索引
- 前言
- 正式開始
- 磁盤、os、MySQL之間的IO
- MySQL與存儲
- 扇區
- 結論
- 磁盤隨機訪問(Random Access)與連續訪問(Sequential Access)
- MySQL 與磁盤交互基本單位
- 小總結
- 簡單介紹一下內存池
- 談回MySQL
- 簡單理解MySQL中的page
- 為何IO交互基本單位是page
- page結構
- 頁目錄
- 單個page的頁目錄
- 多個page的頁目錄
- 內存池中的B+樹
- MyISAM存儲方式
- 聚簇索引和非聚簇索引
- 表中索引相關的操作
- 主鍵索引的操作
- 唯一索引(唯一鍵列)
- 普通索引
- 談回InnoDB和MyISAM
- InnoDB的多個索引
- MyISAM的多個索引
- 查詢索引
- 索引創建原則
- 全文索引
前言
索引是和效率掛鉤的,它的價值在于提高海量數據的檢索速度。
先來看看效率有多高。
我這里創建一個有800萬條記錄的表(只有數據足夠大才能體現出索引有多快,不用看下面的sql,只要知道是一個搞很多數據的東西就行):
-- 庫名字
drop database if exists `_index`;
create database if not exists `bit_index` default character set utf8;
use `bit_index`;--構建一個8000000條記錄的數據
--構建的海量表數據需要有差異性,所以使用存儲過程來創建, 拷貝下面代碼就可以了,暫時不用理解
-- 產生隨機字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;--產生隨機數字
delimiter $$
create function rand_num()
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;--創建存儲過程,向雇員表添加海量數據
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;-- 創建一張雇員表,和我前面博客中講的emp表結構一樣。
CREATE TABLE `EMP` ( `empno` int(6) unsigned zerofill NOT NULL COMMENT '雇員編號',`ename` varchar(10) DEFAULT NULL COMMENT '雇員姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇員職位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇員領導編號',`hiredate` datetime DEFAULT NULL COMMENT '雇傭時間',`sal` decimal(7,2) DEFAULT NULL COMMENT '工資月薪',`comm` decimal(7,2) DEFAULT NULL COMMENT '獎金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部門編號'
);-- 執行存儲過程,添加8000000條記錄
call insert_emp(100001, 8000000);
執行下來會獲得EMP表:
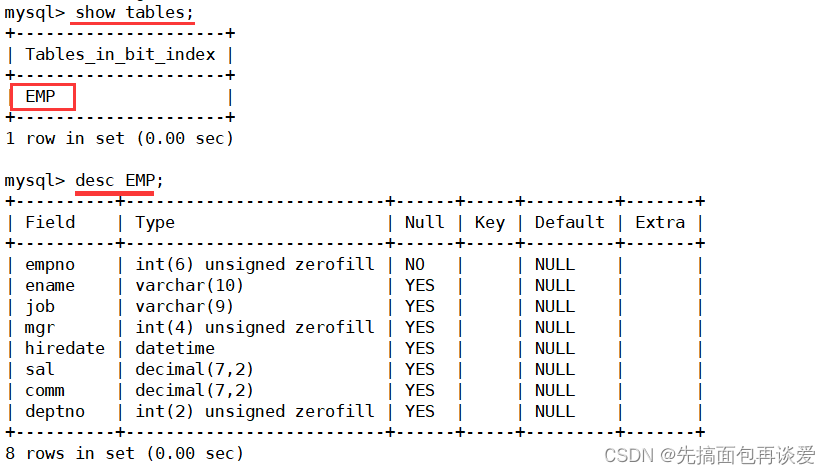
看過我前面博客的同學因該是對于這個表結構很眼熟,這里的EMP就和我前面博客所講過的emp表結構是一樣的。
注意這里表結構中沒有任何的主鍵唯一鍵什么的,這里是為了顯示一下沒有索引時查詢有多慢。等會沒有索引查完之后再加上索引進行查詢,再來看看有多快。
現在里面就有800萬條記錄,我沒法直接進行select *,機器配置不太行可能會直接卡死,不過能顯示一下前幾行:
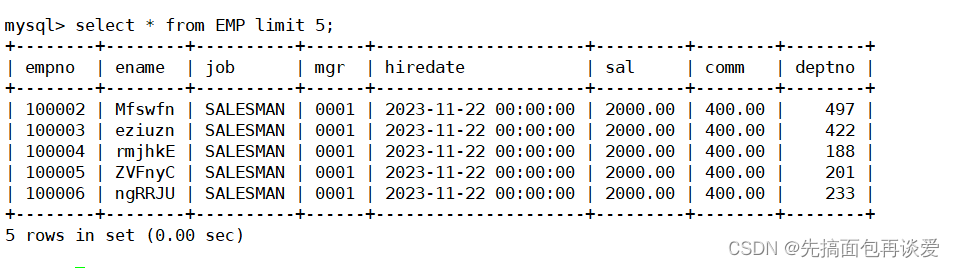
這里顯示了5行,其中ename和deptno都是隨機數據。
我現在來查詢員工編號為898376的員工:

很慢,花了4.3秒,再來幾次:

可以看到穩定在4.1秒,比第一次快了差不多0.2秒。
這樣也太慢了,絕對不能搞成這樣,這還是在本機一個人來操作,在實際項目中,如果放在公網中,假如同時有1000個人并發查詢,那很可能就死機。
那么加上索引來看看會有什么變化,加索引的語法:
alter table 表名 add index(列名);
我現在來給empno加上索引:
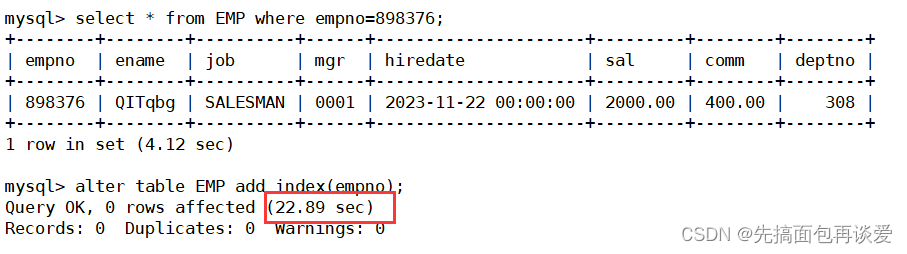
數據有點多,加上索引需要花費的時間還是很多的。等會就來說說為啥。
然后再來查詢:

可以看到清一色的直接干到了0.00s,非常快。
ok,現在已經看到了加不加索引所產生的效果。下面本節課就來講講為什么查詢效率會相差這么多。
正式開始
數據在存儲的時候需要有特定的數據結構,而不同的數據結構查詢的效率是不一樣的。
當然不同的數據結構,都可以進行增刪查改。而這增刪改最重要的一點就是都要先查找,增的時候找位置,刪的時候找數據在哪才能刪,改的時候也是先找到才能改。
比如說你用一個順序表來存儲數據,如果數據沒有序,那查詢就是O(N)的,有點太慢了,如果有序還可以用用二分,能變成O( l o g 2 N log_2N log2?N),這個效率ok。但是順序表刪除和插入不太方便。用鏈表,查詢的時候只能是O(N)了,非常慢,但是鏈表很適合數據插入。用AVL數或者紅黑樹,查的時候為O( l o g 2 N log_2N log2?N)。等等數據結構,不同的數據結構各有各的優勢。
- 數據庫中的數據也是數據,存儲的時候也要有特定的數據結構進行存儲。
為什么加上了索引之后效率會大大提升?
就是因為前后存儲數據的數據結構發生了改變,從而改變了查找的效率。
那么加上了索引前后的數據的存儲結構分別是什么呢?
這個問題先保留,直接說了也無法理解,慢慢來講解。
下面我要一點有關IO效率的問題,涉及到三部分,一部分磁盤,一部分操作系統,一部分mysql本身。
先來簡單說點,mysql啟動了之后在os看來就就是一個用戶層的一個應用進程,在網絡看來就是一個應用層的進程。反正都是應用層的。三者就是這樣:
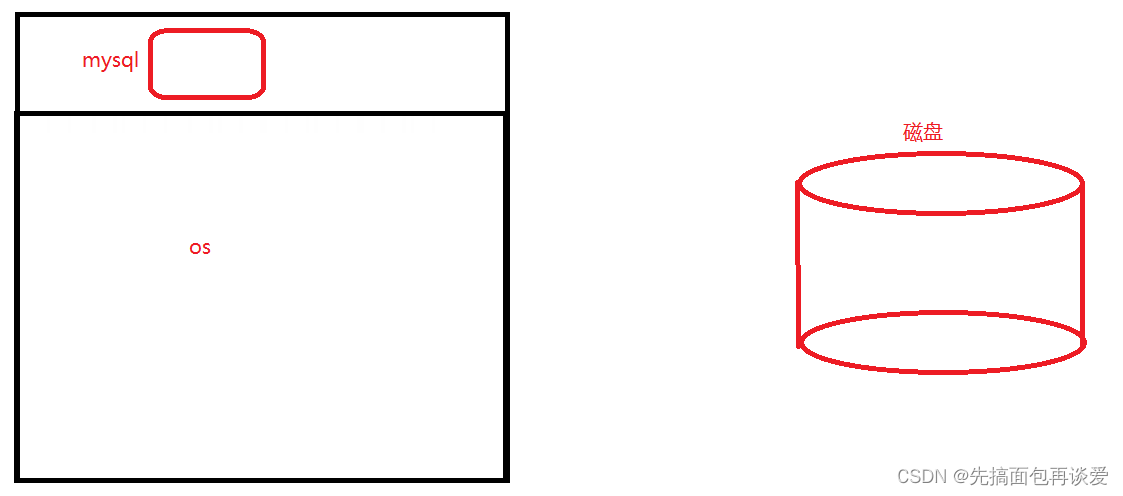
當一個應用層進程想要進行數據IO的時候不是直接和磁盤進行IO的:
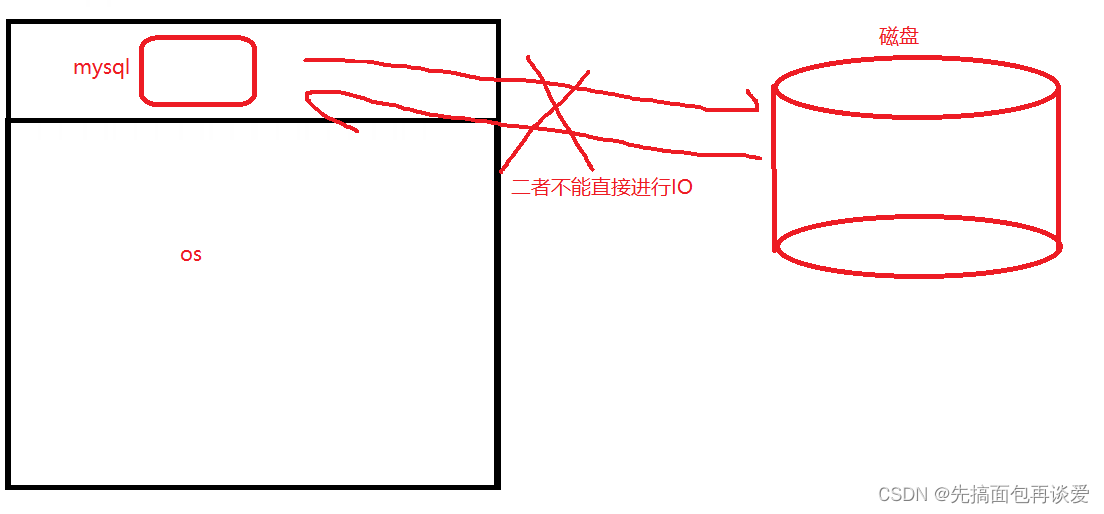
mysql和磁盤交互的數據必須要先經過os:
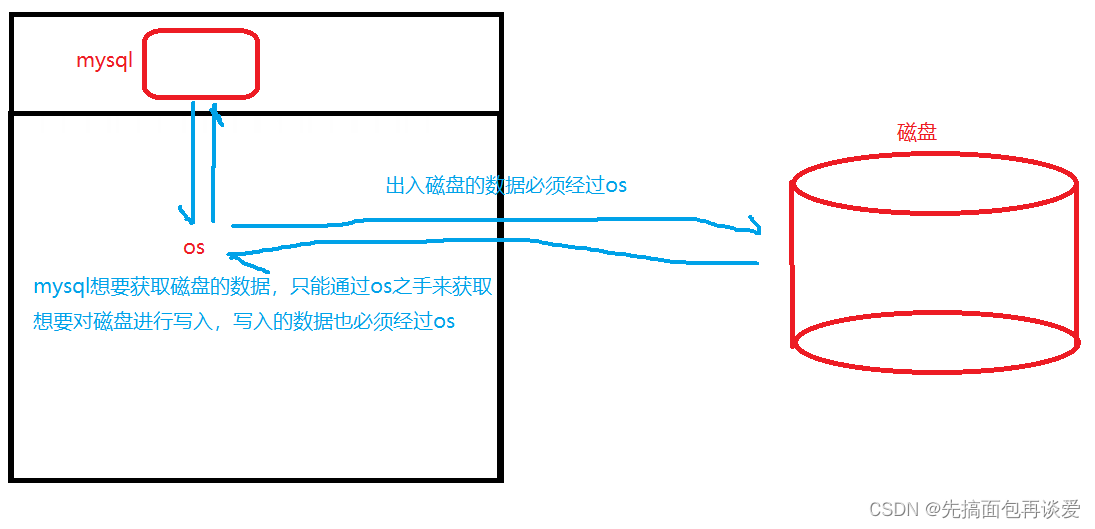
ok,三者關系先介紹到這里,下面來細說說磁盤。
磁盤、os、MySQL之間的IO
為啥要說磁盤呢,因為我們的數據就是直接存放在磁盤上的,得要簡單了解了解磁盤。
其實我前面講基礎文件IO的時候也說過關于磁盤的知識,這里我就簡單講講,如果想要了解的更詳細一點的可以看看我前面這篇博客:【Linux】基礎文件IO、動靜態庫的制作和使用
MySQL與存儲
MySQL 給用戶提供存儲服務,而存儲的都是數據,數據在磁盤這個外設當中。磁盤是計算機中的一個機械設備,相比于計算機其他電子元件,磁盤效率是比較低的,在加上IO本身的特征,可以知道,如何提高效率,是 MySQL 的一個重要話題。
看看完整磁盤長啥樣:

其中有兩個很重要的東西,一個叫磁盤(中間的那個圓片),一個叫磁頭:

再來結合著側面圖來講:
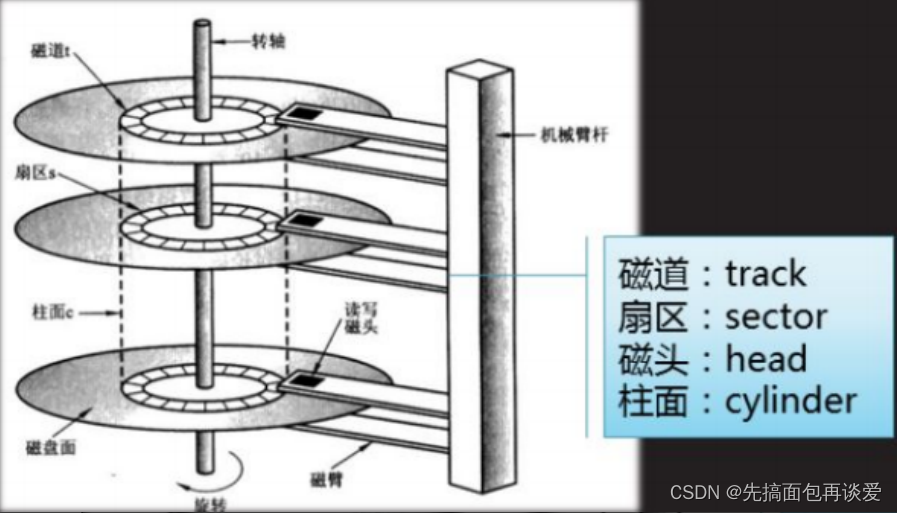
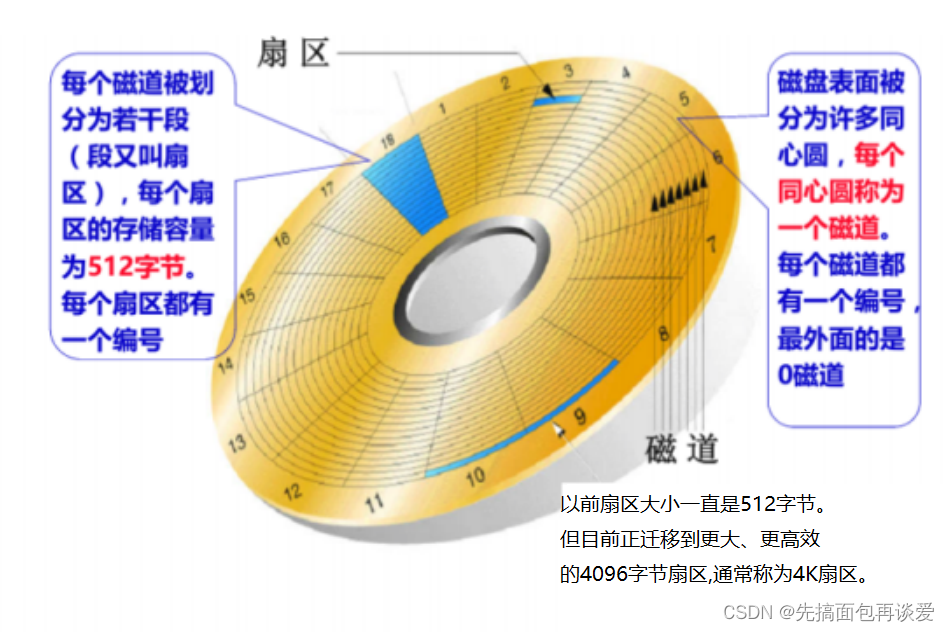
其中磁盤盤片可以分為好幾片這里圖中有3片,每一片又分為兩個面,所以這里就有6個面,我們的數據就存放在每個面上,圖中虛線畫的看起來像圓柱的東西就叫做柱面,每個柱面在盤片上對應位置的東西叫做磁道,磁道會再細分為扇區,每個扇區就是存放數據的基本單元,為512字節。
當有數據進行IO的時候要先進行定位,此時磁頭會進行左右擺動,盤片會進行旋轉,二者一塊配合來定位一個磁道中的某個扇區。
當找到指定位置的扇區之后就能進行IO了。
扇區
數據庫文件,本質其實就是保存在磁盤的盤片當中。也就是上面的一個個小格子中,就是我們經常所說的扇區。當然,數據庫文件很大,也很多,一定需要占據多個扇區。
來看看扇區:
題外話:
從上圖可以看出來,在半徑方向上,距離圓心越近,扇區越小,距離圓心越遠,扇區越大。
那么,所有扇區都是默認512字節嗎?目前是的,我們也這樣認為。因為保證一個扇區多大,是由比特位密度決定的。不過最新的磁盤技術,已經慢慢的讓扇區大小不同了,不過我們現在暫時不考慮。
我們在使用Linux,所看到的大部分目錄或者文件,其實就是保存在硬盤當中的。(當然,有一些內存文件系統,如: proc , sys 之類,我們不考慮)
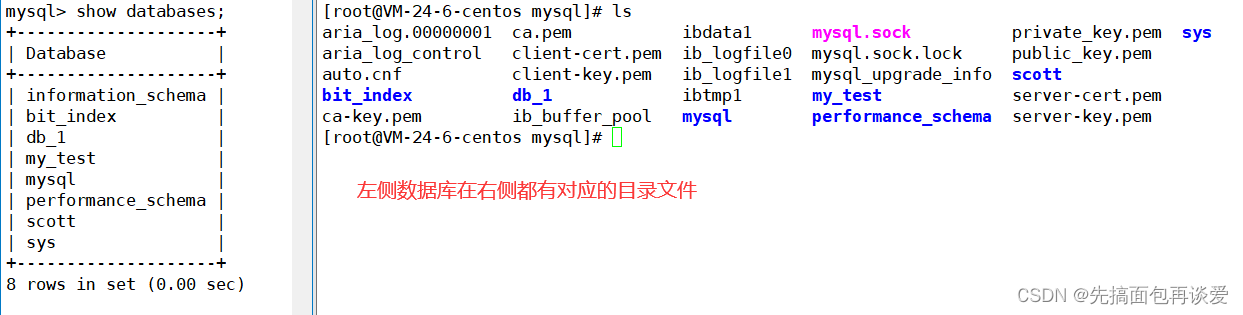
我前面博客中也講過,創建數據庫就是創建一個目錄:
在庫中創建表就是在創建文件:
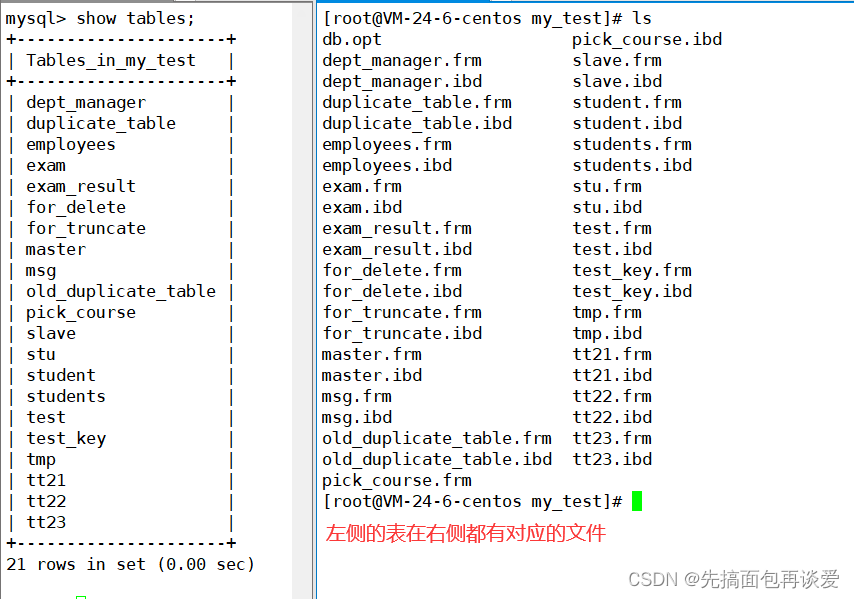
所以,最基本的,找到一個文件的,本質上就是在磁盤找到所有保存文件的扇區。
而我們能夠定位任何一個扇區,那么便能找到所有扇區,因為查找方式是一樣的。
前面說了磁盤和磁頭配合著來就能定位到某個扇區。
每個盤面都有一個磁頭,那么磁頭和盤面的對應關系便是1對1的。
所以,我們只需要知道,磁頭(Heads)、柱面(Cylinder)(等價于磁道)、扇區(Sector)對應的編
號。即可在磁盤上定位所要訪問的扇區。這種磁盤數據定位方式叫做 CHS 。
不過實際系統軟件使用的并不是 CHS (但是硬件是),而是 LBA ,一種線性地址,就是將磁盤中的物理地址抽象化了,將一整個圓轉化成了線性的,線中的每個小塊就是扇區,可以想象成虛擬地址與物理地址間的關系。這個在我剛剛給的那篇博客中有,這里就不細說了,想要了解的同學可以看剛剛給的那篇。
系統將 LBA 地址最后會轉化成為 CHS ,交給磁盤去進行數據讀取。不過,現在不用關心轉化細節,了解依稀這個東西,讓我們邏輯自洽起來即可。
結論
我們現在已經能夠在硬件層面定位,任何一個基本數據塊了(扇區)。那么在系統軟件上,就直接按照扇區(512字節,部分4096字節),進行IO交互嗎?
不是。
如果操作系統直接使用硬件提供的數據大小進行交互,那么系統的IO代碼,就和硬件強相關,換言
之,如果硬件發生變化,系統必須跟著變化。
從目前來看,單次IO 512字節,還是太小了。IO單位小,意味著讀取同樣的數據內容,需要進行多
次磁盤訪問,會帶來效率的降低。
之前學習文件系統,就是在磁盤的基本結構下建立的,文件系統讀取基本單位,就不是扇區,而是
數據塊。而一個數據塊的大小為4KB。
我前面講頁表的時候說過頁框和頁幀的問題,就是內存和磁盤數據交互的基本單位,也就是4KB,想要了解的同學看看這篇:【Linux】頁表講解(一級、二級) 和 vm_area_struct ## 對于我前面博客內容的補充。
磁盤隨機訪問(Random Access)與連續訪問(Sequential Access)
隨機訪問:本次IO所給出的扇區地址和上次IO給出扇區地址不連續,這樣的話磁頭在兩次IO操作之間需要作比較大的移動動作才能重新開始讀/寫數據。
連續訪問:如果當次IO給出的扇區地址與上次IO結束的扇區地址是連續的,那磁頭就能很快的開始這次IO操作,這樣的多個IO操作稱為連續訪問。
如果你沒看懂的話,請看圖:

假如說圖中一格為一個扇區,不同行就代表不同的磁道,那么如果說前后兩次的IO的扇區位置是這樣的:
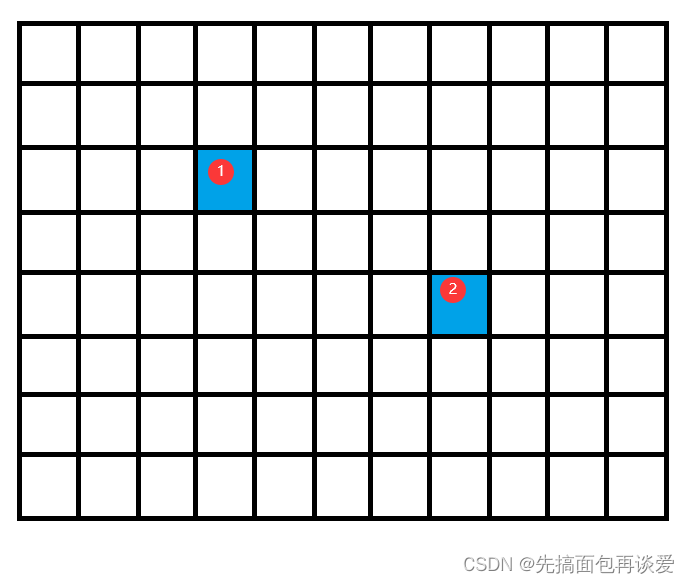
這里就是兩個不連續的扇區,不再同一個磁道,當然不連續,那么兩次IO都會需要在定位上花時間。
但是如果兩次IO的位置是連續的:
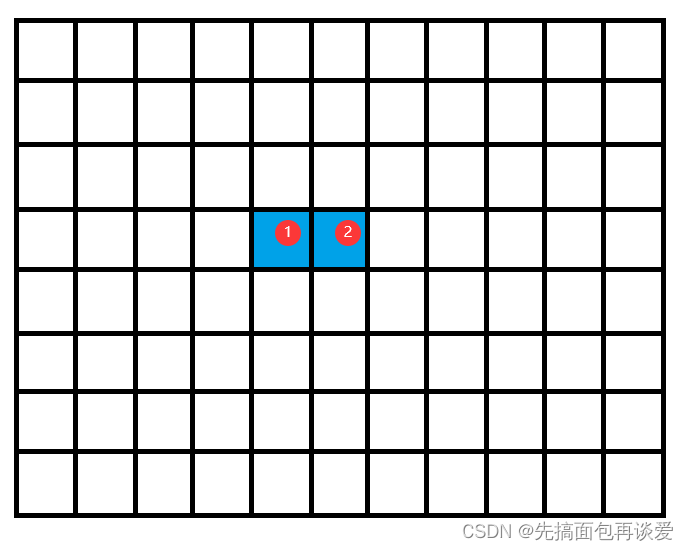
這樣第二次IO的時候就不需要再次重新定位扇區的位置, IO的效率就會比不連續的高一點。
因此盡管相鄰的兩次IO操作在同一時刻發出,但如果它們的請求的扇區地址相差很大的話也只能稱為隨機訪問,而非連續訪問。
磁盤是通過機械運動進行尋址的,也就是磁盤的旋轉和磁頭的擺動,連續訪問不需要過多的定位,故效率比較高。
MySQL 與磁盤交互基本單位
MySQL 作為一款應用軟件,可以想象成一種特殊的文件系統。它有著更高的IO場景,所以,為了提高基本的IO效率, MySQL 進行IO的基本單位是 16KB。 (后面統一使用 InnoDB存儲引擎講解,不同存儲引擎IO的基本單位會不同,InnoDB引擎使用16KB進行IO交互)
前面說系統IO的基本單位是4KB,而MySQL和磁盤IO的數據必須要經過os,那么如果是MySQL進行讀取,系統就會對磁盤連續讀取4次,從而組成16KB,再交付給MySQL:
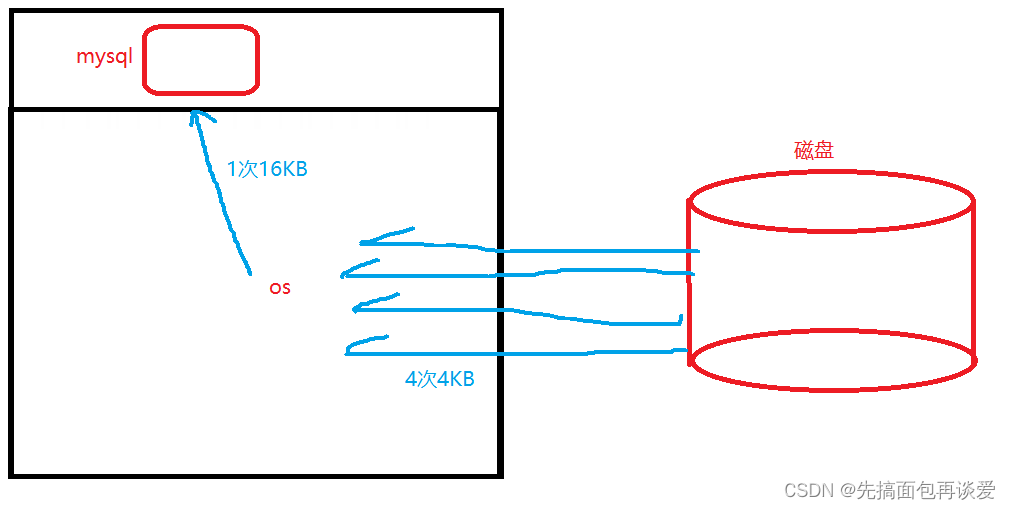
一個扇區的大小為512字節,因為局部性原理(就是加載的的指令附近指令很有可能最近還會被執行),一次多加載一點后續效率能高一點。所以系統選擇用4KB作為IO的基本單位,這里的4KB可以被稱作是一頁(page)。
MySQL中需要進行很多IO,為了更高的效率,所以將其IO的基本單位設定為了16KB。這里的16KB也可看作是一頁(page)。
磁盤中的一個扇區大小為512字節,4KB的頁為系統IO的基本單位,16KB的一頁為MySQL進行IO的一頁,兩個頁不是一個東西。
我們可以查看MySQL中一頁的大小:
SHOW GLOBAL STATUS LIKE 'innodb_page_size';
結果如下:

