Unsupervised MVS論文筆記
- 摘要
- 1 引言
- 2 相關工作
- 3 實現方法
Tejas Khot and Shubham Agrawal and Shubham Tulsiani and Christoph Mertz and Simon Lucey and Martial Hebert. Tejas Khot and Shubham Agrawal and Shubham Tulsiani and Christoph Mertz and Simon Lucey and Martial Hebert. arXiv: 1905.02706, 2019.
https://doi.org/10.48550/arXiv.1905.02706
摘要
在2019年6月6日,作者提出了一種基于學習的多視圖立體視覺(MVS)的方法。雖然目前的深度MVS方法取得了令人印象深刻的結果,但它們關鍵地依賴于真實的3D訓練數據,而獲取這種精確的3D幾何圖形用于監督是一個主要障礙。相反,作者的框架利用多個視圖之間的光度一致性作為監督信號,在一個較寬的基線MVS設置中學習深度預測。然而,僅用光度一致性約束是不可取的。為了克服這一問題,作者提出了一個有效的損失公式: a)強制一階一致性,b)對每個點,有選擇性地強制與一些視圖進行一致性,從而隱式地處理遮擋。在不使用真實數據集進行3D監督的情況下,此方法是有效的,并表明提出的有效損失每個組成部分都對重建結果具有顯著的改進。作者定性地觀察到,作者的重建往往比獲得的事實數據更完整,進一步顯示了這種方法的優點。
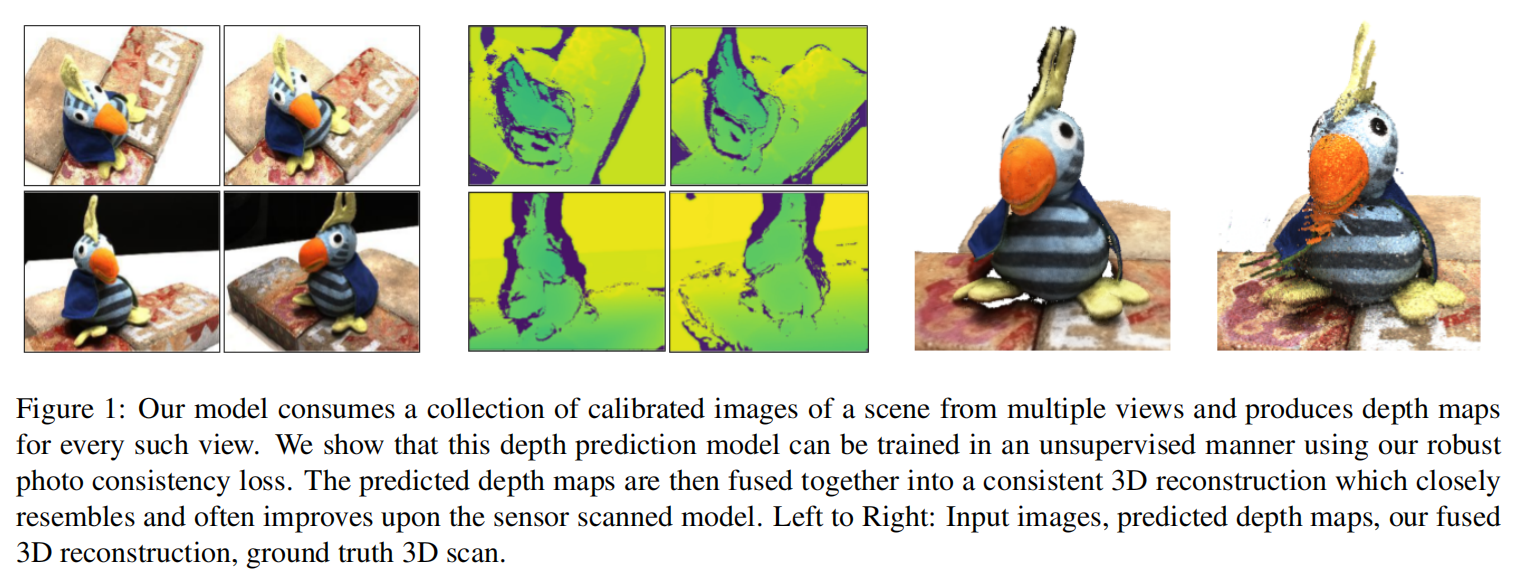
1 引言
從圖像中恢復場景密集的三維結構一直是計算機視覺的一個長期目標。多年來,有幾種方法通過利用潛在的幾何和光度約束來解決這個多視圖立體視覺(MVS)任務——一個圖像中的一個點沿著極線投射到另一個圖像上,并且正確的匹配在光學上是一致的。雖然實施這一見解導致了顯著的成功,但這些純粹的基于幾何的方法對每個場景獨立,并無法對世界隱式地捕獲和利用通用先驗,例如表面往往是平的,因此當信號稀疏時有時表現不佳,如無紋理表面。
為了克服這些限制,一項新興的工作集中于基于學習的MVS任務解決方案,通常訓練CNN來提取和合并跨視圖的信息。雖然這些方法產生了令人印象深刻的性能,但它們在學習階段依賴于真實的3D數據。作者認為,這種形式的監督過于繁瑣,不是自然可行的,因此,尋求不依賴這種3D監督的解決方案具有實用和科學意義。
作者建立在最近的這些基于學習的MVS方法的基礎上,這些方法呈現了具有幾何歸納偏差的CNN架構,但在用于訓練這些CNN的監督形式上存在顯著差異。作者不依賴于真實的三維監督,而是提出了一個以無監督的方式學習多視圖立體視覺的框架,僅依賴于多視圖圖像的訓練數據集。能夠使用這種形式的監督的見解類似于經典方法中使用的見解——正確的幾何形狀將產生光學上一致的重投影,因此可以通過最小化重投影誤差來訓練CNN。
雖然類似的重投影損失已經被最近的方法成功地用于其他任務,如單眼深度估計,但作者注意到,天真地將它們應用于學習MVS是不夠的。這是因為不同的可用圖像可能捕獲到不同的可見場景。因此,一個特定的點(像素)不需要在光度學上與所有其他視圖一致,而是只需要那些它沒有被遮擋的視圖。然而,明確地推理遮擋來恢復幾何,提出了一個雞和蛋的問題,因為遮擋的估計依賴于幾何,反之亦然。
