文章目錄
- 一. 線程安全概述
- 1. 什么是線程安全問題
- 2. 一個存在線程安全問題的程序
- 二. 線程不安全的原因和線程加鎖
- 1. 案例分析
- 2. 線程加鎖
- 2.1 理解加鎖
- 2.2 synchronized的使用
- 2.3 再次分析案例
- 3. 線程不安全的原因
- 三. 線程安全的標準類
一. 線程安全概述
1. 什么是線程安全問題
我們知道操作系統中線程程的調度是搶占式執行的, 宏觀上上的感知是隨機的, 這就導致了多線程在進行線程調度時線程的執行順序是不確定的, 因此多線程情況下的代碼的執行順序可能就會有無數種, 我們需要保證這無數種線程調度順序的情況下, 代碼的執行結果都是正確的, 只要有一種情況下, 代碼的結果沒有達到預期, 就認為線程是不安全的, 對于多線程并發時會使程序出現BUG的代碼稱作線程不安全的代碼, 這就是線程安全問題.
2. 一個存在線程安全問題的程序
定義一個變量count, 初始值為0, 我們想要利用兩個線程將變量count自增10萬次, 每個線程各自負責5萬次的自增任務.
于是寫出了如下代碼:
class Counter {public int count = 0;public void add() {count++;}
}public class TestDemo12 {public static void main(String[] args) {Counter counter = new Counter();// 搞兩個線程, 兩個線程分別針對 counter 來 調用 5w 次的 add 方法Thread t1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {counter.add();}});Thread t2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {counter.add();}});// 啟動線程t1.start();t2.start();// 等待兩個線程結束try {t1.join();t2.join();} catch (InterruptedException e) {e.printStackTrace();}// 打印最終的 count 值System.out.println("count = " + counter.count);}
}
執行結果:
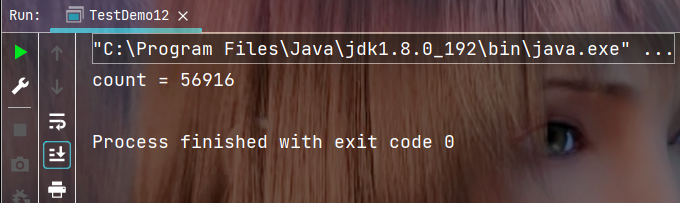
我們預期的結果應該時10萬, 但得到得結果明顯要比10萬小很多, 你可以嘗試將程序多運行幾次你會發現程序每次運行的結果都不一樣, 但絕大部分結果, 都會比預期值要小, 下面就來分析這種結出現的原因.
二. 線程不安全的原因和線程加鎖
1. 案例分析
在上面, 我們使用多線程所寫的程序將將一個初始值為0的變量自增10萬次, 但得到的實際得到的結果要比預期的10萬小, 萬惡之源還是線程的搶占式執行, 線程調度的順序是隨機的, 就造成線程間自增的指令集交叉, 導致運行時出現兩次或者多次自增但值只會自增一次的情況, 導致得到的結果會偏小.
一次的自增操作本質上可以分成三步:
- 把內存中變量的值讀取到CPU的寄存器中(
load). - 在寄存器中執行自增操作(
add) - 將寄存器的值保存至內存中(
save)
如果是兩個線程并發的執行count++, 此時就相當于兩組 load, add, save進行執行, 此時不同的線程調度順序就可能會產生一些結果上的差異.
