? 摘要
鏈接預測[1,2]是圖學習的一種基礎任務,用于判斷圖中的兩個節點是否可能相連,被廣泛應用于藥物發現、知識圖譜補全和在線問答等實際場景。盡管圖神經網絡(Graph Neural Network,GNN)在該問題的性能上取得了顯著進步,但在圖結構噪聲下的差強人意的魯棒性仍是當前深度圖模型的實際瓶頸。
在魯棒圖學習方面,早期工作探索了通過鄰近節點的平滑效果來提高GNN在節點標簽噪聲下的魯棒性,其他方法通過隨機移除邊或主動選擇有信息量的節點或邊來達到類似的效果。然而,當將這些抗噪聲方法應用于帶有噪聲的鏈接預測時,只能取得非常有限的增益。其原因在于,不同于標簽噪聲,這里的圖結構噪聲是雙向的:它會自然地同時擾動輸入圖的拓撲結構和輸出端目標邊的標簽,即同時存在noisy inputs和noisy labels(如下圖1所示),且這種雙向噪聲在現實世界的圖數據中是常見的[3],如點擊率預測、商品推薦等場景。
于是,我們提出一個新的挑戰:如何處理雙邊噪聲以實現魯棒的鏈接預測?
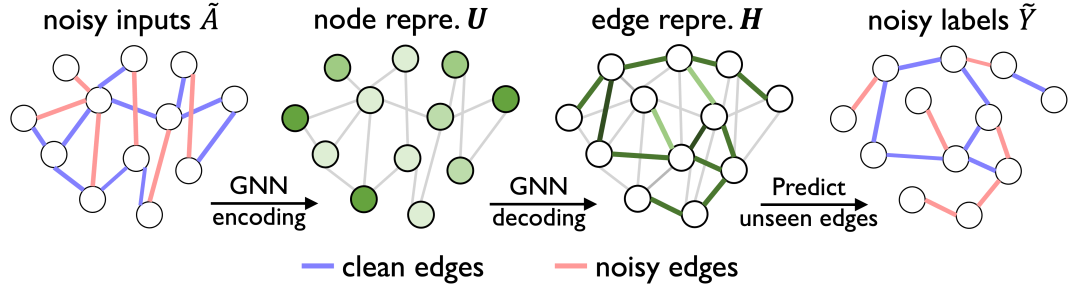
首先,我們進行了一個實證研究,揭示了圖結構噪聲如何雙向干擾輸入拓撲結構和目標標簽,導致性能嚴重下降和表征坍縮。為此,我們提出了一個信息論指導原則,即魯棒圖信息瓶頸(Robust Graph Information Bottleneck,RGIB),以提取可靠的監督信號并避免表征坍縮。