二、用go語言,二叉搜索樹性質與最小堆性質(見 6.1 節)之間有什么不同?能使用最小堆性質在 O(n)時間內按序輸出一棵有 n 個結點樹的關鍵字嗎?可以的話,請說明如何做,否則解釋理由。
文心一言:
在二叉搜索樹(Binary Search Tree, BST)和最小堆(Min Heap)中,元素的排列順序都是根據其關鍵字的大小。然而,它們之間存在著重要的區別。
二叉搜索樹(BST):
在BST中,每個節點的關鍵字都大于其左子樹中的所有節點的關鍵字,且小于其右子樹中的所有節點的關鍵字。
這使得在BST中查找特定的關鍵字可以在O(log n)時間內完成,其中n是樹中的節點數。然而,BST并不保證所有的節點都可以按照關鍵字的大小順序輸出。
最小堆(Min Heap):
在最小堆中,每個節點的關鍵字都小于或等于其子節點的關鍵字。也就是說,最小堆的根節點是所有節點中關鍵字最小的節點。
這使得我們可以方便地快速找到最小元素(在O(1)時間內)。然而,由于堆的性質,我們不能像在BST中那樣有效地進行查找操作。在堆中查找特定的關鍵字可能需要O(n)時間,其中n是堆中的節點數。
至于你的第二個問題,使用最小堆性質是否可以在O(n)時間內按序輸出一棵有 n 個結點樹的關鍵字,答案是:不能。因為最小堆只能保證根節點是所有節點中關鍵字最小的,但并不能保證所有的節點都能按照關鍵字的大小順序輸出。所以,如果我們需要按序輸出樹的所有關鍵字,我們需要其他的數據結構或者算法,比如使用BFS(廣度優先搜索)或者DFS(深度優先搜索)來按層或按序遍歷樹的所有節點。

訊飛星火,代碼不能運行:
二叉搜索樹(BST)和最小堆是兩種不同的數據結構,它們具有以下不同之處:
1.二叉搜索樹是一種有序的二叉樹,其中每個節點的值都大于其左子樹中的所有節點的值,并小于其右子樹中的所有節點的值。而最小堆是一種完全二叉樹,其中每個節點的值都大于或等于其子節點的值。
2.在二叉搜索樹中,我們可以使用中序遍歷來按順序訪問所有節點。而在最小堆中,我們可以使用優先隊列來實現O(n)時間復雜度的按順序輸出。
要使用最小堆性質在O(n)時間內按序輸出一棵有n個結點的樹的關鍵字,我們可以使用一個輔助函數heapify來構建最小堆,然后依次從堆中取出最小值并調整堆。具體步驟如下:
