1 OCR介紹
OCR(Optical Character Recognition)即光學字符識別,是一種將不同類型的文檔(如掃描的紙質文件、PDF文件或圖像文件中的文本)轉換成可編輯和可搜索的數據的技術。OCR技術能夠識別和轉換印刷或手寫文字,廣泛應用于數據錄入、文檔數字化和自動化處理領域。
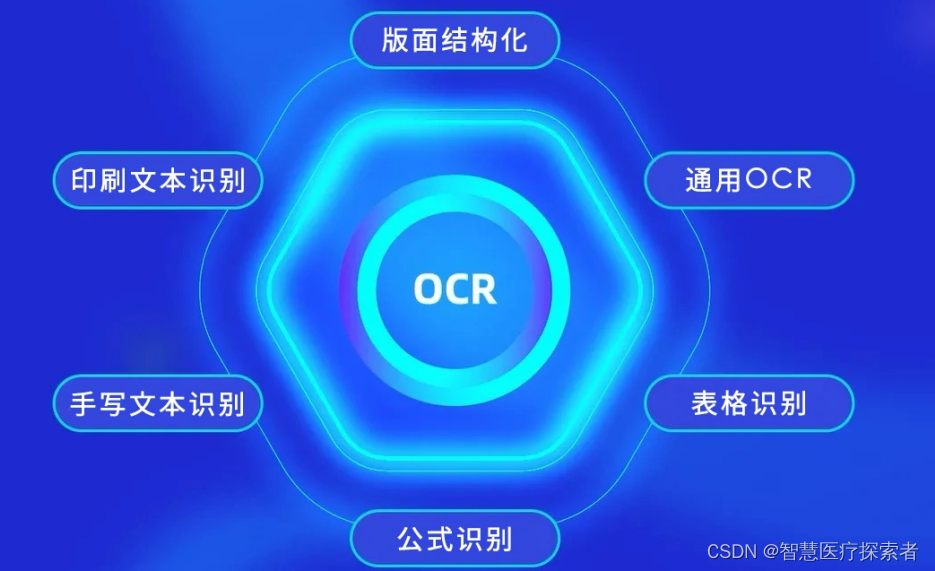
OCR技術已經成為數字化時代不可或缺的一部分,它極大地方便了文本的轉換和處理,為各個行業的數字化轉型做出了貢獻。隨著技術的不斷進步,OCR的應用范圍將進一步拓寬,為更多領域帶來便利和效率的提升。
1.1 基本原理
OCR技術通常涉及以下幾個步驟:
-
圖像獲取:首先獲取文檔的圖像,這可以通過掃描紙質文檔或拍攝圖片來實現。
-
預處理:對圖像進行預處理,以提高識別的準確性。這包括去噪、調整對比度、校正扭曲、二值化等。
-
文本檢測與分割:在預處理后的圖像中檢測文本區域,并將其分割為行、單詞或字符。
-
字符識別:利用模式識別技術,識別分割出的字符或單詞。
-
后處理:將識別結果進行校正和格式化,例如修正拼寫錯誤、保持文本的結構和格式等。
1.2 技術發展
-
早期技術:早期的OCR系統依賴于簡單的模板匹配技術,只能處理特定字體和格式。
-
進階技術:隨著機器學習和人工智能的發展,OCR技術引入了更復雜的算法,如神經網絡,大大提高了識別的準確率和靈活性。
-
深度學習:最近,深度學習在OCR領域的應用取得了顯著的進步,特別是在處理復雜場景和手寫文本方面。
1.3 應用領域
-
文檔自動化處理:在辦公自動化和文檔管理系統中,OCR被用于快速輸入和處理紙質文檔。
-
銀行和金融:銀行使用OCR技術處理支票和其他金融文件。
-
法律和醫療領域:OCR有助于快速轉換和管理大量的法律和醫療記錄。
-
教育和研究:在教育和學術研究中,OCR可用于數字化歷史文檔和圖書。
-
無障礙服務:OCR技術有助于為視覺障礙人士提供無障礙閱讀服務。
1.4 挑戰與限制
-
識別準確率:雖然現代OCR技術已經很先進,但仍然可能在復雜的布局或低質量圖像中遇到識別準確性的問題。
-
語言和字體多樣性:對于一些較少使用的語言或特殊的字體,OCR軟件可能難以準確識別。
-
手寫文本識別:手寫文本的變化性和復雜性使得其識別難度較高。
1.5 未來發展方向
-
