目錄
AdaBoost算法原理
AdaBoost工作詳情
初始權重分配
第一輪
第二輪
后續輪次
最終模型
AdaBoost的API解釋
AdaBoost 對房價進行預測
AdaBoost 與決策樹模型的比較
結論
AdaBoost算法原理
在數據挖掘中,分類算法可以說是核心算法,其中 AdaBoost算法與隨機森林算法一樣都屬于分類算法中的集成算法.
集成的含義就是集思廣益,博取眾長,當我們做決定的時候,我們先聽取多個專家的意見,再做決定。集成算法通常有兩種方式,分別是投票選舉(bagging)和再學習(boosting)。 投票選舉的場景類似把專家召集到一個會議桌前,當做一個決定的時候,讓 K 個專家(K 個模 型)分別進行分類,然后選擇出現次數最多的那個類作為最終的分類結果。再學習相當于把 K 個專家(K 個分類器)進行加權融合,形成一個新的超級專家(強分類器),讓這個超級專家 做判斷.

AdaBoost 的關鍵在于它會給訓練數據中的每個樣本分配一個權重,并在每一輪迭代中調整這些權重。錯誤分類的樣本在下一輪迭代中會得到更高的權重,從而使弱分類器集中注意力于難以分類的樣本。以下是一個具體的示例來解釋 AdaBoost 算法的原理:
AdaBoost工作詳情
假設我們有一個簡單的二分類問題,訓練數據集包含5個樣本:{x1, x2, x3, x4, x5},它們的真實標簽分別為 {1, -1, 1, 1, -1}。
初始權重分配
首先,每個樣本都被賦予相同的權重,即 1/5。
第一輪
- 訓練第一個弱分類器:例如,一個簡單的決策樹。
- 計算錯誤率:弱分類器在加權訓練數據上的錯誤率。例如,假設它錯誤地分類了樣本
x2和x5。 - 更新樣本權重:增加被錯誤分類的樣本的權重,減少正確分類的樣本的權重。例如,
x2和x5的權重增加,而其余樣本的權重減少。 - 計算分類器權重:基于錯誤率計算分類器權重,錯誤率越低的分類器在最終模型中的權重越高。

第二輪
- 訓練第二個弱分類器:使用更新后的樣本權重。
- 重復計算錯誤率、更新樣本權重和分類器權重的過程。
后續輪次
重復以上步驟,直到達到預定的迭代次數,或者達到某個性能閾值。
最終模型
最終的 AdaBoost 模型是所有弱分類器的加權組合,其中每個弱分類器的貢獻由其權重決定。這樣,模型在預測新數據時,會考慮所有弱分類器的預測并加權得到最終結果。
AdaBoost的API解釋
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’, random_state=None)
這個函數,其中有幾 個比較主要的參數,我分別來講解下:
1. base_estimator:代表的是弱分類器。在 AdaBoost 的分類器和回歸器中都有這個參數, 在 AdaBoost 中默認使用的是決策樹,一般我們不需要修改這個參數,當然你也可以指定 具體的分類器。
2. ? n_estimators:算法的最大迭代次數,也是分類器的個數,每一次迭代都會引入一個新的 弱分類器來增加原有的分類器的組合能力。默認是 50。
3. ? learning_rate:代表學習率,取值在 0-1 之間,默認是 1.0。如果學習率較小,就需要比 較多的迭代次數才能收斂,也就是說學習率和迭代次數是有相關性的。當你調整 learning_rate 的時候,往往也需要調整 n_estimators 這個參數。
4. ? algorithm:代表我們要采用哪種 boosting 算法,一共有兩種選擇:SAMME 和 SAMME.R。默認是 SAMME.R。這兩者之間的區別在于對弱分類權重的計算方式不同。
5. ? random_state:代表隨機數種子的設置,默認是 None。隨機種子是用來控制隨機模式 的,當隨機種子取了一個值,也就確定了一種隨機規則,其他人取這個值可以得到同樣的結果。如果不設置隨機種子,每次得到的隨機數也就不同
AdaBoost 對房價進行預測
了解了 AdaBoost 工具包之后,我們看下 sklearn 中自帶的波士頓房價數據集。這個數據集一共包括了 506 條房屋信息數據,每一條數據都包括了 13 個指標,以及一個房屋 價位。13 個指標的含義,可以參考下面的表格