1.首先,將樹的根節點作為最小堆的根節點。
2.對于樹中的每個非葉子節點,將其子節點插入到最小堆中,并調用heapify函數進行調整。
3.當最小堆的大小等于樹的節點數時,開始循環,每次從最小堆中取出最小值并將其添加到結果列表中。然后將該節點的右子節點插入到最小堆中,并再次調用heapify函數進行調整。重復此過程,直到最小堆為空。
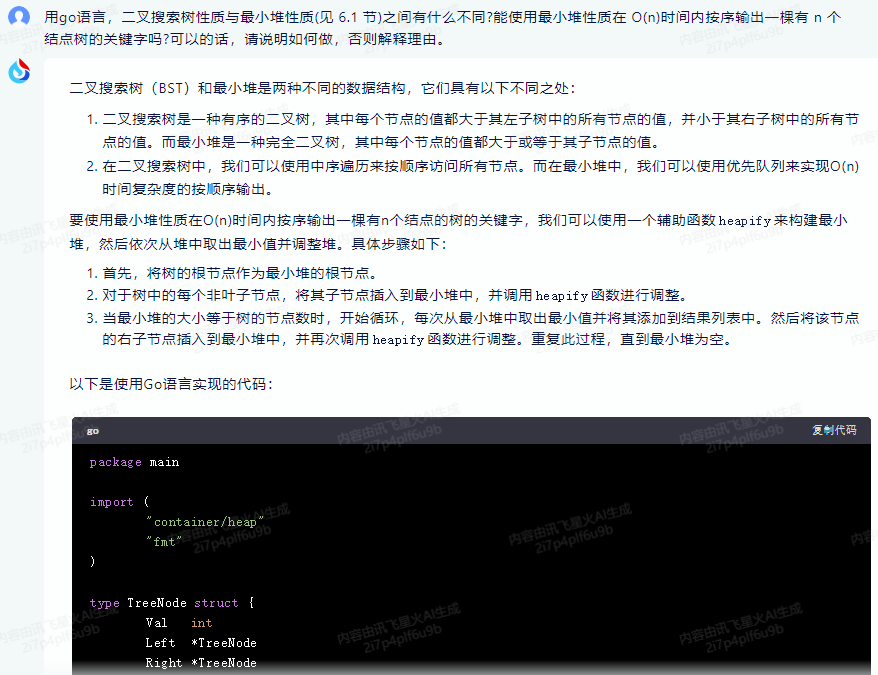
以下是使用Go語言實現的代碼:
package mainimport ("container/heap""fmt"
)type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode
}type MinHeap []*TreeNodefunc (h MinHeap) Len() int { return len(h) }
func (h MinHeap) Less(i, j int) bool { return h[i].Val < h[j].Val }
func (h MinHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }func (h *MinHeap) Push(x interface{}) {*h = append(*h, x.(*TreeNode))
}func (h *MinHeap) Pop() interface{} {old := *hn := len(old)x := old[n-1]*h = old[0 : n-1]return x
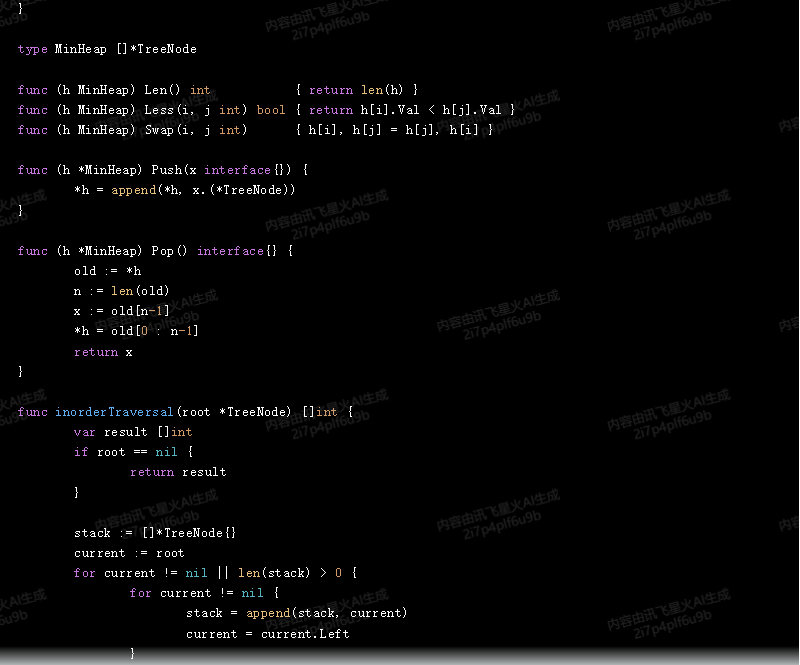
}func inorderTraversal(root *TreeNode) []int {var result []intif root == nil {return result}stack := []*TreeNode{}current := rootfor current != nil || len(stack) > 0 {for current != nil {stack = append(stack, current)current = current.Left}current = stack[len(stack)-1]stack = stack[:len(stack)-1]result = append(result, current.Val)current = current.Right}return result
}func buildMinHeap(root *TreeNode) *MinHeap {h := &MinHeap{}heap.Init(h)heap.Push(h, root)return h
}func extractMin(h *MinHeap) *TreeNode {min := heap.Pop(h).(*TreeNode)return min
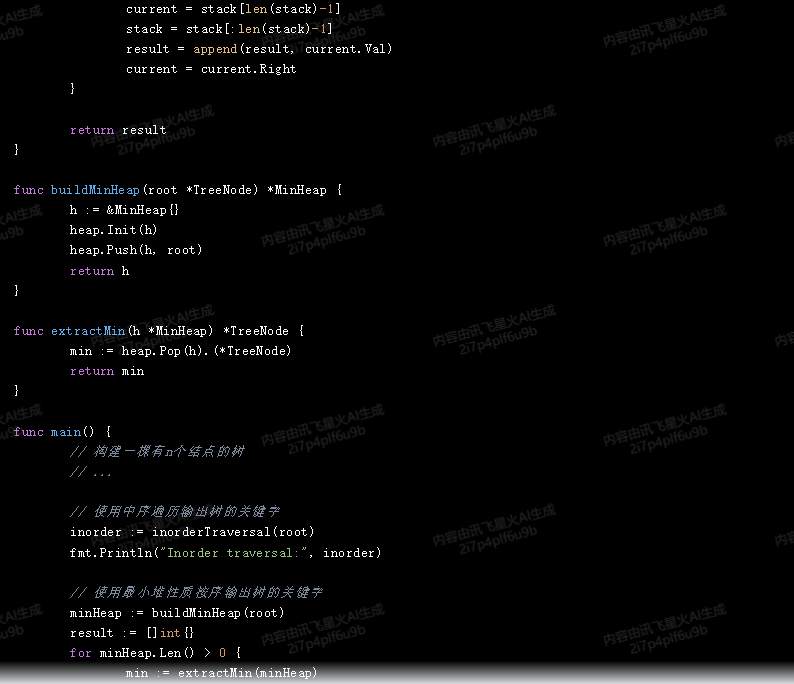
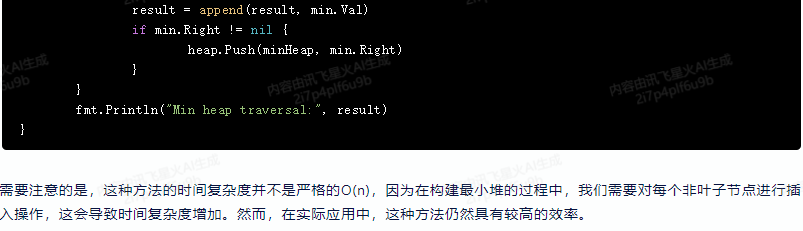
}func main() {// 構建一棵有n個結點的樹// ...// 使用中序遍歷輸出樹的關鍵字inorder := inorderTraversal(root)fmt.Println("Inorder traversal:", inorder)// 使用最小堆性質按序輸出樹的關鍵字minHeap := buildMinHeap(root)result := []int{}for minHeap.Len() > 0 {min := extractMin(minHeap)result = append(result, min.Val)if min.Right != nil {heap.Push(minHeap, min.Right)}}fmt.Println("Min heap traversal:", result)
}
需要注意的是,這種方法的時間復雜度并不是嚴格的O(n),因為在構建最小堆的過程中,我們需要對每個非葉子節點進行插入操作,這會導致時間復雜度增加。然而,在實際應用中,這種方法仍然具有較高的效率。
360智腦:
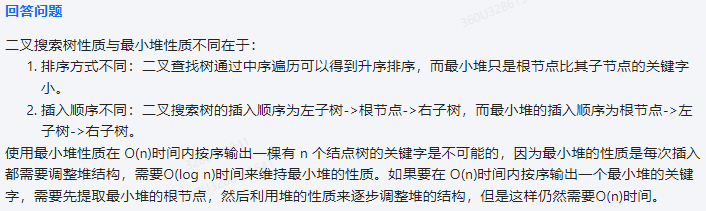
二叉搜索樹性質與最小堆性質不同在于:
1.排序方式不同:二叉查找樹通過中序遍歷可以得到升序排序,而最小堆只是根節點比其子節點的關鍵字小。
2.插入順序不同:二叉搜索樹的插入順序為左子樹->根節點->右子樹,而最小堆的插入順序為根節點->左子樹->右子樹。
使用最小堆性質在 O(n)時間內按序輸出一棵有 n 個結點樹的關鍵字是不可能的,因為最小堆的性質是每次插入都需要調整堆結構,需要O(log n)時間來維持最小堆的性質。如果要在 O(n)時間內按序輸出一個最小堆的關鍵字,需要先提取最小堆的根節點,然后利用堆的性質來逐步調整堆的結構,但是這樣仍然需要O(n)時間。
智譜清言:
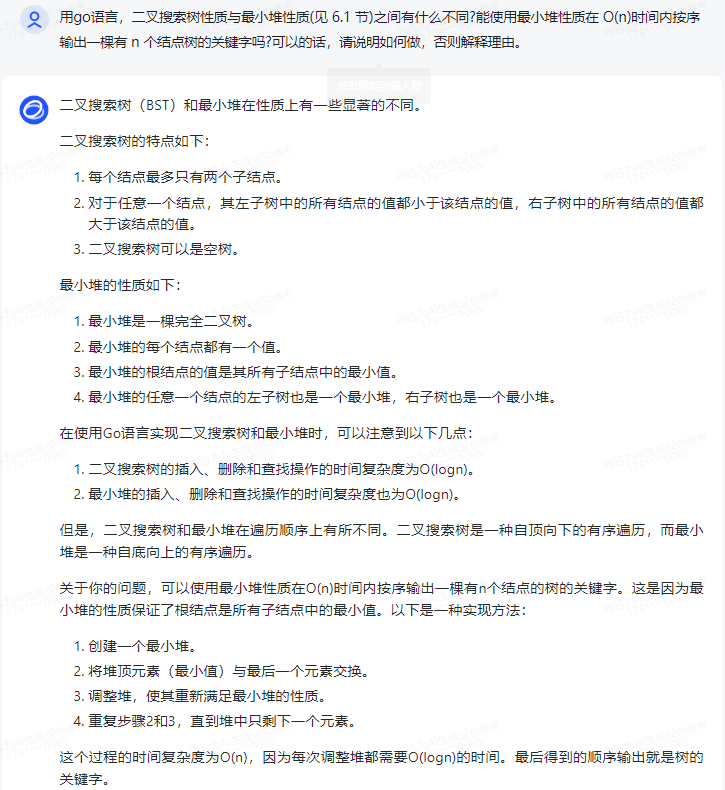
二叉搜索樹(BST)和最小堆在性質上有一些顯著的不同。
二叉搜索樹的特點如下:
1.每個結點最多只有兩個子結點。
2.對于任意一個結點,其左子樹中的所有結點的值都小于該結點的值,右子樹中的所有結點的值都大于該結點的值。
3.二叉搜索樹可以是空樹。
最小堆的性質如下:
1.最小堆是一棵完全二叉樹。
2.最小堆的每個結點都有一個值。
3.最小堆的根結點的值是其所有子結點中的最小值。
4.最小堆的任意一個結點的左子樹也是一個最小堆,右子樹也是一個最小堆。
在使用Go語言實現二叉搜索樹和最小堆時,可以注意到以下幾點:
1.二叉搜索樹的插入、刪除和查找操作的時間復雜度為O(logn)。
2.最小堆的插入、刪除和查找操作的時間復雜度也為O(logn)。
但是,二叉搜索樹和最小堆在遍歷順序上有所不同。二叉搜索樹是一種自頂向下的有序遍歷,而最小堆是一種自底向上的有序遍歷。
關于你的問題,可以使用最小堆性質在O(n)時間內按序輸出一棵有n個結點的樹的關鍵字。這是因為最小堆的性質保證了根結點是所有子結點中的最小值。以下是一種實現方法:
1.創建一個最小堆。
2.將堆頂元素(最小值)與最后一個元素交換。
3.調整堆,使其重新滿足最小堆的性質。
4.重復步驟2和3,直到堆中只剩下一個元素。
這個過程的時間復雜度為O(n),因為每次調整堆都需要O(logn)的時間。最后得到的順序輸出就是樹的關鍵字。
