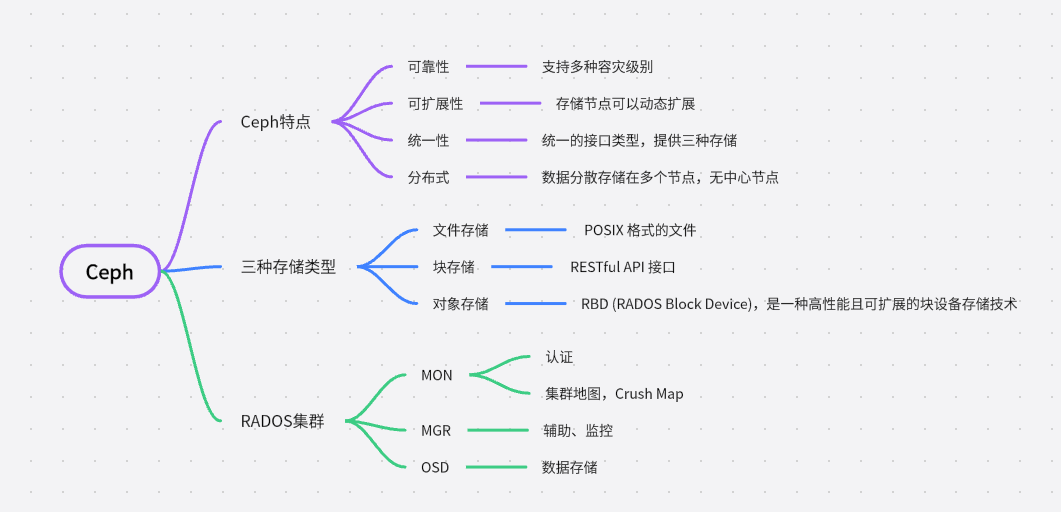
1、Ceph是什么?
“Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability.”這句話說出了Ceph的特性,它是可靠的、可擴展的、統一的、分布式的存儲系統。Ceph可以同時提供對象存儲RADOSGW(Reliable、Autonomic、Distributed、Object Storage Gateway)、塊存儲RBD(Rados Block Device)、文件系統存儲Ceph FS(Ceph Filesystem)3種功能。
-
可靠性,因為它使用數據冗余和容錯機制來保護數據的完整性和可靠性。它將數據分散存儲在多個存儲節點上,通過數據復制和數據恢復技術來避免數據丟失。即使一個存儲節點發生故障,數據仍然可以通過其他節點進行訪問和恢復。(ceph 是支持多種冗余級別的最小稱為盤級別冗余)
-
可擴展性,因為它使用了分布式存儲架構。它可以通過增加存儲節點,來擴展存儲容量和性能。每個節點都可以平行處理和存儲數據,因此可以線性地增加整個系統的存儲容量和吞吐量。這種可擴展性使得Ceph非常適合處理大規模數據存儲和處理需求。
-
統一性:因為它提供了多種存儲功能,包括對象存儲、塊存儲和文件系統存儲。這些不同類型的存儲可以在同一個Ceph集群中同時存在,并且可以根據不同的應用需求進行靈活部署和管理。這種統一性簡化了存儲架構和管理,并且提供了更好的靈活性和應用兼容性。
-
分布式:因為它將數據分散存儲在多個節點上,并且通過網絡連接實現節點之間的通信和數據傳輸。每個節點都可以獨立處理和存儲數據,沒有單點故障,并且可以進行橫向擴展。分布式架構提供了高可用性、高性能和靈活性,并且使得Ceph能夠適應各種應用場景和規模
2、三種存儲類型
-
文件存儲: 文件存儲是一種以文件為單位進行數據存儲的方式。在文件存儲中,數據以文件的形式存儲在文件系統中,可以通過文件名或路徑來進行訪問和管理。文件存儲適用于存儲相對較小的文件,并提供了對文件的完整控制和管理,例如讀取、寫入、修改和刪除文件。常見的文件存儲如NFS。其最常見的用途就是可以多用戶同時掛載后,同時進行讀寫操作。
為什么我們需要文件存儲,有塊存儲不就夠了嗎?
在回答這個問題之前,讓我們先討論一下數據庫。在數據庫等系統中,無論是主從還是多主架構,都面臨著數據不一致的問題。主從架構下,備庫的數據會延遲于主庫,而多主從架構下,如果數據是分布式存放的,則請求只能發送到相應的節點,如果是非分布式存放的,則會有多份數據,導致集群的整體利用率不高。
試想一下,如果我們能將數據只存放一份,其在本質上就解決了在不同節點上數據不一致的問題,我們可以采用類似NFS的架構,將一個目錄映射到多個數據庫節點上,而多個數據庫實例實際上請求的都是同一份數據原文件。此時利用的就是文件存儲能支持多用戶同時掛載和讀寫。
塊存儲是否就不支持多用戶同時讀寫了?