與基本的信息瓶頸GIB[4,5]不同的是,RGIB進一步解耦并平衡了圖拓撲、圖標簽和圖表征之間的相互依賴性,為抵抗雙邊噪聲的魯棒表征構建了新的學習目標。此外,我們探索了兩種實例,RGIB-SSL和RGIB-REP,利用自監督學習和數據重參數化方法的優勢,分別進行隱式和顯式的去噪學習。
簡言之,在本項工作中:
我們發現雙邊噪聲會導致嚴重的表征坍縮和性能下降,并且這種負面影響對常見數據集和圖神經網絡來說是普遍存在的。據我們所知,我們是最早研究在雙邊噪聲下鏈接預測魯棒性問題的。
我們提出了一個通用學習框架RGIB,設計了新的表征學習目標以提高圖神經網絡的魯棒性。我們基于不同的方法論提出了兩種實現方式,即RGIB-SSL和RGIB-REP,并提出了適應性的設計和理論的分析。
RGIB在不修改GNN架構的情況下,在3種常用GNN和6個常見數據集上達到了最有效果,各種噪聲場景下的AUC提升了高達12.9%,模型學到的表征分布顯著恢復,并且對雙邊噪聲更加魯棒。
接下來,將簡要地向大家分享我們近期發表在 NeurIPS 2023 上的有關雙邊噪聲下鏈接預測魯棒性的研究結果。
本項研究結果是淘天集團阿里媽媽展示外投團隊與香港浸會大學韓波老師研究團隊自2022年8月開始通過阿里巴巴創新研究計劃(AIR),共同參與“針對大規模在線廣告的可信賴深度學習” 項目的研究工作。
論文標題: Combating Bilateral Edge Noise for Robust Link Prediction
