文章目錄
- 一、靈感來源
- 二、算法的初始化
- 三、GTO的數學模型
- Phase1:危險信號和安全信號
- Phase2:遷移(探索)
- Phase3:繁殖(開發)
- 四、流程圖
- 五、偽代碼
- 六、算法復雜度
- 七、WO搜索示意圖
- 八、實驗分析和結果
- 23個常見的基礎測試函數
- CEC2021測試函數
- 實際工程優化問題
Walrus optimizer: A novel nature-inspired metaheuristic algorithm
Walrus optimizer: A novel nature-inspired metaheuristic algorithm
摘要:該文獻Introduction介紹了為什么做這個元啟發式算法的原因;Related works列舉了2021-2023年一些算法。我將按照自己理解完全復現這篇文章,包括理論介紹、完整的實驗部分。個人能力有限,如有不足,還請見諒。參考文獻:Han M, Du Z, Yuen K, et al. Walrus Optimizer: A novel nature-inspired metaheuristic algorithm[J]. Expert Systems with Applications, 2023: 122413.
注:僅記錄學習,如有侵權,聯系刪除。
- 1、所寫內容只是個人理解,如有錯誤,還請包涵
- 2、所用主題為slandarer提供的墨滴模板
- 3、CSDN:勉為其難免免
- 4、微信公眾號:飄散在人間的一縷青絲
一、靈感來源
??海象是海洋中除鯨魚外最大的哺乳動物。海象主要生活在北極或附近的溫帶水域,海象是群居動物,過著兩棲生活。海象群的數量從幾十到幾百到幾千不等。它的身體是圓柱形的,粗壯而肥胖,頭部扁平,槍口末端鈍。在上唇周圍有大約400根長而硬的胡須,帶有血管和神經,導致觸覺敏銳。海象最獨特的特征是那對白色、發育良好的上犬齒,它們在其一生中不斷生長,形成象牙。象牙可用于自衛,在泥沙中挖掘蛤蜊、蝦和螃蟹等食物,或在冰上攀爬時支撐身體。
??海象龐大的身體看起來很笨重,但在水中很靈活。在眾多的海洋動物中,海象是最好的潛水員。他們可以在水中潛水 20 分鐘,深度為 500 m。海象潛入海底后可以在水下停留長達 2 小時,一旦需要新鮮空氣,它們可以在 3 分鐘內浮出水面。
??海象具有很強的社區意識,如下所示:
??(1)、當繁殖季節開始時,海象會在海灘上建立自己的領地。最好的位置被最強壯的男性占據。領土的面積根據男性占據的女性數量而變化。
??(2)、海象習慣于生活在陽光無法到達的海洋深水區。像蝙蝠和海豚一樣,海象缺乏獨特的視力;它們依靠合理的定位進行覓食,并通過與同齡人交流來共享食物信息。
??(3)、海象有很強的社交習慣,當它們在水中遇到虎鯨時,它們會采取集體防御策略來保護自己并幫助受傷的虎鯨。長期的生存斗爭經驗使海象無法放松警惕。在這一點上,兩只海象充當警衛。一旦他們的同類受傷,他們就會去幫忙。
??受海象遷徙、繁殖、棲息和覓食行為的啟發(如圖1所示),我們首次提出了一種新的元啟發式算法WO算法。這里需要澄清兩個假設:
??(1)、海象種群通過危險和安全信號來判斷種群行為。
??(2)、海象種群的行為和角色劃分在海象算法中建模。具體來說,海象算法假設雄性、雌性和幼年海象之間的社會結構和相互作用。
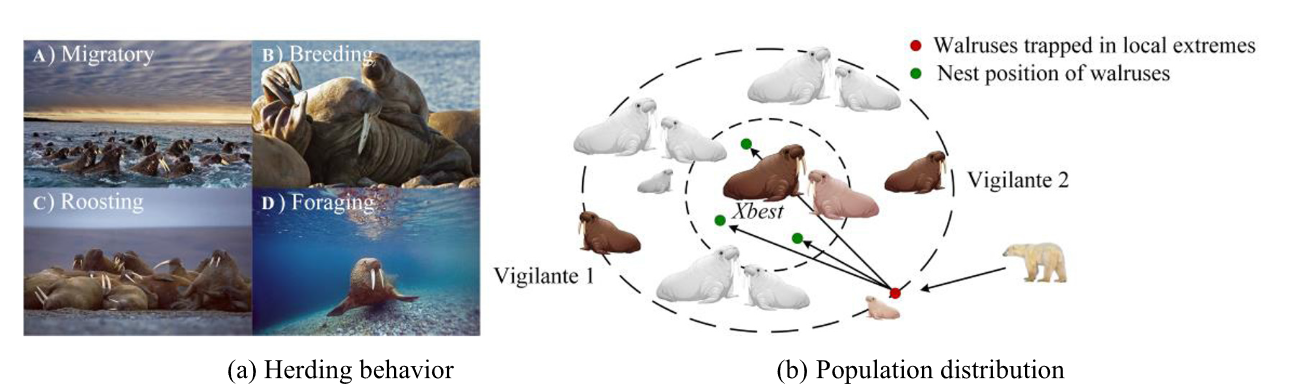
??創新之處在于,海象群中的“義警”是影響象群方向的決定性因素。“治安隊員”發出的[危險信號]及[安全信號],在[行動計劃]的執行過程中起著關鍵作用。在WO中,“危險信號”用于確定WO是執行勘探階段還是開發階段。當“危險信號”滿足一定條件時,海象群遷移到解空間內的新域,這是算法早期階段的探索階段。相反,海象群繁殖,這是算法后期的開發階段。“安全信號”在開發階段起著關鍵作用,它影響著海象是選擇棲息行為還是覓食。其中,雄性海象、雌性海象和幼年海象在棲息行為中相互作用,使種群朝著有利于生存的方向移動;覓食行為包括典型的聚集和逃跑現象,這些現象由“危險信號”控制。在有序的警務環境中,海象群可以避免被捕食者捕獲或死亡(落入局部最佳狀態),并實現種群增長(尋找全局最佳狀態)。
二、算法的初始化
??X代表WO種群矩陣, X i = ( x i , 1 , x i , 2 , . . . , x i , m ) X_{i}=(x_{i,1},x_{i,2},...,x_{i,m}) Xi?=(xi,1?,xi,2?,...,xi,m?)是WO的第i個成員(候選解)。
??F代表適應度函數值。
X = [ X 1 ? X i ? X N ] N × m = [ x 1 , 1 ? x 1 , j ? x 1 , m ? ? ? ? x i , 1 ? x i , j ? x i , m ? ? ? ? x N , 1 ? x N , j ? x N , m ] N × m X=\left[\begin{array}{c} X_{1} \\ \vdots \\ X_{i} \\ \vdots \\ X_{N} \end{array}\right]_{N \times m}=\left[\begin{array}{ccccc} x_{1,1} & \cdots & x_{1, j} & \cdots & x_{1, m} \\ \vdots & \ddots & \vdots & & \vdots \\ x_{i, 1} & \cdots & x_{i, j} & \cdots & x_{i, m} \\ \vdots & & \vdots & \ddots & \vdots \\ x_{N, 1} & \cdots & x_{N, j} & \cdots & x_{N, m} \end{array}\right]_{N \times m} X= ?X1??Xi??XN?? ?N×m?= ?x1,1??xi,1??xN,1???????x1,j??xi,j??xN,j???????x1,m??xi,m??xN,m?? ?N×m?
x i , j = l b j + rand? ? ( u b j ? l b j ) , i = 1 , 2 , … , N , j = 1 , 2 , … , m x_{i, j}=lb_{j}+\text { rand } \cdot\left(ub_{j}-lb_{j}\right), i=1,2, \ldots, N, j=1,2, \ldots, m xi,j?=lbj?+?rand??(ubj??lbj?),i=1,2,…,N,j=1,2,…,m
F = [ F 1 ? F i ? F N ] N × 1 = [ F ( X 1 ) ? F ( X i ) ? F ( X N ) ] N × 1 F=\left[\begin{array}{c} F_{1} \\ \vdots \\ F_{i} \\ \vdots \\ F_{N} \end{array}\right]_{N \times 1}=\left[\begin{array}{c} F\left(X_{1}\right) \\ \vdots \\ F\left(X_{i}\right) \\ \vdots \\ F\left(X_{N}\right) \end{array}\right]_{N \times 1} F= ?F1??Fi??FN?? ?N×1?= ?F(X1?)?F(Xi?)?F(XN?)? ?N×1?
