
本文主要學習一下關于爬蟲的相關前置知識和一些理論性的知識,通過本文我們能夠知道什么是爬蟲,都有那些分類,爬蟲能干什么等,同時還會站在爬蟲的角度復習一下http協議。
Python爬蟲和Scrapy全套筆記直接地址: 請移步這里
共 8 章,37 子模塊
反爬與反反爬
本階段本文主要學習爬蟲的反爬及應對方法。
常見的反爬手段和解決思路
學習目標
- 了解 服務器反爬的原因
- 了解 服務器常反什么樣的爬蟲
- 了解 反爬蟲領域常見的一些概念
- 了解 反爬的三個方向
- 了解 常見基于身份識別進行反爬
- 了解 常見基于爬蟲行為進行反爬
- 了解 常見基于數據加密進行反爬
1 服務器反爬的原因
- 爬蟲占總PV(PV是指頁面的訪問次數,每打開或刷新一次頁面,就算做一個pv)比例較高,這樣浪費錢(尤其是三月份爬蟲)。
三月份爬蟲是個什么概念呢?每年的三月份我們會迎接一次爬蟲高峰期,有大量的碩士在寫論文的時候會選擇爬取一些往網站,并進行輿情分析。因為五月份交論文,所以嘛,大家都是讀過書的,你們懂的,前期各種DotA,LOL,到了三月份了,來不及了,趕緊抓數據,四月份分析一下,五月份交論文,就是這么個節奏。
- 公司可免費查詢的資源被批量抓走,喪失競爭力,這樣少賺錢。
數據可以在非登錄狀態下直接被查詢。如果強制登陸,那么可以通過封殺賬號的方式讓對方付出代價,這也是很多網站的做法。但是不強制對方登錄。那么如果沒有反爬蟲,對方就可以批量復制的信息,公司競爭力就會大大減少。競爭對手可以抓到數據,時間長了用戶就會知道,只需要去競爭對手那里就可以了,沒必要來我們網站,這對我們是不利的。
- 狀告爬蟲成功的幾率小
爬蟲在國內還是個擦邊球,就是有可能可以起訴成功,也可能完全無效。所以還是需要用技術手段來做最后的保障。
2 服務器常反什么樣的爬蟲
- 十分低級的應屆畢業生
應屆畢業生的爬蟲通常簡單粗暴,根本不管服務器壓力,加上人數不可預測,很容易把站點弄掛。
- 十分低級的創業小公司
現在的創業公司越來越多,也不知道是被誰忽悠的然后大家創業了發現不知道干什么好,覺得大數據比較熱,就開始做大數據。分析程序全寫差不多了,發現自己手頭沒有數據。怎么辦?寫爬蟲爬啊。于是就有了不計其數的小爬蟲,出于公司生死存亡的考慮,不斷爬取數據。
- 不小心寫錯了沒人去停止的失控小爬蟲
有些網站已經做了相應的反爬,但是爬蟲依然孜孜不倦地爬取。什么意思呢?就是說,他們根本爬不到任何數據,除了httpcode是200以外,一切都是不對的,可是爬蟲依然不停止這個很可能就是一些托管在某些服務器上的小爬蟲,已經無人認領了,依然在辛勤地工作著。
- 成型的商業對手
這個是最大的對手,他們有技術,有錢,要什么有什么,如果和你死磕,你就只能硬著頭皮和他死磕。
- 抽風的搜索引擎
大家不要以為搜索引擎都是好人,他們也有抽風的時候,而且一抽風就會導致服務器性能下降,請求量跟網絡攻擊沒什么區別。
3 反爬蟲領域常見的一些概念
因為反爬蟲暫時是個較新的領域,因此有些定義要自己下:
-
爬蟲:使用任何技術手段,批量網站信息的一種方式。關鍵在于批量。
-
反爬蟲:使用任何技術手段,阻止別人批量自己網站信息的一種方式。關鍵也在于批量。
-
誤傷:在反爬蟲的過程中,錯誤的將普通用戶識別為爬蟲。誤傷率高的反爬蟲策略,效果再好也不能用。
-
攔截:成功地阻止爬蟲訪問。這里會有攔截率的概念。通常來說,攔截率越高的反爬蟲策略,誤傷的可能性就越高。因此需要做個權衡。
-
資源:機器成本與人力成本的總和。
這里要切記,人力成本也是資源,而且比機器更重要。因為,根據摩爾定律,機器越來越便宜。而根據IT行業的發展趨勢,程序員工資越來越貴。因此,通常服務器反爬就是讓爬蟲工程師加班才是王道,機器成本并不是特別值錢。
4 反爬的三個方向
-
基于身份識別進行反爬
-
基于爬蟲行為進行反爬
-
基于數據加密進行反爬
5 常見基于身份識別進行反爬
1 通過headers字段來反爬
headers中有很多字段,這些字段都有可能會被對方服務器拿過來進行判斷是否為爬蟲
1.1 通過headers中的User-Agent字段來反爬
- 反爬原理:爬蟲默認情況下沒有User-Agent,而是使用模塊默認設置
- 解決方法:請求之前添加User-Agent即可;更好的方式是使用User-Agent池來解決(收集一堆User-Agent的方式,或者是隨機生成User-Agent)
1.2 通過referer字段或者是其他字段來反爬
