一、引子————邊界檢測
我們來看一個最簡單的例子:“邊界檢測(edge detection)”,假設我們有這樣的一張圖片,大小8×8:
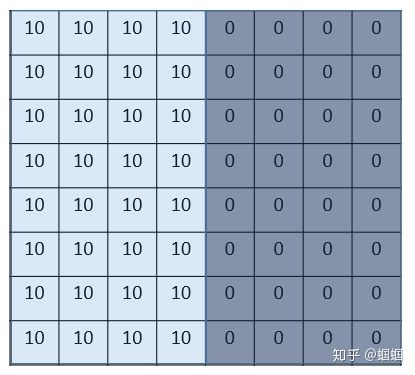
圖片中的數字代表該位置的像素值,我們知道,像素值越大,顏色越亮,所以為了示意,我們把右邊小像素的地方畫成深色。圖的中間兩個顏色的分界線就是我們要檢測的邊界。
怎么檢測這個邊界呢?我們可以設計這樣的一個?濾波器(filter,也稱為kernel),大小3×3:
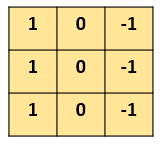
然后,我們用這個filter,往我們的圖片上“蓋”,覆蓋一塊跟filter一樣大的區域之后,對應元素相乘,然后求和。計算一個區域之后,就向其他區域挪動,接著計算,直到把原圖片的每一個角落都覆蓋到了為止。這個過程就是?“卷積”。 (我們不用管卷積在數學上到底是指什么運算,我們只用知道在CNN中是怎么計算的。) 這里的“挪動”,就涉及到一個步長了,假如我們的步長是1,那么覆蓋了一個地方之后,就挪一格,容易知道,總共可以覆蓋6×6個不同的區域。
那么,我們將這6×6個區域的卷積結果,拼成一個矩陣:
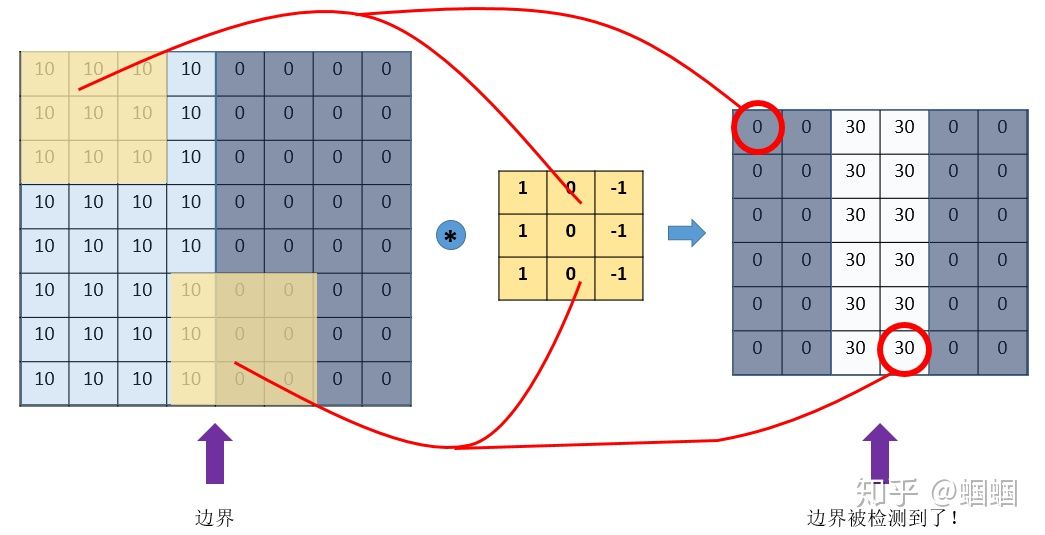
誒?!發現了什么? 這個圖片,中間顏色淺,兩邊顏色深,這說明咱們的原圖片中間的邊界,在這里被反映出來了!