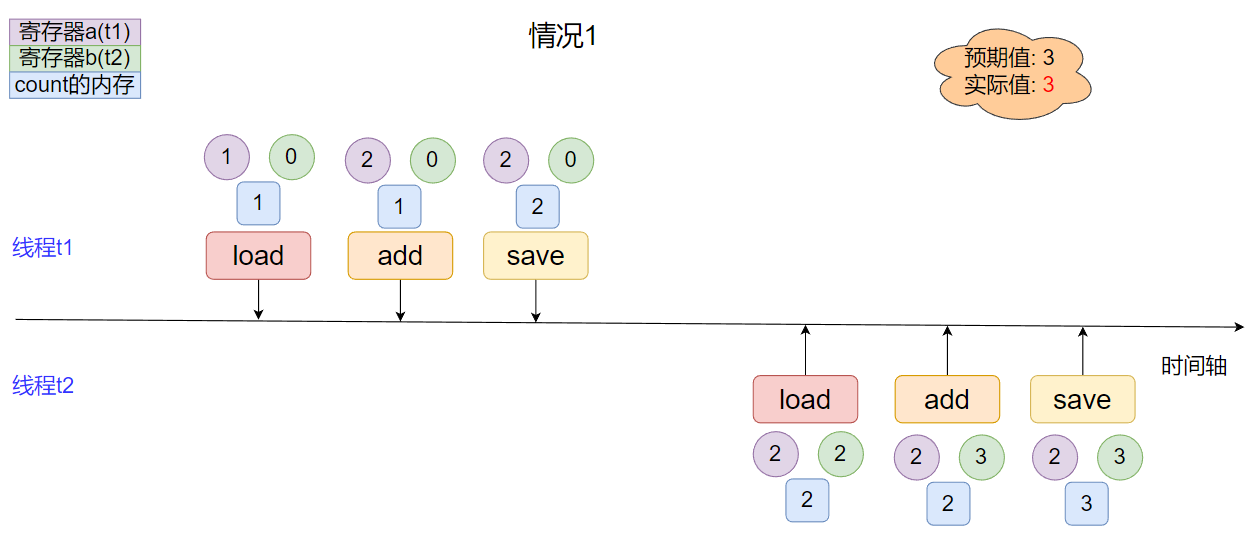
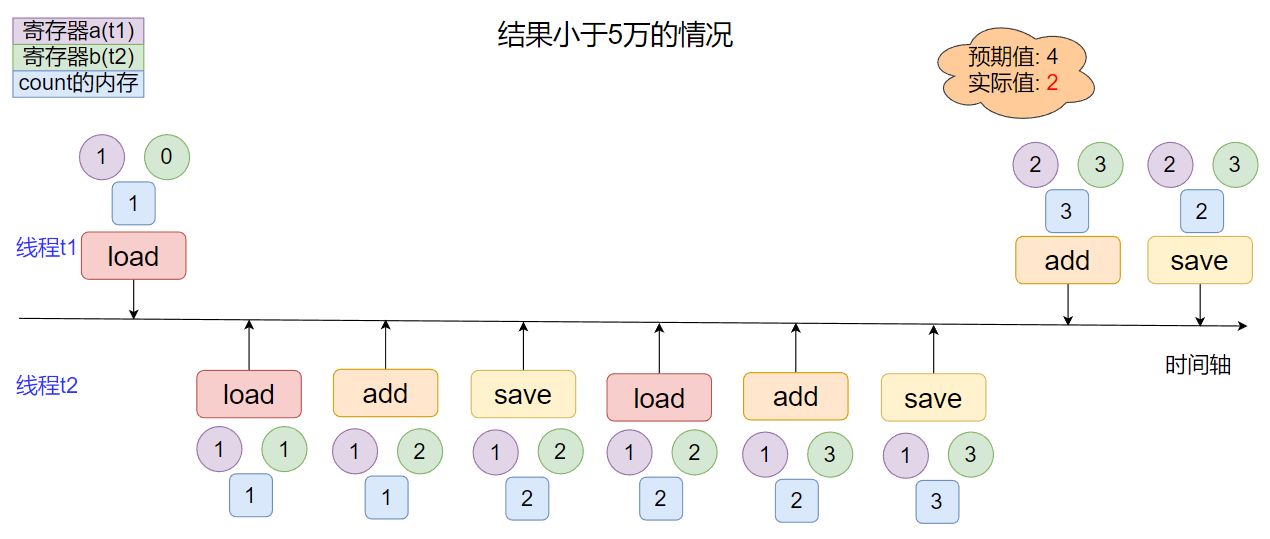
下面的時間軸總結了一個變量由兩個線程并發進行兩次自增時, 常見幾種常見的情況:
- 情況1
線程間指令集無交叉, 實際結果和預期結果一致.
