
🤵?♂? 個人主頁: @AI_magician
📡主頁地址: 作者簡介:CSDN內容合伙人,全棧領域優質創作者。
👨?💻景愿:旨在于能和更多的熱愛計算機的伙伴一起成長!!🐱?🏍
🙋?♂?聲明:本人目前大學就讀于大二,研究興趣方向人工智能&硬件(雖然硬件還沒開始玩,但一直很感興趣!希望大佬帶帶)

摘要: 本系列旨在普及那些深度學習路上必經的核心概念,文章內容都是博主用心學習收集所寫,歡迎大家三聯支持!本系列會一直更新,核心概念系列會一直更新!歡迎大家訂閱
該文章收錄專欄
[?— 《深入解析機器學習:從原理到應用的全面指南》 —?]
@toc
ARIMA定階解決方案
| 名稱 | 介紹 | 優缺點 |
|---|---|---|
| 自相關函數(ACF)和偏自相關函數(PACF) | 通過觀察ACF和PACF圖像的截尾性和拖尾性來確定AR和MA的階數。 | 優點:簡單直觀,易于理解和實現。 缺點:對于復雜的時間序列,圖像解釋可能不明確;需要主觀判斷截尾和拖尾的位置。 |
| 信息準則(AIC、BIC) | 使用AIC(Akaike Information Criterion)或BIC(Bayesian Information Criterion)來選擇最佳模型階數。 | 優點:基于統計學原理,可自動選擇模型階數。 缺點:對于大規模數據集,計算開銷較大。 |
| 網格搜索 | 遍歷多個ARIMA模型的參數組合,通過交叉驗證或驗證集性能來選擇最佳模型。 | 優點:能夠找到最佳參數組合。 缺點:計算開銷較大,需要嘗試多個參數組合;可能受限于搜索范圍和計算資源。 |
| 自動ARIMA(auto.arima) | 自動選擇ARIMA模型的階數,基于AIC準則進行模型搜索和選擇。 | 優點:自動化流程,省去手動選擇模型階數的步驟。 缺點:對于復雜的時間序列,可能無法找到最佳模型。 |
ACF & PACF 定階
使用**自相關函數(ACF)和偏自相關函數(PACF)**來確定AR和MA的階數。ACF表示觀察值與滯后版本之間的相關性,PACF表示觀察值與滯后版本之間的直接相關性。
下面是ACF(自相關函數)和PACF(偏自相關函數)的繪圖函數及其說明,以及對應的模板代碼。
| 名稱 | 說明 | 模板代碼 |
|---|---|---|
plot_acf | 繪制自相關函數(ACF)圖 | plot_acf(x, lags=None, alpha=0.05, use_vlines=True, title='Autocorrelation', zero=False, vlines_kwargs=None, ax=None) |