- 反爬原理:爬蟲默認情況下不會帶上referer字段,服務器端通過判斷請求發起的源頭,以此判斷請求是否合法
- 解決方法:添加referer字段
1.3 通過cookie來反爬
- 反爬原因:通過檢查cookies來查看發起請求的用戶是否具備相應權限,以此來進行反爬
- 解決方案:進行模擬登陸,成功cookies之后在進行數據爬取
2 通過請求參數來反爬
請求參數的方法有很多,向服務器發送請求,很多時候需要攜帶請求參數,通常服務器端可以通過檢查請求參數是否正確來判斷是否為爬蟲
2.1 通過從html靜態文件中請求數據(github登錄數據)
- 反爬原因:通過增加請求參數的難度進行反爬
- 解決方案:仔細分析抓包得到的每一個包,搞清楚請求之間的聯系
2.2 通過發送請求請求數據
- 反爬原因:通過增加請求參數的難度進行反爬
- 解決方案:仔細分析抓包得到的每一個包,搞清楚請求之間的聯系,搞清楚請求參數的來源
2.3 通過js生成請求參數
- 反爬原理:js生成了請求參數
- 解決方法:分析js,觀察加密的實現過程,通過js2pyjs的執行結果,或者使用selenium來實現
2.4 通過驗證碼來反爬
- 反爬原理:對方服務器通過彈出驗證碼強制驗證用戶瀏覽行為
- 解決方法:打碼平臺或者是機器學習的方法識別驗證碼,其中打碼平臺廉價易用,更值得推薦
6 常見基于爬蟲行為進行反爬
1 基于請求頻率或總請求數量
爬蟲的行為與普通用戶有著明顯的區別,爬蟲的請求頻率與請求次數要遠高于普通用戶
1.1 通過請求ip/賬號單位時間內總請求數量進行反爬
- 反爬原理:正常瀏覽器請求網站,速度不會太快,同一個ip/賬號大量請求了對方服務器,有更大的可能性會被識別為爬蟲
- 解決方法:對應的通過購買高質量的ip的方式能夠解決問題/購買個多賬號
1.2 通過同一ip/賬號請求之間的間隔進行反爬
- 反爬原理:正常人操作瀏覽器瀏覽網站,請求之間的時間間隔是隨機的,而爬蟲前后兩個請求之間時間間隔通常比較固定同時時間間隔較短,因此可以用來做反爬
- 解決方法:請求之間進行隨機等待,模擬真實用戶操作,在添加時間間隔后,為了能夠高速數據,盡量使用代理池,如果是賬號,則將賬號請求之間設置隨機休眠
1.3 通過對請求ip/賬號每天請求次數設置閾值進行反爬
- 反爬原理:正常的瀏覽行為,其一天的請求次數是有限的,通常超過某一個值,服務器就會拒絕響應
- 解決方法:對應的通過購買高質量的ip的方法/多賬號,同時設置請求間隨機休眠
2 根據爬取行為進行反爬,通常在爬取步驟上做分析
2.1 通過js實現跳轉來反爬
- 反爬原理:js實現頁面跳轉,無法在源碼中下一頁url
- 解決方法: 多次抓包條狀url,分析規律
2.2 通過蜜罐(陷阱)爬蟲ip(或者代理ip),進行反爬
- 反爬原理:在爬蟲鏈接進行請求的過程中,爬蟲會根據正則,xpath,css等方式進行后續鏈接的提取,此時服務器端可以設置一個陷阱url,會被提取規則,但是正常用戶無法,這樣就能有效的區分爬蟲和正常用戶
- 解決方法: 完成爬蟲的編寫之后,使用代理批量爬取測試/仔細分析響應內容結構,找出頁面中存在的陷阱
2.3 通過假數據反爬
- 反爬原理:向返回的響應中添加假數據污染數據庫,通常家屬劇不會被正常用戶看到
- 解決方法: 長期運行,核對數據庫中數據同實際頁面中數據對應情況,如果存在問題/仔細分析響應內容
2.4 阻塞任務隊列
- 反爬原理:通過生成大量垃圾url,從而阻塞任務隊列,降低爬蟲的實際工作效率
- 解決方法: 觀察運行過程中請求響應狀態/仔細分析源碼垃圾url生成規則,對URL進行過濾
2.5 阻塞網絡IO
- 反爬原理:發送請求響應的過程實際上就是下載的過程,在任務隊列中混入一個大文件的url,當爬蟲在進行該請求時將會占用網絡io,如果是有多線程則會占用線程
- 解決方法: 觀察爬蟲運行狀態/多線程對請求線程計時/發送請求錢
2.6 運維平臺綜合審計
- 反爬原理:通過運維平臺進行綜合管理,通常采用復合型反爬蟲策略,多種手段同時使用
- 解決方法: 仔細觀察分析,長期運行測試目標網站,檢查數據采集速度,多方面處理
7 常見基于數據加密進行反爬
1 對響應中含有的數據進行特殊化處理
通常的特殊化處理主要指的就是css數據偏移/自定義字體/數據加密/數據圖片/特殊編碼格式等
1.1 通過自定義字體來反爬 下圖來自貓眼電影電腦版
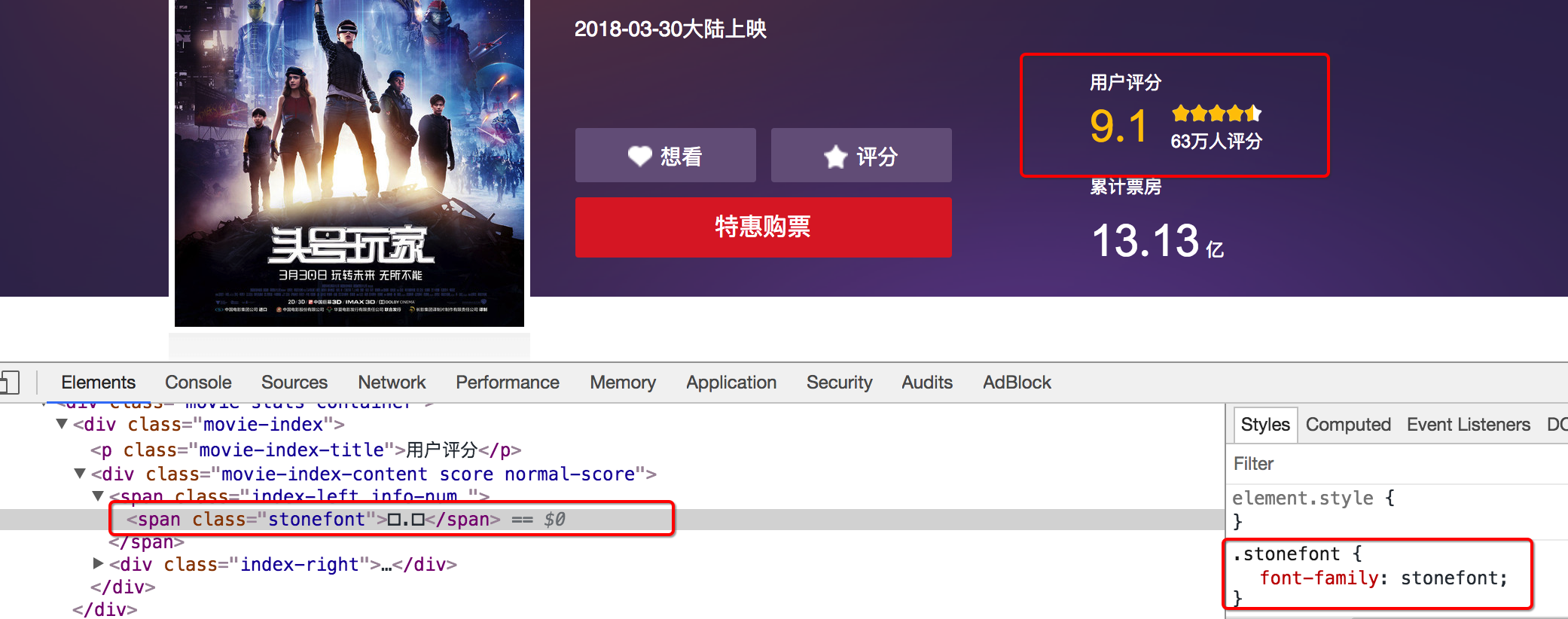
- 反爬思路: 使用自有字體文件
