目錄
https://blog.csdn.net/m0_49956154/article/details/134320307?spm=1001.2014.3001.5501
1經典傳統數倉架構
2離線大數據數倉架構
3數據倉庫三層
數據運營層,源數據層(ODS)(Operational Data Store)
數據倉庫層(DW)(Data Warehouse)
數據應用層ADS(Application Data Service)?
事實表(Fact Table)
維表層(Dimension)
4數據倉庫和數據庫的區別(t數據庫,a倉庫)
?5.關系模型(ER模型+三范式)
E-R模型(Entity-relationship model)
5.1.三范式
概述:
一、3NF知識點
5.2反范式化
?概述
補充之前的 :2023.11-9 hive數據倉庫,概念,架構,元數據管理模式
https://blog.csdn.net/m0_49956154/article/details/134320307?spm=1001.2014.3001.5501
1經典傳統數倉架構
階段一: 1991年 比爾-恩門(bill inmon)出版第一版數據倉庫的書, 標志數據倉庫概念的確立, 稱為恩門模型
?? ?主張自上而下的建設企業級數據倉庫, 建設過程中需要滿足三范式要求
?? ?從分散異構的數據源 -> 數據倉庫 -> 數據集市
?? ?
?? ?存在問題:?
?? ??? ?由于三范式的建模,導致在數據分析中數據易訪問性和系統的性能均收到影響
階段二: 拉爾夫·金博爾(ralph kimball)提出自下而上的建立數據倉庫,整個過程中信息存儲采用維度建模而非三范式
?? ?從數據集市-> 數據倉庫 -> 分散異構的數據源
?? ?
?? ?優點:?
?? ??? ?提出了維度建模新思路, 完全以數據分析便利性為前提建設, 推出了事實-維度模型
?? ??? ?以最終任務為導向, 需要什么, 我們就建立什么
?? ?
?? ?弊端:
?? ??? ?隨著業務的發展, 導致數據集市越來越多, 出現多個數據集的數據混亂和不一致的情況
階段三: 1998年比爾-恩門(bill inmon)推出全新的CIF架構, 核心將數倉架構劃分為不同的層次以滿足不同場景的需求
?? ?如: ODS ?DW ?DA層等
?? ?
?? ?從而明確各個層次的任務分工, 避免原有數據混亂和不一致的問題
?? ?
?? ?而這種思想已經成為截止到今天的建設數據倉庫的指南
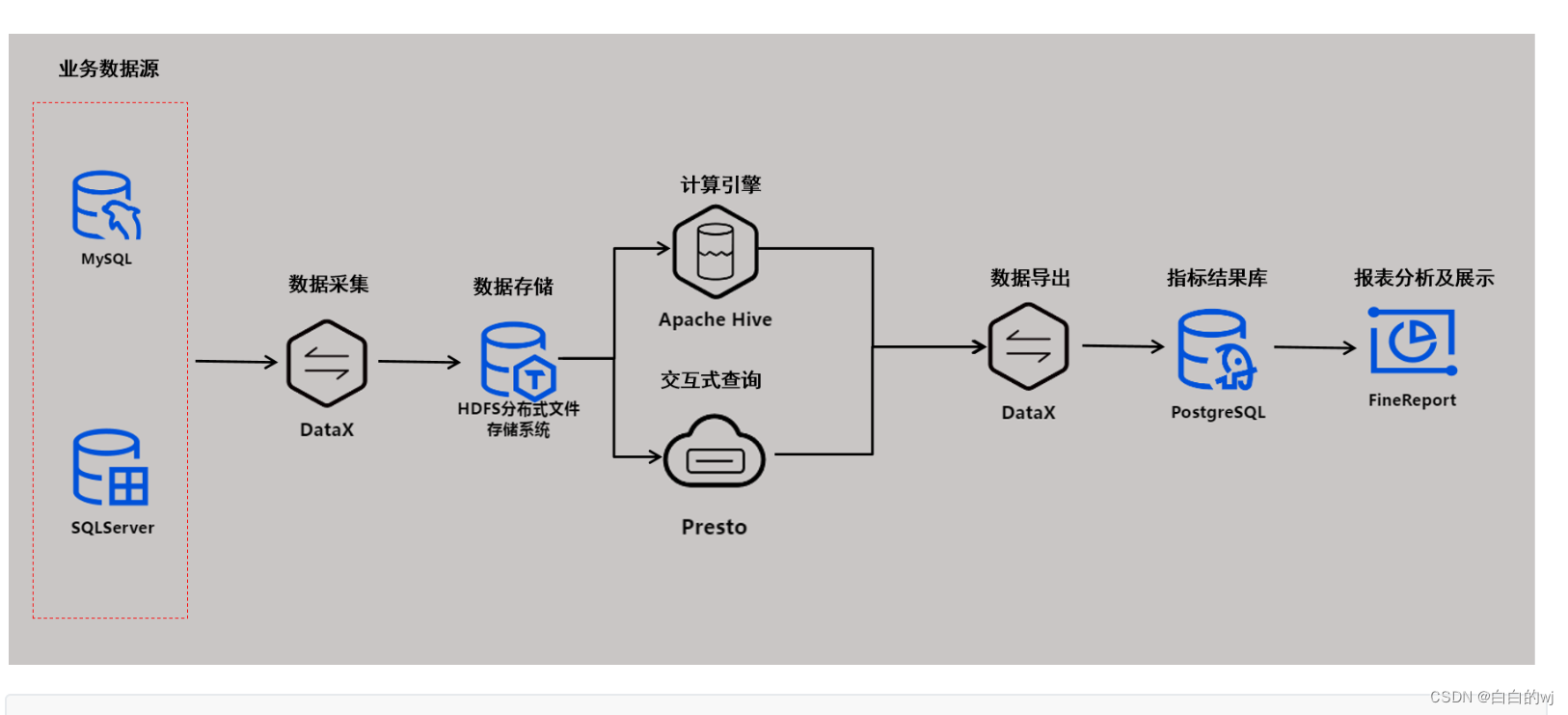
2離線大數據數倉架構
?? ?大數據中的數據倉庫構建就是基于經典數倉架構而來,使用大數據中的工具來替代經典數倉中的傳統工具,架構建設上沒有根本區別
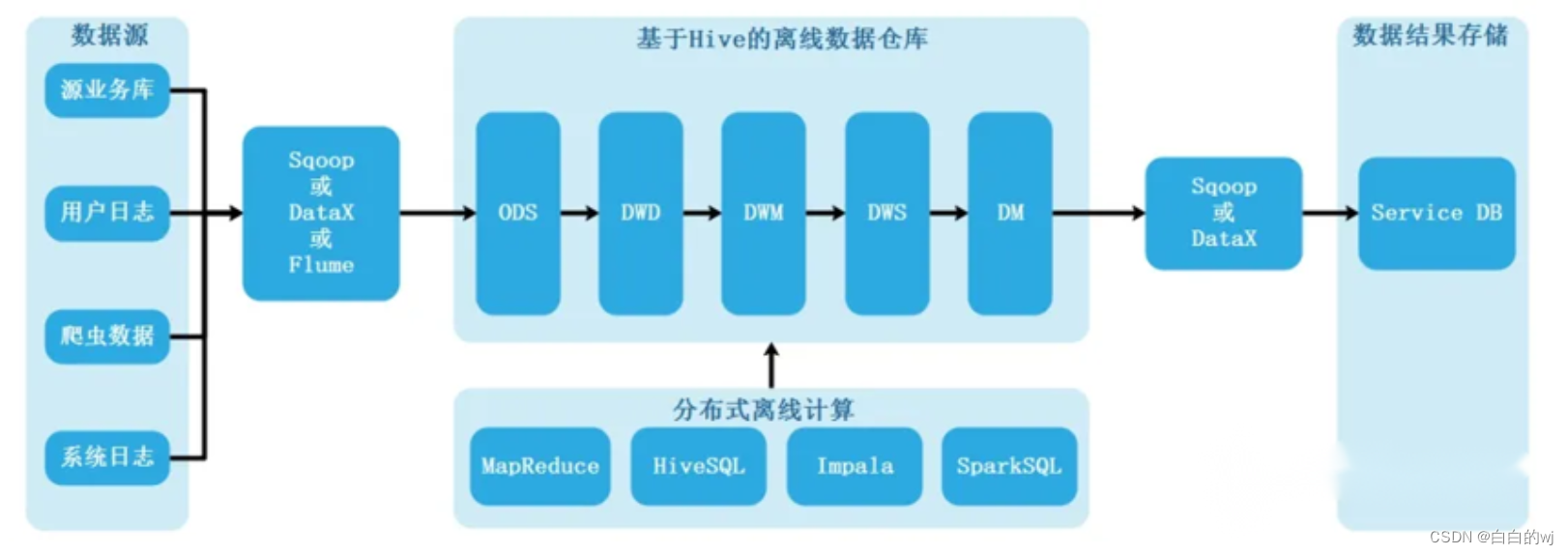
?項目架構圖
?集群管理工具: Cloudera Manager
數據源: 業務系統的Mysql與SQLServer數據庫;?