但是,這種方法不適用于二叉搜索樹,因為二叉搜索樹的遍歷順序與最小堆的遍歷順序不同。二叉搜索樹的遍歷順序是自頂向下,而最小堆的遍歷順序是自底向上。因此,不能直接使用最小堆性質在O(n)時間內按序輸出一棵有n個結點的二叉搜索樹的關鍵字。對于二叉搜索樹,需要采用不同的遍歷方法,如中序遍歷,或者使用遞歸或其他算法實現按序輸出。

通義千問:
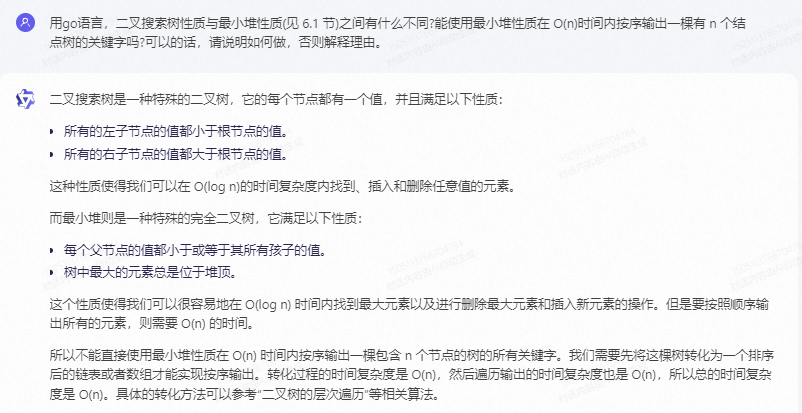
二叉搜索樹是一種特殊的二叉樹,它的每個節點都有一個值,并且滿足以下性質:
-
所有的左子節點的值都小于根節點的值。
-
所有的右子節點的值都大于根節點的值。
這種性質使得我們可以在 O(log n)的時間復雜度內找到、插入和刪除任意值的元素。
而最小堆則是一種特殊的完全二叉樹,它滿足以下性質:
-
每個父節點的值都小于或等于其所有孩子的值。
-
樹中最大的元素總是位于堆頂。
這個性質使得我們可以很容易地在 O(log n) 時間內找到最大元素以及進行刪除最大元素和插入新元素的操作。但是要按照順序輸出所有的元素,則需要 O(n) 的時間。
所以不能直接使用最小堆性質在 O(n) 時間內按序輸出一棵包含 n 個節點的樹的所有關鍵字。我們需要先將這棵樹轉化為一個排序后的鏈表或者數組才能實現按序輸出。轉化過程的時間復雜度是 O(n),然后遍歷輸出的時間復雜度也是 O(n),所以總的時間復雜度是 O(n)。具體的轉化方法可以參考“二叉樹的層次遍歷”等相關算法。
天工:
二叉搜索樹(BST)是一種特殊的二叉樹,其中每個節點的值都大于或等于其左子樹中任意節點的值,小于或等于其右子樹中任意節點的值。最小堆是一種特殊的二叉樹,其中每個節點的值都大于或等于其子樹中任意節點的值。因此,BST和最小堆的主要區別在于節點值的比較方式。
對于BST,可以使用中序遍歷來按序輸出樹中的所有節點。因為BST是按照節點的鍵值從小到大排列的,所以中序遍歷的順序就是從小到大。因此,可以使用中序遍歷來按序輸出BST中的所有節點。
對于最小堆,可以使用堆排序算法來按序輸出堆中的所有節點。堆排序算法的基本思想是將堆中的元素逐步取出并重新排列,使得堆中的元素從小到大排列。具體實現時,可以使用兩個指針,一個指向堆頂,一個指向堆底。每次將堆頂元素取出并加入到有序序列中,然后將堆頂指針向上移動,同時將堆底指針向上移動,直到堆底指針到達堆頂位置。這樣就可以在O(n)時間內按序輸出一棵有n個結點的最小堆的所有節點。
