講解 MySQL 中索引、觸發器、存儲過程、存儲函數的使用
文章目錄
- 1. 索引
- 1.1 索引的分類
- 1.2 索引的設計原則
- 1.3 如何使用(create index)
- 2. 觸發器
- 2.1 觸發器的分類
- 2.2 如何使用(create trigger)
- 3. 存儲過程
- 3.1 如何使用(create procedure)
- 3.1.1 存儲過程主體
- 4. 存儲函數
- 4.1 與存儲過程的區別
- 4.2 如何使用(create function)
1. 索引
-
索引是一種特殊的數據結構。(就像書的目錄一樣)
-
索引是提高數據庫性能的重要方式,所有字段都可以添加索引。
給某個字段添加索引,就相當于給這個字段添加目錄,下次再通過這個字段查的時候,就會直接找到該位置,而不是從頭開始查。
-
使用索引,可以快速查詢表中的記錄。但索引會占用內存空間
1.1 索引的分類
1、普通索引:不需要任何限制條件的索引,可在任意數據類型上創建
2、唯一索引:添加索引的字段,該字段的值必須唯一,比如:主鍵索引
3、全文索引:針對文本類型。只能創建在 char、varchar、text 數據類型的字段上
實際應用: 查詢數據量較大的字符串類型的字段時,使用全文索引可以提高速度。但 InnoDB (mysql默認的數據存儲引擎)不支持全文索引
4、單列索引:只對應一個字段的索引
5、多列索引:在一張表的多個字段上創建一個索引
注意: 多列索引,查詢時只需要使用第一個字段即可觸發索引。
6、空間索引:只能建立在空間數據類型上(比如:GIS(地理信息系統),因為地理信息的數據就是空間數據,描述的是空間位置,如經緯度)
注意: InnoDB 不支持空間索引
主鍵自帶索引,其它字段可以手動添加索引(但一般不會添加)
1.2 索引的設計原則
1、添加索引時,是出現在 where 語句中的字段,不是 select 后面要查詢的字段。
select name from user where id=1; -- 給id添加,而不是給name
2、添加索引的字段,這一列的值盡量唯一,效率更高(因為本身就是通過這個值查詢的,而現在有多個,還需要判斷是哪個)
3、不要添加過多的索引,因為索引占用內存空間,沒有用的索引也占用,所以維護成本高。
通常情況下,就用主鍵自帶的索引
1.3 如何使用(create index)
-- 1. 添加索引:索引名可自定義,一般為:idx_添加索引的字段名
-- 方式一:
alter table 表名 add index 索引名(字段名);
-- 方式二(推薦):
create index 索引名 on 表名(字段名);-- 2. 刪除索引
-- 方式一:
alter table 表名 drop index 索引名;
-- 方式二(推薦):
drop index 索引名 on 表名;
2. 觸發器
1、觸發器中定義了一系列操作,在對指定的表進行 插入、更新或刪除 (沒有查詢)的同時自動執行這些操作。觸發器是不需要調用的
2、為什么有這個機制?
舉個例子:因為有些時候對一個表的操作,不僅僅是單表,還有跟它關聯的其它表,比如:刪除一個班級的時候,你在班級表中把對應的班級刪除了,但是學生你也應該進行相應的操作,因為班級都沒有了,這個學生對應的班級也就沒有了。所以觸發器中就可以定義這些操作。
3、觸發器的優點:
-
開發更快。因為觸發器是存儲在數據庫中的,在應用程序中不用每次都編寫觸發器中的操作。
比如:不需要每次刪一個班級,你就要編寫對學生操作的 SQL
-
更容易維護。定義觸發器后,訪問目標表會自動調用觸發器。
比如:假如關聯的不是學生了,是教師,怎么辦?那只需要修改觸發器中的內容即可
-
業務的全局實現。如果修改業務代碼,只需要修改觸發器。
就是不需要改 Java 程序中的代碼,只需要修改觸發器即可
2.1 觸發器的分類
- 前置觸發器: 在 更新或插入 操作之前執行,關鍵字為:before