從上面這個例子中,我們發現,我們可以通過設計特定的filter,讓它去跟圖片做卷積,就可以識別出圖片中的某些特征,比如邊界。 上面的例子是檢測豎直邊界,我們也可以設計出檢測水平邊界的,只用把剛剛的filter旋轉90°即可。對于其他的特征,理論上只要我們經過精細的設計,總是可以設計出合適的filter的。
我們的CNN(convolutional neural network),主要就是通過一個個的filter,不斷地提取特征,從局部的特征到總體的特征,從而進行圖像識別等等功能。
那么問題來了,我們怎么可能去設計這么多各種各樣的filter呀?首先,我們都不一定清楚對于一大推圖片,我們需要識別哪些特征,其次,就算知道了有哪些特征,想真的去設計出對應的filter,恐怕也并非易事,要知道,特征的數量可能是成千上萬的。
其實學過神經網絡之后,我們就知道,這些filter,根本就不用我們去設計,每個filter中的各個數字,不就是參數嗎,我們可以通過大量的數據,來?讓機器自己去“學習”這些參數嘛。這,就是CNN的原理。
二、CNN的基本概念
1.padding 填白
從上面的引子中,我們可以知道,原圖像在經過filter卷積之后,變小了,從(8,8)變成了(6,6)。假設我們再卷一次,那大小就變成了(4,4)了。
這樣有啥問題呢??主要有兩個問題: - 每次卷積,圖像都縮小,這樣卷不了幾次就沒了; - 相比于圖片中間的點,圖片邊緣的點在卷積中被計算的次數很少。這樣的話,邊緣的信息就易于丟失。
為了解決這個問題,我們可以采用padding的方法。我們每次卷積前,先給圖片周圍都補一圈空白,讓卷積之后圖片跟原來一樣大,同時,原來的邊緣也被計算了更多次。
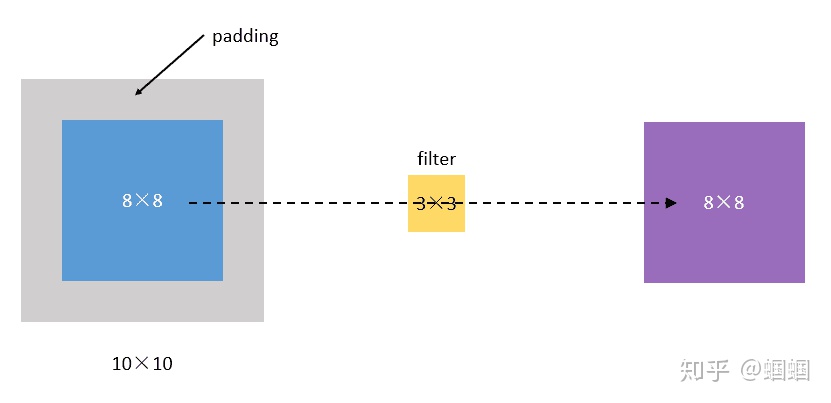
比如,我們把(8,8)的圖片給補成(10,10),那么經過(3,3)的filter之后,就是(8,8),沒有變。
