成語音的音質接近自然語音,被廣泛應用。但其缺點也較為明顯,包括音庫制作時間長、需要保存整個音庫、拓展性差、合成語音自然度受音庫和挑選算法影響,魯棒性不高等。
?隨著統計建模理論的完善,以及對語音信號理解的深入,基于統計參數的語音合成方法(Statistical Parametric Speech Synthesis,SPSS)被提出。其基本原理是使用統計模型,對語音的參數化表征進行建模。在合成階段,給定待合成文本,使用統計模型預測出對應的聲學參數,經過聲碼器vocoder合成語音波形。統計參數語音合成方法是目前的主流語音合成方法之一。統計參數音合成方法的優點很多,包括只需要較少的人工干預,能夠快速地自動構建系統,同時具有較強的靈活性,能夠適應不同發音人,不同發音風格,多語種的語音合成,具有較強的魯棒性等。由于語音參數化表示以及統計建模的平均效應,統計參數語音合成方法生成的語音自然度相比自然語音通常會有一定的差距。基于隱馬爾科夫HMM的統計參數語音合成方法是發展最為完善的一種。基于HMM的統計參數語音合成系統能夠同時對語音的基頻、頻譜和時長進行建模,生成出連續流暢且可懂度高的語音,被廣泛應用,但其合成音質較差。
和統計參數語音合成系統類似,深度學習語音合成系統也可大致分為兩個部分:文本前端和聲學后端。文本前端的主要作用是文本預處理,如:為文本添加韻律信息,并將文本詞面轉化為語言學特征序列(Linguistic Feature Sequence);聲學后端又可以分為聲學特征生成網絡和聲碼器,其中聲學特征生成網絡根據文本前端輸出的信息產生聲學特征,如:將語言學特征序列映射到梅爾頻譜Mel 或線性譜;聲碼器利用頻譜等聲學特征,生成語音樣本點并重建時域波形,如:將梅爾頻譜恢復為對應的語音。近年來,也出現了完全端到端的語音合成系統,將聲學特征生成網絡和聲碼器和合并起來,聲學后端成為一個整體,直接將語言學特征序列,甚至文本詞面端到端轉換為語音波形。
2. 語音合成各部分
2.1. 文本前端
文本前端的作用是從文本中提取發音和語言學信息,其任務至少包括以下四點。
(a). 文本正則化
在語音合成中,用于合成的文本存在特殊符號、阿拉伯數字等,需要把符號轉換為文本。如“1.5?元” 需要轉換成“一點五元”,方便后續的語言學分析。
(b). 韻律預測
該模塊的主要作用是添加句子中韻律停頓或起伏。如“在抗擊新型冠狀病毒的戰役中,黨和人民群眾經受了一次次的考驗”,如果停頓信息不準確就會出現:“在/抗擊/新型冠狀病毒/的/戰役中,黨/和/人民群眾/經受了/一次/次/的/考驗”。“一次次”的地方存在一個錯誤停頓,這將會導致合成語音不自然,如果嚴重些甚至會影響語義信息的傳達。
(c). 字形轉音素
文字轉化為發音信息。比如“中國”是漢字表示,需要先將其轉化為拼音“zhong1 guo2”,以幫助后續的聲學模型更加準確地獲知每個漢字的發音情況。
(d). 多音字和變調
許多語言中都有多音字的現象,比如“模型”和“模樣”,這里“模”字的發音就存在差異。另外,漢字中又存在變調現象,如“一個”和“看一看”中的“一”發音音調不同。所以在輸入一個句子的時候,文本前端就需要準確判斷出文字中的特殊發音情況,否則可能會導致后續的聲學模型合成錯誤的聲學特征,進而生成不正確的語音。
2.2.?聲學特征生成網絡?Acoustic model
聲學特征生成網絡根據文本前端的發音信息,產生聲學特征,如梅爾頻譜或線性譜。近年來,基于深度學習的生成網絡甚至可以去除文本前端,直接由英文等文本生成對應的頻譜。但是一般來說,因為中文字形和讀音關聯寥寥,因此中文語音合成系統大多無法拋棄文本前端,換言之,直接將中文文本輸入到聲學特征生成網絡中是不可行的。基于深度學習的聲學特征生成網絡發展迅速,比較有代表性的模型有Tacotron系列,FastSpeech系列等。近年來,也涌現出類似于VITS的語音合成模型,將聲學特征生成網絡和聲碼器融合在一起,直接將文本映射為語音波形。