plot_pacf | 繪制偏自相關函數(PACF)圖 | plot_pacf(x, lags=None, alpha=0.05, method='ywunbiased', use_vlines=True, title='Partial Autocorrelation', zero=False, vlines_kwargs=None, ax=None) |
函數參數說明:
x:要計算自相關或偏自相關的序列數據。lags:要繪制的滯后階數。默認為None,表示繪制所有滯后階數。alpha:置信區間的置信水平。默認為0.05,表示95%的置信水平。use_vlines:是否在圖中使用垂直線表示置信區間。默認為True。title:圖的標題。默認為"Autocorrelation"(自相關)或"Partial Autocorrelation"(偏自相關)。zero:是否在圖中包含零滯后(lag)線。默認為False。vlines_kwargs:用于控制垂直線屬性的可選參數。ax:用于繪制圖形的matplotlib軸對象。默認為None,表示創建一個新的軸對象。
示例代碼:
對于經典的時間序列數據,您可以使用其他專門的庫來獲取,例如 pandas-datareader、yfinance、Alpha Vantage 等。
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import pandas as pd
from statsmodels.datasets import get_rdataset
from statsmodels.tsa.arima.model import ARIMA# 獲取AirPassengers數據集
#data = get_rdataset('AirPassengers').data # Not do stationate# 示例數據
data = [0, 1, 2, 3, 4, 5,6,7,8,9,10,11,12,13]# 定義繪制自相關圖&偏相關函數
def draw_acf_pcf(ts):sample_size = len(ts)max_lags = sample_size // 2 - 1 # 設置最大滯后期數為樣本大小的50%plt.figure(facecolor='white', figsize=(10, 8))plot_acf(ts)plot_pacf(ts,lags = max_lags)plt.title('自相關圖')plt.show()
當計算部分相關系數時,通常需要注意設置滯后期數(nlags)的值,以確保其不超過樣本大小的50%。這是因為計算部分相關系數需要估計協方差矩陣的逆矩陣,而當滯后期數過大時,逆矩陣的計算可能會變得不穩定。這里默認為50% - 1