??式中: x i , j x_{i, j} xi,j?代表第i個成員的第j個變量的值;N是種群大小;m是維度;rand代表[0,1]之間的隨機數; l b j lb_{ j} lbj?代表下限; u b j ub_{ j} ubj?代表上限。
三、GTO的數學模型
??海象種群分為成年和幼體,分別占種群的90%和10%。在成年海象中,雄性與雌性的比例為1:1。
Phase1:危險信號和安全信號
??海象在覓食和棲息時都非常警惕。會有1至2只海象作為警衛在周圍巡邏,一旦發現意外情況,會立即發出危險信號。其中危險信號和安全信號定義如下:
Dangersignal? = A ? R α = 1 ? t / T A = 2 × α R = 2 × r 1 ? 1 \begin{aligned} & \text { Dangersignal }=A^* R \\ & \alpha=1-t / T \\ & A=2 \times \alpha \\ & R=2 \times r_1-1 \end{aligned} ??Dangersignal?=A?Rα=1?t/TA=2×αR=2×r1??1?
??其中 A A A和 R R R是危險因子, α \alpha α隨著迭代次數的增加,從1減小到0。 Levy? ( Dim? ) \text { Levy }(\text { Dim }) ?Levy?(?Dim?)是Levy飛行, T T T是最大迭代次數。
??WO中危險信號對應的安全信號定義如下:
Safetysignal? = r 2 \begin{aligned} & \text { Safetysignal }=r_2 \\ \end{aligned} ??Safetysignal?=r2??
??其中 r 1 r_1 r1?和 r 2 r_2 r2?是在[0,1]內的隨機數。
Phase2:遷移(探索)
??當危險因子過高時,海象群會遷移到更適合種群生存的地區。在此階段,海象位置更新如下:
X i , j t + 1 = X i , j t + Migrationstep? X_{i, j}^{t+1}=X_{i, j}^t+\text { Migrationstep } Xi,jt+1?=Xi,jt?+?Migrationstep?
Migrationstep? = ( X m t ? X n t ) ? β ? r 3 2 \text { Migrationstep } =\left(X_m^t-X_n^t\right) \bullet \beta \bullet r_3{ }^2 ?Migrationstep?=(Xmt??Xnt?)?β?r3?2
β = 1 ? 1 1 + exp ? ( ? t ? T 2 T × 10 ) \beta=1-\frac{1}{1+\exp \left(-\frac{t-\frac{T}{2}}{T} \times 10\right)} β=1?1+exp(?Tt?2T??×10)1?
??其中 X i , j t + 1 X_{i, j}^{t+1} Xi,jt+1?是i個個體在第j個維度上的更新位置, X i , j t X_{i, j}^{t} Xi,jt?是當前位置,Migration_step是海象運動的步長,從種群中隨機選擇兩個警惕者,其位置對應于 X m t X_m^t Xmt?和 X m n X_m^n Xmn?, β \beta β是遷移步長控制因子,它隨著迭代變化為平滑曲線, r 3 r_3 r3?是在[0,1]內的隨機數。
Phase3:繁殖(開發)
??與遷徙相反,當風險因素較低時,海象群傾向于在洋流中繁殖。在繁殖過程中,主要有兩種行為,陸上棲息和水下覓食。數學模型如下。
??(1)棲息行為
??雄性、雌性和幼年海象是我們對種群成員的分類。他們有不同的方式來更新他們的立場。
??第 1 步:雄性海象的重新分布
??采用Halton序列分布進行雄性海象位置更新,可以擴大種群的搜索分布
??第 2 步:更新雌性海象的位置
??雌性海象受到雄性海象 Male? i , j t \text { Male }_{i, j}^t ?Male?i,jt?和領頭海象 X best? t X_{\text {best }}^t Xbest?t?的影響。隨著迭代過程的進行,雌性海象逐漸減少對配偶的影響,而更多地受到領導者的影響。
Female? i , j t + 1 = Female? i , j t + α ? ( Male? i , j t ? Female? i , j t ) + ( 1 ? α ) ? ( X best? t ? Female? i , j t ) \begin{aligned} \text { Female }_{i, j}^{t+1}= & \text { Female }_{i, j}^t+\alpha \bullet\left(\text { Male }_{i, j}^t-\text { Female }_{i, j}^t\right)+(1-\alpha) \\ & \bullet\left(X_{\text {best }}^t-\text { Female }_{i, j}^t\right) \end{aligned} ?Female?i,jt+1?=??Female?i,jt?+α?(?Male?i,jt???Female?i,jt?)+(1?α)?(Xbest?t???Female?i,jt?)?
??第 3 步:更新幼年海象的位置
??種群邊緣的幼年海象經常成為虎鯨和北極熊的目標。因此,幼年海象需要更新其當前位置以避免捕食。
Juvenile? i , j t + 1 = ( O ? Juvenile? i , j t ) ? P O = X best? t + Juvenile? i , j t ? L F \begin{aligned} & \text { Juvenile }_{i, j}^{t+1}=\left(O-\text { Juvenile }_{i, j}^t\right) \bullet P \\ & O=X_{\text {best }}^t+\text { Juvenile }_{i, j}^t \bullet L F \end{aligned} ??Juvenile?i,jt+1?=(O??Juvenile?i,jt?)?PO=Xbest?t?+?Juvenile?i,jt??LF?
??P是幼年海象的遇險系數,是[0,1]的隨機數,O是參考安全位置,LF是基于 L ?evy分布的隨機數向量,表示Levy運動。
Levy ? ( a ) = 0.05 × x ∣ y ∣ 1 a σ x = [ Γ ( 1 + α ) sin ? ( π α 2 ) Γ ( 1 + α 2 ) α 2 ( α ? 1 ) 2 ] 1 α , σ y = 1 , α = 1.5 \begin{gathered} \operatorname{Levy}(a)=0.05 \times \frac{x}{|y|^{\frac{1}{a}}} \\ \sigma_x=\left[\frac{\Gamma(1+\alpha) \sin \left(\frac{\pi \alpha}{2}\right)}{\Gamma\left(\frac{1+\alpha}{2}\right) \alpha 2^{\frac{(\alpha-1)}{2}}}\right]^{\frac{1}{\alpha}}, \sigma_y=1, \alpha=1.5 \end{gathered} Levy(a)=0.05×∣y∣a1?x?σx?=[Γ(21+α?)α22(α?1)?Γ(1+α)sin(2πα?)?]α1?,σy?=1,α=1.5?
??其中,其中x和y是兩個正態分布變量, x N ( 0 , σ x 2 ) x \mathrm{~N}\left(0, \sigma_x^2\right) x?N(0,σx2?), y N ( 0 , σ x 2 ) y \mathrm{~N}\left(0, \sigma_x^2\right) y?N(0,σx2?) 。 σ x \sigma_x σx? 和 σ y \sigma_y σy?是標準差, Γ ( x ) = ( x + 1 ) ! \Gamma(x)=(x+1) ! Γ(x)=(x+1)!
