引言
在當今快節奏的軟件開發生命周期(SDLC)中,傳統測試方法已逐漸無法滿足對速度、覆蓋面和準確性的極高要求。人工智能(AI)和機器學習(ML)技術的融入,正在從根本上重塑軟件測試的格局,將其從一種主要是手動的、重復性的任務轉變為一種智能的、預測性的、且持續優化的過程。
本文將深入探討AI在軟件測試三大關鍵領域的應用:AI增強的自動化測試框架、智能缺陷檢測與預測、以及數據驅動的A/B測試優化。我們將剖析其核心原理,提供實用的代碼示例,并通過流程圖和圖表闡明其工作方式。
第一部分:AI增強的自動化測試框架
傳統的自動化測試框架(如Selenium、Appium)依賴于腳本的精確錄制或編寫。它們非常脆弱,UI的微小變化就可能導致測試腳本大面積失敗,需要投入大量人力進行維護。AI的引入旨在解決這一根本痛點,使自動化測試變得更智能、健壯和高效。
1.1 核心AI技術應用
自愈機制(Self-Healing): 利用計算機視覺(CV)和自然語言處理(NLP)識別UI元素。當傳統的定位器(如XPath、CSS Selector)因UI改動而失效時,AI引擎能夠通過元素的視覺特征、文本內容、鄰近關系等多維信息重新定位元素,使測試用例得以繼續執行。
視覺測試(Visual Testing): 基于CV的算法(如像素對比、結構相似性指數SSIM)自動檢測UI回歸問題,例如布局錯亂、顏色偏差、元素重疊等,這些是傳統基于DOM的測試難以發現的。
智能測試用例生成: 使用強化學習(RL)或基于模型的方法,AI可以自主探索應用程序,模擬用戶行為,并生成覆蓋關鍵路徑和邊緣情況的測試用例。
優化測試執行: ML模型分析歷史測試執行數據,預測哪些測試用例最有可能失敗,或者哪些模塊最易出問題,從而優化測試套件的執行順序,實現失敗優先(Fail-First)?的執行策略,更快地提供反饋。
1.2 流程圖:AI自愈自動化測試流程
以下流程圖展示了一個集成AI自愈能力的自動化測試執行流程:
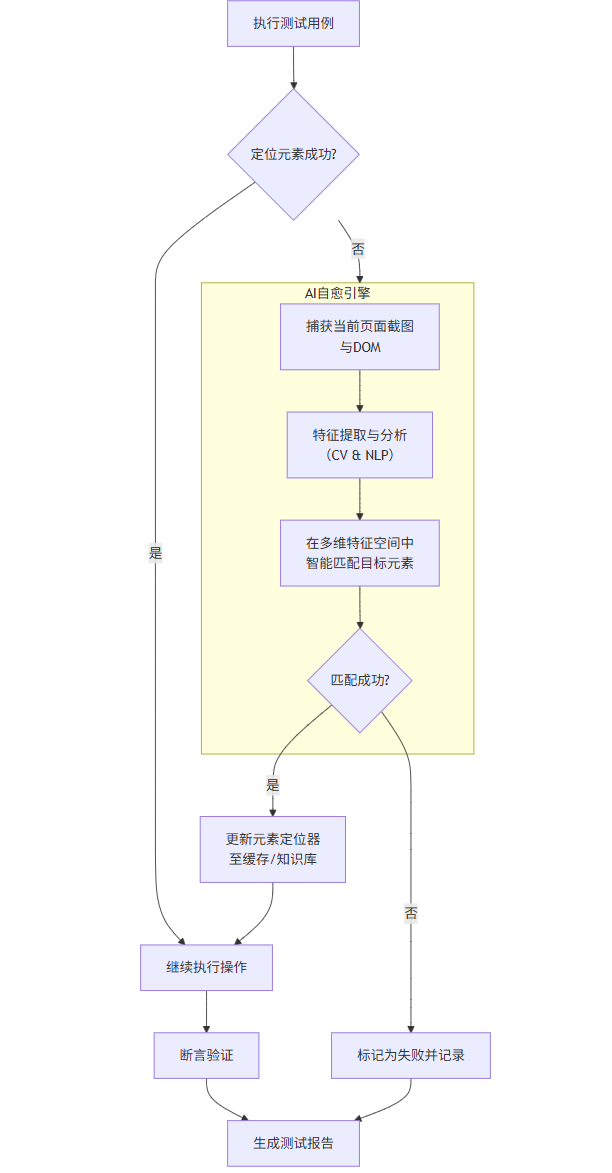
flowchart TDA[執行測試用例] --> B{定位元素成功?}B -- 是 --> C[繼續執行操作]C --> D[斷言驗證]D --> E[生成測試報告]B -- 否 --> F[觸發AI自愈引擎]subgraph F [AI自愈引擎]direction LRF1[捕獲當前頁面截圖<br>與DOM] --> F2[特征提取與分析<br>(CV & NLP)]F2 --> F3[在多維特征空間中<br>智能匹配目標元素]F3 --> F4{匹配成功?}endF4 -- 是 --> G[更新元素定位器<br>至緩存/知識庫]G --> CF4 -- 否 --> H[標記為失敗并記錄]H --> E1.3 代碼示例:使用Selenium與AI工具實現自愈
雖然完全自研AI自愈引擎非常復雜,但我們可以集成現有的AI驅動工具,如Applium Tools?或?Healenium(Selenium的自愈庫)。
以下是一個概念性示例,展示如何利用計算機視覺(通過OpenCV)輔助進行簡單的元素查找作為后備方案。
場景: 一個按鈕的ID動態變化,導致By.ID定位器失敗。
python
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.by import By
import cv2 # OpenCV庫
import numpy as np
