我們可以把它想象成一個?“老師”和“學生”?協作學習的過程。
全局服務器?=?“老師”
本地客戶端?=?“學生”
整個模型更新的過程遵循一個核心原則:“數據不動,模型動”。原始數據永遠留在本地客戶端,只有模型的參數(即模型的“知識”)在服務器和客戶端之間流動。
下面我們以最經典、最常用的?聯邦平均算法(Federated Averaging, FedAvg)?為例,分步拆解這個更新過程。
1、總體流程概覽
整個過程是一個循環迭代的過程,每一輪通信(Communication Round)都包含以下四個核心步驟,如下圖所示:
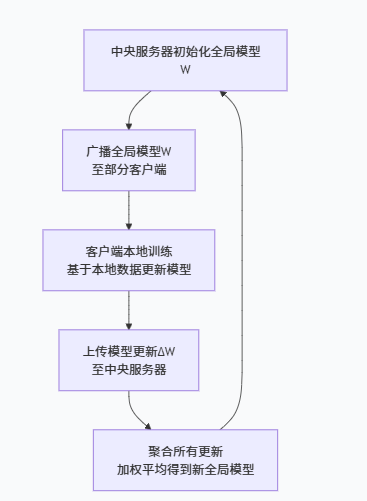
2、第一步:服務器端-初始化與廣播(老師布置作業)
初始化:中央服務器會隨機初始化一個全局模型,我們稱之為?W_global(全局模型)。這就像一個剛畢業的新老師,腦子里有一套基礎但還不精準的知識體系。
選擇與廣播:
在每一輪訓練開始時,服務器會從所有可用的客戶端(比如上百萬部手機)中,隨機選擇一小部分(例如1000部)。這么做主要是為了效率,不可能每次都讓所有人參與,不然會增加通信開銷。
服務器將當前的全局模型?W_global?發送給這些被選中的客戶端。
這就好比老師(服務器)把今天的教案(全局模型)發給了班上的一部分同學(客戶端)。
3、第二步:客戶端 - 本地模型更新(學生自己做功課)
收到全局模型的每個客戶端,會開始執行本地訓練:
加載數據:客戶端從自己的本地存儲中加載私有的訓練數據(比如你手機上的照片、輸入法記錄)。
本地訓練:
客戶端用收到的?W_global?作為初始模型,用自己的本地數據進行訓練,執行多次(比如10次)梯度下降(SGD)迭代。
訓練完成后,客戶端手上的模型參數更新了,我們稱之為?W_local(本地參數)。
這就好比每個同學(客戶端)都按照老師發的教案(W_global)自學,并結合自己的練習題(本地數據),總結出了一套自己的解題心得(W_local)。注意,每個同學的練習題都不一樣,所以他們的心得也各有側重(這個就設計到現實生活中的數據異構性,每個客戶端的數據不一樣,訓練的參數也會不一樣,甚至最后可能無法收斂,這過程中也會出現壞學生為了應付了事隨便寫的參數,或者偽造參數,就會導致最后模型的性能降低。當然也會有壞客戶為了破壞模型性能,會選擇偽造參數,竊取參數,也就需要對參數進行加密等操作)。
全局模型?=?一本不斷再版的?“通用教材”
本地客戶端?=?使用這本教材的?“學生”(每個學生都有自己的私人練習題)
聯邦學習的過程?=?共同編寫和修訂這本教材的過程
計算更新:
客戶端計算出本地模型與初始全局模型的差異(即更新量):ΔW = W_local - W_global。有些實現也會直接上傳整個?W_local。
關鍵:?客戶端絕不會上傳它的原始數據,只上傳模型的“更新量”或“新參數”。這完美保護了隱私。
4、全局模型
每一輪訓練,服務器都會收集一批客戶端的“學習心得”(模型更新),然后把這些心得中最有價值的部分融合起來,更新到這本“教材”里。所以,全局模型是所有參與客戶端集體智慧的結晶。
最終的產品與目標:
聯邦學習的最終目標,就是要訓練出這個高質量的全局模型。我們所有的工作——本地計算、通信、聚合——都是為了讓它變得更好、更智能、更通用。
訓練完成后,這個全局模型可以被部署到新設備上直接使用,或者作為基礎模型供進一步微調。它就是整個項目的產出物。
5、服務器端 - 聚合更新(老師批改作業,匯總答案)
收集更新:服務器等待所有被選中的客戶端上傳它們的模型更新?ΔW?, ΔW?, ..., ΔW_k(或它們的新參數?W_local?, W_local?, ...)。
加權平均:
服務器不會簡單地把所有更新一平均了事。它會做一個加權平均。
權重取決于每個客戶端本地數據的數量。數據量越大的客戶端,它的“話語權”就越大。
計算公式:
新的全局模型:其中?
n?, n?, ..., n_k?是每個客戶端本地數據的樣本數量。
