1. 行業背景
1.1 電商發展歷史
電商1.0: 初創階段20世紀90年代,電商行業剛剛興起,主要以B2C模式為主,如亞馬遜、eBay等 ? 電商2.0: 發展階段21世紀初,電商行業進入了快速發展階段,出現了淘寶、京東等大型電商平臺,同時也出現了C2C模式和O2O模式 ? 電商3.0: 成熟階段2010年代,電商行業進入了成熟階段,各大電商平臺開始加強自身的品牌建設和服務體系,同時也出現了跨境電商、社交電商、農村電商等新興模式。 ? 電商4.0: 新零售階段2016年以后,電商行業進入了電商階段,以阿里巴巴、京東等為代表的電商巨頭開始布局線下實體店,實現線上線下的無縫銜接,推動電商行業向更高層次發展。
1.2 什么是電商4.0
電商4.0其實就是新零售階段, 主要由三部分組成: 線上服務、線下體驗、新物流
線上服務:線上服務指的是通過互聯網平臺提供的購物、支付、物流等服務 ? 線下體驗:線下體驗則是指在實體店鋪中提供的商品展示、試穿試用、售后服務等體驗 ? 新物流:新物流則是指通過物流技術和網絡優化提高物流效率和服務質量
1.3 電商企業類型
-
1- 電商服務商
-
2- 貨架、售貨機
-
3- 無人便利店
-
4- 線上線下實體店
-
5- 生鮮、果蔬平臺
1.4 生鮮電商行業概述
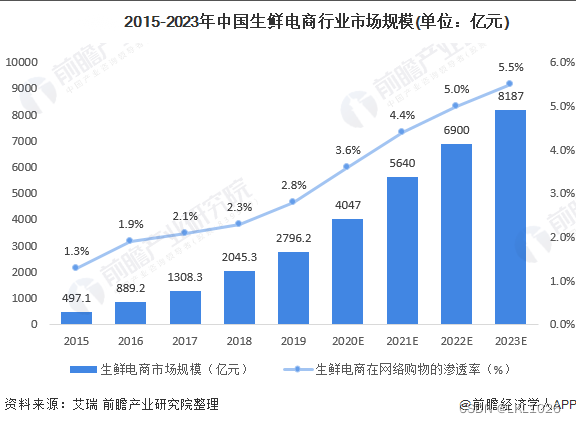
生鮮產品具有高頻剛需的特點, 是具有即時性需求, 目前在線下占比要遠高于線上, 未來線上生鮮銷售將會是龐大的市場

各大頭部企業也可以著手布局生鮮市場
1.5 生鮮電商行業發展趨勢
隨著消費者網購生鮮習慣逐漸養成, 以及目前直播帶貨等多重作用下, 生鮮市場線上滲透率將不斷提高
2. 項目業務流程與需求說明
2.1 公司介紹
黑馬甄選與2016年7月成立, 發展至今經過6年時間, 門店遍布全國30多個城市, 超過1300家門店
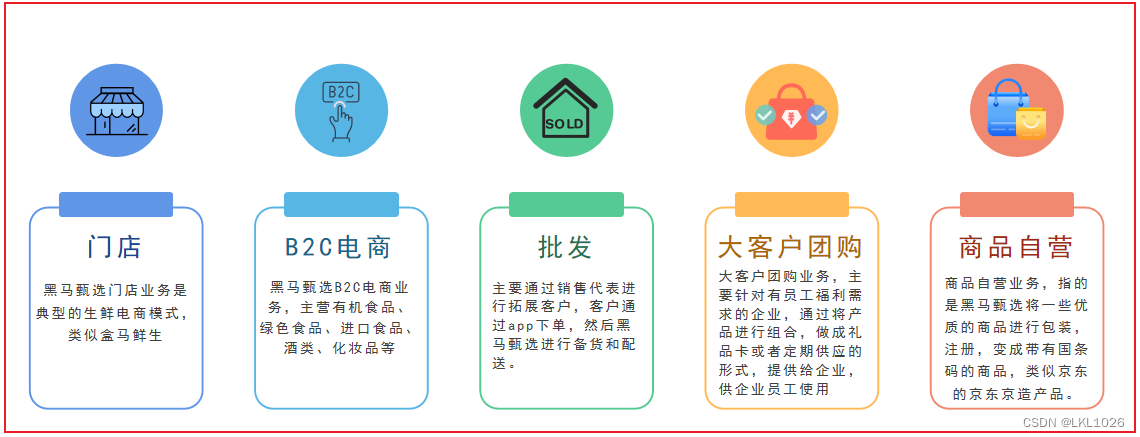
目前主營業務線有五條: ==門店 B2C電商 批發 大客戶團購 商品自營==
2.2 業務介紹
2.3 項目背景