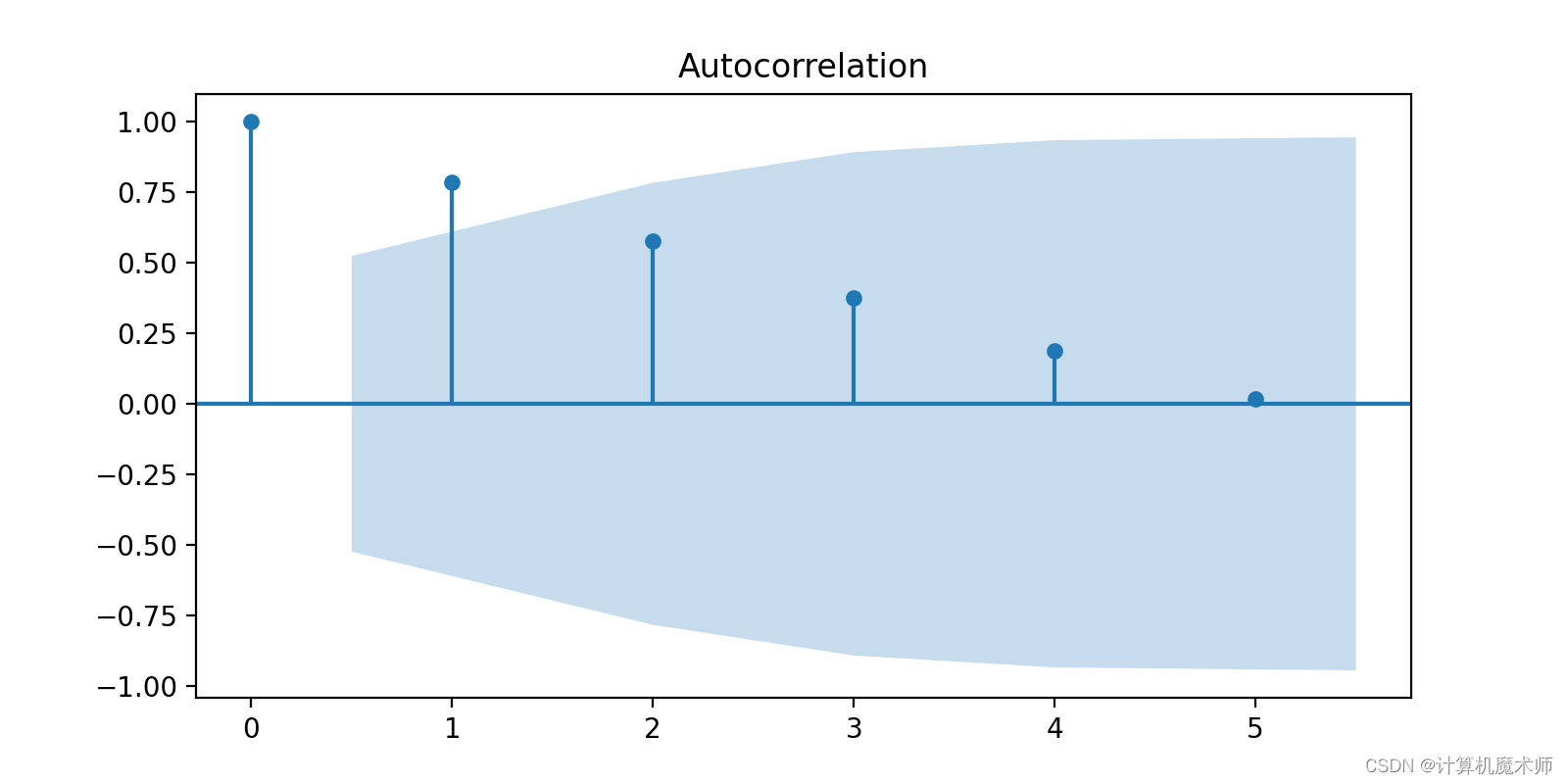
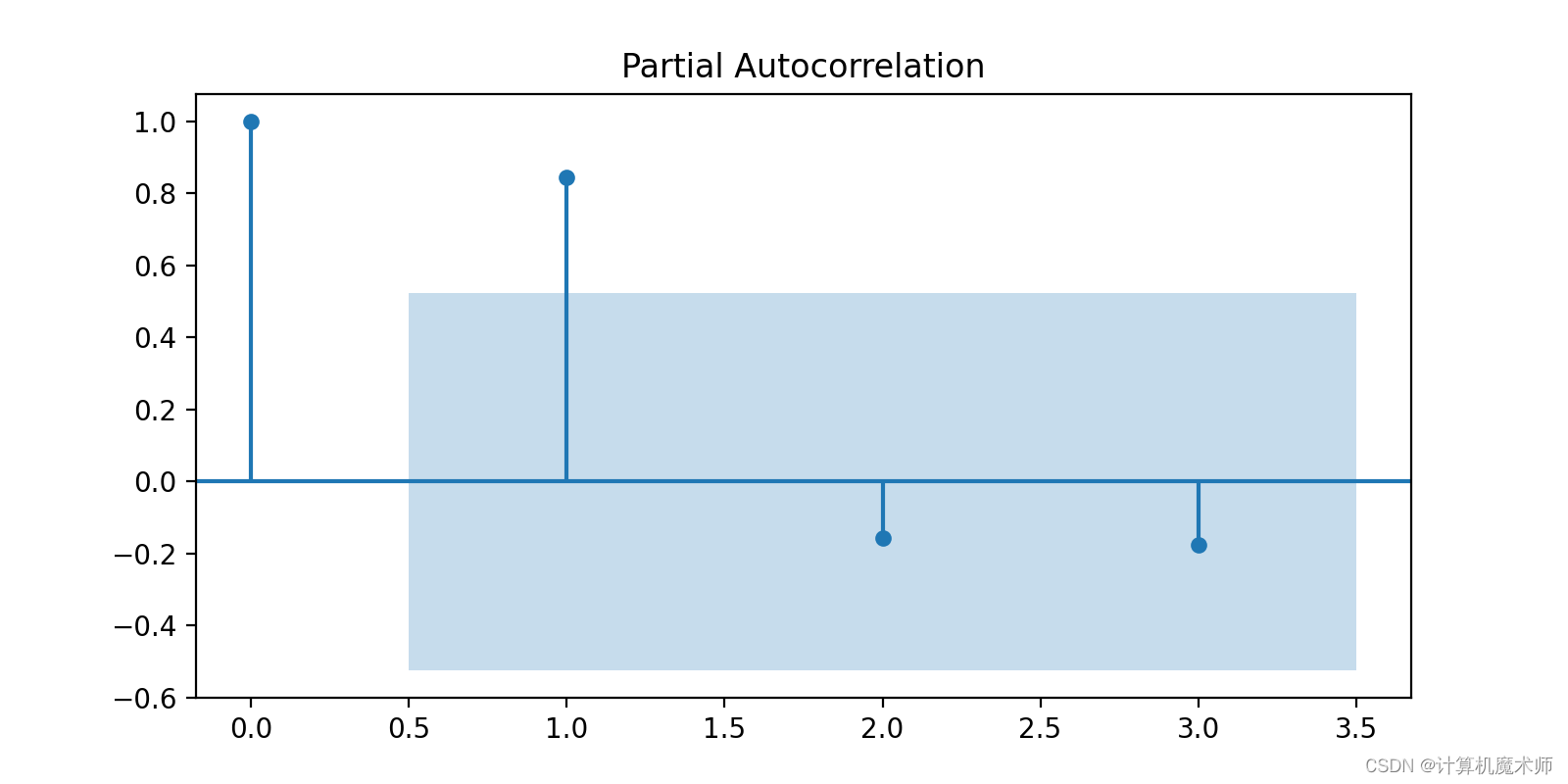
- 觀察ACF圖和PACF圖的截尾性:首先,觀察ACF圖和PACF圖的截尾性。在ACF圖中,如果自相關系數在滯后階數后逐漸衰減并趨于零,這表明可以考慮使用自回歸(AR)模型(拖尾)。在PACF圖中,如果偏相關系數在滯后階數后截尾并趨于零,這表明可以考慮使用滑動平均(MA)模型。(截尾)
- 觀察ACF圖和PACF圖的截尾性:首先,觀察ACF圖和PACF圖的截尾性。在ACF圖中,如果自相關系數在滯后階數后逐漸衰減并趨于零,這表明可以考慮使用自回歸(AR)模型。在PACF圖中,如果偏相關系數在滯后階數后截尾并趨于零,這表明可以考慮使用滑動平均(MA)模型。
- 確定AR模型階數:根據ACF圖的截尾性,確定AR模型的階數。階數可以根據ACF圖中第一個超過置信區間的滯后階數來確定。
- 確定MA模型階數:根據PACF圖的截尾性,確定MA模型的階數。階數可以根據PACF圖中第一個超過置信區間的滯后階數來確定。
- 確定ARMA模型階數:如果ACF圖和PACF圖都有截尾性,可以考慮使用ARMA模型。階數可以根據ACF圖和PACF圖的信息共同確定。
- 確定AR模型階數:根據ACF圖的截尾性,確定AR模型的階數。階數可以根據ACF圖中第一個超過置信區間的滯后階數來確定。
- 確定MA模型階數:根據PACF圖的截尾性,確定MA模型的階數。階數可以根據PACF圖中第一個超過置信區間的滯后階數來確定。
- 確定ARMA模型階數:如果ACF圖和PACF圖都有截尾性,可以考慮使用ARMA模型。階數可以根據ACF圖和PACF圖的信息共同確定。
可以看到自相關圖出現拖尾,而偏向關圖在2階截尾,所以選用ARIMA(2, K , 1)
信息準則(AIC、BIC)定階
信息準則(Information Criteria)是一種用于模型選擇和定階(model selection and model order determination)的統計方法。其中兩個常用的信息準則是AIC(Akaike Information Criterion)和BIC(Bayesian Information Criterion)。它們的目標是在考慮模型擬合優度的同時,懲罰模型復雜度,避免過度擬合。
AIC和BIC的原理都基于信息理論。信息理論是研究信息傳輸、壓縮和表示的數學理論,其中一個重要概念是信息熵(Information Entropy)。信息熵度量了一個隨機變量的不確定性或信息量。