這里顯示出來的16384指的是字節,來算一算,除以1024:
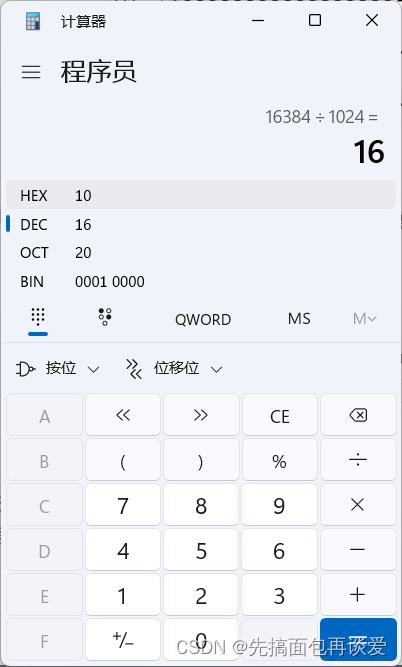
字節除以1024,單位就是KB,這里也就是16KB,那么就是用InnoDB存儲引擎時MySQL進行IO的基本單位。
也就是說,磁盤這個硬件設備的基本單位是 512 字節,而 MySQL InnoDB引擎使用 16KB 進行IO交互。即, MySQL 和磁盤(中間要經過os)進行數據交互的基本單位是 16KB 。這個基本數據單元,在 MySQL 這里叫做page(注意和系統的page區分)。
小總結
-
MySQL 中的數據文件,是以page為單位保存在磁盤當中的(IO的單位為16KB,這也就決定了每次進行IO的時候都要加載16KB的內容,也就間接決定了MySQL文件的基本單位)。
-
MySQL 的 CURD(我前面博客講的MySQL的增(create)刪(delete)查(retrieve)改(update),四者首字母對應CURD) 操作,都需要通過計算來找到對應的插入位置,或者找到對應要修改或者查詢的數據。
-
而只要涉及計算,就需要CPU參與,而為了便于CPU參與,一定要能夠先將數據移動到內存當中。
-
所以在特定時間內,數據一定是磁盤中有,內存中也有。后續操作完內存數據之后,以特定的刷新策略,刷新到磁盤。而這時,就涉及到磁盤和內存的數據交互,也就是IO了。而此時IO的基本單位就是Page。
-
為了更好的進行上面的操作, MySQL 服務器在內存中運行的時候,在服務器內部,就申請了被稱為 Buffer Pool 的的大內存空間,來進行各種緩存。其實就是很大的內存空間,來和磁盤數據進行IO交互。其實就是內存池,等會來討論這個話題。
-
為了更高的效率,一定要盡可能的減少系統和磁盤IO的次數,因為系統與磁盤IO的次數越多,磁盤就要進行越多的定位。假如有40KB的數據,以4KB為基本單位,那么就是進行10次IO,如果10次連續搞完,那就是連續定位,不需要多次定位扇區的位置,但如果分10次搞完,那么中間可能會還要重新定位扇區,相比而言,肯定是前者效率更高。
簡單介紹一下內存池
這里只是簡單說一下內存池是干啥的,等會再說MySQL中的內存池更詳細的作用。
為了效率更高一點,MySQL中也搞了內存池,我前面沒有寫過關于內存池的博客,這里簡單介紹一下功能是啥。
就拿喝水來舉例子,假如你有一個杯子,每次喝水時必須要用這個杯子來喝水,但是接水的地方離你有點遠,你不想每次喝水的時候都要拿著杯子去接水,于是你為了圖個方便,買了個水壺,每次接水的時候就把水壺灌滿,喝水的時候用用水壺往你的杯子里面倒一點,等喝完的時候再去接水的地方把水壺灌滿。
其實內存池原理就和這個差不多,圖個方便。每次用數據的時候不是向磁盤中要16KB用一用就完了,而是要很多個16KB放到一塊,等這很多個16KB都用完了就再向磁盤要,同時把其中的一些修改后且不需要的數據返回給磁盤。這樣與磁盤IO的次數就會減少效率就能高一點。
所以內存池也是為了效率而搞的。根據名字中的池就能理解,就像一個蓄水池一樣,用水的時候從蓄水池中拿,而不是跑大老遠拿一點再回來。
MySQL是用C/C++寫的,內存池就是用new提前開出來的一大塊空間,我們可以在配置文件(my.cnf,在/etc下)中看到這個內存池有多大:
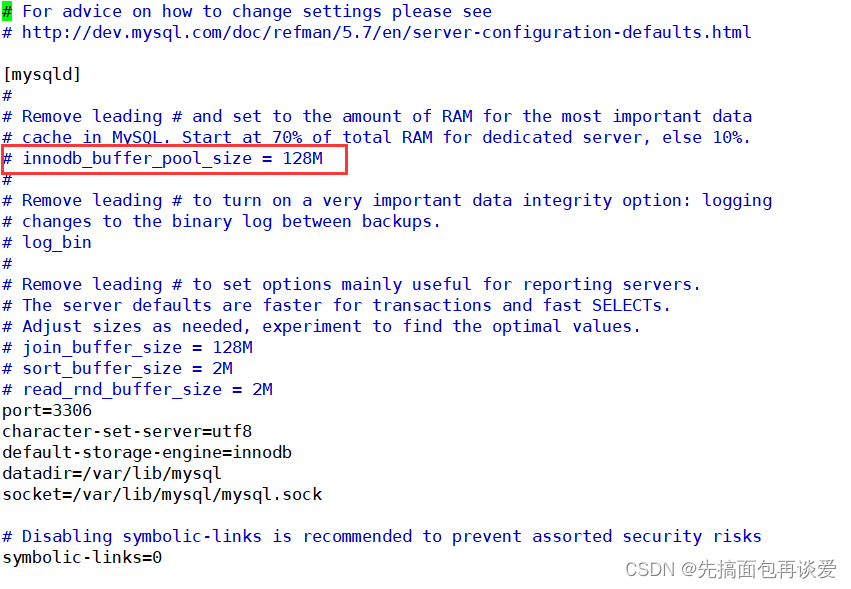
可以看到InnoDB的內存池為128MB。不過這里注釋掉了,就算沒有注釋默認也是有的,而且默認的大小就是128MB。我們把注釋去掉之后能自己改這里內存池的大小,不過我這里就不搞了。
128有多少個KB呢?
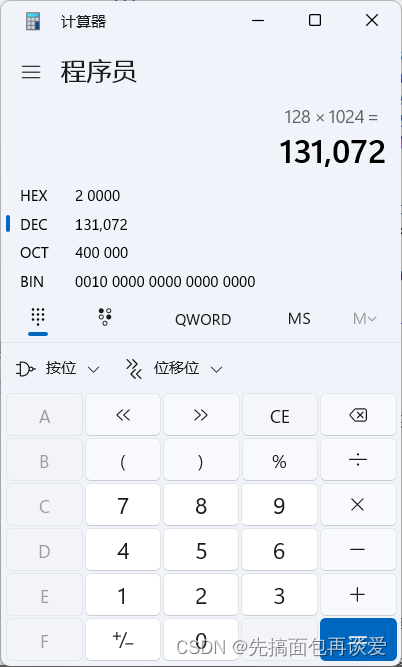
這么多個。這么多KB能有多少個16KB呢?
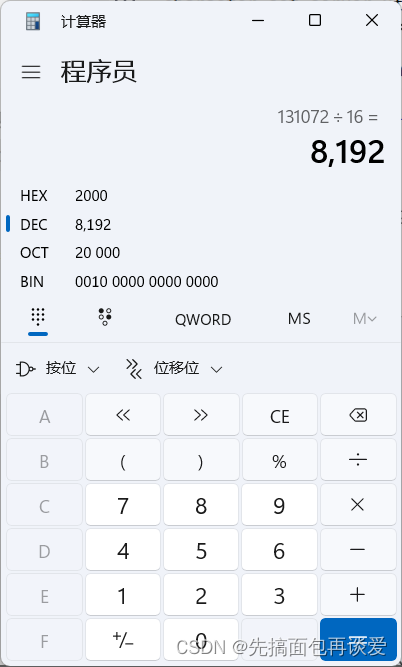
注意,這里只是簡單地計算了內存池中可以容納的頁數,實際使用中可能受到其他因素的影響,例如操作系統的內存管理、服務器的硬件配置等。
所以128MB的內存池,能存放好幾千個page以用來進行讀寫。
談回MySQL
到這里要確定三點:
- MySQL以16KB為基本單位進行MySQL級別的IO的。
- MySQL讀取的時候會將數據先放到buffer pool中,寫的時候也是將buffer pool中的數據交給系統,系統再將數據交給磁盤。
- IO時要盡量減少系統和磁盤IO的次數,一次IO數據越大,IO的次數越少,效率就會更高一點。
來搞一張表:

show 一下:
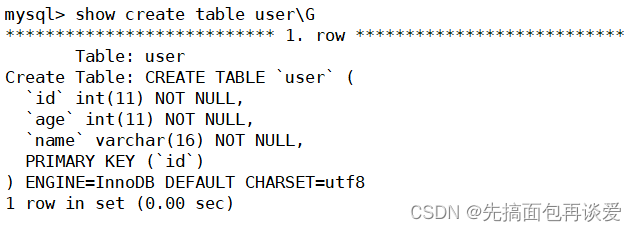
其中id為主鍵,我們來插入點數據:
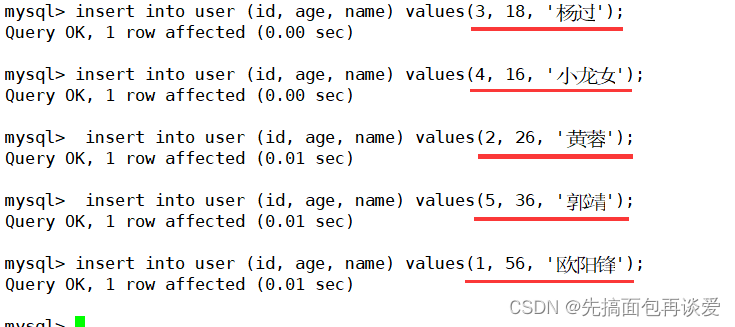
注意我是按照id無序的方式插入的。
select:

這里查出來的結果卻是有序的。
為啥?
這個問題也是暫時先擱置,后面再說。
如果沒有主鍵,那存放的時候是按什么順序的查看的就是按照什么順序的。
簡單理解MySQL中的page
如何理解MySQL中的一個page呢?
剛剛說了MySQL中的page為MySQLIO的基本單位,為16KB。
剛剛還說了MySQL中有一個內存池,為了效率,這個內存池中會存放很多的16KB,剛剛也說了其中至少能放好幾千個page,那么這么多page,MySQL自身也是需要把這些page管理起來的。
怎么管理呢?
還是先描述,再組織(這個我前面博客中一直在說)。和os管理很多東西一樣。給第一次聽到先描述再組織的同學解釋一下。
先描述,就是用一個結構體(或者類)來將一個抽象的物體具象化,比如說這里的page,大小為16KB,那么就實現一個大小為16KB的結構體就行。
再組織,就是用某種特定的數據結構將這些結構體組織起來,就比如說鏈表。
假如說MySQL中用的是鏈表(實際上并不是)來組織所有的page的,那么page結構體就可以是這樣:

