1.什么是Ribbon
目前主流的負載方案分為以下兩種:
????????集中式負載均衡,在消費者和服務提供方中間使用獨立的代理方式進行負載,有硬件的(比如 F5),也有軟件的(比如 Nginx)。
????????客戶端根據自己的請求情況做負載均衡,Ribbon 就屬于客戶端自己做負載均衡。
????????Spring Cloud Ribbon是基于Netflix Ribbon 實現的一套 客戶端的負載均衡工具, Ribbon客戶端組件提供一系列的完善的配置,如超 時,重試等。通過 Load Balancer 獲取到服務提供的所有機器實例,Ribbon會自動基于某種規則(輪詢,隨機)去調用這些服務。Ribbon也 可以實現我們自己的負載均衡算法。
1.1 客戶端的負載均衡
????????例如spring cloud中的ribbon,客戶端會有一個服務器地址列表,在發送請求前通過負載均衡算法選擇一個服務器,然后進行訪問,這是 客戶端負載均衡;即在客戶端就進行負載均衡算法分配。
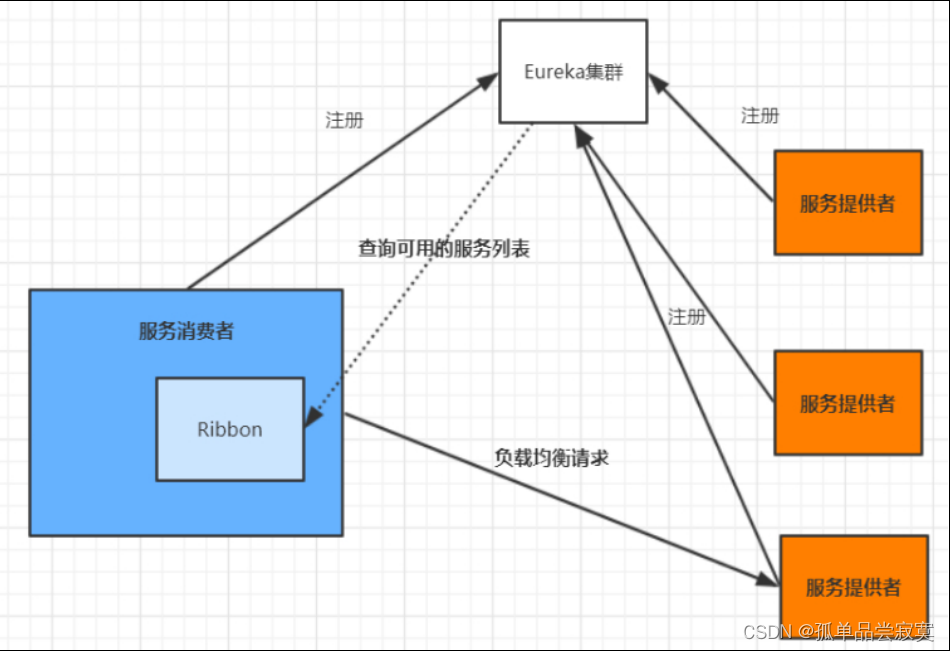
1.2 服務端的負載均衡
????????例如Nginx,通過Nginx進行負載均衡,先發送請求,然后通過負載均衡算法,在多個服務器之間選擇一個進行訪問;即在服務器端再進 行負載均衡算法分配。
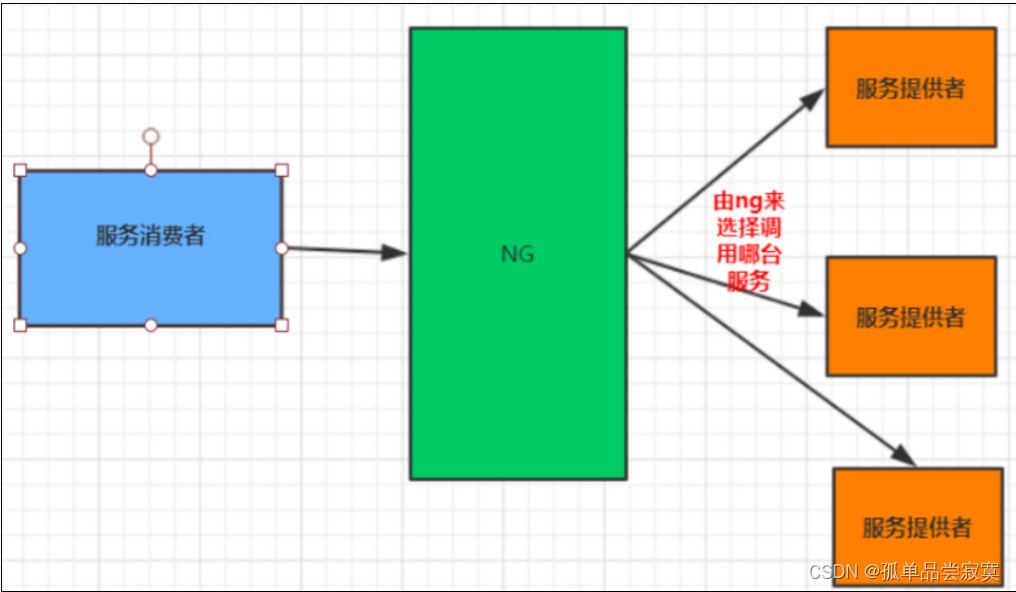
1.3 常見負載均衡算法
????????隨機,通過隨機選擇服務進行執行,一般這種方式使用較少;
????????輪訓,負載均衡默認實現方式,請求來之后排隊處理;
????????加權輪訓,通過對服務器性能的分型,給高配置,低負載的服務器分配更高的權重,均衡各個服務器的壓力;
????????地址Hash,通過客戶端請求的地址的HASH值取模映射進行服務器調度。 ip --->hash
????????最小鏈接數,即使請求均衡了,壓力不一定會均衡,最小連接數法就是根據服務器的情況,比如請求積壓數等參數,將請求分配到當前壓力最小的服務器上。 最小活躍數
2. Nacos使用Ribbon
nacos-discovery依賴了ribbon,可以不用再引入ribbon依賴

2) 添加 @LoadBalanced 注解
@Configurationpublic class RestConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}} 3) 修改controller
@Autowiredprivate RestTemplate restTemplate;@RequestMapping(value = "/findOrderByUserId/{id}")public R findOrderByUserId(@PathVariable("id") Integer id) {// RestTemplate調用//String url = "http://localhost:8020/order/findOrderByUserId/"+id;//模擬ribbon實現//String url = getUri("mall‐order")+"/order/findOrderByUserId/"+id;
// 添加@LoadBalanced
String url = "http://mall‐order/order/findOrderByUserId/"+id;
R result = restTemplate.getForObject(url,R.class);return result;
} 3 Ribbon負載均衡策略
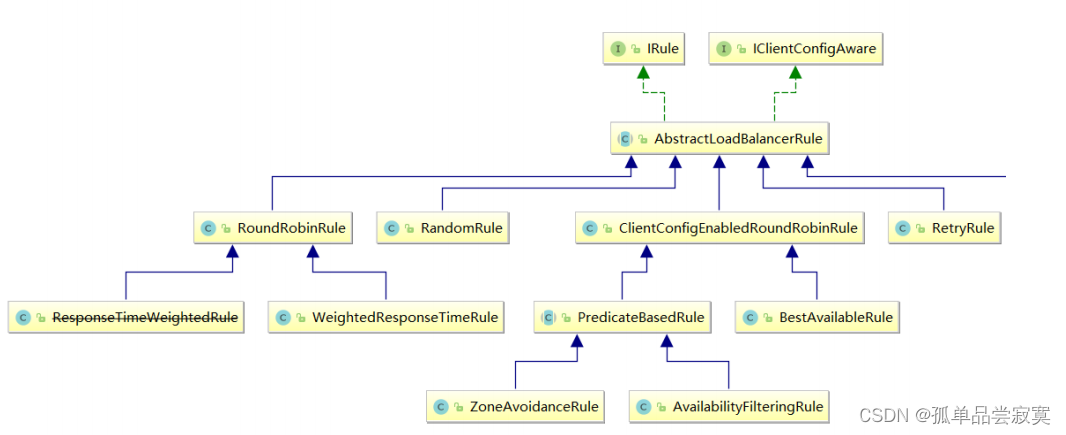