??(2)覓食行為
??水下覓食包括逃跑和采集行為
??a) 逃跑行為
??海象在水下覓食時也會受到天敵的攻擊,它們會根據同伴發出的危險信號逃離當前的活動區域。這種行為發生在WO的后期迭代中,對種群的一定程度的擾動有助于海象進行全局探索。
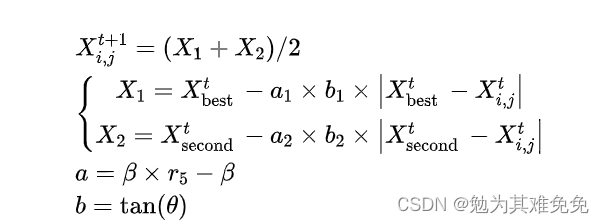
??其中, X 1 X_1 X1?和 X 2 X_2 X2?是影響海象聚集行為的兩個權重, X second? t X_{\text {second }}^t Xsecond?t?是第二只海象在當前迭代中的位置, ∣ X second? t ? X i , j t ∣ \left|X_{\text {second }}^t-X_{i, j}^t\right| ?Xsecond?t??Xi,jt? ?表示當前海象與第二只海象之間的距離,a和b為聚集系數, r 5 r_5 r5?為隨機數,位于[0,1], θ \theta θ取的值范圍為0到π。
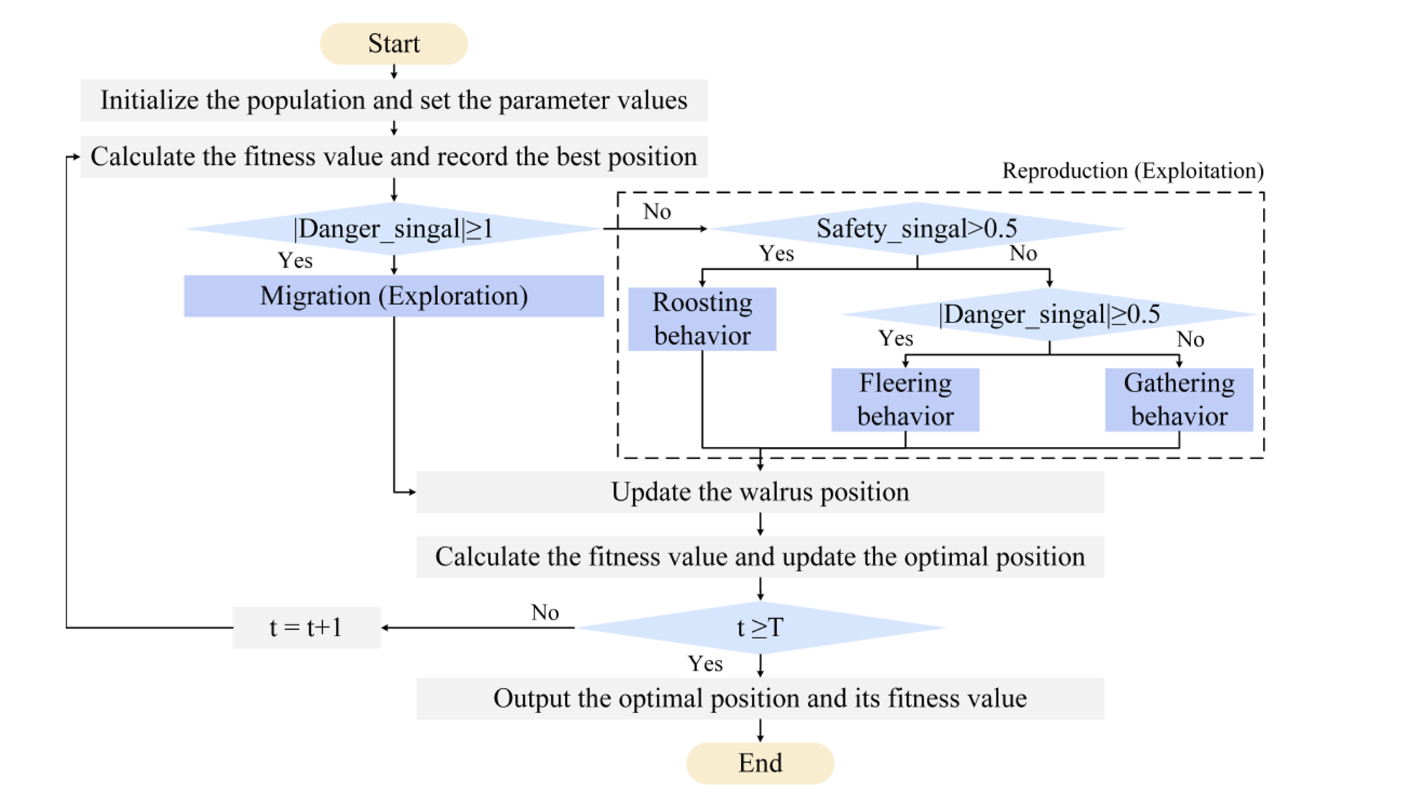
四、流程圖
??在WO中,危險信號用于確定WO是執行勘探階段還是開發階段。當危險信號絕對值不小于1時,海象群遷移到解空間內的新域,即算法早期的探索階段;相反,海象群繁殖,這是算法后期的開發階段。安全信號在開發階段起著關鍵作用,它影響著個體海象是選擇棲息行為還是覓食行為。其中,覓食行為包括聚集和逃跑兩種典型現象,它們受危險信號的控制。
五、偽代碼

六、算法復雜度
??在求解優化問題時,計算復雜度對于評估算法的效率非常有用,它取決于三個主要過程:初始化、適應度評估和解決方案的更新。初始化過程和更新機制的計算復雜度分別為O(N)和O(N × T)+ O(N × T × D),其中N為種群大小,T為最大迭代次數,D為給定問題的維數。因此,WO的計算復雜度為O(N ×( T +T × D +1))。算法在運行過程中臨時占用的內存空間量可以用空間復雜度來衡量。WO算法的空間復雜度是在其初始化過程中考慮的任何時間使用的最大空間量。因此,WO算法的空間復雜度為 O(N × Dim)。
七、WO搜索示意圖
??為了可視化所提出的算法的行為,本節顯示了海象群行為的模擬。下圖描繪了30個海象在三維空間中尋找單峰和多峰函數最優解的群體行為。紅點表示全局最佳位置,其余為海象位置。當t=1時,海象在解空間中隨機生成,散射范圍較寬。隨著迭代的繼續,所有海象的搜索范圍逐漸縮小。最后,所有海象都匯聚到紅點上。單模態函數的搜索結果可以表明WO具有較好的開發能力,多模態函數的搜索結果可以反映WO較強的探索能力。(注:與文獻中稍有不同的是我加了一個原函數圖像,Sphere就是常見的測試函數F1,Rastrigin函數是F9,直接修改序號即可)



八、實驗分析和結果
??寫了很久筆記了,也沒有寫完整的實驗。在這篇中,完整的復現一下。包括多次獨立運行、對數據的統計、導入到excel、出圖,鍛煉一下,順便縫縫補補自己以前的爛代碼。整體的思路就按照這篇論文的來寫吧。后續看到好看的圖再補充吧。
??為了適當驗證WO算法的性能,原作者進行了大量實驗。
23個常見的基礎測試函數
??1、定性分析
??使用幾種單峰和多模態標準準則函數對WO的定性結果進行評估,并使用WO的4個不同標準對結果進行評估,包括搜索歷史、第一智能體的軌跡、平均擬合度和收斂曲線。搜索歷史圖顯示了海象個體在迭代期間訪問的所有位置;軌跡圖監控第一只海象在迭代過程中的變化情況;平均適應度圖顯示了海象種群的整體變化;收斂行為圖記錄了總體每次迭代后的最佳解。
??從23個基準測試中選出10個典型函數進行分析。從搜索歷史可以看出,WO在處理不同情況時,包括促進多樣化、探索解決方案空間的有利區域、開發最優位置鄰域等,都呈現出相似的模式。(一旦涉及了位置繪圖可視化,要么每個測試問題的維度設置為2,要么就是畫圖的時候選擇前兩個位置。在此我選擇第二種方法)
??種群大小設置為30,迭代次數設置為400。從23個里面選擇了十個來進行分析。
%% 定性分析23個基準測試函數
clear
clc
close all
populationSize = 30;
Max_iteration = 400;
selet_fcn = [1,3,7,8,10,12,14,15,18,21];
for i=1:length(selet_fcn)-5fn = 1;Function_name=strcat('F',num2str(selet_fcn(i)));[lb,ub,dim,fobj]=Get_Functions_details(Function_name);% dim = 2;% rng('shuffle');%根據當前時間初始化生成器,在每次調用 rng 后會產生一個不同的隨機數序列。