2.3. 聲碼器?Vocoder
通過聲學特征產生語音波形的系統被稱作聲碼器,聲碼器是決定語音質量的一個重要因素。一般而言,聲碼器可以分為以下4類:純信號處理,如Griffin-Lim、STRAIGHT和WORLD;自回歸深度網絡模型,如WaveNet和WaveRNN;非自回歸模型,如Parallel WaveNet、ClariNet和WaveGlow;基于生成對抗網絡(Generative Adversarial Network,GAN)的模型,如MelGAN、Parallel WaveGAN和HiFiGAN。
3.?語音合成評價指標
對合成語音的質量評價,主要可以分為主觀和客觀評價。主觀評價是通過人類對語音進行打分,比如平均意見得分(Mean Opinion Score,MOS)、眾包平均意見得分(CrowdMOS,CMOS)和ABX測試。客觀評價是通過計算機自動給出語音音質的評估,在語音合成領域研究的比較少,論文中常常通過展示頻譜細節,計算梅爾倒譜失真(Mel Cepstral Distortion,MCD)等方法作為客觀評價。客觀評價還可以分為有參考和無參考質量評估,這兩者的主要判別依據在于該方法是否需要標準信號。有參考評估方法除了待評測信號,還需要一個音質優異的,可以認為沒有損傷的參考信號。常見的有參考質量評估主要有ITU-T P.861 (MNB)、ITU-T P.862 (PESQ)、ITU-T P.863 (POLQA)、STOI和BSSEval。無參考評估方法則不需要參考信號,直接根據待評估信號,給出質量評分,無參考評估方法還可以分為基于信號、基于參數以及基于深度學習的質量評估方法。常見的基于信號的無參考質量評估包括ITU-T P.563和ANIQUE+,基于參數的方法有ITU-T G.107(E-Model)。近年來,深度學習也逐步應用到無參考質量評估中,如:AutoMOS、QualityNet、NISQA和MOSNet。
主觀評價中的MOS評測是一種較為寬泛的說法,由于給出評測分數的主體是人類,因此可以靈活測試語音的不同方面。比如在語音合成領域,主要有自然度MOS(MOS of Naturalness)和相似度MOS(MOS of Similarity)。但是人類給出的評分結果受到的干擾因素較多,谷歌對合成語音的主觀評估方法進行了比較,在評估較長語音中的單個句子時,音頻樣本的呈現形式會顯著影響參與人員給出的結果。比如僅提供單個句子而不提供上下文,與相同句子給出語境相比,被測人員給出的評分差異顯著。國際電信聯盟(International Telecommunication Union,ITU)將MOS評測規范化為ITU-T P.800,其中絕對等級評分(Absolute Category Rating,ACR)應用最為廣泛,ACR的詳細評估標準有5.0-1.0從優到劣。
在使用ACR方法對語音質量進行評價時,參與評測的人員(簡稱被試)對語音整體質量進行打分,分值范圍為1~5分,分數越大表示語音質量越好。MOS大于4時,可以認為該音質受到大部分被試的認可,音質較好;若MOS低于3,則該語音有比較大的缺陷,大部分被試并不滿意該音質。
二、語音信號基礎
1.?語音基本概念
聲波通過空氣傳播,被麥克風接收,通過 采樣、量化、編碼轉換為離散的數字信號,即波形文件。音量、音高和音色是聲音的基本屬性。
1.1 能量
