題目一
此題用暴力枚舉做過(80分)現如今終于用二維前綴和做到滿分。

試題編號: 202309-2
試題名稱: 坐標變換(其二)
時間限制: 2.0s
內存限制: 512.0MB
問題描述:
問題描述

樣例輸入:
10 5
2 0.59
2 4.956
1 0.997
1 1.364
1 1.242
1 0.82
2 2.824
1 0.716
2 0.178
2 4.094
1 6 -953188 -946637
1 9 969538 848081
4 7 -114758 522223
1 9 -535079 601597
8 8 159430 -511187
樣例輸出
-1858706.758 -83259.993
-1261428.46 201113.678
-75099.123 -738950.159
-119179.897 -789457.532
114151.88 -366009.892
題目分析(個人理解)
- 其實對于二維數據的存儲和處理非常想用numpy的,但是考試的IOI機子不支持,只能用常規的二維列表存儲。
- 使用一個列表an[]存每一步操作之后的參數,由于對于一個坐標有兩種操作,一種拉伸一種旋轉,所以是個二維列表,第一維度表示查詢的序號。第二維度表示該查詢的具體內容(拉伸多少倍或旋轉多少度),因此第二維度的第一個元素用1初始化(表示拉伸,可直接乘拉伸倍數即可)第二個元素用0初始化(表示旋轉,只需要做加法加即可)。
- 注意規則,**i和j是開始查詢數到結束,經歷的操作是從i到j。有兩種思想,第一種暴力窮舉,每輸入一個要處理的坐標就進行一次遍歷,因此超時只能80分,第二種二維前綴和的思想,每輸入一行查詢操作就假想已經執行并且存入數組,這樣在后續執行的時候只需要切片即可,大大降低時間復雜度。
- 如何截取前綴和的一部分?不難發現對于拉伸倍數只需要用除法判斷從i到j進行每一步查詢之后總的拉伸倍數即可,對于旋轉,只需用末減初即可判斷最后到底拉伸了多少最后按照公式計算即可。
- 上代碼!!!
import mathn,m = map(int,input().split())#設置前綴積的初始化
an = []
an.append([1,0])for i in range(n):#存入執行每一步之后的拉伸和旋轉參數kind,act = input().split()if kind == '1':#如果是拉伸temp1 = an[i][0]*float(act)temp2 = an[i][1]an.append([temp1,temp2])else:#如果是旋轉temp2 = an[i][1]+float(act)temp1 = an[i][0]an.append([temp1, temp2])for v in range(m):#開始切片操作執行i,j,x,y = map(int,input().split())k = an[j][0] / an[i-1][0]#對于拉伸做除法c = an[j][1] - an[i-1][1]#對于旋轉做減法dx = k*(x*math.cos(c) - (y*math.sin(c)))dy = k*(x*math.sin(c) + (y*math.cos(c)))print("{:.3f} {:.3f}".format(dx,dy))題目二
