云布道師
本文根據 2023 云棲大會演講實錄整理而成,演講信息如下:
演講人:劉一鳴 | 阿里云自研大數據產品負責人
演講主題:Data+AI 時代大數據平臺應該如何建設
今天分享的主題是 Data+AI 時代大數據平臺應該如何建設,這個話題既是對我們過去一年工作的反思和總結,同時也是希望通過這個反思和總結,不管大家是否使用阿里云的平臺和技術,在未來大數據平臺的選型、運維、創新上都可以有一些啟發,同時也會思考未來大數據人的角色、工作方式是否有一些新的變化。
阿里云大數據的核心是兩款分布式計算引擎,在 ODPS(Open Data Processing Platform)品牌之下,今天的分享也會更多圍繞 ODPS 的兩個核心引擎來講(面向批量數據加工和海量存儲的 MaxCompute、面向實時數倉以及交互式分析場景的Hologres)。下面進入正題,希望跟大家分享我們過去做平臺時候的反思,什么能力是關鍵能力,以及今年我們做了哪些能力的提升。
降本能力:靈活的付費模式驅動大數據成本的顯著下降
降本能力是每個大數據平臺的核心能力,特別是作為公共云上的服務方,我們不希望大家使用云上的大數據平臺是一個成本的黑洞,越用越貴,每年老板說錢花哪里去還說不清楚,我們希望不僅給用戶提供一個成本費用說得清楚用得明白的平臺,也希望給用戶提供一個通過正確使用產品可以不斷降低單位擁有成本的平臺。降本從不意味著要使用更便宜的規格,更少的資源,這會潛在犧牲平臺的服務質量,不是正確的降本姿勢,低價往往質量缺少保障,最后會收獲更低質量的服務,更低質量的研發投入,最后導致平臺無法維系。
合理的降本方式首先是選擇合適的采購策略、付費策略,選擇一個合適的技術。以MaxCompute 為例,平臺提供多種付費方式,從比較經典的預付費或者叫包年包月,到用得最多的后付費或者叫按量付費的模型。預付費對預算控制更精確,費用提前說清楚,但資源使用受限制,無法滿足臨時性需求,也會產生閑置資源的空閑浪費。按量付費模型根據實際業務規模產生費用,無需提前做容量規劃,但實際費用容易超出預算控制。現在我們希望把兩種模式做一些結合。
我們看到大部分數據加工作業都具備一定的時間規律,夜間往往高峰期,早上上班看到計算結果,白天相對水位是低峰期,這里可以利用 MaxCompute 的分時彈性能力,日常低水位運行,高峰期彈性出來額外資源。分時彈性去年上線的,今年通過對庫存管理的優化,實現庫存效率上的提升,在 9 月 20 日開始 MaxCompute 彈性部分的 CU 單價直接降低 50%。如果一天有 8h 作業跑不滿的情況,采用分時作業的方式一定是降本的,希望每個用戶可以根據大家實際使用場景去選擇分時策略。
原理類似 ECS 上的 Spot Instance,MaxCompute 今年推出了閑時作業,也通常叫做 SpotJob,定價直接是按量付費定價的三分之一,閑時作業是把大數據集群的閑置資源服務出來,不一定保障每天運行的時候都能得到一樣的資源,執行一樣快,在集群繁忙時會有更多的作業等待時間,但對于延時不敏感的作業,如歷史數據的導入、日常開發調試作業的場景,通過使用閑時作業可以有效降本 66%。
分時彈性既能滿足彈性,也能滿足預算的管理,那么該怎么設置是最優的?MaxCompute 發布了成本優化器,幫助用戶分析過去 30 天所有作業的資源分布特征,展示出高峰期和低谷期,給出彈性策略應該怎么設計的建議。在彈性的基礎上,我們給作業增加了一個關鍵的約束條件叫基線,基線之前的作業需要足夠的資源保障,讓結果準時計算出來,基線之后的作業可以跑慢一些,更節省資源和費用,這樣就區分了作業的優先級和重要性。絕大部分用戶使用成本優化器之后,通常有 20% 以上成本降低,建議大家可以盡快采用起來。
接下來我們談談存儲如何降本。數據在實際使用時會分特征,有些數據是高頻訪問,數據的重要性有可能更高,有些數據是低頻訪問數據,一個月就讀取一兩次,有的數據是審計要求,不可以刪除,一年不一定訪問一次。數據有價值分配,那么我們的數據成本是否也應該有分層設計呢?當然。MaxCompute 為不同訪問特征,不同價值數據提供不同的存儲能力,分層存儲提供了分層的單價。通過分層存儲的方式可以看到一些低頻訪問的數據,長期訪問的數據成本可以降到以前的三分之一。