論文下載: https://openreview.net/pdf?id=ePkLqJh5kw
代碼鏈接: https://github.com/tmlr-group/RGIB
🔍 本期話題:如何從優化的角度來解決數據噪聲呢?歡迎評論區留言討論~
1. 問題定義
為了定量研究雙邊圖結構噪聲的影響,我們在一系列GNN基準數據集上合理地模擬不同程度的擾動,詳細說明見如下定義3.1。需要注意的是,目前最常采用的數據劃分方式是隨機地將部分邊分為觀測部分和預測目標部分,因此在訓練集中,噪聲邊會被劃分到輸入和標簽中。
雙邊噪聲的生成(定義3.1):假設存在一組干凈的訓練數據,即觀察到的圖,以及查詢邊的標簽 。通過向原始鄰接矩陣添加邊噪聲,同時保持節點特征不變,生成了噪聲鄰接矩陣。類似地,通過向標簽添加邊噪聲生成了噪聲標簽。具體而言,給定噪聲比例,噪聲邊 () 通過將 A 中的零元素以概率翻轉為一來生成。滿足和。類似地,可生成噪聲標簽并添加到原始標簽中,其中 。
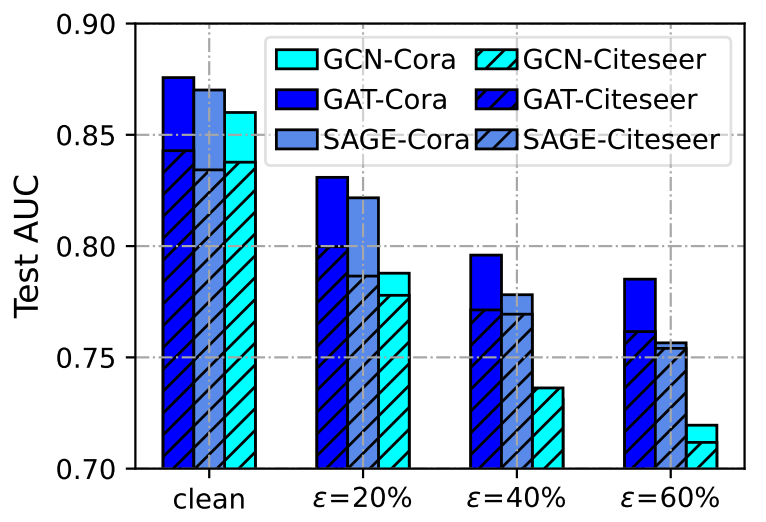
基于此定義,我們進行實驗并發現,雙邊圖結構噪聲導致GNN的性能顯著下降(見圖4),而更大的噪聲比率通常導致更嚴重的性能退化。這意味著,經過標準訓練的GNN容易受到雙邊圖結構噪聲的影響,表現出嚴重的魯棒性問題。此外,雙邊噪聲帶來的性能下降遠遠大于單邊輸入噪聲或標簽噪聲的影響。
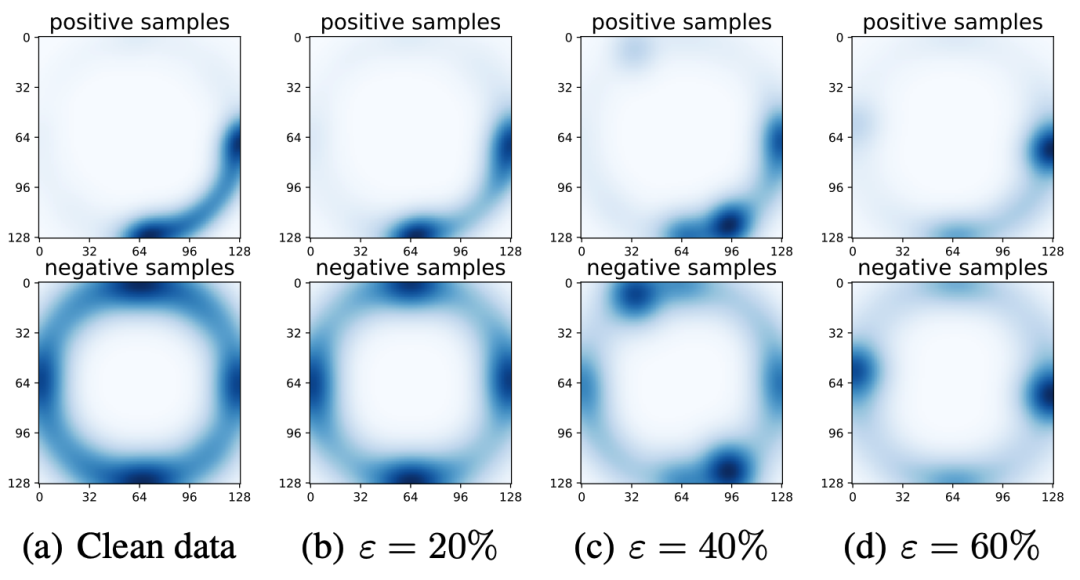
