這里寫自定義目錄標題
- 參考資料
- 比較和分類
- 基礎知識
- 16.3 有模型學習
- 16.3.1 策略評估
- 遞歸形式:Bellman 等式
- 16.3.2 策略改進
- 16.3.3 策略迭代
- 16.3.3 值迭代
- 16.4 免模型學習
- on-policy off-policy
- 16.4.1 蒙特卡羅強化學習
- 16.4.2 時序差分學習
- Sarsa算法:同策略算法(on-policy):行為策略是目標策略
- Q-learning算法:異策略算法(off-policy):行為策略不是目標策略
- 多步時序差分:無偏且方差小
- 16.5 值函數近似
- 16.6 模仿學習
- 16.6.1 直接模仿學習
- 16.6.2 逆強化學習(inverse RL)
- 生成式對抗模仿學習(generative adversarial imitation learning,GAIL)
- 深度Q網絡算法
- 經驗回放(experience replay)
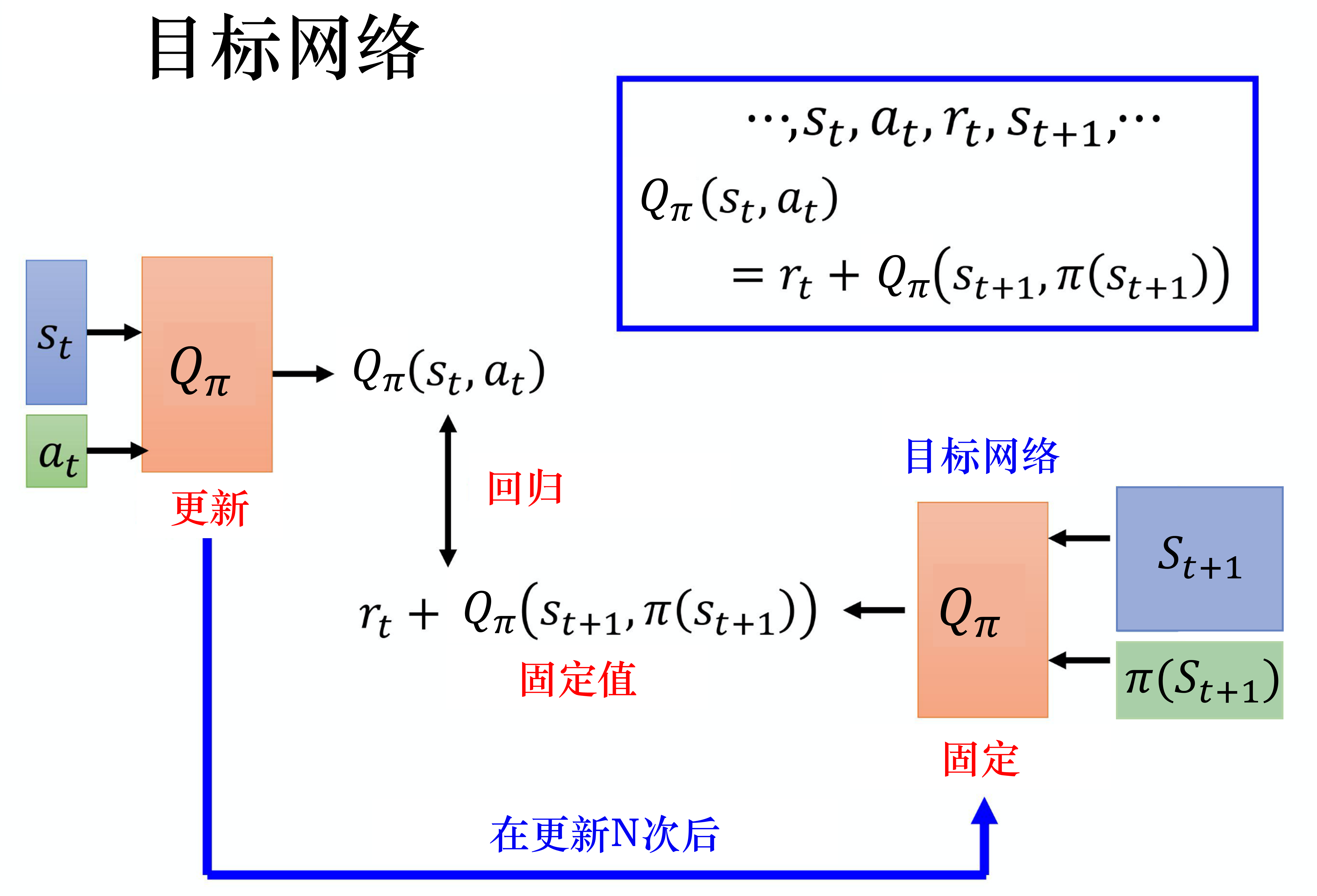
- 目標網絡(target network)
- deep Q network, DQN
- Double Deep Q-Network
- 優先級經驗回放 (prioritized experience replay, PER)
- Dueling Deep Q-Network
- 策略梯度 Policy Gradients
- REINFORCE:蒙特卡洛策略梯度
- Actor-Critic
- Advantage Actor-Critic
- 時序差分殘差 Actor-Critic
- Asynchronous Advantage Actor-Critic (A3C)
- 路徑衍生策略梯度(pathwise derivative policy gradient)
- 深度Q網絡→路徑衍生策略梯度
- Actor-Critic and GAN
- 信賴域策略優化 (Trust Region Policy Optimization, TRPO)
- 近端策略優化(proximal policy optimization,PPO)
- PPO-懲罰(PPO-Penalty)
- PPO-截斷(PPO-Clip)
- 深度確定性策略梯度 (Deep Deterministic Policy Gradient, DDPG)
- 雙延遲深度確定性策略梯度(twin delayed DDPG,TD3)
- 截斷的雙 Q 學習(clipped double Q-learning)
- 延遲的策略更新(delayed policy updates)
- 目標策略平滑(target policy smoothing)
- Soft Actor-Critic
- 目標導向的強化學習(goal-oriented reinforcement learning,GoRL)
- 多智能體強化學習(multi-agent reinforcement learning,MARL)
- 多智能體 DDPG(muli-agent DDPG,MADDPG)
- 應用案例:用戶關聯和信道分配
- a stochastic game
- Multi-Agent Q-Learning Method
- Multi-Agent dueling double DQN Algorithm
- 應用案例:分布式動態下行鏈路波束成形
- Limited-Information Exchange Protocol
- Distributed DRL-Based DTDE Scheme for DDBC
- Distributed DRL-Based DTDE Scheme for DDBC
參考資料
《機器學習》周志華
《機器學習》(西瓜書)公式詳解
南瓜書PumpkinBook
Reinforcement Learning: An Introduction
second edition
Richard S. Sutton and Andrew G. Barto
incompleteideas代碼
張尚彤代碼
周沫凡強化學習
周沫凡強化學習代碼
周沫凡Python tutorial
張偉楠,沈鍵,俞勇
動手學強化學習
動手學強化學習代碼
蘑菇書
王琦,楊毅遠,江季,Easy RL:強化學習教程,人民郵電出版社,2022.
Easy RL:強化學習教程
面向非地面網絡的智能無線資源管理機制與算法研究
[1]曹陽. 面向非地面網絡的智能無線資源管理機制與算法研究[D]. 電子科技大學, 2023. DOI: 10.27005/d.cnki.gdzku.2023.000168.
波束成形論文代碼
中文整理的強化學習資料
https://hunch.net/~beygel/deep_rl_tutorial.pdf
https://icml.cc/2016/tutorials/deep_rl_tutorial.pdf
Tutorial: Deep Reinforcement Learning
David Silver, Google DeepMind
我的筆記2020年簡書
我的筆記2020年CSDN
比較和分類
on-policy算法的采樣效率比較低。
下表的算法全是model-free
| 算法 | 回合更新/單步更新 | on-policy / off-policy | Policy-Based / Value-Based | 策略 | 狀態 | 動作 |
|---|---|---|---|---|---|---|
| Monte Carlo | 回合更新 | on-policy / off-policy | ||||
| Sarsa | 單步更新 | on-policy | Value-Based | 離散 | 離散 | |
| Q learning | 單步更新 | off-policy | Value-Based | 離散 | 離散 | |
| DQN | 單步更新 | off-policy | Value-Based | 連續 | 離散 | |
| Policy Gradients | 回合更新→單步更新 | on-policy | Policy-Based | 隨機 | 連續 | |
| REINFORCE | 回合更新 | on-policy | Policy-Based | 隨機 | 連續 | |
| Actor-Critic | 可以單步更新 | on-policy | Policy-Based / Value-Based | |||
| TRPO | on-policy | 隨機 | ||||
| PPO | on-policy | 隨機 | ||||
| DDPG | 單步更新 | off-policy | 確定 | 連續 | ||
| Soft Actor-Critic | off-policy | Policy-Based / Value-Based | 隨機 |
actor會基于概率做出動作。
critic會對做出的動作給出動作的價值。
基礎知識
以單智能體強化學習為例,具體的MDP數學模型M可以概括為M={S,A,R,P},其中,S,A,R和P分別表示智能體的狀態集合、動作集合,獎勵函數集合和狀態轉移概率集合。
強化學習任務對應了四元組 E= (X,A,P,R)
- 狀態空間X
- 動作空間A
- 狀態轉移概率P:X×A×X→實數域
- 獎賞R:X×A×X→實數域
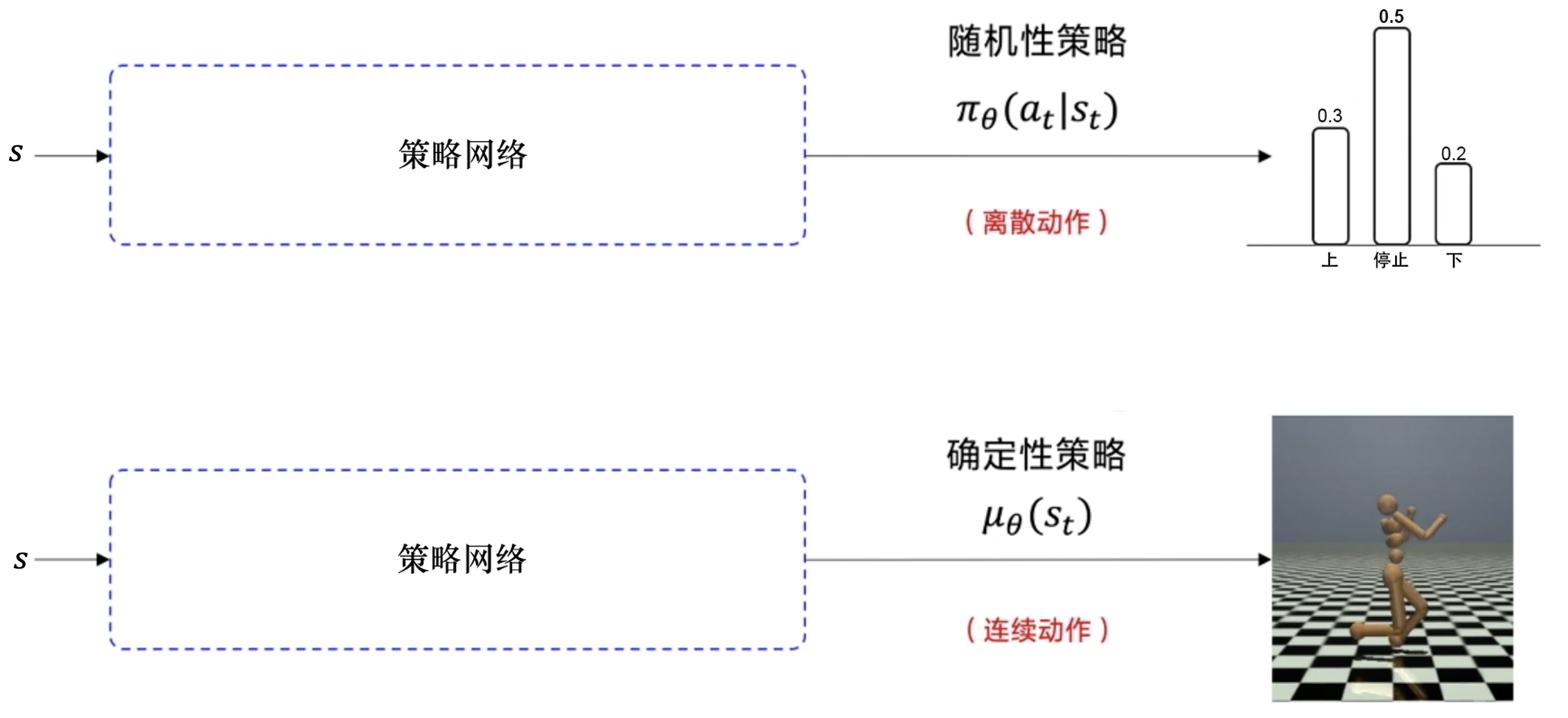
確定性策略:a=π(x),即在狀態x下執行a動作;
隨機性策略:P=π(x,a),即在狀態x下執行a動作的概率。
π ( a ∣ s ) = p [ A t = a ∣ S t = s ] \pi(a|s)=p[A_t=a|S_t=s] π(a∣s)=p[At?=a∣St?=s]
強化學習在某種意義上可看作具有“延遲標記信息”的監督學習問題
K-搖臂賭博機
僅探索法:將嘗試的機會平均分給每一個動作,即輪流執行,最終將每個動作的平均獎賞作為期望獎賞的近似值。
僅利用法:將嘗試的機會分給當前平均獎賞值最大的動作。
欲累積獎賞最大,則必須在探索與利用之間達成較好的折中
ε-貪心法:基于一個概率來對探索和利用進行折中
以概率ε進行探索:πε(s) = 以均勻概率從A中選取動作
以概率1-ε進行利用:πε(s) = π(s) = a r g m a x a Q ( s , a ) argmax_{a} Q(s,a) argmaxa?Q(s,a),即選擇當前最優的動作。
