項目簡介
一個通過Whisper模型將YouTube播放列表中的視頻轉換成高質量文字稿的項目。
這個基于 Python 的工具旨在將 YouTube 視頻和播放列表轉錄為文本。它集成了多種技術,例如用于轉錄的 Fast-Whisper、用于自然語言處理的 SpaCy 以及用于 GPU 加速的 CUDA,旨在高效處理視頻內容。該腳本能夠處理單個視頻和整個播放列表,輸出準確的文字記錄和元數據。項目核心內容:
1、YouTube下載:使用pytube下載YouTube視頻或播放列表的音頻。
2、音頻轉錄:利用faster_whisper.WhisperModel將音頻轉換成文字。
3、NLP處理:可選地整合SpaCy,用于改進句子分割,提高文字稿的可讀性和結構。
4、CUDA加速:實現CUDA支持,用于兼容硬件的處理速度提升。
這個工具適用于內容分析、輔助創建視頻字幕和封閉字幕、教育目的以及視頻內容的存檔和檢索。
功能概述
核心組件
-
YouTube 下載:使用 pytube 從 YouTube 視頻或播放列表下載音頻。
-
音頻轉錄:利用 faster_whisper.WhisperModel 將音頻轉換為文本。該模型是 OpenAI 的 Whisper 的變體,旨在提高速度和準確性。
-
NLP 處理:可以選擇集成 SpaCy 以進行復雜的句子分割,從而增強轉錄本的可讀性和結構。
-
CUDA 加速:實現對 GPU 利用率的 CUDA 支持,提高兼容硬件的處理速度。
詳細工作流程
-
初始化:
-
該腳本首先根據 convert_single_video 標志確定是處理單個視頻還是播放列表。
-
它設置必要的目錄來存儲下載的音頻、文字記錄和元數據。
-
-
環境配置:
-
將 CUDA Toolkit 路徑添加到系統環境以供 GPU 使用。
-
根據 CPU 核心數配置用于轉錄的工作線程數量。
-
-
視頻處理:
-
對于播放列表中的每個視頻或單個視頻,腳本都會下載音頻。
-
它確保每個音頻文件的唯一命名以避免覆蓋。
-
-
轉錄:
-
音頻文件被傳遞到 WhisperModel 進行轉錄。
-
如果可用,該腳本會處理 GPU 加速,否則默認為 CPU。
-
使用 SpaCy 或基于自定義正則表達式的拆分器將轉錄結果拆分為句子。
-
-
元數據生成:
-
除了腳本之外,腳本還會生成元數據,包括每個片段的時間戳和置信度分數。
-
-
輸出:
-
記錄以純文本、CSV 和 JSON 格式保存,提供原始記錄和結構化元數據。
-
-
顯示/讀取:
-
為了使文字記錄更易于閱讀,提供了一個 html 文件 transcript_reader.html ,它可以進一步清理并提供“閱讀器模式”,您可以在其中選擇字體、文本大小、文本寬度和切換深色模式。只需在瀏覽器中打開此 html 文件,然后粘貼 generated_transcript_combined_texts 文件夾中生成的文件之一的轉錄文本即可。
-
|
|
|---|
| 實際操作的屏幕截圖 |
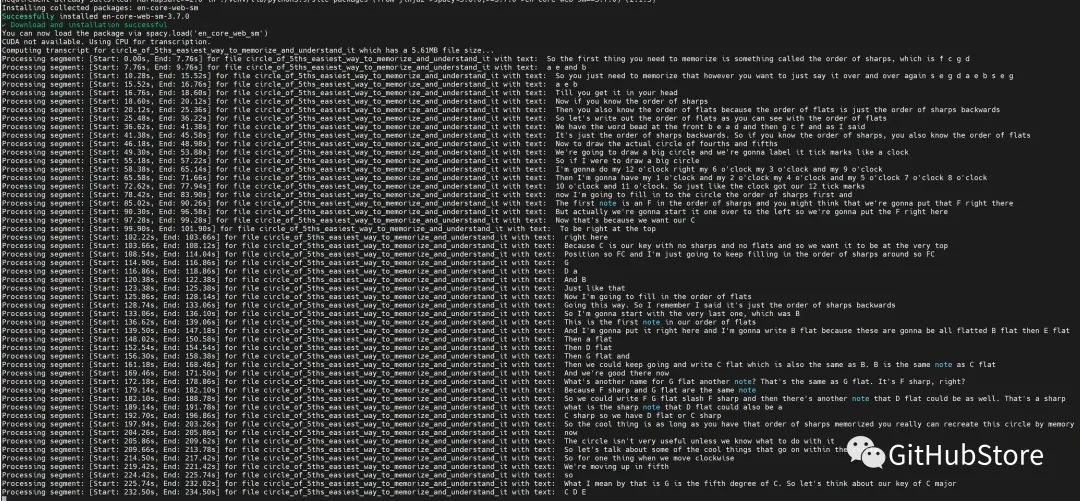
|
|
|
|---|---|
| 將成績單文本粘貼到成績單閱讀器 HTML 文件中 | 使用深色模式和 Cambria 字體的閱讀器 |
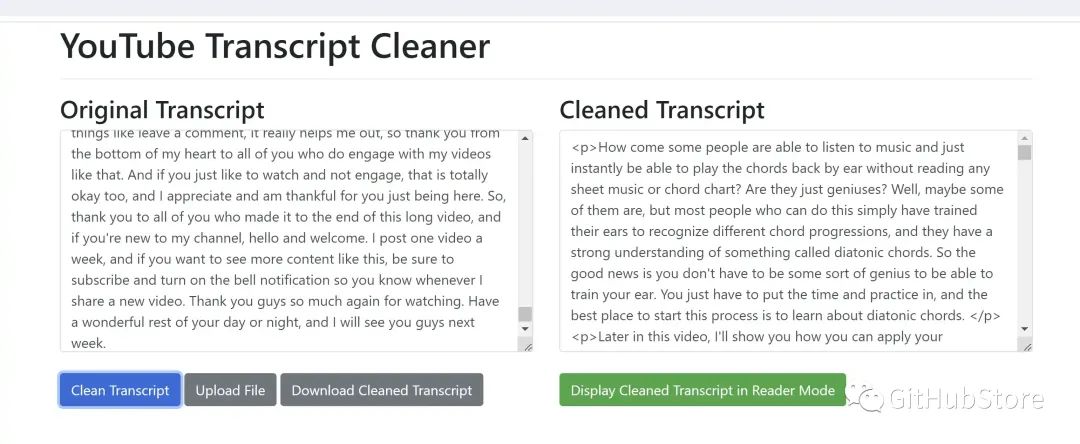

項目鏈接
https://github.com/Dicklesworthstone/bulk_transcribe_youtube_videos_from_playlist
)







)







,反向最大匹配算法(BMM)和雙向最大匹配算法(BM)原理及實現)


