文章目錄
- 前言
前言
對于一些Saas化軟件,當某個租戶在執行查詢SQL時,如果查詢條件出現了BUG,導致去查了所有租戶的數據,這種情況是非常嚴重的,此時就需要在架構層面做限制,禁止一些特殊SQL的執行,另外,為了保護數據庫,也可能會限制某些查詢語句不要查詢太多的數據,那么怎樣在平臺架構層面對業務層的SQL做攔截和校驗呢?
本文分享一下我司的做法。
我們集團里有的項目用的Mybatis,有的項目用的Spring Data JPA,共同點在于都用的Druid連接池,所以可以在Druid層面做SQL的攔截和校驗。
Druid提供了FilterEventAdapter機制,可以用來攔截數據庫連接的創建、Statement或PreparedStatement的創建、SQL語句的執行等等,我們可以自定義一個FilterEventAdapter:
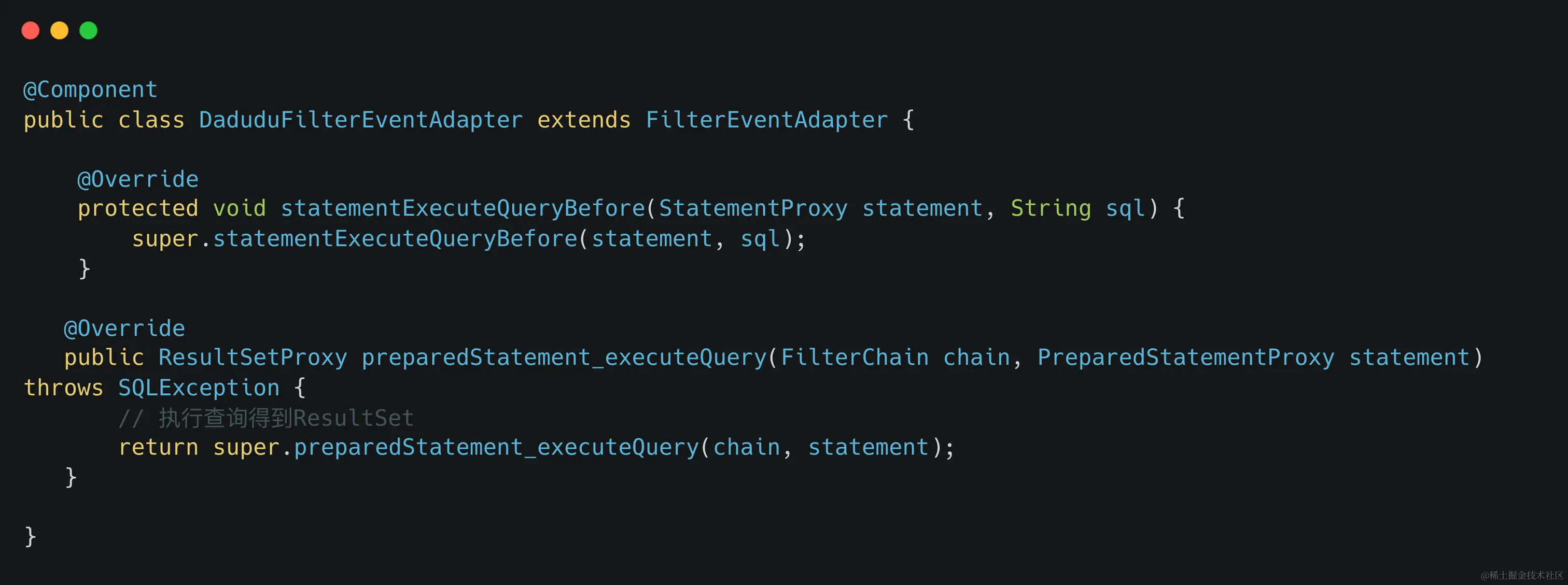
其中statementExecuteQueryBefore()方法表示在執行某個查詢語句前的攔截點,preparedStatement_executeQuery()方法表示執行查詢語句的地方,比如正常情況下preparedStatement_executeQuery()方法順利執行的話就會得到ResultSetProxy,可以理解為就是ResultSet,也就代表查詢結果集。
所以如果我們想做查詢語句的攔截,這兩個方法都可以做到,回到文章題目:想要限制每次查詢的結果集不能超過10000行,該如何實現?我這里給兩種不同的實現方式。