音頻的能量通常指的是時域上每幀的能量,幅度的平方。在簡單的語音活動檢測(Voice Activity Detection,VAD)中,直接利用能量特征:能量大的音頻片段是語音,能量小的音頻片段是非語音(包括噪音、靜音段等)。這種VAD的局限性比較大,正確率也不高,對噪音非常敏感。
1.2?短時能量
短時能量體現的是信號在不同時刻的強弱程度。設第 n 幀語音信號的短時能量用 表示,則其計算公式為:
上式中, ?為幀長,
為該幀中的樣本點。
1.3?聲強和聲強級?sound intensity或acoustic intensity
單位時間內通過垂直于聲波傳播方向的單位面積的平均聲能,稱作聲強,聲強用 I 表示,單位為“瓦/平米”。實驗研究表明,人對聲音的強弱感覺并不是與聲強成正比,而是與其對數成正比,所以一般聲強用聲強級來表示:
其中,I為聲強, 稱為基本聲強,聲強級的常用單位是分貝(dB)。
1.4?響度?loudness
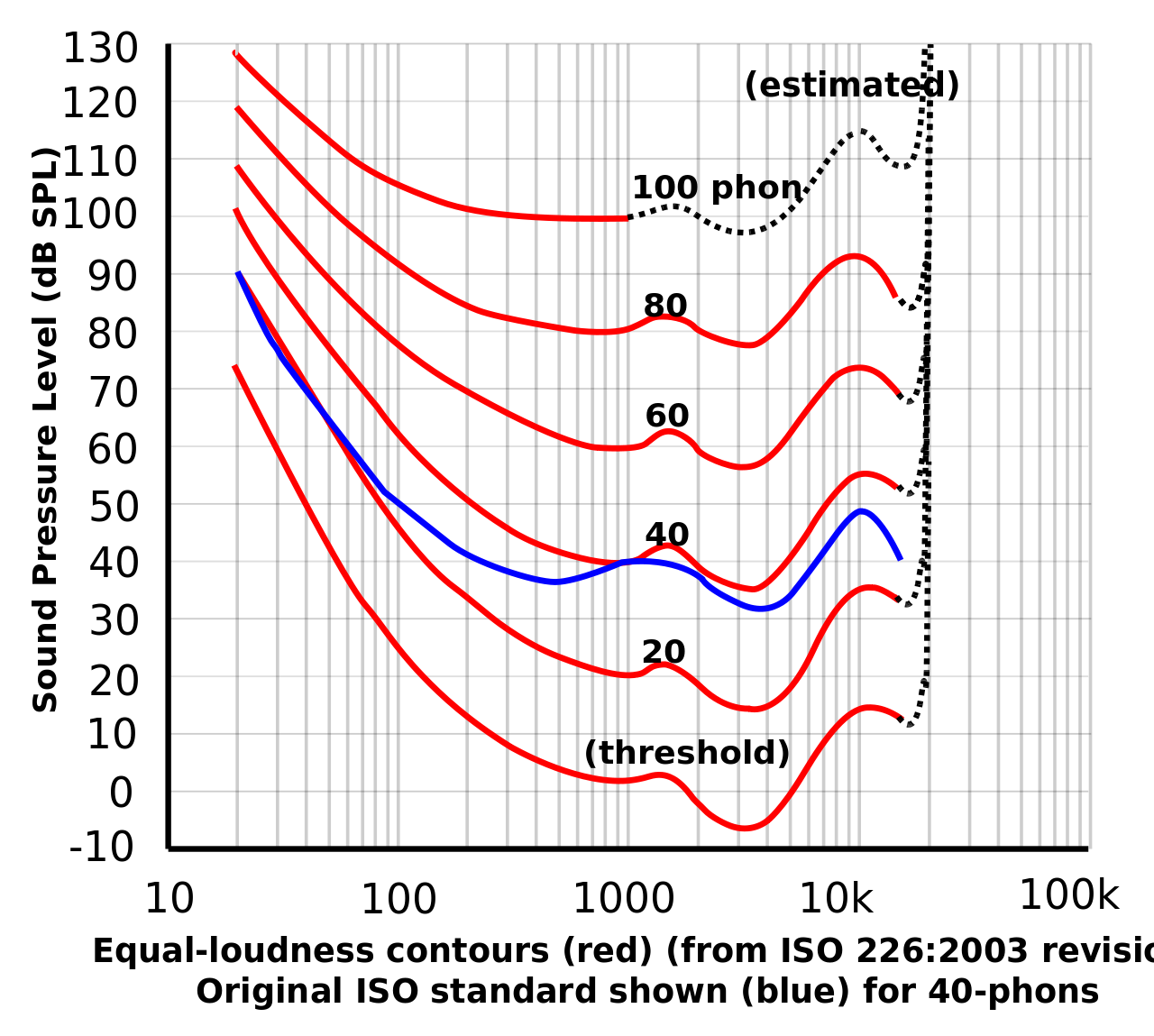
響度是一種主觀心理量,是人類主觀感覺到的聲音強弱程度,又稱音量。響度與聲強和頻率有關。一般來說,聲音頻率一定時,聲強越強,響度也越大。相同的聲強,頻率不同時,響度也可能不同。響度若用對數值表示,即為響度級,響度級的單位定義為方,符號為phon。根據國際協議規定,0dB聲強級的1000Hz純音的響度級定義為0 phon,n dB聲強級的1000Hz純音的響度級就是n phon。其它頻率的聲強級與響度級的對應關系要從如圖等響度曲線查出。
1.5?過零率
過零率體現的是信號過零點的次數,體現的是頻率特性。
其中, 表示幀數,
表示每一幀中的樣本點個數,
為符號函數,即
1.6?共振峰
聲門處的準周期激勵進入聲道時會引起共振特性,產生一組共振頻率,這一組共振頻率稱為共振峰頻率或簡稱共振峰。共振峰包含在語音的頻譜包絡中,頻譜包絡的局部極大值就是共振峰。頻率最低的共振峰稱為第一共振峰,記作$f_1$,頻率更高的共振峰稱為第二共振峰$f_2$、第三共振峰$f_3$……以此類推。實踐中一個元音用三個共振峰表示,復雜的輔音或鼻音,要用五個共振峰。
2.?語言學
語言學研究人類的語言,計算語言學則是一門跨學科的研究領域,試圖找出自然語言的規律,建立運算模型,語音合成其實就是計算語言學的子領域之一。在語音合成中,一般需要將文本轉換為對應的音素,然后再將音素輸入到后端模型中,因此需要為每個語種甚至方言構建恰當合理的音素體系。相關概念如下。
- 音素(phoneme):也稱音位,是能夠區別意義的最小語音單位,同一音素由不同人/環境閱讀,可以形成不同的發音。
- 字素(grapheme):音素對應的文本。
- 發音(phone): 某個音素的具體發音。實際上,phoneme和phone都是指的是音素,音素可具化為實際的音,該過程稱為音素的語音體現。一個音素可能包含著幾個不同音值的音,因而可以體現為一個音、兩個音或更多的同位音。但是在一些論述中,phoneme偏向于表示發音的符號,phone更偏向于符號對應的實際發音,因此phoneme可對應無數個phone。
- ?音節(syllable):音節由音素組成。在漢語中,除兒化音外,一個漢字就是一個音節。如wo3(我)是一個音節,zhong1(中)也是一個音節。
3.?音頻格式
- *.wav: 波形無損壓縮格式,是語音合成中音頻語料的常用格式,主要的三個參數:采樣率,量化位數和通道數。一般來說,合成語音的采樣率采用16kHz、22050Hz、24kHz,對于歌唱合成等高質量合成場景采樣率可達到48kHz;量化位數采用16bit;通道數采用1.