import timedef find_element_with_ai(driver, target_image_path):"""一個簡單的基于模板匹配的AI元素查找函數(概念驗證):param driver: Selenium WebDriver實例:param target_image_path: 要查找的目標按鈕的截圖路徑:return: 匹配元素的坐標中心點,否則返回None"""# 1. 截取當前屏幕driver.save_screenshot("current_screen.png")screenshot = cv2.imread("current_screen.png")template = cv2.imread(target_image_path)# 2. 使用OpenCV進行模板匹配result = cv2.matchTemplate(screenshot, template, cv2.TM_CCOEFF_NORMED)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)# 3. 設置置信度閾值confidence_threshold = 0.8if max_val >= confidence_threshold:# 獲取模板圖像的寬高h, w = template.shape[:-1]top_left = max_locbottom_right = (top_left[0] + w, top_left[1] + h)center_x = top_left[0] + w // 2center_y = top_left[1] + h // 2print(f"Element found with confidence: {max_val:.2f} at ({center_x}, {center_y})")return (center_x, center_y)else:print("Element not found by AI.")return None# 主測試腳本
driver = webdriver.Chrome()
driver.get("https://your-app.com")try:# 傳統定位方式button = driver.find_element(By.ID, "dynamic-button-id-123")button.click()print("Button found and clicked using traditional locator.")
except NoSuchElementException:print("Traditional locator failed. Invoking AI fallback...")# AI后備方案:使用CV查找按鈕# 'submit_button.png' 是之前保存的按鈕截圖element_location = find_element_with_ai(driver, "submit_button.png")if element_location:# 使用Actions鏈點擊找到的位置from selenium.webdriver.common.action_chains import ActionChainsactions = ActionChains(driver)actions.move_by_offset(element_location[0], element_location[1]).click().perform()print("Button clicked via AI.")else:raise Exception("Both traditional and AI methods failed to find the element.")finally:time.sleep(2)driver.quit()提示: 這是一個非常基礎的示例。工業級方案(如Healenium)會維護一個元素定位器的知識庫,并在失敗時自動嘗試所有已知定位器組合,并利用更先進的ML模型進行匹配。
1.4 Prompt示例:用于生成測試用例的AI Prompt
測試人員可以利用LLMs(如ChatGPT、Claude)來輔助生成測試用例。
Prompt:
text