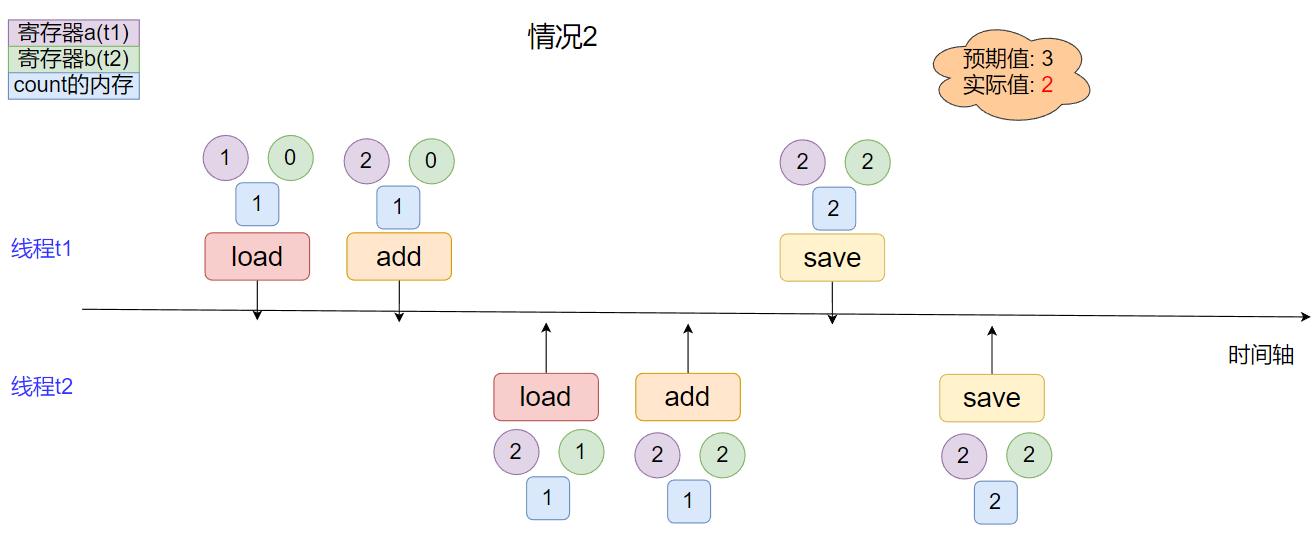
- 情況2
線程間指令集存在交叉, 實際結果小于預期結果.
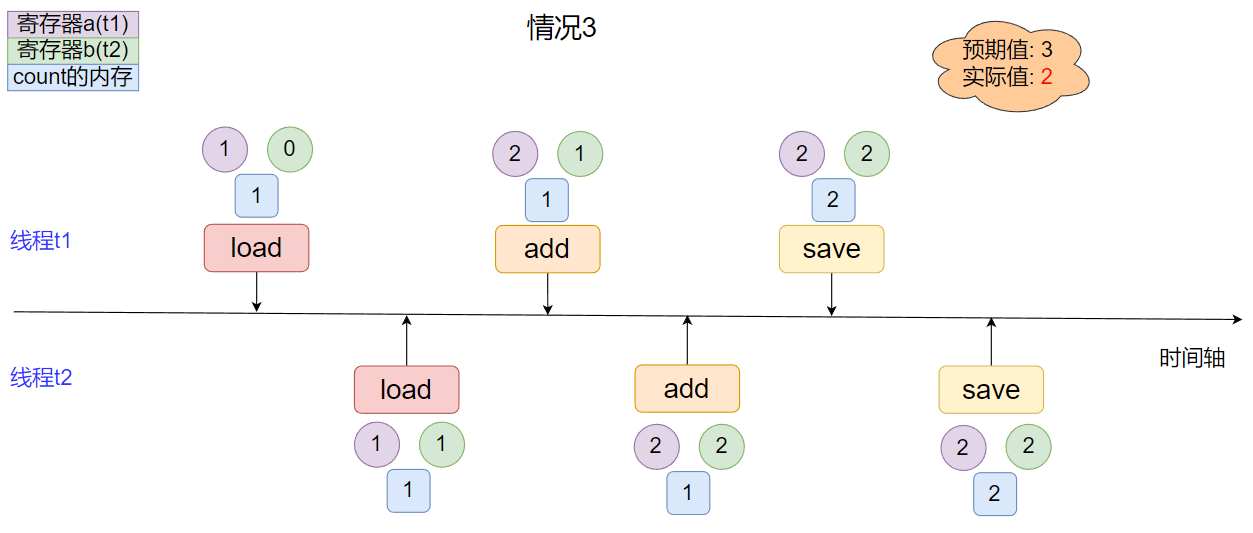
- 情況3
線程間指令集完全交叉, 實際結果小于預期結果.