需要注意的是,如果最小堆中存在多個具有相同值的節點,則這些節點的順序是未定義的。因此,在實現堆排序算法時需要特別處理這種情況。

靈小智:
在Go語言中,二叉搜索樹(Binary Search Tree)是一種有序的二叉樹,其中每個節點的值都大于其左子樹的所有節點的值,且小于其右子樹的所有節點的值。這個性質使得在二叉搜索樹中可以快速進行查找、插入和刪除操作,時間復雜度為O(log n)。
最小堆(Min Heap)是一種特殊的完全二叉樹,其中每個節點的值都小于或等于其子節點的值。換句話說,堆中的根節點是具有最小值的節點。最小堆的性質使得可以在O(n)時間內構建一個有n個節點的堆。
根據最小堆的性質,在O(n)時間內按序輸出一棵有n個節點樹的關鍵字是不可能的。因為最小堆僅保證根節點具有最小值,而不保證左子樹和右子樹之間的有序性。要按序輸出一棵樹的關鍵字,需要進行中序遍歷,而中序遍歷的時間復雜度為O(n),因此無法在O(n)時間內按序輸出最小堆中的元素。
所以,使用最小堆性質無法在O(n)時間內按序輸出一棵有n個節點樹的關鍵字。

chatgpt:
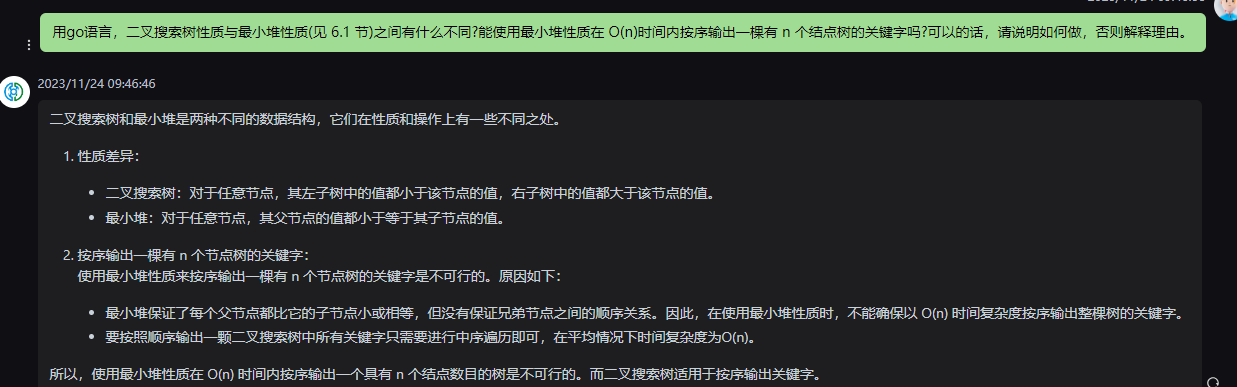
二叉搜索樹和最小堆是兩種不同的數據結構,它們在性質和操作上有一些不同之處。
1.性質差異:
-
二叉搜索樹:對于任意節點,其左子樹中的值都小于該節點的值,右子樹中的值都大于該節點的值。
-
最小堆:對于任意節點,其父節點的值都小于等于其子節點的值。
2.按序輸出一棵有 n 個節點樹的關鍵字:
使用最小堆性質來按序輸出一棵有 n 個節點樹的關鍵字是不可行的。原因如下:
-
最小堆保證了每個父節點都比它的子節點小或相等,但沒有保證兄弟節點之間的順序關系。因此,在使用最小堆性質時,不能確保以 O(n) 時間復雜度按序輸出整棵樹的關鍵字。
-
要按照順序輸出一顆二叉搜索樹中所有關鍵字只需要進行中序遍歷即可,在平均情況下時間復雜度為O(n)。
所以,使用最小堆性質在 O(n) 時間內按序輸出一個具有 n 個結點數目的樹是不可行的。而二叉搜索樹適用于按序輸出關鍵字。





單據接口對接)










)