塊存儲也支持多用戶同時讀寫,但是需要通過適當的權限控制和管理來確保數據的一致性和安全性,也就是說需要自行解決數據一致性問題。
-
塊存儲塊存儲是一種以塊(通常是固定大小的數據塊)為單位進行數據存儲的方式。在塊存儲中,數據以塊的形式存儲在獨立的存儲設備上,每個塊都有唯一的標識符。塊存儲將數據劃分為相對較小且固定大小的塊,這些塊可以根據需要進行讀取、寫入和修改。塊存儲適用于需要隨機讀寫訪問的應用,如數據庫、虛擬機和操作系統。塊存儲可以理解為一個磁盤或分區,在linux 系統中此類設備被映射為一個 塊類型的文件。如下圖中的類型為b(block)
ll /dev/sda
brw-rw---- 1 root disk 8, 0 Nov 13 17:53 /dev/sda而對塊設備如果用mkfs.xfs 或 mkfs.ext4 等命令執行文件系統初始化后就是一個文件系統設備。
-
對象存儲?對象存儲以對象形式存儲數據,每個對象都有唯一的標識符。對象通常包含數據本身以及與其相關的元數據。云存儲服務如Amazon S3和OpenStack Swift就是典型的對象存儲系統。當你上傳照片到云相冊或者將文件存儲到云端時,這些數據都會以對象的形式存儲。每個對象都有一個唯一的標識符,比如URL或者API密鑰。
ceph自身是一個對象存儲,其能提供對象存儲我們能理解,為什么其還能提供塊存儲和文件存儲了?
通用的 RADOS 存儲結構和可靠的分布式存儲技術。通過統一接口可以更好地處理各種數據類型,以及整合其他存儲服務的優勢,從而提供塊存儲和對象存儲和文件存儲三種存儲功能。
3 、 Ceph的邏輯分層
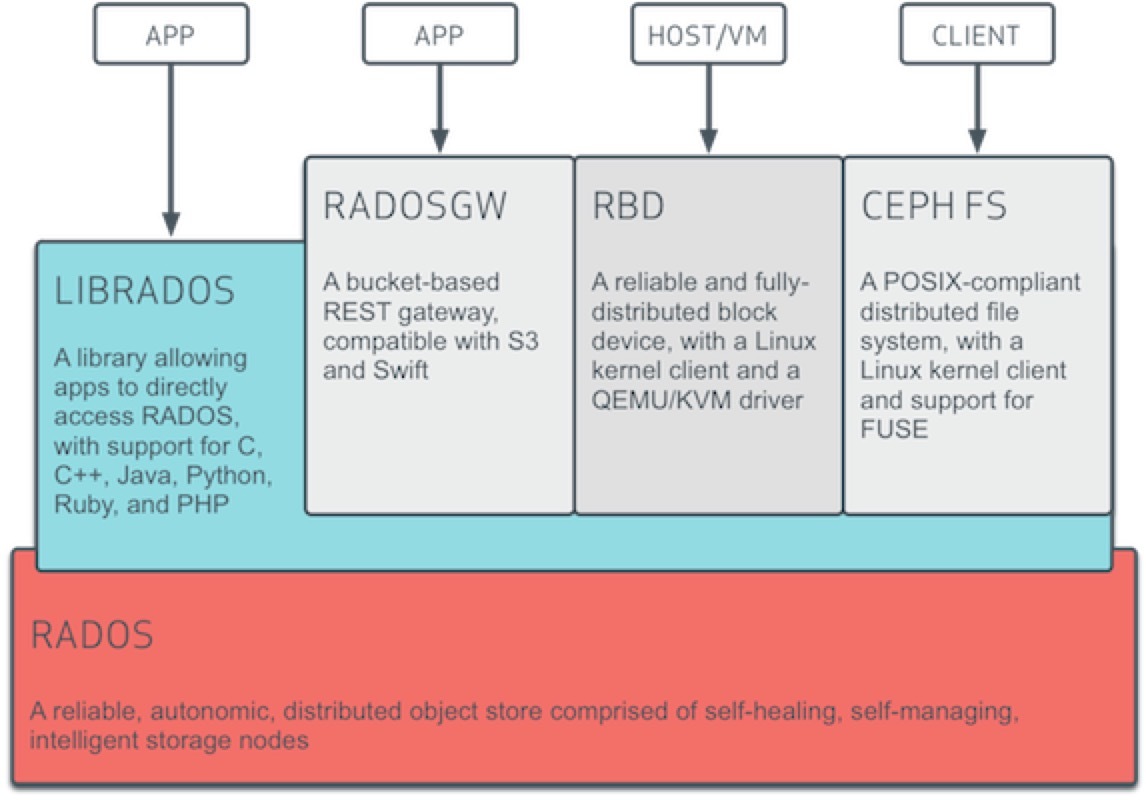
Ceph 官方給的邏輯架構如下圖
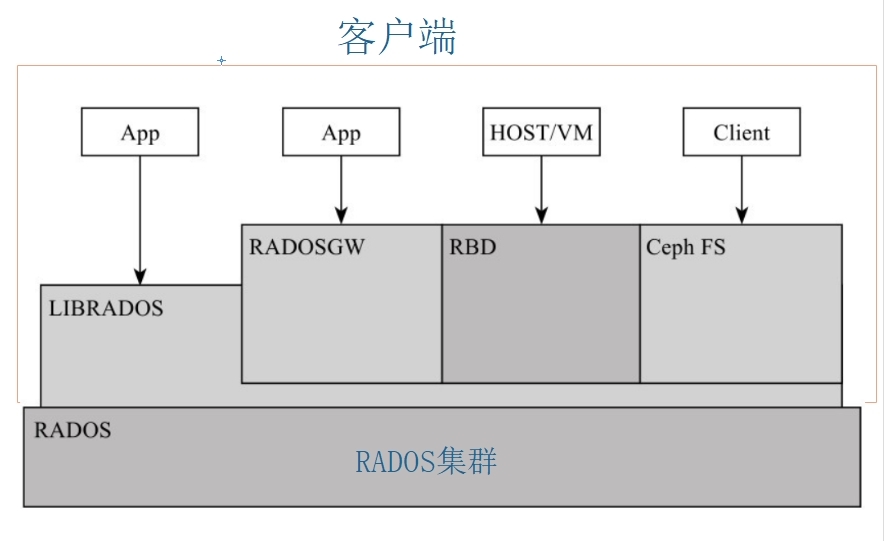
