一、需求背景
??????接手一個老項目,在項目啟動的時候,需要將xxx省整個省的所有區域數據數據、以及系統字典配置逐條保存在Redis緩存里面,這樣查詢的時候會更快;
??????區域數據+字典數據一共大概20000多條,,前同事直接使用 list.forEach()逐條寫入Redis,如下:
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
/*** @author xxx* @version 1.0* @date 2022/7/21 15:29* @Description: 項目啟動成功后初始化區域數據到redis*/
@Component
@Slf4j
public class AreasInitialComponent implements ApplicationRunner {@AutowiredprivateAreaMapper areaMapper;private static boolean isStart = false;/*** 項目啟動后,初始化字典到緩存*/@Overridepublic void run(ApplicationArguments args) throws Exception {if (isStart) {return;}try {log.info("Start*******************項目啟動后,初始化字典到緩存*******************");QueryWrapper<Area> wrapper = new QueryWrapper<>();wrapper.eq("del", "0");List<Area> areas = areaMapper.selectList(wrapper);if (!CollectionUtils.isEmpty(areas )) {RedisCache redisCache = SpringUtils.getBean(RedisCache.class);//先將區域集合整體做個緩存log.info("*******************先將區域集合整體做個緩存*******************");AreaUtil.setAreaListCache(redisCache, areas);//再將每一條區域進行緩存areas.stream().forEach(a -> {AreaUtil.setAreaCache(redisCache, a.getId(), a);});}isStart = true;log.info("End*******************項目啟動后,初始化字典到緩存*******************");}catch (Exception e) {e.printStackTrace();}}
}
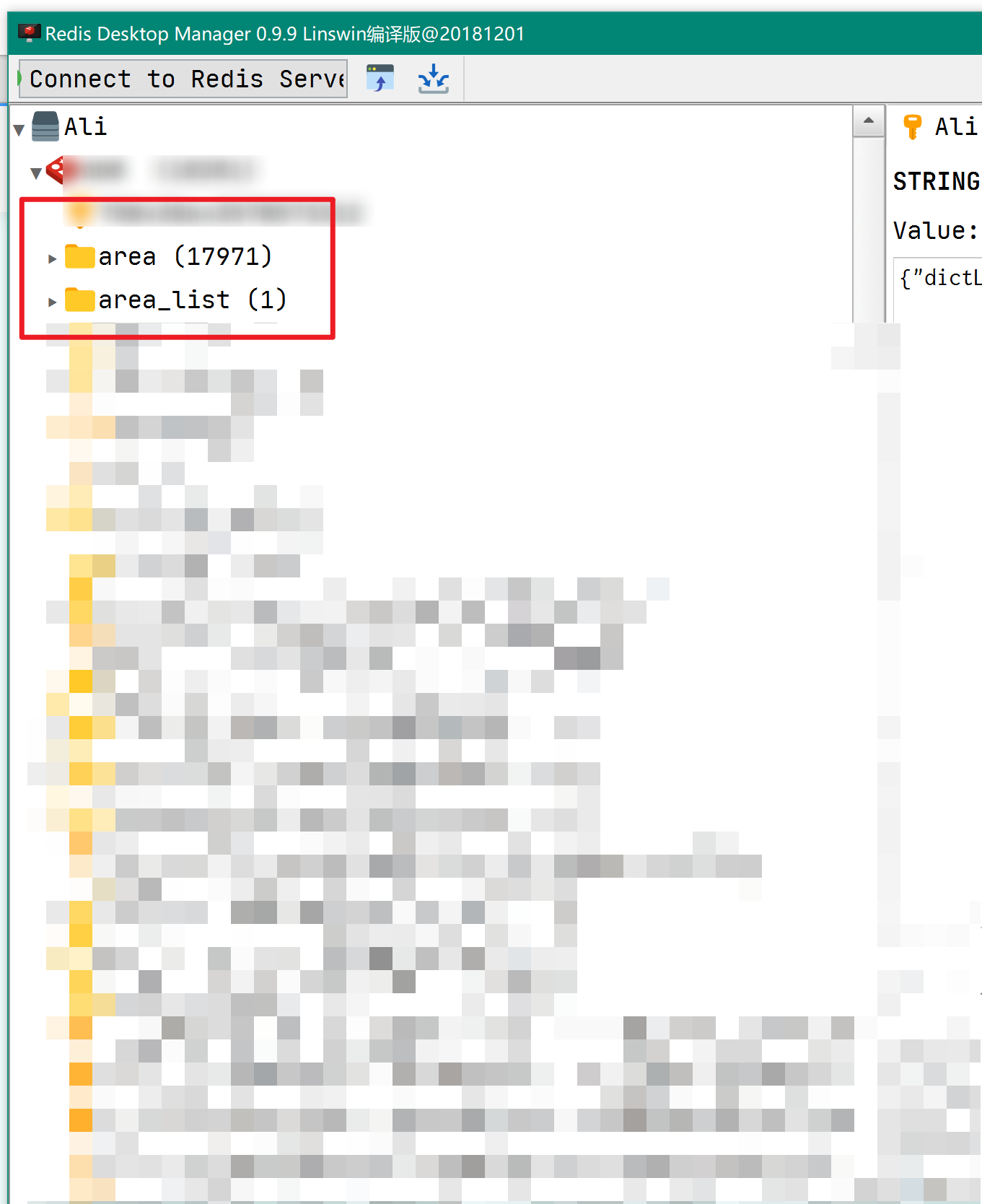
導致項目啟動速度巨慢,再加上需要使用代理軟件才能連接公司的數據庫,每次啟動項目都需要10幾分鐘,當真是苦不堪言;由于受不了這樣的啟動速度,因此決定自己動手優化。
二、解決思路
??????聯想到MySQL的事務打包方式,于是自己動手嘗試通過Redis打包事務+分批提交的方式來提高啟動速度,具體實現如下:
三、實現方法
- 實現方法
@Autowiredpublic RedisTemplate redisTemplate; /*** 逐條設置區域緩存** @param areas* @throws InterruptedException*/public void setAreaCacheItemByItem(List<Area> areas) throws InterruptedException {MoreThreadCallBack<Area> callBack = new MoreThreadCallBack<>();callBack.setThreadCount(10);callBack.setLimitCount(50);callBack.setTitle("設置區域緩存批量任務");callBack.setAllList(areas);callBack.call((list, threadNum) -> {//使用自定義線程回調工具分攤任務redisTemplate.execute(new SessionCallback<Object>() {@Overridepublic Object execute(RedisOperations operations) throws DataAccessException {//開啟redis事務operations.multi();list.forEach(item -> {operations.opsForValue().set(item.getId(), item);});// 提交事務operations.exec();return null;}});});}
- 線程回調工具
MoreThreadCallBack()
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.compress.utils.Lists;import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;@Data
@Slf4j
public class MoreThreadCallBack<P> {public int limitCount = 1000;private int threadCount = 10;private List<P> allList;private AtomicInteger errorCheck;private String title;public interface CallBack<P> {void call(List<P> list, Integer threadNum);}public boolean call(CallBack<P> callBack) throws InterruptedException, RuntimeException {if (allList.isEmpty()) {return false;}// 線程池ExecutorService exec = Executors.newCachedThreadPool();// 根據大小判斷線程數量if (allList.size() <= limitCount) {threadCount = 1;}// 等待結果類final CountDownLatch countDownLatch = new CountDownLatch(threadCount);// 分攤多份List<List<P>> llist = Lists.newArrayList();for (int i = 0; i < threadCount; i++) {llist.add(Lists.newArrayList());}int index = 0;for (P p : allList) {llist.get(index).add(p);index = index == (threadCount - 1) ? 0 : index + 1;}// 異常記錄errorCheck = new AtomicInteger(0);// 執行for (int i = 0; i < llist.size(); i++) {List<P> list = llist.get(i);final Integer threadNum = i;exec.execute(() -> {long startTime = System.currentTimeMillis();//拋出異常 自身不處理log.info("標題:{}-{}號線程開始回調執行 數量:{}", this.getTitle(), threadNum, list.size());callBack.call(list, threadNum);long endTime = System.currentTimeMillis();log.info("標題:{}-{}號線程回調執行完畢 耗時:{}", this.getTitle(), threadNum, +(endTime - startTime));countDownLatch.countDown();});}// 等待處理完畢countDownLatch.await();// 關閉線程池exec.shutdown();return errorCheck.get() <= 0;}public boolean next() {// 檢測是否有線程提前結束if (errorCheck.get() > 0) {return false;}return true;}public void error() {errorCheck.incrementAndGet();}public String getTitle() {return title == null ? "" : title;}
}- 經過如上處理以后,項目啟動速度大大提升,
由原本的10幾分鐘縮短至1分鐘左右,成果如下:
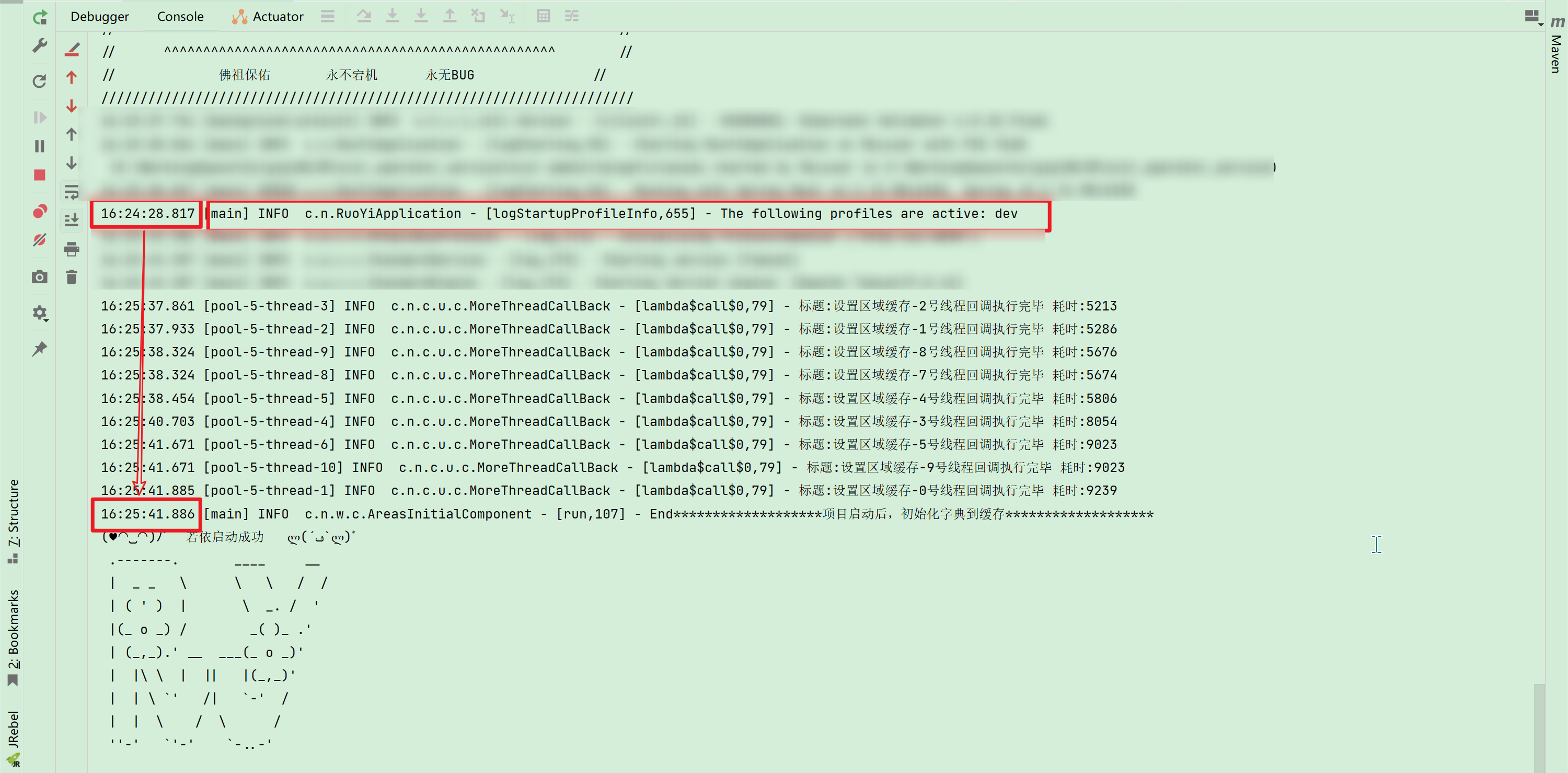









)
![BUUCTF [WUSTCTF2020]find_me 1](http://pic.xiahunao.cn/BUUCTF [WUSTCTF2020]find_me 1)
跳轉及傳值的幾種方式 router-link + query + params)