- *.flac: Free Lossless Audio Codec,無損音頻壓縮編碼。
- *.mp3: Moving Picture Experts Group Audio Player III,有損壓縮。
- *.wma: Window Media Audio,有損壓縮。
- *.avi: Audio Video Interleaved,avi文件將音頻和視頻包含在一個文件容器中,允許音視頻同步播放。
4.?數字信號處理
4.1.?模數轉換?Analog to Digital Converter,ADC
模擬信號到數字信號的轉換(Analog to Digital Converter,ADC)稱為模數轉換。
奈奎斯特(Nyquist)采樣定理:要從抽樣信號中無失真地恢復原信號,抽樣頻率應大于2倍信號最高頻率。抽樣頻率小于2倍頻譜最高頻率時,信號的頻譜有混疊。抽樣頻率大于2倍頻譜最高頻率時,信號的頻譜無混疊。如果對語音模擬信號進行采樣率為16000Hz的采樣,得到的離散信號中包含的最大頻率為8000Hz。
4.2. 頻譜泄露?spectral leakage
音頻處理中,經常需要利用傅里葉變換將時域信號轉換到頻域,而一次快速傅里葉變換(FFT)只能處理有限長的時域信號,但語音信號通常是長的,所以需要將原始語音截斷成一幀一幀長度的數據塊。這個過程叫 信號截斷,也叫\lstinline{分幀}。分完幀后再對每幀做FFT,得到對應的頻域信號。FFT是離散傅里葉變換(DFT)的快速計算方式,而做DFT有一個先驗條件:分幀得到的數據塊必須是整數周期的信號,也即是每次截斷得到的信號要求是周期主值序列。
但做分幀時,很難滿足 周期截斷,因此就會導致 {頻譜泄露}。要解決非周期截斷導致的頻譜泄露是比較困難的,可以通過 {加窗}盡可能減少頻譜泄露帶來的影響。窗類型可以分為漢寧窗、漢明窗、平頂窗等。雖然加窗能夠減少頻譜泄露,但加窗衰減了每幀信號的能量,特別是邊界處的能量,這時加一個合成窗,且overlap-add,便可以補回能量。
4.3.?頻率分辨率
頻率分辨率是指將兩個相鄰譜峰分開的能力,在實際應用中是指分辨兩個不同頻率信號的最小間隔。
三、語音特征提取
原始信號是不定長的時序信號,不適合作為機器學習的輸入。因此一般需要將原始波形轉換為特定的特征向量表示,該過程稱為語音特征提取。
1.?預處理
包括預加重、分幀和加窗。
1.1?預加重?pre-emphasis
語音經過說話人的口唇輻射發出,受到唇端輻射抑制,高頻能量明顯降低。一般來說,當語音信號的頻率提高兩倍時,其功率譜的幅度下降約6dB,即語音信號的高頻部分受到的抑制影響較大。在進行語音信號的分析和處理時,可采用預加重(pre-emphasis)的方法補償語音信號高頻部分的振幅,在傅里葉變換操作中避免數值問題,本質是施加高通濾波器。假設輸入信號第 $n$ 個采樣點為 $x[n]$ ,則預加重公式如下:
五、聲學模型?Acoustic model
