 ?
?
論文標題: Making Large Language Models Perform Better in Knowledge Graph Completion
論文鏈接:?https://arxiv.org/abs/2310.06671?
代碼鏈接:GitHub - zjukg/KoPA: [Paper][Preprint 2023] Making Large Language Models Perform Better in Knowledge Graph Completion
01. 動機
大語言模型憑借其強大的文本理解與生成能力在AI的各個領域中掀起了研究的熱潮。大語言模型(LLM)與知識圖譜(KG)的結合是未來大語言模型未來的重要發展方向之一。一方面,大模型憑借其豐富的文本理解和生成能力可以完成知識圖譜的構建以及推理和補全,另一方面,知識圖譜也可以為大模型提供可信的外部知識,緩解大模型中出現的幻覺現象。這篇論文著眼于基于大模型的知識圖譜補全(LLM4KGC),探索了如何才能更好地讓大語言模型完成知識圖譜補全這項任務。
02. 貢獻
已有的LLM4KGC的方法往往是通過指令微調的方式,構造提示詞模版將一條條的三元組輸入大模型中對大模型進行微調,來訓練出能夠完成KGC任務的LLM,但是這樣的方法沒有充分利用KG中存在的復雜結構信息,導致LLM無法充分地理解知識圖譜中的結構信息,從而限制了LLM解決KGC問題的能力。圍繞如何在LLM中引入KG結構信息這一個問題,該文章做出了如下幾點貢獻:
- 論文探究了在常見的LLM范式(不需要訓練的In-Context Learning和需要訓練的指令微調)基礎上如何引入知識圖譜的結構信息,分別提出了一種結構增強的上下文學習方法和結構增強的指令微調方法
- 論文提出了一種知識前綴適配器(Knowledge Prefix Adapter, KoPA),將KG中提取的結構知識通過一個適配器映射到大模型的文本token表示空間中,并和三元組的文本一起進行指令微調,使得LLM能夠充分理解KG中的結構信息,并在結構信息的輔助下完成知識圖譜的推理。
- 論文進行了大量的實驗,來驗證了論文中提出的多種方法的性能,探索最合理的結構信息引入方案。
03. 方法
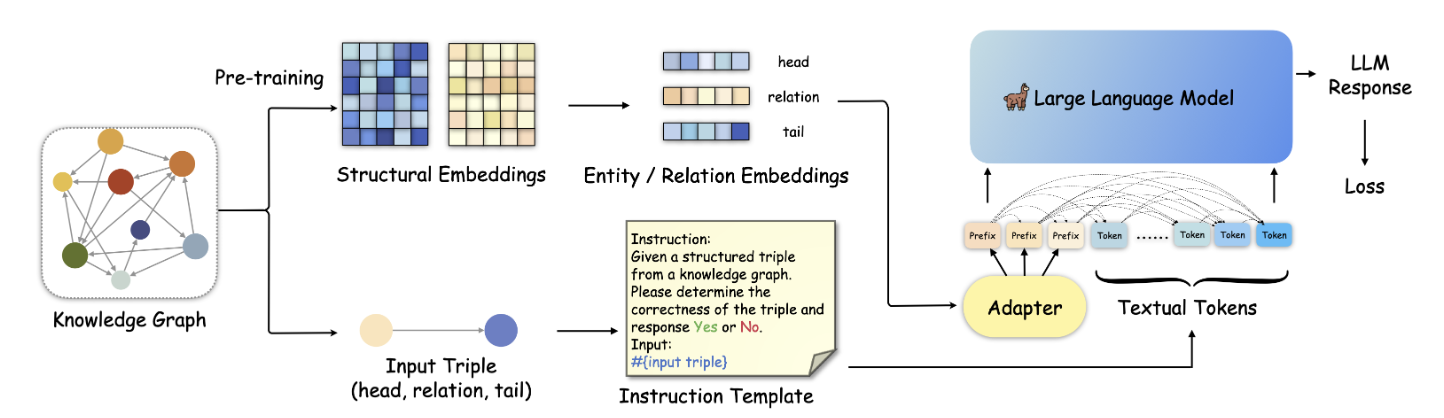 ?
?
論文首先提出了結構增強的上下文學習和指令微調方法,通過將輸入的三元組的局部結構信息通過文本描述的方式添加到指令模版中,實現結構信息的注入。
另一方面,論文中提出的知識前綴適配器(KoPA)的主要設計方案如上圖所示,首先KoPA通過結構特征的預訓練提取知識圖譜中實體和關系的結構信息,之后,KoPA通過一個設計好的適配器,將輸入三元組對應的結構特征投影到大語言模型的文本表示空間中,然后放置于輸入prompt的最前端,讓輸入的提示詞模版中的每個token都能“看到”這些結構特征,然后通過微調的Next Word Prediction目標對LLM的訓練。論文對不同的結構信息引入方案進行了對比,對比的結果如下:
 ?
?