技術改進:不斷改進OCR技術,提高對復雜文本和圖像的處理能力。
-
深度學習的應用:利用深度學習模型進一步提升識別準確率和速度。
-
多語種支持:增強對多種語言和方言的支持能力。
-
集成與應用拓展:將OCR技術與其他技術結合,如自然語言處理(NLP),擴展到更多應用場景。
2 paddleocr介紹
PaddleOCR是由百度開發的一款開源光學字符識別(OCR)工具,基于PaddlePaddle深度學習框架。它專注于提供輕量級、靈活且高效的OCR解決方案,旨在幫助開發者和研究人員在各種應用場景中快速部署OCR功能。PaddleOCR涵蓋了OCR的全流程,包括文本檢測、文本識別和文本校正等環節。
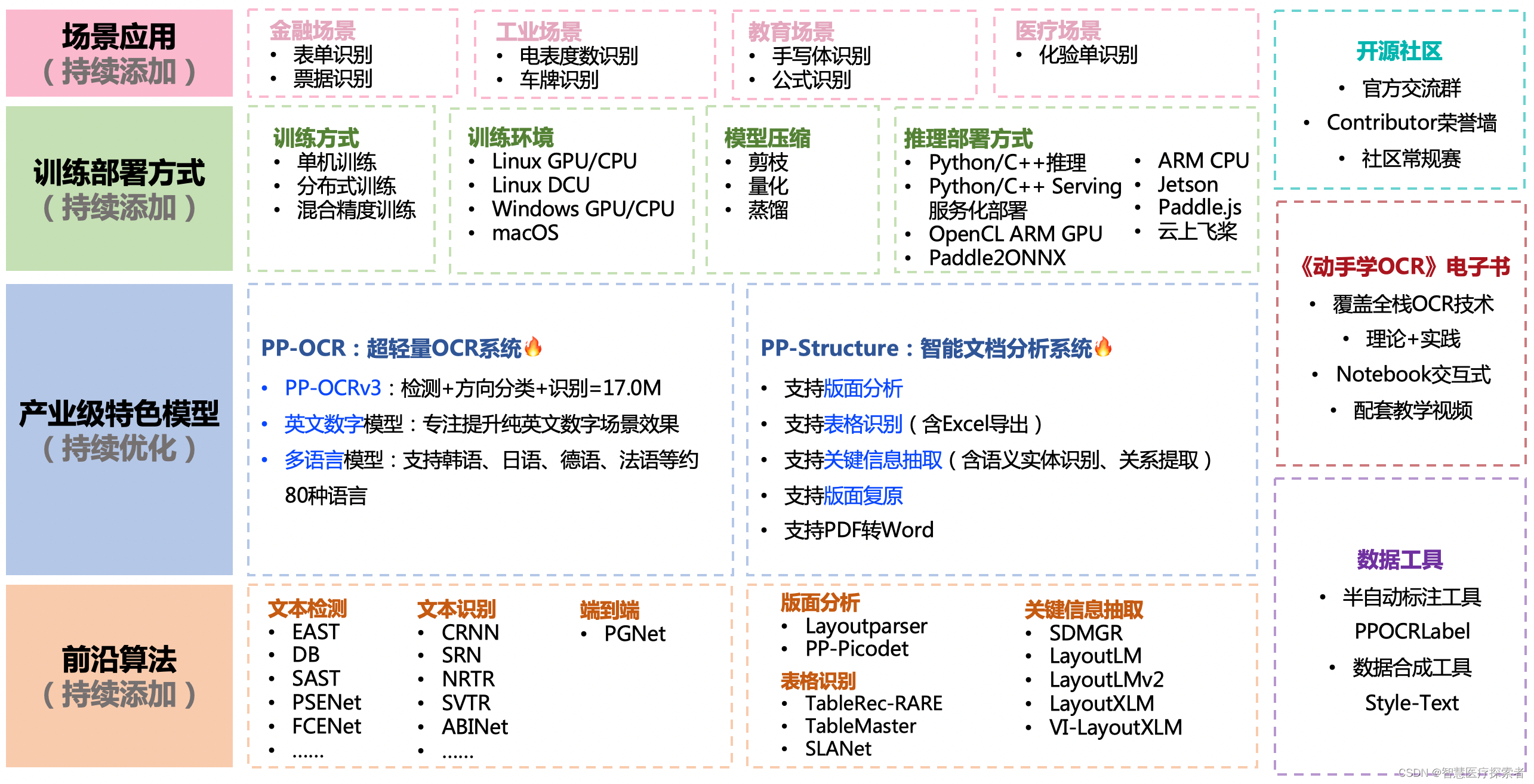
PaddleOCR是一個功能強大且靈活的OCR工具,它基于深度學習技術,提供了高效和準確的文字識別能力。它的輕量級設計、多語種支持和易用性使其適用于多種應用場景。作為一個開源項目,PaddleOCR持續發展和完善,是構建OCR應用的優秀選擇。隨著技術的不斷進步和應用需求的日益增長,PaddleOCR將在自動化處理和智能識別領域發揮更大的作用。
項目地址:https://github.com/PaddlePaddle/PaddleOCR
體驗地址:https://aistudio.baidu.com/application/detail/7658
2.1 核心特性
-
多語種支持: PaddleOCR支持多種語言的識別,包括英文、中文、日文、韓文等,滿足全球化應用的需求。
-
高識別準確率: 基于先進的深度學習模型和算法,PaddleOCR在多個公開數據集上展現出優秀的識別性能。
-
輕量化模型: 提供了輕量級模型,適用于移動設備和邊緣計算場景,能夠在資源受限的環境中快速運行。
-
靈活易用: PaddleOCR提供了簡潔的API和豐富的文檔,使得開發者可以輕松集成OCR功能到自己的應用中。
-
開源社區: 作為一個開源項目,PaddleOCR擁有活躍的社區支持,持續更新和改進。
2.2 技術組成
-
文本檢測: PaddleOCR使用深度學習模型來檢測圖像中的文本區域。它支持檢測多種形狀和布局的文本,如水平文本、傾斜文本和彎曲文本。
-
文本識別: 在檢測出文本區域后,PaddleOCR使用文本識別模型來識別這些區域中的文字內容。
