1.CMS的兩種模式與一種特殊策略
1.1Backgroud CMS(沒有并發失敗的情況)
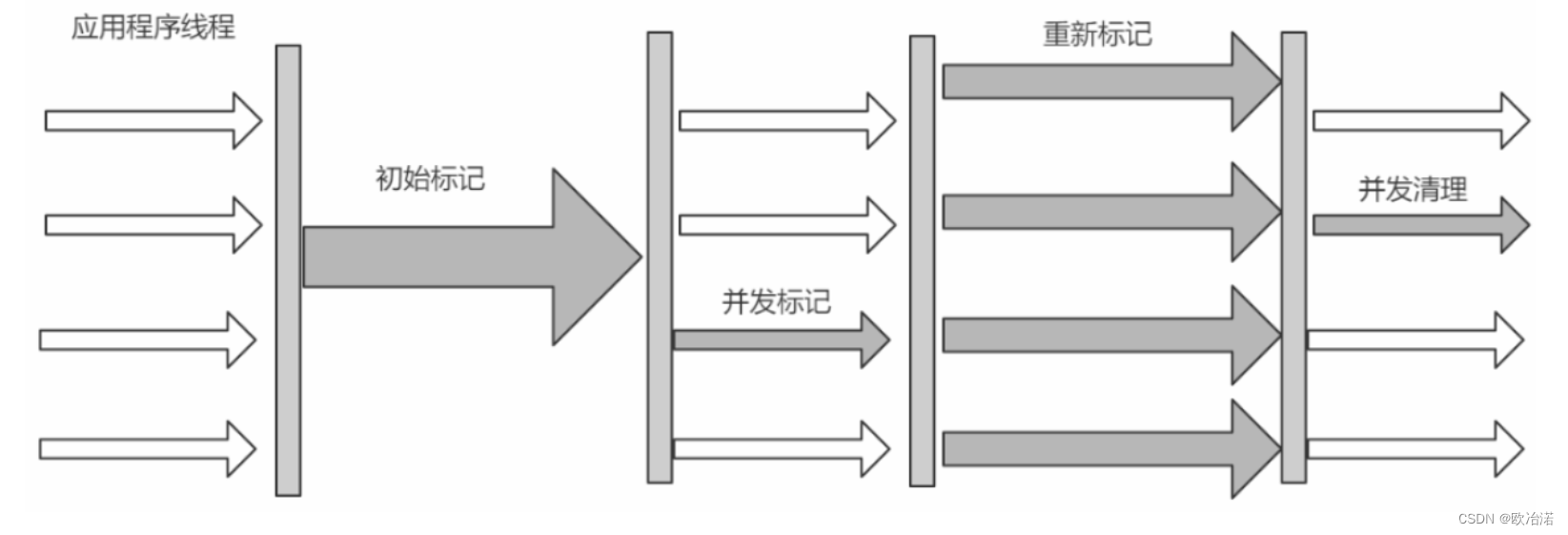
1.1.1并發標記還能被整理成兩個流程
(1)初始標記
(2)并發標記(3)(4)在這個階段發生
(3)并發預處理
(4)可中止的預處理
(5)重新標記
(6)并發清除
1.1.2為什么我們的并發標記細化之后還會額外有兩個流程出現呢?
討論這個問題之前,我們先思考一個問題,假設CMS要進行老年代的垃圾回收,我們如何判斷被年輕代的對象引用的老年代對象是可達對象。
當老年代被回收的時候,我們如何判斷A對象是存活對象。
必須掃描新生代來確定,所以CMS雖然是老年代的垃圾回收器,卻需要掃描新生代的原因。
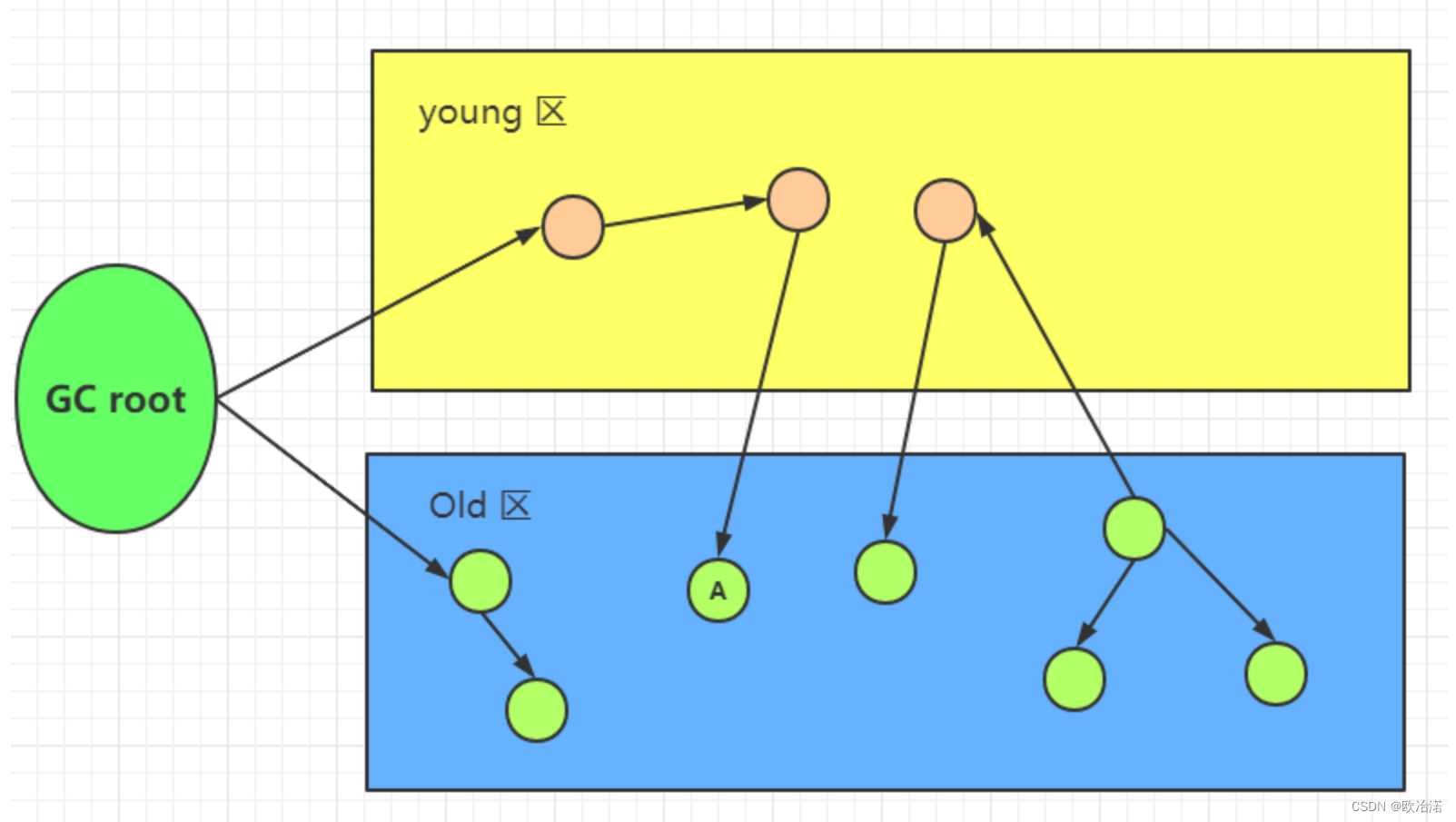
既然這個時候我需要掃描新生代,那么全量掃描會不會很慢
答:肯定會的 ,但是接踵而來的問題:既然會很慢,我們的停頓時間很長,可是CMS的目標是什么,CMS(Concurrent Mark Sweep)收集器是一種以獲取最短回收停頓時間為目標的收集器。這不是與他的設計理念不一致嗎?
1.1.3那怎么讓我們的回收變快?
肯定是垃圾越少越快。所以我們的CMS想到了一種方式,就是我先進行新生代的垃圾回收,也就是一次young GC,回收完畢之后。是不是我們新生代的對象就變少了,那么我再進行垃圾回收,是不是就變快了。可以通過CMS提供的兩個參數控制垃圾的回收。
CMSScheduleRemarkEdenSizeThreshold 默認值:2M
CMSScheduleRemarkEdenPenetration 默認值:50%
這兩個參數組合起來就是預清理之后,Eden空間使用超過2M的時候啟動可中斷的并發預清理,(CMS-concurrent-abortable-preclean),到Eden空間使用率到達50%的時候中斷(但不是結束),然后進入Remark(重新標記階段)。
1.1.4這里面有個概念,為什么并發預處理前面會有可中斷的意思