接著,我們檢查GNN學習得到的表征。從圖5的uniformity分布可以看出,表征在雙邊噪聲的作用下嚴重坍縮,由原本較為均勻的環狀分布逐步退化成了幾個單點,且更高的噪聲率會導致更嚴重的坍縮程度,這反映了噪聲對于圖學習的負面影響,也是最終性能下降的重要原因。
2. 解決方案
2.1 GIB的固有缺陷
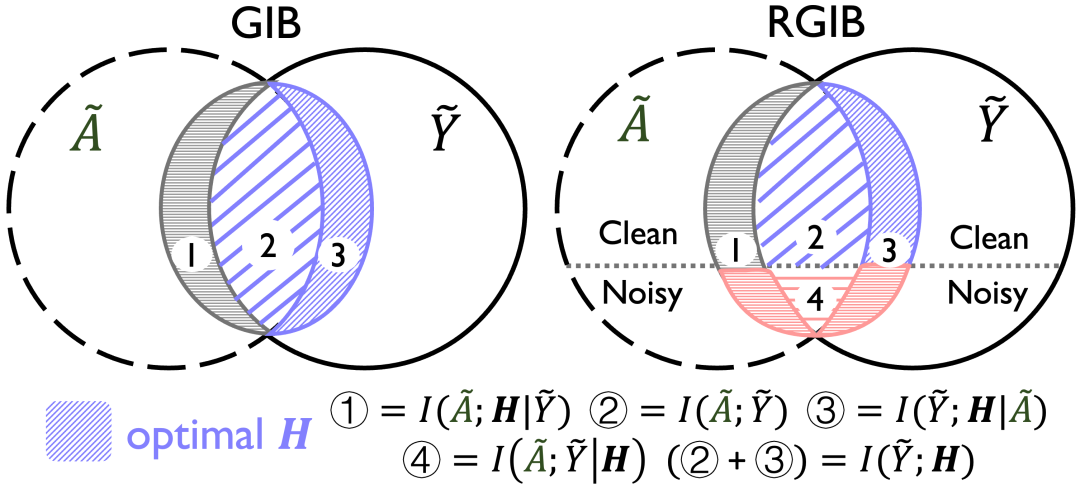
為了增強圖表征的魯棒性并避免嚴重的表征坍縮,我們可以利用圖信息瓶頸(Graph Information Bottleneck,GIB)[4,5] 的信息約束作為圖表征優化的目標,即:
其中,超參數用于限制互信息項,以避免表征過多捕獲來自的與任務無關的信息。基本的GIB可以有效地防御輸入擾動,然而,它在本質上容易受到標簽噪聲的影響,因為它完全地保留了標簽噪聲的監督,所以基本的GIB不能夠解決雙邊噪聲問題。
2.2 RGIB優化目標設計
在本工作中,我們嘗試對GIB進行分析和改進。注意到,基本的GIB通過直接約束來降低,以處理輸入噪聲。同樣地,標簽噪聲可以隱藏在中,但是簡單地約束來正則化并不理想,因為它與GIB原始方程沖突,并且也無法處理內的噪聲。因此,進一步解耦、和之間的依賴關系至關重要。
注意到,噪聲可以存在于、和這幾個區域。分析上,我們知道:
其中是一個常數,冗余可以被最小化。因此,可以近似拆解為,和,這三個信息項的平衡可以構成雙邊圖結構噪聲問題的解決方案。