-
文本校正: 對于檢測或識別過程中的錯誤,PaddleOCR提供了文本校正功能,以提高最終識別結果的準確性。
2.3 應用場景
-
文件數字化: PaddleOCR可用于將紙質文件或PDF文檔轉換為可編輯的數字格式。
-
身份驗證: 在身份驗證和KYC(了解你的客戶)流程中,PaddleOCR可以用來識別身份證件上的信息。
-
自動化辦公: 在自動化辦公系統中,PaddleOCR可以用于自動處理和分析文檔中的文字。
-
智能交通: 在智能交通系統中,PaddleOCR可以用于車牌識別和交通標志識別。
-
零售和商業分析: PaddleOCR可以應用于零售場景,用于識別收據、發票和產品標簽上的信息。
2.4 性能優化和部署
-
模型優化: PaddleOCR針對不同的應用場景提供了多種優化后的模型,以滿足性能和資源消耗之間的平衡。
-
跨平臺部署: PaddleOCR支持在多種平臺上部署,包括服務器、云平臺、移動設備和IoT設備。
-
容器化和云服務: PaddleOCR支持容器化部署,也可以作為云服務提供OCR能力。
2.5 社區和支持
-
開源協作: 作為一個開源項目,PaddleOCR鼓勵社區成員參與貢獻,包括代碼貢獻、問題反饋和功能建議。
-
文檔和示例: PaddleOCR提供了詳細的文檔、快速入門指南和豐富的應用示例,幫助開發者快速上手。
3 使用paddleocr進行文字識別
3.1 conda環境準備
conda環境準備詳見:annoconda
3.2 運行環境構建
conda create --name paddleocr python=3.8
conda activate paddleocrpip install paddlepaddle==2.5.2 -i https://mirror.baidu.com/pypi/simplegit clone https://github.com/PaddlePaddle/PaddleOCR
cd PaddleOCR
pip install -r reqirements.txtpip install paddleocr==2.7.0.3 -i https://mirror.baidu.com/pypi/simple3.3 模型下載
PP-OCR系列模型列表
| 模型簡介 | 模型名稱 | 推薦場景 | 檢測模型 | 方向分類器 | 識別模型 |