為了避免這一點,作者注意到,雖然正確的幾何估計不需要與所有視圖的光度一致性,但它應該至少與某些視圖一致性。此外,在MVS設置中,跨視圖的照明變化也很重要,因此只在像素空間中強制執行一致性是不可取的,而作者認為強制執行額外的基于梯度的一致性。
作者提出了一個有效的重投影損失,使我們能夠捕獲上述要求的照片,并允許使用所需的監督形式學習MVS。該方法的公式允許處理遮擋,但沒有明確地為圖像建模。該方法的設置和示例輸出如上圖1所示。該模型在沒有三維監督的情況下進行訓練,以一組圖像作為輸入,預測每幅圖像的深度圖,然后將其結合起來,得到一個密集的三維模型。
總之,該論文的主要貢獻是:
1)提出一個以無監督的方式學習多視圖立體視覺的框架,只使用來自新視圖的圖像作為監督信號。
2)一種用于學習無監督深度預測的有效多視圖光度一致性損失,允許隱式地克服跨訓練視圖之間的照明變化和遮擋。
2 相關工作
多視圖立體視覺重建
關于MVS的工作有著悠久而豐富的歷史。在這里只討論有代表性的作品,感興趣的讀者可以進行相關調查。MVS的實現有四個主要步驟:視圖選擇、傳播方案、補丁匹配和深度圖融合。已經有研究為每個像素聚合多個視圖的方案,作者的構思可以看作是在訓練過程中通過損失函數整合了其中的一些想法。基于補丁匹配的立體匹配的方法取代了經典的種子和擴展傳播方案。補丁匹配已被用于多視圖立體視覺結合迭代實現傳播方案,深度估計和法線。深度圖融合將單個深度圖合并到一個單一點云中,同時確保結果點在多個視圖之間保持一致,并刪除不正確的估計。深度表示繼續主導MVS基準測試和尋找深度圖像作為輸出的方法,從而將MVS問題解耦成更易于處理的部分。
基于學習的MVS
利用CNN學習到的特征能夠很自然地適合于MVS的第三步:匹配圖像補丁。CNN特征已被用于立體匹配,同時使用度量學習來定義相似度的概念。這些方法需要一系列的后處理步驟來最終生成成對的視差圖。專注于學習MVS所有步驟的工作相對較少。體素表示自然地從不同的視圖編碼表面可見性,這已經在一些工作中得到證實。選擇這種表示的常見缺點是不清楚如何將它們縮放到更多樣化和大規模的場景。有些工作使用CNN特征創建代價體,視差值通過可微soft argmin操作回歸獲得。結合上述方法的優點,并借鑒經典方法的見解,最近的工作為多個視圖生成深度圖像,并將它們融合以獲得三維重建。至關重要的是,上述所有方法都依賴于3D監督,本篇工作放寬了這一要求。
無監督深度估計
由于減少監督需求的類似動機,最近的一些單目]或雙目立體深度預測方法利用了光度一致性損失。作為監督信號,這些圖像依賴于訓練過程中來自雙目圖像對或單目視頻的圖像。作為可見性推理的手段,網絡用于預測可解釋性、失效掩模或通過加入觀察置信度的概率模型。這些方法在一個狹窄的基線設置上運行,在訓練過程中使用的幀之間的視覺變化有限,因此不會由于遮擋和照明變化而遭受顯著的影響。當前的目標是在MVS設置中利用光度損失進行學習,因此Unsupervised MVS提出一個有效的構思來處理這些挑戰。



)

)
)





)