Softmax算法:基于當前每個動作的平均獎賞值來對探索和利用進行折中
τ趨于0時, Softmax 將趨于“僅利用”
τ趨于無窮大時, Softmax 將趨于“僅探索”
16.3 有模型學習
有模型學習:狀態空間、動作空間、轉移概率以及獎賞函數都已經給出
預測(prediction)和控制(control)是馬爾可夫決策過程里面的核心問題。
預測(評估一個給定的策略)的輸入是馬爾可夫決策過程 <S,A,P,R,γ> 和策略π,輸出是價值函數Vπ。
控制(搜索最佳策略)的輸入是馬爾可夫決策過程 <S,A,P,R,γ>,輸出是最佳價值函數(optimal value function)V?和最佳策略(optimal policy)π?。
16.3.1 策略評估
折扣累積回報: G t = R t + 1 + γ R t + 2 + ? = ∑ k = 0 ∞ γ k R t + k + 1 G_t=R_{t+1}+\gamma R_{t+2}+\cdots =\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}} Gt?=Rt+1?+γRt+2?+?=∑k=0∞?γkRt+k+1?
狀態值函數(V):Vπ(x),即從狀態x出發,使用π策略所帶來的累積獎賞;
υ π ( s ) = E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] \upsilon_{\pi}\left(s\right)=E_{\pi}\left[{G_t|S_t=s}\right] =E_{\pi}\left[\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}|S_t=s}\right] υπ?(s)=Eπ?[Gt?∣St?=s]=Eπ?[∑k=0∞?γkRt+k+1?∣St?=s]
狀態值函數V表示執行策略π能得到的累計折扣獎勵:
V π ( s ) = E [ R ( s 0 , a 0 ) + γ R ( s 1 , a 1 ) + γ 2 R ( s 2 , a 2 ) + γ 3 R ( s 3 , a 3 ) + … ∣ s = s 0 ] V^π(s) = E[R(s_0,a_0)+γR(s_1,a_1)+γ^2R(s_2,a_2)+γ^3R(s_3,a_3)+…|s=s_0] Vπ(s)=E[R(s0?,a0?)+γR(s1?,a1?)+γ2R(s2?,a2?)+γ3R(s3?,a3?)+…∣s=s0?]
V π ( s ) = R ( s , a ) + γ ∑ s ′ ∈ S p ( s ′ ∣ s , π ( s ) ) V π ( s ′ ) V^{\pi}(s)=R(s, a)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} | s, \pi(s)\right) V^{\pi}\left(s^{\prime}\right) Vπ(s)=R(s,a)+γ∑s′∈S?p(s′∣s,π(s))Vπ(s′)
狀態-動作值函數(Q):Qπ(x,a),即從狀態x出發,執行動作a后再使用π策略所帶來的累積獎賞。
q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] q_{\pi}\left(s,a\right)=E_{\pi}\left[{G_t|S_t=s,A_t=a}\right] =E_{\pi}\left[\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}|S_t=s,A_t=a}\right] qπ?(s,a)=Eπ?[Gt?∣St?=s,At?=a]=Eπ?[∑k=0∞?γkRt+k+1?∣St?=s,At?=a]
狀態動作值函數Q(s,a)表示在狀態s下執行動作a能得到的累計折扣獎勵:
Q π ( s , a ) = E [ R ( s 0 , a 0 ) + γ R ( s 1 , a 1 ) + γ 2 R ( s 2 , a 2 ) + γ 3 R ( s 3 , a 3 ) + … ∣ s = s 0 , a = a 0 ] Q^π(s,a) = E[R(s_0,a_0)+γR(s_1,a_1)+γ^2R(s_2,a_2)+γ^3R(s_3,a_3)+…|s=s_0,a=a_0] Qπ(s,a)=E[R(s0?,a0?)+γR(s1?,a1?)+γ2R(s2?,a2?)+γ3R(s3?,a3?)+…∣s=s0?,a=a0?]
Q π ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S p ( s ′ ∣ s , π ( s ) ) Q π ( s ′ , π ( s ′ ) ) Q^{\pi}(s, a)=R(s, a)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} | s, \pi(s)\right) Q^{\pi}\left(s^{\prime}, \pi\left(s^{\prime}\right)\right) Qπ(s,a)=R(s,a)+γ∑s′∈S?p(s′∣s,π(s))Qπ(s′,π(s′))
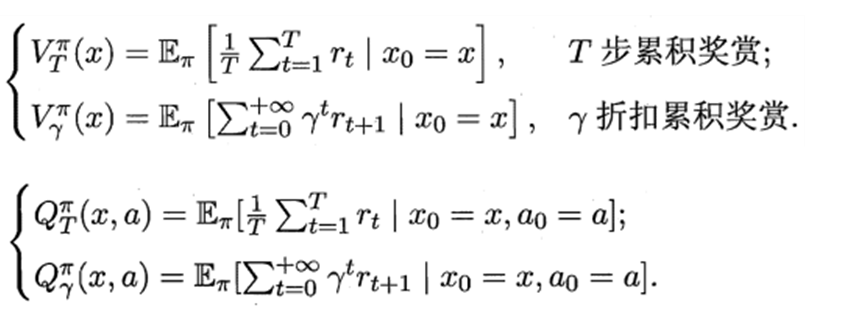
遞歸形式:Bellman 等式
狀態值函數的Bellman方程:
υ ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ R t + 2 + ? ∣ S t = s ] = E [ R t + 1 + γ ( R t + 2 + γ R t + 3 + ? ) ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 + γ υ ( S t + 1 ) ∣ S t = s ] \upsilon(s)=E[G_t|S_t=s] \\ =E[R_{t+1}+\gamma R_{t+2}+\cdots |S_t=s] \\ =E[R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3}+\cdots)|S_t=s] \\ =E[R_{t+1}+\gamma G_{t+1}|S_t=s] \\ =E[R_{t+1}+\gamma\upsilon(S_{t+1})|S_t=s] υ(s)=E[Gt?∣St?=s]=E[Rt+1?+γRt+2?+?∣St?=s]=E[Rt+1?+γ(Rt+2?+γRt+3?+?)∣St?=s]=E[Rt+1?+γGt+1?∣St?=s]=E[Rt+1?+γυ(St+1?)∣St?=s]
狀態動作值函數的Bellman方程:
q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] = E π [ R t + 1 + γ q ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ] q_{\pi}(s,a)=E_{\pi}[G_t|S_t=s,A_t=a]\\ =E_{\pi}[R_{t+1}+\gamma q(S_{t+1},A_{t+1})|S_t=s,A_t=a] qπ?(s,a)=Eπ?[Gt?∣St?=s,At?=a]=Eπ?[Rt+1?+γq(St+1?,At+1?)∣St?=s,At?=a]
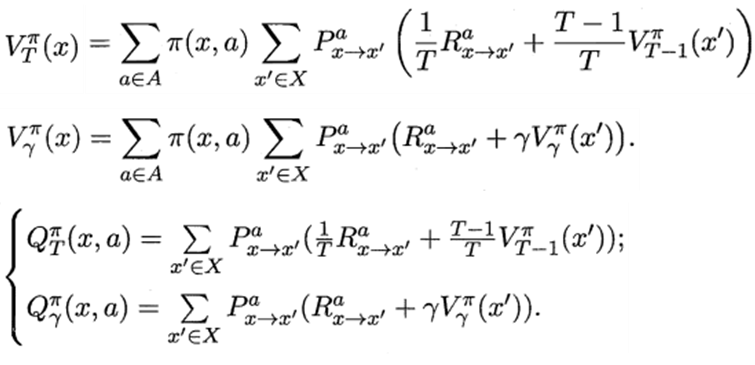
16.3.2 策略改進
最優策略:使得值函數對所有狀態求和的值最大的策略
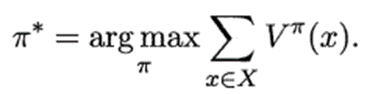
最優值函數:最優策略對應的值函數
策略改進: π ′ ( s ) = argmax ? a ∈ A Q π ( s , a ) \pi^{'}(s)=\underset{a∈A}{\operatorname{argmax}} Q^{\pi}(s, a) π′(s)=a∈Aargmax?Qπ(s,a)
π ? ( s ) = argmax ? a Q ? ( s , a ) \pi^{*}(s)=\underset{a}{\operatorname{argmax}} Q^{*}(s, a) π?(s)=aargmax?Q?(s,a)
16.3.3 策略迭代
策略迭代:不斷迭代進行策略評估和策略改進,直到策略收斂、不再改變為止