基于上述分析,我們提出了RGIB(Robust Graph Information Bottleneck),一個新的表征學習目標來平衡、兩方面的監督信息,即:
其中對的約束鼓勵更有信息量的表征以防止坍縮(),并限制其容量()以避免過擬合。另外兩個互信息項和,相互約束后驗信息以減輕雙邊噪聲對的負面影響。
需要注意的是,互信息項如通常是難以精確計算的。因此,我們基于不同的方法論,來給出兩種實際的RGIB實現,即RGIB-SSL和RGIB-REP。其中,RGIB-SSL通過自監督正則化顯式地優化表征,而RGIB-REP通過重參數化隱式地優化表征,詳細設計如下。
2.3 RGIB實例化
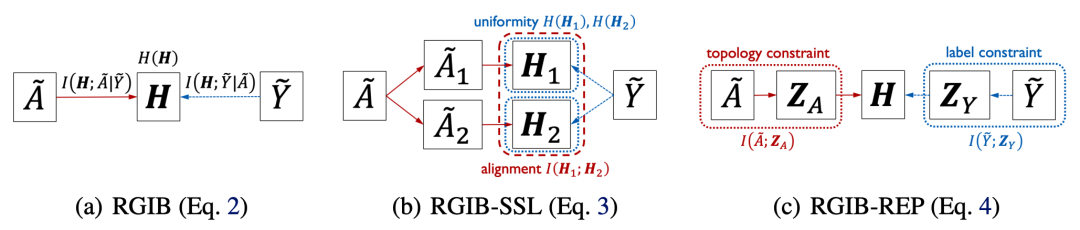
RGIB-SSL: 圖表征在監督學習范式下已經退化,自然地,我們將其修改為自監督學習的范式,通過uniformity項鼓勵表征提高信息量來緩解坍縮,并配合alignment項隱式地捕捉含噪變量之間的可靠關系(見圖6b),即:
其中用于平衡一個監督和兩個自監督正則化項,當時,RGIB-SSL可退化為基本的GIB。和是兩個增強圖和的表征。
RGIB-REP: 另一種實現方式是,通過重新參數化拓撲空間和標簽空間的信息,保留干凈的信息并丟棄噪聲部分。為此,我們通過構建隱變量,顯式地建模和的可靠性,以學習一個抗噪聲的(見圖6c),即:
其中,隱變量和是從含噪的和中提取的干凈信號。它們的補充部分和 被視為噪聲,滿足和。當和時,RGIB-REP可退化為基本的GIB。此外,測量了選擇樣本的監督信號,其中分類器以作為輸入而不是原始的,即。