IRule
這是所有負載均衡策略的父接口, 里邊的核心方法就是 choose 方法,用來選擇一個服務實例 。
AbstractLoadBalancerRule
AbstractLoadBalancerRule 是一個抽象類,里邊主要定義了一個 ILoadBalancer ,這里定義它的目的主要是 輔助負責均衡策略選取合適的服務端實 例。
RandomRule
看名字就知道,這種負載均衡策略就是 隨機選擇一個服務實例 ,看源碼我們知道,在 RandomRule 的無參構造方法中初始化了一個 Random 對象, 然后在它重寫的choose 方法又調用了 choose(ILoadBalancer lb, Object key) 這個重載的 choose 方法,在這個重載的 choose 方法中,每次利用 random對象生成一個不大于服務實例總數的隨機數,并將該數作為下標所以獲取一個服務實例。
RoundRobinRule
RoundRobinRule 這種負載均衡策略叫做線性 輪詢負載均衡策略 。這個類的 choose(ILoadBalancer lb, Object key) 函數整體邏輯是這樣的:開啟 一個計數器count ,在 while 循環中遍歷服務清單,獲取清單之前先通過 incrementAndGetModulo 方法獲取一個下標,這個下標是一個不斷自增長 的數先加1 然后和服務清單總數取模之后獲取到的(所以這個下標從來不會越界),拿著下標再去服務清單列表中取服務,每次循環計數器都會加
1 ,如果連續 10 次都沒有取到服務,則會報一個警告 No available alive servers after 10 tries from load balancer: XXXX 。
RetryRule (在輪詢的基礎上進行重試)
看名字就知道這種負載均衡策略帶有 重試 功能。首先 RetryRule 中又定義了一個 subRule ,它的實現類是 RoundRobinRule ,然后在 RetryRule 的
choose(ILoadBalancer lb, Object key) 方法中,每次還是采用 RoundRobinRule 中的 choose 規則來選擇一個服務實例,如果選到的實例正常就返
回,如果選擇的服務實例為 null 或者已經失效,則在失效時間 deadline 之前不斷的進行重試(重試時獲取服務的策略還是 RoundRobinRule 中定義的
策略),如果超過了 deadline 還是沒取到則會返回一個 null 。
WeightedResponseTimeRule ( 權重 —nacos 的NacosRule ,Nacos還擴展了一個自己的基于配置的權重擴展 ) WeightedResponseTimeRule是 RoundRobinRule 的一個子類,在 WeightedResponseTimeRule 中對 RoundRobinRule 的功能進行了擴展,
WeightedResponseTimeRule 中會根據每一個實例的運行情況來給計算出該實例的一個 權重 ,然后在挑選實例的時候則根據權重進行挑選,這樣能 夠實現更優的實例調用。WeightedResponseTimeRule 中有一個名叫 DynamicServerWeightTask 的定時任務,默認情況下每隔 30 秒會計算一次 各個服務實例的權重,權重的計算規則也很簡單, 如果一個服務的平均響應時間越短則權重越大,那么該服務實例被選中執行任務的概率也就越大 。
ClientConfigEnabledRoundRobinRule
ClientConfigEnabledRoundRobinRule 選擇策略的實現很簡單,內部定義了 RoundRobinRule , choose 方法還是采用了 RoundRobinRule 的 choose方法,所以它的選擇策略 和 RoundRobinRule 的選擇策略一致 ,不贅述。