[Best_score,Best_pos,PO_cg_curve,All_Pos,fitness1st,fitnessallmean]=WO3(populationSize,Max_iteration,lb,ub,dim,fobj);%% 繪制定性分析圖figure('NumberTitle','off','Color','w','Name','函數圖像','Units','centimeters','Position',[4,15,40,7])tiledlayout(1,5);nexttile%繪制原圖像fun_plot(Function_name)nexttile%搜索歷史圖fun_plot(Function_name);h = gca;h.Children(2).Visible = "off";hold onview(0,90)for i = 1:length(All_Pos)temp = All_Pos{i};scatter(temp(:,1),temp(:,2),12,'k')endtitle('Search history')box ongrid onnexttileplot(fitness1st,'Color',[6, 253, 244]./255,'LineWidth',1.5)title('Trajectory in 1st agents')box ongrid onnexttileplot(fitnessallmean,'Color',[28, 29, 252]./255,'LineWidth',1.5)title('average fitness of all agents')box ongrid onnexttilesemilogx(PO_cg_curve,'Color',[245, 42, 237]./255,'LineWidth',1.5)title('Convergence curve')box ongrid on
end









??關于圖搜索歷史和第一智能體的跡和原文不一樣,理解不到位。暫時先這樣放著,待后續理解更透徹了再修改這個圖。其實這個每跑一次產生的圖都不一樣,感興趣的可以多跑幾次試試。
??2、定量分析
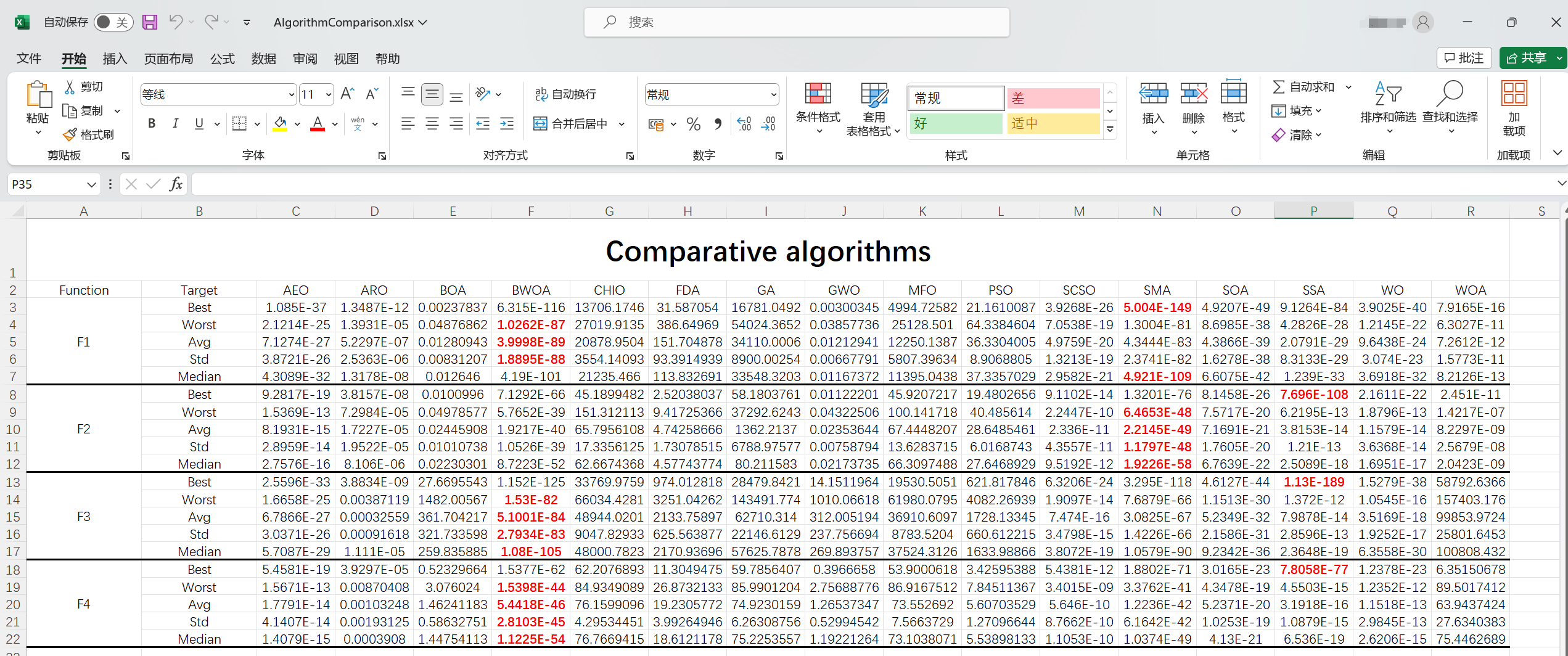
??這部分仿真時,文中未明確說明種群大小和迭代次數,在此我設置種群大小為30,迭代次數為100。文中所提及的ABC、AOS、ChoA、FOA、SHO算法我暫時沒有,在此我換四個其他算法,AEO、ARO、CHIO、FDA、SMA。為了節約時間,我獨立運行了30次,并調用excel的com服務器將結果寫在了excel表中。在此列出前四個函數的表格。對每一行的最小值進行的字體加粗,顏色設置為紅色的處理。
%% 存儲多個算法對比數據 平均值 最優值 最差值 中位數 標準差
clc
clear
close all
%% 加載實驗數據
load 20231107_30_100_30_16_PM.mat
file_path=[pwd,'\AlgorithmComparison.xlsx'];%設置當前路徑
tryexcelApp=actxGetRunningServer('Excel.Application');%如果Excel 服務器已經打開,返回其句柄
catchexcelApp=actxserver('Excel.Application');%如果Excel服務器沒有打開,則創建一個Excel服務器,并返回句柄
end
excelApp.Visible = true; % 使 Excel 可見
%% 添加一個新的工作簿
%如果存在test.xlsx文件,則打開文件,若不存在則創建一個,然后保存
if exist(file_path,'file')workbook=excelApp.Workbooks.Open(file_path);%打開 注意這里打開的必須是絕對路徑
elseworkbook=excelApp.Workbooks.Add;%創建 創建工作簿的時候默認是1 在excel選項中設置workbook.SaveAs(file_path)%保存
end%% 使用默認的工作表
sheet = workbook.Sheets.Item(1);
%% 設置工作表的名稱
sheet.Name = 'Algorithm Comparison';
%% 合并單元格并設置 "Comparative algorithms" 標題
% 假設總共有12個算法名稱加上'Function'和'target'列,因此共14列
titleRange = sheet.Range('A1:R1'); % 直接指定從A1到N1的范圍
titleRange.MergeCells = true;
titleRange.Value = 'Comparative algorithms';
titleRange.HorizontalAlignment = -4108;%使用 xlCenter 的數值
titleRange.Font.Bold = true;
titleRange.RowHeight = 50;
titleRange.Font.Size = 24;
% 填充算法名稱 從加載的數據中讀取
for i = 1:length(algorithms)temp = strsplit(algorithms{i},'.');algorithms(i)=temp(1);
end
% algorithms = {'AEO', 'ACO', 'SSA', 'SSA', 'SSA', 'SSA', 'SSA', 'SSA', 'SSA', 'SSA', 'SSA', 'SSA'};
% 從第三列開始填充算法名稱
for i = 1:length(algorithms)% 使用Excel列字母可以使得引用更加清晰colLetter = char('B' + i); % 因為算法從第三列開始,所以是 'B' + irangeStr = sprintf('%s2', colLetter); % 生成范圍字符串,如 'C2', 'D2', 等sheet.Range(rangeStr).Value = algorithms{i};
end
%% 假設有以下函數和指標
