MySQL是一個廣泛使用的關系型數據庫管理系統。通過SQL語言進行數據操作和查詢,還支持多用戶、多線程和分布式操作等功能。
在實際使用中,我們會遇到各種查詢條件,如字段名、表名、邏輯運算符、比較運算符、函數等。其中,有些查詢條件可能數據量比較大,導致查詢速度變慢。下面就來探討一下如果通過利用內存過濾方式來進行效率優化。

相信各位應用研發小伙伴在日常研發過程中,會經常遇到批量入參場景,需要根據入參信息從數據庫獲取相應資訊。
常規的做法,大家更多的會采用對入參數據拼接形成執行SQL方式,因為這種方式編寫簡單,邏輯清晰,但是面臨的可能是嚴重的效能問題。
【場景舉例】
接口API - data.get 入參集合ParamLists為1000筆數據,業務邏輯需要根據入參條件批量獲取業務數據,并進行業務后續業務處理:

目前應用研發常用方式【SQL拼接】:

當前方式是否存在效能風險?
是
- 因為每個條件都需要進行判斷,并且需要根據條件進行索引以查找匹配值。如果條件過多,則檢索的數據量就會變得非常大,因此查詢效率會降低。
- 查詢條件也會影響索引的使用。如果一個查詢條件沒有索引,那么MySQL就需要掃描整個表來找到匹配值,這也是很耗時,根據以往慢SQL表現,一般耗時會在5s以上。
先可以通過執行計劃,判斷當前SQL是否有效或者正確的使用到索引。在索引分析時,需要注意的是,并不是SQL有使用到索引就排除索引問題,執行計劃索引分析時,需要關注type欄位,判斷出當前是否使用到索引,以及索引使用類型,range、index、all都是需要被重點關注的。同時結合ref,key_len欄位判斷索引使用是否合理 ,以及extra判斷是否有額外操作消耗,比如排序、臨時表等。
下面主要說明下,對于這種大量入參拼接查詢場景,怎么可以通過內存過濾方式處理。思想是,在一定數據量前提下,利用索引快速查詢冗余數據,同?時結合內存快速過濾需要的數據。
(1)數據量評估
評估使用索引欄位查詢后的數據量,比如以上案例tenatsid為wo_detail索引欄位,則查看該租戶下數據量,如果數據量為2w以內(這里為初略標準,具體可以根據需要輸出的欄位以及數據量做內存評估),
則可以考慮使用內存方式解決,如果數據量過大,可能會帶來額外的內存或者效能問題。
(2)SQL調整
此時SQL可以調整為:

因為整體數據量少,且能有效使用到索引查詢,因此SQL查詢效率快,一般在毫秒級,如果索引條件更加精確可以減少更多數據量。但需要注意的是,當前獲取到數據集是冗余的,它包含了我們需要的數據集以及其它數據集。接下來就是期望在內存中過濾出我們需要的數據
(3)內存數據過濾優化
到此我們期望從2w筆數據在內存中快速找到1000筆數據信息:
驗證數據準備:
1、datas 為數據庫讀取數據約2w筆
2、param 為入參數據量約1000筆
數據對應關系:1v1,即1個入參條件對應1條數據庫數據
(為了測試內存數據過濾優化帶來的效能提升,我這里提前將入參和數據庫數據按統一條件排序)
【常規循環讀取】
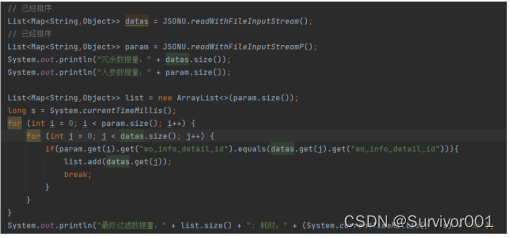
結果:
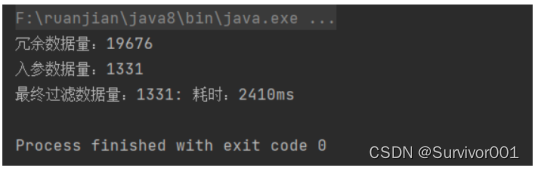
過濾耗時約2秒,相對于直接從數據庫讀取數據,在一定數據量下前提下,內存過濾時間相對更快。
是否有更快的過濾優化方式呢?
當然有
- 確保入參數據和查找數據的保持相同的欄位順序,減少無效查找次數。
- 內循環查找中記錄index,減少時間復雜度。
思路如下:
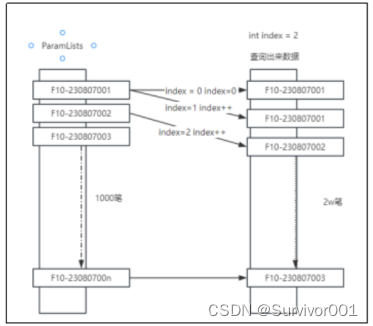
因為ParmList與查詢數據保持相同欄位順序,再過濾過程中,每處理掃描一條數據數組則index++
當進行F10-230807002數據查找時,此時index=2,這時直接從數據庫集合中index為2位置開始讀取數據。
如此,在1v1數據查詢中,可以將時間復雜度從O(N*M)將到O(N),在1vN中數據庫集合越大,則提效越明顯。
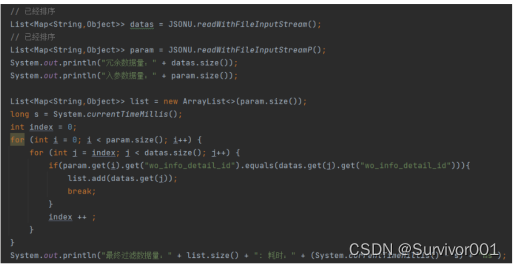
結果:
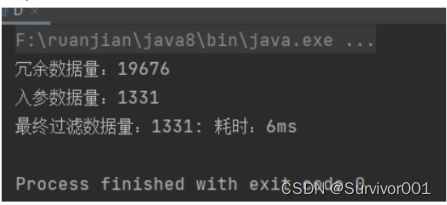
可以看到耗時時間從2s - >6ms
如果:入參和數據庫場景為1vn場景下,這個時候就不能使用break,可以定義一個標識來記錄當前入參數據的讀取是否結束
結論
? ? ? 在大數據量拼接SQL查詢業務中,根據場景數據量、復雜程度等條件綜合判斷優化方案,一般場景中數據量不是很大時可以考慮使用【冗余讀取+內存過濾優化方案】來處理。如果數據集合過大,可能帶來內存和更多的效能問題時,可以考慮采用其他方案,比如分批處理、臨時表關聯處理等



演示案例)