我們把上面這種“讓卷積之后的大小不變”的padding方式,稱為?“Same”方式, 把不經過任何填白的,稱為?“Valid”方式。這個是我們在使用一些框架的時候,需要設置的超參數。
2.stride 步長
前面我們所介紹的卷積,都是默認步長是1,但實際上,我們可以設置步長為其他的值。 比如,對于(8,8)的輸入,我們用(3,3)的filter, 如果stride=1,則輸出為(6,6); 如果stride=2,則輸出為(3,3);(這里例子舉得不大好,除不斷就向下取整)
3.pooling 池化
這個pooling,是為了提取一定區域的主要特征,并減少參數數量,防止模型過擬合。 比如下面的MaxPooling,采用了一個2×2的窗口,并取stride=2:
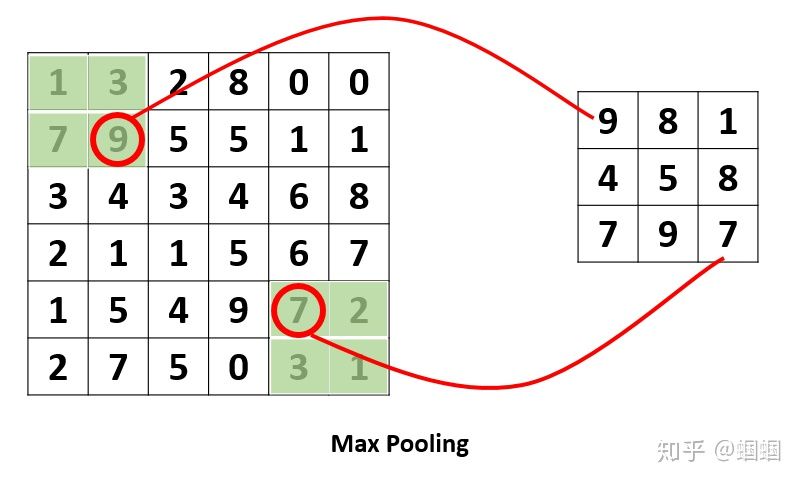
除了MaxPooling,還有AveragePooling,顧名思義就是取那個區域的平均值。
4.對多通道(channels)圖片的卷積
這個需要單獨提一下。彩色圖像,一般都是RGB三個通道(channel)的,因此輸入數據的維度一般有三個:(長,寬,通道)。 比如一個28×28的RGB圖片,維度就是(28,28,3)。
前面的引子中,輸入圖片是2維的(8,8),filter是(3,3),輸出也是2維的(6,6)。
如果輸入圖片是三維的呢(即增多了一個channels),比如是(8,8,3),這個時候,我們的filter的維度就要變成(3,3,3)了,它的?最后一維要跟輸入的channel維度一致。?這個時候的卷積,是三個channel的所有元素對應相乘后求和,也就是之前是9個乘積的和,現在是27個乘積的和。因此,輸出的維度并不會變化。還是(6,6)。
但是,一般情況下,我們會?使用多了filters同時卷積,比如,如果我們同時使用4個filter的話,那么?輸出的維度則會變為(6,6,4)。
我特地畫了下面這個圖,來展示上面的過程:
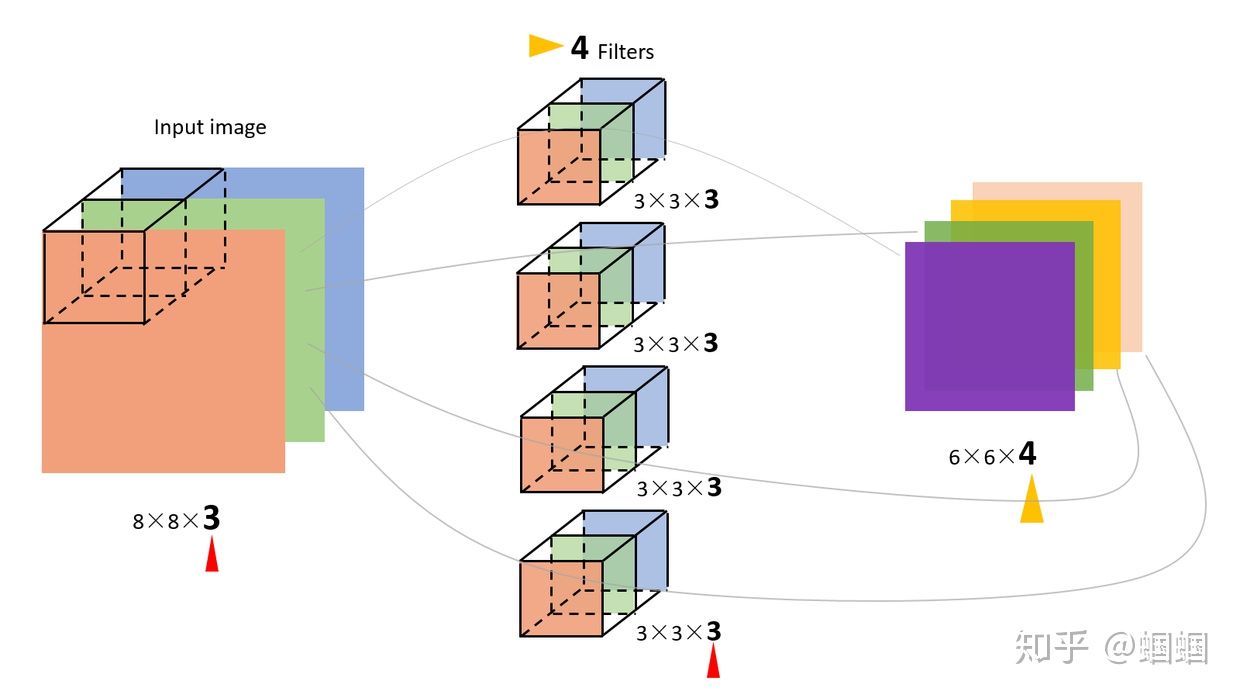
圖中的輸入圖像是(8,8,3),filter有4個,大小均為(3,3,3),得到的輸出為(6,6,4)。 我覺得這個圖已經畫的很清晰了,而且給出了3和4這個兩個關鍵數字是怎么來的,所以我就不啰嗦了(這個圖畫了我起碼40分鐘)。
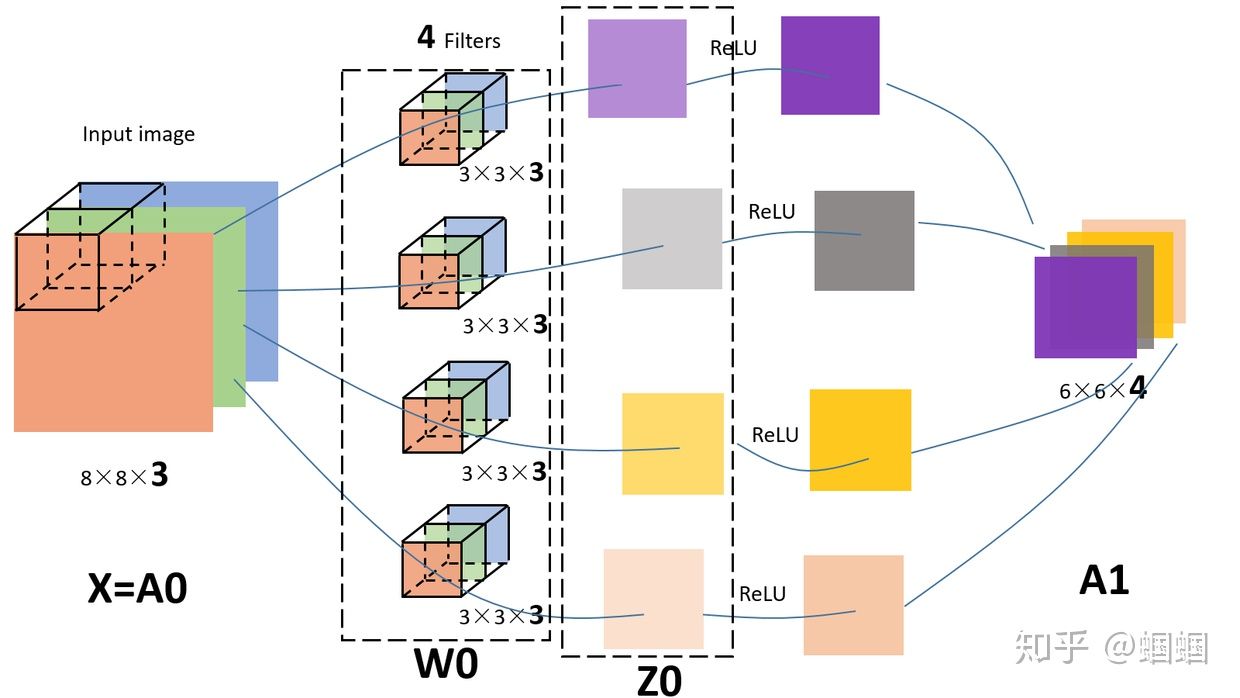
其實,如果套用我們前面學過的神經網絡的符號來看待CNN的話,
- 我們的輸入圖片就是X,shape=(8,8,3);
- 4個filters其實就是第一層神金網絡的參數W1,,shape=(3,3,3,4),這個4是指有4個filters;
- 我們的輸出,就是Z1,shape=(6,6,4);
- 后面其實還應該有一個激活函數,比如relu,經過激活后,Z1變為A1,shape=(6,6,4);
所以,在前面的圖中,我加一個激活函數,給對應的部分標上符號,就是這樣的:
三、CNN的結構組成
上面我們已經知道了卷積(convolution)、池化(pooling)以及填白(padding)是怎么進行的,接下來我們就來看看CNN的整體結構,它包含了3種層(layer):
1. Convolutional layer(卷積層–CONV)
由濾波器filters和激活函數構成。 一般要設置的超參數包括filters的數量、大小、步長,以及padding是“valid”還是“same”。當然,還包括選擇什么激活函數。
2. Pooling layer (池化層–POOL)
這里里面沒有參數需要我們學習,因為這里里面的參數都是我們設置好了,要么是Maxpooling,要么是Averagepooling。 需要指定的超參數,包括是Max還是average,窗口大小以及步長。 通常,我們使用的比較多的是Maxpooling,而且一般取大小為(2,2)步長為2的filter,這樣,經過pooling之后,輸入的長寬都會縮小2倍,channels不變。