16.3.3 值迭代
值迭代:不斷迭代進行策略評估,直到值函數收斂、不再改變為止

16.4 免模型學習
在原始策略上使用ε-貪心策略
ε-貪心法:基于一個概率來對探索和利用進行折中
以概率ε進行探索:πε(s) = 以均勻概率從A中選取動作
以概率1-ε進行利用:πε(s) = π(s) = a r g m a x a Q ( s , a ) argmax_{a} Q(s,a) argmaxa?Q(s,a),即選擇當前最優的動作。
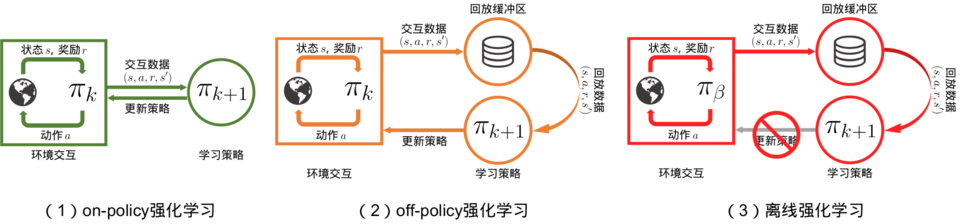
on-policy off-policy
the target policy: the policy being learned about
the behavior policy: the policy used to generate behavior
In this case we say that learning is from data “off” the target policy, and the overall process is termed off-policy learning.
目標策略:正在被學習的策略。要學習的智能體。代理和環境交互過程中所選擇的動作
行為策略:被用來產生行為的策略。與環境交互的智能體。計算評估函數的過程中選擇的動作
同策略(on-policy):行為策略是目標策略
要學習的智能體和與環境交互的智能體相同
智能體直接采用正在優化的策略函數收集訓練數據,即利用自身在特定時間內產生的連續決策軌跡更新當前的DNN參數。
異策略(off-policy):行為策略不是目標策略。
要學習的智能體和與環境交互的智能體不相同
智能體在收集訓練數據時采用與正在優化的策略函數不一致的策略。
智能體在訓練過程中可以不斷和環境交互,得到新的反饋數據。
on-policy算法:直接使用這些反饋數據
off-policy算法:先將數據存入經驗回放池中,需要時再采樣。
離線強化學習(offline reinforcement learning):在智能體不和環境交互的情況下,僅從已經收集好的確定的數據集中,通過強化學習算法得到比較好的策略。
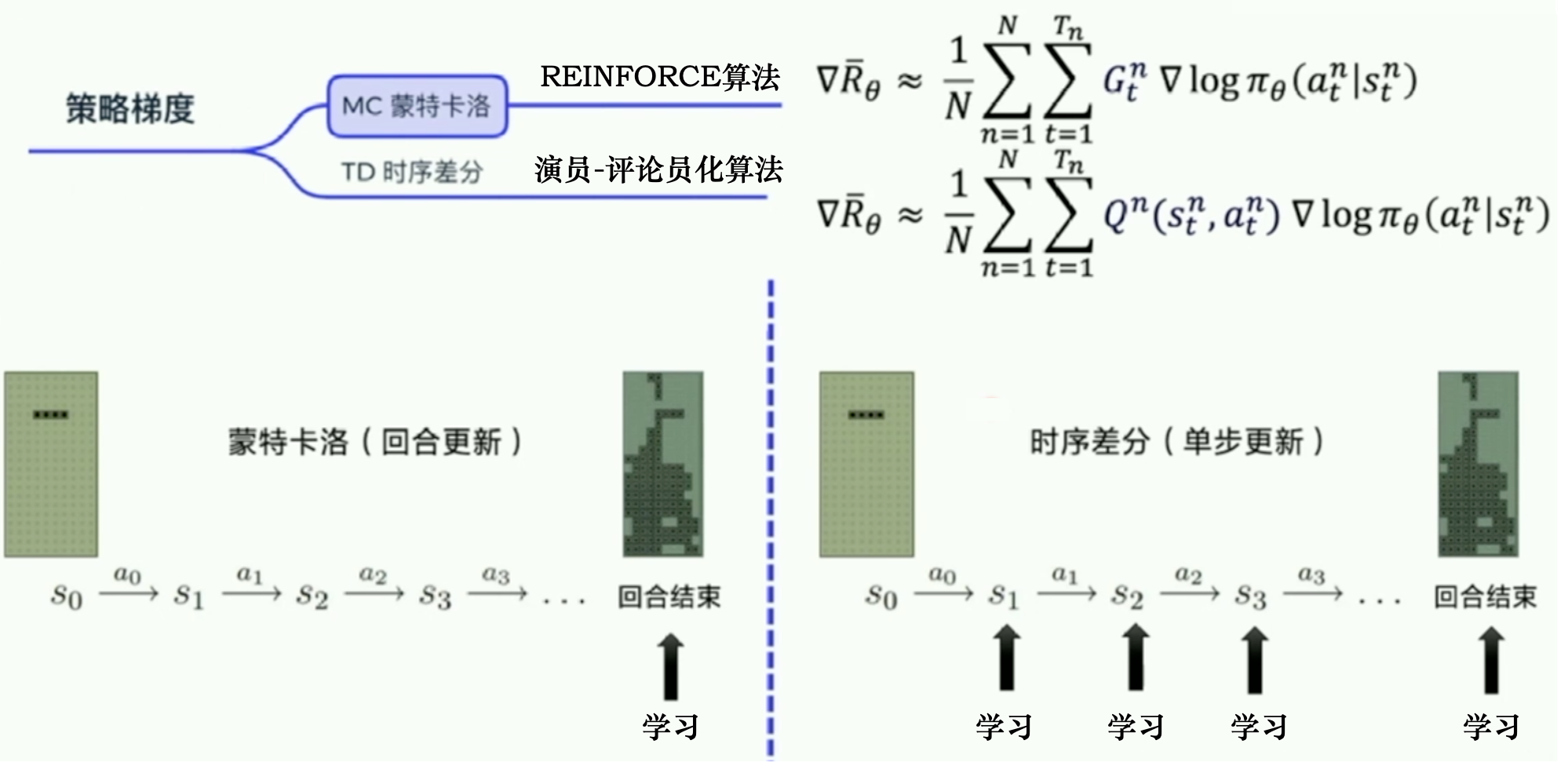
16.4.1 蒙特卡羅強化學習
蒙特卡羅強化學習:通過采樣來進行策略評估。
多次“采樣”,然后求取平均累積獎賞來作為期望累積獎賞的近似
由于采樣必須為有限次數,因此該方法更適合于使用 步累積獎賞的強化學習任務。
估計狀態-動作值函數

同策略(on-policy)蒙特卡羅強化學習算法:被評估和被改進的都是同一個策略
異策略(off-policy)蒙特卡羅強化學習算法:僅在評估時使用ε-貪心策略,而在改進時使用原始策略
蒙特卡羅強化學習算法沒有充分利用強化學習任務的 MDP 結構
16.4.2 時序差分學習
蒙特卡羅強化學習算法在一個完整的采樣軌跡完成后再對所有的狀態-動作對進行更新。
實際上這個更新過程能增量式進行。
時序差分(Temporal Difference ,簡稱 TD )學習則結合了動態規劃與蒙特卡羅方法的思想,能做到更高效的免模型學習。
Sarsa算法:同策略算法(on-policy):行為策略是目標策略
每次更新值函數需知道前一步的狀態(state)x、前一步的動作(action)a、獎賞值(reward)R、當前狀態(state)x’、將要執行的動作(action)a’:
Q ( s , a ) ← Q ( s , a ) + α [ R + γ Q ( s ′ , a ′ ) ? Q ( s , a ) ] , γ ∈ [ 0 , 1 ) Q(s,a)←Q(s,a)+\alpha[R+\gamma Q\left(s^{\prime}, a^{\prime}\right)-Q(s,a)],\gamma∈[0,1) Q(s,a)←Q(s,a)+α[R+γQ(s′,a′)?Q(s,a)],γ∈[0,1)
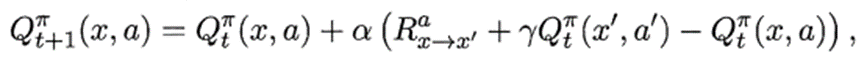
更新步長α越大,則越靠后的累積獎賞越重要。
π(s) = a r g m a x a Q ( s , a ) argmax_{a} Q(s,a) argmaxa?Q(s,a)

on policy 同策略
在選擇動作執行的時候采取的策略 = 在更新Q表的時候采取的策略
行為策略 行動策略是ε-greedy策略
目標策略 評估策略是ε-greedy策略
Q-learning算法:異策略算法(off-policy):行為策略不是目標策略
每次更新值函數需知道前一步的狀態(state)x、前一步的動作(action)a、獎賞值(reward)R、當前狀態(state)x’
Q值表:state為行,action為列,reward為元素
Q ( s , a ) ← Q ( s , a ) + α [ R + γ max ? a ′ Q ( s ′ , a ′ ) ? Q ( s , a ) ] , γ ∈ [ 0 , 1 ) Q(s,a)←Q(s,a)+\alpha[R+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s,a)],\gamma∈[0,1) Q(s,a)←Q(s,a)+α[R+γmaxa′?Q(s′,a′)?Q(s,a)],γ∈[0,1)
學習率*(Q的真實值 - Q的估計值)
如果學習率越大,那么新估計值代替舊估計值的程度也越大

off-policy 異策略
在選擇動作執行的時候采取的策略 ≠ 在更新Q表的時候采取的策略
行為策略 行動策略是ε-greedy策略
目標策略 更新Q表的策略是貪婪策略
Q-learning的目標策略不管行為策略會產生什么動作。Q-learning的目標策略默認下一個動作就是 Q 值最大的那個動作,并且默認按照最佳的策略去優化目標策略,所以它可以更大膽地去尋找最優的路徑,它表現得比 Sarsa 大膽得多。
異策略算法的這個循環可以拆開成2個部分:與環境交互(執行動作,獲得獎勵和觀察狀態)和學習(用動作,獎勵,狀態更新Q),從而實現離線學習。
離線學習的行為策略一直沒更新,訓練效果應該也不好?
多步時序差分:無偏且方差小
蒙特卡洛方法利用當前狀態之后每一步的獎勵而不使用任何價值估計
時序差分算法只利用一步獎勵和下一個狀態的價值估計。
蒙特卡洛方法:無偏(unbiased),方差大
方差大,因為每一步的狀態轉移都有不確定性,而每一步狀態采取的動作所得到的不一樣的獎勵最終都會加起來,這會極大影響最終的價值估計;
時序差分算法:有偏,方差小
方差小,因為只關注了一步狀態轉移,用到了一步的獎勵
有偏,因為用到了下一個狀態的價值估計而不是其真實的價值。
多步時序差分可以結合二者的優勢
多步sarsa
Sarsa(0):Sarsa 是一種單步更新法, 在環境中每走一步, 更新一次自己的行為準則。等走完這一步以后直接更新行為準則
Sarsa(1):走完這步, 再走一步, 然后再更新
Sarsa(n):如果等待回合完畢我們一次性再更新呢, 比如這回合我們走了 n 步
Sarsa(lambda):有了一個 lambda 值來代替我們想要選擇的步數
lambda 是腳步衰減值, 是一個在 0 和 1 之間的數
當 lambda 取0, 就變成了 Sarsa 的單步更新
當 lambda 取 1, 就變成了回合更新, 對所有步更新的力度都是一樣
當 lambda 在 0 和 1 之間, 取值越大, 離寶藏越近的步更新力度越大
16.5 值函數近似
直接對連續狀態空間的值函數進行學習
值函數能表達為狀態的線性函數
線性值函數近似 Sarsa 算法
線性值函數近似 Q-learning算法
16.6 模仿學習
模仿學習
假設存在一個專家智能體,其策略可以看成最優策略,我們就可以直接模仿這個專家在環境中交互的狀態動作數據來訓練一個策略,并且不需要用到環境提供的獎勵信號。
逆強化學習(inverse RL)
16.6.1 直接模仿學習
直接模仿人類專家的“狀態-動作對"
行為克隆(behavior cloning,BC)
直接使用監督學習方法,將專家數據(狀態,動作)中的狀態看作樣本輸入,動作視為標簽
16.6.2 逆強化學習(inverse RL)
逆強化學習:從人類專家提供的范例數據中反推出獎賞函數
生成式對抗模仿學習(generative adversarial imitation learning,GAIL)
2016 年由斯坦福大學研究團隊提出的基于生成式對抗網絡的模仿學習
它詮釋了生成式對抗網絡的本質其實就是模仿學習。
深度Q網絡算法
Q-learning算法:狀態離散,動作離散,并且空間都比較小的情況下適用
若動作是連續(無限)的,神經網絡的輸入:狀態s和動作a。輸出:在狀態s下采取動作a能獲得的價值。
若動作是離散(有限)的,除了可以采取動作連續情況下的做法,我們還可以:神經網絡的輸入:狀態s。輸出:每一個動作的Q值。
通常 DQN(以及 Q-learning)只能處理動作離散的情況,因為在Q函數的更新過程中有max_a這一操作。
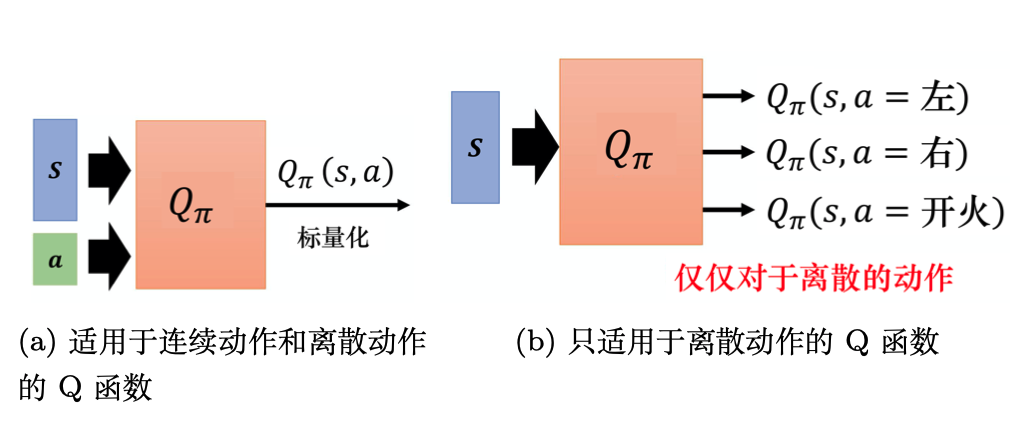
Q網絡:用于擬合Q函數的神經網絡
用權重為w的Q網絡 Q ( s , a , w ) Q(s,a,w) Q(s,a,w)表示value函數 Q ? ( s , a ) Q^?(s,a) Q?(s,a)
DQN 算法最終更新的目標:最小化損失函數
Q 網絡的損失函數構造為均方誤差的形式:
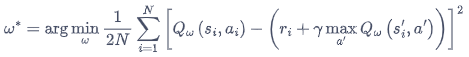
I = ( r + γ max ? a Q ( s ′ , a ′ , w ) ? Q ( s , a , w ) ) 2 I=\left(r+\gamma \max _{a} Q\left(s^{\prime}, a^{\prime}, \mathbf{w}\right)-Q(s, a, \mathbf{w})\right)^{2} I=(r+γmaxa?Q(s′,a′,w)?Q(s,a,w))2
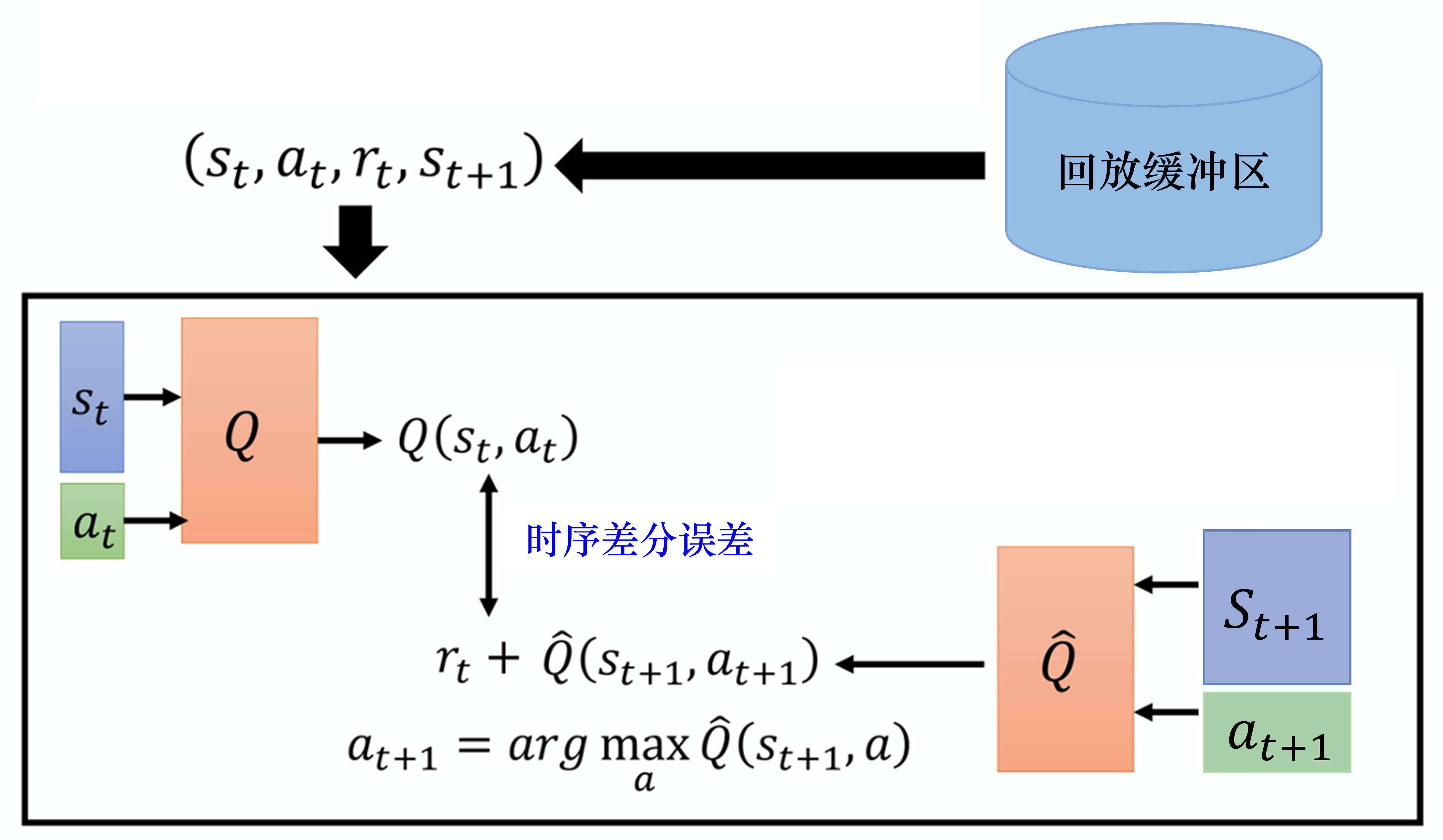
經驗回放(experience replay)
如果某個算法使用了經驗回放,該算法就是off-policy算法。
維護一個回放緩沖區,將每次從環境中采樣得到的四元組數據(狀態、動作、獎勵、下一狀態)存儲到回放緩沖區中,訓練 Q 網絡的時候再從回放緩沖區中隨機采樣若干數據來進行訓練。
好處:
- 打破樣本之間的相關性,讓其滿足獨立假設。
在 MDP 中交互采樣得到的數據本身不滿足獨立假設,因為這一時刻的狀態和上一時刻的狀態有關。
非獨立同分布的數據對訓練神經網絡有很大的影響,會使神經網絡擬合到最近訓練的數據上。
回放緩沖區里面的經驗來自于不同的策略,我們采樣到的一個批量里面的數據會是比較多樣的。 - 提高樣本效率。
每一個樣本可以被使用多次,十分適合深度神經網絡的梯度學習。
與環境交互比較慢,訓練網絡比較快。
目標網絡(target network)
損失函數包含神經網絡的輸出,因此在更新網絡參數的同時目標也在不斷地改變,這容易造成神經網絡訓練的不穩定性。
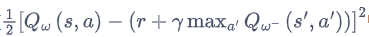
訓練網絡:用于計算損失函數的前一項,并且使用正常梯度下降方法來進行更新。
目標網絡:用于計算損失函數的后一項 r + γ max ? a ′ Q ( s ′ , a ′ , w ? ) r+\gamma \max _{a'} Q\left(s^{\prime}, a^{\prime}, \mathbf{w}-\right) r+γmaxa′?Q(s′,a′,w?)
訓練網絡在訓練中的每一步都會更新。
目標網絡的參數每隔幾步才會與訓練網絡同步一次。
這樣做使得目標網絡相對于訓練網絡更加穩定。
deep Q network, DQN