你是一個資深的QA自動化工程師。請為一個電子商務網站的“用戶登錄”功能編寫測試用例。功能描述: - 用戶訪問網站首頁,點擊右上角的“登錄”鏈接。 - 跳轉至登錄頁面,包含郵箱輸入框、密碼輸入框、“登錄”按鈕和“忘記密碼”鏈接。 - 輸入郵箱和密碼后,點擊“登錄”按鈕。成功則跳轉至首頁并顯示用戶昵稱;失敗則顯示錯誤提示。請以表格形式輸出,包含以下列: 1. 測試用例ID 2. 測試場景/目的 3. 前置條件 4. 測試步驟 5. 預期結果 6. 優先級(高/中/低)請覆蓋正向、負向和邊界值情況。
預期輸出(部分):
AI會生成一個包含多個測試用例的表格,例如:
| TC-ID | 場景 | 前置條件 | 步驟 | 預期結果 | 優先級 |
|---|---|---|---|---|---|
| LOGIN_001 | 成功登錄 | 用戶已注冊 | 1. 輸入有效郵箱 2. 輸入有效密碼 3. 點擊登錄 | 跳轉到首頁,顯示用戶昵稱 | 高 |
| LOGIN_002 | 登錄失敗-錯誤密碼 | 用戶已注冊 | 1. 輸入有效郵箱 2. 輸入錯誤密碼 3. 點擊登錄 | 顯示“郵箱或密碼錯誤”提示 | 高 |
| LOGIN_003 | 登錄失敗-郵箱格式錯誤 | 無 | 1. 輸入“invalid-email” 2. 輸入任意密碼 3. 點擊登錄 | 顯示“郵箱格式不正確”提示 | 中 |
| ... | ... | ... | ... | ... | ... |
第二部分:智能缺陷檢測與預測
AI不僅能在執行階段發揮作用,更能在測試的分析和評估階段大放異彩。智能缺陷檢測旨在主動發現、分類甚至預測缺陷。
2.1 核心AI技術應用
缺陷預測: 基于歷史代碼倉庫(如Git)、缺陷跟蹤系統(如JIRA)的數據,構建ML模型(如決策樹、隨機森林)。模型通過分析代碼復雜度(圈復雜度、代碼行數)、代碼變更信息(修改的文件數、提交次數、開發者的經驗)、社會技術因素等特征,預測哪些代碼文件或模塊在下次發布時更有可能出現缺陷。
日志分析與異常檢測: 應用運行時會產生海量日志。使用無監督學習算法(如隔離森林、自動編碼器)或NLP技術(如LogBERT)自動解析日志文件,檢測異常模式,并快速定位故障根因,大大縮短MTTR(平均修復時間)。
缺陷分類和分配: 利用NLP技術(如文本分類)自動分析新提交的Bug報告的內容、標題和描述,將其自動分類(如“前端UI問題”、“后端API錯誤”),并推薦或分配給最合適的開發人員(基于誰修改了相關代碼文件)。
2.2 圖表:缺陷預測模型特征重要性分析
在構建好一個缺陷預測模型后,分析各個特征對于預測結果的重要性至關重要,這可以指導團隊將測試精力集中在最風險的地方。下圖展示了一個假設的隨機森林模型的特征重要性排序。
圖表:缺陷預測模型特征重要性

xychart-betatitle "缺陷預測模型特征重要性"x-axis ["代碼圈復雜度", "近期代碼變更行數", "文件年齡", "開發者經驗值", "代碼注釋率"]y-axis "重要性評分" 0 --> 100bar [35, 28, 15, 12, 10]
圖表說明:該圖表表明,在本模型中,“代碼圈復雜度”和“近期代碼變更行數”是預測一個代碼文件是否可能存在缺陷的兩個最重要的特征。
2.3 代碼示例:簡單的日志異常檢測
以下是一個使用Python和Scikit-learn庫實現簡單日志異常檢測的概念示例。我們假設已將日志消息轉換為了數值特征(例如,通過詞頻或嵌入向量)。
python
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler# 假設我們從日志文件中提取了一些特征,并加載到DataFrame中