上面列舉的三種情況并不是所有可能狀況, 其他狀況也類似, 可以自己嘗試推導一下, 觀察上面列出的情況情況, 我們不難發現出當多線程的指令集沒有交叉情況出現的時侯, 程序就可以得到正確的結果; 而一旦指令集間有了交叉, 結果就可能會比預期的要小, 也就是說造成這里線程安全問題的原因在于這里的自增操作不是原子性的.
那么再觀察上面有問題的結果, 思考結果一定是大于5萬嗎, 其實不一定, 只是這種可能性比較小, 當線程當t2自增兩次或多次,t1只自增一次, 最后的效果是加1.
當然也有可能最后計算出來的結果是正確的, 不過再這種有問題的情況下可能就更小了, 但并不能說完全沒有可能.
那么如何解決上面的線程安全問題呢, 我們只需要想辦法讓自增操作變成原子性的即可, 也就是讓load, add, save三步編程一個整體, 也就是下面介紹的對對象加鎖.
2. 線程加鎖
2.1 理解加鎖
為了解決由于 “搶占式執行” 所導致的線程安全問題, 我們可以針對當前所操作的對象進行加鎖, 當一個線程拿到該對象的鎖后, 就會將該對象鎖起來, 其他線程如果需要執行該對象所限制任務時, 需要等待該線程執行完該對象這里的任務后才可以.
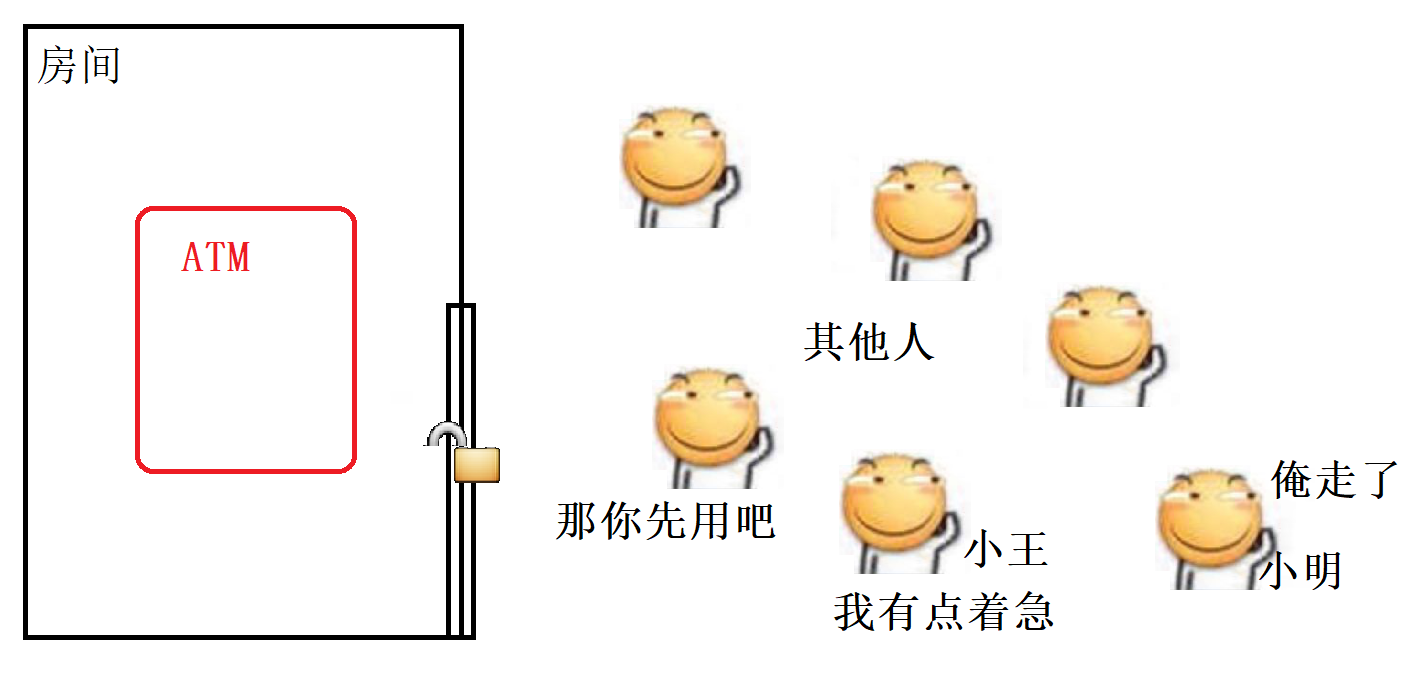