更多技術細節請見正文。
3. 實驗結果
我們提供了多維度的實驗結果,以驗證和理解所提的RGIB方法。
3.1 主要性能對比
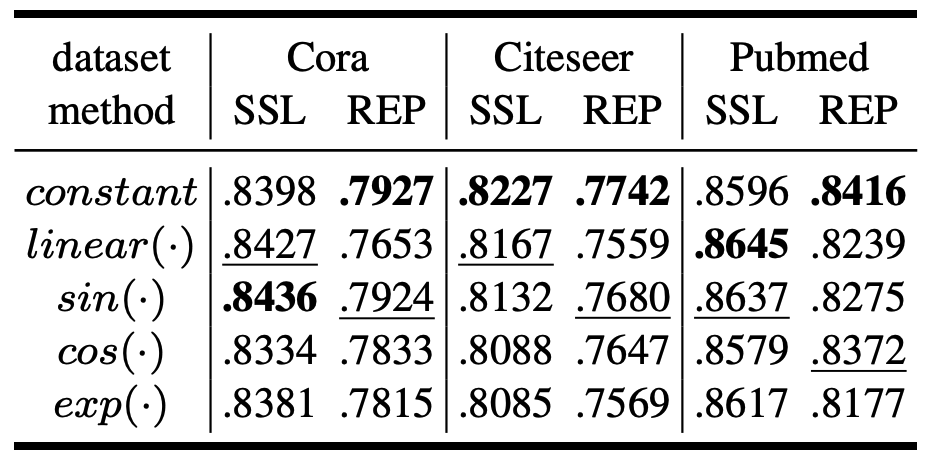
如表1所示,RGIB在所有6個數據集上,在不同噪聲比例下,都取得了最佳結果,特別是在Cora和Citeseer數據集上,與次佳方法相比,RGIB帶來的AUC提升達12.9%。
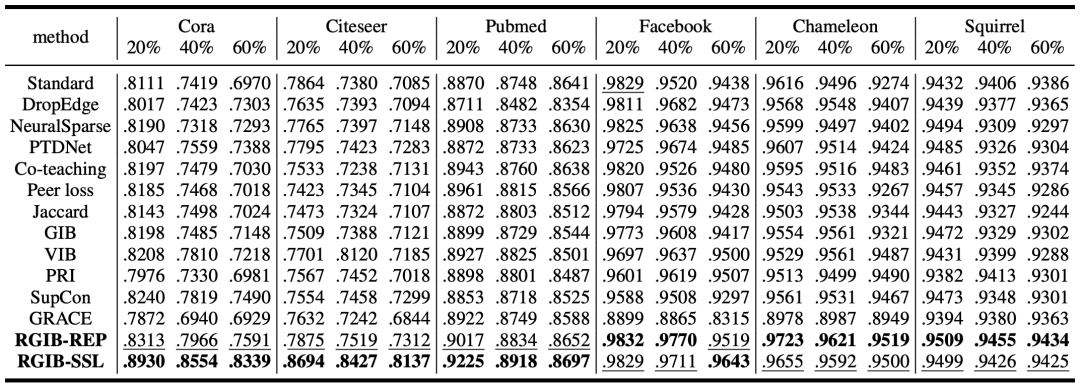
表2中展示了單邊噪聲的實驗結果。無論是針對單邊輸入噪聲還是標簽噪聲,RGIB仍然超越了所有的基準方法。實驗表明,雙邊圖結構噪聲可以通過統一的學習框架來建模和解決,而此前的去噪方法只能用于特定的噪聲模式。
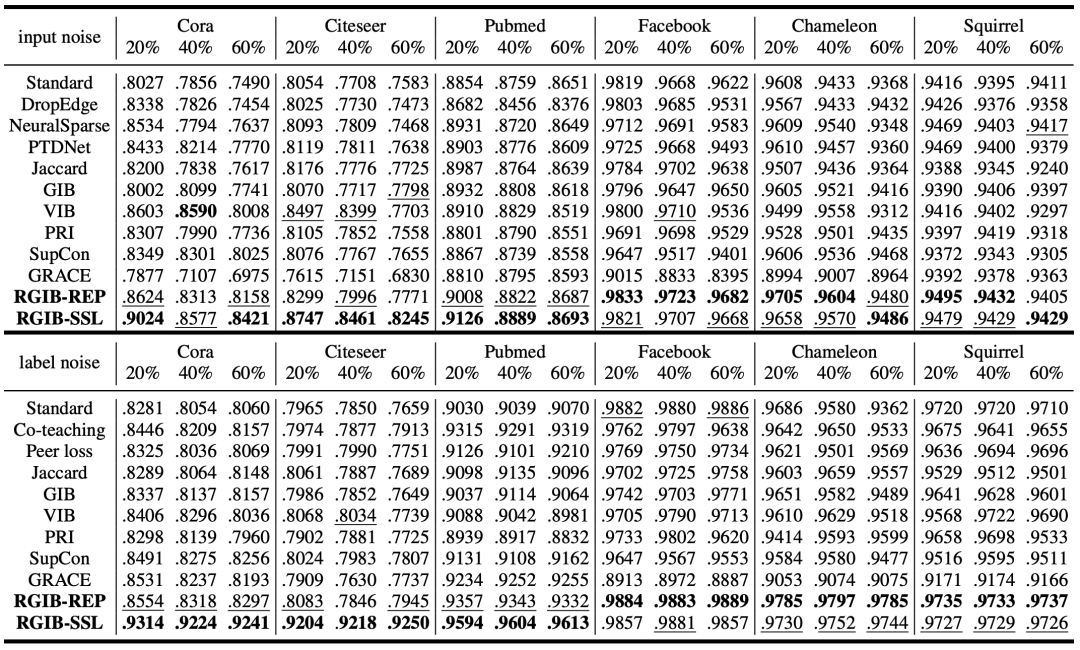
3.2 多方面的消融實驗及深入討論
我們進一步進行了諸多消融實驗,深入探討了所提方法在不同角度下的表現。
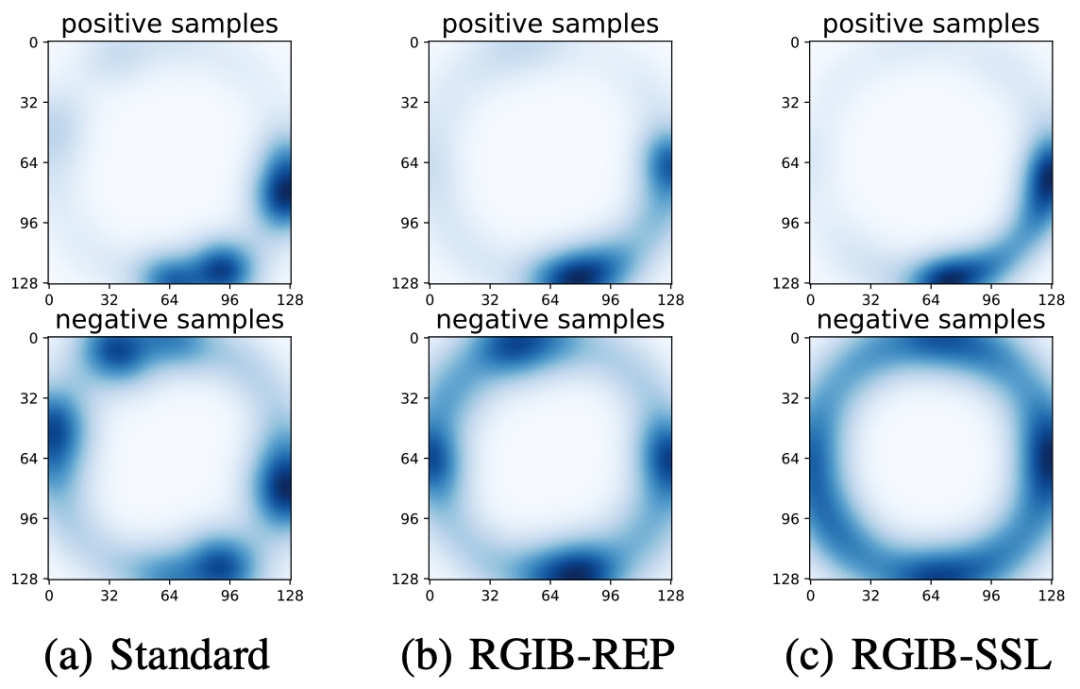
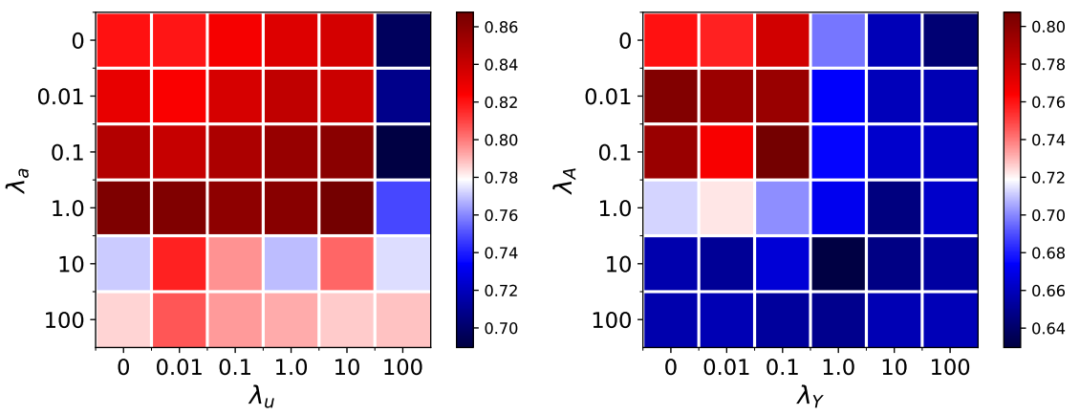

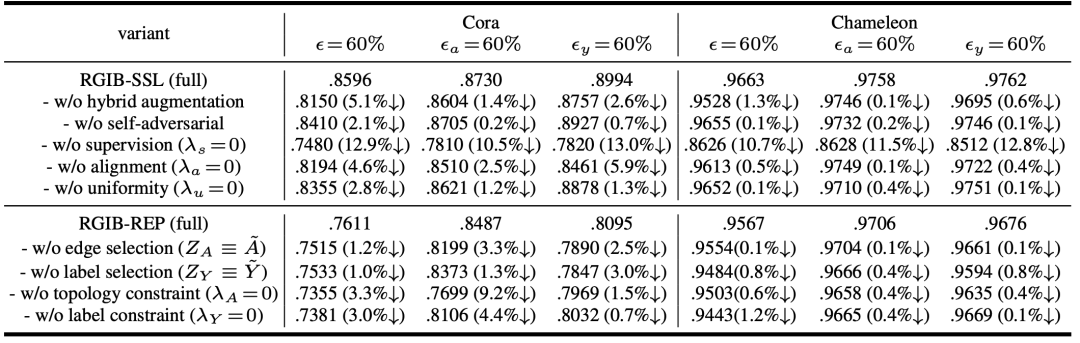
除此以外,我們提供了更多的可視化及相關實驗結果,感興趣的讀者請移步原文與附錄部分。
4. 算法落地