functions = {'F1', 'F2', 'F3', 'F4'};
metrics = {'Best', 'Worst', 'Avg', 'Std', 'Median'};
% 為函數名、指標和隨機數據填充表格
% 為函數名、指標和隨機數據填充表格
for i = 1:length(functions)% 合并相同函數名的單元格startRow = (i-1)*length(metrics)+3; % 函數開始的行號endRow = startRow + length(metrics) - 1; % 函數結束的行號mergeRangeStr = sprintf('A%d:A%d', startRow, endRow);mergeRange = sheet.Range(mergeRangeStr);mergeRange.MergeCells = true;mergeRange.Value = functions{i};mergeRange.VerticalAlignment = -4108; % 垂直居中mergeRange.HorizontalAlignment = -4108; % 水平居中% 為每個指標生成并填充隨機數據for j = 1:length(metrics)metricCell = sprintf('B%d', (i-1)*length(metrics)+j+2);sheet.Range(metricCell).Value = metrics{j};% 為每個指標的算法生成并填充隨機數據% for k = 1:length(algorithms)% dataCell = sprintf('%s%d', char('B' + k), (i-1)*length(metrics)+j+2);% sheet.Range(dataCell).Value = rand();% endend
end
sheet.Range('A2').Value = 'Function';
sheet.Range('B2').Value = 'Target';
% 調整列寬
% 調整第一列和第二列的列寬
sheet.Range('A:A').ColumnWidth = 15;
sheet.Range('B:B').ColumnWidth = 15;% 假設算法從第三列開始,一共有12個算法
% 調整算法列的列寬
for i = 3:(2+length(algorithms))colLetter = char('A' + i - 1); % 將列號轉換為列字母sheet.Range([colLetter ':' colLetter]).ColumnWidth = 10;
end
%% 獲取用過的范圍(整個數據區域)
usedRange = sheet.UsedRange;
% 你現在可以對這個范圍進行操作,比如設置單元格的格式
% 設置整個區域的單元格內容居中對齊
usedRange.HorizontalAlignment = -4108; % 水平居中
usedRange.VerticalAlignment = -4108; % 垂直居中
%% 設置字體顏色
% 找到最小值的位置
minall = min(comparealg,[],2);
[minindexX,minindexY]=find(comparealg==minall);minLocations = [minindexX,minindexY]; % 最小值位置矩陣% 轉換最小值位置到 Excel 單元格地址并設置為紅色
for i = 1:size(minLocations, 1)% 計算 Excel 單元格地址rowIndex = minLocations(i, 1) + 2; % +2 是因為數據從 C3 開始colIndex = minLocations(i, 2) + 2; % +2 是因為數據從第三列開始cellAddress = sprintf('%s%d', char('A' + colIndex-1), rowIndex);sheet.Range(cellAddress).Font.Color = 255; % 設置字體顏色為紅色sheet.Range(cellAddress).Font.Bold = true; % 設置字體為加粗
end
% 假設每個函數的數據占據 5 行
numRowsPerFunction = 5;
numFunctions = 4; % F1, F2, F3, F4
startCol = 'A'; % 數據開始的列
endCol = 'R'; % 數據結束的列
startRow = 3; % 數據開始的行% 加粗每個函數數據行的底部邊框
for i = 1:numFunctions% 計算函數數據塊的最后一行lastRow = startRow + i * numRowsPerFunction - 1;% 構建范圍字符串rangeStr = sprintf('%s%d:%s%d', startCol, lastRow, endCol, lastRow);% 獲取范圍range = sheet.Range(rangeStr);% 設置底部邊框樣式為加粗range.Borders.Item('xlEdgeBottom').LineStyle = 1; % Continuous linerange.Borders.Item('xlEdgeBottom').Weight = 4; % Thick weight
end
%% 存數據指定 Excel 范圍