【問題描述】給定一個N×M的矩陣A,請你統計有多少個子矩陣 (最小1×1,最大N×M) ,滿足子矩陣中所有數的和不超過給定的整數K?
【輸入格式】第一行包含三個整數N, M和K,之后N行每行包含M個整數,代表矩陣A
【樣例輸入】
3 4 10
1 2 3 4
5 6 7 8
9 10 11 12
【樣例輸出】
19
【評測用例規模與約定】
30%的數據,N, M≤20 5分
70%的數據,N, M≤100 10分
100%的數據,1≤N, M≤500 15分
0≤Ai j≤1000; 1≤K≤250000000
題目分析(個人理解)
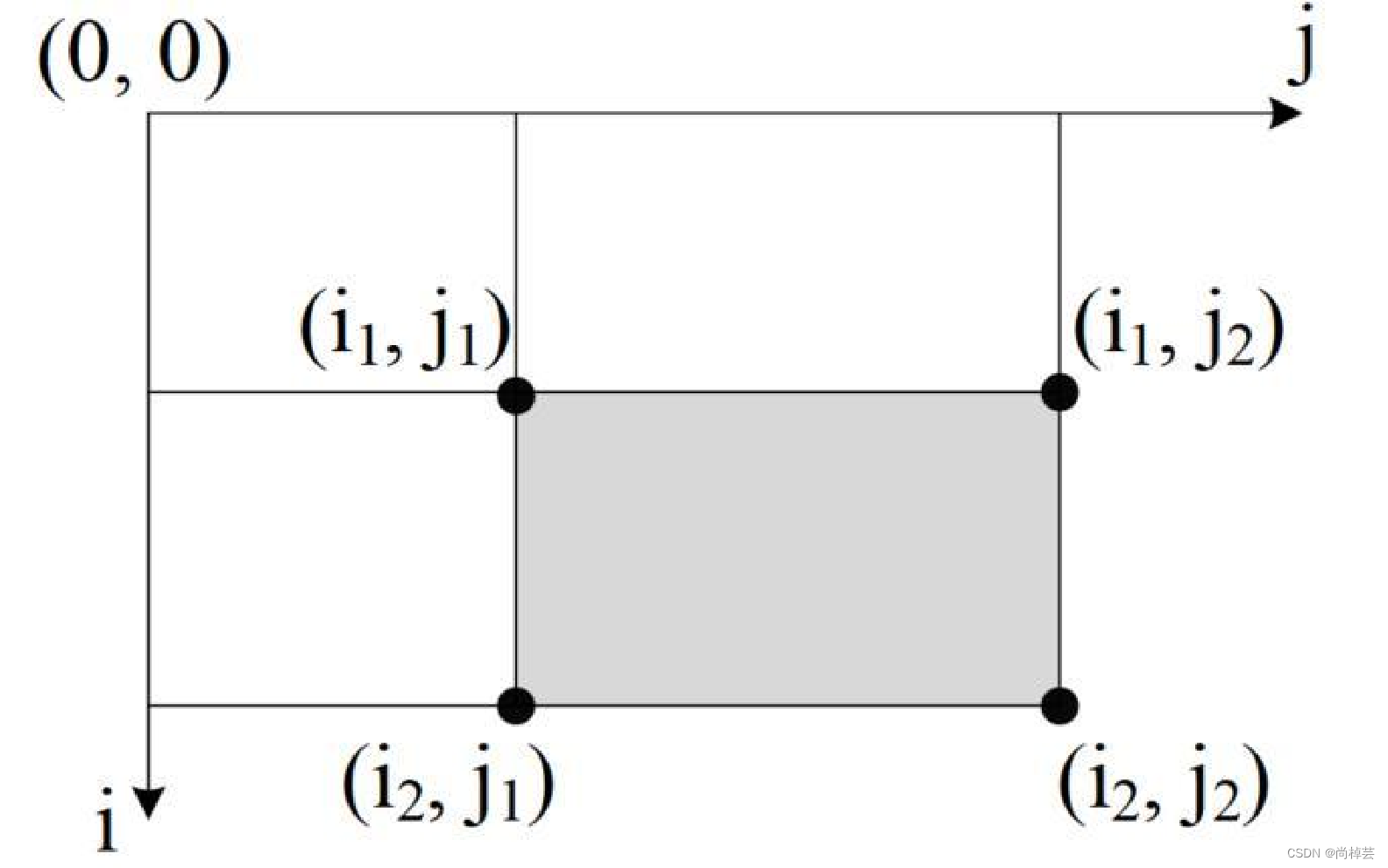
- “二維前綴和”,定義s[][]:
s[i][j]表示子矩陣[1, 1] ~ [i, j]的和
(1)預計算出s[][],然后快速計算二維子區間和:
(2)陰影子矩陣[i1, j1] ~ [i2, j2]區間和,等于:
s[i2][j2] - s[i2][j1-1] - s[i1-1][j2] + s[i1-1][j1-1]
其中s[i1-1][ j1-1]被減了2次,需要加回來1次 - 本題統計二維子矩陣和≤k的數量,而不用具體指出是哪些子矩陣,可以用尺取法優化。
以一維區間和為例,查詢有多少子區間[j1, j2]的區間和s[j2] - s[j1] ≤ k。

若s[j2] - s[j1] ≤ k,那么在子區間[j1, j2]上,有j2 - j1+1個子區間滿足≤ k。用同向掃描的尺取法,用滑動窗口[j1, j2]遍歷,復雜度降為O(n)。
對于二維,矩陣的行子區間和仍用2重暴力遍歷只把列區間和用尺取法優化。
3. 上代碼!!!
n, m, k = map(int, input().split())
a = [[0] for i in range(n)]
a.insert(0,[0]*(m+1))
for i in range(1,n+1): #從a[1][1]開始,讀矩陣a[i].extend(map(int, input().split()))
s = [[0]*(m+1) for i in range(n+1)]
for i in range(1,n+1):for j in range(1,m+1):s[i][j] = s[i-1][j] + a[i][j]
ans = 0
for i1 in range(1,n+1):for i2 in range(i1,n+1):j1=1; z=0for j2 in range(1,m+1):z += s[i2][j2]-s[i1-1][j2] while z>k: z -= s[i2][j1]-s[i1-1][j1]j1 += 1 ans += j2-j1+1
print(ans)
總結











)






)