對于某一個查詢SQL,我們首先得知道這個SQL將會查出多少條數據,那就得把該查詢SQL,比如select a,b,c from t where a=1,改造成為select count(1) from t where a=1,執行改造后的count語句就能知道原始SQL會查出多少條記錄了。
我這里提供一個方法,能夠把簡單的select語句改造為count語句(原諒我不能把公司內部的代碼貼出來~~~)
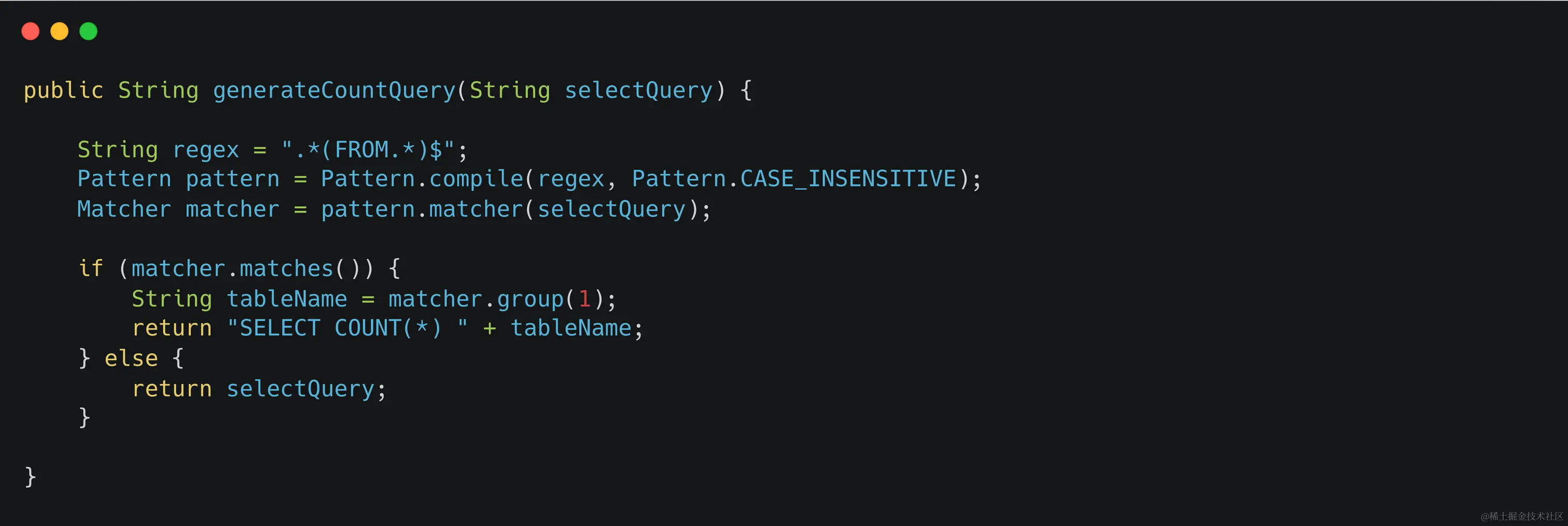
然后,我們就能在statementExecuteQueryBefore()方法中做攔截判斷了:
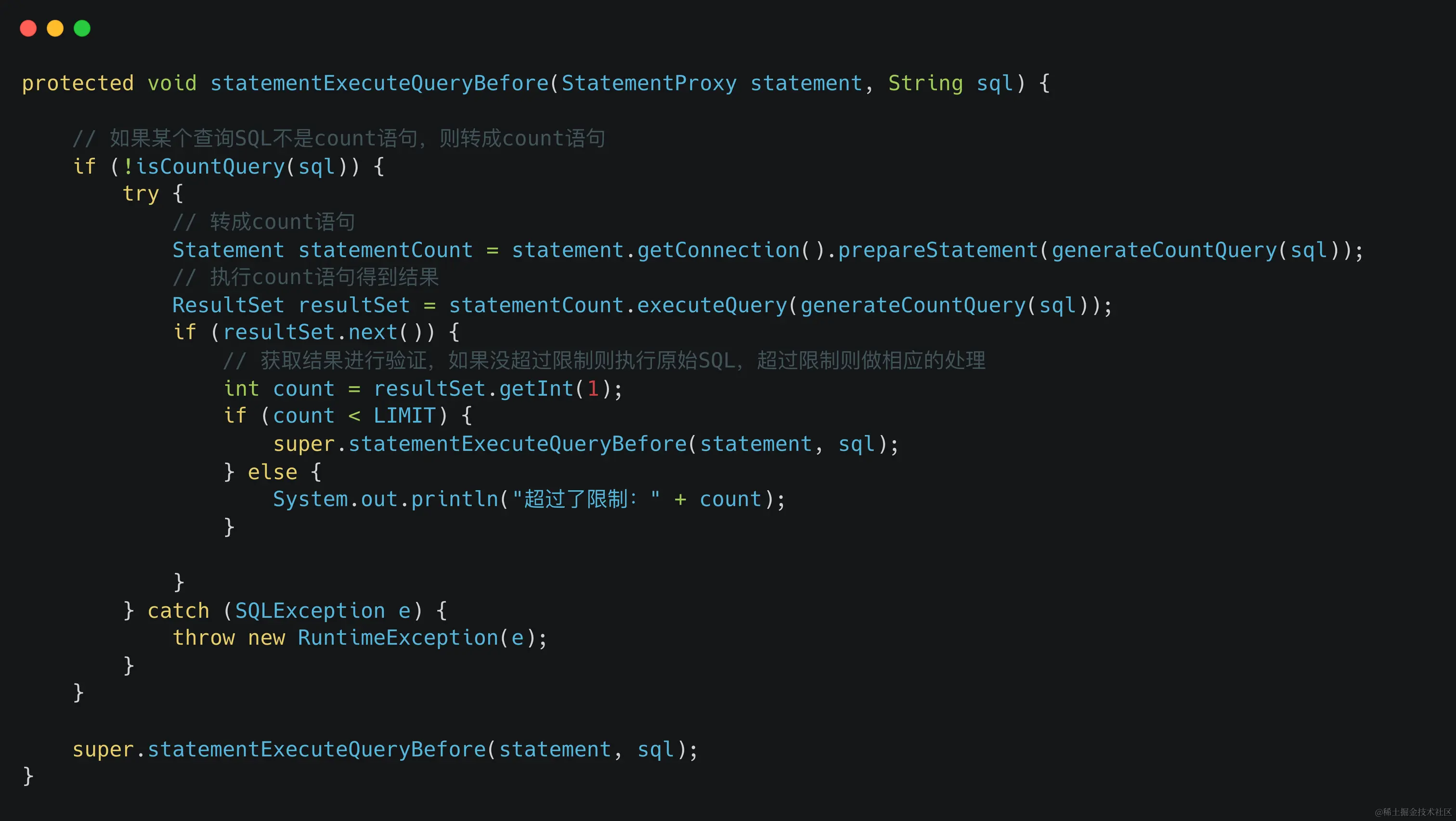