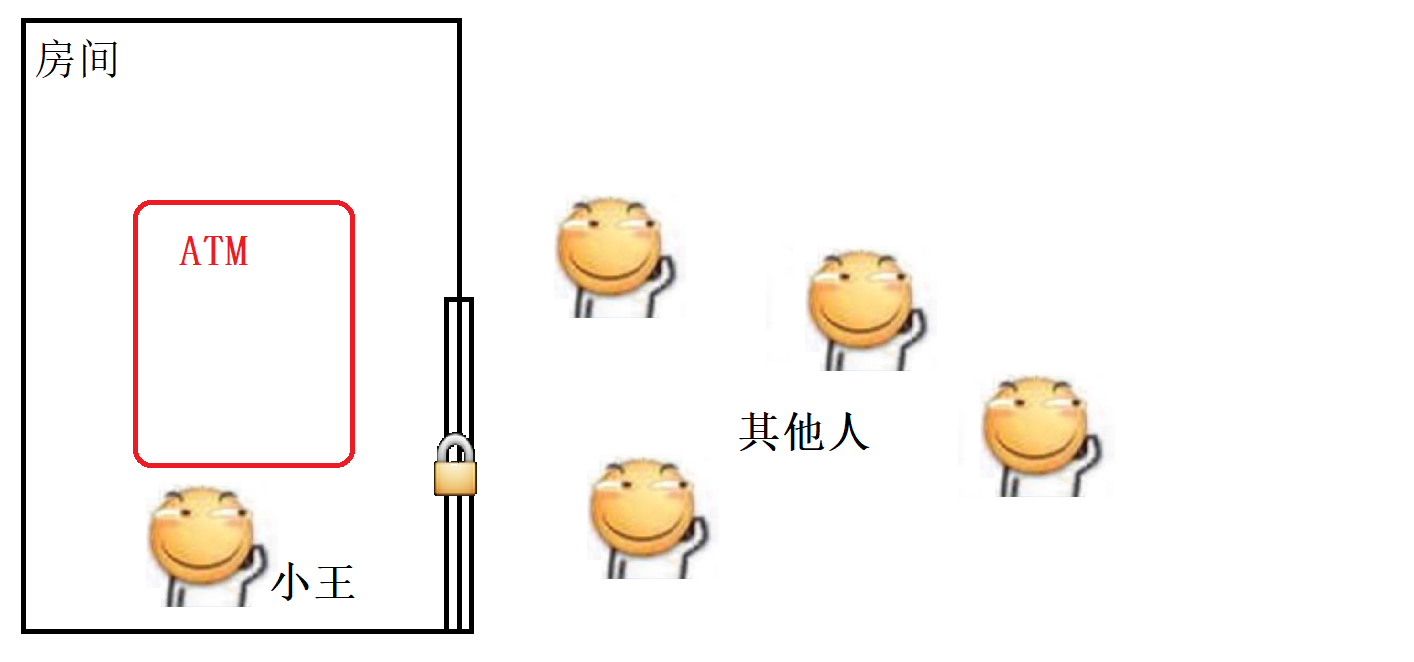
用現實生活中的例子來理解, 假設小明要去銀行的ATM機子上辦理業務, 我們知道為了安全, 每臺ATM一般都在一個單獨的小房間里面, 這個小房間由一扇門和一把鎖, 當小明進入房間使用ATM時, 門就會自動鎖上, 此時如果其他人想要使用這臺ATM就得等小明使用完從房間里面出來才行, 那么這里的 “小明” 就相當于一個線程, ATM就相當于一個對象, 房間就相當于一把鎖, 其他想使用這臺ATM機子的人就相當于其他的線程.

在Java中最常用的加鎖操作就是使用synchronized關鍵字進行加鎖.
2.2 synchronized的使用
synchronized 會起到互斥效果, 某個線程執行到某個對象的 synchronized 中時, 其他線程如果也執行到同一個對象 synchronized 就會阻塞等待.
線程進入 synchronized 修飾的代碼塊, 相當于加鎖, 退出 synchronized 修飾的代碼塊, 相當于解鎖.
- 使用方式1
使用synchronized關鍵字修飾普通方法, 這樣會給方法所對在的對象加上一把鎖.