本文提出的RGIB-SSL方法,在展示外投業務中進行了算法落地。在該業務中,商家廣告被投放于全域互聯網媒體流量上。本技術通過在預訓練上對用戶廣告行為特征構圖并約束RGIB,增強了對點擊行為的預估魯棒性,從而提升精排階段點擊率預估的準確性,提升投放廣告的精準度與質量與在媒體流量出價上的準確度,使得大盤營收獲得約5%的提升。該技術全面應用于展示外投的幾乎所有媒體流量,覆蓋數十家媒體、近百個流量資源位和數億用戶。
5. 總結及展望
本文研究了帶有雙邊圖結構噪聲的鏈接預測問題,并發現在這種雙邊噪聲下,GNN學習得到的表征嚴重坍縮。基于這一觀察,我們引入了魯棒圖信息瓶頸原則RGIB,旨在通過解耦和平衡輸入、標簽和表征之間的互信息來提取可靠信號,以增強表征魯棒性并避免坍縮。展望未來,可將RGIB拓展至節點預測(Node Classification)、整圖預測(Graph Classification)即知識圖譜推理(Knowledge Graph Reasoning)等任務上。此外,正交于本文研究的結構噪聲(Structural Noise),圖節點特征上的噪聲(Feature Noise)同樣值得關注。
??參考文獻
[1] D. Liben-Nowell and J. Kleinberg. The link-prediction problem for social networks. Journal of the American society for information science and technology, 2007.