現代工業級神經網絡語音合成系統主要包括三個部分:文本前端、聲學模型和聲碼器,文本輸入到文本前端中,將文本轉換為音素、韻律邊界等文本特征。文本特征輸入到聲學模型,轉換為對應的聲學特征。聲學特征輸入到聲碼器,重建為原始波形。
1.?Tacotron1
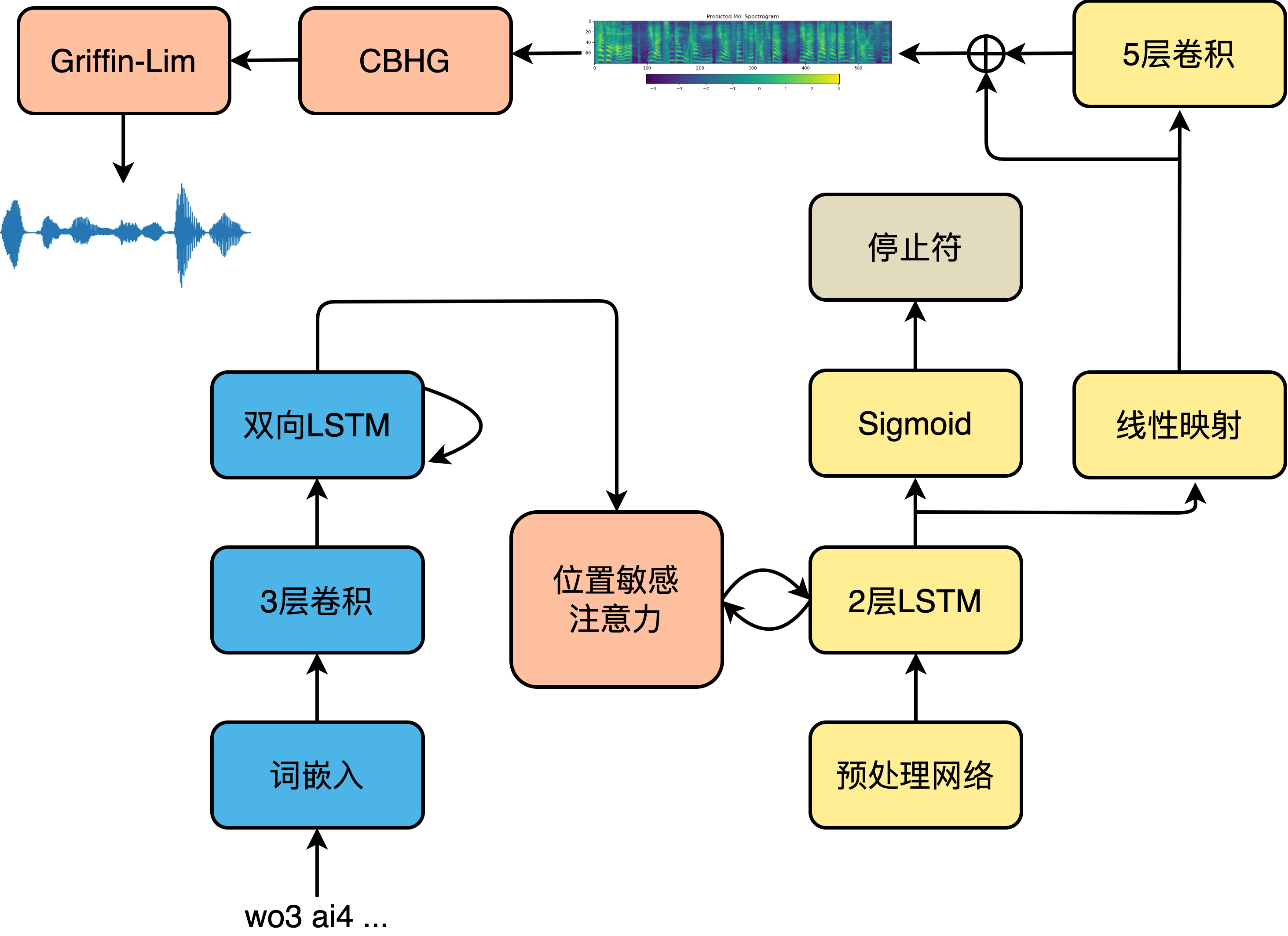

1.1?聲學特征建模網絡
Tacotron-2的聲學模型部分采用典型的序列到序列seq2seq結構。編碼器是3個卷積層和一個雙向LSTM層組成的模塊,卷積層給予了模型類似于N-gram感知上下文的能力,并且對不發音字符更加魯棒。經詞嵌入的注音序列首先進入卷積層提取上下文信息,然后送入雙向LSTM生成編碼器隱狀態。編碼器隱狀態生成后,就會被送入注意力機制,以生成編碼向量。我們利用了一種被稱為位置敏感注意力(Location Sensitive Attention,LSA),該注意力機制的對齊函數為:
其中,?為待訓練參數,
是偏置值,
為上一時間步
的解碼器隱狀態,
為當前時間步
的編碼器隱狀態,
為上一個解碼步的注意力權重
經卷積獲得的位置特征,如下式:
其中, ?是經過softmax的注意力權重的累加和。位置敏感注意力機制不但綜合了內容方面的信息,而且關注了位置特征。解碼過程從輸入上一解碼步或者真實音頻的頻譜進入解碼器預處理網絡開始,到線性映射輸出該時間步上的頻譜幀結束,模型的解碼過程如下圖所示。

頻譜生成網絡的解碼器將預處理網絡的輸出和注意力機制的編碼向量做拼接,然后整體送入LSTM中,LSTM的輸出用來計算新的編碼向量,最后新計算出來的編碼向量與LSTM輸出做拼接,送入映射層以計算輸出。輸出有兩種形式,一種是頻譜幀,另一種是停止符的概率,后者是一個簡單二分類問題,決定解碼過程是否結束。為了能夠有效加速計算,減小內存占用,引入縮減因子r(Reduction Factor),即每一個時間步允許解碼器預測r個頻譜幀進行輸出。解碼完成后,送入后處理網絡處理以生成最終的梅爾頻譜,如下式所示。
其中, 是解碼器輸出,
表示最終輸出的梅爾頻譜,
是后處理網絡的輸出,解碼器的輸出經過后處理網絡之后獲得
?。
在Tacotron-2原始論文中,直接將梅爾頻譜送入聲碼器WaveNet生成最終的時域波形。但是WaveNet計算復雜度過高,幾乎無法實際使用,因此可以使用其它聲碼器,比如Griffin-Lim、HiFiGAN等。
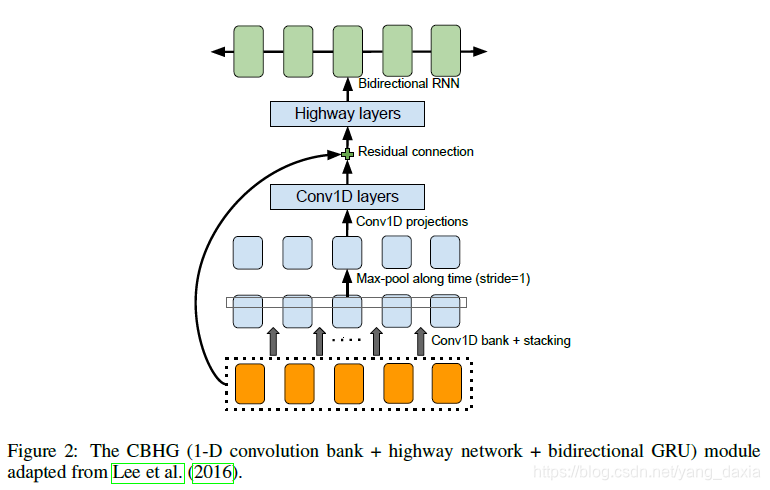
1.2 CBHG 模塊
1.3?損失函數
Tacotron2的損失函數主要包括以下4個方面:
- 1.?進入后處理網絡前后的平方損失。
? 其中, 表示從音頻中提取的真實頻譜,
分別為進入后處理網絡前、后的解碼器輸出,
為每批的樣本數。
- 2.?從CBHG模塊中輸出線性譜的平方損失。
?其中, 是從真實語音中計算獲得的線性譜,
是從CBHG模塊輸出的線性譜。
- 3.?停止符交叉熵
其中, 為停止符真實概率分布,
是解碼器線性映射輸出的預測分布。
- 4.?L2正則化
其中, 為參數總數,