Double Deep Q-Network
[1509.06461] Deep Reinforcement Learning with Double Q-learning
DQN的問題:DQN算法通常會導致對Q值的過高估計
DQN:Q_next = max(Q_next(s’, a_all))
Y t D Q N ≡ R t + 1 + γ max ? a Q ( S t + 1 , a ; θ t ? ) Y_{t}^{\mathrm{DQN}} \equiv R_{t+1}+\gamma \max _{a} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}^{-}\right) YtDQN?≡Rt+1?+γmaxa?Q(St+1?,a;θt??)
Double DQN:Q_next = Q_next(s’, argmax(Q_eval(s’, a_all)))
Y t DoubleDQN? ≡ R t + 1 + γ Q ( S t + 1 , argmax ? a Q ( S t + 1 , a ; θ t ) ; θ t ? ) Y_{t}^{\text {DoubleDQN }} \equiv R_{t+1}+\gamma Q\left(S_{t+1}, \underset{a}{\operatorname{argmax}} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}\right); \boldsymbol{\theta}_{t}^{-}\right) YtDoubleDQN??≡Rt+1?+γQ(St+1?,aargmax?Q(St+1?,a;θt?);θt??)
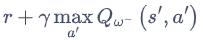
DQN的優化目標為 ,動作的選取依靠目標網絡
,動作的選取依靠目標網絡
Double DQN 的優化目標為 ,動作的選取依靠訓練網絡
,動作的選取依靠訓練網絡
用訓練網絡計算使Q值最大的動作
用目標網絡計算Q值
當前的Q網絡w用于選擇動作
舊的Q網絡w?用于評估動作
I = ( r + γ Q ( s ′ , argmax ? a ′ Q ( s ′ , a ′ , w ) , w ? ) ? Q ( s , a , w ) ) 2 I=\left(r+\gamma Q\left(s^{\prime}, \underset{a^{\prime}}{\operatorname{argmax}} Q\left(s^{\prime}, a^{\prime}, \mathbf{w}\right), \mathbf{w}^{-}\right)-Q(s, a, \mathbf{w})\right)^{2} I=(r+γQ(s′,a′argmax?Q(s′,a′,w),w?)?Q(s,a,w))2
Double DQN 的代碼實現可以直接在 DQN 的基礎上進行,無須做過多修改。
優先級經驗回放 (prioritized experience replay, PER)
[1511.05952] Prioritized Experience Replay
Double Learning and Prioritized Experience Replay
重視值得學習的樣本
時序差分誤差 = 網絡的輸出與目標之間的差距
如果采樣過的數據的時序差分誤差特別大,那么應該讓它們以比較大的概率被采樣到。

batch 抽樣的時候并不是隨機抽樣, 而是按照 Memory 中的樣本優先級來抽
用到 TD-error, 也就是 Q現實 - Q估計 來規定優先學習的程度
如果 TD-error 越大, 就代表我們的預測精度還有很多上升空間, 那么這個樣本就越需要被學習, 也就是優先級 p 越高
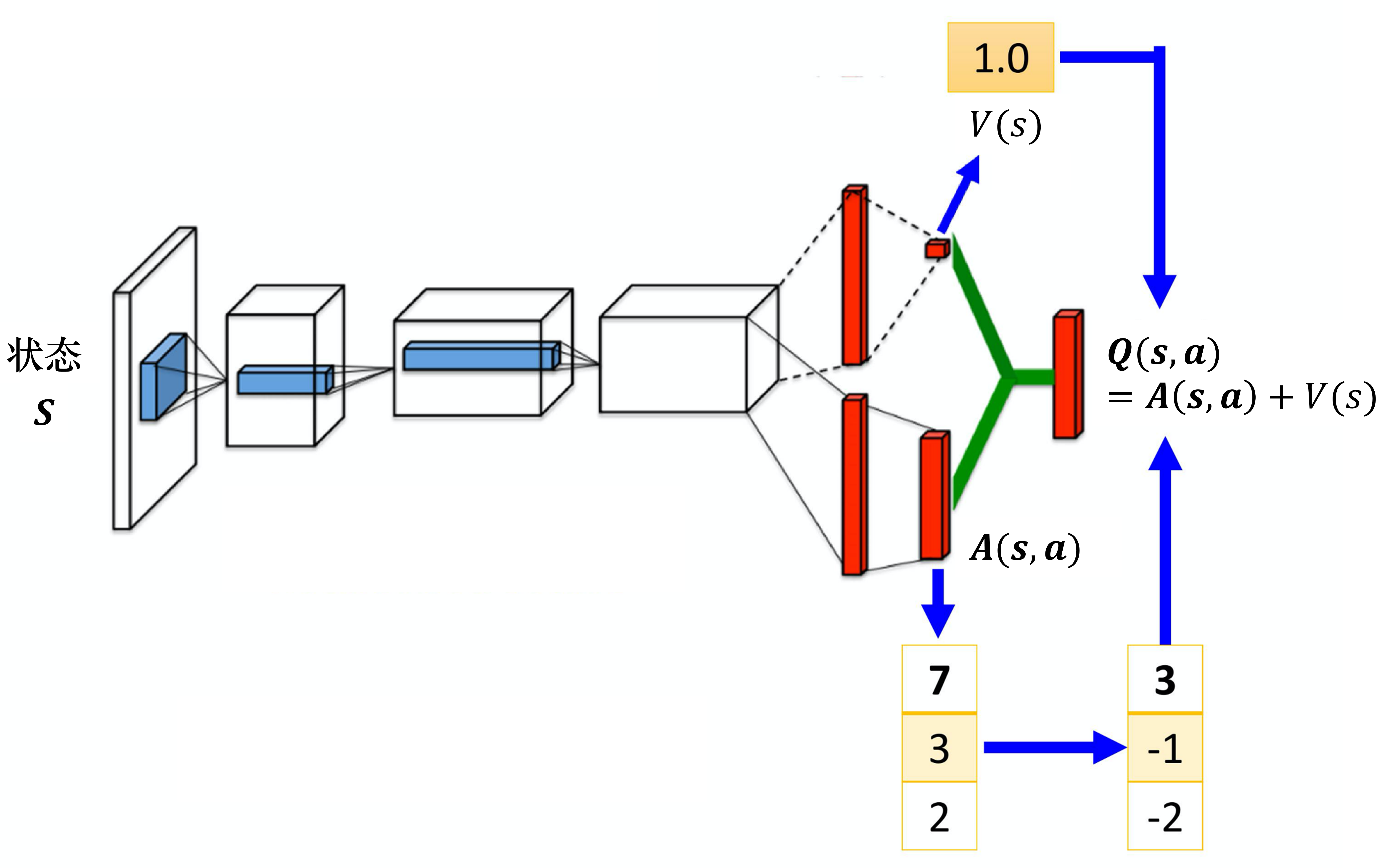
Dueling Deep Q-Network
[1511.06581] Dueling Network Architectures for Deep Reinforcement Learning
Dueling DQN 能夠很好地學習到不同動作的差異性,在動作空間較大的環境下非常有效。
動作狀態價值函數 = 狀態價值函數 + 優勢函數
將Q網絡分成2個通道
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) Q_{\eta, \alpha, \beta}(s,a) = V_{\eta, \alpha}(s) + A_{\eta, \beta}(s,a) Qη,α,β?(s,a)=Vη,α?(s)+Aη,β?(s,a)
V η , α ( s ) V_{\eta, \alpha}(s) Vη,α?(s):狀態價值函數,與action無關
A η , β ( s , a ) A_{\eta, \beta}(s,a) Aη,β?(s,a):該狀態下采取不同動作的優勢函數,與action有關
η \eta η是狀態價值函數和優勢函數共享的網絡參數,一般用在神經網絡中,用來提取特征的前幾層
α \alpha α和 β \beta β分別為狀態價值函數和優勢函數的參數。
競爭深度Q網絡的問題:最后學習的結果可能是這樣的:
智能體就學到V(s)等于0,A(s,a)等于Q,就和原來的深度Q網絡一樣。
解決方案:在把A(s,a)與V(s)加起來之前,先處理A(s,a)。比如減去均值
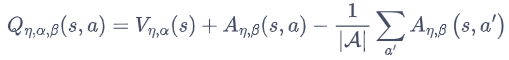
雖然它不再滿足bellman最優方程,但實際應用時更加穩定。
策略梯度 Policy Gradients
基于值函數的方法:學習值函數,然后根據值函數導出一個策略。學習過程中并不存在一個顯式的策略
基于策略的方法:直接顯式地學習一個目標策略。
policy gradient要輸出不是action的value,而是具體的那一個action,跳過了value這個階段。輸出的這個action可以是一個連續的值。
優點:連續動作
在策略梯度中,梯度可以寫成一般的形式:
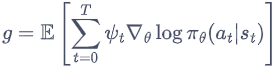
其中, ψ t \psi_t ψt?可以有很多種形式

