
導論:從數字化世界到可計算世界
數字地圖的演進,本質上是一場關于“世界可計算性”的持續探索。第一代地圖的核心任務是數字化轉錄(Digital Transcription),它成功地將物理世界的靜態元素——道路、建筑、興趣點(POI)——抽象為數據庫中可供計算機檢索的結構化數據。這是一個偉大的成就,它讓我們擁有了物理世界的數字鏡像。然而,一個真正有用的導航服務所必須面對的,是一個充滿動態、隨機性和復雜交互的真實世界,其核心挑戰便是交通。

交通系統是一個典型的復雜自適應系統(Complex Adaptive System),更接近于一個混沌系統。其宏觀狀態由億萬個獨立決策主體(駕駛員)的微觀行為、復雜的環境因素(天氣、光照、道路設施)以及深刻的時空依賴性(上游的交通事故會在幾分鐘內引發數公里長的擁堵)共同涌現而成。對這樣一個系統進行精確建模、可靠預測和最優決策,是現代導航技術皇冠上的明珠。
高德地圖給出的答案,是系統性地、分層次地應用深度學習技術,構建了一個從底層數據處理到頂層人機交互的完整智能技術棧。這一架構的核心思想,是從“連接”物理世界的基本信息,躍遷至“理解”其內在運行規律,并最終實現“預測”和“決策”的智能閉環。這標志著地圖服務的核心價值,正從信息提供(Information Provision) 轉向 決策支持(Decision Support)乃至自主決策(Autonomous Decision-Making)。
近年來,高德地圖提出的全面AI化戰略及其AI原生地圖應用,是這一技術哲學演進的必然產物和集大成者。它標志著其內部的深度學習應用不再是服務于特定功能的、孤立的“優化補丁”,而是被整合進一個統一的、具備感知、推理與行動能力的“空間智能體”(Spatial Agent)。這不僅是一次技術升級,更是一場產品范式的革命。

本文將以前所未有的深度,解構這一智能體系的四大關鍵層次,剖析深度學習模型如何在不同尺度上解決導航中的核心問題,并最終融為一體:
- 微觀路線層(Microscopic Route Level):聚焦于單次導航任務。我們將深入探討如何利用先進的序列模型(如LSTM),將ETA(預估到達時間)這一核心指標的預測精度推向物理極限,剖析其如何克服傳統方法的根本性缺陷。
- 宏觀路網層(Macroscopic Network Level):將視角提升至整個城市。我們將解析圖神經網絡(GNN)如何將復雜的城市路網抽象為數學上的“圖”,從而洞察并預測整個城市交通網絡的宏觀流動趨勢與擁堵演化。
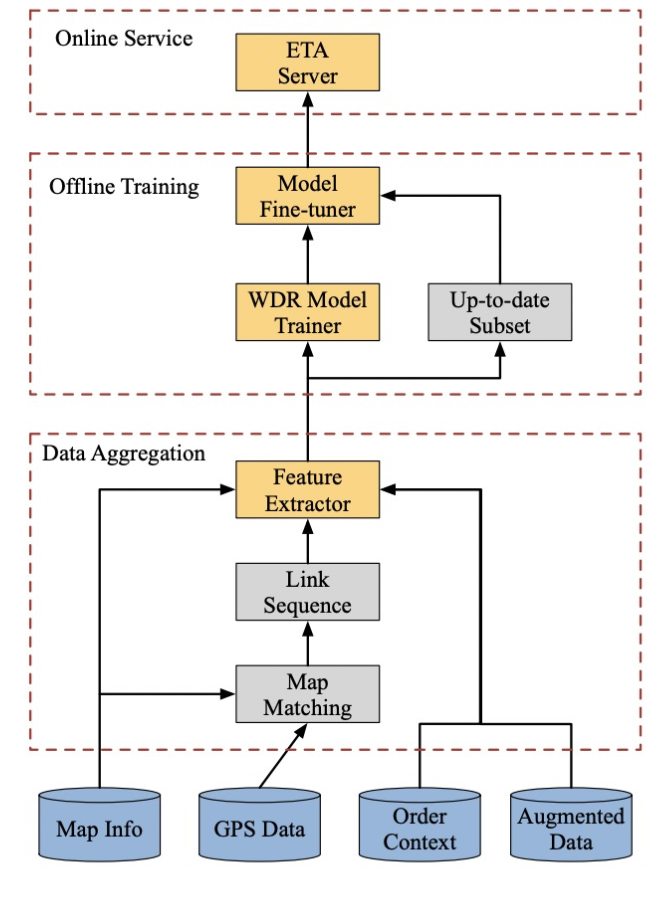
- Foundational 數據層(Foundational Data Layer):深入系統的基石。我們將揭示高德如何通過混合分類模型,從每日億萬級的原始軌跡數據中“去偽存真”,確保輸入上層模型的數據是純凈、可靠的,這是整個智能體系的“免疫系統”。
- 交互與決策層(Interaction & Decision-Making Layer):探索智能的頂層表達。我們將分析大語言模型(LLM)如何扮演“中央大腦”的角色,將底層復雜的感知與預測能力,封裝成可與用戶進行自然語言交互、主動完成復雜任務規劃的智能體。
通過對這四個層次的穿透式分析,我們將揭示一個世界領先的地圖服務商,是如何通過深度學習,將其產品從一個靜態的、被動響應的“信息瀏覽器”,重構為一個動態的、主動思考的、具備深刻時空理解力的“計算引擎”。
一、 微觀路線層:基于序列模型的ETA精準預測
預估到達時間(Estimated Time of Arrival, ETA)是導航服務與用戶之間最直接、最核心的“契約”。一個可靠的ETA是信任的基石,而一個飄忽不定的ETA則是焦慮的源頭。在深度學習介入之前,ETA的計算經歷了從基于規則、基于歷史統計到基于經典機器學習的漫長演進,但始終未能完美解決真實路況的高度動態性問題。
1.1 范式困境:孤立預測與特征工程的極限
傳統方法的根本缺陷在于其**“靜態”和“孤立”的視角**。
