Redis 主從復制如何同步數據呢?
參考文章:https://blog.csdn.net/Seky_fei/article/details/106877329
https://zhuanlan.zhihu.com/p/55532249
https://cloud.tencent.com/developer/article/2063597
https://xie.infoq.cn/article/4cffee02a2a12c2450412fa21
在 Redis2.8 之后,進行主從同步使用 psync 命令,在 2.8 之前使用 sync 命令,sync 在斷線情況下會進行全量復制,效率很低,因此使用 psync 命令進行改進,具備了 全量同步 和 部分同步 的功能
psync 命令格式如下:
# runid 為 master 的身份 id
# offset 是從節點同步命令的偏移量
psync [runid] [offset]
那么在從節點第一次同步主節點數據時,會向主節點發送 psync ? -1 命令,那么 master 收到命令后,匹配 runid,如果匹配成功,會使用 bgsave 生成 RDB 文件快照,并將 RDB 文件發送給 slave,slave 在收到 RDB 快照后將數據載入
如果從節點是斷線之后重新連接上主節點,那么在同步數據時,會向主節點發送 psync runid offset ,那么 master 在收到命令之后,如果 runid 匹配成功,會判斷 offset 這個偏移量與 master 本機的數據緩存的偏移量相差是否超過了 復制積壓緩沖區 的大小,如果超過了,說明 slave 斷線時間太長了,master 的 復制積壓緩沖區 中的數據已經和 slave 的數據不連續了,因此進行全量復制;否則,就進行增量復制,將 slave 斷線期間沒有收到的數據給發送一下就可以了
主節點在接收到命令時,如何保存命令并將命令增量復制給從節點?
master 在接收命令時,將命令傳遞給 slave 的同時,也會將命令存放到 復制積壓緩沖區,并且記錄當前積壓隊列中存放命令的偏移量 offset,當 slave 重連時,master 會根據 slave 傳的 offset 和自己最新命令的 offset 進行比較,如果相差的大小超過 復制積壓緩沖區 的大小,就直接進行全量復制;否則,就增量復制
復制積壓緩沖區 其實就是一個環形的循環隊列,默認大小為 1MB,該緩沖區大小越大,允許 slave 斷線的時間就越長
#設置復制積壓緩沖區大小
repl-backlog-size 1mb
Redis 4.0 PSYNC2.0
在 Redis2.8 之后,使用 psync runid offset 來實現增量同步,但是如果發生了主從切換,那么新的 master 的 runid 和 offset 都會發生變化,因此還是需要全量復制
在 Redis4.0 的 PSYNC2.0 中優化了這個問題,即使發生了主從切換,如果條件允許,也可以進行增量同步
那么在 PSYNC2.0 中,舍棄了 runid 的概念,使用 replid 和 replid2 來代替,并且 replid2 和 second_replid_offset 是一對:
- 對 master 來說,
replid就是自己的復制 id,沒有發生主從切換之前,replid2為空,發生主從切換之后,新的 master 的replid2是舊 master 的 replid - 對 slave 來說,
replid保存的是自己當前正在同步的 master 的replid,replid2保存的舊 master 的 replid
second_replid_offset 記錄了上一次復制的主庫的 offset
psync2.0中如何判斷增量復制?