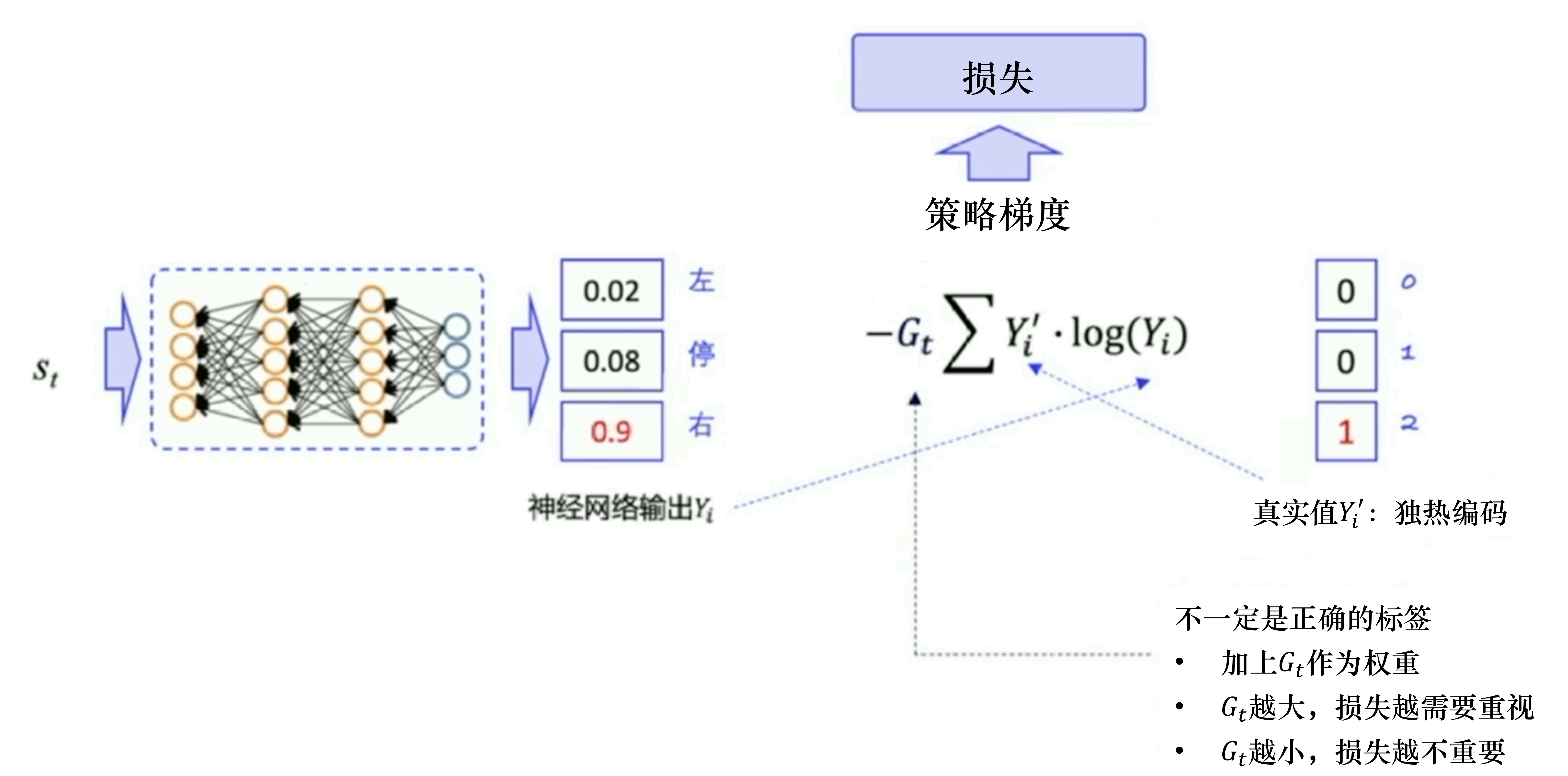
最小化損失 → 最大化Y’=1對應的那個Y
REINFORCE:蒙特卡洛策略梯度
Gt:從第t步開始,往后能夠獲得的總獎勵

REINFORCE 算法
1.用一個策略模型來輸出動作概率。通過 sample() 函數得到一個具體的動作,與環境交互,得到整個回合的數據。
2.執行 learn() 函數,用這些數據去構造損失函數,“扔”給優化器優化,更新策略模型。
在狀態s對所選動作a的吃驚度:delta(log(Policy(s,a)) * V)
Policy(s,a)概率越小,-log(Policy(s,a))(即-log§)越大
如果Policy(s,a)很小時,拿到的R大,即V大,那-delta(log(Policy(s,a)) * V)就更大,表示更吃驚。(選了一個不常選的動作,卻發現它能得到的reward很大,那么大幅修改參數)
因為使用了蒙特卡洛方法,REINFORCE算法的缺點:回合更新
1.梯度估計的方差很大
2.只能在序列結束后進行更新,這同時也要求任務具有有限的步數
Actor-Critic算法則可以在每一步之后都進行更新,并且不對任務的步數做限制。
Actor-Critic
Actor-Critic算法既學習價值函數,又學習策略函數
本質上是基于策略的算法,因為這一系列算法的目標都是優化一個帶參數的策略,只是會額外學習價值函數,從而幫助策略函數更好地學習。
Actor-Critic有演員網絡和評論家網絡。
- Actor使用策略梯度函數:生成動作并與環境交互。
策略函數,描述狀態和離散動作或連續動作分布的映射關系。
在Critic價值函數的指導下用策略梯度學習一個更好的策略。 - Critic使用價值函數:評估Actor的表現,并在下一階段指導Actor的行為。
傳統的值函數,來評估不同狀態下的收益
通過Actor與環境交互收集的數據學習一個價值函數,這個價值函數會用于判斷在當前狀態什么動作是好的,什么動作不是好的。
它可以加速策略梯度函數的收斂,但這還不足以解決復雜的問題。
結合了Policy Gradient (Actor)和Function Approximation (Critic)的方法
Actor基于概率選行為
Critic基于Actor的行為評判行為的得分
Actor根據Critic的評分修改選行為的概率
Actor 在運用 Policy Gradient 的方法進行 Gradient ascent 的時候, 由 Critic 來告訴他, 這次的 Gradient ascent 是不是一次正確的 ascent。如果這次的得分不好, 那么就不要 ascent 那么多
Actor-Critic的優勢:可以進行單步更新,比傳統的Policy Gradient要快。
Actor-Critic的劣勢:取決于Critic的價值判斷,但是Critic難收斂,再加上Actor的更新,就更難收斂。
Advantage Actor-Critic
Q π ( s , a ) = V π ( s ) + A π ( s , a ) Q^\pi(s,a) = V^\pi(s) + A^\pi(s,a) Qπ(s,a)=Vπ(s)+Aπ(s,a)
A π ( s , a ) = Q π ( s , a ) ? V π ( s ) A^\pi(s,a)= Q^\pi(s,a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)?Vπ(s)
Advantage Actor-Critic采用了優勢函數
缺點:需要估計2個網絡:Q網絡和 V網絡。估計不準的風險變成原來的兩倍。
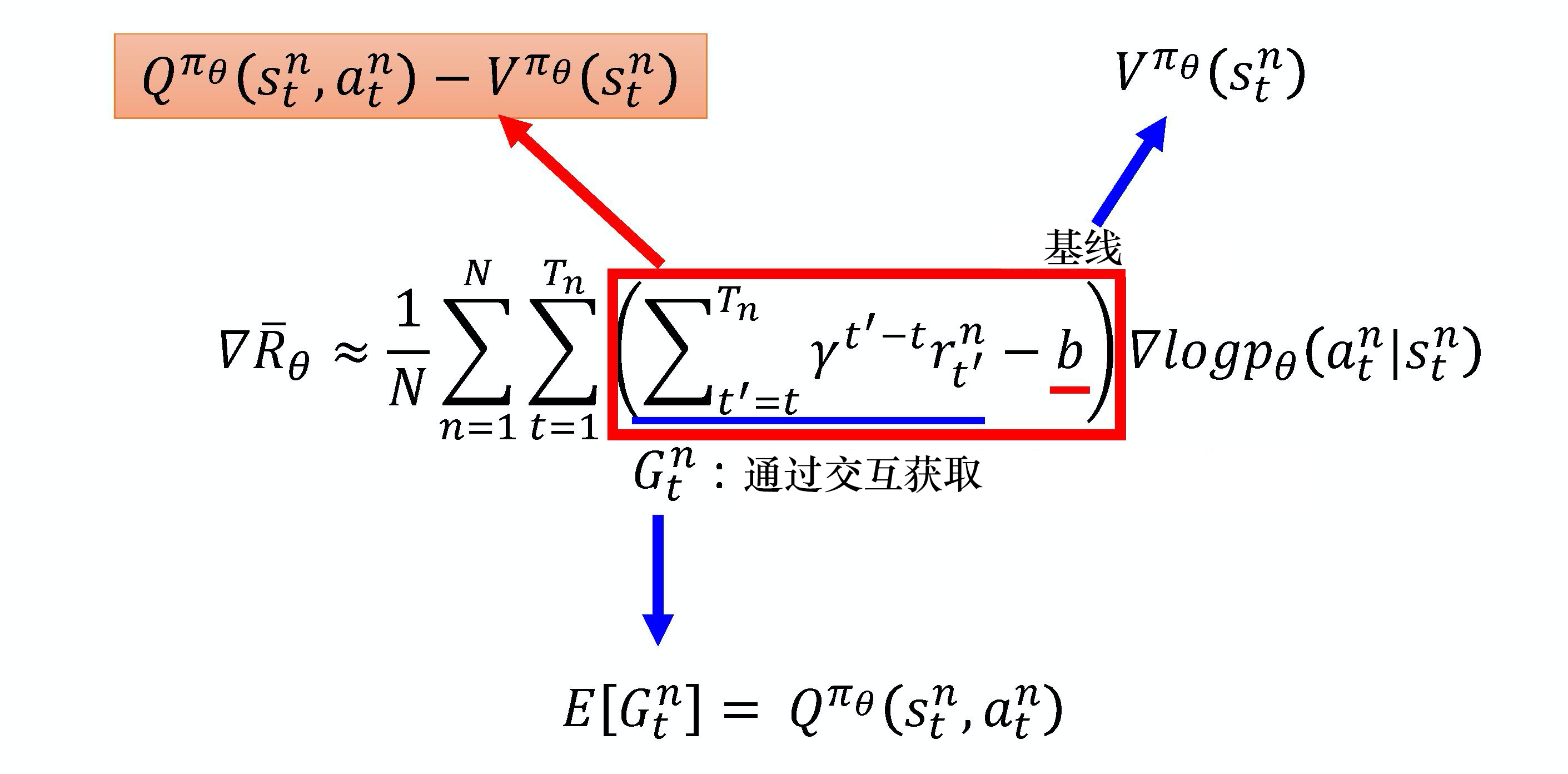
時序差分殘差 Actor-Critic
A π ( s t , a t ) = Q π ( s t , a t ) ? V π ( s t ) A^\pi(s_{t}, a_{t})= Q^\pi(s_{t}, a_{t}) - V^\pi(s_{t}) Aπ(st?,at?)=Qπ(st?,at?)?Vπ(st?)
用 r t + γ V π ( s t + 1 ) r_{t}+ \gamma V^\pi(s_{t+1}) rt?+γVπ(st+1?)替換 Q π ( s t , a t ) Q^\pi(s_{t}, a_{t}) Qπ(st?,at?)得到
r t + γ V π ( s t + 1 ) ? V π ( s t ) r_{t}+ \gamma V^\pi(s_{t+1}) - V^\pi(s_{t}) rt?+γVπ(st+1?)?Vπ(st?)
不需要估計Q,只需要估計V
引入一個隨機的參數r,r的方差小于G的方差
Critic網絡Vπ(s)接收一個狀態,輸出一個標量。
Actor的策略π(s)接收一個狀態,
如果動作是離散的,輸出就是一個動作的分布。
如果動作是連續的,輸出就是一個連續的向量。
Actor網絡和Critic網絡的輸入都是s,所以它們前面幾個層(layer)是可以共享的。
Asynchronous Advantage Actor-Critic (A3C)
[1602.01783] Asynchronous Methods for Deep Reinforcement Learning
異步優勢演員-評論員算法
不同于經驗回放,異步優勢演員評論家在環境的多個實例上異步地并行執行多個代理。這種并行性還去相關代理的數據,變成一個更加平穩的過程中,因為在任何給定的時間步,并行代理都會經歷各種不同的狀態。
A3C同時使用很多個進程(worker),每一個進程就像一個影分身,最后這些影分身會把所有的經驗值集合在一起。
如果CPU少,那么不好實現A3C,但可以實現Advantage Actor-Critic。