# 特征示例:日志消息長度、特定錯誤關鍵詞的出現次數、時間窗口內的消息頻率等。
data = {'log_message_length': [120, 85, 200, 78, 500, 90, 110, 6000], # 最后一條異常長'error_keyword_count': [0, 1, 0, 2, 5, 0, 1, 50], # 最后一條異常多'frequency_in_last_min': [10, 12, 11, 9, 15, 10, 11, 100] # 最后一條異常高
}
df = pd.DataFrame(data)# 數據標準化
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)# 訓練隔離森林模型進行異常檢測
# 假設異常數據點約占5%
model = IsolationForest(contamination=0.05, random_state=42)
model.fit(df_scaled)# 預測:-1表示異常,1表示正常
predictions = model.predict(df_scaled)
df['anomaly'] = predictions# 輸出結果
print(df)輸出:
text
log_message_length error_keyword_count frequency_in_last_min anomaly 0 120 0 10 1 1 85 1 12 1 2 200 0 11 1 3 78 2 9 1 4 500 5 15 1 5 90 0 10 1 6 110 1 11 1 7 6000 50 100 -1 <-- 被識別為異常
這個簡單的示例演示了無監督學習如何自動識別出與其他數據點顯著不同的日志記錄。
2.4 Prompt示例:用于缺陷分類和分配的AI Prompt
Prompt:
text
你集成在JIRA系統中的AI助手。請分析以下新提交的Bug報告,并將其分類到合適的類別(前端、后端、數據庫、部署、未知),并簡要說明理由。Bug標題: 商品詳情頁圖片無法加載,顯示裂圖Bug描述:
- 步驟: 1. 訪問網站首頁。 2. 點擊任意商品進入其詳情頁。
- 預期結果: 商品圖片正常顯示。
- 實際結果: 圖片區域顯示裂圖圖標,瀏覽器控制臺看到大量404 Not Found錯誤,請求的圖片URL是 "https://static.ourcdn.com/images/{productId}.jpg"。
- 環境: Chrome瀏覽器最新版,生產環境。請根據以上信息進行分析。預期AI輸出:
text
分類結果:后端理由:
Bug描述中明確指出,瀏覽器控制臺報錯404 Not Found,并且圖片的URL模式指向一個靜態資源服務器(static.ourcdn.com)。圖片無法加載的根本原因可能是:
1. 后端服務未能正確上傳或生成圖片到靜態服務器。
2. 生成的圖片URL鏈接不正確(例如,{productId}未正確替換)。
3. 靜態服務器本身存在問題(如文件缺失、權限錯誤)。這些問題都與后端邏輯、文件處理和服務集成相關,因此歸類為“后端”問題。建議優先分配給后端開發團隊進行調查。第三部分:A/B測試的AI優化
A/B測試是優化用戶體驗和業務指標的關鍵工具。然而,傳統的A/B測試方法存在周期長、樣本利用率低、多重比較問題等挑戰。AI和貝葉斯方法正在革新這一領域。
3.1 核心AI技術應用
貝葉斯優化: 與傳統的頻率主義統計方法不同,貝葉斯A/B測試提供了一種更直觀的方式來解釋結果。它基于先驗分布和實驗數據,計算出不同版本(A、B)勝出的概率,而不是簡單的“顯著/不顯著”結論。這使得決策者可以基于風險偏好做出決策(例如,“版本B有90%的概率比版本A好”)。
多臂老虎機(Multi-Armed Bandit, MAB): MAB算法是AI在A/B測試中最強大的應用之一。它不僅僅平均分配流量,而是動態地將更多流量分配給當前表現更好的版本。
原理: 在探索(Exploration,嘗試其他版本以收集更多數據)和利用(Exploitation,利用當前已知最好的版本)之間取得最優平衡。