可中斷意味著,假設你一直在預處理,預處理是干什么,無非就是去幫你把正式應該處理的前置工作給做了。所以他一定干了很多事情,但是這些事情遲早有個頭,所以就設置了一個時間對他進行打斷。所以,并發預處理的邏輯是當你發生了minor GC ,我就預處理結束了但是,我怎么知道你什么時候發生minor GC?
答案是我不知道,垃圾回收是JVM自動調度的,所以我們無法控制垃圾回收,那我不可能無限制的執行下去,總要有個結束時間吧,所以CMS提供了一個參數
CMSMaxAbortablePrecleanTime ,默認為5S
只要到了5S,不管發沒發生Minor GC,有沒有到CMSScheduleRemardEdenPenetration都會中止此階段,進入remark,如果在5S內還是沒有執行Minor GC怎么辦?CMS提供一個參數
CMSScavengeBeforeRemark參數,使remark前強制進行一次Minor GC。
1.2老年代的策略:記憶集解決每次oldGC都要yuongGC的問題
當我們進行young gc時,可作為gc roots的東西除了常見的棧引用、靜態變量、常量、鎖對象、class對象這些常見的之外,如果老年代有對象引用了我們的新生代對象,那么老年代的對象也應該加入gc roots的范圍中,但是如果每次進行young gc我們都需要掃描一次老年代的話,那我們進行垃圾回收的代價實在是太大了,因此我們引入了一種叫做記憶集的抽象數據結構來記錄這種引用關系。
記憶集是一種用于記錄從非收集區域指向收集區域的指針集合的數據結構。
如果我們不考慮效率和成本問題,我們可以用一個數組存儲所有有指針指向新生代的老年代對象。但是如果這樣的話我們維護成本就很好,打個比方,假如所有的老年代對象都有指針指向了新生代,那么我們需要維護整個老年代大小的記憶集,毫無疑問這種方法是不可取的。因此我們引入了卡表的數據結構
1.2.1卡表
記憶集是我們針對于跨代引用問題提出的思想,而卡表則是針對于該種思想的具體實現。(可以理解為記憶集是結構,卡表是實現類)
在hotspot虛擬機中,卡表是一個字節數組,數組的每一項對應著內存中的某一塊連

——抽象工廠模式)
)




)