為模型中的參數,這里排除偏置值、RNN以及線性映射中的參數。最終的損失函數為上述4個部分的損失之和,如下式:
2.?FastSpeech
FastSpeech是基于Transformer顯式時長建模的聲學模型,由微軟和浙大提出。
1.?模型結構
FastSpeech 2和上代FastSpeech的編解碼器均是采用FFT(feed-forward Transformer,前饋Transformer)塊。編解碼器的輸入首先進行位置編碼,之后進入FFT塊。FFT塊主要包括多頭注意力模塊和位置前饋網絡,位置前饋網絡可以由若干層Conv1d、LayerNorm和Dropout組成。
論文中提到語音合成是典型的一對多問題,同樣的文本可以合成無數種語音。上一代FastSpeech主要通過目標側使用教師模型的合成頻譜而非真實頻譜,以簡化數據偏差,減少語音中的多樣性,從而降低訓練難度;向模型提供額外的時長信息兩個途徑解決一對多的問題。在語音中,音素時長自不必說,直接影響發音長度和整體韻律;音調則是影響情感和韻律的另一個特征;能量則影響頻譜的幅度,直接影響音頻的音量。在FastSpeech 2中對這三個最重要的語音屬性單獨建模,從而緩解一對多帶來的模型學習目標不確定的問題。

在對時長、基頻和能量單獨建模時,所使用的網絡結構實際是相似的,在論文中稱這種語音屬性建模網絡為變量適配器(Variance Adaptor)。時長預測的輸出也作為基頻和能量預測的輸入。最后,基頻預測和能量預測的輸出,以及依靠時長信息展開的編碼器輸入元素加起來,作為下游網絡的輸入。變量適配器主要是由2層卷積和1層線性映射層組成,每層卷積后加ReLU激活、LayerNorm和Dropout。
同樣是通過長度調節器(Length Regulator),利用時長信息將編碼器輸出長度擴展到頻譜長度。具體實現就是根據duration的具體值,直接上采樣。一個音素時長為2,就將編碼器輸出復制2份,給3就直接復制3份,拼接之后作為最終的輸出。
對于音高和能量的預測,模塊的主干網絡相似,但使用方法有所不同。以音高為例,能量的使用方式相似。首先對預測出的實數域音高值進行分桶,映射為一定范圍內的自然數集,然后做嵌入。
3.?VITS
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一種結合變分推理(variational inference)、標準化流(normalizing flows)和對抗訓練的高表現力語音合成模型。和Tacotron和FastSpeech不同,Tacotron / FastSpeech實際是將字符或音素映射為中間聲學表征,比如梅爾頻譜,然后通過聲碼器將梅爾頻譜還原為波形,而VITS則直接將字符或音素映射為波形,不需要額外的聲碼器重建波形,真正的端到端語音合成模型。VITS通過隱變量而非之前的頻譜串聯語音合成中的聲學模型和聲碼器,在隱變量上進行建模并利用隨機時長預測器,提高了合成語音的多樣性,輸入同樣的文本,能夠合成不同聲調和韻律的語音。VITS合成音質較高,并且可以借鑒之前的FastSpeech,單獨對音高等特征進行建模,以進一步提升合成語音的質量,是一種非常有潛力的語音合成模型。