04. 實驗
實現部分,該論文選取了三個數據集,進行了三元組分類的實驗。三元組分類是一項重要的知識圖譜補全任務,旨在判斷給定三元組的正確性。論文的主要實驗結果如下:
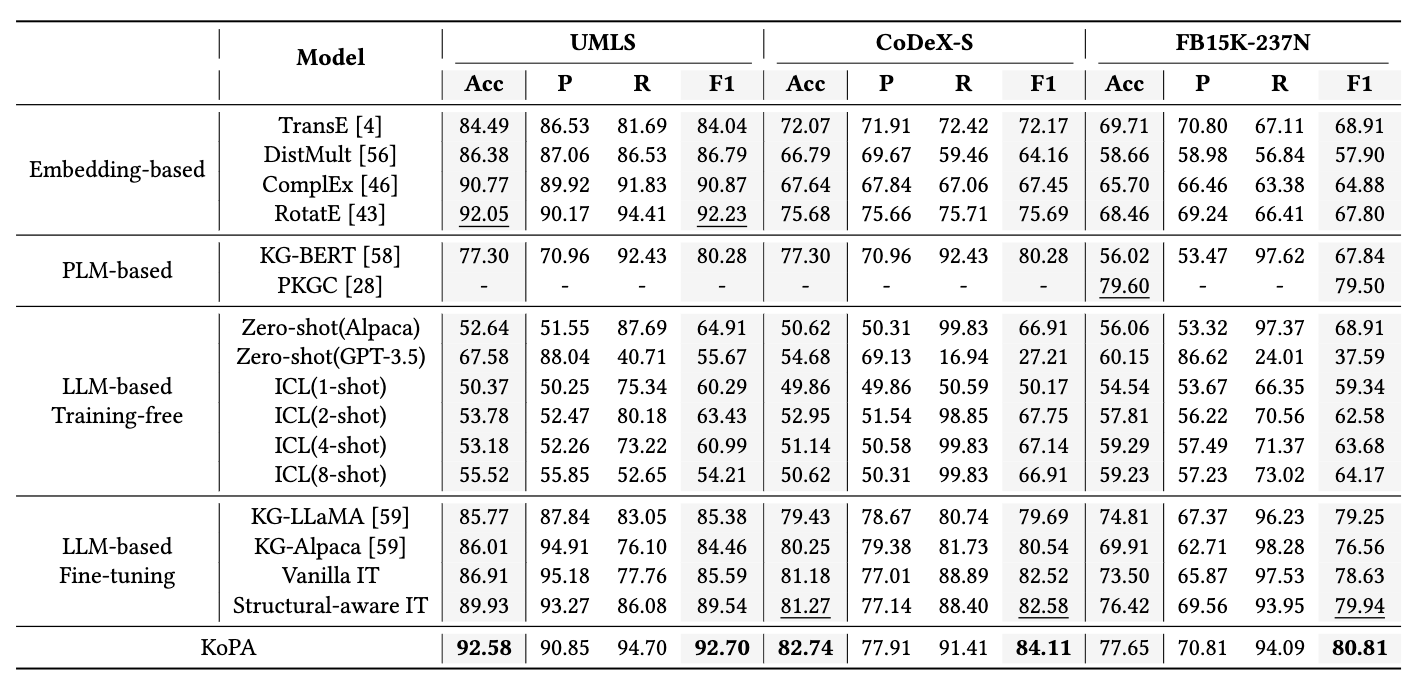 ?
?
可以看到,相比于傳統方法、基于大模型的方法和引入結構信息的方法來說,KoPA在三個數據集上的準確率、F1值等指標取得了一定的提升。此外論文還對KoPA中適配器的可遷移性、模塊設計的合理性等進行了分析,感興趣的讀者可以通過閱讀原論文了解進一步的內容。
05. 總結
該論文探索了如何將知識圖譜中的結構知識引入大語言模型中,以更好地完成知識圖譜推理,同時提出了一個新的知識前綴適配器,將從知識圖譜中提取到的向量化的結構知識注入到大模型中。在未來,作者將進一步探索基于大語言模型的復雜知識圖譜推理,同時也將關注如何利用知識圖譜使得大語言模型能夠在知識感知的情況下完成更多下游任務比如問答、對話等等。
關于TechBeat人工智能社區
▼
TechBeat(www.techbeat.net)隸屬于將門創投,是一個薈聚全球華人AI精英的成長社區。
我們希望為AI人才打造更專業的服務和體驗,加速并陪伴其學習成長。
期待這里可以成為你學習AI前沿知識的高地,分享自己最新工作的沃土,在AI進階之路上的升級打怪的根據地!
更多詳細介紹>>TechBeat,一個薈聚全球華人AI精英的學習成長社區?








![[HCIE] IPSec-VPN (IKE自動模式)](http://pic.xiahunao.cn/[HCIE] IPSec-VPN (IKE自動模式))







)