計算和存儲可以通過平臺的使用策略來節省成本,其實還可以通過存儲技術的創新實現進一步的降本。JSON 是互聯網上使用非常廣泛的數據結構,半結構化,查詢靈活,存儲也方便,Schema 可以隨時調整,但過去 JSON 如果用字符串去存儲的時候,哪怕僅僅訪問一個字節,也需要把幾兆字節全部解析出來,對計算和IO都是極大的浪費。另一種方案是 JSON 數據落庫前,提前進行 JSON 結構的打寬,需要大量的加工作業,也是對計算資源的浪費。
如何有效提升 JSON 數據類型的存儲和訪問效率成為大數據平臺的關鍵能力,今年包括 MaxCompute 和 Hologres,都提供 JSON 原生化的管理能力,包括元數據支持和存儲列式壓縮,把半結構化作為一級處理類型來支持,在用戶實踐中,絕大部分用戶的 JSON 存儲成本會降到以前的五分之一,而且查詢會變得更快。
輕運維能力:Serverless 變革大數據運維模式
云上大數據平臺,應該提供運維足夠簡單易用,把臟活累活幫助使用者運維掉,幫助大數據工程師實現角色升級,從過去相對被動每天考慮系統平臺的穩定性、擴展性、資源如何分配、備份、容災、升級、修 bug 這些臟活累活中解脫出來,轉變成數據的分析師,變成AI專家,變成領域專家,而不是做重復的運維工作。
我們認為 Serverless 架構是解決運維問題的關鍵,那么如何做 Serverless 架構呢?從大數據架構上講,通常我們分三種:1.Shared-Nothing 架構,存算一體。通過節點之間的橫向擴展,實現計算力和存儲能力的提升。2.Shared-Everything,計算存儲全部解耦開來,所有的資源都可以共享。3. Shared-Data,Data 部分是共享,計算部分隔離開來,提供更好的隔離能力。每個技術會選擇不同架構。
MaxCompute 選擇 Shared-Everything,對平臺側的隔離技術實現要求很高,對運維側、調度側要求更高,所有計算資源、存儲資源是共享在統一的公共集群里。Hologres 選擇 Shared-Data 架構,這個系統需要更多考慮在線服務場景下資源的隔離和穩定性,所以不同系統選擇不同架構。
這個架構背后我們會把整個集群當做一個統一的計算資源來管理。對用戶來說最大價值是,不僅是使用成本的降低,不需要提前做容量規劃,更重要的是,不需要處理復雜的升級運維,讓用戶可以實現零停機的方式實現版本的迭代,這都是 Serverless 架構創造的價值,平臺側希望把臟活累活,包括升級、備份、災備、彈性這些事情通過架構的方式把它解決,這也是 Serverless 背后核心的理念。
大家過去講 Serverless 更多講資源上省錢,只為使用的資源付費,而我相信Serverless 更多是把運維方式轉變,讓工程師更聚焦到價值的創造上。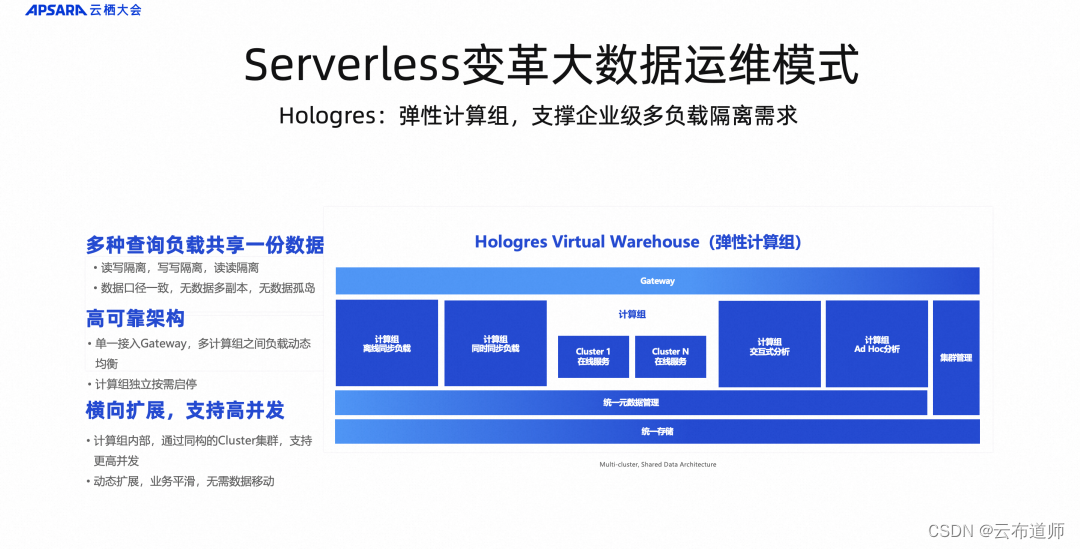
Hologres 在 Serverless 架構上一直演進,今年提出了彈性計算組的概念,這個計算組概念背后是共享數據,共享接入層,但在計算節點上做了資源切分,當不同業務團隊使用同一份數據的時候,每個團隊可以為自己的使用場景去彈性分配資源,同時保障數據的一致性,支持實時寫入,實時查詢,這是在 Hologres 上做的創新。
開放能力:湖倉一體與開放性
在談到大數據平臺的開放性時,更多講 Open Storage + Open Format,今天阿里的大數據平臺希望做到更多一層。云計算對技術的開放性要求會更高,一方面云廠商不希望自己變成綁架用戶的角色,MaxCompute 也不希望大家使用之后就被綁架在平臺上,不可以切換。另一方面云平臺上不同技術之間交互的強度、密度是遠大于線下的,技術之間需要分鐘級部署,分鐘級打通,用戶對技術的交互性要求很高,我們希望把開放性做得很徹底,我們不希望把創新只放在自己手里,我們希望把創新交還給用戶。