3.1?模型整體結構
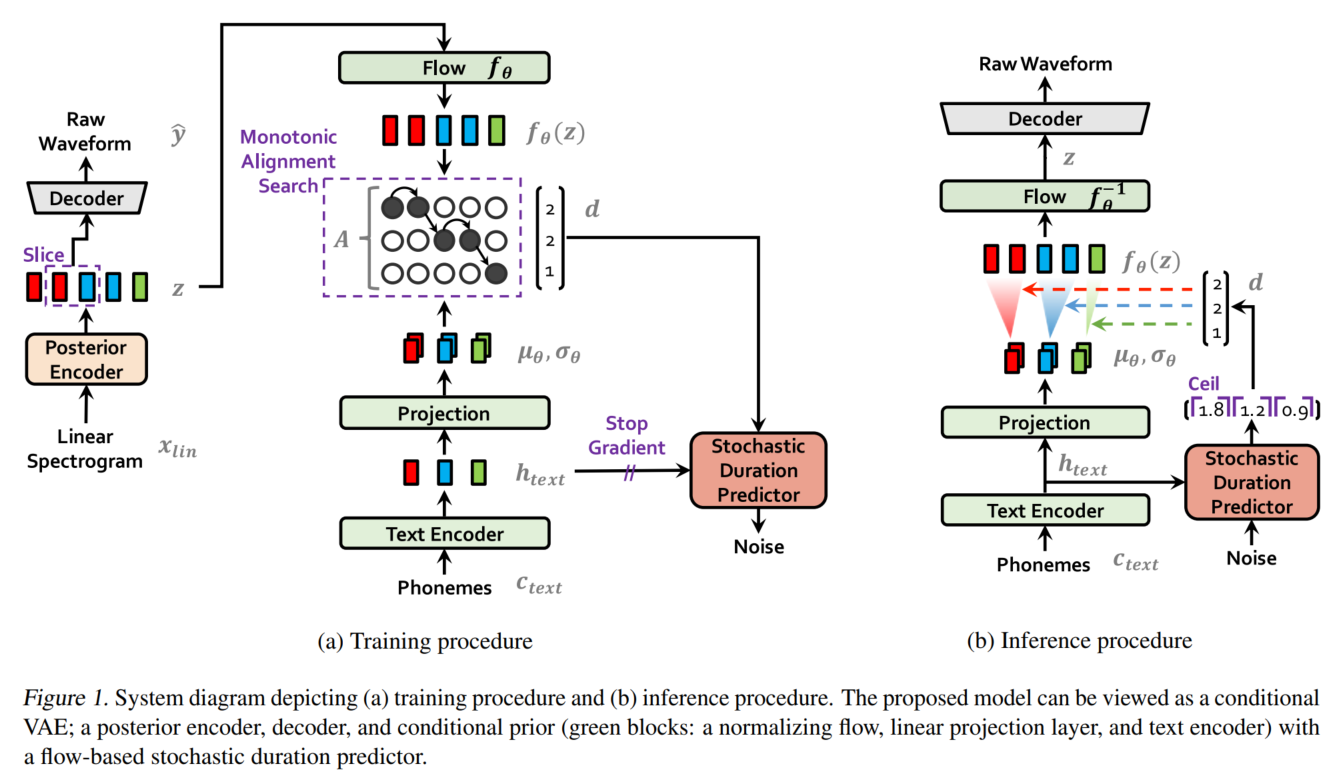
VITS包括三個部分:
- 后驗編碼器(Posterior Encoder)。如上圖(a)的左下部分所示,在訓練時輸入線性譜,輸出隱變量
,推斷時隱變量
產生。VITS的后驗編碼器采用WaveGlow和Glow-TTS中的非因果WaveNet殘差模塊。應用于多人模型時,將說話人嵌入向量添加進殘差模塊,{僅用于訓練}。這里的隱變量
- 解碼器Decoder。如上圖(a)左上部分所示,解碼器從提取的隱變量
- 先驗編碼器。如上圖(a)右側部分所示,先驗編碼器結構比較復雜,作用類似于Tacotron / FastSpeech的聲學模型,只不過VITS是將音素映射為中間表示
- 隨機時長預測器Stochastic Duration Predictor。如上圖(a)右側中間橙色部分。從條件輸入
估算音素時長的分布。應用于多人模型時,在說話人嵌入向量之后添加一個線性層,并將其拼接到文本編碼器的輸出
- 判別器。實際就是HiFi-GAN的多周期判別器,在上圖中未畫出,{僅用于訓練}。目前看來,對于任意語音合成模型,加入判別器輔助都可以顯著提升表現。
3.2?變分推斷
VITS可以看作是一個最大化變分下界,也即ELBO(Evidence Lower Bound)的條件VAE。
?
六、聲碼器(Vocoder)
聲碼器(Vocoder),又稱語音信號分析合成系統,負責對聲音進行分析和合成,主要用于合成人類的語音。聲碼器主要由以下功能:分析Analysis,操縱Manipulation,合成Synthesis
分析過程主要是從一段原始聲音波形中提取聲學特征,比如線性譜、MFCC;操縱過程是指對提取的原始聲學特征進行壓縮等降維處理,使其表征能力進一步提升;合成過程是指將此聲學特征恢復至原始波形。人類發聲機理可以用經典的源-濾波器模型建模,也就是輸入的激勵部分通過線性時不變進行操作,輸出的聲道諧振部分作為合成語音。輸入部分被稱為激勵部分(Source Excitation Part),激勵部分對應肺部氣流與聲帶共同作用形成的激勵,輸出結果被稱為聲道諧振部分(Vocal Tract Resonance Part),對應人類發音結構,而聲道諧振部分對應于聲道的調音部分,對聲音進行調制。
聲碼器的發展可以分為兩個階段,包括用于統計參數語音合成(Statistical Parameteric Speech Synthesis,SPSS)基于信號處理的聲碼器,和基于神經網絡的聲碼器。常用基于信號處理的聲碼器包括Griffin-Lim,STRAIGHT 和 WORLD。早期神經聲碼器包括WaveNet、WaveRNN等,近年來神經聲碼器發展迅速,涌現出包括MelGAN、HiFiGAN、LPCNet、NHV等優秀的工作。
1.?Griffin-Lim聲碼器
?