數據抽取: 使用DataX實現關系型數據庫和大數據集群的雙向同步;?
數據存儲: HDFS?
計算引擎: Hive
交互查詢引擎: Presto
OLAP: PG
數據可視化: Fine Report
調度系統: DolphinScheduler(海豚調度)
3數據倉庫三層,四大特性
1- 面向主題: ?分析什么 ?什么就是我們的主題
2- 集成性: 數據從各個數據源匯聚而來, 數據的結構都不一定一樣
3- 非易失性(穩定性): 存儲都是過去歷史的數據, 不會發送變更, 甚至某些數據倉庫都不支持修改操作
4- 時變性: 隨著時間推移, 將最近發生的數據也需要放置到數據倉庫中, 同時分析的方案也無法滿足當前需求, 需要變更分析的手段
?
數據運營層,源數據層(ODS)(Operational Data Store)
數據運營層ODS(Operation Data Store) -也就是最接近數據源的一層,直接對接的數據源(如:業務庫、埋點日志、消息隊列等)。ODS數數倉的最底層。
該層是存儲數量最大的、未經過太多處理的、最原數據始的一層。該層還起到一個數據備份的作用,比如特殊的行業,一般ODS層需要存儲一年甚至多年,不過普通公司一般存儲三個月到六個月。
一般情況下,在數據進入ODS層的時候,都會對數據做一些最基本的處理。例如:
- 數據來源分區
- 數據按照時間分區存儲,一般按照天分區,也有一些公司按照年、月、日三級分區存儲
- 進行最基本的數據處理,如格式錯誤的丟棄、過濾掉關鍵信息丟失的數據。
注意:一般公司也會把以上的基本處理放到DWM層來進行。
數據倉庫層(DW)(Data Warehouse)
DWD(Data WareHouse Detail) -數據細節層。該層與ODS層保持相同的數據顆粒度,區別在于,改成主要是對ODS層進行數據的清洗和規范化操作,比如說去除空數據、臟數據等。該層由于對數據處理的粒度比較細,一般情況下都是編寫代碼實現的。很多時候存儲的是事實表、維度表和實體表。DWM(Data WareHouse Middle) -數據中間層。該層主要是對DWD層做一些輕微的聚合操作,生成一些指標列的聚合結果表。DWS(Data WareHouse Service) -數據服務層。該層是在DWM層基礎之上,整合匯總成一個主題域的數據服務層,一般是寬表(具有多個列的表),該層為后續的業務查詢、OLAP分析和數據分發提供支撐。
數據應用層ADS(Application Data Service)?