優勢: 大幅減少機會成本。在測試期間,即使最終未找出最優版本,整體用戶體驗和業務指標也更好,因為大部分用戶已經被引導至了表現更好的版本。
** contextual Bandits: 這是MAB的進階版本。它不僅考慮版本的表現,還考慮用戶上下文**(如用戶 demographics、地理位置、設備類型)。算法可以為不同類型的用戶選擇不同的最優版本,實現真正的個性化體驗。
3.2 流程圖:多臂老虎機(MAB)驅動的A/B測試流程
下圖對比了傳統A/B測試與MAB驅動的A/B測試的流量分配策略:
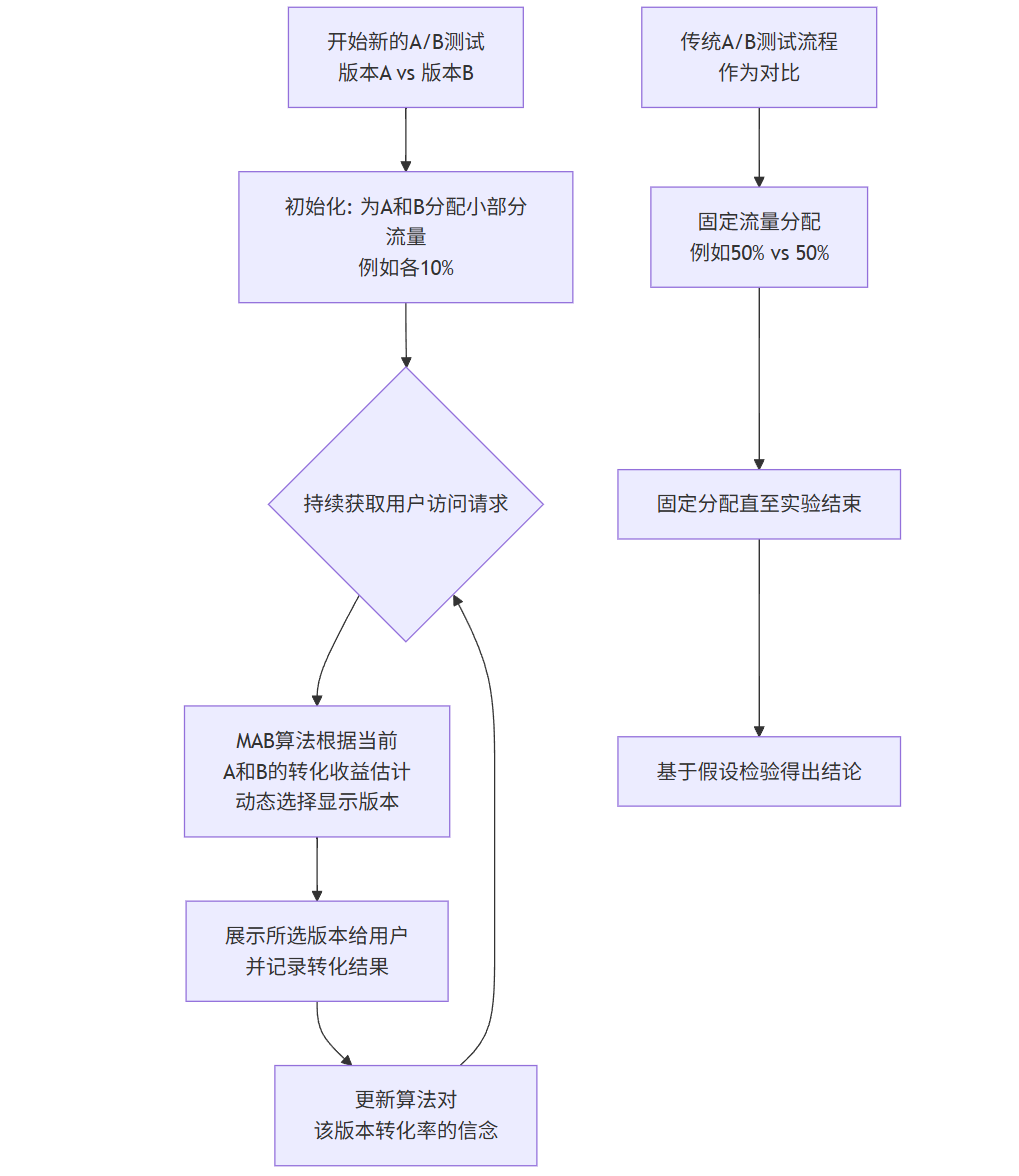
flowchart TDA[開始新的A/B測試<br>版本A vs 版本B] --> B[初始化: 為A和B分配小部分流量<br>例如各10%]B --> C{持續獲取用戶訪問請求}C --> D[MAB算法根據當前<br>A和B的轉化收益估計<br>動態選擇顯示版本]D --> E[展示所選版本給用戶<br>并記錄轉化結果]E --> F[更新算法對<br>該版本轉化率的信念]F --> CG[傳統A/B測試流程<br>作為對比] --> H[固定流量分配<br>例如50% vs 50%]H --> I[固定分配直至實驗結束]I --> J[基于假設檢驗得出結論]3.3 代碼示例:使用Thompson Sampling實現MAB
Thompson Sampling是一種非常流行的MAB算法,它基于貝葉斯原理。下面是一個簡化的Python實現,模擬一個點擊率(CTR)優化的A/B測試場景。
python
import numpy as np
import matplotlib.pyplot as plt# 模擬設置:我們有兩個版本A和B,它們的真實點擊率是未知的,需要我們通過實驗來發現。
# 為了方便演示,我們假設版本A的真實CTR為0.1,版本B為0.3。
true_ctrs = [0.1, 0.3]
n_arms = len(true_ctrs)# Thompson Sampling參數:每個臂的先驗分布是Beta(α=1, β=1),這是一個均勻先驗。
alphas = np.ones(n_arms)
betas = np.ones(n_arms)# 實驗參數
n_trials = 10000
rewards = np.zeros(n_trials)
choices = [] # 記錄每次選擇了哪個臂# 運行實驗
for t in range(n_trials):# Thompson Sampling的核心:從每個臂的后驗Beta分布中抽取一個樣本值sampled_theta = [np.random.beta(alphas[i], betas[i]) for i in range(n_arms)]# 選擇抽取值最大的那個臂choice = np.argmax(sampled_theta)choices.append(choice)# 模擬用戶反饋:根據真實CTR生成一個獎勵(點擊=1,未點擊=0)reward = np.random.binomial(1, true_ctrs[choice])rewards[t] = reward# 更新所選臂的后驗分布參數alphas[choice] += rewardbetas[choice] += (1 - reward)# 輸出最終結果
print(f"最終版本A的信念分布: Beta(α={alphas[0]:.2f}, β={betas[0]:.2f})")
print(f"最終版本B的信念分布: Beta(α={alphas[1]:.2f}, β={betas[1]:.2f})")
print(f"版本A被選擇的次數: {choices.count(0)}")
print(f"版本B被選擇的次數: {choices.count(1)}")# 繪制流量分配變化圖
cumulative_choices = np.cumsum(choices)