[2] M. Zhang and Y. Chen. Link prediction based on graph neural networks. In NeurIPS, 2018.
[3] B. Wu, J. Li, C. Hou, G. Fu, Y. Bian, L. Chen, and J. Huang. Recent advances in reliable deep graph learning: Adversarial attack, inherent noise, and distribution shift. arXiv, 2022.
[4] T. Wu, H. Ren, P. Li, and J. Leskovec. Graph information bottleneck. In NeurIPS, 2020.
[5] ?J. Yu, T. Xu, Y. Rong, Y. Bian, J. Huang, and R. He. Graph information bottleneck for subgraph recognition. arXiv, 2020
??團隊介紹
🏷 阿里媽媽展示外投團隊
阿里媽媽展示外投團隊是阿里媽媽核心廣告技術團隊之一,也是阿里媽媽業務增長最快的團隊。依托于集團龐大而真實的營銷場景,以AI技術驅動實現客戶商品營銷, 并承擔集團App用戶增長等業務需求。我們持續探索人工智能,聯邦學習,深度學習,強化學習,知識圖譜,圖學習等前沿技術在外投廣告和用增方面的落地應用。在創造業務價值的同時,團隊近幾年在ICML、NIPS、WWW、CIKM、SIGIR、KDD、NAACL等領域知名會議上發表過多篇論文。真誠歡迎對廣告算法、推薦系統、NLP等方向感興趣的同學加入我們, 一起成長!
???簡歷投遞郵箱:alimama_tech@service.alibaba.com
// 點擊↓閱讀原文,了解JD詳細詳情
🏷 香港浸會大學可信機器學習和推理組
香港浸會大學可信機器學習和推理課題組 (TMLR Group) 由多名青年教授、博士后研究員、博士生、訪問博士生和研究助理共同組成,課題組隸屬于理學院計算機系。課題組專攻可信表征學習、基于因果推理的可信學習、可信基礎模型等相關的算法,理論和系統設計以及在自然科學上的應用,具體研究方向和相關成果詳見本組Github (https://github.com/tmlr-group)。課題組由政府科研基金以及工業界科研基金資助,如香港研究資助局杰出青年學者計劃,國家自然科學基金面上項目和青年項目,以及國內外企業的科研基金。青年教授和資深研究員手把手帶,GPU計算資源充足,長期招收多名博士后研究員、博士生、研究助理和研究實習生。感興趣的同學請發送個人簡歷和初步研究計劃到郵箱 :bhanml@comp.hkbu.edu.hk。
🔍?本期話題:如何從優化的角度來解決數據噪聲呢?歡迎評論區留言討論~
END

也許你還想看
丨Memorization Discrepancy:利用模型動態信息發現累積性注毒攻擊
丨CBRL:面向ROI約束競價問題的課程引導貝葉斯強化學習框架
丨基于對抗梯度的探索模型及其在點擊預估中的應用
丨一種用于在線廣告自動競價的協作競爭多智能體框架
丨NAACL22 & SIGIR22 | 面向 CTR 的外投廣告動態創意優化實踐
關注「阿里媽媽技術」,了解更多~

喜歡要“分享”,好看要“點贊”哦?~
↓歡迎留言參與討論↓



)





之hwclock)







:為APP程序添加命令)