數據應用層ADS(Application Data Service) -該層主要為數據產品和數據分析提供數據支撐。一般會存放在ES、MySQL、Redis等數據庫系統中,為應用系統提供數據,也可以存放在hive或者Druid中,供數據分析與數據挖掘使用,比如數據報表就是存在該層中。
事實表(Fact Table)
事實表是指存儲有事實記錄的表,比如系統日志、銷售記錄等。事實表的記錄在不斷地增長,比如電商的商品訂單表,就是類似的情況,所以事實表的體積通常是遠大于其他表。
維表層(Dimension)
維度表(Dimension Table)或維表,有時也稱查找表(Lookup Table),是與事實表相對應的一種表;它保存了維度的屬性值,可以跟事實表做關聯,相當于將事實表上經常重復出現的屬性抽取、規范出來用一張表進行管理。
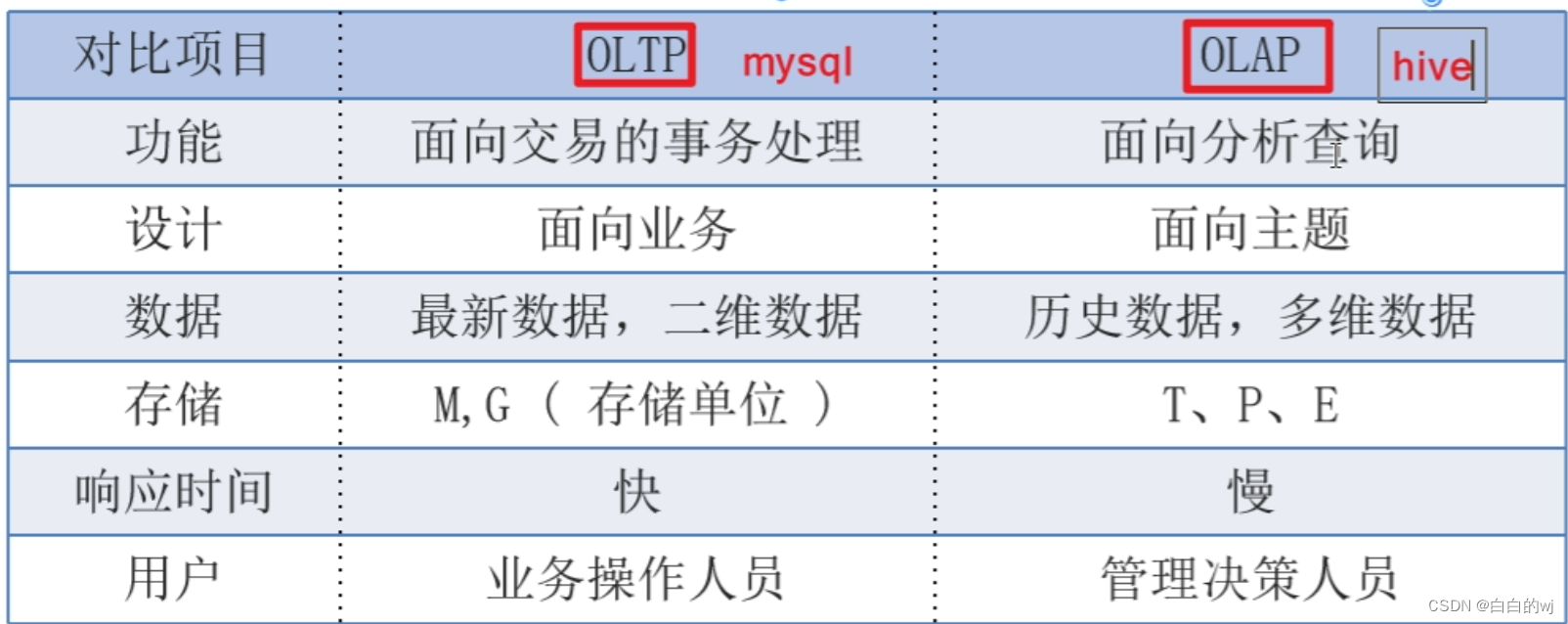
4數據倉庫和數據庫的區別(t數據庫,a倉庫)
數據庫與數據倉庫的區別:實際講的是OLTP與OLAP的區別
OLTP(On-Line Transaction Processin):叫聯機事務處理,也可以稱面向用戶交易的處理系統, ?主要面向用戶進行增刪改查
OLAP(On-Line Analytical Processing):叫聯機分析處理,一般針對某些主題的歷史數據進行分析 主要面向分析,支持管理決策。
數據倉庫主要特征:面向主題的(Subject-Oriented )、集成的(Integrated)、非易失的(Non-Volatile)和時變的(Time-Variant)
數據倉庫的出現,并不是要取代數據庫,主要區別如下:
- ? ? 數據庫是面向事務的設計,數據倉庫是面向主題設計的。
- ? ? 數據庫是為捕獲數據而設計,數據倉庫是為分析數據而設計
- ?? ?數據庫一般存儲業務數據,數據倉庫存儲的一般是歷史數據。
- ? ? 數據庫設計是盡量避免冗余,一般針對某一業務應用進行設計,比如一張簡單的User表,記錄用戶名、密碼等簡單數據即可,符合業務應用,但是不符合分析。
- ?? ?數據倉庫在設計是有意引入冗余,依照分析需求,分析維度、分析指標進行設計。
?5.關系模型(ER模型+三范式)
E-R模型(Entity-relationship model)
表示:
實體: 用矩形框表示。
屬性: 實體的屬性用橢圓框表示。
聯系:實體間的聯系用菱形框表示,并在連線上標明聯系的類型,即1—1、1—n或m—n。
兩個實體之間的聯系