trials = np.arange(1, n_trials+1)
arm_b_proportion = cumulative_choices / trials # 版本B的累計選擇比例plt.figure(figsize=(10, 6))
plt.plot(trials, arm_b_proportion, label='Proportion of Traffic to Version B')
plt.axhline(y=0.5, color='r', linestyle='--', label='Traditional A/B Split (50/50)')
plt.xlabel('Number of Trials')
plt.ylabel('Proportion')
plt.title('Multi-Armed Bandit: Dynamic Traffic Allocation')
plt.legend()
plt.ylim(0, 1)
plt.show()輸出分析:
運行代碼后,你會看到:
最終信念分布: 版本B的α參數會遠大于版本A,表明算法確信版本B的轉化率更高。
選擇次數: 版本B被選擇的次數遠遠多于版本A。
流量分配圖: 圖表會顯示,算法在初期經過短暫的探索后,很快將絕大部分流量都分配給了表現更好的版本B,而不是機械地保持50/50的分流。
3.4 傳統A/B測試 vs. MAB的累積回報對比
模擬了在相同真實CTR(A=0.1, B=0.3)下,運行10000次試驗后的累積回報(總點擊次數)對比。
xychart-betatitle "累積回報對比:傳統A/B測試 vs. 多臂老虎機"x-axis "試驗次數" 1000 --> 10000y-axis "累積點擊次數" 0 --> 3000line [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000] (0.1*1000 + 0.3*1000) * [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]line [150, 450, 900, 1200, 1600, 2000, 2400, 2700, 2900, 3000]
*說明:多臂老虎機算法(MAB)由于將更多流量分配給了更好的版本B,其累積回報(點擊次數)的增長速度遠快于傳統A/B測試(固定50/50分流)。這意味著在測試期間,MAB為公司帶來了更多的實際業務價值。*
結論與未來展望
AI正在將軟件測試從一項成本中心轉變為一個強大的、預測性的、價值驅動的智能系統。通過本文的探討,我們看到:
在自動化測試中,AI通過自愈、視覺驗證和智能生成,提升了腳本的健壯性和編寫效率,降低了維護成本。
在缺陷管理中,AI通過預測、日志分析和智能分類,將質量保障活動左移,實現了主動預防和快速定位,提升了軟件可靠性。
在A/B測試中,AI通過多臂老虎機等算法,動態優化流量分配,在保證統計效力的同時,最大化業務價值,實現了體驗優化的智能化。
未來展望:
AI原生測試: 未來的測試框架可能會從設計之初就深度集成AI,實現完全自主的“測試智能體”,能夠理解需求、自主設計測試、執行并報告結果。
大語言模型(LLM)的深度集成: LLM可用于直接生成復雜的端到端測試代碼、理解自然語言描述的Bug報告、甚至直接模擬用戶會話進行聊天機器人測試。
全鏈路預測性維護: AI將整合代碼、日志、監控、基礎設施等全鏈路數據,構建一個預測性質量保障平臺,在用戶遇到問題之前提前預測并修復故障。
擁抱AI測試不再是可選項,而是企業在數字化競爭中保持敏捷、高質量和用戶體驗的必由之路。建議組織和測試從業者開始探索和試點這些AI驅動的方法和工具,逐步將其融入DevOps和CI/CD管道中,構建面向未來的智能質量保障體系。


))






詳解)


)