BestAvailableRule
BestAvailableRule 繼承自 ClientConfigEnabledRoundRobinRule ,它在 ClientConfigEnabledRoundRobinRule 的基礎上主要增加了根據 loadBalancerStats中保存的服務實例的狀態信息來 過濾掉失效的服務實例的功能,然后順便找出并發請求最小的服務實例來使用。 然而 loadBalancerStats有可能為 null ,如果 loadBalancerStats 為 null ,則 BestAvailableRule 將采用它的父類即 ClientConfigEnabledRoundRobinRule的服務選取策略(線性輪詢)。
ZoneAvoidanceRule
( 默認規則 ,復合判斷server所在區域的性能和server的可用性選擇服務器。 )
ZoneAvoidanceRule 是 PredicateBasedRule 的一個實現類,只不過這里多一個過濾條件, ZoneAvoidanceRule 中的過濾條件是以
ZoneAvoidancePredicate 為主過濾條件和以
AvailabilityPredicate 為次過濾條件組成的一個叫做 CompositePredicate 的組合過濾條件,過濾成功之后,繼續采用線性輪詢
( RoundRobinRule ) 的方式從過濾結果中選擇一個出來。 AvailabilityFilteringRule (先過濾掉故障實例,再選擇并發較小的實例) 過濾掉一直連接失敗的被標記為circuit tripped的后端Server,并過濾掉那些高并發的后端Server或者使用一個AvailabilityPredicate來 包含過濾server的邏輯,其實就是檢查status里記錄的各個Server的運行狀態。
3.2.1 修改默認負載均衡策略
@Configurationpublic class RibbonConfig {/*** 全局配置* 指定負載均衡策略* @return*/@Bean
public IRule iRule() {// 指定使用Nacos提供的負載均衡策略(優先調用同一集群的實例,基于隨機權重)
return new NacosRule();
}
} 注意:此處有坑。 不能寫在@SpringbootApplication注解的@CompentScan掃描得到的地方,否則自定義的配置類就會被所有的 RibbonClients共享。 不建議這么使用,推薦yml方式
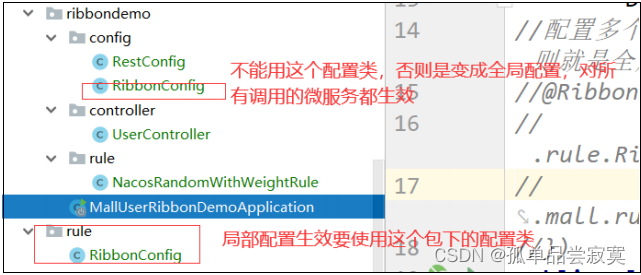

利用@RibbonClient指定微服務及其負載均衡策略。
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class,DruidDataSourceAutoConfigure.class})//@RibbonClient(name = "mall‐order",configuration = RibbonConfig.class)//配置多個 RibbonConfig不能被@SpringbootApplication的@CompentScan掃描到,否則就是全局配置的效果@RibbonClients(value = {// 在SpringBoot主程序掃描的包外定義配置類@RibbonClient(name = "mall‐order",configuration = RibbonConfig.class),@RibbonClient(name = "mall‐account",configuration = RibbonConfig.class)})