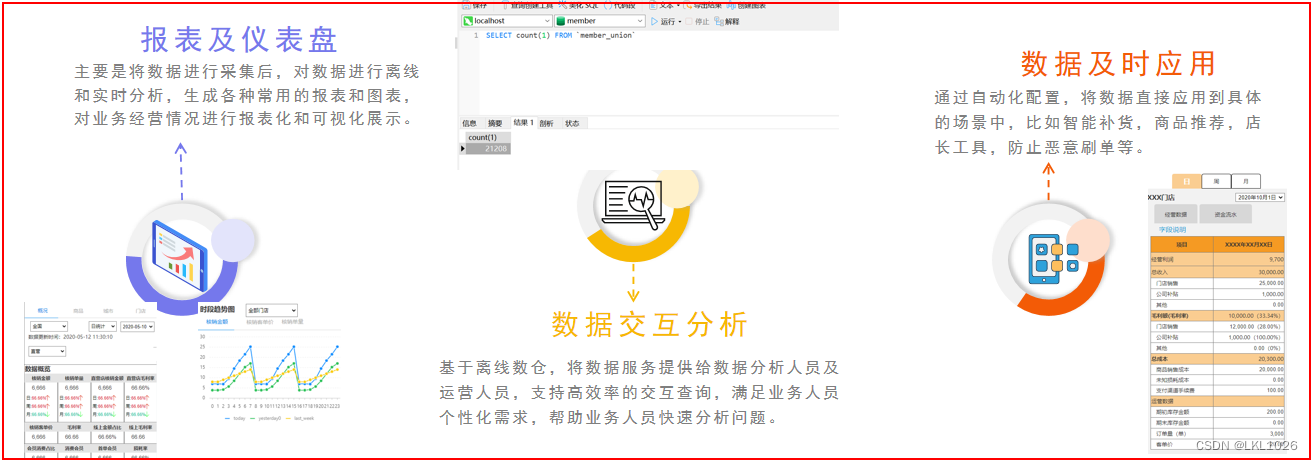
隨著生鮮電商行業的迅速發展,公司累計了大量數據。為了從已有的數據中挖掘出有價值的信息,搭建了黑馬甄選大數據處理平臺。主要對各業務線的數據進行分析,從而便于精細化管理,最終提高用戶數量及活躍度,提高商品銷量,降低運營成本。
2.4 需求說明
==本次項目共計有四大需求: 銷售需求 會員需求 供應鏈需求 商城需求==
-
銷售需求:
劃分為線上銷售流程和線下銷售流程,業務部門需要全面分析線上線下的銷售情況,包括銷售、取消、退款的金額、成本、單量、SKU以及活動的情況。
-
會員需求:
因為黑馬甄選是生鮮電商業務,包括線上和線下,所以會員也分為線上會員和線下會員。 主要統計會員的注冊、消費、充值、余額情況。注意線上會員也可以在線下消費,使用相同的手機號即可。
-
供應鏈需求
劃為為要貨到貨流程與商品劃撥流程 ? 為精細化運營,業務部門嚴格管控供應鏈,要求計算:庫存的數量、金額、SKU、周轉、動銷、損耗數量和金額、盤點差異以及要貨、收貨、配送、退貨、退配、調入、調出、系統調整的數量和金額。
-
商城需求
商城需求指的是對商城的訪問日志進行分析,主要是流量數據和交易數據。如何評價線上平臺的好壞,UV/PV/新訪客數量/跳出數/瀏覽時長等都是非常重要的指標
3. 項目架構詳解
3.1 離線數倉架構方案
-
經典傳統數倉架構
階段一: 1991年 比爾-恩門(bill inmon)出版第一版數據倉庫的書, 標志數據倉庫概念的確立, 稱為恩門模型主張自上而下的建設企業級數據倉庫, 建設過程中需要滿足三范式要求從分散異構的數據源 -> 數據倉庫 -> 數據集市存在問題: 由于三范式的建模,導致在數據分析中數據易訪問性和系統的性能均收到影響 ? 階段二: 拉爾夫·金博爾(ralph kimball)提出自下而上的建立數據倉庫,整個過程中信息存儲采用維度建模而非三范式從數據集市-> 數據倉庫 -> 分散異構的數據源優點: 提出了維度建模新思路, 完全以數據分析便利性為前提建設, 推出了事實-維度模型以最終任務為導向, 需要什么, 我們就建立什么弊端:隨著業務的發展, 導致數據集市越來越多, 出現多個數據集的數據混亂和不一致的情況 ? 