- 后置觸發器: 在 更新、插入或刪除 后執行,關鍵字為:after
- before delete 觸發器: 在 刪除之前 執行,關鍵字為:before delete
- insted of 觸發器: 對復雜的視圖執行 插入、更新、刪除時執行,關鍵字為:insted of
2.2 如何使用(create trigger)
1、創建
create trigger 觸發器名(可自定義:一般為t_觸發器類型操作名稱_on_哪個表)
觸發時刻 什么操作 on 哪個表上制定觸發器 for each row
觸發器需要執行的操作
觸發器需要執行的操作:如果要執行多個語句,可使用:begin 語句 end
提示:觸發器需要執行的操作,這一部分肯定包含多個語句,每個語句都是以分號結尾,這時服務器處理程序的時候遇到第一個分號就會認為程序結束,這肯定不行。所以使用
delimiter 結束符號(比如:$$)命令講 MySQL 中的結束標志修改為其它符號。最后使用opdelimiter ;或者delimiter ;恢復即可。比如:delimiter $$ create trigger t_afterInsert_on_tab1 after insert on tab1 for each row begininsert into tab2(name,age) values(new.name,new.age); end$$ delimiter;假如運行不報錯,結果也符合預期,一般不需要設置。
例1: 給 tab1 表添加一條數據后,然后 tab2 表自動添加這個數據:
create trigger t_afterInsert_on_tab1
after insert on tab1 for each row
begininsert into tab2(name,age) values(new.name,new.age);
end;
這樣執行 insert into tab1(name,age) values('abc',23); 后,tab2 表中也有數據了。
注意:
① new.字段名 用來引用新行的一列,old.字段名 用來引用更新或刪除它之前的已有行的一列。
② 對于 insert,只有 new 是合法的,對于 delete,只有 old 是合法的,對于 update,new、old
都合法。
例2: 刪除 tab1 表的后,然后 tab2 表也刪除:
create trigger t_afterDelete_on_tabl
after delete on tab1 for each row
begindelete from tab2 where tab2.id = old.id;
end;
這樣執行 delete from tab1 where id=2; 后,tab2 表中對應 id=2 的數據也刪除了。
2、刪除觸發器:drop trigger 觸發器名;
3. 存儲過程
在實際開發中用的比較多的一種方式
1、存儲過程是一組為了完成特定功能的 SQL 的集合。經過編譯后存儲在數據庫中,用戶可以通過存儲過程的名稱調用(可傳參)。
跟觸發器有點像,但是觸發器需要有一張目標表。存儲過程跟 java 中的方法一樣,可以根據需要調用。
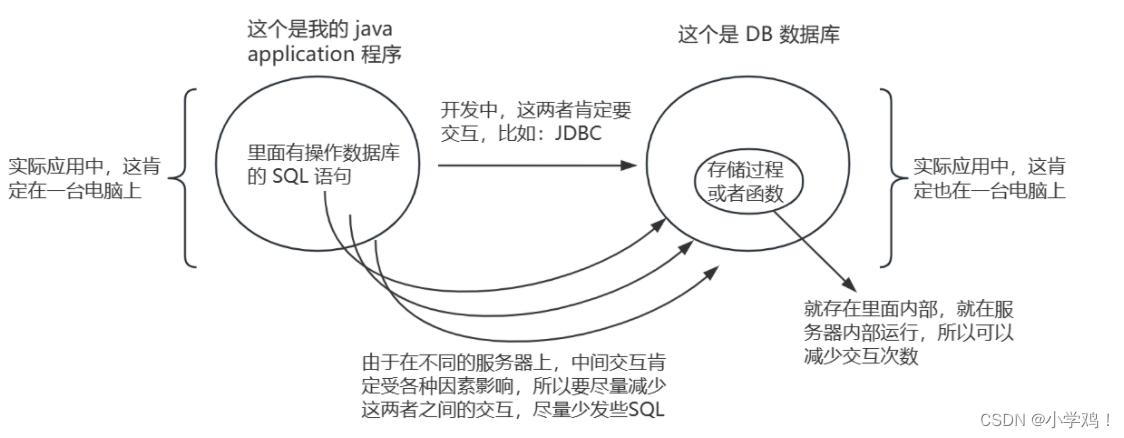
2、一次編寫,多次調用,避免重復編寫相同的SQL,存儲過程和函數(函數:跟存儲過程類似)都是在數據庫執行的,可以減少 java 程序和數據庫之間的數據傳輸,提高效率。
3、存儲過程的優點:
- 模塊化程序設計。把一些語句組裝在一起。
- 執行速度更快。如果某個操作需要執行大量的 SQL,存儲過程比直接執行 SQL 效率更高(假如 SQL 重復,對于重復的 SQL,存儲過程優勢更為明顯)
- 更好的安全機制。對于沒有權限存儲過程的用戶,可以通過授權的方式執行存儲過程。
3.1 如何使用(create procedure)
1、創建
create procedure 存儲過程名([參數,...])