以上面的自增代碼為例, 對add()方法和加鎖, 實質上是個一個對象加鎖, 在這里這個鎖對象就是this.
class Counter {public int count = 0;synchronized public void add() {count++;}
}
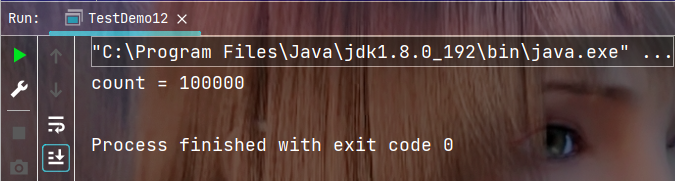
對代碼做出如上修改后, 執行結果如下:
- 使用方式2
使用synchronized關鍵字對代碼段進行加鎖, 需要顯式指定加鎖的對象.
還是基于最開始的代碼進行修改, 如下:
class Counter {public int count = 0;public void add() {synchronized (this) {count++;}}
}
執行結果:

- 使用方式3
使用synchronized關鍵字修飾靜態方法, 相當于對當前類的類對象進行加鎖.
class Counter {public static int count = 0;synchronized public static void add() {count++;}
}
執行結果:
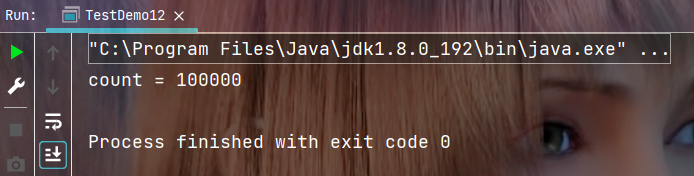
2.3 再次分析案例
我們這里再來分析一下, 為什么上鎖之后, 線程就安全了, 代碼如下:
class Counter {public int count = 0;public void add() {count++;}
}public class TestDemo12 {public static void main(String[] args) {Counter counter = new Counter();// 搞兩個線程, 兩個線程分別針對 counter 來 調用 5w 次的 add 方法Thread t1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {counter.add();}});Thread t2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {counter.add();}});// 啟動線程t1.start();t2.start();// 等待兩個線程結束try {t1.join();t2.join();} catch (InterruptedException e) {e.printStackTrace();}// 打印最終的 count 值System.out.println("count = " + counter.count);}
}
加鎖, 其實就是想要保證這里自增操作 load, add, save的原子性, 但這里上鎖后并不是說讓這三步一次完成, 也不是在執行這三步過程中其他線程不進行調度, 加鎖后其實是讓其他想操作的線程阻塞等待了.
比如我們考慮兩個線程指令集交叉的情況下, 加鎖操作是如何保證線程安全的, 不妨記加鎖為lock,解鎖為unlock, t1和t2兩個線程的運行過程如下:
t1線程首先獲取到目標對象的鎖, 對對象進行了加鎖, 處于lock狀態, t1線程load操作之后, 此時t2線程來執行自增操作時會發生阻塞, 直到t1線程的自增操作執行完成后, 釋放鎖變為unlock狀態, 線程才能成功獲取到鎖開始執行load操作… , 如果有兩個以上的線程以此類推…

加鎖本質上就是把并發變成了串行執行, 這樣的話這里的自增操作其實和單線程是差不多的, 甚至上由于add方法, 要做的事情多了加鎖和解鎖的開銷, 多線程完成自增可能比單線程的開銷還要大, 那么多線程是不是就沒用了呢? 其實不然, 對方法加鎖后, 線程運行該方法才會加鎖, 執行完該方法的操作后就會解鎖, 此方法外的代碼并沒有受到限制, 這部分程序還是可以多線程并發執行的, 這樣整體上多線程的執行效率還是要比單線程要高許多的.
注意:
- 加鎖, 一定要明確是對哪個對象加的鎖, 如果兩個線程針對同一個對象加鎖, 會產生阻塞等待(鎖競爭/鎖沖突); 而如果兩個線程針對不同對象加鎖, 不會產生鎖沖突.
3. 線程不安全的原因
- 最根本的原因: 搶占式執行, 隨機調度, 這個原因我們無法解決.
- 代碼結構.
我們最初給出的代碼之所以有線程安全的原因, 是因為我們設計的代碼是讓兩個線程同時去修改一個相同的變量.