這些指標分析得還是挺細的,但實際上,我們不用關心具體的含義,要做的就是如何通過這 13 個指標推導出最終的房價結果。
?
首先加載數據,將數據分割成訓練集和測試集,然后創建 AdaBoost 回歸模型,傳入訓練集 數據進行擬合,再傳入測試集數據進行預測,就可以得到預測結果。最后將預測的結果與實際 結果進行對比,得到兩者之間的誤差。具體代碼如下:
from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error from sklearn.datasets import load_boston
from sklearn.ensemble import AdaBoostRegressor
# 加載數據
data=load_boston()
# 分割數據
train_x, test_x, train_y, test_y = train_test_split(data.data, data.target, test_size=0.25, random_state=33)
# 使用AdaBoost回歸模型
regressor=AdaBoostRegressor()regressor.fit(train_x,train_y) 12
pred_y = regressor.predict(test_x)mse = mean_squared_error(test_y, pred_y)
print("房價預測結果 ", pred_y) 15
print("均方誤差 = ",round(mse,2))
同樣,我們可以使用不同的回歸分析模型分析這個數據集,比如使用決策樹回歸和 KNN 回歸。
編寫代碼如下:
# 使用決策樹回歸模型
dec_regressor=DecisionTreeRegressor() dec_regressor.fit(train_x,train_y)
pred_y = dec_regressor.predict(test_x) mse = mean_squared_error(test_y, pred_y)
print("決策樹均方誤差 = ",round(mse,2))# 使用KNN回歸模型
knn_regressor=KNeighborsRegressor()
knn_regressor.fit(train_x,train_y)
pred_y = knn_regressor.predict(test_x)
mse = mean_squared_error(test_y, pred_y)
print("KNN均方誤差 = ",round(mse,2))
你能看到相比之下,AdaBoost 的均方誤差更小,也就是結果更優。雖然 AdaBoost 使用了弱 分類器,但是通過 50 個甚至更多的弱分類器組合起來而形成的強分類器,在很多情況下結果 都優于其他算法。因此 AdaBoost 也是常用的分類和回歸算法之一?
AdaBoost 與決策樹模型的比較
在 sklearn 中 AdaBoost 默認采用的是決策樹模型,我們可以隨機生成一些數據,然后對比 下 AdaBoost 中的弱分類器(也就是決策樹弱分類器)、決策樹分類器和 AdaBoost 模型在 分類準確率上的表現。
如果想要隨機生成數據,我們可以使用 sklearn 中的 make_hastie_10_2 函數生成二分類數 據。假設我們生成 12000 個數據,取前 2000 個作為測試集,其余作為訓練集。有了數據和訓練模型后,我們就可以編寫代碼。我設置了 AdaBoost 的迭代次數為 200,代 表 AdaBoost 由 200 個弱分類器組成。針對訓練集,我們用三種模型分別進行訓練,然后用測試集進行預測,并將三個分類器的錯誤率進行可視化對比,可以看到這三者之間的區別:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.metrics import zero_one_loss