階段三: 1998年比爾-恩門(bill inmon)推出全新的CIF架構, 核心將數倉架構劃分為不同的層次以滿足不同場景的需求如: ODS DW DA層等從而明確各個層次的任務分工, 避免原有數據混亂和不一致的問題而這種思想已經成為截止到今天的建設數據倉庫的指南
-
離線大數據數倉架構
大數據中的數據倉庫構建就是基于經典數倉架構而來,使用大數據中的工具來替代經典數倉中的傳統工具,架構建設上沒有根本區別
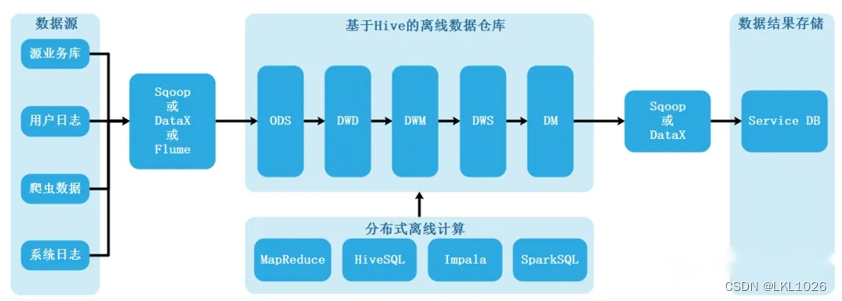
3.2 項目架構圖

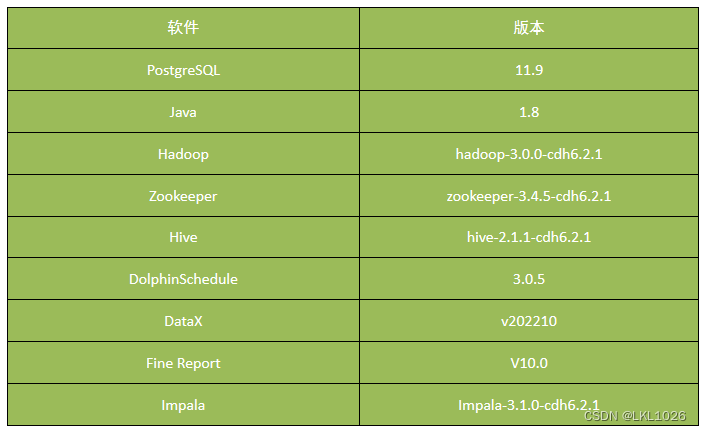
集群管理工具: Cloudera Manager 數據源: 業務系統的Mysql與SQLServer數據庫; 數據抽取: 使用DataX實現關系型數據庫和大數據集群的雙向同步; 數據存儲: HDFS 計算引擎: Hive 交互查詢引擎: Presto OLAP: PG 數據可視化: Fine Report 調度系統: DolphinScheduler(海豚調度)
面試中: 你能否講一下這個項目的基本介紹呢? 你們這個項目的架構大概是再怎么樣?
項目介紹: 給誰做的項目 是一個什么項目 項目的簡單的背景 項目最終成果 (簡歷中, 項目介紹部分要體現的內容)項目架構: 技術架構: 本次項目主要涉及了那些組件數據流向: 數據從哪來 --> 到哪去 + 各個組件起到了什么作用本次項目中主要負責的點:后期學到了去整理自己擅長你可以帶著面試官走, 讓他一直聽你說, 他只需要回復 yes
小作業: 完成架構圖的梳理(自己制圖) –> 講解項目介紹和項目架構
11.21號晚: 與各位組長
11.22號晚上: 各組自行安排
3.3 人員規劃
開發人員:10個人職責劃分:經理(1個人)(甲方:技術經理、乙方:項目經理)產品(1個人)大數據開發(4個人)運維(1個人)(DBA/集群搭建與維護/安全等工作)測試(1個人)前端(1個人)Java工程師(1個人)