AIC的計算公式為:AIC = 2k - 2ln(L),其中k是模型參數的數量,L是似然函數的最大值。AIC的原理是通過最大化似然函數來擬合數據,然后用模型參數的數量k對擬合優度進行懲罰。AIC的數值越小,表示模型的擬合優度越好。
BIC的計算公式為:BIC = k * ln(n) - 2ln(L),其中k是模型參數的數量,n是樣本量,L是似然函數的最大值。BIC的原理是在AIC的基礎上引入了對樣本量n的懲罰。BIC的數值越小,表示模型的擬合優度越好。
下面通過一個簡單的案例來說明AIC和BIC的應用:
假設有一個簡單的線性回歸模型,要根據數據集選擇模型的階數(即變量的數量)。
假設我們有以下數據集:
X = [1, 2, 3, 4, 5]
Y = [2, 4, 6, 8, 10]
我們可以考慮的模型階數有1、2、3、4。對于每個階數,我們擬合相應的線性回歸模型,并計算AIC和BIC的值。
階數為1時,模型為 Y = β0 + β1X
階數為2時,模型為 Y = β0 + β1X + β2X^2
階數為3時,模型為 Y = β0 + β1X + β2X^2 + β3X^3
階數為4時,模型為 Y = β0 + β1X + β2X^2 + β3X^3 + β4X^4
對于每個模型,我們可以計算出似然函數的最大值(最小二乘法),然后帶入AIC和BIC的計算公式得到相應的值。假設計算結果如下:
階數1的AIC = 10.2,BIC = 12.4
階數2的AIC = 8.5,BIC = 12.0
階數3的AIC = 7.8,BIC = 12.8
階數4的AIC = 9.1,BIC = 15.6
根據AIC和BIC的值,我們可以選擇AIC和BIC值最小的模型作為最優模型。在這個案例中,階數為3的模型具有最小的AIC和BIC值,因此我們選擇階數為3的模型作為最優模型。
這個案例說明了AIC和BIC在模型選擇和定階中的應用過程。它們通過考慮模型的擬合優度和復雜度,幫助我們選擇最優的模型,避免過度擬合。
以下是使用庫的的實現,
# 通過BIC矩陣進行模型定階
data_w = data_w.astype(float)
pmax = 3 # 可以根據圖選定
qmax = 3
bic_matrix = [] # 初始化BIC矩陣
for p in range(pmax+1):tmp = []for q in range(qmax+1):try:tmp.append(ARIMA(data_w, (p, 2, q)).fit().bic) except:tmp.append(None)bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix)
# 找出最小值位置
p, q = bic_matrix.stack().idxmin()