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
# 設置AdaBoost迭代次數
n_estimators=200
# 使用
X,y=datasets.make_hastie_10_2(n_samples=12000,random_state=1)
# 從12000個數據中取前2000行作為測試集,其余作為訓練集
train_x, train_y = X[2000:],y[2000:]
test_x, test_y = X[:2000],y[:2000]
# 弱分類器
dt_stump = DecisionTreeClassifier(max_depth=1,min_samples_leaf=1)
dt_stump.fit(train_x, train_y)
dt_stump_err = 1.0-dt_stump.score(test_x, test_y)
# 決策樹分類器
dt = DecisionTreeClassifier()
dt.fit(train_x, train_y)
dt_err = 1.0-dt.score(test_x, test_y)
# AdaBoost分類器
ada = AdaBoostClassifier(base_estimator=dt_stump,n_estimators=n_estimators)
ada.fit(train_x, train_y)
# 三個分類器的錯誤率可視化
fig = plt.figure()
# 設置plt正確顯示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
ax = fig.add_subplot(111)
ax.plot([1,n_estimators],[dt_stump_err]*2, 'k-', label=u'決策樹弱分類器 錯誤率')
ax.plot([1,n_estimators],[dt_err]*2,'k--', label=u'決策樹模型 錯誤率')
ada_err = np.zeros((n_estimators,))
# 遍歷每次迭代的結果 i為迭代次數, pred_y為預測結果
for i,pred_y in enumerate(ada.staged_predict(test_x)):# 統計錯誤率ada_err[i]=zero_one_loss(pred_y, test_y)
# 繪制每次迭代的AdaBoost錯誤率
ax.plot(np.arange(n_estimators)+1, ada_err, label='AdaBoost Test 錯誤率', color='orange')
ax.set_xlabel('迭代次數')
ax.set_ylabel('錯誤率')
leg=ax.legend(loc='upper right',fancybox=True)
plt.show()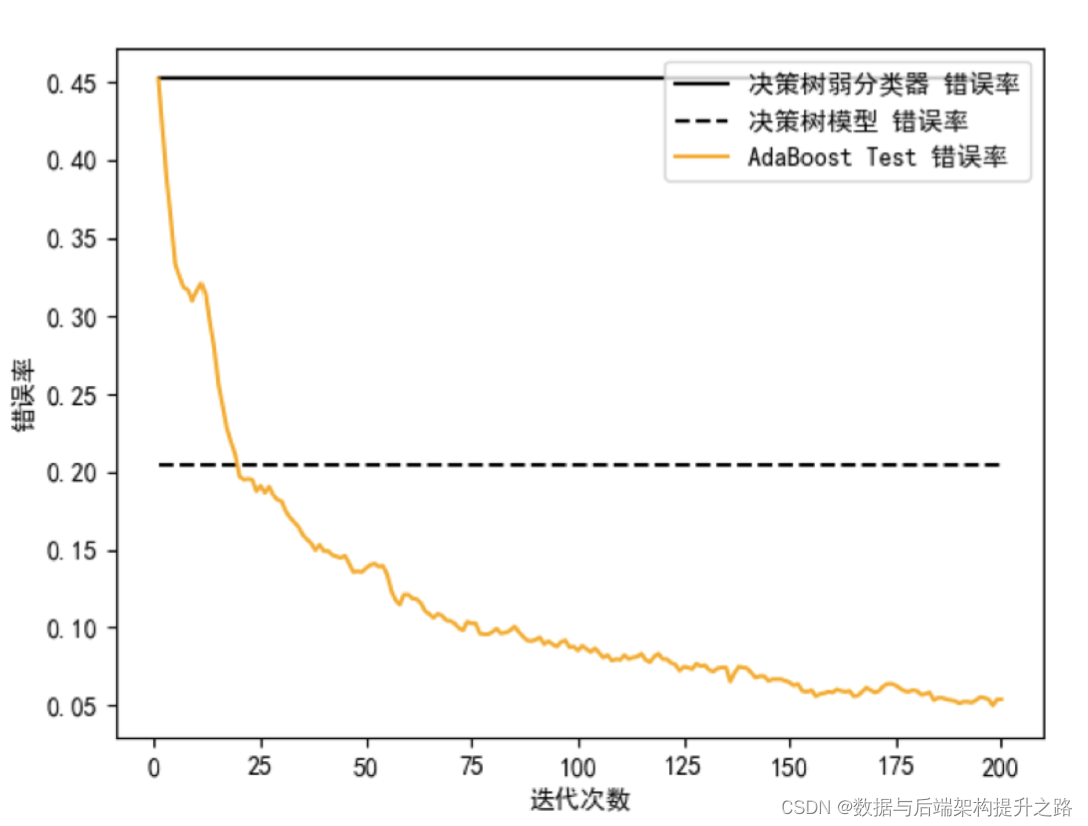
從圖中你能看出來,弱分類器的錯誤率最高,只比隨機分類結果略好,準確率稍微大于 50%。決策樹模型的錯誤率明顯要低很多。而 AdaBoost 模型在迭代次數超過 25 次之后,錯 誤率有了明顯下降,經過 125 次迭代之后錯誤率的變化形勢趨于平緩。
因此我們能看出,雖然單獨的一個決策樹弱分類器效果不好,但是多個決策樹弱分類器組合起來形成的AdaBoost 分類器,分類效果要好于決策樹模型。
結論
AdaBoost 算法有效地集中于那些難以正確分類的樣本,逐漸調整分類器以解決這些難題。這使得 AdaBoost 成為一種強大的集成方法,尤其適用于處理復雜的分類問題。

)
)


——高速通信下解決數據處理慢的問題(20ms以內))

)





![[Android]使用Git將項目提交到GitHub](http://pic.xiahunao.cn/[Android]使用Git將項目提交到GitHub)