路徑衍生策略梯度(pathwise derivative policy gradient)
路徑衍生策略梯度
可以看成一種特別的DQN方法,解連續動作
可以看成一種特別的Actor-Critic方法
原來的Actor-Critic的問題:Critic只告訴Actor好或不好的,沒有告訴Actor什么樣是好。
Critic會直接告訴Actor什么動作才是好的。
- 策略π與環境交互并估計Q值。
- 固定Q值,只去學習一個Actor。假設這個Q值估得很準,它知道在某一個狀態采取什么樣的動作會得到很大的Q值。
接下來就學習這個Actor,Actor在給定s的時候,采取了a,可以讓最后Q函數算出來的值越大越好。
我們用準則(criteria)去更新策略π

深度Q網絡→路徑衍生策略梯度

Actor-Critic and GAN
Connecting Generative Adversarial Network and Actor-Critic Methods
| Actor-Critic | GAN 生成對抗網絡 | |
|---|---|---|
| Actor 演員 | generator 生成器 | |
| Critic 評論員 | discriminator 判別器 |

信賴域策略優化 (Trust Region Policy Optimization, TRPO)
基于策略的方法:參數化智能體的策略,并設計衡量策略好壞的目標函數,通過梯度上升的方法來最大化這個目標函數,使得策略最優。
策略梯度算法的缺點:當策略網絡是深度模型時,沿著策略梯度更新參數,很有可能由于步長太長,策略突然顯著變差,進而影響訓練效果。
TRPO算法優點:在理論上能夠保證策略學習的性能單調性。
在 2015 年被提出
近端策略優化(proximal policy optimization,PPO)
TRPO算法的缺點:計算過程非常復雜,每一步更新的運算量非常大。
OpenAI提出的一種解決Policy Gradient不好確定Learning rate(或者Step size)的問題
因為如果step size過大,學出來的Policy會一直亂動,不會收斂
如果Step Size太小,對于完成訓練,收斂時間太長
PPO利用New Policy和Old Policy的比例,限制了New Policy的更新幅度,讓Policy Gradient對稍微大點的Step size不那么敏感。
PPO-懲罰(PPO-Penalty)
PPO-截斷(PPO-Clip)
深度確定性策略梯度 (Deep Deterministic Policy Gradient, DDPG)
動作連續、off-policy、確定性策略(目標策略),單步更新
確定性策略:a=π(x),即在狀態x下執行a動作;
隨機性策略:P=π(x,a),即在狀態x下執行a動作的概率。
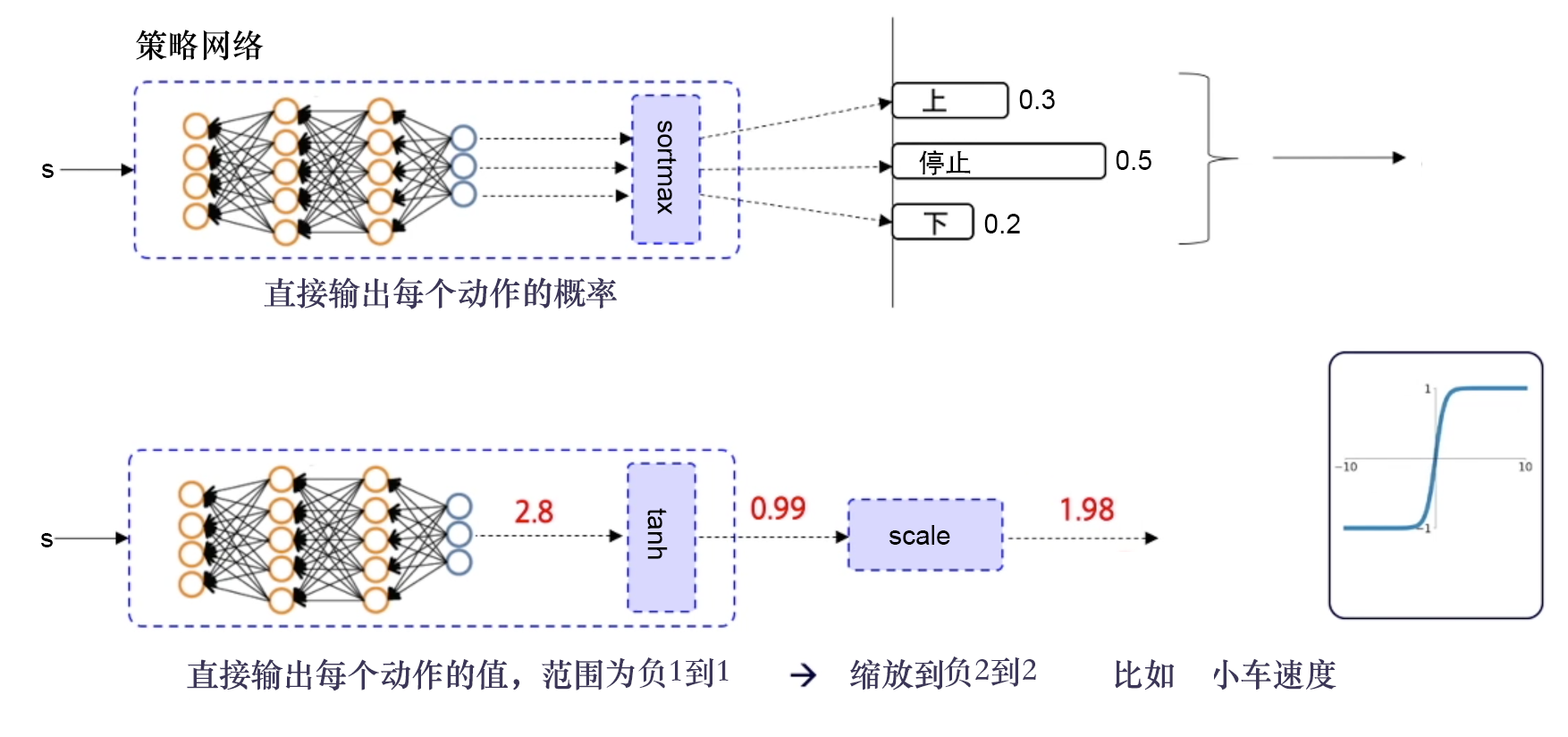
輸出離散動作,加一層 softmax 層,確保所有的輸出是動作概率,并且所有的動作概率和為 1。
輸出連續動作,加一層 tanh 函數,把輸出限制到 [?1,1],然后根據實際動作的范圍將其縮放,再輸出給環境。
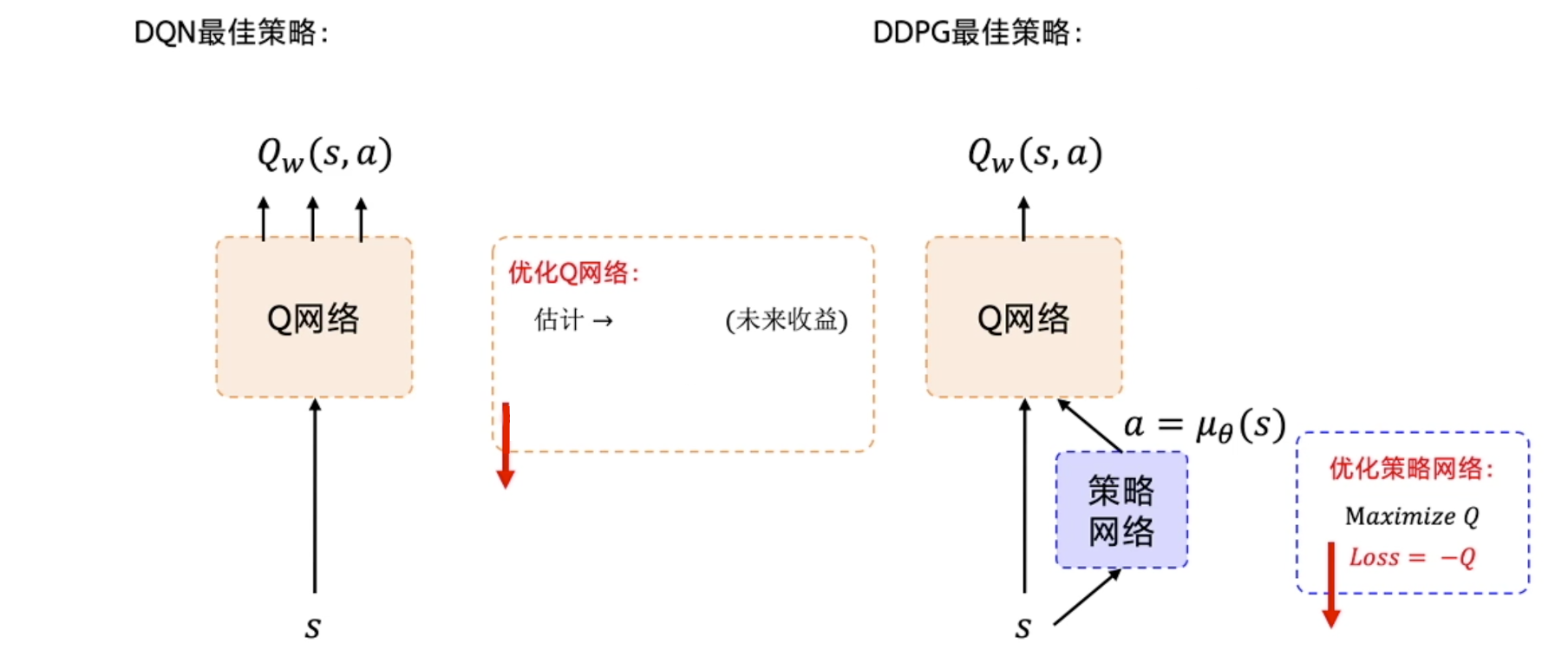
Google DeepMind提出的
使用Actor-Critic結構,結合了DQN結構的優勢,提高了Actor-Critic的穩定性和收斂性。
由于有環境反饋的獎勵存在,因此Critic的評分會越來越準確,所評判的Actor的表現也會越來越好。
優化策略網絡的梯度:最大化Q值。損失函數:-Q。
優化Q網絡:讓Q網絡的輸出逼近Q_target。損失函數:Qw(s,a)和Q_target的均方差。
DDPG要用到4個神經網絡,其中Actor和Critic各用1個網絡,此外它們都各自有1個目標網絡。
訓練需要用到的數據:只需要s、a、r、s′
經驗回放:用回放緩沖區把這些數據存起來,然后采樣進行訓練。經驗回放的技巧與DQN中的是一樣的。因為 DDPG 使用了經驗回放技巧,所以 DDPG 是off-policy。
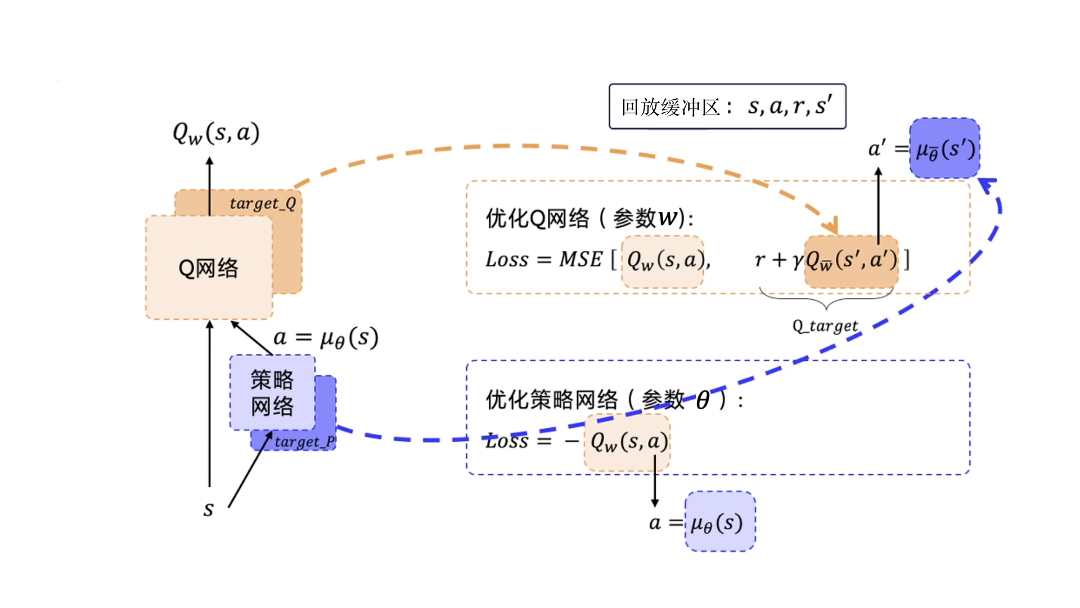
目標網絡的更新
軟更新: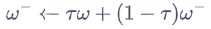
在DQN中,τ=1,即每隔一段時間將Q網絡直接復制給目標Q網絡;
在DDPG中,τ<1,目標Q網絡逐漸接近Q網絡。目標μ網絡也使用這種軟更新的方式。
DDPG采用了Double DQN中的技術來更新Q網絡。
由于DDPG采用的是確定性策略,它本身的探索仍然十分有限。
DQN算法的探索:行為策略采用貪婪策略
DDPG算法的探索:行為策略引入隨機噪聲。不相關的、均值為 0 的高斯噪聲