3. Fully Connected layer(全連接層–FC)
這個前面沒有講,是因為這個就是我們最熟悉的家伙,就是我們之前學的神經網絡中的那種最普通的層,就是一排神經元。因為這一層是每一個單元都和前一層的每一個單元相連接,所以稱之為“全連接”。 這里要指定的超參數,無非就是神經元的數量,以及激活函數。
接下來,我們隨便看一個CNN的模樣,來獲取對CNN的一些感性認識:
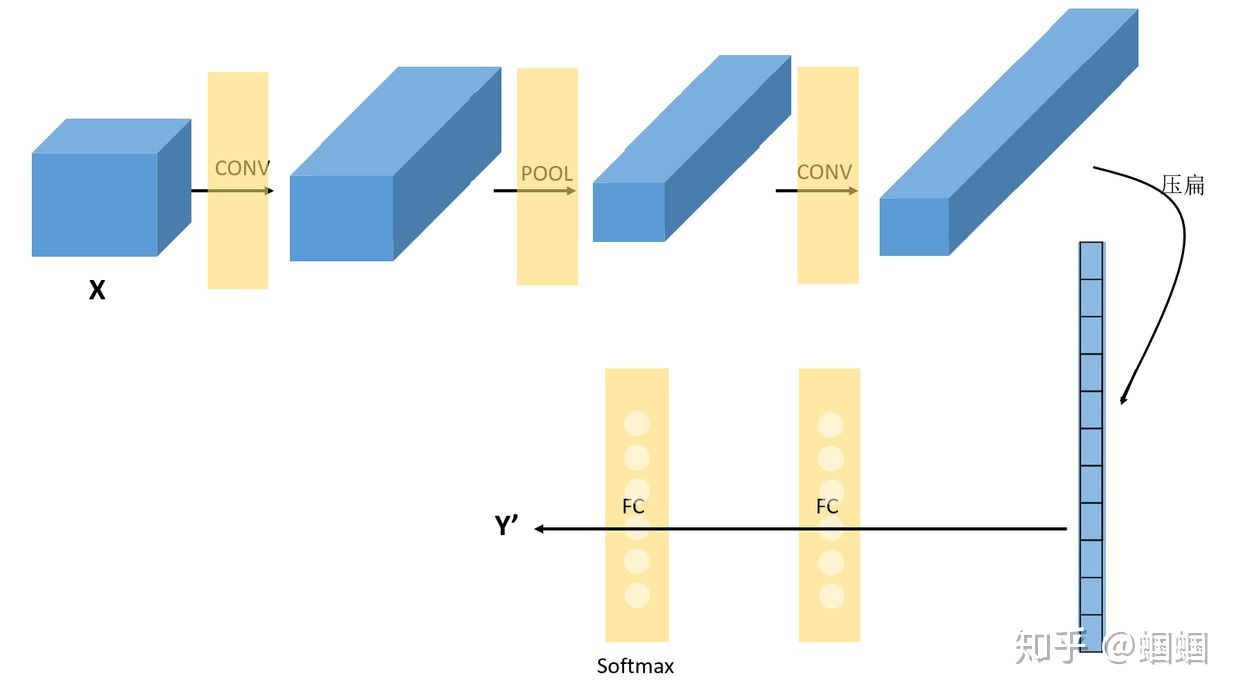
上面這個CNN是我隨便拍腦門想的一個。它的結構可以用: X–>CONV(relu)–>MAXPOOL–>CONV(relu)–>FC(relu)–>FC(softmax)–>Y 來表示。
這里需要說明的是,在經過數次卷積和池化之后,我們?最后會先將多維的數據進行“扁平化”,也就是把?(height,width,channel)的數據壓縮成長度為?height × width × channel?的一維數組,然后再與?FC層連接,這之后就跟普通的神經網絡無異了。
可以從圖中看到,隨著網絡的深入,我們的圖像(嚴格來說中間的那些不能叫圖像了,但是為了方便,還是這樣說吧)越來越小,但是channels卻越來越大了。在圖中的表示就是長方體面對我們的面積越來越小,但是長度卻越來越長了。
四、卷積神經網絡 VS. 傳統神經網絡
其實現在回過頭來看,CNN跟我們之前學習的神經網絡,也沒有很大的差別。 傳統的神經網絡,其實就是多個FC層疊加起來。 CNN,無非就是把FC改成了CONV和POOL,就是把傳統的由一個個神經元組成的layer,變成了由filters組成的layer。
那么,為什么要這樣變?有什么好處? 具體說來有兩點:
1.參數共享機制(parameters sharing)