從節點向主節點發送同步請求,那么主節點需要判斷兩個東西:
-
從節點的 offset 是否在
復制積壓緩沖區中 -
判斷復制歷史是否一樣
判斷復制歷史首先 master 要判斷 replid 是否一致,也就是從節點的 replid 和 master 的 replid2 相同,如果一致(表明新的主節點和從節點之前都是復制的同一個主節點),再來判斷這個 offset 是否在上一次的 second_replid_offset,如果也在的話,就可以進行增量同步
下邊這個例子說明一下為什么 offset 要在上一次的 second_replid_offset 中:
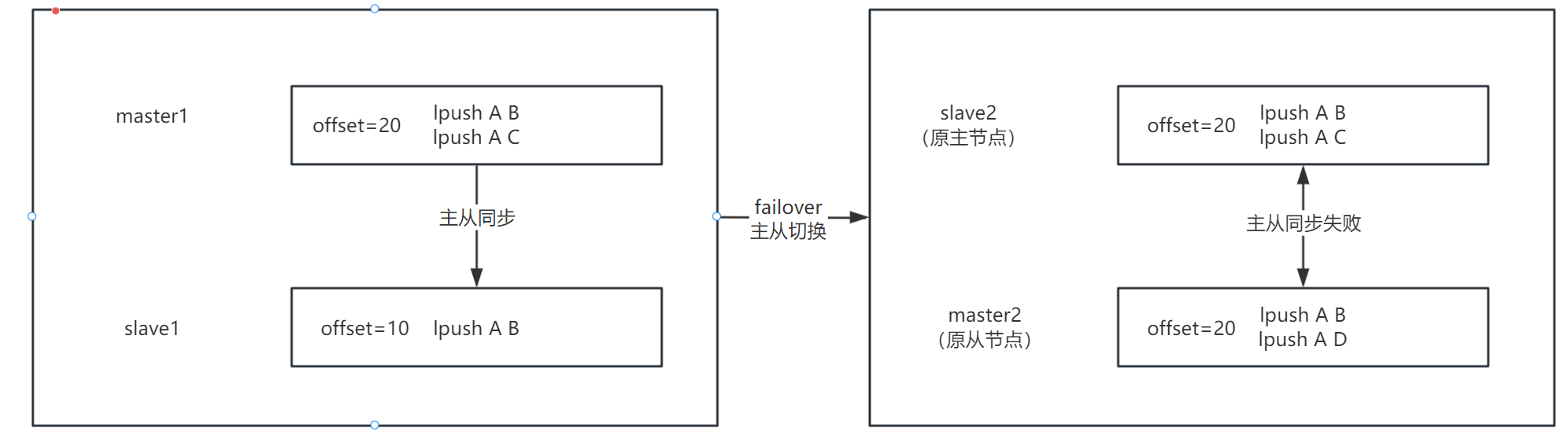
比如一主一從機器來說,master1 和 slave1,master1 中寫入兩條數據:
# master1
lpush A B
lpush A C
我們假設一條數據偏移量為 10,那么在 master1 中插入兩條數據,master1 的 offset = 20,此時 master1 和 slave1 主從復制,slave1 在復制完第一條數據之后,也就是 lpush A B 之后,failover 后 slave1 變為新的 master,我們先稱原 slave1 為 master2,原 master1 為 slave2
那么 master2 又會接收新的請求,假如在 master2 中寫入如下數據:
# master2
lpush A D
那么此時 master2 中也有兩條數據了,如上圖,在發生主從切換之后,master2 和 slave2 的 offset 都是 20,是相同的,但是他們兩個能進行增量復制嗎?
肯定不可以,雖然他們的 offset 是相同的,但是他的復制上下文已經變了,原來的 slave 進行主從復制是基于
lpush A B
lpush A C
這個上下文來進行復制的,那么在主從切換之后,新的主庫寫入了新的數據,新主庫的上下文已經變為了:
lpush A B
lpush A D
和原來主庫的上下文都不同了,那么只單純比較 offset 是沒有意義的,所以需要拿 offset 和 second_replid_offset 進行比較
PSYNC-AOF【擴展內容】
詳細參考:Redis 主從復制演進歷程與百度智能云的實踐
百度智能云提出了 - PSYNC-AOF 方案
在 Redis 的主從復制中存在的問題,首先就是內存,Redis 的數據都存儲在內存中,Backlog(復制積壓緩沖區) 也在內存中,那么內存容量是有限的,當主從連接斷開重連后,從庫在主庫的 Backlog 中查找數據,因為 Backlog 容量是有限的,所以查找數據也有限,那么如果主從斷連時間過長的話,就在 Backlog 中找不到對應的數據,就需要進行全量復制了
那么 PSYNC-AOF 方案中,將 AOF 的內容和 Backlog 內容保持一致,主從斷連后,從庫去主庫的 Backlog 中查找數據,那么如果沒有找到的話,嘗試從 AOF 里找,那么通過 RDB 文件作為基準,AOF 作為增量,就可以實現一個更大的 復制積壓緩沖區 ,從而可以應對更長的網絡延遲以及網絡斷開。
總結:總之,主從復制的痛點在于如果主從連接斷開時間過長,或者發生主從切換,會導致全量復制,全量復制很傷,所以優化主從數據同步的目的就是盡可能地避免全量復制

)

,一行代碼解決顯示對齊問題!)

生成驗證碼)
:模塊緩存清理工具)

![[補題記錄] Complete the Permutation(貪心、set)](http://pic.xiahunao.cn/[補題記錄] Complete the Permutation(貪心、set))









:導入導出和發送請求查看響應)