range = sheet.Range('C3:R22');
% 將數據一次性寫入指定范圍
range.Value = comparealg;
%% 保存工作簿 指定為絕對路徑
workbook.Save();%% 清理
workbook.Close();
excelApp.Quit();
excelApp.release;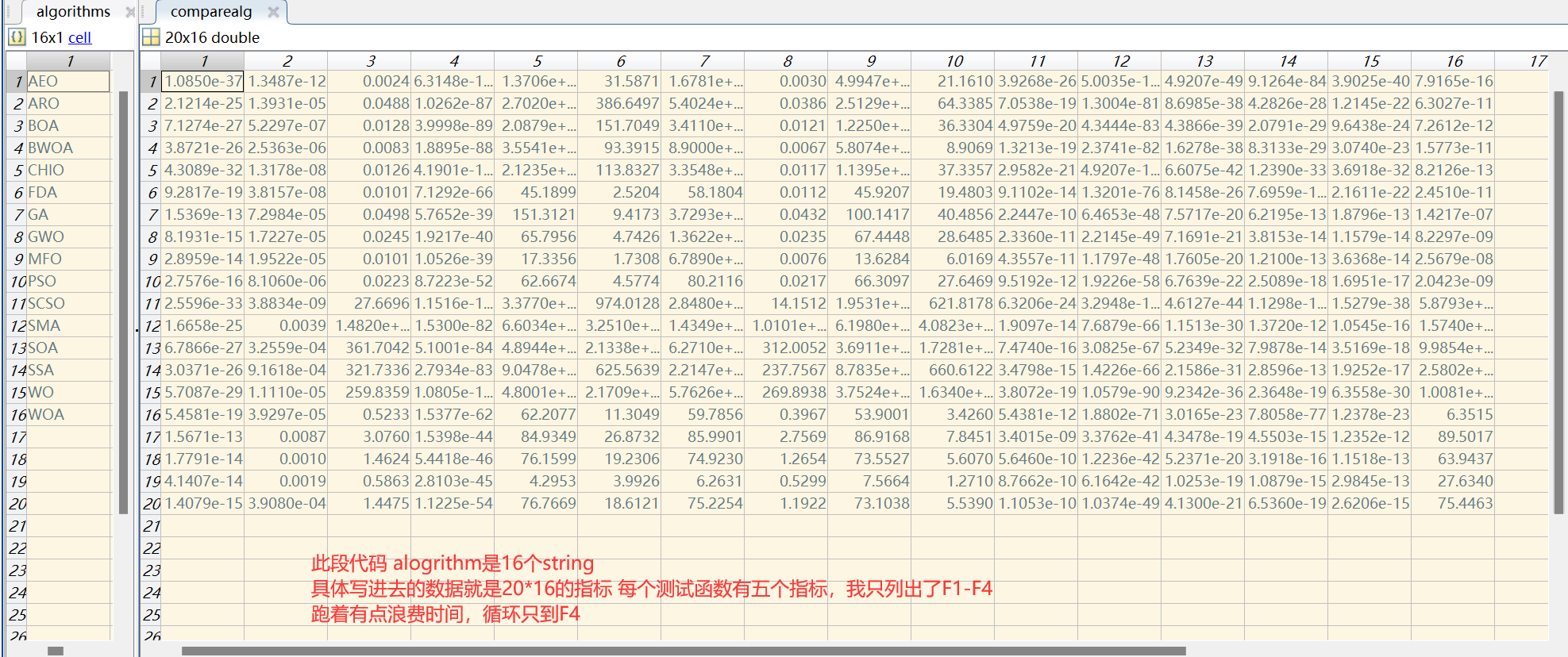
??3、收斂性分析
??就是一個常規的迭代曲線圖。文獻中這么排版了,在此列出前四個函數。
%% 繪制迭代曲線
clear;clc;close all
addpath Algorithms\
addpath Algorithms\
cd Algorithms\
s = what;
algorithms = s.m;
cd D:\智能優化算法\WO\定量分析
SearchAgents_no = 30;
Max_iteration = 100;
figure('NumberTitle','off', ...'Color','w', ...'Name','迭代曲線對比圖', ...'Units','centimeters', ...'Position',[4,15,40,7])
tiledlayout(1,4)
for j=1:4fn = j;Function_name=strcat('F',num2str(fn));[lb,ub,dim,fobj]=Get_Functions_details(Function_name);[Min_AEO,~, AEO_curve] = AEO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj );[Min_ARO,~, ARO_curve] = ARO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj );[Min_BOA,~, BOA_curve] =GWO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_BWOA,~, BWOA_curve]=BWOA(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_CHIO,~, CHIO_curve]=CHIO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_FDA,~, FDA_curve]=FDA(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_GA,~, GA_curve]=GA(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_GWO,~, GWO_curve]=GWO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_MFO,~, MFO_curve]=MFO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_PSO,~, PSO_curve]=PSO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_SCSO,~, SCSO_curve]=SCSO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_SMA,~, SMA_curve]=SMA(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_SOA,~, SOA_curve]=SOA(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_SSA,~, SSA_curve]=SSA(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_WO,~, WO_curve]=WO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);[Min_WOA,~, WOA_curve]=WOA(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);nexttilesemilogy(AEO_curve)hold onsemilogy(ARO_curve);semilogy(BOA_curve);semilogy(BWOA_curve);semilogy(CHIO_curve);semilogy(FDA_curve);semilogy(GA_curve);semilogy(GWO_curve);semilogy(MFO_curve);semilogy(PSO_curve);semilogy(SCSO_curve);semilogy(SMA_curve);semilogy(SOA_curve);semilogy(SSA_curve);semilogy(WO_curve,'r','LineWidth',2);semilogy(WOA_curve);xlabel('iteration')ylabel('fitness')
end% 填充算法名稱 從加載的數據中讀取
for i = 1:length(algorithms)temp = strsplit(algorithms{i},'.');algorithms(i)=temp(1);