print('當BIC最小時,p值和q值分別為: ', p, q)
以下是具體代碼實現,查看細節可以更好了解原理
import numpy as np
from sklearn.linear_model import LinearRegression
from scipy.stats import normdef calculate_aic(n, k, rss):aic = 2 * k - 2 * np.log(rss)return aicdef calculate_bic(n, k, rss):bic = k * np.log(n) - 2 * np.log(rss)return bic# 生成示例數據
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
Y = np.array([2, 4, 6, 8, 10])# 計算模型的AIC和BIC值
n = len(X) # 樣本量
aic_values = []
bic_values = []for k in range(1, 5): # 嘗試不同的階數model = LinearRegression()model.fit(X[:, :k], Y)y_pred = model.predict(X[:, :k])rss = np.sum((Y - y_pred) ** 2) # 殘差平方和aic = calculate_aic(n, k, rss)bic = calculate_bic(n, k, rss)aic_values.append(aic)bic_values.append(bic)# 選擇最優模型的階數
best_aic_index = np.argmin(aic_values)
best_bic_index = np.argmin(bic_values)best_aic_order = best_aic_index + 1
best_bic_order = best_bic_index + 1print("AIC values:", aic_values)
print("BIC values:", bic_values)
print("Best AIC order:", best_aic_order)
print("Best BIC order:", best_bic_order)
其實就是在機器學習的根據參數和殘差作為損失值,選擇損失值最小的

🤞到這里,如果還有什么疑問🤞🎩歡迎私信博主問題哦,博主會盡自己能力為你解答疑惑的!🎩🥳如果對你有幫助,你的贊是對博主最大的支持!!🥳
)





)




主析取范式)

)
小白也可以看懂)