這就好比老師(服務器)收上所有同學的作業(模型更新),發現有的同學做的題多(數據量大),有的做的題少。老師更相信做題多的同學的經驗,于是給他們的答案更高的權重,最后匯總所有答案的優點,形成了一份全新的、更完善的教案(W_global_new)。
全局模型=一本不斷再版的?“通用教材”
本地客戶端=使用這本教材的?“學生”(每個學生都有自己的私人練習題)
聯邦學習的過程?=?共同編寫和修訂這本教材的過程
6、循環迭代
服務器用這個更新后的?W_global_new?替換掉舊的全局模型。然后,整個過程重復第一步:選擇新的一批客戶端,廣播新的全局模型,開始下一輪的學習。
如此循環往復,直到全局模型達到一個令人滿意的精度或收斂為止。
7、全局模型與聯邦訓練之間的關聯(“教材”與“編寫過程”如何互動?)
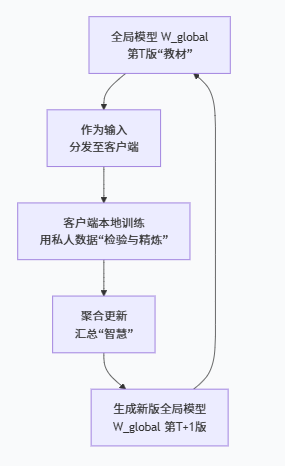
全局模型既是聯邦訓練的“輸入”,也是它的“輸出”。這個“輸入-處理-輸出”的循環,構成了訓練的完整閉環。
作為“輸入” (Starting Point):
在每一輪訓練開始時,當前版本的全局模型(
W_global^t)被分發給選中的客戶端。作用:?它確保了所有客戶端是在同一個知識基礎上進行學習和改進的。如果每個客戶端都從自己的隨機點開始,最終就無法將它們的知識融合到一起。
經歷“處理” (Processing):
客戶端收到全局模型后,用它在本地的、私有的數據上進行學習。這個學習過程可以看作是對全局模型的一次?“檢驗”和“ refinement(精煉)”?。
檢驗:?模型在用戶A的數據上可能表現好,在用戶B的數據上表現差,這暴露了模型的不足和偏差。
精煉:?每個客戶端都會根據本地數據的特點,對模型進行微調,讓它更適應自己的數據分布。這個過程相當于每個學生用私人練習題去驗證和補充教材內容,并做了自己的筆記。
作為“輸出” (Updated Product):
服務器將客戶端返回的更新(“學生們的筆記”)進行聚合(加權平均),生成一個新版本的全局模型(
W_global^{t+1})。作用:?新模型融合了更多樣、更廣泛的知識,理論上比舊模型更全面、性能更好、泛化能力更強。這就像老師匯總了所有學生的優秀筆記,修訂出了教材的“第二版”。
這個新模型立即成為下一輪訓練的輸入,循環往復。
重點:
不能把全局模型想象成一個固定的“指揮官”。
要把它想象成一個不斷進化、不斷成長的“核心”。它從一張白紙(隨機初始化)開始,通過不斷地“聽取”成千上萬客戶端的意見(聚合更新),吸收全世界的知識,最終成長為一個見多識廣、能力強大的模型。
8、總結
| 步驟 | 執行者 | 動作 | 輸入 | 輸出 | 比喻 |
|---|---|---|---|---|---|
| 1. 廣播 | 全局服務器 | 選擇客戶端并發送模型 | 當前全局模型?W_global | W_global?(發送) | 老師布置作業 |
| 2. 本地更新 | 本地客戶端 | 本地訓練 | W_global?+?本地數據 | 本地模型?W_local | 學生自己做功課 |
| 3. 聚合 | 全局服務器 | 加權平均 | 所有客戶端的?W_local | 新全局模型?W_global_new | 老師批改匯總 |
| 4. 循環 | 重復過程 |
隱私保護:數據始終在本地,只傳輸模型參數更新,這是聯邦學習的立身之本。
通信效率:客戶端本地進行多次迭代,大大減少了服務器和客戶端之間的通信輪數,這是FedAvg算法的巨大優勢。
非獨立同分布:每個客戶端的數據分布不同,這是聯邦學習的主要挑戰。加權平均是一種有效的聚合策略,旨在求取“最大公約數”。
異構性:客戶端的設備、網絡、數據量都不同,所以你的開題設計需要考慮如何選擇客戶端、如何處理掉隊者等問題。

)

)

并進行歸一化的標準操作)


——llama_index實現上下文窗口增強檢索RAG)









)