end
legnedpos = gca().Position;
legend(algorithms,'Position',legnedpos+[legnedpos(3)+0.003,0,-0.1,0])
??4、穩定性分析
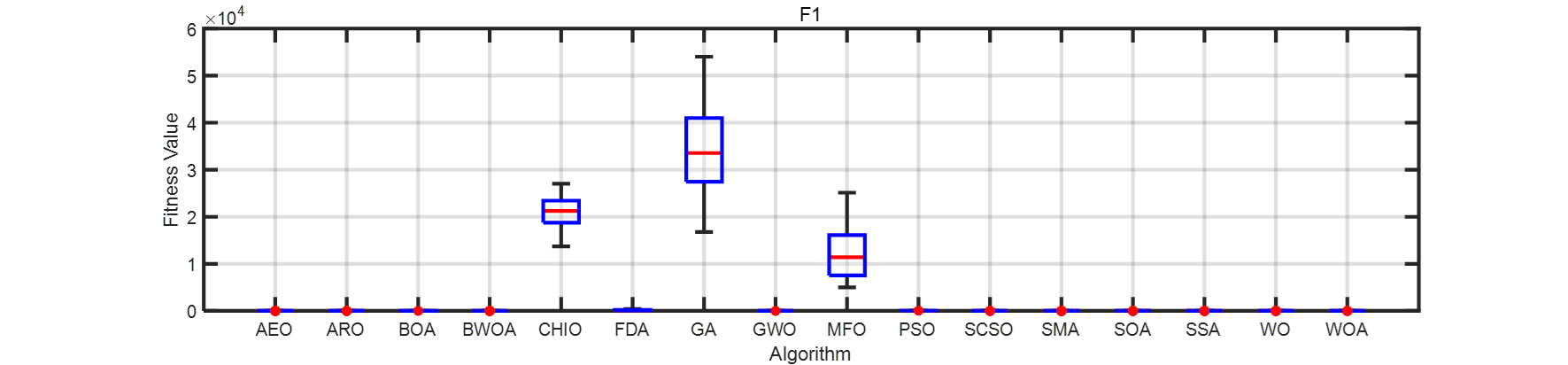
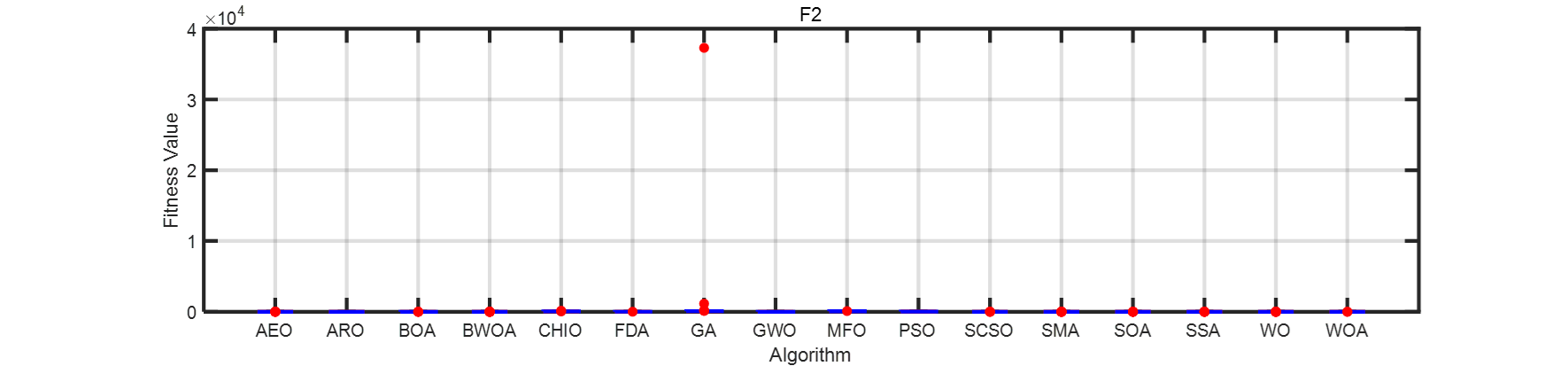
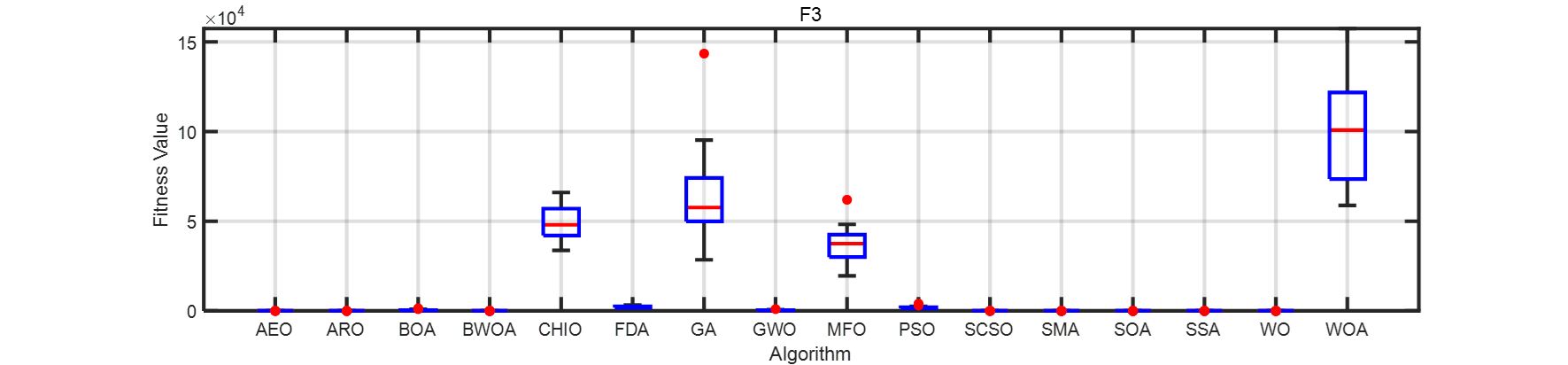
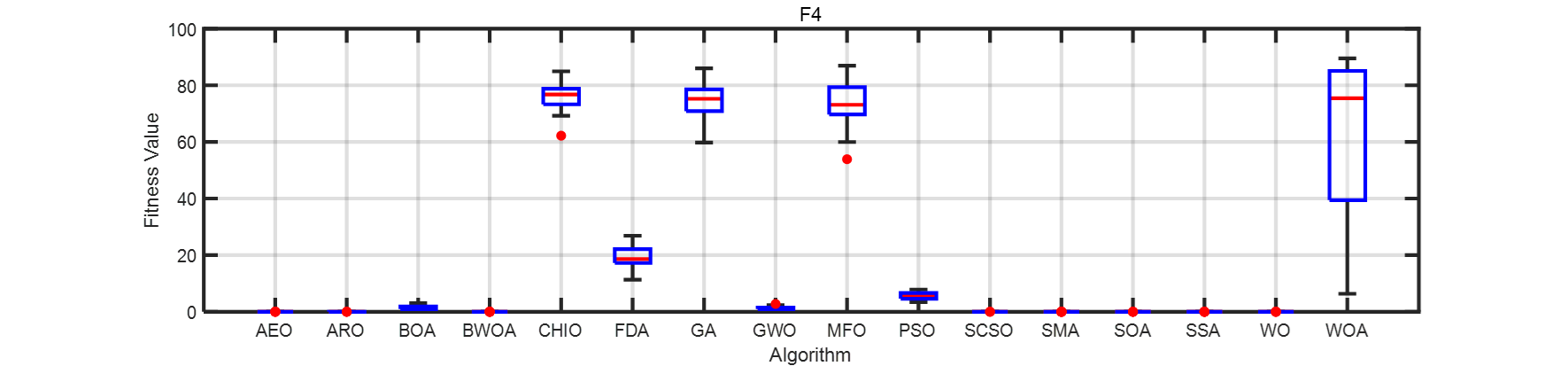
??畫了一個箱線圖。在此列出matlab代碼。
%% 穩定性分析
% 繪制箱線圖
clc;clear;close all
% 加載獨立運行得到的數據
load 20231107_30_100_30_16_PM.mat
% 填充算法名稱 從加載的數據中讀取
for i = 1:length(algorithms)temp = strsplit(algorithms{i},'.');algorithms(i)=temp(1);
end
% 繪制小提琴圖
for i=1:4F1 = resultall{i};figure('NumberTitle','off', ...'Color','w', ...'Name','穩定性分析', ...'Units','centimeters', ...'Position',[4,15,30,7])handelbox = boxchart(F1);box onset(gca,'xticklabels',algorithms, ...'LineWidth',2)xlabel('Algorithm')ylabel('Fitness Value')grid onhandelbox.BoxFaceColor = 'w';handelbox.BoxEdgeColor = 'b';handelbox.BoxMedianLineColor = 'r';handelbox.LineWidth = 2;handelbox.MarkerColor = 'r';handelbox.MarkerStyle = ".";handelbox.MarkerSize = 15;title(strcat('F',num2str(i)))
end
??5、靈敏性分析
??這個分析就是來尋找算法的最佳參數設置。文中選取了最大迭代次數,種群個數以及雄性個體占比三個參數。
??原文中,圖7 ( a )和( b )分別展示了F1在不同的最大迭代次數和搜索代理數下的WO收斂曲線。圖7 ( c )展示了WO在F5上的收斂曲線,以及不同比例的雄性個體在群體中的分布。計算結果和可視化表明,當最大迭代次數增加時,WO收斂到最優解。此外,從圖7 ( b )可以看出,當種群數量的數量增加時,迭代次數減少。圖7 ( c )顯示了當p從0.3到0.4時WO的相對穩定的行為。基于此分析,p的最佳值可以被建議為其最大值(即p = 0.45),其中WO的結果最好。
clear ;clc;close all
%% F5 6 12 13 14 15
populationSize = [30,50,80,100];
Max_iteration = [200,500,1000,2000];
p = [0.3,0.35,0.4,0.45];
populationSize=populationSize(4);
p = p(4);
fn=1;
Function_name=strcat('F',num2str(fn));
[lb,ub,dim,fobj]=Get_Functions_details(Function_name);
colormap = ['k','m','c','b'];
figure('Color','w')
for i=1:length(Max_iteration)rng('shuffle');[Best_score,Best_pos,WO_cg_curve]=WO(populationSize,Max_iteration(i),lb,ub,dim,fobj,p);semilogy(WO_cg_curve,colormap(i),'LineWidth',2)hold onend
set(gca,'XMinorGrid','on','YMinorGrid','on', ...'LineWidth',1)
legend({'T=200';'T=500';'T=1000';'T=2000'})
xlabel('Iteration')
ylabel('Best score obtained so far')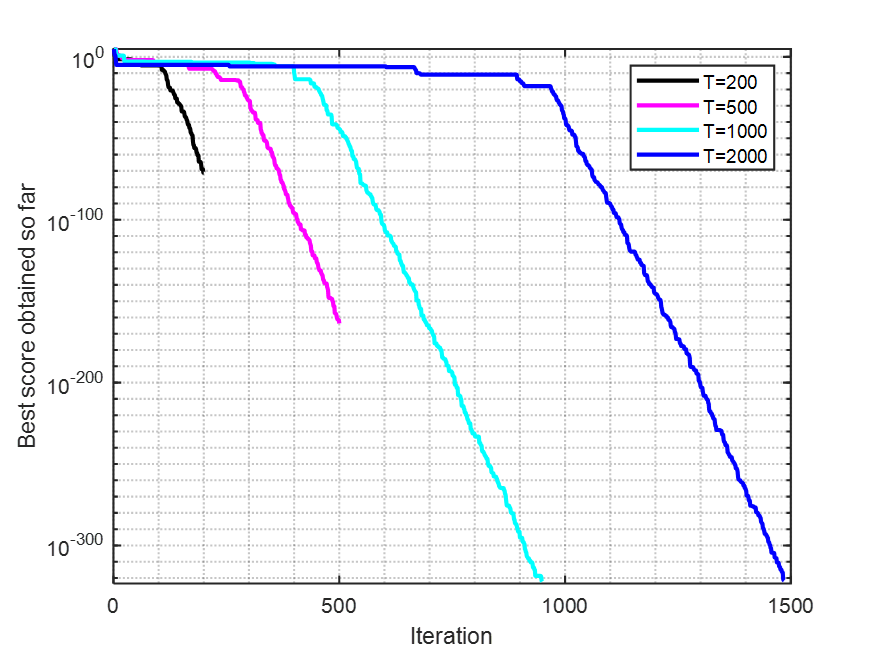
clear ;clc;close all
%% F5 6 12 13 14 15
populationSize = [30,50,80,100];
Max_iteration = [200,500,1000,2000];
p = [0.3,0.35,0.4,0.45];
Max_iteration =Max_iteration(4);
p = p(4);
fn=1;
Function_name=strcat('F',num2str(fn));
[lb,ub,dim,fobj]=Get_Functions_details(Function_name);
colormap = ['k','m','c','b'];