- 解決思路:切換到手機版/解析字體文件進行翻譯
1.2 通過css來反爬 下圖來自貓眼去哪兒電腦版
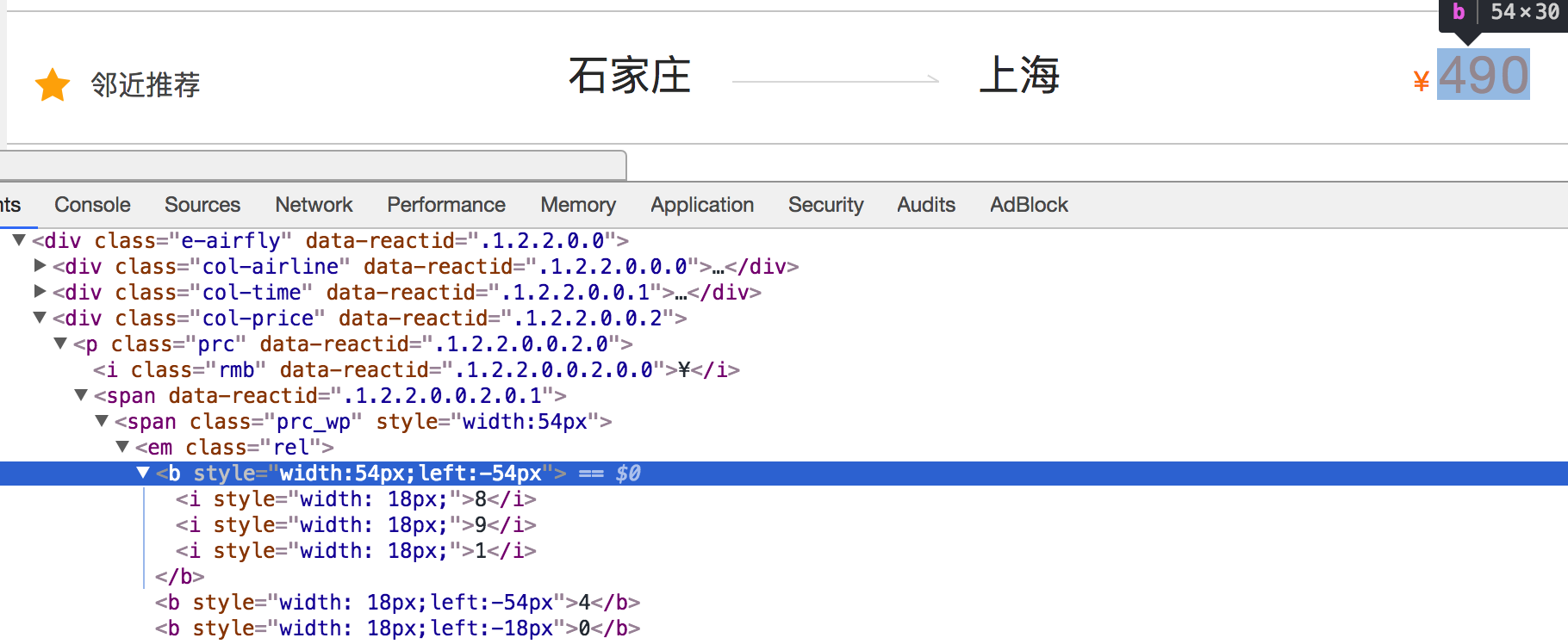
- 反爬思路:源碼數據不為真正數據,需要通過css位移才能產生真正數據
- 解決思路:計算css的偏移
1.3 通過js動態生成數據進行反爬
- 反爬原理:通過js動態生成
- 解決思路:解析關鍵js,獲得數據生成流程,模擬生成數據
1.4 通過數據圖片化反爬
- 58同城短租](https://baise.58.com/duanzu/38018718834984x.shtml)
- 解決思路:通過使用圖片解析引擎從圖片中解析數據
1.5 通過編碼格式進行反爬
- 反爬原理: 不適用默認編碼格式,在響應之后通常爬蟲使用utf-8格式進行解碼,此時解碼結果將會是亂碼或者報錯
- 解決思路:根據源碼進行多格式解碼,或者真正的解碼格式
小結
- 掌握 常見的反爬手段、原理以及應對思路
反爬與反反爬
本階段本文主要學習爬蟲的反爬及應對方法。
驗證碼處理
學習目標
- 了解 驗證碼的相關知識
- 掌握 圖片識別引擎的使用
- 了解 常見的打碼平臺
- 掌握 通過打碼平臺處理驗證碼的方法
1.圖片驗證碼
1.1 什么是圖片驗證碼
- 驗證碼(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自動區分計算機和人類的圖靈測試)的縮寫,是一種區分用戶是計算機還是人的公共全自動程序。
1.2 驗證碼的作用
- 防止惡意破解密碼、刷票、論壇灌水、刷頁。有效防止某個黑客對某一個特定注冊用戶用特定程序暴力破解方式進行不斷的登錄嘗試,實際上使用驗證碼是現在很多網站通行的方式(比如招商銀行的網上個人銀行,百度社區),我們利用比較簡易的方式實現了這個功能。雖然登錄麻煩一點,但是對網友的密碼安全來說這個功能還是很有必要,也很重要。
1.3 圖片驗證碼在爬蟲中的使用場景
- 注冊
- 登錄
- 頻繁發送請求時,服務器彈出驗證碼進行驗證
1.4 圖片驗證碼的處理方案
- 手動輸入(input) 這種方法僅限于登錄一次就可持續使用的情況
- 圖像識別引擎解析 使用光學識別引擎處理圖片中的數據,目前常用于圖片數據提取,較少用于驗證碼處理
- 打碼平臺 爬蟲常用的驗證碼解決方案
2.圖片識別引擎
OCR(Optical Character Recognition)是指使用掃描儀或數碼相機對文本資料進行掃描成圖像文件,然后對圖像文件進行分析處理,自動識別文字信息及版面信息的軟件。
2.1 什么是tesseract
- Tesseract,一款由HP實驗室開發由Google維護的開源OCR引擎,特點是開源,免費,支持多語言,多平臺。
- 項目地址:https://github.com/tesseract-ocr/tesseract
2.2 圖片識別引擎環境的安裝
1 引擎的安裝
- mac環境下直接執行命令
brew install --with-training-tools tesseract
-
windows環境下的安裝 可以通過exe安裝包安裝,下載地址可以從GitHub項目中的wiki找到。安裝完成后記得將Tesseract 執行文件的目錄加入到PATH中,方便后續調用。
-
linux環境下的安裝
sudo apt-get install tesseract-ocr
2 Python庫的安裝
# PIL用于打開圖片文件pip/pip3 install pillow# pytesseract模塊用于從圖片中解析數據pip/pip3 install pytesseract
2.3 圖片識別引擎的使用
- 通過pytesseract模塊的 image_to_string 方法就能將打開的圖片文件中的數據提取成字符串數據,具體方法如下
from PIL import Image
import pytesseractim = Image.open()result = pytesseract.image_to_string(im)print(result)
2.4 圖片識別引擎的使用擴展
- tesseract簡單使用與訓練
- 其他ocr平臺