public class MallUserRibbonDemoApplication {public static void main(String[] args) {SpringApplication.run(MallUserRibbonDemoApplication.class, args);}} 配置文件 :調用指定微服務提供的服務時,使用對應的負載均衡算法
修改application.yml
# 被調用的微服務名mall‐order:ribbon:# 指定使用Nacos提供的負載均衡策略(優先調用同一集群的實例,基于隨機&權重)NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule 3.2.2 自定義負載均衡策略
通過實現 IRule 接口可以自定義負載策略,主要的選擇服務邏輯在 choose 方法中。
1) 實現基于Nacos權重的負載均衡策略
@Slf4jpublic class NacosRandomWithWeightRule extends AbstractLoadBalancerRule {@Autowiredprivate NacosDiscoveryProperties nacosDiscoveryProperties;@Overridepublic Server choose(Object key) {DynamicServerListLoadBalancer loadBalancer = (DynamicServerListLoadBalancer) getLoadBalancer();String serviceName = loadBalancer.getName();NamingService namingService = nacosDiscoveryProperties.namingServiceInstance();try {//nacos基于權重的算法Instance instance = namingService.selectOneHealthyInstance(serviceName);return new NacosServer(instance);} catch (NacosException e) {log.error("獲取服務實例異常:{}", e.getMessage());e.printStackTrace();}return null;}@Overridepublic void initWithNiwsConfig(IClientConfig clientConfig) {}} 2) 配置自定義的策略
2.1)配置文件:
修改application.yml
# 被調用的微服務名mall‐order:ribbon:# 自定義的負載均衡策略(基于隨機&權重)NFLoadBalancerRuleClassName: com.tuling.mall.ribbondemo.rule.NacosRandomWithWeightRule 3.3 饑餓加載
在進行服務調用的時候,如果網絡情況不好,第一次調用會超時。
Ribbon默認懶加載,意味著只有在發起調用的時候才會創建客戶端。
開啟饑餓加載,解決第一次調用慢的問
ribbon:eager‐load:# 開啟ribbon饑餓加載enabled: true# 配置mall‐user使用ribbon饑餓加載,多個使用逗號分隔clients: mall‐order 源碼對應屬性配置類:RibbonEagerLoadProperties
測試:


)



)












——簡單工廠模式)