3.4 開發周期
總周期: 八個月左右 階段劃分:需求調研、評審(7周)設計架構(2周)需求開發(16周)集成測試(3周)上線部署,試運行,調優(4周)
3.5 項目服務器架構選型
3.5.1 Hadoop發行版本選型
最終選擇: CDH平臺
兼容性 穩定性 強大的管理平臺 基礎功能免費
3.5.2 服務器的選型
本次項目中主要以物理機方案
考慮點:1- 機器成本考慮: 物理機: 以128G內存,20核物理CPU,40線程,8THDD和2TSSD硬盤,單臺報價4W出頭,需考慮托管服務器費用。一般物理機壽命5年左右, 平均每年 8k云主機: 以阿里云為例,差不多相同配置,每年5W2- 運維成本考慮物理機: 需要有專業的運維人員云主機: 很多運維工作都由阿里云已經完成,運維相對較輕松物理機運維成本更高從長遠考慮, 隨著運維人員的減少, 成本逐步降低, 而云主機成本, 隨著依賴程度越高, 成本也會逐步提升, 并且本地物理機數據安全性更高
3.5.3 集群數據規模
業務情況說明:
用戶量:1000W 日活:線上80W + 線下45W(線下只統計購買人數) 門店數量:1300家 門店日均單量:線上100單 + 線下350單 日均營業額:線上5000元 + 線下10000元
每日增量數據:
業務數據: 平均每條訂單及其相關表(訂單、人員、支付、物流、庫存等等)的存儲量:20K 20K * 58W = 11g日志數據: 每條數據0.5k-1.5k,平均1k,平均每人產生30條日志 1k * 80w * 30條 = 23g
規模計算(了解)
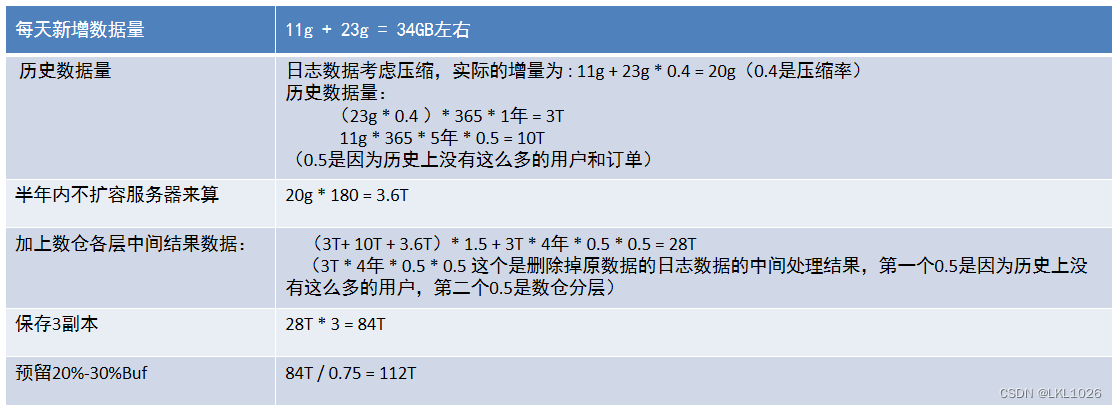
知道最終需要112TB空間
服務器規劃:
所以存儲+計算服務器需要大概11臺(晚上跑批任務,白天進行數據清洗以及查詢、交互分析), 因為有Presto基于內存的計算任務,所以計算節點需要再加5臺, 另外加上管理服務器3臺, 測試服務器3臺, 總共需要22臺。
3.5.4 項目服務器架構選型
3.5.5 測試服務器規劃