微軟Azure 圖像識別:https://azure.microsoft.com/zh-cn/services/cognitive-services/computer-vision/有道智云文字識別:http://aidemo.youdao.com/ocrdemo阿里云圖文識別:https://www.aliyun.com/product/cdi/騰訊OCR文字識別:https://cloud.tencent.com/product/ocr
3 打碼平臺
1.為什么需要了解打碼平臺的使用
現在很多網站都會使用驗證碼來進行反爬,所以為了能夠更好的數據,需要了解如何使用打碼平臺爬蟲中的驗證碼
2 常見的打碼平臺
- 云打碼:http://www.yundama.com/
能夠解決通用的驗證碼識別
- 極驗驗證碼智能識別輔助:http://jiyandoc.c2567.com/
能夠解決復雜驗證碼的識別
3 云打碼的使用
下面以云打碼為例,了解打碼平臺如何使用
3.1 云打碼官方接口
下面代碼是云打碼平臺提供,做了個簡單修改,實現了兩個方法:
- indetify:傳入圖片的響應二進制數即可
- indetify_by_filepath:傳入圖片的路徑即可識別
其中需要自己配置的地方是:
username = 'whoarewe' # 用戶名password = '***' # 密碼appid = 4283 # appidappkey = '02074c64f0d0bb9efb2df455537b01c3' # appkeycodetype = 1004 # 驗證碼類型
云打碼官方提供的api如下:
#yundama.pyimport requests
import json
import timeclass YDMHttp:apiurl = 'http://api.yundama.com/api.php'username = ''password = ''appid = ''appkey = ''def __init__(self, username, password, appid, appkey):self.username = usernameself.password = passwordself.appid = str(appid)self.appkey = appkeydef request(self, fields, files=[]):response = self.post_url(self.apiurl, fields, files)response = json.loads(response)return responsedef balance(self):data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid,'appkey': self.appkey}response = self.request(data)if (response):if (response['ret'] and response['ret'] < 0):return response['ret']else:return response['balance']else:return -9001def login(self):data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid,'appkey': self.appkey}response = self.request(data)if (response):if (response['ret'] and response['ret'] < 0):return response['ret']else:return response['uid']else:return -9001def upload(self, filename, codetype, timeout):data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid,'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)}file = {'file': filename}response = self.request(data, file)if (response):if (response['ret'] and response['ret'] < 0):return response['ret']else:return response['cid']else:return -9001def