首先,阿里云的大數據完全擁抱 Open Storage + Open Format,提供了湖倉一體的解決方案,為用戶提供接近原生的元數據管理和數據讀寫體驗。對于什么是湖倉一體,行業內有兩個思路,一個是在湖上長出一個倉,把湖變成倉。典型特點是把湖上的數據結構提供更好的更新能力,接近數據庫的開發體驗。另一個方式從倉的管理能力拓展外表能力,實現湖上半結構化、非結構化數據以元數據方式管理起來,相當于倉去管理湖,這也是湖倉一體的形態。MaxCompute 是第二種形態,用倉去管湖,把存在 OSS 上的 Hudi 格式、Delta Lake 等格式,包括今年阿里自己創新的 Paimon 格式,都可以在 MaxCompute 和 Hologres 中作為外表直接訪問。同時也做了一些創新,把 OSS上 的非結構化文件定義為抽象的目錄表,這樣在數倉里可以用更加精細化的安全管控方式去做授權,哪些用戶可以訪問哪些文件,怎么訪問,包括審計都可以記錄下來。
湖倉一體最關鍵是元數據的管理,數據不管存在倉上、湖上,需要有一個統一的視圖可以看到所有的元數據,數據被誰定義,數據怎么解析,這是湖倉一體核心的概念,而并不是一定是一個系統還是兩個系統。
MaxCompute 今年在開放性上有很大的變化。大家過去認為倉的理念是數據計算都在這兒,但我們今天希望把 MaxCompute 存儲作為獨立的產品形態對外提供服務,把Storage這一層提供產品化的能力,提供 Storage API,支持高吞吐、高性能的原生 IO 接口。不管使用機器學習的 PAI 平臺還是使用 Spark、Presto,都可以像MaxCompute 原生的 SQL 引擎一樣去訪問倉里的數據,我們希望把自研大數據平臺的數據開放出去,支持用戶使用第三方引擎持續創新。
智能優化能力:AI 加持的智能數倉
過去做優化的時候很依賴于 DBA 同學對一個數倉技術原理的理解,在云的時代,用戶把數據托管到云平臺上,云平臺就有很大責任幫助用戶做好優化這件事。我們希望從過去基于經驗的運維向智能化運維前進。
比如 MaxCompute 通過物化視圖把公共的 SQL 計算子集推薦出來,實現資源的復用,這是一種空間換時間非常有效的方法。經過一年多時間的迭代,在推薦效率上已經做了很大的改進,絕大部分推薦出來的物化視圖質量都是很高,可以做到成本的節省和效率上的提升。
大數據成為 AI 的基礎設施
今年 AI 很熱,很多了不起的創新,但其實 AI 的創新中,大數據也扮演了關鍵的基礎設施角色。同時我們也希望用了云上大數據平臺的用戶,不需要再做那些低效繁重的運維工作,而是更多做一些 AI 上的場景和應用創新。我們也提出了大數據 AI 一體化,事實上大數據 AI 是各有分工,大數據為 AI 提供數據的支撐,這包括大數據平臺要做好規模數據的處理,提供分布式計算框架,提供科學計算的一站式開發環境,其次機器學習平臺也會為大數據平臺提供優化的算法、優化的模型。
在過去 SQL 的基礎上,我們認為 Python 也應該成為 MaxCompute 平臺的一級開發語言。MaxCompute 全新發布,One Env+One Data+One Code,這背后核心就是提供一個 Python 的運行環境,一個Notebook的交互式開發體驗,讓有 SQL 基礎的同學,有 Python 經驗的同學,需要利用 Python Library 進行數據處理的場景,可以在統一的開發環境下,實現高效率的開發和調試,實現 Python 和coMaxCompute 數據的原生打通。
全面升級 DataFrame 能力,發布分布式計算框架 MaxFrame,100% 兼容 Pandas 等數據處理接口,通過一行代碼即可將原生 Pandas 自動轉為 MaxFrame 分布式計算,打通數據管理、大規模數據分析、處理到 ML 開發全流程,打破大數據及 AI 開發使用邊界,大大提高開發效率。
最后講下向量數據庫,Hologres 內置達摩院向量引擎 Proxima,支持高性能、實時化的向量檢索服務。使用 SQL 接口可以訪問向量數據,在原有交互式分析場景下幫助大家更好使用 AI 場景。




)

:Routine Load查看和修改作業)
)


限制等)



redis 的擴展應用 lua(一))



——合并數組區間_中等)