存儲過程主體
參數: 不加參數時,存儲過程后面的括號不可省略。三部分組成:[in|out|inout] 參數名 參數類型
-
in 輸入參數。可以使數據傳遞給一個存儲過程
-
out 輸出參數。當需要返回一個答案或結果的時候,存儲過程使用輸出參數
3.1.1 存儲過程主體
存儲過程主體: 指在調用存儲過程的時候必須執行的語句。如果要執行多個語句,可使用:begin 語句 end
注意:存儲過程主體中也有可能包含多個 SQL 語句。同理:只要運行不報錯,結果也符合預期,一般不需要修改結束標志。
下面的內容只能使用在存儲過程體中:
① 聲明局部變量
在存儲過程中可以聲明局部變量,用來存儲臨時結果。語法:declare 變量名,... 變量類型 [default 默認值] ,比如:declare num int default 5; 或者 declare num int; 或者 declare str1,str2 varchar(10);
-
局部變量只能在
begin ... end語句中使用,而且必須在存儲過程的開頭。 -
給局部變量賦值:
set 變量名=表達式;-- 多個 set 變量名=表達式, 變量名=表達式,...;
② select into 語句
把選定的列值直接存儲到變量中。如:select 姓名,專業名 into name,project
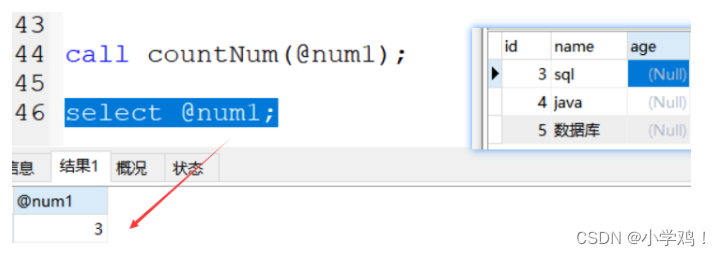
例子: 總計數據總數后并返回
create procedure countNum(out num int)
begin select count(*) into num from tab1;
end;-- 問題1:怎么調?
call countNum(@num1);
-- 其中 @num1 就是定義一個變量來接收返回的結果,@用來定義用戶變量-- 問題2:怎么查看結果?
select @num1;
③ 流程控制語句
-
if 語句
if 條件 then 語句 [elseif 條件 then 語句] .... [else 語句] end if;例子: 根據傳進來的值,選擇判斷后,存入表格
create procedure addData(in target int) begin declare addName varchar(10);-- 賦值if target=1 then set addName="java";elseif target=2 then set addName="sql";else set addName="數據庫";end if;-- 插入insert into tab1(name) values(addName); end;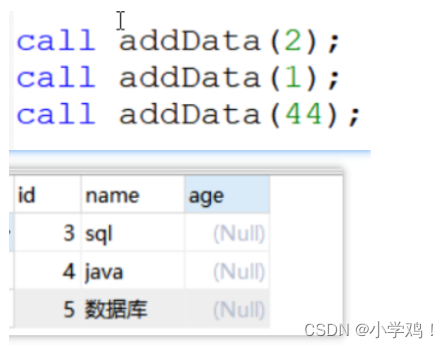
-
case 語句。與之前的分支查詢稍微不同
case 要判斷的值或表達式when 與判斷的值做比較的值 then 語句[when 與判斷的值做比較的值 then 語句][else 語句] end case;-- 或者(推薦) casewhen 條件 then 語句...[else 語句] end case; -
循環語句。MySQL 支持 3 中循環:while、repeat、loop。循環開始標識 和 循環結束標識 要有都有,要沒有都沒有,且自定義的名字要一樣。
[循環開始標識:] while 條件 do語句 end while [循環結束標識];============= [循環開始標識:] repeat語句until 條件 end repeat [循環結束標識];============= [循環開始標識:] loop語句 end loop [循環結束標識];問題:怎么跳出循環?----> leave(類似 break)、iterate(類似 continue)比如:
create procedure doloop() begin set @a=10; -- @a就是用戶變量(前面有@標識)label:loopset @a=@a-1;if @a<0 then leave label; -- 滿足條件后跳出循環end if;end loop label; -- 要有都有 end;
2、調用存儲過程:call 存儲過程名([參數]);
3、刪除存儲過程:drop procedure 存儲過程名;
4. 存儲函數
存儲函數與存儲過程非常相似
4.1 與存儲過程的區別
- 存儲函數不能有輸出參數,參數只能為 in(可以省略,所以存儲函數的參數只有名稱和類型)。
- 不能用 call 語句來調用存儲函數。而是 select 語句。
- 存儲函數必須包含一條 return 語句(也就是函數必須有返回值),而存儲過程不允許包含
4.2 如何使用(create function)
1、創建
create function 存儲函數名([參數,...])returns type存儲函數主體
其中:returns type 聲明函數返回值的數據類型,比如:
-- 通過id查詢名字并返回
create function name_student(student_id int)
returns int
beginreturn(select name from tab1 where id=student_id);
end;
begin 里面的 return 就是需要返回的東西,所以將內容放到 () 里面。也可以直接 return ,比如:return true; 或者 return '123';
2、調用:select 存儲函數名([參數]);
3、刪除:drop function 存儲函數名;








)