因服務器資源有限,考慮到大部分學員電腦性能配置不高,該項目采用二臺服務器進行演示學習,服務器配置如下:

各軟件安裝節點說明:

注意:
打開虛擬機-> 選擇我已移動
用戶名: root
密碼: 123456
4. 項目環境部署
4.1 CM介紹與架構
cloudera manager 是一款大數據的統一監控管理平臺, 此平臺主要是對cloudera公司旗下CDH版本軟件進行管理工作, 提供的服務: 統一的監控, 自動化部署, 對CDH軟件進行相關管理
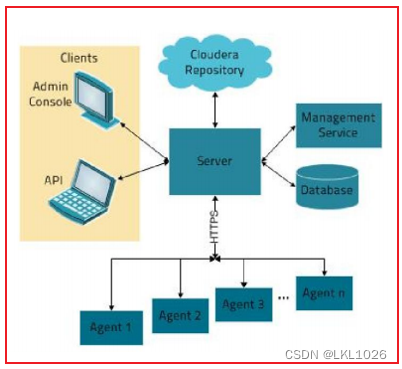
Server:Cloudera Manager的核心是Cloudera Manager Server。提供了統一的UI和API方便用戶和集群上的CDH以及其它服務進行交互,能夠安裝配置CDH和其相關的服務軟件,啟動停止服務,維護集群中各個節點服務器以及上面運行的進程。 Agent:安裝在每臺主機上的代理服務。它負責啟動和停止進程,解壓縮配置,觸發安裝和監控主機 Management Service:執行各種監控、報警和報告功能的一組角色的服務 Database:CM自身使用的數據庫,存儲配置和監控信息 Cloudera Repository:云端存儲庫,提供可供Cloudera Manager分配的軟件 Client:用于與服務器進行交互的接口1) Admin Console:管理員可視化控制臺2) API:開發人員使用API可以創建自定義的Cloudera Manager應用程序
CM的web頁面
鏈接: http://hadoop01:7180/cmf/home 用戶名: admin 密碼: admin
4.2 部署項目環境
此部分大家可直接參考<<00黑馬甄選離線大數據平臺項目環境部署文檔>>即可
4.3啟動環境
先配置本地映射
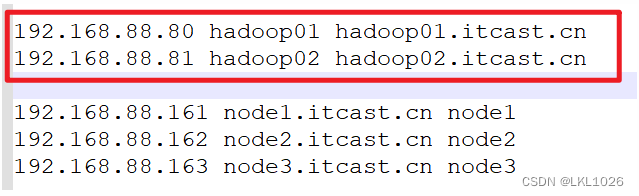
進入C:\Windows\System32\drivers\etc目錄,把以下內容復制粘貼到hosts文件內