一對一(1:1):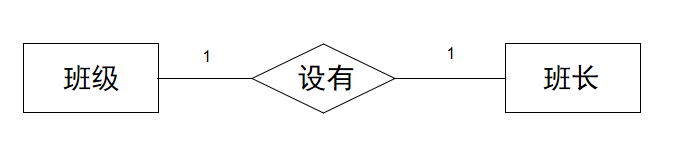
一對多(1:n)
多對多(m:n)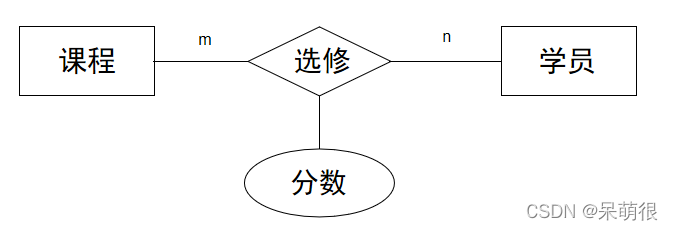
5.1.三范式
概述:
在關系型數據庫中,關于數據表設計的基本原則,規則就稱為范式。可以理解為,一張數據表的設計結構需要滿足的某種設計標準的級別。想要設計一個結構合理的關系型數據庫,必須滿足一定的范式(規則)。
范式的英文名稱是Normal Form,簡稱NF。它是英國人E.F.codd(埃德加·弗蘭克·科德)在上個世紀70年代提出關系數據庫模型后總結出來的。范式是關系數據庫理論的基礎,也是我們在設計數據庫結構過程中所要遵循的規則和指導方法。
1981年,科德因在關系型數據庫方面的貢獻獲得了圖靈獎。他也被譽為:“關系數據庫之父”
3NF知識點
設計關系數據庫時,遵從不同的規范要求,設計出合理的關系型數據庫,這些不同的規范要求被稱為不同的范式,各種范式呈遞次規范,越高的范式數據庫冗余越小。
根據數據庫冗余的大小,目前關系型數據庫有六種范式,各種范式呈遞次規范,越高的范式數據庫冗余越小。注意: 范式就是設計數據庫的通用規范,一般遵循前三種范式即可
第一范式(1NF)
第二范式(2NF)
第三范式(3NF)
巴斯-科德范式(BCNF)
第四范式 ( 4NF)
第五范式(5NF,又稱完美范式)
第一范式(1NF): 強調的是列的原子性,即列不能夠再分成其他幾列,不可再分解;。
第二范式(2NF): 滿足 1NF的基礎上,另外包含兩部分內容,要求記錄有惟一標識,即實體的惟一性
一是表必須有一個主鍵;
二是非主鍵字段必須間接或直接的依賴于主鍵
第三范式(3NF): 滿足 2NF的基礎上,3NF是對字段冗余性的約束,即任何字段不能由其他字段派生出來,它要求字段沒有冗余。另外包含
非主鍵列必須直接依賴于主鍵,不能存在傳遞依賴。
即不能存在:非主鍵列 A 依賴于非主鍵列 B,非主鍵列 B 依賴于主鍵的情況。
5.2反范式化
?概述
有的時候不能簡單按照規范要求設計數據表,因為有的數據看似冗余,其實對業務來說十分重要。這個時候,我們就要遵循業務優先的原則,首先滿足業務需求,再盡量減少冗余。
如果數據庫中的數據量比較大,系統的UV和PV訪問頻次比較高,則完全按照MySQL的三大范式設計數據表,讀數據時產生大量的關聯查詢,在一定程度上會影響數據庫的讀性能。如果我們想對查詢效率進行優化,反范式優化也是一種優化思路。此時,可以通過在數據表中增加冗余字段來提高數據庫的讀性能。
















真題解析)

)
)