result(self, cid):data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid,'appkey': self.appkey, 'cid': str(cid)}response = self.request(data)return response and response['text'] or ''def decode(self, filename, codetype, timeout):cid = self.upload(filename, codetype, timeout)if (cid > 0):for i in range(0, timeout):result = self.result(cid)if (result != ''):return cid, resultelse:time.sleep(1)return -3003, ''else:return cid, ''def post_url(self, url, fields, files=[]):# for key in files:# files[key] = open(files[key], 'rb');res = requests.post(url, files=files, data=fields)return res.text username = 'whoarewe' # 用戶名password = '***' # 密碼appid = 4283 # appidappkey = '02074c64f0d0bb9efb2df455537b01c3' # appkeyfilename = 'getimage.jpg' # 文件位置codetype = 1004 # 驗證碼類型# 超時timeout = 60def indetify(response_content):if (username == 'username'):print('請設置好相關參數再測試')else:# 初始化yundama = YDMHttp(username, password, appid, appkey)# 登陸云打碼uid = yundama.login();print('uid: %s' % uid)# 查詢余額balance = yundama.balance();print('balance: %s' % balance)# 開始識別,圖片路徑,驗證碼類型ID,超時時間(秒),識別結果cid, result = yundama.decode(response_content, codetype, timeout)print('cid: %s, result: %s' % (cid, result))return resultdef indetify_by_filepath(file_path):if (username == 'username'):print('請設置好相關參數再測試')else:# 初始化yundama = YDMHttp(username, password, appid, appkey)# 登陸云打碼uid = yundama.login();print('uid: %s' % uid)# 查詢余額balance = yundama.balance();print('balance: %s' % balance)# 開始識別,圖片路徑,驗證碼類型ID,超時時間(秒),識別結果cid, result = yundama.decode(file_path, codetype, timeout)print('cid: %s, result: %s' % (cid, result))return resultif __name__ == '__main__':pass
4 常見的驗證碼的種類
4.1 url地址不變,驗證碼不變
這是驗證碼里面非常簡單的一種類型,對應的只需要驗證碼的地址,然后請求,通過打碼平臺識別即可
4.2 url地址不變,驗證碼變化
這種驗證碼的類型是更加常見的一種類型,對于這種驗證碼,大家需要思考:
在登錄的過程中,假設我輸入的驗證碼是對的,對方服務器是如何判斷當前我輸入的驗證碼是顯示在我屏幕上的驗證碼,而不是其他的驗證碼呢?
在網頁的時候,請求驗證碼,以及提交驗證碼的時候,對方服務器肯定通過了某種手段驗證我之前的驗證碼和最后提交的驗證碼是同一個驗證碼,那這個手段是什么手段呢?