|---|---|---|---|---|---|
| 中英文超輕量PP-OCRv4模型(15.8M) | ch_PP-OCRv4_xx | 移動端&服務器端 | 推理模型 / 訓練模型 | 推理模型 / 訓練模型 | 推理模型 / 訓練模型 |
| 中英文超輕量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移動端&服務器端 | 推理模型 / 訓練模型 | 推理模型 / 訓練模型 | 推理模型 / 訓練模型 |
| 英文超輕量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移動端&服務器端 | 推理模型 / 訓練模型 | 推理模型 / 訓練模型 | 推理模型 / 訓練模型 |
- 超輕量OCR系列更多模型下載(包括多語言),可以參考PP-OCR系列模型下載,文檔分析相關模型參考PP-Structure系列模型下載
PaddleOCR場景應用模型
| 行業 | 類別 | 亮點 | 文檔說明 | 模型下載 |
|---|---|---|---|---|
| 制造 | 數碼管識別 | 數碼管數據合成、漏識別調優 | 光功率計數碼管字符識別 | 下載鏈接 |
| 金融 | 通用表單識別 | 多模態通用表單結構化提取 | 多模態表單識別 | 下載鏈接 |
| 交通 | 車牌識別 | 多角度圖像處理、輕量模型、端側部署 | 輕量級車牌識別 | 下載鏈接 |
- 更多制造、金融、交通行業的主要OCR垂類應用模型(如電表、液晶屏、高精度SVTR模型等),可參考場景應用模型下載
3.4 識別效果展示


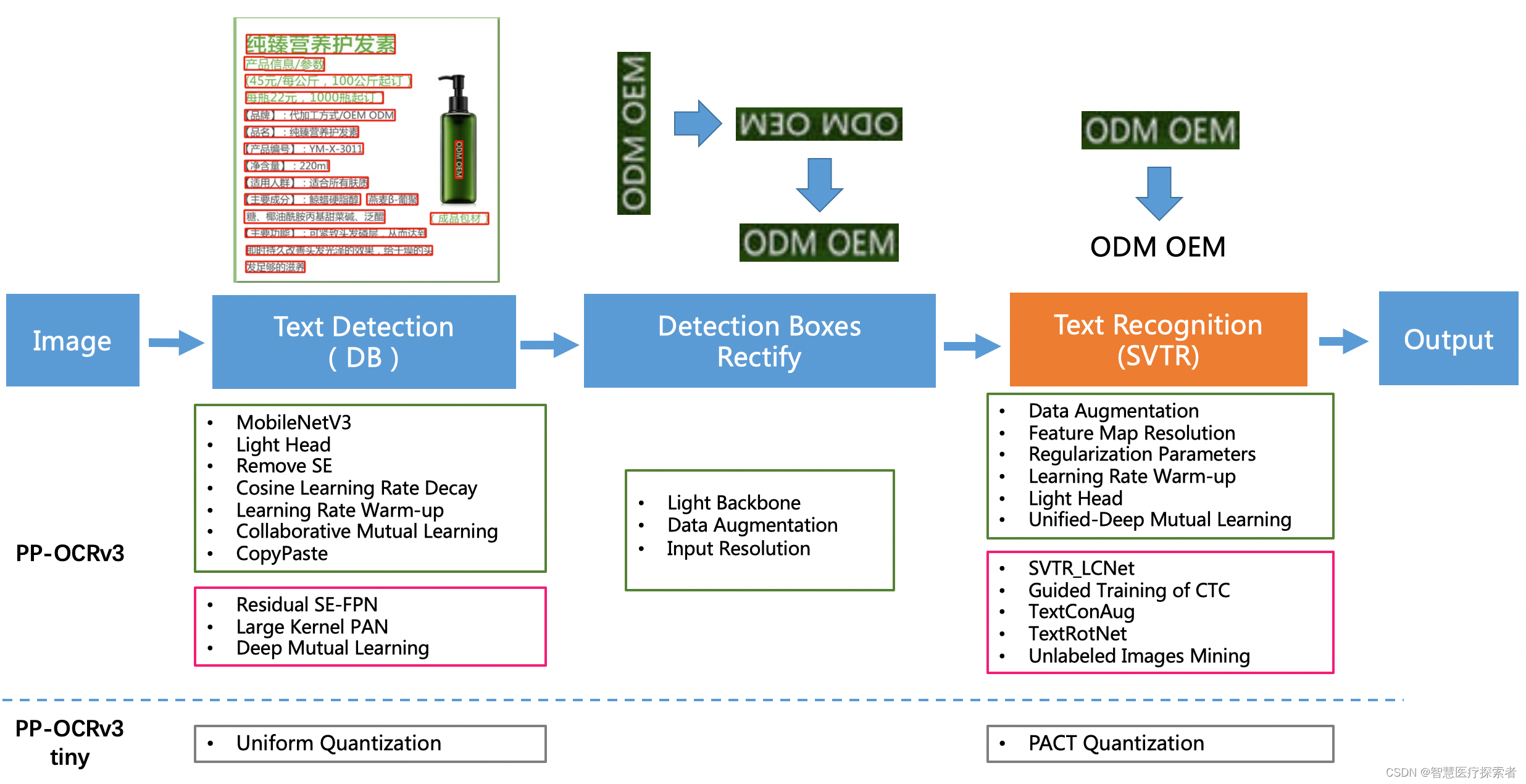 3.5 代碼調用進行識別
3.5 代碼調用進行識別
from paddleocr import PaddleOCRocr = PaddleOCR(use_angle_cls=True, use_gpu=False, ocr_version='PP-OCRv3')
text = ocr.ocr(cropped, cls=True)
for t in text:print(t[0][1])

)











版本升級體驗支持H264及其他多個H264版本)

)
)