如果我們將代碼設計成一個線程修改一個變量, 多個線程讀取同一個變量, 多個線程修改多個不同的變量等, 這些情況下, 都是線程安全的; 所以我們可以通過調整代碼結構來規避這個問題, 但代碼結構是來源于需求的, 這種調整有時候不是一個普適性特別高的方案.
- 原子性.
如果我們的多線程操作中修改操作是原子的, 那出問題的概率還比較小, 如果是非原子的, 出現問題的概率就非常高了, 就比如我們最開頭寫的程序以及上面的分析.
- 指令重排序和內存可見性問題
主要是由于編譯器優化造成的指令重排序和內存可見性無法保證, 就是當線程頻繁地對同一個變量進行讀取操作時, 一開始會讀內存中的值, 到了后面可能就不會讀取內存中的值了, 而是會直接從寄存器上讀值, 這樣如果內存中的值做出修改時, 線程就感知不到這個變量已經被修改, 就會導致線程安全問題, 歸根結底這是編譯器優化的結果, 編譯器/jvm在多線程環境下產生了誤判, 結合下面的代碼進行理解:
import java.util.Scanner;class MyCounter {volatile public int flag = 0;
}public class TestDemo13 {public static void main(String[] args) {MyCounter myCounter = new MyCounter();Thread t1 = new Thread(() -> {while (myCounter.flag == 0) {// 這個循環體咱們就空著}System.out.println("t1 循環結束");});Thread t2 = new Thread(() -> {Scanner scanner = new Scanner(System.in);System.out.println("請輸入一個整數: ");myCounter.flag = scanner.nextInt();});t1.start();t2.start();}
}
執行結果:

上面的代碼中, t2線程修改flag的值讓t1線程結束, 但當我們修改了flag的值后線程t1線程并沒有終止, 這就是編譯優化導致線程感知不到內存的變化, 從而導致線程不安全.
while (myCounter.flag == 0) {
// 這個循環體咱們就空著
}
t1線程中的這段代碼用匯編來理解, 大概是下面兩步操作:
load, 把內存中flag的值讀取到寄存器中.cmp, 把寄存器的值和0進行比較, 根據比較結果, 決定下一步往哪個地方執行(條件跳轉指令).
要知道, 計算機中上面這個循環的執行速度是極快的, 一秒鐘執行百萬次以上, 在這許多次循環中, 在t2真正修改之前, load得到的結果都是一樣的, 另一方面, CPU 針對寄存器的操作, 要比內存操作快很多, 也就是說load操作和cmp操作相比, 速度要慢的多, 此時jvm就針對這些操作做出了優化, jvm判定好像是沒人修改flag的值的, 于是在之后就不再真正的重復load, 而是直接讀取寄存器當中的值.
所以總結這里的內存可見性問題就是, 一個線程針對一個變量進行讀取操作, 同時另一個線程針對這個變量進行修改, 此時讀到的值, 不一定是修改之后的值, 這個讀線程沒有感知到變量的變化.
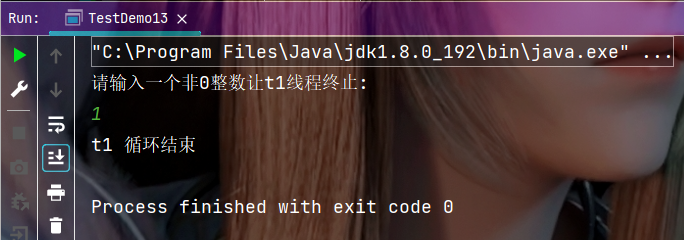
但實際上flag的值是有人修改的, 為了解決這個問題, 我們可以使用volatile關鍵字保證內存可見性, 我們可以給flag這個變量加上volatile關鍵字, 意思就是告訴編譯器,這個變量是 “易變” 的, 一定要每次都重新讀取這個變量的內存內容, 不可以進行優化了.
class MyCounter {volatile public int flag = 0;
}
修改后的執行結果:
編譯器優化除了導致的內存可見性問題會有線程安全問題, 還有指令重排序也會導致線程安全問題, 指令重排序通俗點來講就是編譯器覺得你寫的代碼太垃圾了, 就把你的代碼自作主張進行了調整, 也就是編譯器會智能的在保持原有邏輯不變的情況下, 調整代碼的執行順序, 從而加快程序的執行效率.