figure('Color','w')
for i=1:length(populationSize)rng('shuffle');[Best_score,Best_pos,WO_cg_curve]=WO(populationSize(i),Max_iteration,lb,ub,dim,fobj,p);semilogy(WO_cg_curve,colormap(i),'LineWidth',2)hold onend
set(gca,'XMinorGrid','on','YMinorGrid','on', ...'LineWidth',1)
% legend({'T=200';'T=500';'T=1000';'T=2000'})
legend({'N=30';'N=50';'N=80';'N=100'})
% legend({'T=200';'T=500';'T=1000';'T=2000'})
xlabel('Iteration')
ylabel('Best score obtained so far')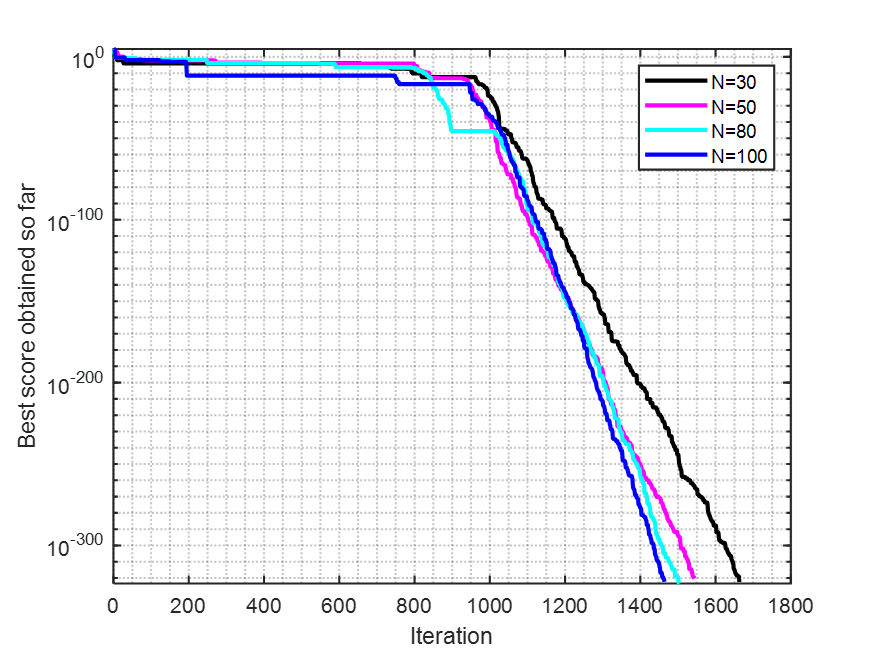
clear ;clc;close all
%% F5 6 12 13 14 15
populationSize = [30,50,80,100];
Max_iteration = [200,500,1000,2000];
p = [0.3,0.35,0.4,0.45];
populationSize=populationSize(4);
Max_iteration =Max_iteration(4);
fn=5;
Function_name=strcat('F',num2str(fn));
[lb,ub,dim,fobj]=Get_Functions_details(Function_name);
colormap = ['k','m','c','b'];
figure('Color','w')
for i=1:length(p)rng('shuffle');[Best_score,Best_pos,WO_cg_curve]=WO(populationSize,Max_iteration,lb,ub,dim,fobj,p(i));semilogy(WO_cg_curve,colormap(i),'LineWidth',2)hold onend
set(gca,'XMinorGrid','on','YMinorGrid','on', ...'LineWidth',1)
% legend({'T=200';'T=500';'T=1000';'T=2000'})
% legend({'N=30';'N=50';'N=80';'N=100'})
legend({'P=0.30';'P=0.35';'P=0.40';'P=0.45'})
xlabel('Iteration')
ylabel('Best score obtained so far')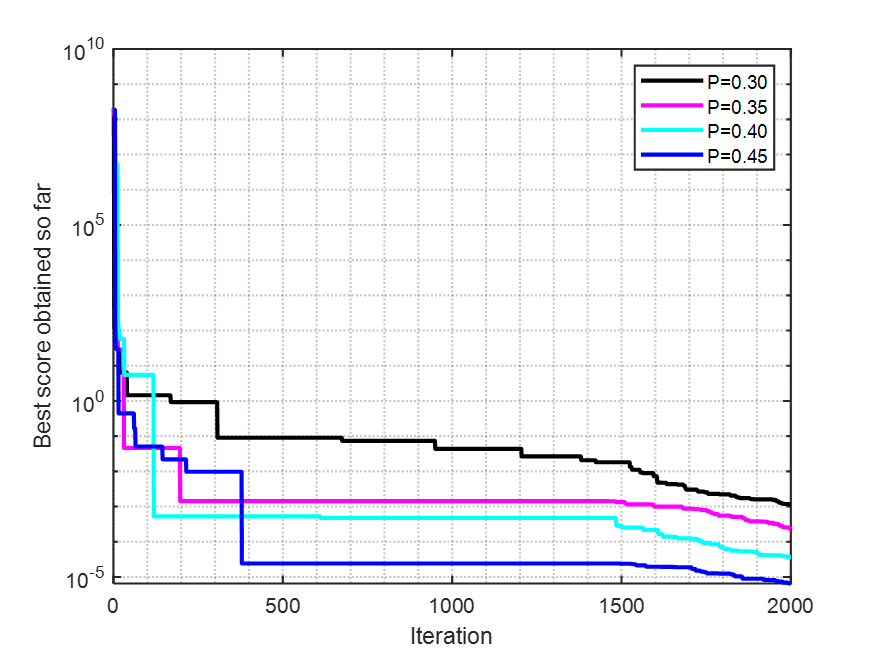
??從上面三幅圖中可以看出,T,N,P三個參數都有影響。種群個數和迭代次數的增加會導致算法時間上的增加,在做具體案例分析時,應該選擇合適的迭代次數和種群個數;P值的影響不會特別大,按照原文獻的介紹,我也用F5測試函數,想要達到文獻的效果。是需要多次運行的,這些P值在解決具體問題的時候,個人覺得不會影響特別大。P在[0.30,0.45]之間都可以。源代碼上P值默認設置的是0.4。
??6、可擴充性分析
??通過改變F1 ~ F13的維度來測試所提出的WO的可擴展性,以確定增加維度對不同測試函數計算結果的影響。測試函數的維度分別為50、100、500。文獻中對其進行了大量分析,用了13個測試函數,做了三個表格,感興趣的可以參考一下。最后對所有算法進行Friedman檢驗,做了一個排名,證明了所提算法的優越性。
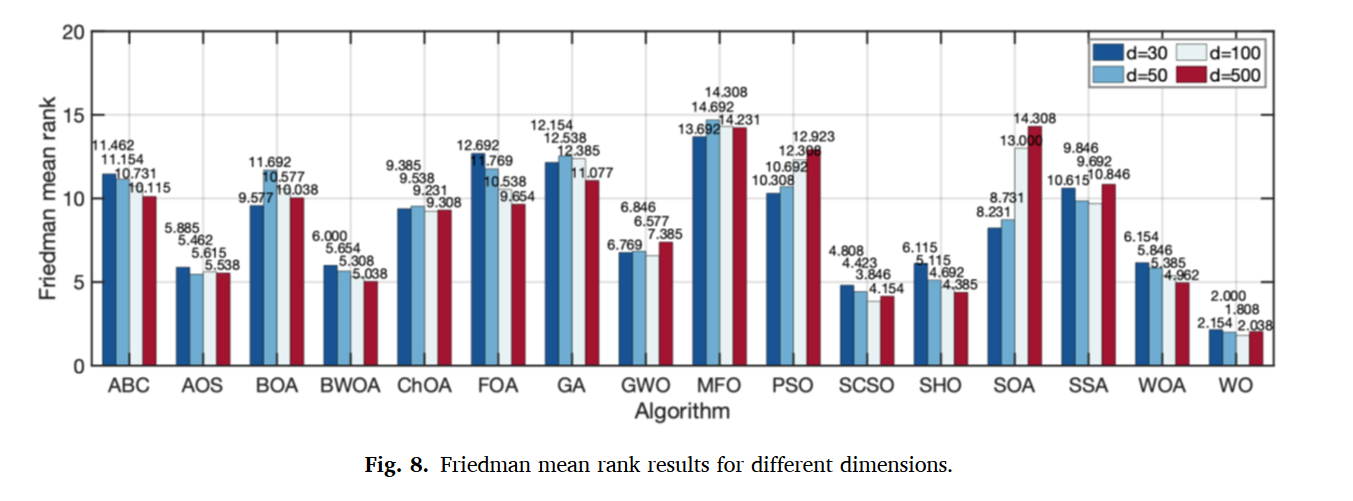
??結果表明,WO排在第一位,而SCSO、SHO和WOA分別排在第二位、第三位和第四位。
CEC2021測試函數
??測試函數下載地址
??這節中,作者又換了幾個算法。做了定量分析,收斂性分析和穩定性分析。我不再重復繪圖了。在這簡單說一下CEC系列的函數怎么使用吧。CEC系列的測試函數有很多,一般下載下來就會給你編譯好的matlab可執行文件,后綴名.mexw64。以CEC2017為例
??1. run the following command in Matlab window:
mex cec17_func.cpp -DWINDOWS
??2. Then you can use the test functions as the following example:
f = cec17_func(x,func_num);
here x is a D*pop_size matrix.
實際工程優化問題
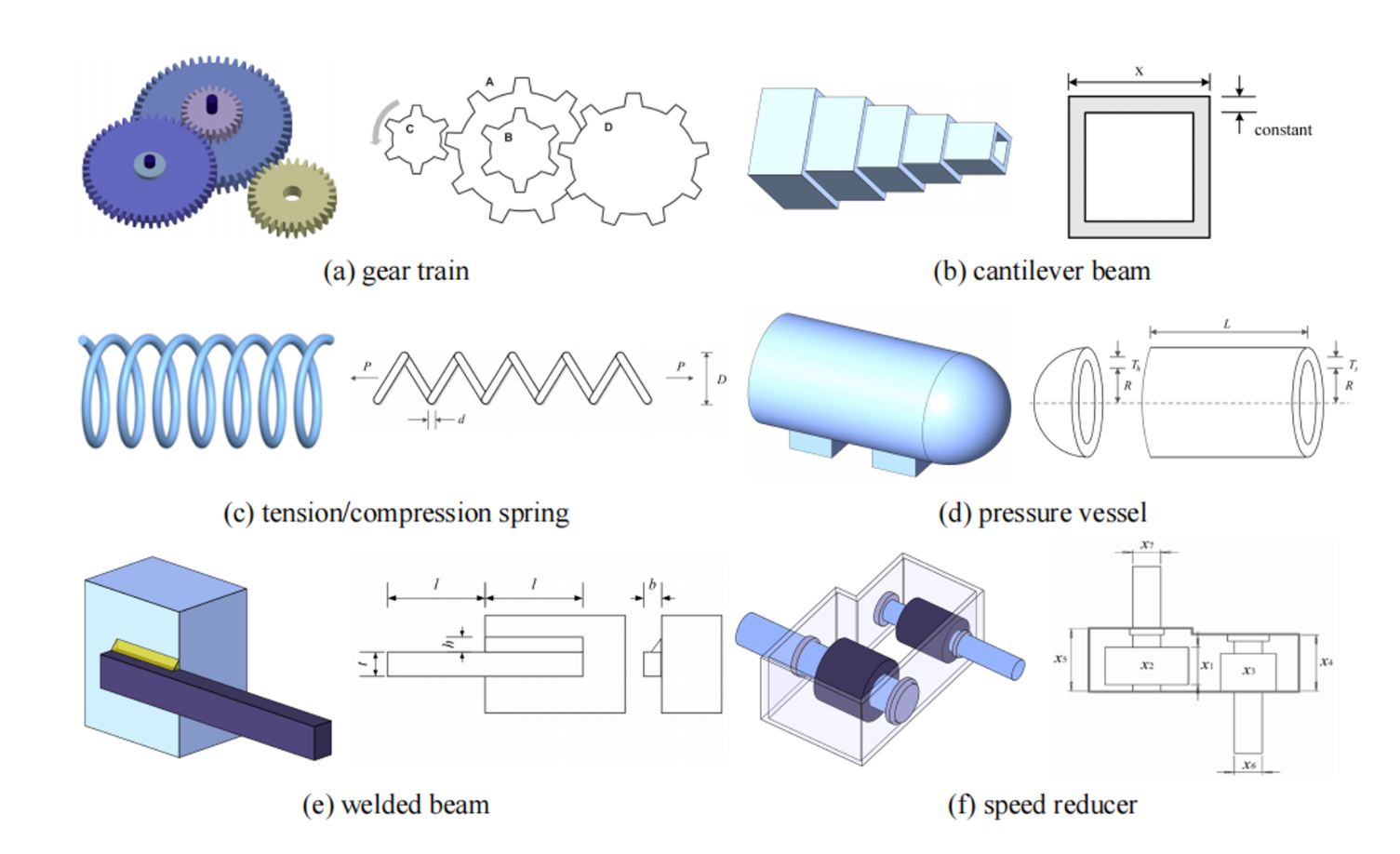

??經典工程優化malab代碼下載鏈接

??注:原文已經進行大量實驗結果分析,感興趣的請閱讀原文,學習學習一篇好的論文是怎么寫的。源代碼也已公開,我就不點運行和截圖了,大家自行下載。
??特別提示:不要買什么基本的算法,這些算法都是全網公開的,優秀的東西從來都不保密,不怕任何人抄襲的,各位不要再交智商稅了。

)




)





)

)
)