雙延遲深度確定性策略梯度(twin delayed DDPG,TD3)
雙延遲深度確定性策略梯度
TD3代碼
DDPG對于超參數和其他類型的調整方面經常很敏感。
DDPG常見的問題:已經學習好的 Q 函數開始顯著地高估 Q 值,導致策略被破壞,因為它利用了 Q 函數中的誤差。
截斷的雙 Q 學習(clipped double Q-learning)
TD3通過最小化均方差來同時學習兩個Q函數:Q ? 1 和 Q ? 2 。
2個Q函數都使用一個目標,2個Q函數中給出的較小的值會被作為 Q-target
延遲的策略更新(delayed policy updates)
以較低的頻率更新動作網絡,以較高的頻率更新評價網絡
通常每更新2次評價網絡就更新1次策略。
目標策略平滑(target policy smoothing)
在目標動作中加入噪聲,通過平滑 Q 沿動作的變化,使策略更難利用 Q 函數的誤差。
Soft Actor-Critic
off-policy、隨機性策略
比DDPG穩定
Soft Actor-Critic
DDPG 的訓練非常不穩定,收斂性較差,對超參數比較敏感,也難以適應不同的復雜環境。
2018 年,一個更加穩定的算法 Soft Actor-Critic(SAC)被提出。
SAC 的前身是 Soft Q-learning,它們都屬于最大熵強化學習的范疇。
Soft Q-learning 不存在一個顯式的策略函數,而是使用一個函數的波爾茲曼分布,在連續空間下求解非常麻煩。為了解決這個問題,SAC 提出使用一個 Actor 表示策略函數。
最大熵強化學習(maximum entropy RL)的思想就是除了要最大化累積獎勵,還要使得策略更加隨機。如此,強化學習的目標中就加入了一項熵的正則項
熵正則化增加了強化學習算法的探索程度,α越大,探索性就越強,有助于加速后續的策略學習,并減少策略陷入較差的局部最優的可能性。
最大熵強化學習:通過控制策略所采取動作的熵來調整探索與利用的平衡

目標導向的強化學習(goal-oriented reinforcement learning,GoRL)
目標導向的強化學習
事后經驗回放(hindsight experience replay,HER)算法于 2017 年神經信息處理系統(Neural Information Processing Systems,NeurIPS)大會中被提出,成為 GoRL 的一大經典方法。
多智能體強化學習(multi-agent reinforcement learning,MARL)
單智能體強化學習算法的基本假設:動態環境是穩態的(stationary),即狀態轉移概率和獎勵函數不變。
多智能體強化學習要比單智能體更困難:
- 在每個智能體的視角下,環境是非穩態的(non-stationary),即對于一個智能體而言,即使在相同的狀態下采取相同的動作,得到的狀態轉移和獎勵信號的分布可能在不斷改變;
- 多個智能體的訓練可能是多目標的,不同智能體需要最大化自己的利益;
- 訓練評估的復雜度會增加,可能需要大規模分布式訓練來提高效率。
獨立學習(independent learning):完全去中心化的算法
獨立 PPO(Independent PPO,IPPO)算法
中心化訓練去中心化執行(centralized training with decentralized execution,CTDE)
中心化訓練:在訓練的時候使用一些單個智能體看不到的全局信息而以達到更好的訓練效果
去中心化執行:在執行時不使用這些信息,每個智能體完全根據自己的策略直接動作。
優點:能夠在訓練時有效地利用全局信息以達到更好且更穩定的訓練效果,同時在進行策略模型推斷時可以僅利用局部信息,使得算法具有一定的擴展性。
多智能體 DDPG(muli-agent DDPG,MADDPG)
每個智能體實現一個 DDPG 的算法。
所有智能體共享一個中心化的 Critic 網絡,該 Critic 網絡在訓練的過程中同時對每個智能體的 Actor 網絡給出指導,而執行時每個智能體的 Actor 網絡則是完全獨立做出行動,即去中心化地執行。

應用案例:用戶關聯和信道分配
N. Zhao, Y. -C. Liang, D. Niyato, Y. Pei, M. Wu and Y. Jiang, “Deep Reinforcement Learning for User Association and Resource Allocation in Heterogeneous Cellular Networks,” in IEEE Transactions on Wireless Communications, vol. 18, no. 11, pp. 5141-5152, Nov. 2019, doi: 10.1109/TWC.2019.2933417.
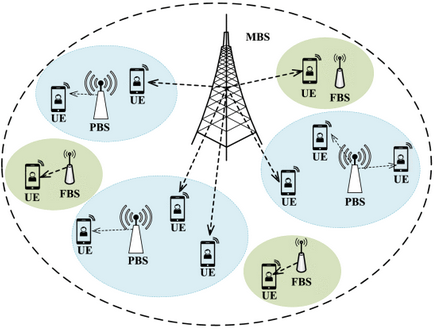
L BSs → N UEs
K orthogonal channels
the Joint user association and resource allocation Optimization Problem
variables: discrete
1.bli(t)=1: the i i ith UE chooses to associate with the BS l l l at time t t t
2.cik(t)=1: the i i ith UE utilizes the channel C k Ck Ck at time t t t
constraints
1.each UE can only choose at most one BS at any time
2.each UE can only choose at most one channel at any time
3.the SINR of the i t h ith ith UE ≥
a stochastic game
state
si(t) ∈{0, 1}
si(t)=0 means that the ith UE cannot meet its the minimum QoS requirement, that is, Γi(t) < Ωi
the number of possible states is 2 N 2^N 2N
action
alki(t)={bli(t),cik(t)},
1.bli(t)=1: the i i ith UE chooses to associate with the BS l l l at time t t t
2.cik(t)=1: the i i ith UE utilizes the channel C k Ck Ck at time t t t
The number of possible actions of each UE is L K LK LK = L種選擇方式 * K種選擇方式
reward
the long-term reward Φi = the weighted sum of the instantaneous rewards over a finite period T
the reward of the ith UE = the ith UE’s utility - the action-selection cost Ψi
Ψi > 0. Note that the negative reward (?Ψi) acts as a punishment.
to guarantee the minimum QoS of all UEs, this negative reward should be set big enough.
the ith UE’s utility = \rho_i * the total transmission capacity of the ith UE - the total transmission cost associated with the ith UE
Multi-Agent Q-Learning Method
At the beginning of each training episode, the network state is initialized through message passing.
- Each UE is connected to the neighboring BS with the maximum received signal power.
By using a pilot signal, each UE can measure the received power from the associated BS and the randomly-selected channel. - Then, each UE reports its own current state to its current associated BS.
By the message passing among the BSs through the backhaul communication link, the global state information of all UEs is obtained. - Then, the BSs send this global state informations to all UEs.
Each episode ends when the QoS of all UEs is satisfied or when the maximum step T is reached.
The total episode reward is the accumulation of instantaneous rewards of all steps within an episode.

Q i ( s , a i ) = Q i ( s , a i ) + δ [ u i ( s , a i , π ? i ) + γ max ? a i ′ ∈ A i Q i ( s ′ , a i ′ ) ? Q i ( s , a i ) [ u i ( s , a i , π ? i ) + γ max ? a i ′ ∈ A i Q i ( s ′ , a i ′ ) ] , {Q_{i}}(s,a_{i})={Q_{i}}(s,a_{i})+ \delta \left[{ {u_{i}}(s,a_{i},{\mathcal{ \pi }}_{-i}) + \gamma \max \limits _{a_{i}' \in {\mathcal{ A}}_{i}} {Q_{i}}({s'},{a_{i}'})} {- {Q_{i}}(s,a_{i})\vphantom {\left [{ {u_{i}}(s,a_{i},{\mathcal{ \pi }}_{-i}) + \gamma \max \limits _{a_{i}' \in {\mathcal{ A}}_{i}} {Q_{i}}({s'},{a_{i}'})}\right.} }\right], Qi?(s,ai?)=Qi?(s,ai?)+δ[ui?(s,ai?,π?i?)+γai′?∈Ai?max?Qi?(s′,ai′?)?Qi?(s,ai?)[ui?(s,ai?,π?i?)+γai′?∈Ai?max?Qi?(s′,ai′?)],
Multi-Agent dueling double DQN Algorithm
dueling double deep Q-network (D3QN)
A NN function approximator Q i ( s , a i ; θ ) ≈ Q i ? ( s , a i ) Q_{i}(s,a_{i};{\theta }) \approx {Q_{i}^{*}}(s,a_{i}) Qi?(s,ai?;θ)≈Qi??(s,ai?) with weights θ is used as an online network.
The DQN utilizes a target network alongside the online network to stabilize the overall network performance.
experience replay
During learning, instead of using only the current experience (s, ai,ui(s, ai),s′), the NN can be trained through sampling mini-batches of experiences from replay memory D uniformly at random.
By reducing the correlation among the training examples, the experience replay strategy ensures that the optimal policy cannot be driven to a local minima.
double DQN
since the same values are used to select and evaluate an action in Q-learning and DQN methods, Q-value function may be over-optimistically estimated.
Thus, double DQN (DDQN) [44] is used to mitigate the above problem
dueling architecture
The advantage function A(s, ai) describes the advantage of the action ai compared with the other possible actions.
This dueling architecture can lead to better policy evaluation.
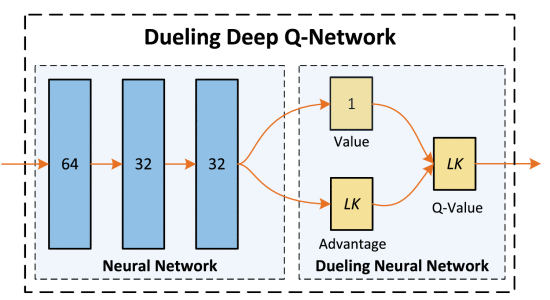
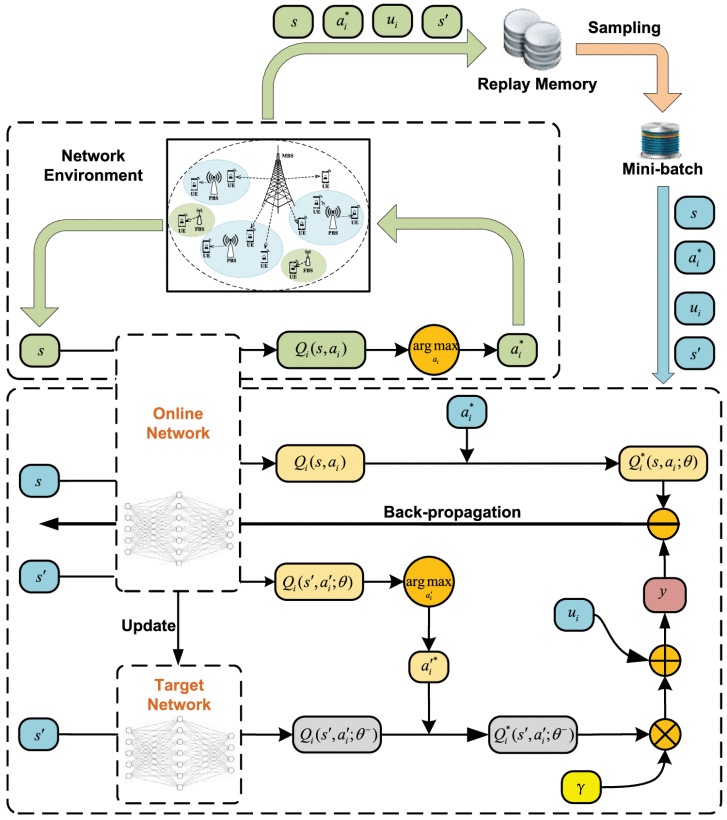
L i ( θ ) = E s , a i , u i ( s , a i ) , s ′ [ ( y i D Q N ? Q i ( s , a i ; θ ) ) 2 ] , {L_{i}}({\theta }) = {E_{s,a_{i},u_{i}(s,a_{i}),s'}}[{(y_{i}^{DQN} - Q_{i}(s,a_{i};{\theta }))^{2}}], Li?(θ)=Es,ai?,ui?(s,ai?),s′?[(yiDQN??Qi?(s,ai?;θ))2],
上圖里面紅色的y為
y i D D Q N = u i ( s , a i ) + γ Q i ( s ′ , arg ? max ? a i ′ ∈ A i Q i ( s ′ , a i ′ ; θ ) ; θ ? ) . y_{i}^{DDQN} = {u_{i}}(s,a_{i}) + \gamma Q_{i}\left ({s',\mathop {\arg \max }\limits _{a'_{i} \in {\mathcal{ A}}_{i}} Q_{i}(s',a'_{i};{\theta });\theta ^{-} }\right). yiDDQN?=ui?(s,ai?)+γQi?(s′,ai′?∈Ai?argmax?Qi?(s′,ai′?;θ);θ?).