Probabilistic formulation
重要的TTS范式。WaveNet 最早是作為文本到波形模型(text-to-waveform)推出的(因此結合了聲學模型(acoustic model)和聲碼器(vocoding)),可根據附加信息進行局部和全局調節;后來它被擴展為從輸入頻譜圖(spectrograms)合成波形,從而淪為傳統聲碼器的角色。GAN 通常用于將頻譜圖映射為波形(有效地充當聲碼器(vocoders)),或從隨機輸入中 "想象 "波形,因此包含了 TTS 管道的所有中間步驟以及決定輸出何種文本的機制。Tacotron 利用 seq2seq 模型來學習音素/字符(phonemes/characters)到音頻特征的映射,從而隱含地將文本分析與聲學模型(acoustic model)結合起來;FastSpeech 在此基礎上進行了迭代,用 Transformers 代替了 RNN。
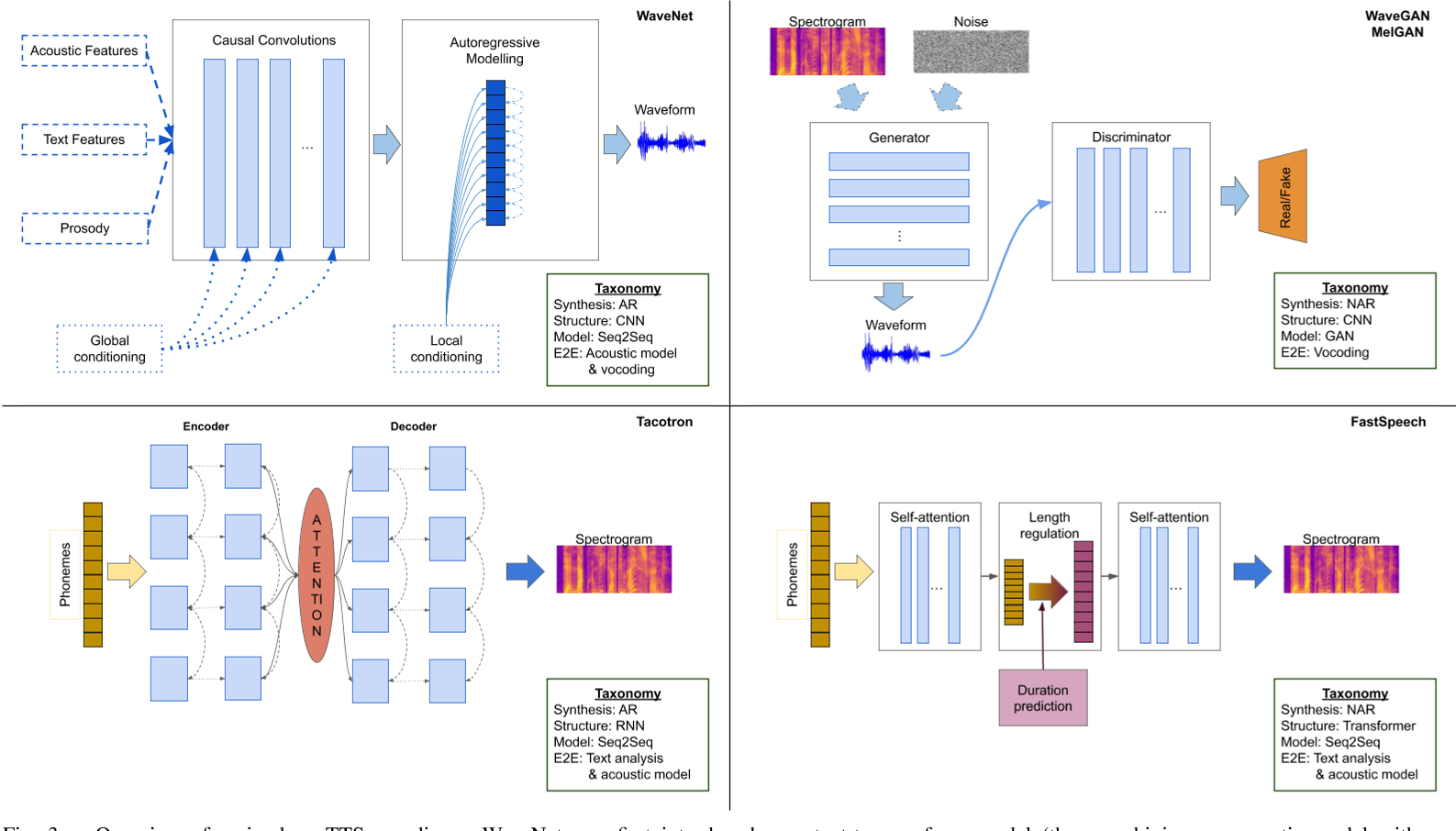
References
中文:Speech Synthesis: Past, Present and Future (2019),ppt
英文:Statistical approach to speech synthesis---past, present, and future(2019)
In Search of the Optimal Acoustic Features for Statistical Parametric Speech Synthesis?
深度學習于語音合成研究綜述-阿里云開發者社區
語音合成到了跳變點?深度神經網絡變革TTS最新研究匯總-騰訊云開發者社區-騰訊云
基于深度學習語音合成技術研究 - 知乎
整合向:
1. 音頻特征 — 張振虎的博客 張振虎 文檔
GitHub - cnlinxi/book-text-to-speech: A book about Text-to-Speech (TTS) in Chinese.

 deta t)

——第106天:Pyecharts繪制多種炫酷桑基圖參數說明+代碼實戰)