這種方式的好處是:如果某個查詢SQL確實超過限制了,那么就它被攔截了,但是缺點是:如果很多SQL并沒有超過限制,那么就多余執行了count語句,降低了性能。
那么我們來看看第二種方案,這種方法重寫的是preparedStatement_executeQuery方法,思路是:先執行原始SQL,得到ResultSet,然后通過ResultSet來判斷結果集是否超過了限制,如果超過了限制則告警,比如代碼為:
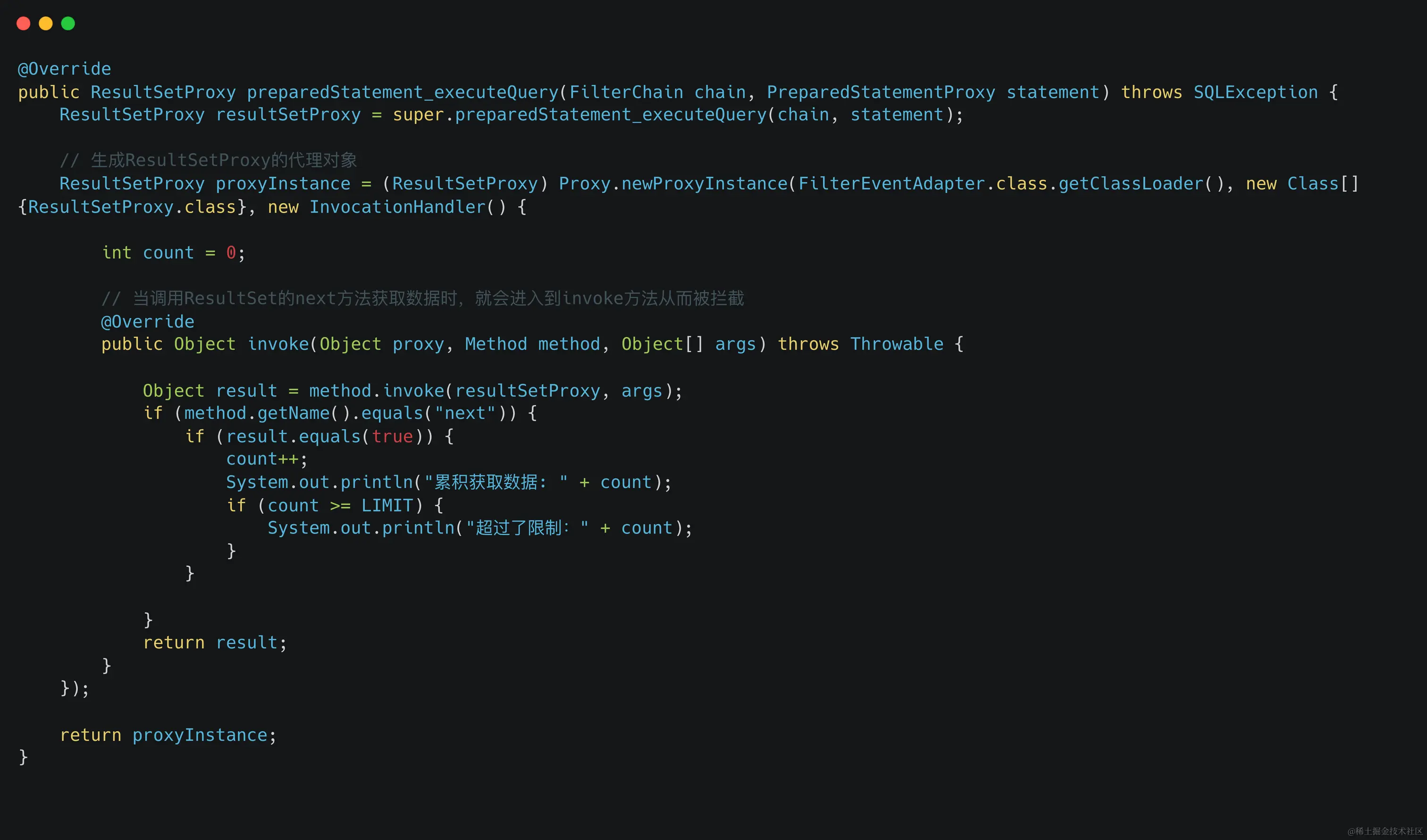
這種方案和第一種方案的優缺點正好相反,優點是:沒有額外執行count語句,缺點是:如果查詢語句確實超過了限制只能事后告警了。
這兩種方案似乎魚和熊掌不可兼得,大家覺得哪個方案更好呢?






)








】)



