上期介紹了基于亞馬遜云科技的大語言模型相關研究方向,以及大語言模型的訓練和構建優化。本期將介紹大語言模型訓練在亞馬遜云科技上的最佳實踐。
大語言模型訓練在亞馬遜云科技上的最佳實踐
本章節內容,將重點關注大語言模型在亞馬遜云科技上的最佳訓練實踐。大致分為五大方面:
計算(Compute)?— Amazon SageMaker Training
存儲(Storage)?— 可以通過兩種方式完成數據加載和檢查點(checkpointing)配置:Amazon FSx Lustre 文件系統或Amazon S3
并行化(Parallelism)— 選擇分布式訓練庫對于正確使用 GPU 至關重要。我們建議使用經過云優化的庫,例如 SageMaker 分片數據并行處理,但自管理庫和開源庫也可以使用
聯網(Networking)?— 確保 EFA 和 NVIDA的 GPUDirectRDMA已啟用,以實現快速的機器間通信
彈性(Resiliency)?— 在大規模情況下,可能會發生硬件故障。我們建議定期寫入檢查點(checkpointing)
以下我們會簡單介紹下大語言模型訓練并行化(Parallelism)在亞馬遜云科技上的最佳實踐。
大語言模型訓練的并行化(Training Parallelism)
大語言模型通常有數十到數千億個參數,這使得它們無法容納在單個 GPU 卡中。大語言模型領域目前已有多個訓練分布式計算的開源庫,例如:FSDP、DeepSpeed 和 Megatron。你可以在 Amazon SageMaker Training 中直接運行這些庫,也可以使用 Amazon SageMaker 分布式訓練庫,這些庫已經針對亞馬遜云進行了優化,可提供更簡單的開發人員體驗。
因此,在大語言模型領域的開發人員,在亞馬遜云科技上目前有兩種選擇:
在 Amazon SageMaker 上使用優化過的分布式庫進行分布式訓練;
自己來管理分布式訓練。
以下將概述如何在 Amazon SageMaker 上,使用優化過的分布式庫進行分布式訓練。
為了提供更好的分布式訓練性能和可用性,Amazon SageMaker Training 提出了幾種專有擴展來擴展 TensorFlow 和 PyTorch 訓練代碼。在真實場景里,大語言模型的訓練通常以多維度并行(3D-parallelism)的方式在進行:
數據并行(data parallelism):可拆分訓練小批次并將其饋送到大語言模型的多個相同副本,以提高處理速度
流水線并行(pipeline parallelism):將大語言模型的各個層歸因于不同的 GPU 甚至實例,以便將大語言模型的大小擴展到單個 GPU 和單個服務器以外
Tensor 并行(tensor parallelism):將單個層拆分為多個 GPU,通常位于同一服務器內,以將單個層擴展到超過單個 GPU 的大小
以下示例圖,展示了如何在具有 8*k*3 個 GPU(每臺服務器 8 個 GPU)的 k*3 服務器集群上訓練 6 層模型。數據并行度為 k,流水線并行度為 6,張量并行度為 4。集群中的每個 GPU 包含模型層的四分之一,完整模型分為三臺服務器(總共 24 個 GPU)。
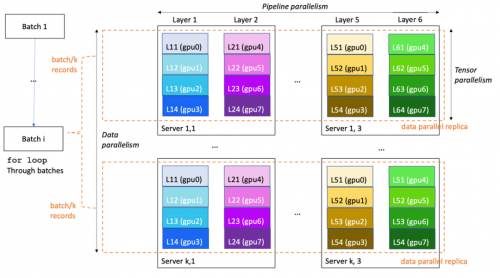
其中和大語言模型特別相關的分布式實踐包括:
Amazon SageMaker 分布式模型并行 — 該庫使用圖形分區生成針對速度或內存進行了優化的智能大語言模型分區。Amazon SageMaker 分布式模型并行提供了最新、最好的大語言模型訓練優化,包括數據并行、流水線并行、張量并行、優化器狀態分片、激活檢查點和卸載。
Amazon SageMaker 分片數據并行——在?MiCS: Near-linear Scaling for Training Gigantic Model on Public Cloud?論文中,引入了一種新的模型并行策略,該策略僅在數據并行組上劃分模型,而不是整個集群。借助 MiCS,亞馬遜云科技的科學家們能夠在每個 GPU 上實現 176 萬億次浮點運算(理論峰值的 56.4%),從而在 EC2 P4de 實例上訓練 210 層、1.06 萬億個參數的大語言模型。作為 Amazon SageMaker 并行共享數據,MIC 現已能夠向 Amazon SageMaker Training 客戶提供。
Amazon SageMaker 分布式訓練庫提供高性能和更簡單的開發者體驗。開發人員無需編寫和維護自定義的并行進程啟動器,或使用特定于框架的啟動工具,因為并行啟動器已經內置在 Amazon SageMaker 的任務啟動 SDK 之中。
與傳統分布式訓練相比,大語言模型的微調通常不僅要求數據并行,數據并行和模型并行需要同時進行。Amazon SageMaker Model Parallelism 在易用性和穩定性 (OOM) 上與開源自建方案(如 DeepSpeed)相比具有核心競爭優勢。對于基于哪些大語言模型進行具體微調、具體最佳實踐等技術細節,你還可以咨詢亞馬遜云科技的解決方案架構師團隊,獲得更進一步的技術支持和專業建議。
總結
本期文章我們一起探討大語言模型的發展歷史、語料來源、數據預處理流程策略、訓練使用的網絡架構、最新研究方向分析(LLaMA、PaLM-E 等),以及在亞馬遜云科技上進行大語言模型訓練的一些最佳落地實踐等。



)




)

-日志輸出”的功能詳解)
)



,手把手帶你安裝運行VS2022以及背景圖設置)