很明顯,就是通過cookie來實現的,所以對應的,在請求頁面,請求驗證碼,提交驗證碼的到時候需要保證cookie的一致性,對此可以使用requests.session來解決
小結
- 了解 驗證碼的相關知識
- 掌握 圖片識別引擎的使用
- 了解 常見的打碼平臺
- 掌握 通過打碼平臺處理驗證碼的方法
chrome瀏覽器使用方法介紹
學習目標
- 了解 新建隱身窗口的目的
- 了解 chrome中network的使用
- 了解 尋找登錄接口的方法
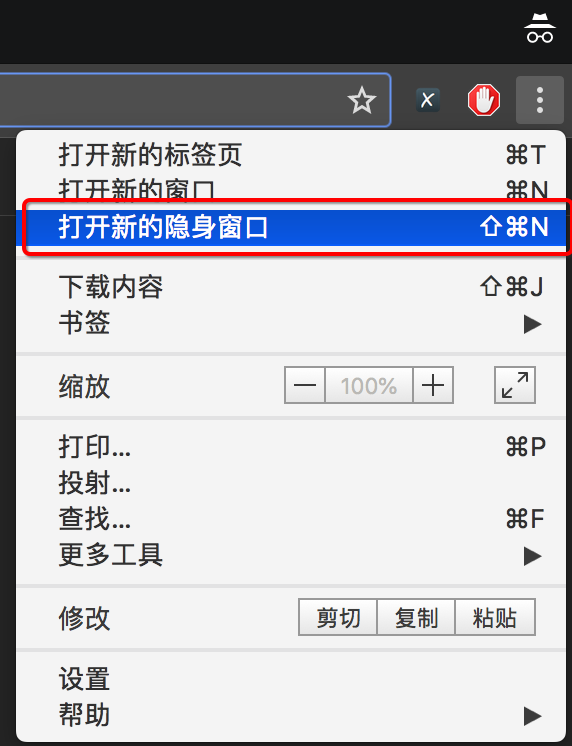
1 新建隱身窗口
瀏覽器中直接打開網站,會自動帶上之前網站時保存的cookie,但是在爬蟲中首次頁面是沒有攜帶cookie的,這種情況如何解決呢?
使用隱身窗口,首次打開網站,不會帶上cookie,能夠觀察頁面的情況,包括對方服務器如何設置cookie在本地
2 chrome中network的更多功能
2.1 Perserve log
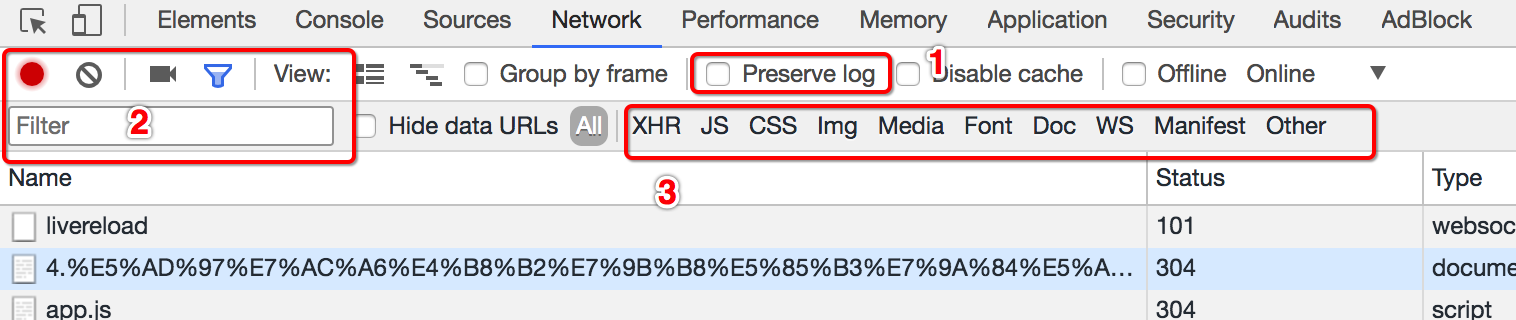
默認情況下,頁面發生跳轉之后,之前的請求url地址等信息都會消失,勾選perserve log后之前的請求都會被保留 
2.2 filter過濾
在url地址很多的時候,可以在filter中輸入部分url地址,對所有的url地址起到一定的過濾效果,具體位置在上面第二幅圖中的2的位置
2.3 觀察特定種類的請求
在上面第二幅圖中的3的位置,有很多選項,默認是選擇的all,即會觀察到所有種類的請求
很多時候處于自己的目的可以選擇all右邊的其他選項,比如常見的選項:
- XHR:大部分情況表示ajax請求
- JS:js請求
- CSS:css請求
但是很多時候我們并不能保證我們需要的請求是什么類型,特別是我們不清楚一個請求是否為ajax請求的時候,直接選擇all,從前往后觀察即可,其中js,css,圖片等不去觀察即可
不要被瀏覽器中的一堆請求嚇到了,這些請求中除了js,css,圖片的請求外,其他的請求并沒有多少個
3 尋找登錄接口
回顧之前人人網的爬蟲我們找到了一個登陸接口,那么這個接口從哪里找到的呢?