192.168.88.80 hadoop01 hadoop01.itcast.cn 192.168.88.81 hadoop02 hadoop02.itcast.cn
配置虛擬機內存
演示16g內存情況
設置hadoop01內存10g
設置hadoop02內存4g
大于16g的同學,根據實際情況隨時調整即可
啟動并連接CM
先依次啟動hadoop01,hadoop02虛擬機,然后復制以下CM鏈接到瀏覽器,進入CM管理頁面
CM頁面鏈接: http://hadoop01:7180/cmf/home 用戶名: admin 密碼: admin
點擊主機查看內存使用情況:

注意:
如果內存不夠用的同學,建議Cloudera Management Service里面的4個服務都關閉
關閉CM4個服務后,頁面如下:
4.4設置交換內存
參考筆記中的 Linux中虛擬內存的配置?文檔

5.業務數據介紹與準備
項目涉及核心業務表:
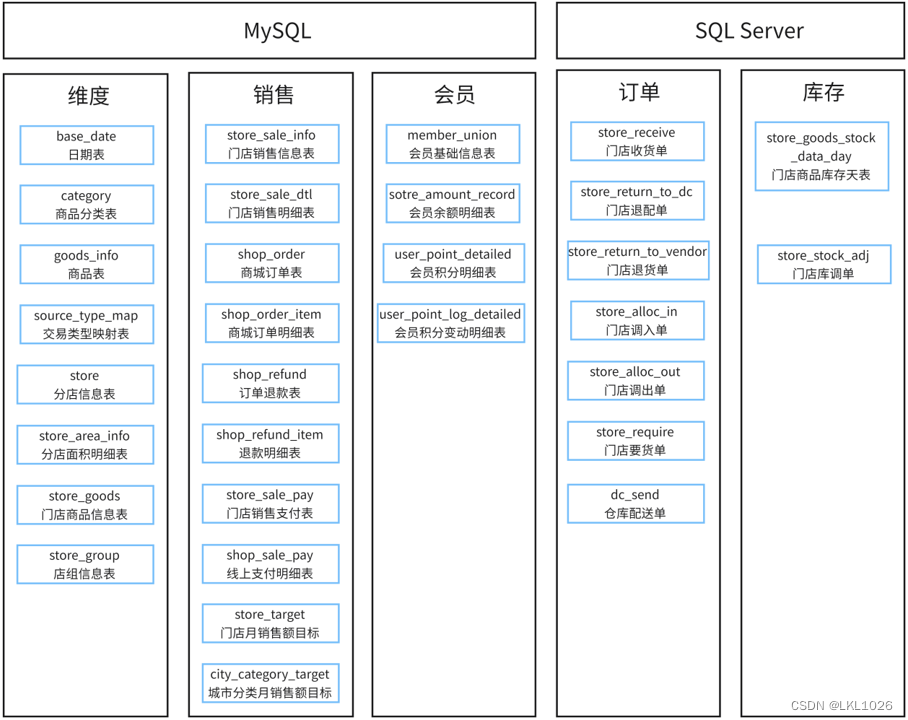
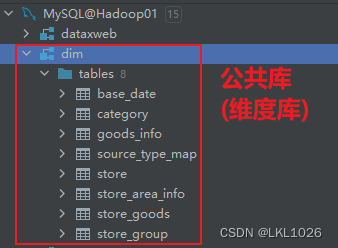
項目一共有有31張表,其中包含8張維度表,23張業務核心表。其中訂單表和庫存表存儲在SQL Server中,其他表存儲在MySQL中。
導入業務到指定的數據庫中(此操作在實際工作中不存在):
連接數據庫
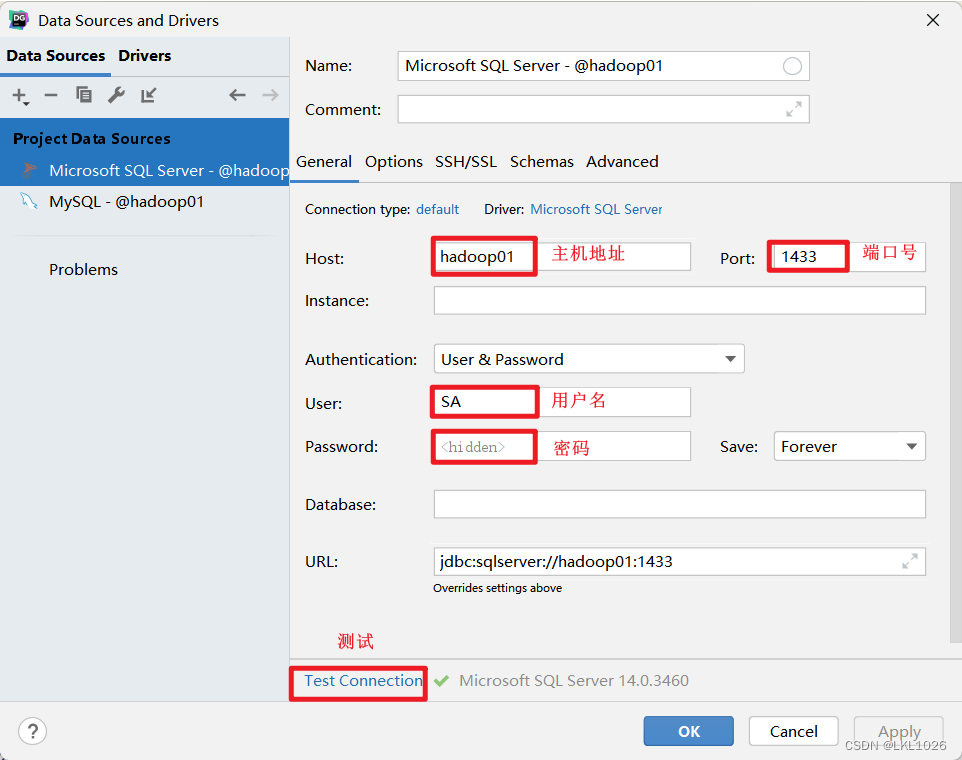
mysql:IP: 192.168.88.80端口號: 3306用戶名: root密碼: 123456sqlserver:IP: 192.168.88.80端口號: 1433用戶名: SA密碼: ITheima123
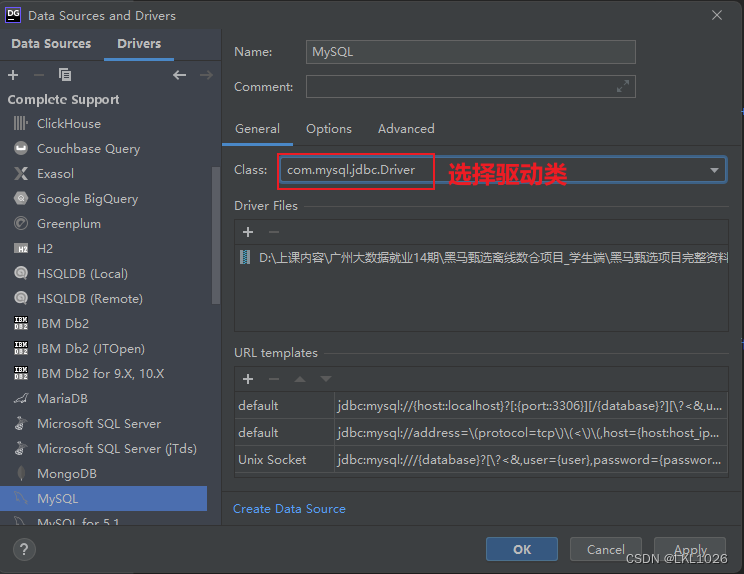
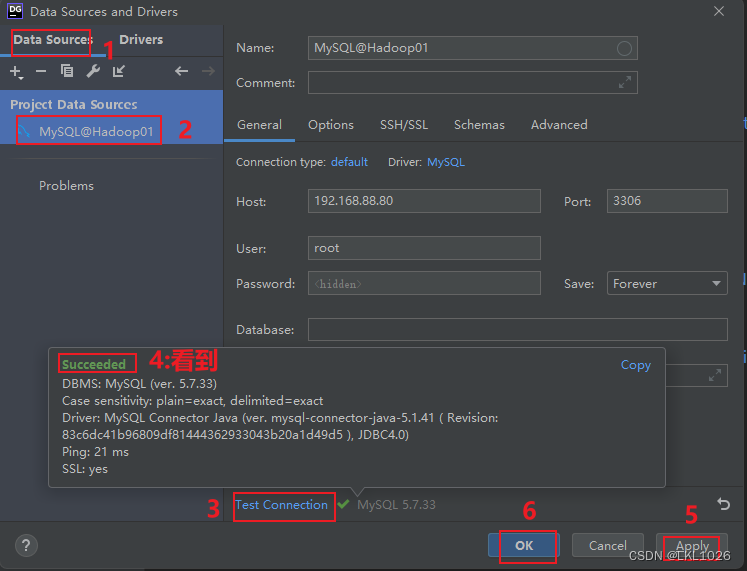
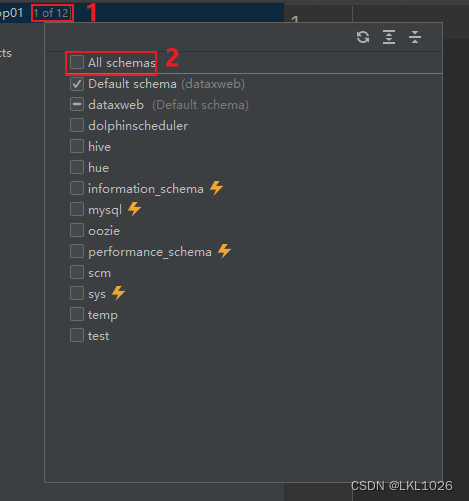
DG連接MySQL
注意: 虛擬機是mysql5,所以選擇mysql5和mysql8的驅動jar包都可以連接上,只要保證連接上就行!!!