應用案例:分布式動態下行鏈路波束成形
J. Ge, Y. -C. Liang, J. Joung and S. Sun, “Deep Reinforcement Learning for Distributed Dynamic MISO Downlink-Beamforming Coordination,” in IEEE Transactions on Communications, vol. 68, no. 10, pp. 6070-6085, Oct. 2020, doi: 10.1109/TCOMM.2020.3004524.
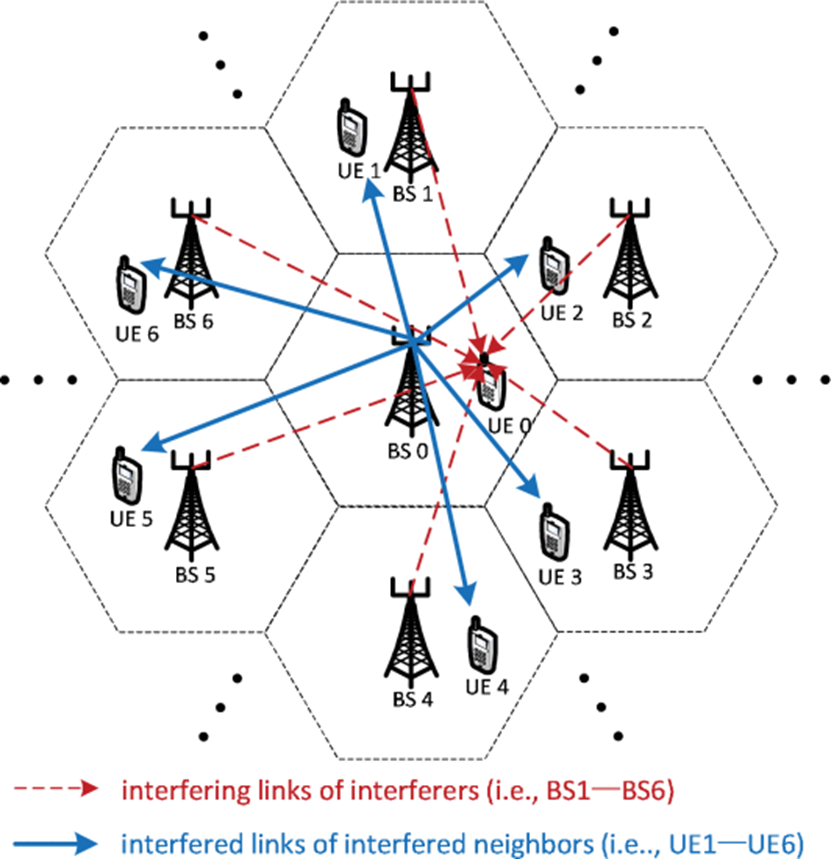
multi-cell MISO-IC model
a downlink cellular network of K cells
no intra-cell interference
all the BSs are equipped with a uniform linear array having N N N ( N ≥ 1 N≥1 N≥1) antenna elements.
max ? W ( t ) ∑ k = 1 K C k ( W ( t ) ) 8a s . t . 0 ≤ ∥ w k ( t ) ∥ 2 ≤ p m a x , ? k ∈ K , 8b \max _{\mathbf {W}{(t)}}~\sum _{k=1}^{K}C_{k}(\mathbf {W}{(t)}) \text{8a}\\{\mathrm{ s.t.}}~0\leq \left \|{\mathbf {w}_{k}{(t)}}\right \|^{2} \leq p_{\mathrm{ max}},~\forall k \in \mathcal {K},\text{8b} maxW(t)??∑k=1K?Ck?(W(t))8as.t.?0≤∥wk?(t)∥2≤pmax?,??k∈K,8b
the beamformer of BS k k k
the available maximum transmit power budget of each BS
Limited-Information Exchange Protocol
a downlink data transmission framework
The first phase (phase 1) is a preparing phase for the subsequent data transmission
the second phase (phase 2) is for the downlink data transmission.
in the centralized approaches, the cascade procedure of collecting global CSI, computing beamformers, and sending beamformers to the corresponding BSs is supposed to be carried out within phase 1.
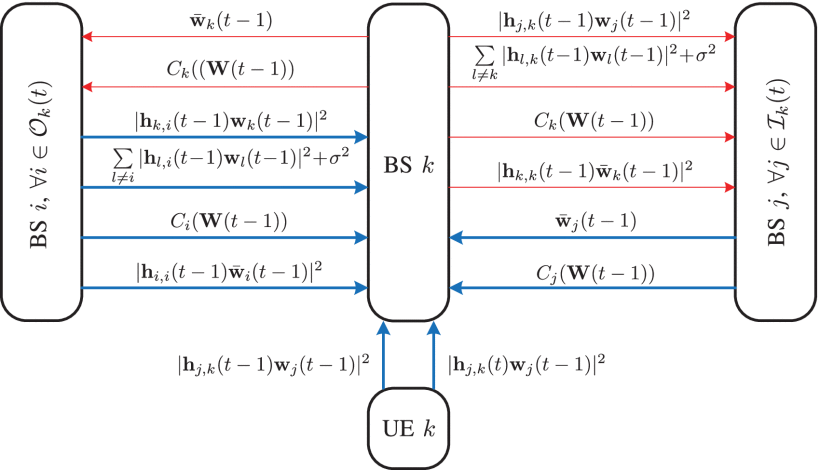
Designed limited-information exchange protocol in time slot t.
BSs are able to share their historical measurements and other information with their interferers and interfered neighbors.
- The received interference power from interferer j ∈ I k ( t ) j∈Ik(t) j∈Ik(t) in time slot t ? 1 t?1 t?1
, i.e., ∣ ∣ h ? j , k ( t ? 1 ) w j ( t ? 1 ) ∣ ∣ 2 ∣∣h?j,k(t?1)wj(t?1)∣∣2 ∣∣h?j,k(t?1)wj(t?1)∣∣2 . - The total interference-plus-noise power of UE k k k in time slot t ? 1 t?1 t?1
, i.e., ∑ l ≠ k ∣ ∣ h ? l , k ( t ? 1 ) w l ( t ? 1 ) ∣ ∣ 2 + σ 2 ∑l≠k∣∣h?l,k(t?1)wl(t?1)∣∣2+σ2 ∑l=k∣∣h?l,k(t?1)wl(t?1)∣∣2+σ2 . - The achievable rate of direct link k k k in time slot t ? 1 t?1 t?1
, i.e., C k ( W ( t ? 1 ) ) Ck(W(t?1)) Ck(W(t?1)) . - The equivalent channel gain of direct link k k k in time slot t ? 1 t?1 t?1
, i.e., ∣ ∣ h ? k , k ( t ? 1 ) w ˉ k ( t ? 1 ) ∣ ∣ 2 ∣∣h?k,k(t?1)wˉk(t?1)∣∣2 ∣∣h?k,k(t?1)wˉk(t?1)∣∣2 .
Distributed DRL-Based DTDE Scheme for DDBC
distributed-training-distributed-executing (DTDE)
distributed dynamic downlink-beamforming coordination (DDBC)
each BS is an independent agent
a multi-agent reinforcement learning problem
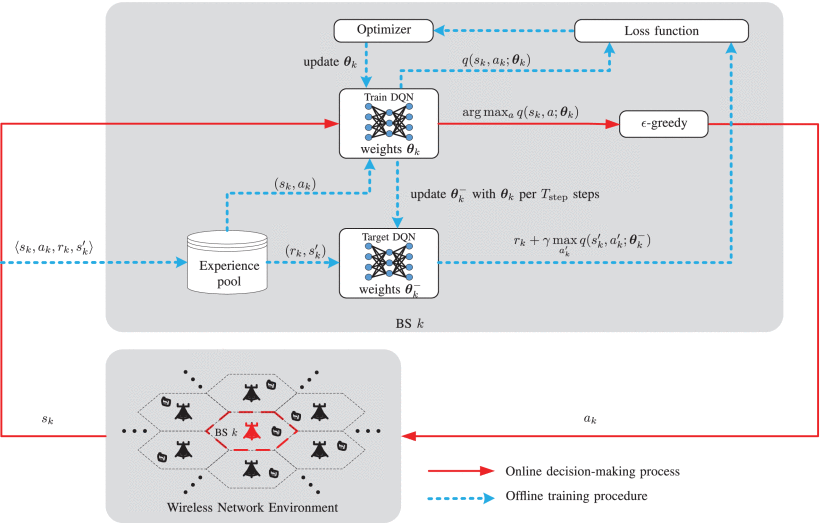
Illustration of the proposed distributed DRL-based DTDE scheme in the considered multi-agent system.
- Actions
A = { ( p , c ) , p ∈ P , c ∈ C } , \mathcal {A} = \{(p, {\mathbf{c}}),~p\in \mathcal {P},~{\mathbf{c}}\in \mathcal {C}\}, A={(p,c),?p∈P,?c∈C},
P = { 0 , 1 Q p o w ? 1 p m a x , 2 Q p o w ? 1 p m a x , ? , p m a x } \mathcal {P}=\left \{{0, \tfrac {1}{Q_{\mathrm{ pow}}-1}p_{\mathrm{ max}},\,\,\tfrac {2}{Q_{\mathrm{ pow}}-1}p_{\mathrm{ max}},\,\,\cdots,\,\,p_{\mathrm{ max}}}\right \} P={0,Qpow??11?pmax?,Qpow??12?pmax?,?,pmax?}
C = { c 0 , c 1 , ? , c Q c o d e ? 1 } \mathcal {C}=\left \{{\mathbf {c}_{0},\,\,\mathbf {c}_{1},\,\,\cdots,\,\,\mathbf {c}_{Q_{\mathrm{ code}}-1}}\right \} C={c0?,c1?,?,cQcode??1?}
1.the transmit power of BS k in time slot t
2.code c k ( t ) ck(t) ck(t)
the total number of available actions is Q = Q p o w Q c o d e Q=QpowQcode Q=QpowQcode - States
1.Local Information
2.Interferers’ Information
3.Interfered Neighbors’ Information - Reward
the achievable rate of agent k k k
the penalty on BS k is defined as the sum of the achievable rate losses of the interfered neighbors j∈Ok(t+1) , which are interfered by BS k , as follows:
Distributed DRL-Based DTDE Scheme for DDBC

In training step t , the prediction error
L ( θ ) = 1 2 M b ∑ ? s , a , r , s ′ ? ∈ D ( r ′ ? q ( s , a ; θ ) ) 2 L(\boldsymbol {\theta })= \frac {1}{2M_{b}}\sum \limits _{\langle s,a,r,s'\rangle \in \mathcal {D}}\left ({r'-q(s,a; \boldsymbol {\theta })}\right)^{2} L(θ)=2Mb?1??s,a,r,s′?∈D∑?(r′?q(s,a;θ))2
the target value of reward
r ′ = r + γ max ? a ′ q ( s ′ , a ′ ; θ ? ) r'= r + \gamma \max \limits _{a'}q(s',a'; \boldsymbol {\theta }^{-}) r′=r+γa′max?q(s′,a′;θ?)
the optimizer returns a set of gradients shown in (22) to update the weights of the trained DQN through the back-propagation (BP) technique
? L ( θ ) ? θ = 1 M b ∑ ? s , a , r , s ′ ? ∈ D ( r ′ ? q ( s , a ; θ ) ) ? q ( s , a ; θ ) . \frac {\partial L(\boldsymbol {\theta })}{\partial \boldsymbol {\theta }}= \frac {1}{M_{b}}\sum _{\langle s,a,r,s'\rangle \in \mathcal {D}}\left ({r'-q(s,a; \boldsymbol {\theta })}\right)\nabla q(s,a; \boldsymbol {\theta }). ?θ?L(θ)?=Mb?1?∑?s,a,r,s′?∈D?(r′?q(s,a;θ))?q(s,a;θ).







)


)
)


ConfigFS 的核心數據結構)