上面所說的原因并不是造成線程安全的全部原因, 一個代碼究竟是線程安全還是不安全, 都得具體問題具體分析, 難以一概而論, 如果一個代碼踩中了上面的原因,也可能是線程安全, 而如果一個代碼沒踩中上面的原因,也可能是線程不安全的, 我們寫出的多線程代碼, 只要不出bug, 就是線程安全的.
JMM模型 :
在看內存可見性問題時, 還可能碰到JMM(Java Memory Model)模型, 這里簡單介紹一下, JMM其實就是把操作系統中的寄存器, 緩存(cache)和內存重新封裝了一下, 在JMM中寄存器和緩存稱為工作內存, 內存稱為主內存; 其中緩存和寄存器一樣是在CPU上的, 分為一級緩存L1, 二級緩存L2和三級緩存L3, 從L1到L3空間越來越大, 最大也比內存空間小, 最小也比寄存器空間大,訪問速度越來越慢, 最慢也比內存的訪問速度快, 最快也沒有寄存器訪問快.
synchronized與volatile關鍵字的區別:
synchronized關鍵字能保證原子性, 但是是否能夠保證內存可見性是不一定的, 而volatile關鍵字只能保證內存可見性不能保證原子性.
三. 線程安全的標準類
Java 標準庫中很多都是線程不安全的, 這些類可能會涉及到多線程修改共享數據, 又沒有任何加鎖措施, 這些類在多線代碼中使用要格外注意,下面列出的就是一些線程不安全的集合:
- ArrayList
- LinkedList
- HashMap
- TreeMap
- HashSet
- TreeSet
- StringBuilder
但是還有一些是線程安全的, 使用了一些鎖機制來控制, 如下:
- Vector (不推薦使用)
- HashTable (不推薦使用)
- ConcurrentHashMap
- StringBuffer
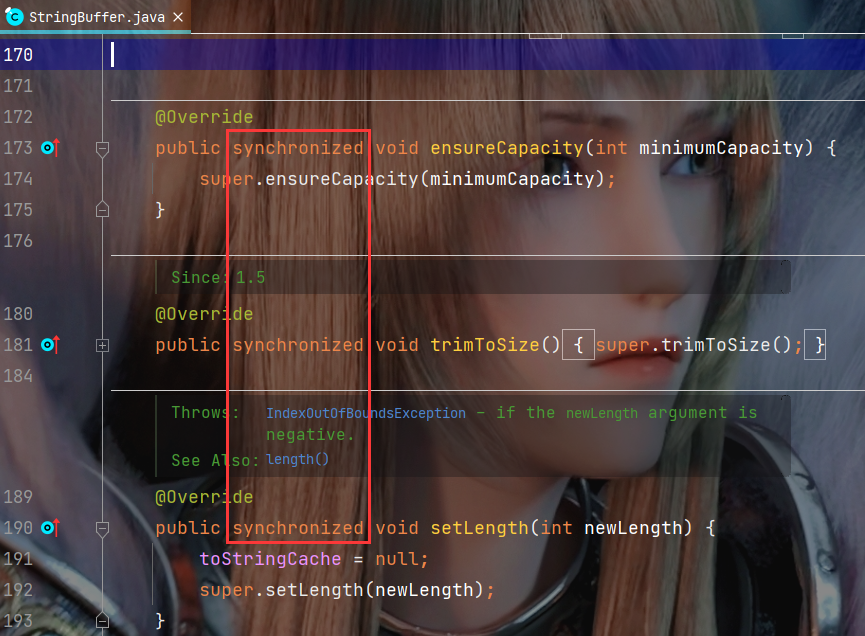
比如我們可以看一下StringBuffer中的方法, 絕大多數都是加鎖了的.
還有的雖然沒有加鎖, 但是不涉及 “修改”, 仍然是線程安全的:
- String
我們需要的知道的是加速操作是有副作用的, 在加鎖的同時, 會帶來額外的時間開銷, 那些線程安全的類已經強制加鎖了, 但有些情況下, 不使用多線程是沒有線程安全問題的, 這個時候使用那些線程不安全感的類更好一些, 而且使用這些線程不安全的類更靈活, 就算面臨線程安全問題, 我們可以自行手動加鎖, 有更多的選擇空間.

)




主析取范式)

)
小白也可以看懂)









)