我們對比一下傳統神經網絡的層和由filters構成的CONV層: 假設我們的圖像是8×8大小,也就是64個像素,假設我們用一個有9個單元的全連接層:
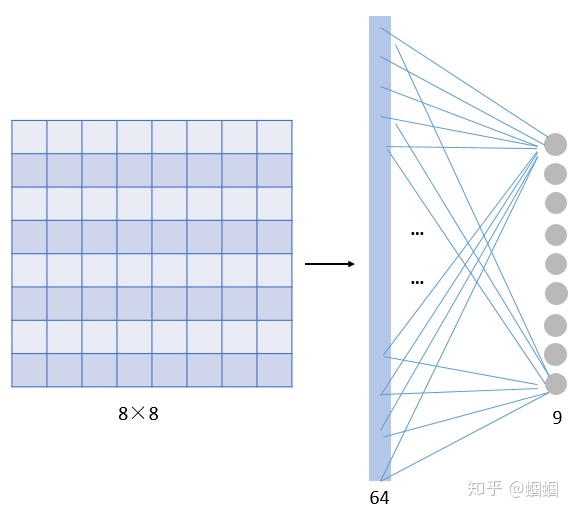
那這一層我們需要多少個參數呢?需要?64×9 = 576個參數(先不考慮偏置項b)。因為每一個鏈接都需要一個權重w。
那我們看看?同樣有9個單元的filter是怎么樣的:
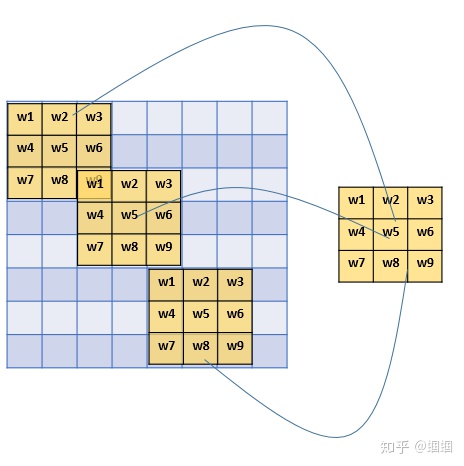
其實不用看就知道,有幾個單元就幾個參數,所以總共就9個參數!
因為,對于不同的區域,我們都共享同一個filter,因此就共享這同一組參數。 這也是有道理的,通過前面的講解我們知道,filter是用來檢測特征的,那一個特征一般情況下很可能在不止一個地方出現,比如“豎直邊界”,就可能在一幅圖中多出出現,那么?我們共享同一個filter不僅是合理的,而且是應該這么做的。
由此可見,參數共享機制,讓我們的網絡的參數數量大大地減少。這樣,我們可以用較少的參數,訓練出更加好的模型,典型的事半功倍,而且可以有效地?避免過擬合。 同樣,由于filter的參數共享,即使圖片進行了一定的平移操作,我們照樣可以識別出特征,這叫做?“平移不變性”。因此,模型就更加穩健了。
2.連接的稀疏性(sparsity of connections)
由卷積的操作可知,輸出圖像中的任何一個單元,只跟輸入圖像的一部分有關系:
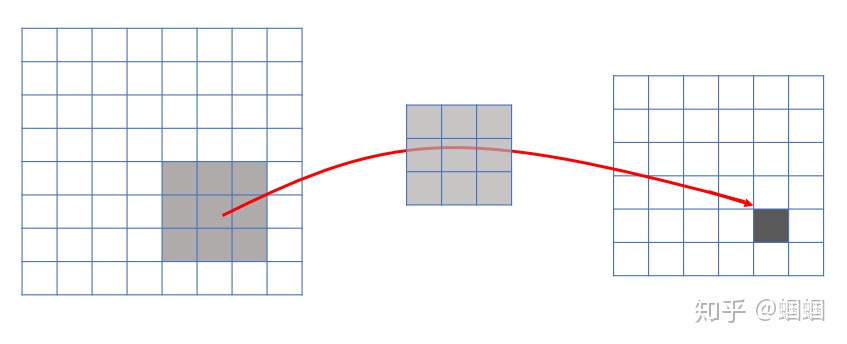
而傳統神經網絡中,由于都是全連接,所以輸出的任何一個單元,都要受輸入的所有的單元的影響。這樣無形中會對圖像的識別效果大打折扣。比較,每一個區域都有自己的專屬特征,我們不希望它受到其他區域的影響。
正是由于上面這兩大優勢,使得CNN超越了傳統的NN,開啟了神經網絡的新時代。







)
與合成)





)



)