假如說上面的這個page有16KB,其中的buff就是用來存放多條記錄的。
這個在內存池中的體現就是會new很多這樣的結構體,有前后指針,這樣每個page就能串起來了,這樣在buffer pool內部就對page進行了建模。
為何IO交互基本單位是page
其實前面也比較含蓄的說過了。
為何MySQL和磁盤進行IO交互的時候,要采用Page的方案進行交互呢?用多少加載多少不香嗎?
如上面剛插入的5條記錄,如果MySQL要查找id=2的記錄,第一次加載id=1,第二次加載id=2,一次一條記錄,那么就需要2次IO。如果要找id=5,那么就需要5次IO。
但,如果這5條(或者更多)都被保存在一個Page中(16KB,更準確的是剛剛圖中page的buff能保存很多記錄),那么第一次IO查找id=2的時候,整個Page會被加載到MySQL的Buffer Pool中,這里完成了一次IO。但是往后如果在查找id=1,3,4,5等,完全不需要進行IO了,而是直接在內存中進行了。所以,就在單Page里面,大大減少了IO的次數。效率就提高了。
你怎么保證,用戶一定下次找的數據,就在這個Page里面?我們不能嚴格保證,但是有很大概率,因為有局部性原理。
往往IO效率低下的最主要矛盾不是IO單次數據量的大小,而是IO的次數。
page結構
其實為了效率,page保存的數據都是有序且相關的,所以實際并不是我前面圖中的buff,而是這樣:
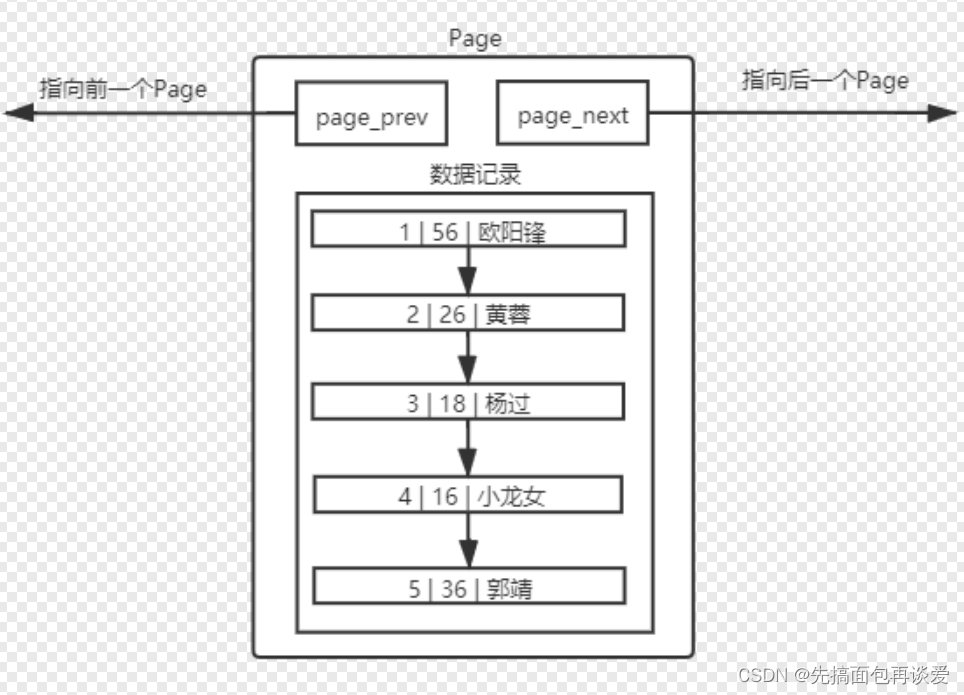
不同的Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 構成雙向鏈表
因為有主鍵, MySQL 會默認按照主鍵給我們的數據進行排序。
為什么數據庫在插入數據時要對其進行排序呢?我們按正常順序插入數據不是也挺好的嗎?
插入數據時排序的目的,就是優化查詢的效率。
頁內部存放數據的模塊,實質上也是一個鏈表的結構,鏈表的特點也就是增刪快,查詢修改慢,所以優化查詢的效率是必須的。
正是因為有序,在查找的時候,從頭到后都是有效查找,沒有任何一個查找是浪費的,而且,如果運氣好,是可以提前結束查找過程的
而這些排序工作都是mysqld(MySQL的服務器)做的,這也就回答了前面的一個遺留問題。
此時page和page之間用鏈式鏈接,page內的各條記錄也是用鏈式鏈接,也就是這樣:
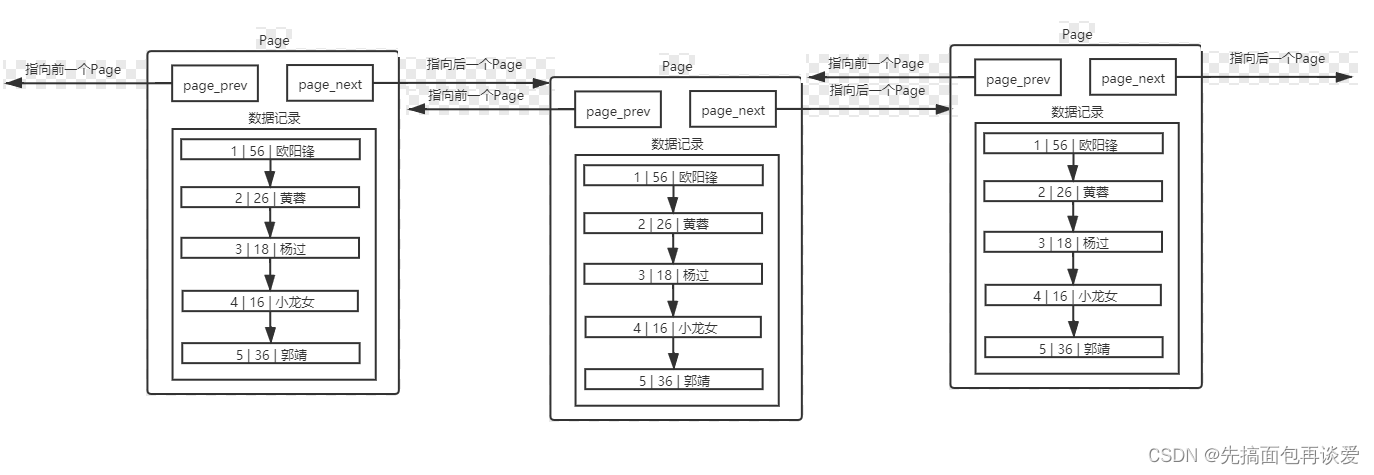
圖太大了看不清,只搞了三個,實際上是可以有很多個的。
這樣在找數據的時候就要在page間和page內進行查找,那么想要提高查找的效率就要考慮兩個方面,一個是在page之間如何提高查找效率,二是在page內部如何提高查找效率。
頁目錄
通過上面的分析,我們知道,上面頁模式中,只有一個功能,就是在查詢某條數據的時候直接將一整頁的數據加載到內存中,以減少硬盤IO次數,從而提高性能。但是,我們也可以看到,現在的頁模式內部,實際上是采用了鏈表的結構,前一條數據指向后一條數據,本質上還是通過數據的逐條比較來取出特定的數據。
如果有1千萬條數據,一定需要多個Page來保存1千萬條數據,多個Page彼此使用雙鏈表鏈接起來,而且每個Page內部的數據也是基于鏈表的。那么,查找特定一條記錄,也一定是線性查找。這效率也太低了。
所以為了提高效率,就搞出來了頁目錄,這里先不說頁目錄是啥,先來說說我們日常生活中的目錄是干啥的。
我們在看一本C語言書籍的時候,如果我們要看<指針章節>,找到該章節有兩種做法
- 從頭逐頁的向后翻,直到找到目標內容
- 通過書提供的目錄,發現指針章節在234頁(假設),那么我們便直接翻到234頁。同時,查找目錄的方案,可以順序找,不過因為目錄肯定少,所以可以快速提高定位
- 本質上,書中的目錄,是多花了紙張的,但是卻提高了效率
- 所以,目錄,是一種“空間換時間的做法”
一本書如果有五百多頁,可能其目錄有十來頁,有了這十來頁我們的查找某一個專題的效率就能大大提高。而設定目錄的前提是書的頁數是有序的。
MySQL中也是采用了同樣的做法。
單個page的頁目錄
剛剛說page中的數據在存儲時是這樣的鏈式結構:
page有16KB,假如說一條記錄有12字節的話,就能存放下:
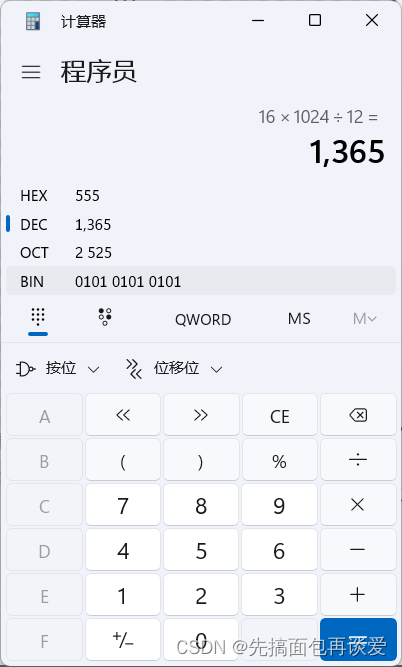
1365條記錄,不過去掉兩個前后指針,假如說8個字節,那就是可以存放1264條記錄,如果這1000多條記錄以O(N)的時間復雜度去查找的話效率就會比較低。
那么可以少保存一點記錄,把這些省下來的空間構建一個頁目錄,就像書本一樣,查找的效率就會高很多:
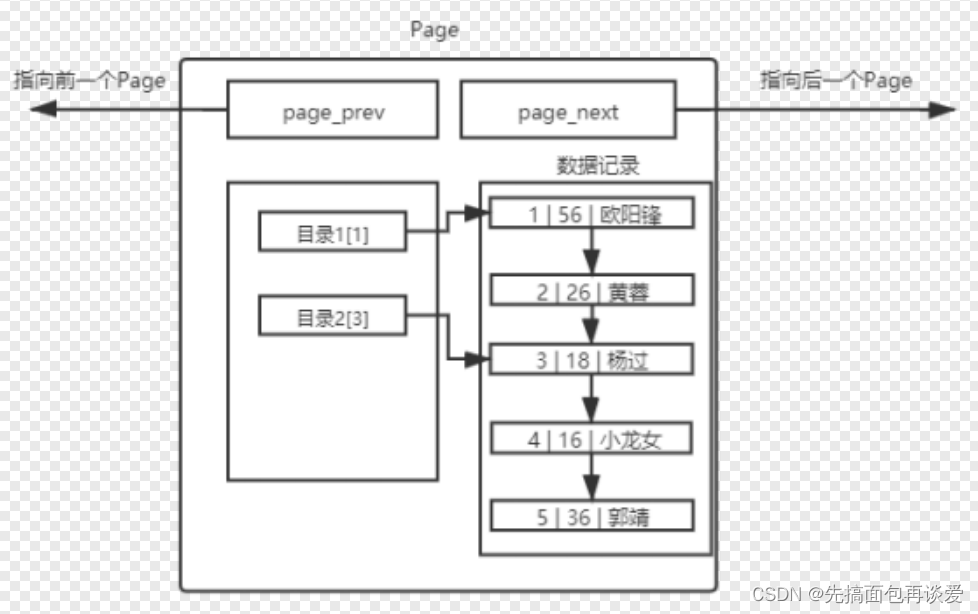
上面目錄1中存放的是1,表示主鍵的1,對應歐陽鋒那條記錄。
目錄2中存放的是3,表示主鍵3,對應楊過那條記錄。
查找的時候就不用再遍歷每個記錄了,而是遍歷目錄,通過目錄來定位到記錄所在的區間。
所以知道為啥排序了吧,主鍵有序可以方便我們引入頁目錄,從而方便查找。
上圖中數據比較少,所以這也感覺不出來快多少,多了才能體現出來。
那么此時多個page連接起來就是這樣:
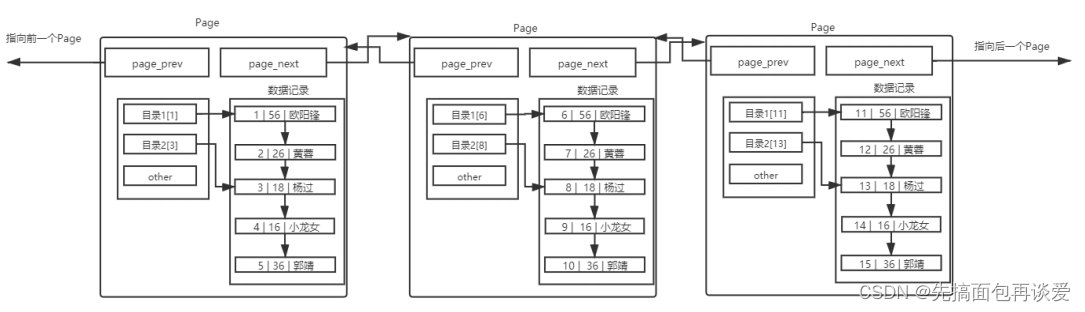
需要注意,上面的圖,是理想結構,大家也知道,目前要保證整體有序,那么新插入的數據,不一定會在新Page上面,這里僅僅做演示。
此時查找的就能快一些。不過page之間的效率還是有點低,因為數據是在某一個page中的,我們這里查找的時候沒法直接定位page,還是得要遍歷一個個page以找到數據所在的page。
如果查找的時候能夠快速定位到想要的page就能大大提高效率。
多個page的頁目錄
MySQL 中每一頁的大小只有 16KB ,單個Page大小固定,所以隨著數據量不斷增大, 16KB 不可能存下所有的數據,那么必定會有多個頁來存儲數據。也就是剛剛這張圖:
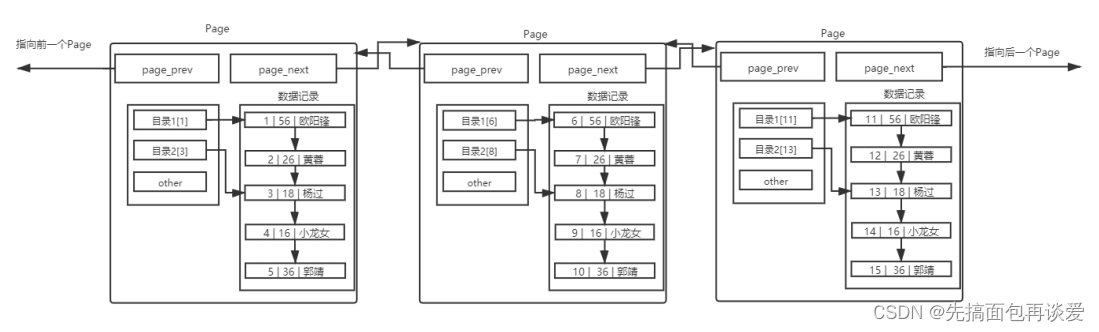
在單表數據不斷被插入的情況下, MySQL 會在容量不足的時候,自動開辟新的Page來保存新的數據,然后通過指針的方式,將所有的Page組織起來。
那么多表間的查詢效率如何提升呢?
解決方案,其實就是我們之前的思路,給Page也帶上目錄。
- 使用一個目錄項來指向某一頁,而這個目錄項存放的就是將要指向的頁中存放的最小數據的鍵值。
- 和頁內目錄不同的地方在于,這種目錄管理的級別是頁,而頁內目錄管理的級別是行。
- 其中,每個目錄項的構成是:鍵值+指針。
看圖:
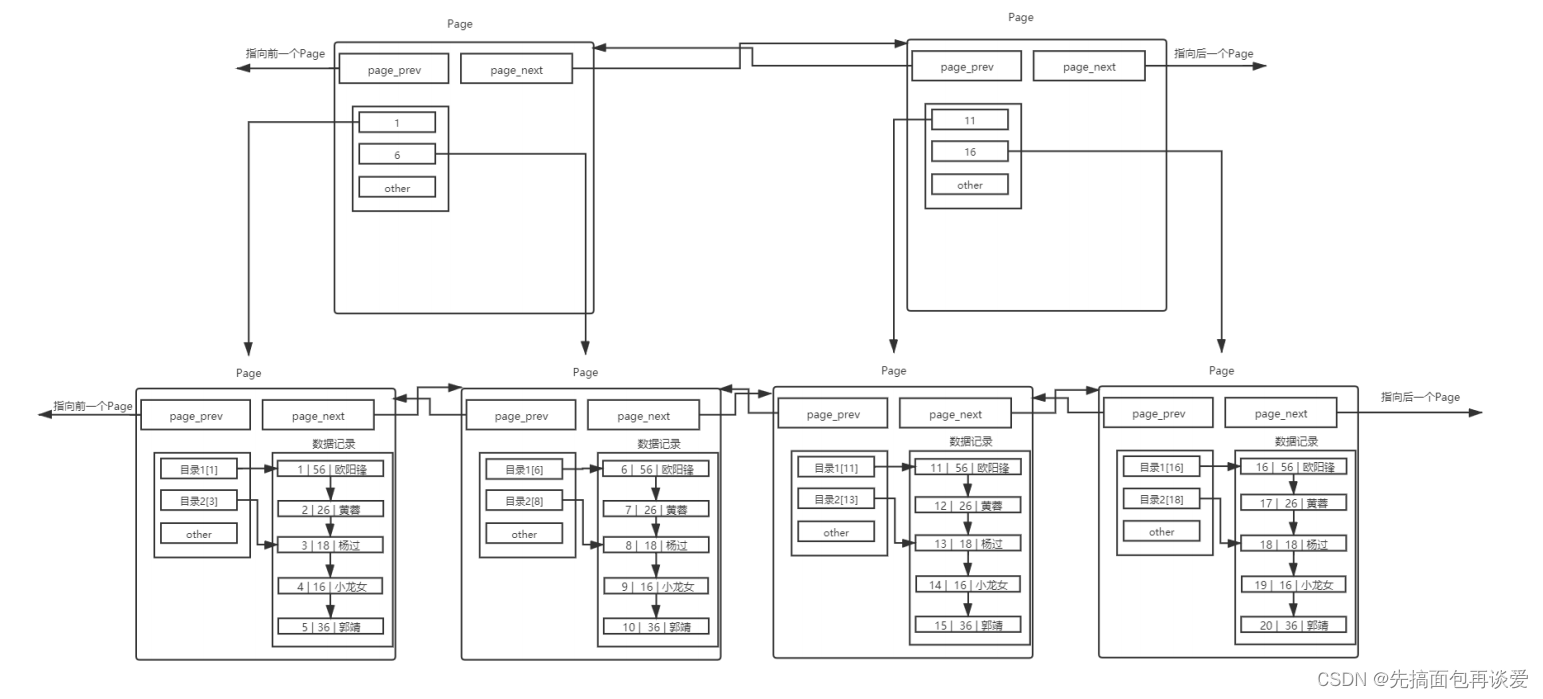
用一個目錄頁來管理頁目錄,目錄頁中的數據存放的就是指向的那一頁中最小的主鍵值和對應page的指針。查找的時候,就可通過比較目錄頁中存放的各,找到該訪問那個Page,此時就可以直接在那個page中找了。
如果有連續的訪問一大段數據,那么就可以先定位一個page,這個page中的數據訪問完之后直接通過prev_next來訪問下一個page,這樣效率就會更高。
同樣的假如說現在是在64位下,一個指針8B,主鍵用的是int,那么目錄頁中一對指針和主鍵就是12B,那么一個目錄頁也就可以存放下來1365個page的地址和對應主鍵,如果是這樣的話一個目錄頁就能管理1265*16KB = 21840KB的數據,也就是21MB的數據,這樣如果是128MB的內存池,就可以有多個目錄頁,那么假如說有6個目錄頁吧,這樣查找的時候還是需要定位一下在哪個目錄頁,又得要遍歷這6個目錄頁中存放的指針—主鍵對,有點慢,想要再快一點就可以再在上層加一個目錄頁來將這個6個目錄頁關聯起來:
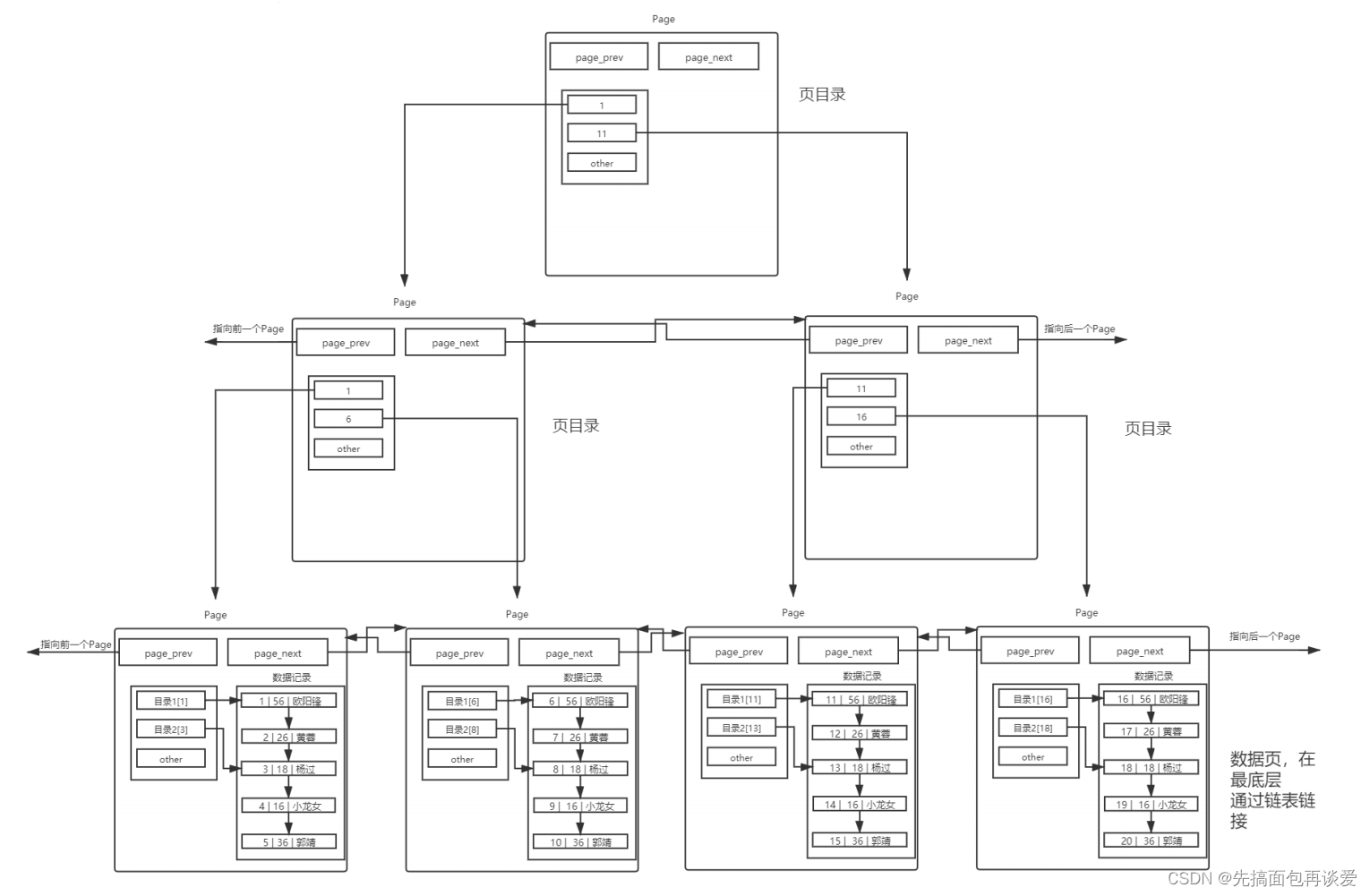
同樣,最頂上的目錄頁存放的是中間目錄頁中最小的主鍵值,這樣每次查找的時候就可以先查找最頂上的目錄頁,找到數據所在的中間層目錄頁,然后再通過中間層目錄頁找到數據記錄所在的page,效率就會大大提升。
如果數據結構比較好的同學應該知道上面圖中就是一顆B+樹,用B+樹來構建索引,這樣每次查找都能排除一大批數據,查找的效率非常高。
內存池中的B+樹
葉子結點保存有數據,非葉子結點不保存數據,只保存主鍵—指針對,這樣非葉子節點就能保存更多的目錄項,目錄頁也就可以管理更多的page,也就意味著這棵樹一定會是一棵矮胖型的樹,這樣查找的時候路上途徑的節點就會減少,所有的節點都是page(也就都是IO的基本單位),也就意味著找到目標數據需要的pageIO更少,也就是IO次數更少,這樣就提高了IO的效率。這一點直接從IO上提高了效率。
剛開始查詢只需要加載根節點page,再往下找的時候找到哪個page再加載對應的page。且每個page都有頁目錄,可以大大提高搜索效率。這一點就從算法上提高了效率。
這整個B+樹結構就被稱為MySQL InnoDB下的索引結構,不過其中非葉子結點是不會像鏈表一樣穿起來的,也就是這樣:
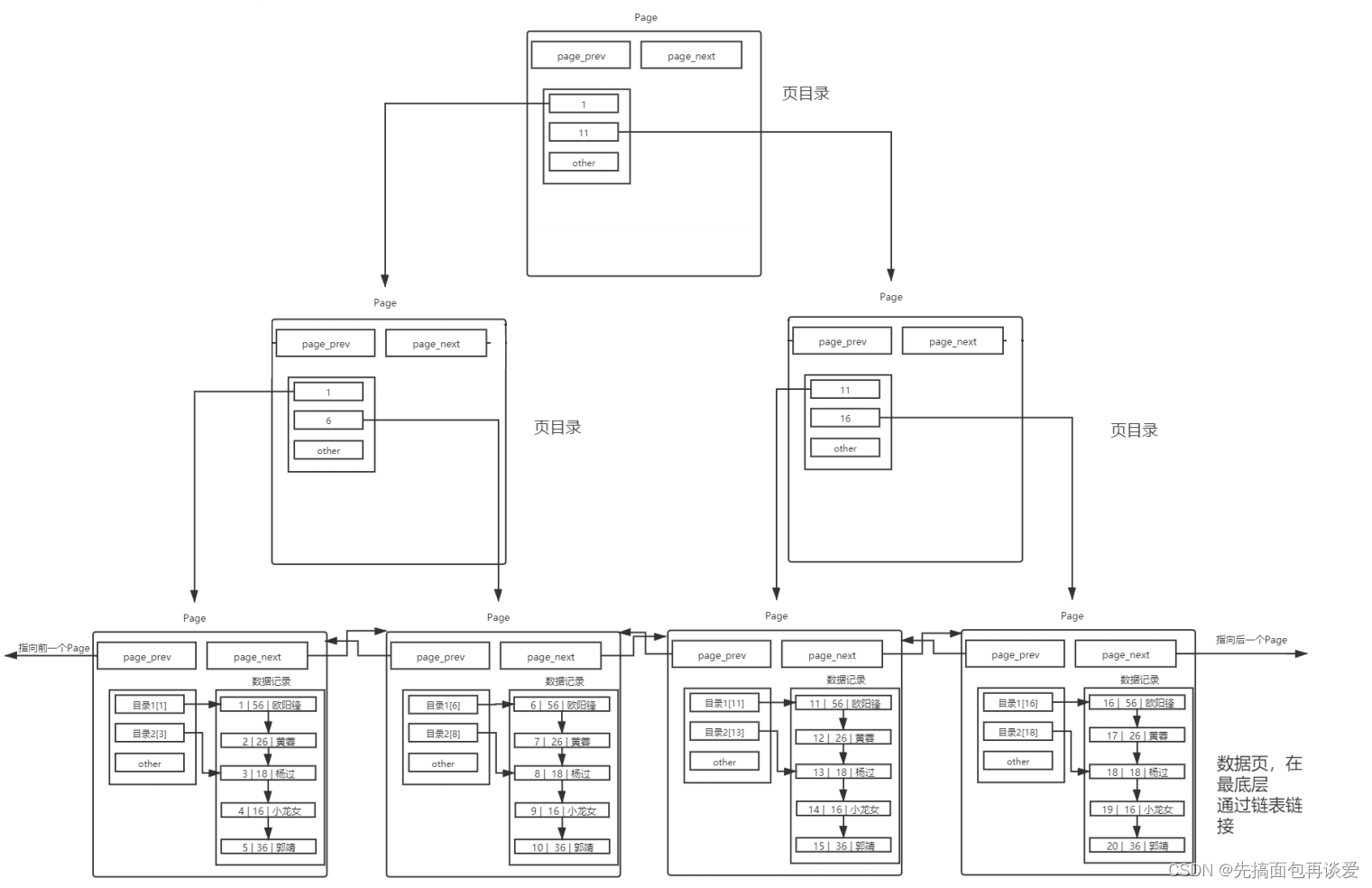
我們建表之后就是在這整個結構上進行CURD操作。
如果沒有手動設置主鍵也會是這樣的結構,后面講事務的博客會細說這一點,現在簡單了解一下,當我們沒有手動設置主鍵的時候,MySQL會自動搞一個隱藏列作為主鍵,我們看不見,而對應B+樹就是按照這個隱藏的主鍵列構建的,前面沒有設置主鍵進行查詢的時候用的都是非索引列進行查找,就會非常慢,因為是在線性遍歷,但是設置了主鍵之后MySQL就會自動按照主鍵列作為索引的值來構建一棵B+樹,而這一整棵B+樹都是放在內存池中的。
一張表對應多棵B+樹(表中可以不光有主鍵,唯一鍵也會有索引,而且普通列也可以通過add添加索引,等會會講),多張表就會有更多的B+樹。
為什么葉子結點要用鏈表連起來?
a. 這是B+樹的特點,而不是MySQL自己實現成這樣的,是MySQL選擇了B+樹。
b. 查找的時候我們比較希望進行范圍查找(當查詢的多條記錄跨page的時候可以快速的定位到下一個page中的數據)。
InnoDB 在建立索引結構來管理數據的時候,其他數據結構為何不行?
- 鏈表?線性遍歷,速度太慢。
- 二叉搜索樹?退化問題,可能退化成為線性結構
- AVL &&紅黑樹?雖然是平衡或者近似平衡,但是畢竟是二叉結構,相比較多階B+,AVL和紅黑的層數太多了,二者肯定是一個瘦高型的樹,查找的時候經過的節點會很多,IO的效率就比B+低。
- Hash?官方的索引實現方式中, MySQL 是支持HASH的,不過 InnoDB 和 MyISAM 并不支持。Hash跟進其算法特征,決定了雖然有時候也很快(O(1)),不過,在面對范圍查找就明顯不行,另外還有其他差別,有興趣可以查一下。
這里有張存儲引擎對應數據結構的圖:
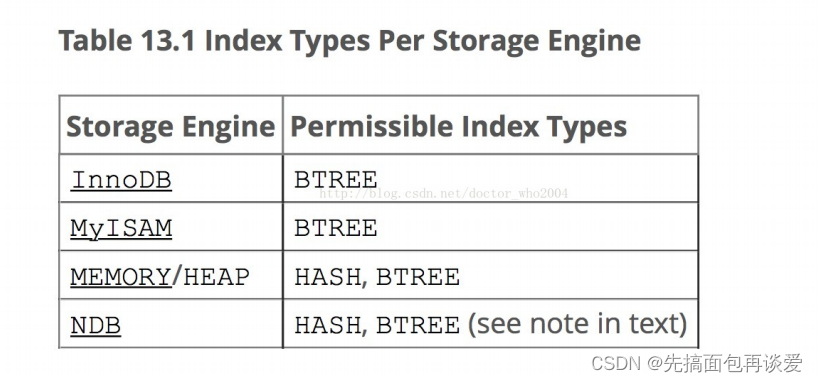
上面的BTREE指的是B+樹,不是B樹。
那為什么不用B樹來存儲數據呢?先來看看B樹的結構:
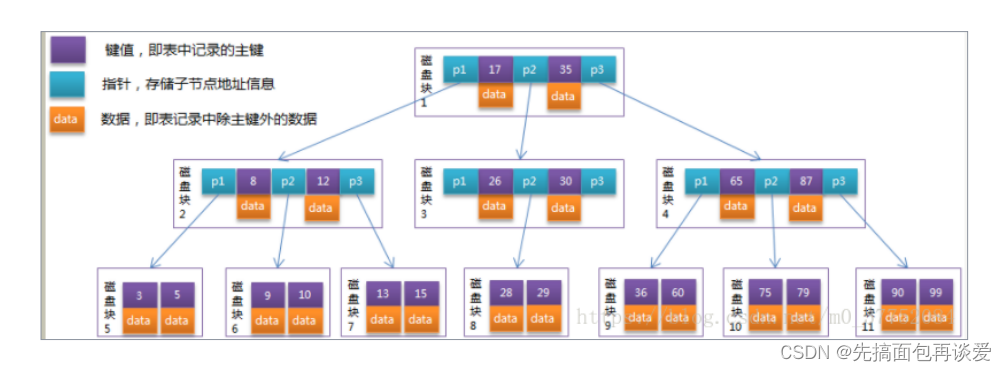
再來看看B+樹的結構:
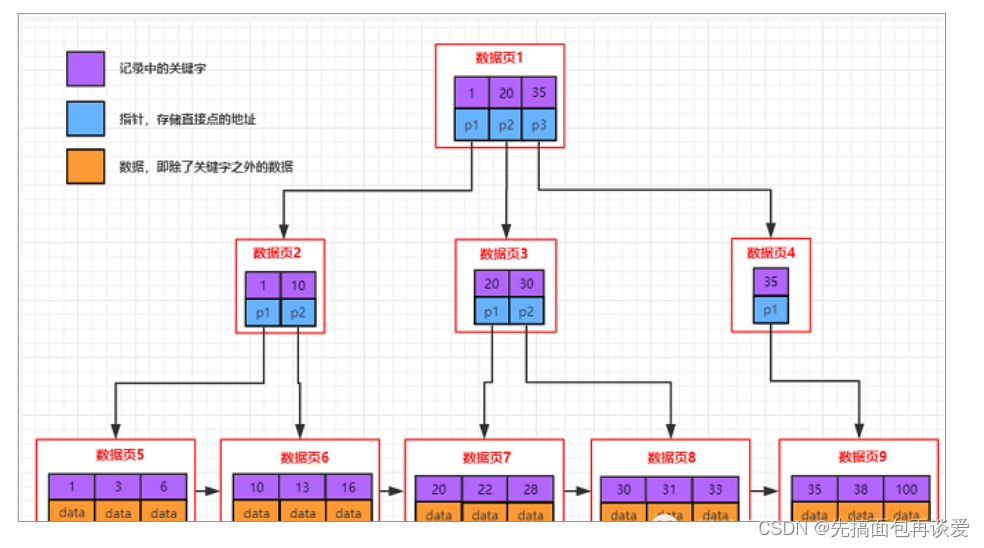
上面的圖,是在網上找的,大家也可以搜一下。
目前這兩棵樹,對我們最有意義的區別是:
- B樹節點,既有數據,又有Page指針,單個目錄頁保存的目錄項變少,相對于B+的高度會更高,就會經過更多次的IO,效率就低一點。而B+,只有葉子節點有數據,其他目錄頁,只有鍵值和Page指針。不過B樹可能提前在飛葉子節點上找到數據。
- B+葉子節點,全部相連,而B沒有,不利于范圍查找。
為何選擇B+?
- 節點不存儲data,這樣一個節點就可以存儲更多的key。可以使得樹更矮,所以IO操作次數更少。葉子節點相連,更便于進行范圍查找。
相對而言B+更好。
有一個網站可以查看不同數據結構動態CURD的過程,感興趣的同學可以看看:
Data Structure Visualizations
進去之后長這樣:

比如其中的B+樹:
可以選擇不同的degree:
上面所講的存儲方式是InnoDB的默認存儲方式,再來簡單說說MyISAM的存儲方式。
MyISAM存儲方式
MyISAM 引擎同樣使用B+樹作為索引結果,葉節點的data域存放的是數據記錄的地址,而不是直接存放數據記錄。下圖為 MyISAM表的主索引, Col1 為主鍵。
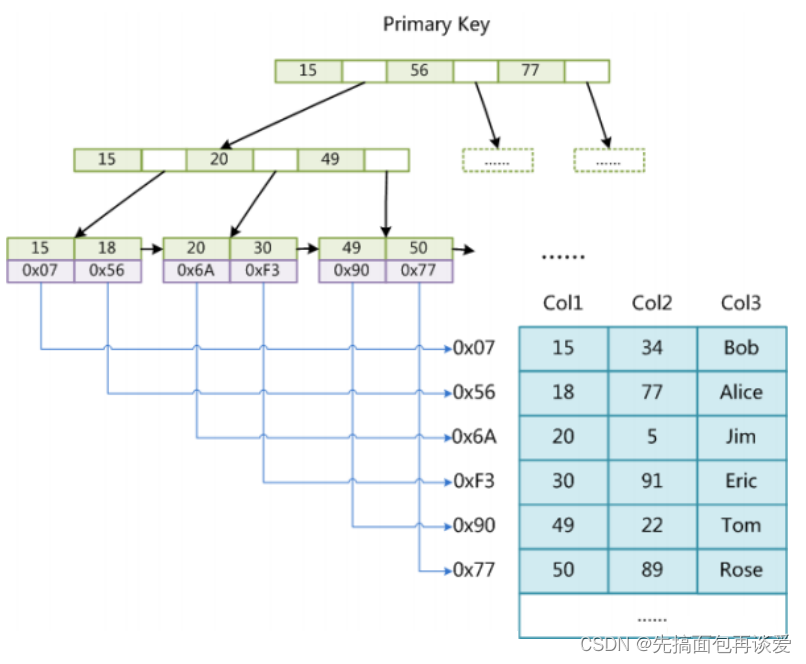
可以看到還是用B+樹來構建索引的,只不過葉子結點存儲的數據不一樣,所有表中的數據記錄是存放在其他地方的,B+樹的葉子結點用來存放每一個數據記錄對應的地址。這樣找的時候過程和InnoDB差不多,只不過是直接找到了數據的地址,然后再通過地址訪問到數據記錄。
所以, MyISAM 最大的特點是,將索引Page和數據Page分離,也就是葉子節點沒有數據,只有對應數據的地址。
相較于 InnoDB 索引, InnoDB 是將索引和數據放在一起的。
前面說了建庫就是建文件,我現在來建一個庫,里面搞兩張表,一張存儲引擎用InnoDB,一張存儲引擎用MyISAM:
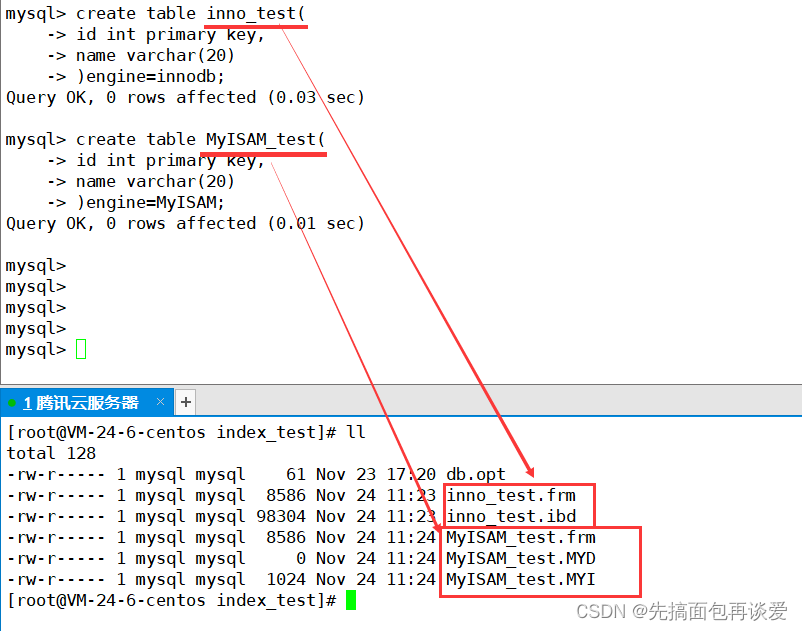
可以看到用InnoDB的有兩個文件,一個.frm,是用來存放表結構的(表結構也是數據,也要進行存放),一個ibd,表示index(索引)block data(數據塊),意思就是索引和數據是存在一起的。
再來看MyISAM,三個文件,一個.frm的存放表結構的文件,一個MYD,表示存放數據的文件,一個MYI,表示存放索引的文件。
存索引就是存放B+樹。
聚簇索引和非聚簇索引
InnoDB 這種用戶數據與索引數據在一起索引方案,叫做聚簇索引
而MyISAM就是非聚簇索引,因為數據和索引不在一塊。
表中索引相關的操作
MySQL 除了默認會建立主鍵索引外,我們用戶也有可能建立按照其他列信息建立的索引,一般這種索引可以叫做輔助(普通)索引。
先來看看主鍵索引,再來說普通索引。
主鍵索引的操作
直接上例子吧,搞一張表:

這張表中有一個主鍵,id即為主鍵列。那么id列最開始就會自動有一個索引,我們可以用下面的語法來查看某個表的索引信息:
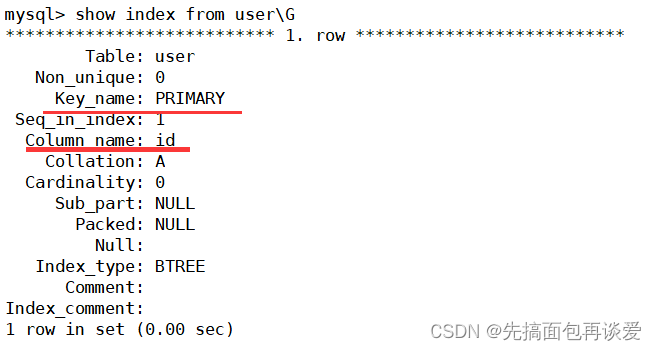
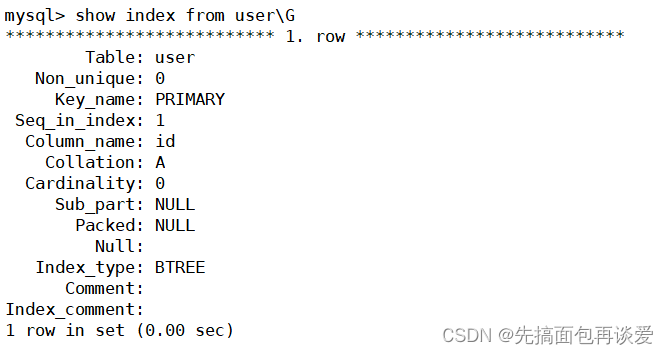
show index from 表名;
比如說這里的user:

Non_unique值為1表示非唯一,即該索引可以包含重復的值;Non_unique值為0表示唯一,即該索引的值必須唯一。
因為當前只有一個主鍵索引,所以只會顯示這一個。在邏輯上創建主鍵的同時會在底層以主鍵為關鍵字創建一個B+樹。
當我把主鍵去掉之后就找不到了:
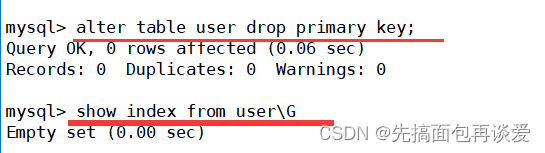
此時用id查找就會很慢。
上面創建表的時候就設置主鍵,是第一種創建主鍵索引的方式。還有一種創建表時設置主鍵的方式:
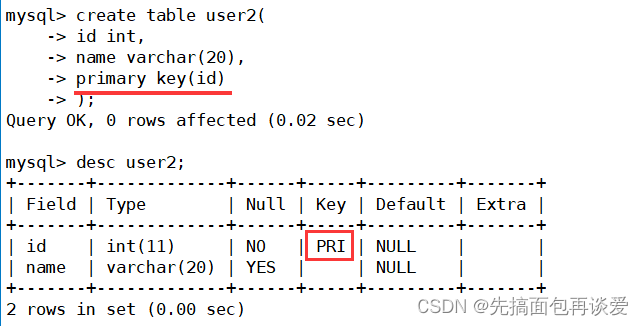
show index:
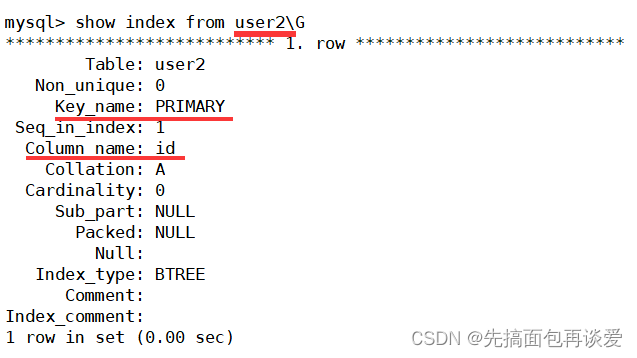
成功。
手動對已經創建且沒有主鍵的表添加主鍵列就算是第三種創建主鍵索引的方式,剛剛刪除了user表的主鍵列,下面手動添上:
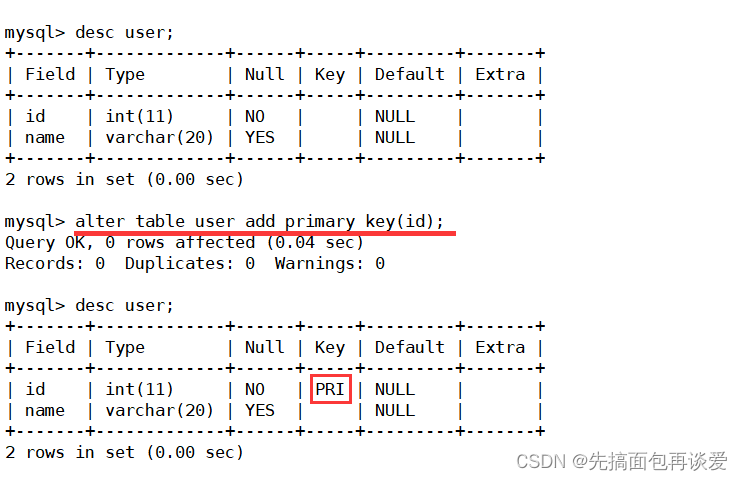
show一下:
成功。
再來試試復合主鍵,再來創建一個表:

還沒有加上主鍵,現在加上復合主鍵:
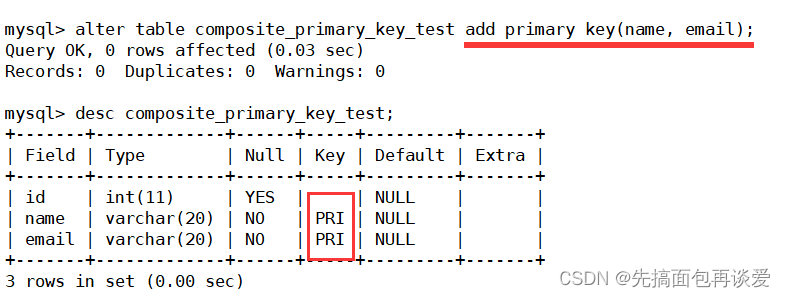
關于復合主鍵是啥我就不講了,不懂的同學可以看我前面的這篇博客:復合主鍵
show index:

兩個Column_name一個為name,一個email。就是復合主鍵索引。
復合索引用的時候有兩點要注意:
- 索引最左匹配原則
- 索引覆蓋
最左匹配,比如說剛剛的name和email作為復合索引,插入(張三, 1312335@qq.com)

此時如果查找(‘張三’, 1312335@qq.com),是按照索引來找的:

如果是查張三,會按照索引來查:

但是如果找的是email,是不會按照索引來找的:

不過這里就一行記錄,看不出來差別。后面再說一下這個復合索引的用處。
主鍵索引的特點:
- 一個表中,最多有一個主鍵索引,當然可以使復合主鍵
- 主鍵索引的效率高(主鍵不可重復)
- 創建主鍵索引的列,它的值不能為null,且不能重復
- 主鍵索引的列基本上是int
唯一索引(唯一鍵列)
后面還有一個普通索引,其實唯一索引和普通索引沒啥區別,至于為啥等會就知道了。
除了設置主鍵會自動構建索引以外,設置唯一鍵也會自動構建索引。
同樣的,也是建表的時候就設置唯一鍵(兩種方式),add添加唯一鍵。
建表:
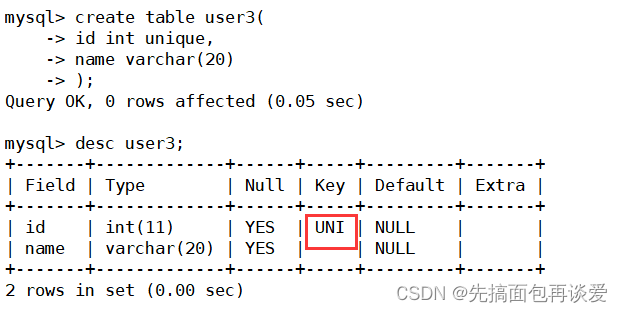
show index:
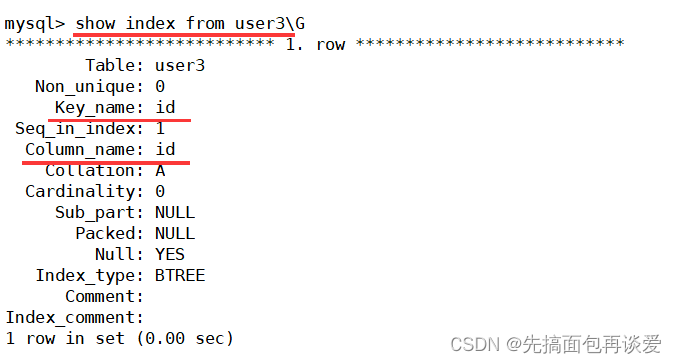
唯一鍵不是主鍵,而且一個表中唯一鍵可能有多個,所以索引的名字就直接跟著唯一鍵列的列名了。
再來去掉這個唯一索引,注意去掉唯一索引用的不是alter table drop unique key(列名),這里的drop語法是用來刪除某一列的,而且這里用的也不對。而是:
alter table drop index key(列名);
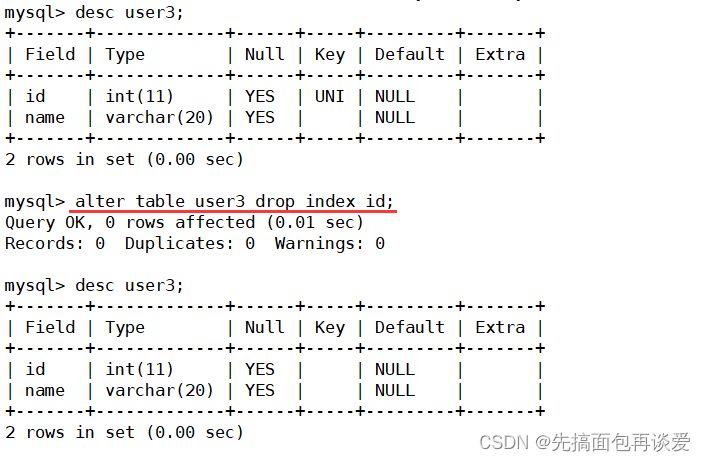
等會的普通索引也是這樣刪除的,所以說唯一鍵索引和普通索引沒啥區別。
show:

加回來:
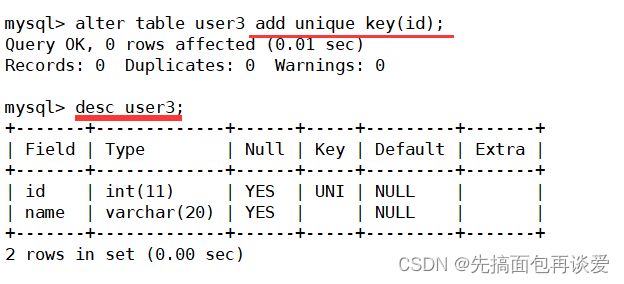
show:
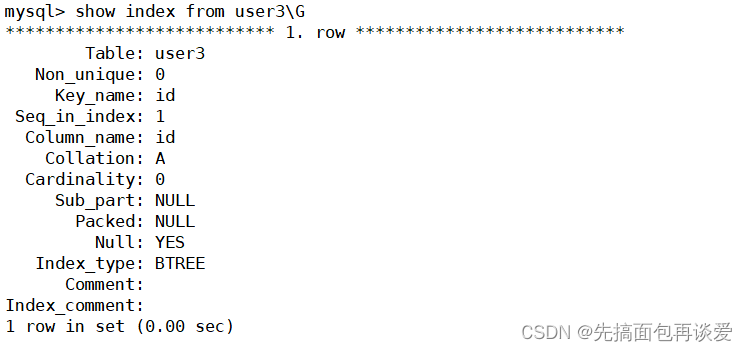
創建表時在末尾添加unique:
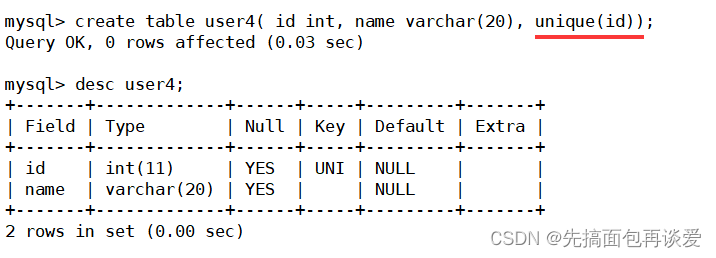
show:
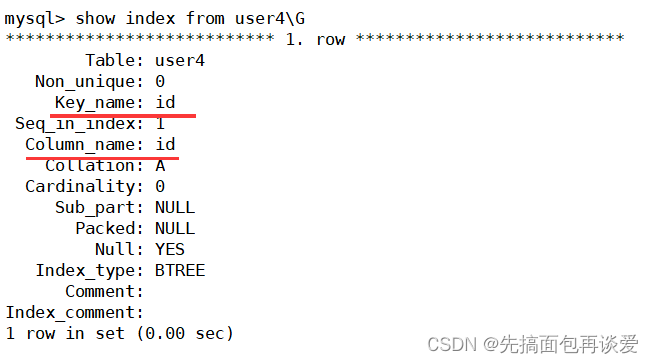
復合唯一索引。
建表:

show:

復合索引的名字為name,就是在創建的時候unique(name, qq)從左往右第一列的列名。查找對比的時候和剛剛講的復合主鍵索引一樣。
唯一索引的特點:
- 一個表中,可以有多個唯一索引
- 查詢效率高
- 如果在某一列建立唯一索引,必須保證這列不能有重復數據
- 如果一個唯一索引上指定not null,等價于主鍵索引
普通索引
創建普通索引也有三種方式,不過和前面不太一樣:
第一種
create table user6(id int primary key,name varchar(20),email varchar(30),index(name) --在表的定義最后,指定某列為索引
);
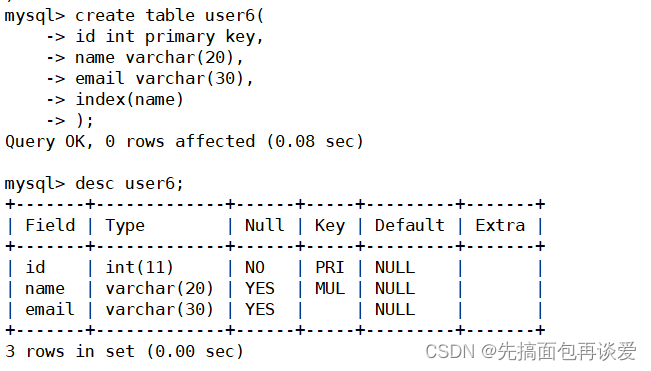
show:

第二種
create table user7(id int primary key,name varchar(20),email varchar(30)
);alter table user7 add index(name); --創建完表以后指定某列為普通索引
建表:

添加:
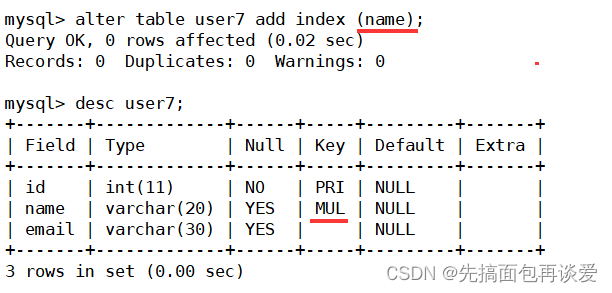
show:
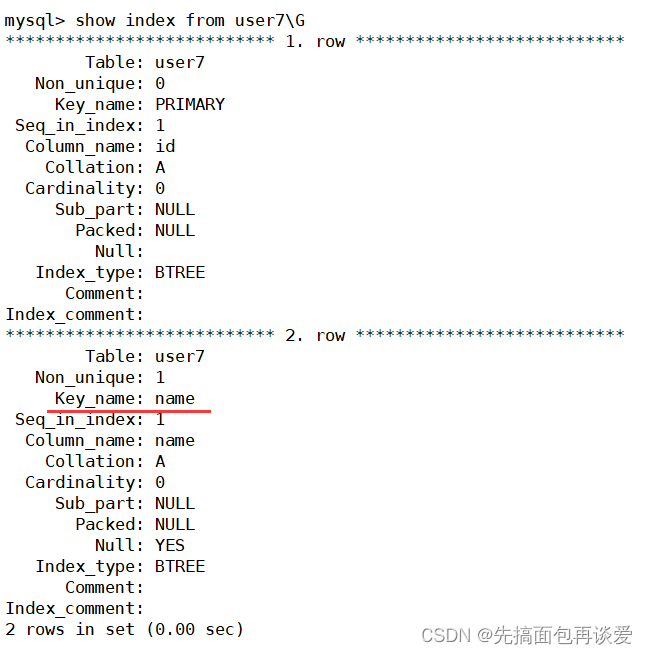
第三種:
create table user8(id int primary key,name varchar(20),email varchar(30)
);-- 創建一個索引名為 idx_name 的索引
create index idx_name on user8(name);
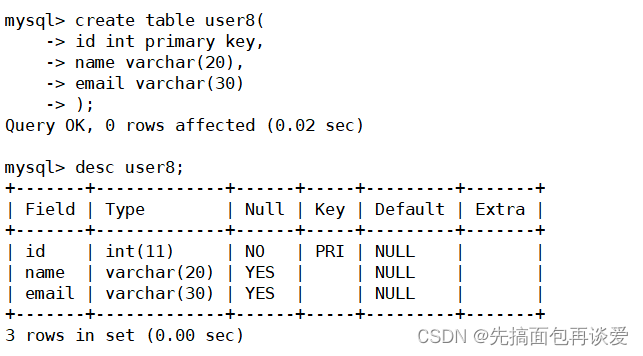
創建索引:
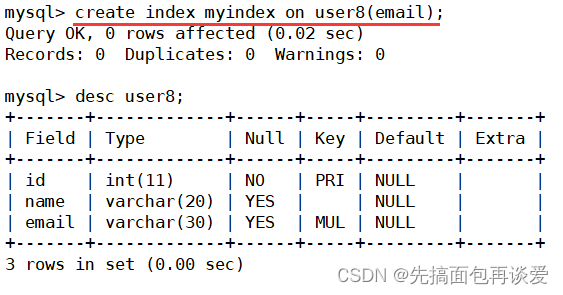
show:

注意我剛剛創建索引的時候索引名字給的是myindex。所以這里索引名就是myindex。
來去掉這個索引:
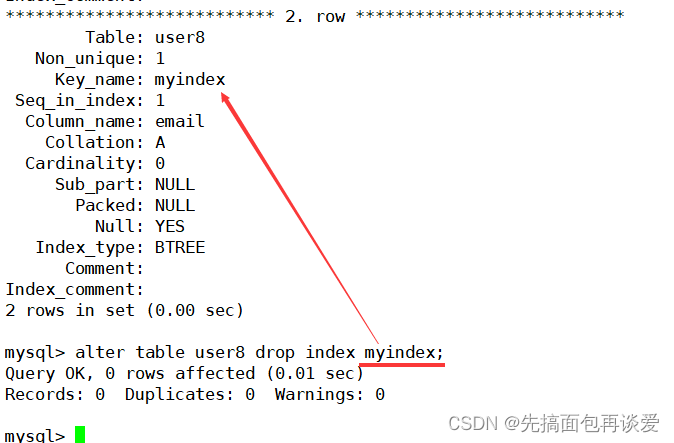
注意去掉索引的時候用的是索引名,不是列名。
添加一個復合索引:
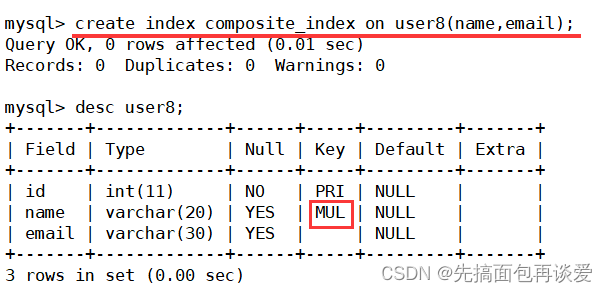
show:
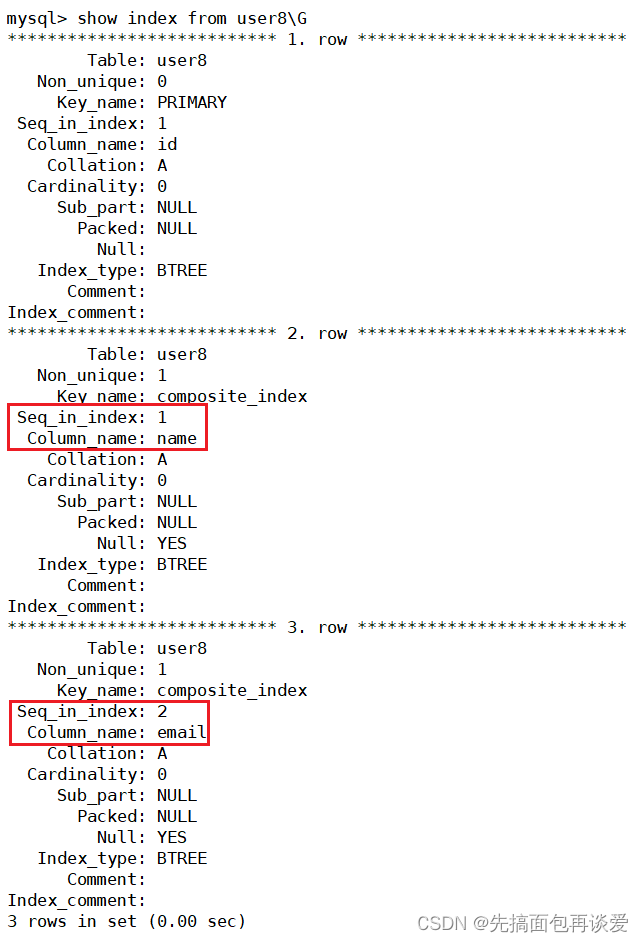
注意二者的索引名字都是composite_index,兩個和一塊是一個復合索引。查找對比的時候和剛剛講的復合主鍵索引一樣。
談回InnoDB和MyISAM
多個索引下B+樹是什么樣子的?
其實只要多一個索引就會多一棵B+樹,也就是一個索引對應一個B+樹,無論是主鍵索引還是普通索引(我這里就直接把唯一索引當做普通索引了)。
不過不同的存儲引擎做法不太一樣,這里就說一下InnoDB和MyISAM的。
InnoDB的多個索引
InnoDB是以主鍵所構建的B+樹為主。
主鍵的那棵B+樹,葉子結點存放了所有列的數據記錄,這一點要搞清楚。
比如說id、name、qq和email,4列中id作為主鍵。那么以id為關鍵字的所有數據都會被記錄在主鍵構建的B+樹中。
假如說這是以主鍵id構建出來的B+樹:
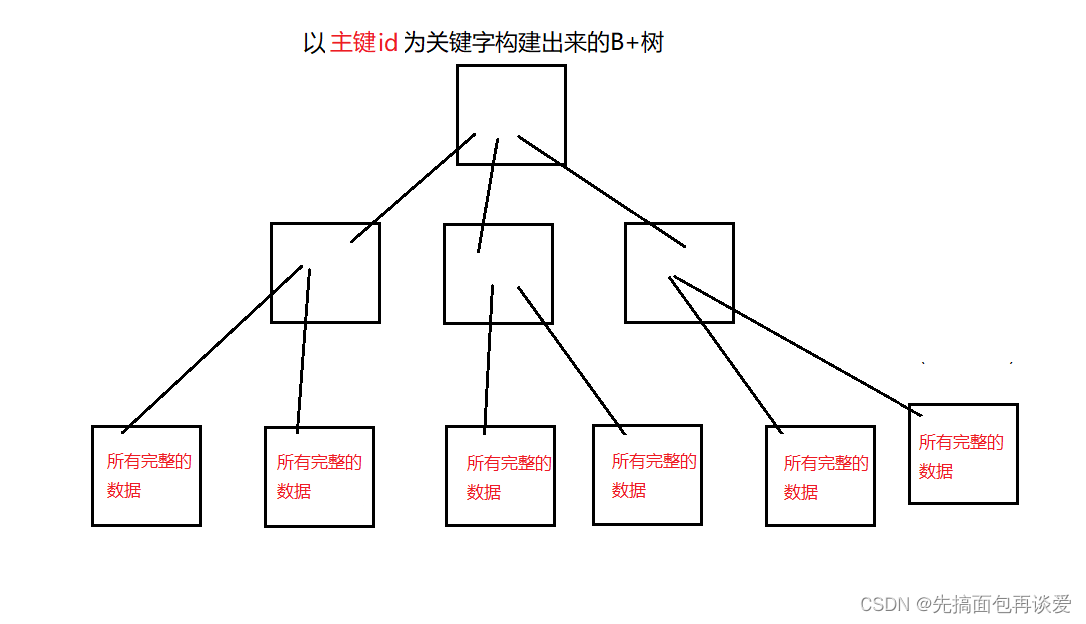
而普通索引的B+樹,葉子結點中只會保存普通索引列和主鍵列的數據。
比如說以name列作為普通索引,就會構建一棵以name作為關鍵字的B+樹,葉子結點中只會保存name和id列的數據,如圖:
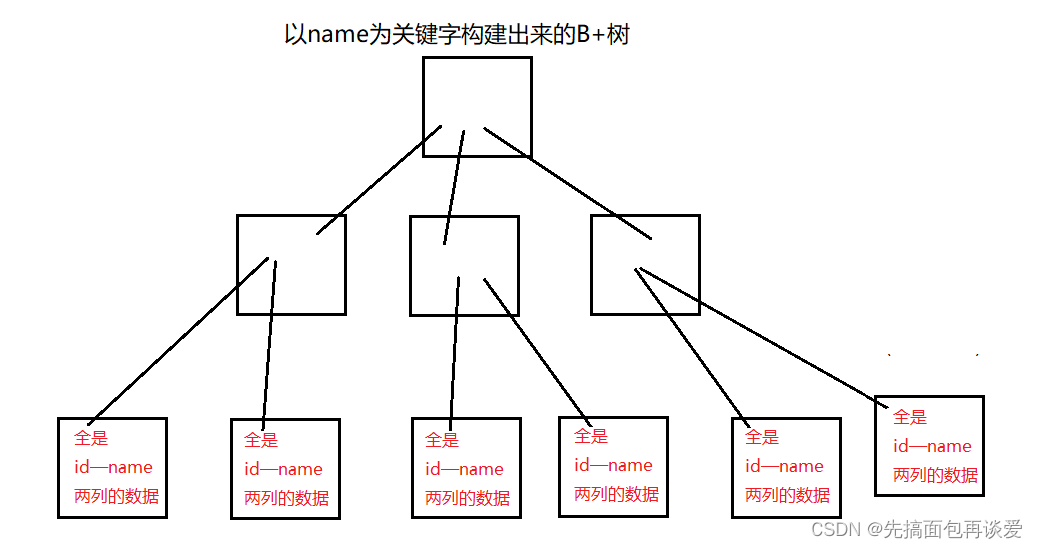
當進行查找的時候,如果是用name進行查找的話,比如說找張三,那么就會先通過以name為關鍵字構建出來的B+樹找到對應的name和id,然后再通過id去主鍵構建出來的B+樹中找到完整的數據。
整個流程就是這樣:
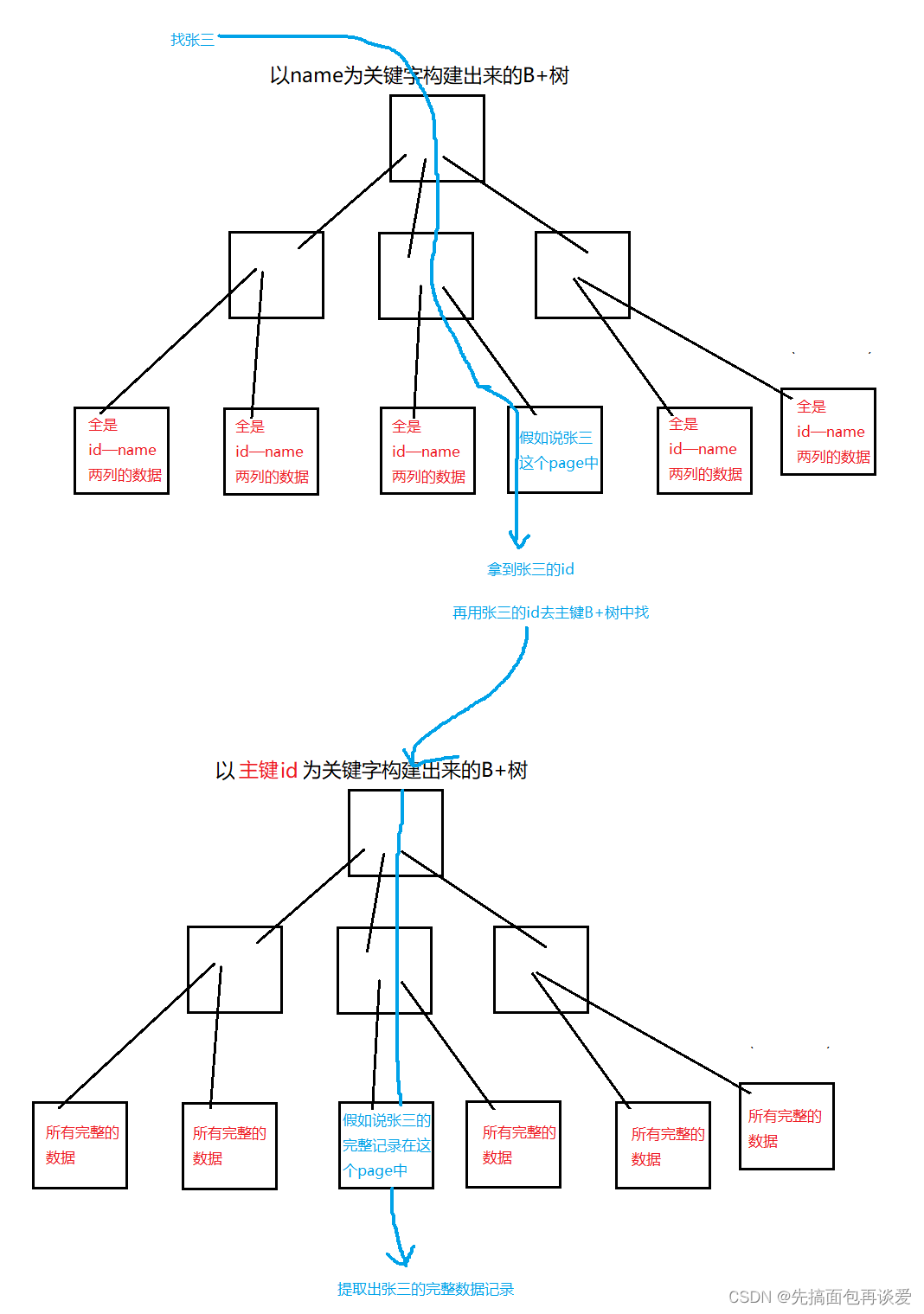
而上面的這個操作用專業術語來說就叫做回表查詢。
為什么要這樣做呢?
因為如果普通索引構建出來的B+樹葉子結點中也保存了所有的數據就會造成非常多的重復數據,空間上會很浪費。
再來說說復合索引的用處。
同樣的還是上面的id、name、qq、email。
如果我現在以name、qq建一個復合的普通索引,那么就會建議對應的B+樹,樹中葉子結點保存的就是id、name和qq這三個列的數據。
那么復合索引用處在哪呢?
比如說我現在要找張三的qq,但是我不知道張三的id,那么我就必須得要按照人名找,此時找的時候直接通過復合索引的B+樹找到對應的id、name和qq記錄,然后就可以直接提取出來張三的qq,不需要再通過id來再去id構建的B+樹中去找張三的完整數據記錄了。
這一點就非常適合高頻的通過非主鍵列(比如說name)來找其他列,不需要進行回表。這就是索引覆蓋。
MyISAM的多個索引
MyISAM更為簡單一點。
因為MyISAM的所有數據是單獨存在一個地方的,不和索引在一塊,主鍵對應的B+樹葉子結點是直接存放完整數據地址的。
如果新建了其他的索引,同樣會創建一棵B+樹,但是樹中葉子結點也是存放對應的完整數據的地址,那么這樣普通索引就和逐漸索引沒什么區別了,無非就是主鍵不能重復,而非主鍵可重復(如果非主鍵加上unique,也就是唯一索引,那么就和逐漸約束一樣了)。
所有索引的B+樹都是用葉子結點直接存放數據地址:
查詢索引
其實剛剛已經說了一個,就是:
show index from 表名;
再演示一下:
還有一個:
show keys from 表名
兩種方式得到的結果是完全一樣的:

索引創建原則
-
比較頻繁作為查詢條件的字段應該創建索引
-
唯一性太差的字段不適合單獨創建索引,即使頻繁作為查詢條件,比如說性別,只有男女那就沒必要搞成索引。
-
更新非常頻繁的字段不適合作創建索引
-
不會出現在where子句中的字段不該創建索引
全文索引
這個是個邊緣知識,了解一下就行。
當對文章字段或有大量文字的字段進行檢索時,會使用到全文索引。MySQL提供全文索引機制,但是有要求,要求表的存儲引擎必須是MyISAM,而且默認的全文索引支持英文,不支持中文。如果對中文進行全文檢索,可以使用sphinx的中文版(coreseek)。
演示一下,建張表:
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine=MyISAM;

插入點數據:
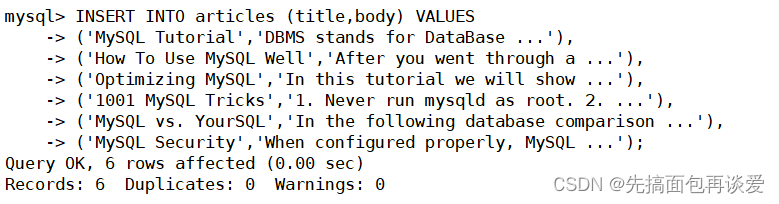
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
查詢有沒有database數據
如果使用如下查詢方式,雖然查詢出數據,但是沒有使用到全文索引:

可以用explain工具看一下,是否使用到索引:

其中的key為NULL,表示沒有用到索引。
如何使用全文索引呢?
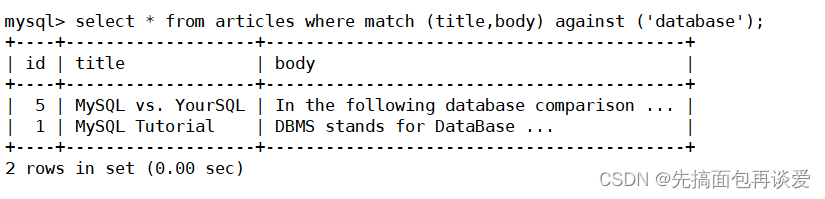
通過explain來分析這個sql語句:

key用到了title。
就講這么多。
到此結束。。。




并開啟Launchpad活動)