http://www.renren.com
3.1 尋找action對的url地址
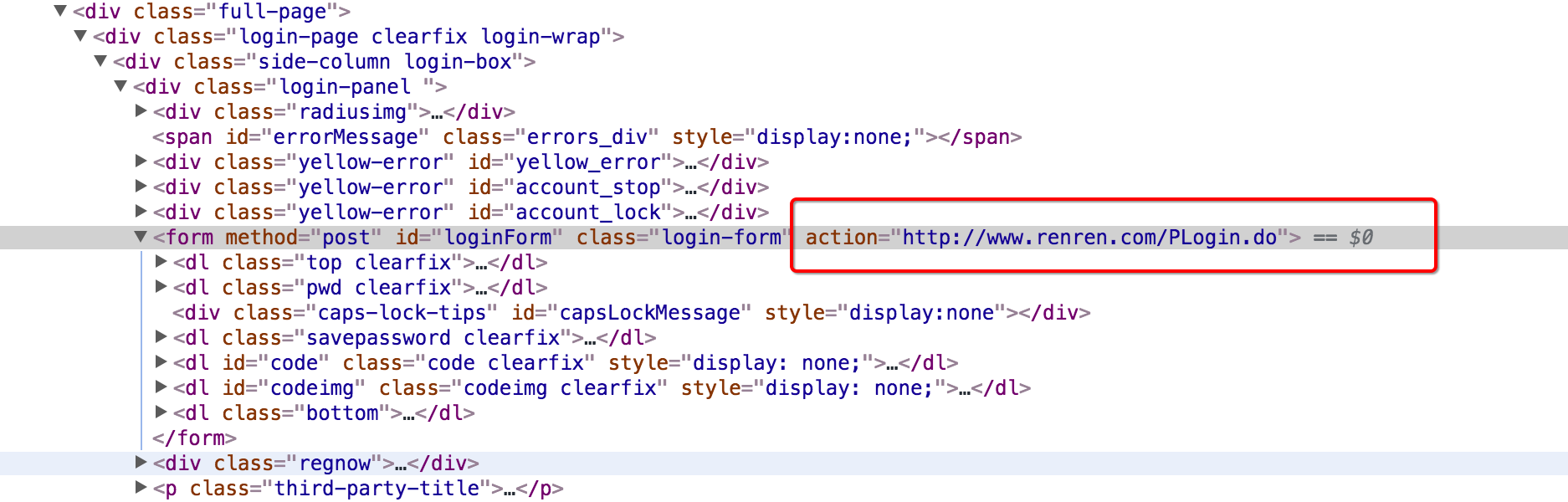
可以發現,這個地址就是在登錄的form表單中action對應的url地址,回顧前端的知識點,可以發現就是進行表單提交的地址,對應的,提交的數據,僅僅需要:用戶名的input標簽中,name的值作為鍵,用戶名作為值,密碼的input標簽中,name的值作為鍵,密碼作為值即可
思考:
如果action對應的沒有url地址的時候可以怎么做?
3.2 通過抓包尋找登錄的url地址
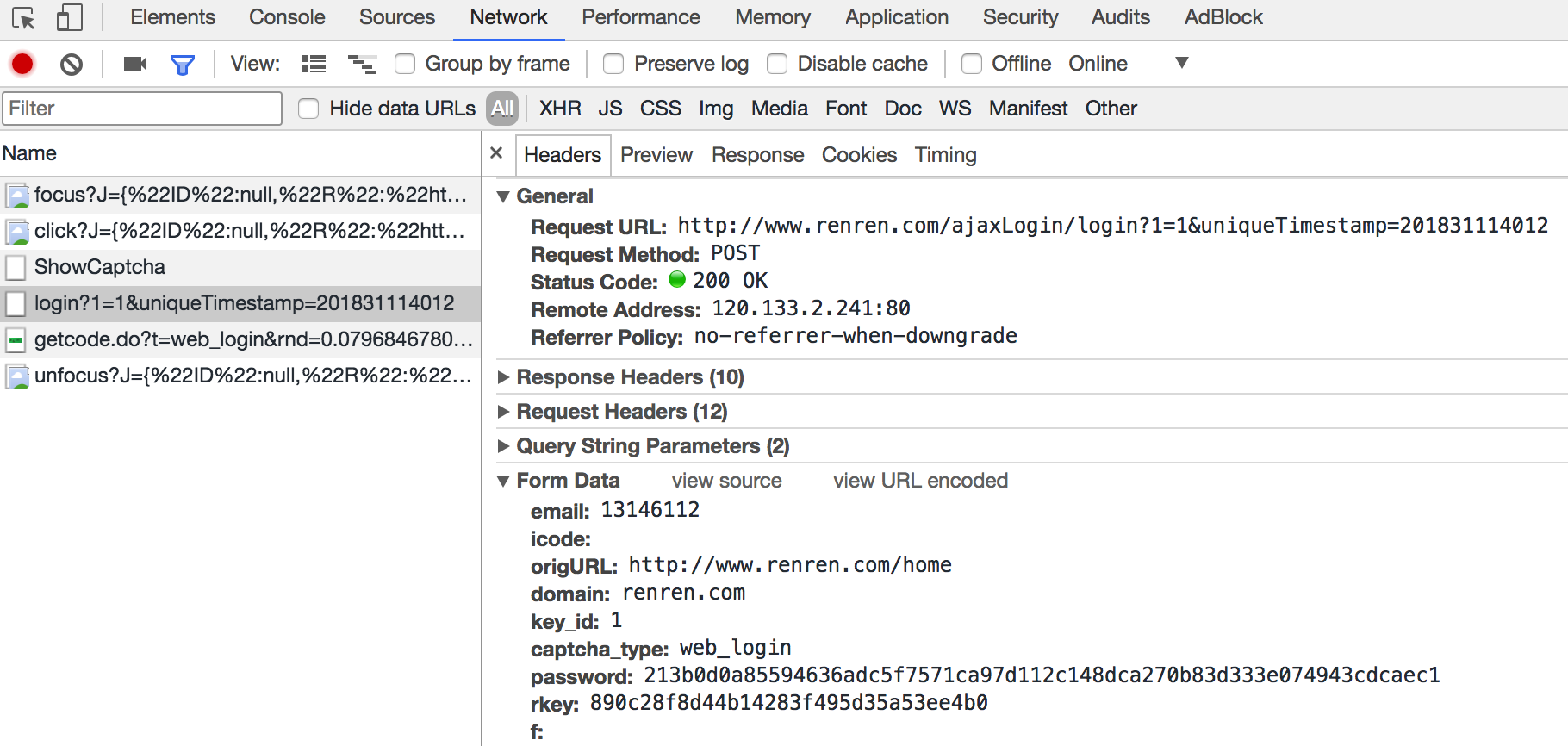