可以總結為兩部分,一個集群、一個客戶端。 集群就是底層的RADOS集群。客戶端就是在RADOS集群之上,利用librados 編程接口的進一步抽象。其本質都是RADOS集群的客戶端。
3.1、客戶端
如果說RADOS集群是一個具備自我修復等特性,提供了一個可靠、自動、智能的分布式存儲,那用戶怎么使用他了?因此RADOS提供了供librados庫,允許應用程序直接訪問,支持C/C++、Java和Python等語言。那是否有一個librados庫就可以被用戶直接訪問到了,理論上只需要調用其庫就可以使用DADOS集群。但是又有多少人有能力直接用編程能力去訪問RADOS集群了。
因此在librados庫基礎上做了進一步的封裝,針對主流的塊存儲使用提供了?RBD,針對文件存儲使用提供Ceph FS?,基于當前流行的RESTful協議的網關,并且兼容S3和Swift,提供了radosgw?。因為無論是librados、rdb radosgw Ceph fs 都是RADOS的客戶端。
3.2 、RADOS集群
一個最小化的RADOS集群只有三個組件?MON?和MGR?和?OSD?,其系統架構如下
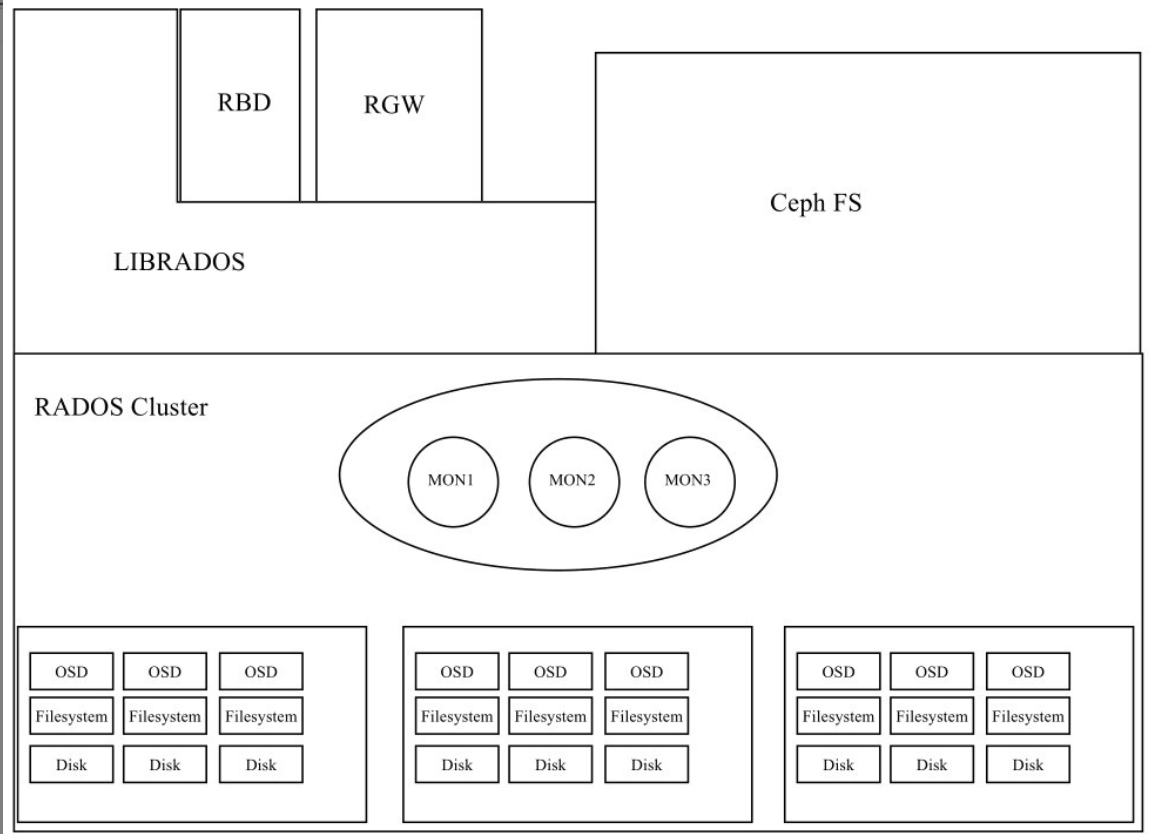
看到這可能有小伙伴會說 不對把,不是應該還有mds嗎?先說mds,其主要功能就給文件存儲提供元數據索引的,如果我們Ceph集群不需要文件存儲,就不需要mds組件了。
3.3 RADOS集群組件

-
mon: Ceph Monitor是負責監視整個群集的運行狀況的,這些信息都是由維護集群成員的守護程序來提供的,如各個節點之間的狀態、集群配置信息。Ceph monitor map包括OSD Map、PG Map、MDS Map和CRUSH等,這些Map被統稱為集群Map。這五張map可以說代表了mon的大部分功能。
-