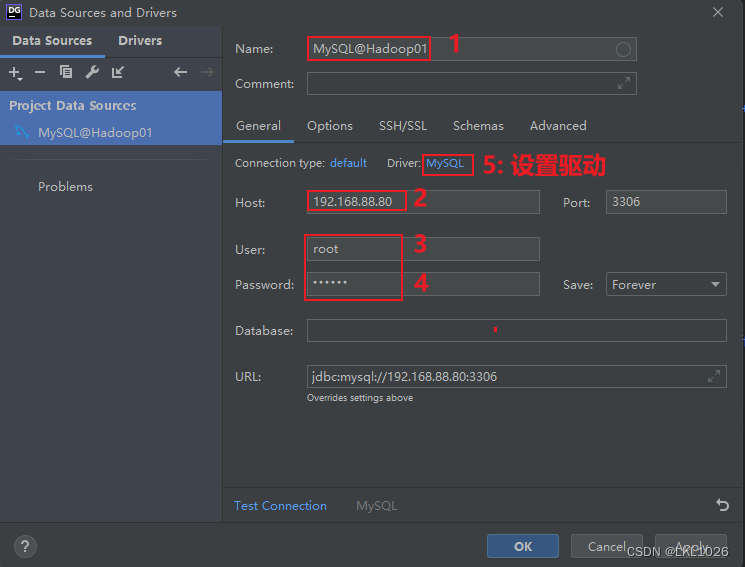
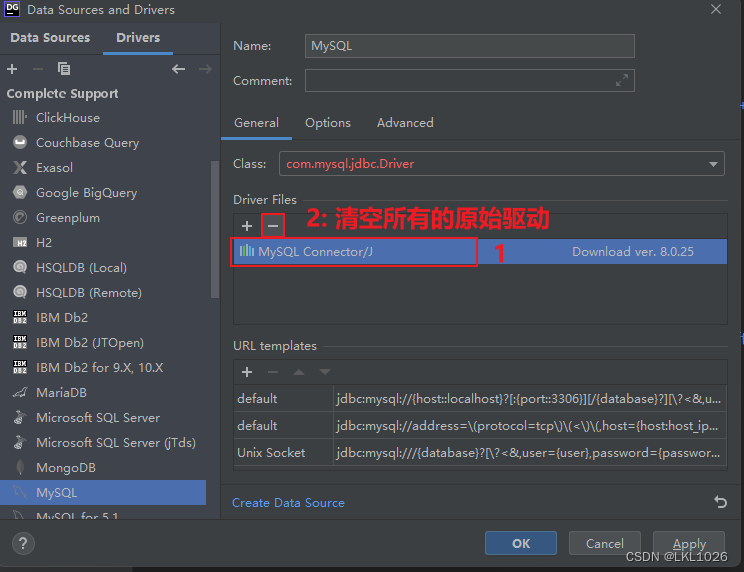
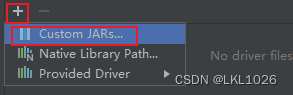
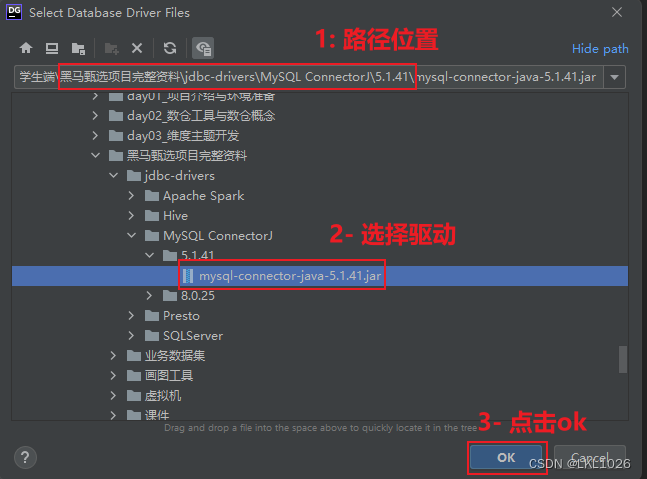
注意: 后續如何基于這個驅動連不上, 可以使用 8的版本的試試
DG連接SqlServer
準備業務數據
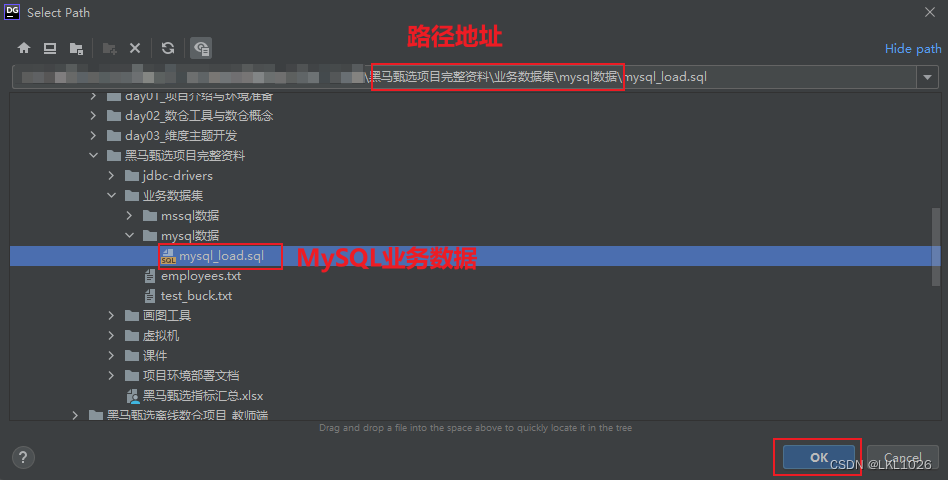
準備MySQL業務數據
連接成功后, 執行數據導入:

結果顯示:
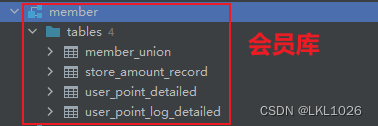
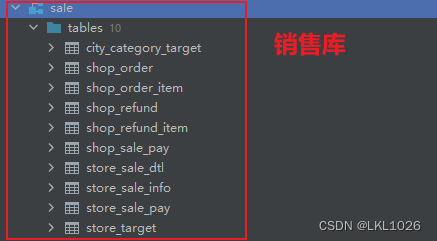
準備SQLServer業務數據
和mysql數據一樣,右鍵選擇Run SQL Script -> 去選擇黑馬甄選離線數倉項目完整資料\06業務數據集\sqlserver數據\mssql_load.sql
最終的結果:
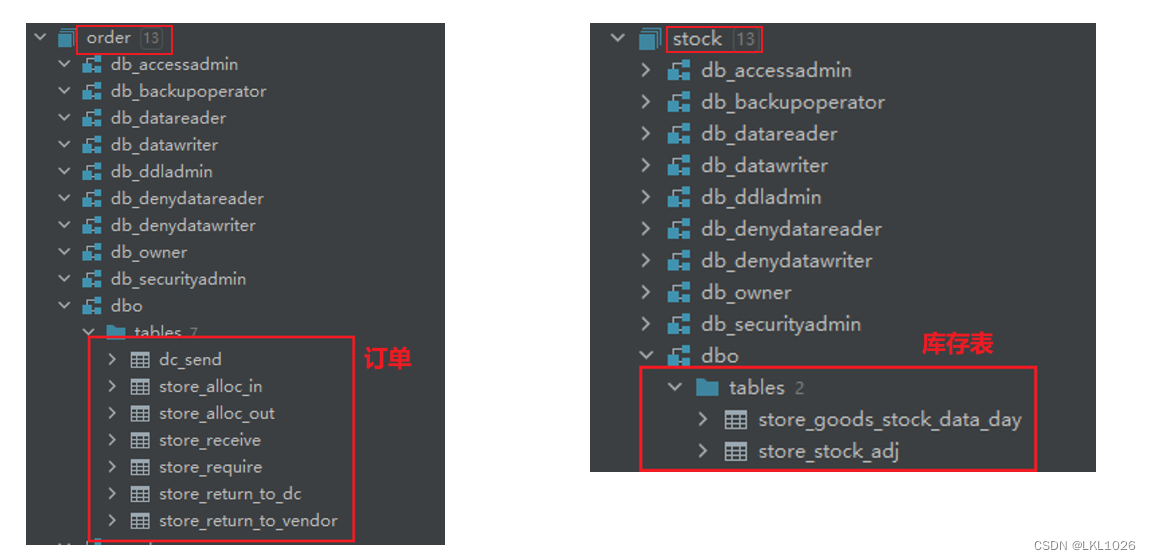
數據庫實驗(數據庫需求分析):音樂軟件數據管理系統)




)