通過抓包可以發現,在這個url地址和請求體中均有參數,比如uniqueTimestamp和rkey以及加密之后的password
這個時候我們可以觀察手機版的登錄接口,是否也是一樣的
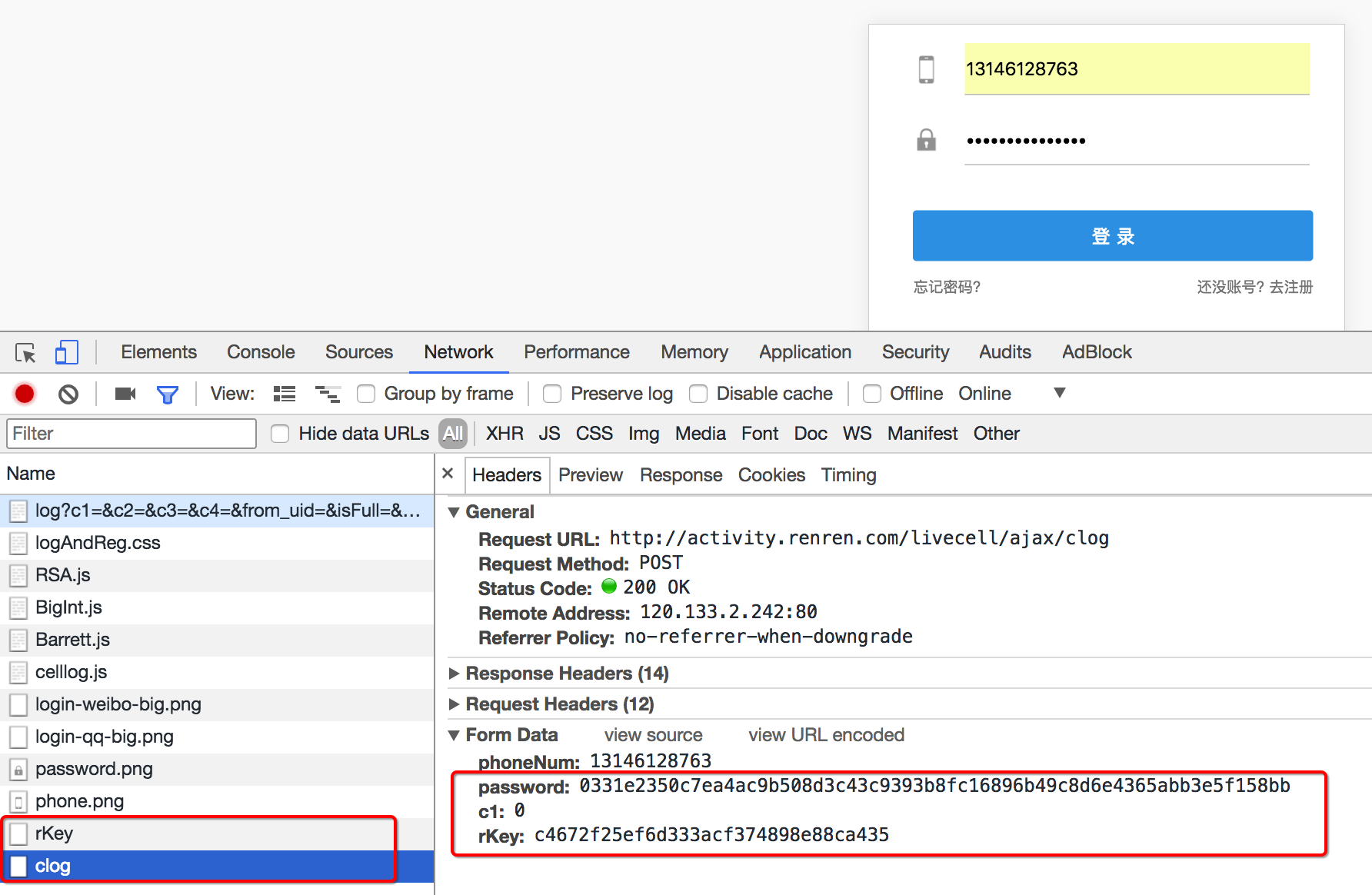
可以發現在手機版中,依然有參數,但是參數的個數少一些,這個時候,我們可以使用手機版作為參考,下一節來學習如何分析js
小結
-
使用隱身窗口的主要目的是為了避免首次打開網站攜帶cookie的問題
-
chrome的network中,perserve log選項能夠在頁面發生跳轉之后任然能夠觀察之前的請求
-
確定登錄的地址有兩種方法:
- 尋找from表單action的url地址
- 通過抓包

)













)