MGR:Ceph ManagerMGR 承載了許多輔助功能,如監控、報告和資源分配。現在,Ceph Manager Daemon 更多地實現了監視、管理及一些自動化任務,包括維護集群元數據、系統故障檢測等。它可以實現跨多個 Ceph 組件的自動容災和調度,提高整個系統的穩定性和可靠性。
-
OSD: OSD是Ceph的對象存儲守護進程。它負責存儲數據,處理數據復制、恢復、重新平衡,并通過檢查其他守護進程是否有故障來向Ceph Monitor提供一些監控信息。每個存儲服務器(存儲節點)運行一個或多個OSD守護進程,通常每個磁盤存儲設備對應一個OSD守護進程
總結: 一個集群需要被訪問,總需是先需要一個認證功能,認證之后將用戶的請求調度到后端真正的服務,這個過程就是mon的功能,因為其是分布式的存儲,其靠Paxos算法來保證數據一致性。為了集群的穩定,mon維護了集群的map。 mgr則更多是提供監控和輔助功能來減輕mon的負擔,osd則是數據真正的存放位置。
在上文中我們說過Ceph集群是無中心節點的分布式存儲,那其是怎么做到了?
一切的一切都是靠計算,簡單的說就是真正的數據存儲在那個osd上,其是靠計算出來,而非查詢元數據節點查詢出來的。這個計算的過程就是CRUSH算法。關于CRUSH算法我們將在后面章節來討論,這里我們了解Ceph集群的結構,下一章我們將手動部署一套最小化的Ceph集群來體驗下Ceph存儲的使用。
文章轉載自:ALEX_li88
原文鏈接:https://www.cnblogs.com/alex0815/p/17850402.html






![【Sorted Set】Redis常用數據類型: ZSet [使用手冊]](http://pic.xiahunao.cn/【Sorted Set】Redis常用數據類型: ZSet [使用手冊])



)

-uniclould增刪改查業務開發)