- 基于歷史統計:這種方法假設“歷史會重演”,它會根據當前是周幾、幾點,去查詢歷史上此時此刻此路段的平均速度。這在路況平穩時勉強可用,但無法應對任何“意外”,如一場突如其來的大雨、一次臨時的交通管制或一起交通事故。
- 經典機器學習(如GBDT):梯度提升決策樹等模型將ETA預測看作一個回歸問題。它們通過引入更多的人工特征(如天氣、節假日、周邊POI密度等)來提升精度。然而,它們仍面臨兩大無法逾越的障礙:
- 特征工程的極限:模型的上限被人類工程師的想象力所束縛。特征的設計過程耗時耗力,且永遠無法窮盡所有影響交通的細微因素。更重要的是,特征之間的復雜交互關系(例如,下雨天在晚高峰對主干道的影響遠大于對支路的影響)很難被手動捕捉。
- 時空依賴的缺失:這是最致命的缺陷。這些模型通常將一條路線拆解成N個獨立的路段,對每個路段的通行時間進行孤立預測,最后簡單求和。這種方法完全忽略了交通流的**“傳導效應”(Propagation Effect)**。現實中,路段A的突發擁堵,不僅使其自身通行時間增加,更必然會延遲車輛進入后續路段B、C的時間。而路段B、C在新的、被延后的時間點上,其路況可能已經發生了翻天覆地的變化。這種“一步錯,步步錯”的連鎖誤差,是傳統ETA模型在復雜路況下頻繁“跳變”、失去準頭的主要原因。
1.2 范式革新:將路線視為時間序列
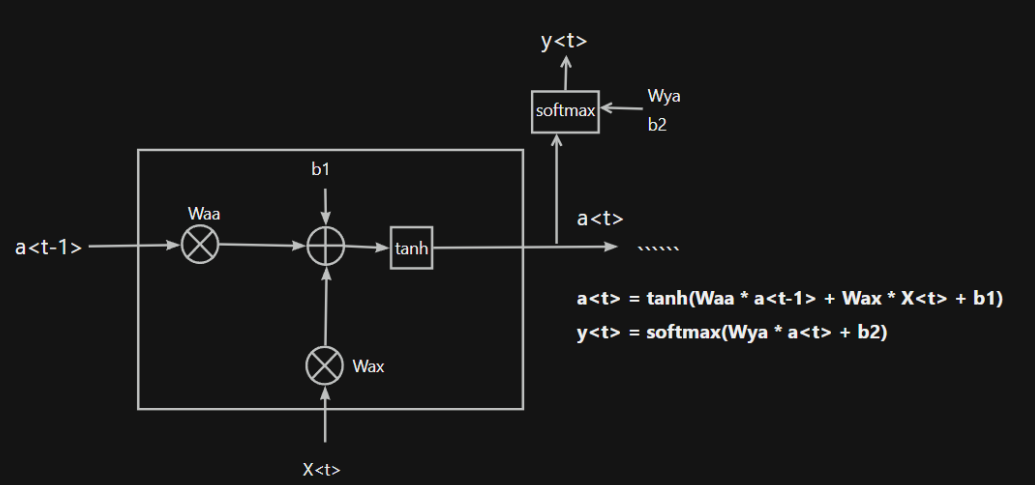
深度學習,特別是循環神經網絡(RNN)及其變體,為ETA預測帶來了革命性的范式轉變。其核心思想簡潔而深刻:不再將一條路線視為一堆路段的無序集合,而是將其看作一個以空間為軸線、以路段為單位的、具有嚴格先后順序的時間序列。 高德地圖在此場景下深度應用了長短期記憶網絡(LSTM)。
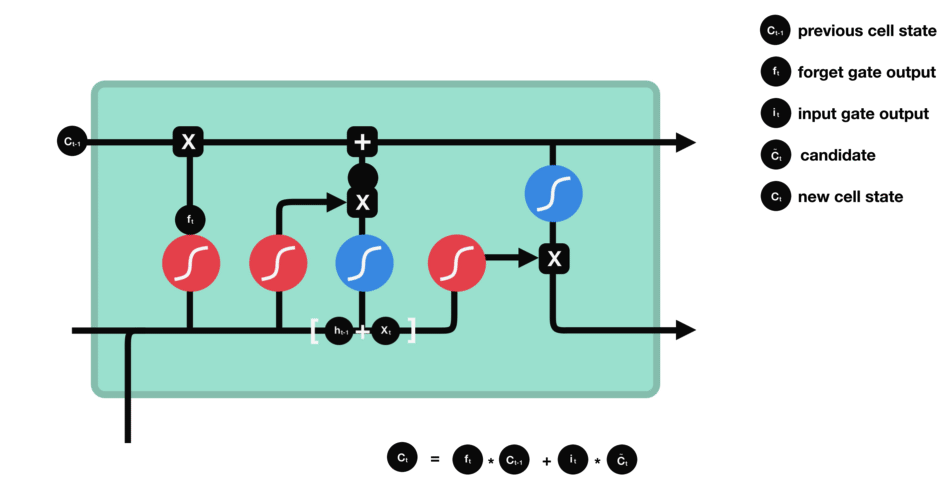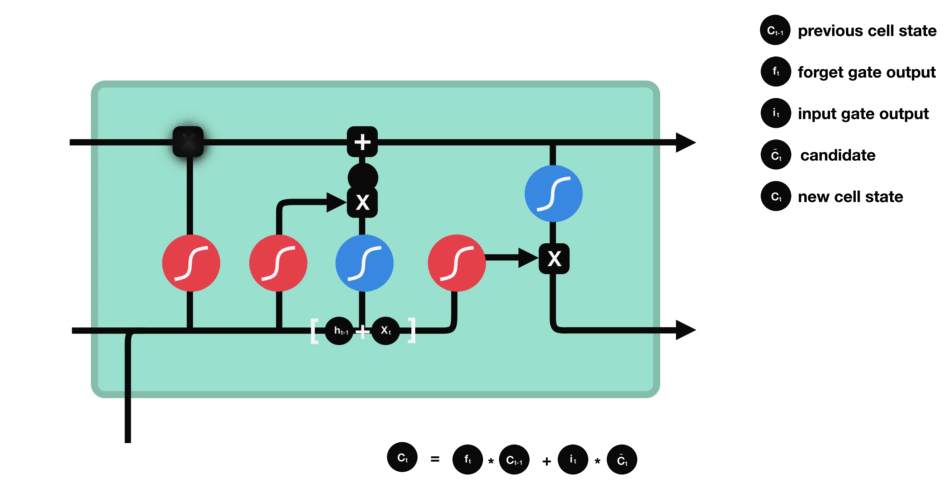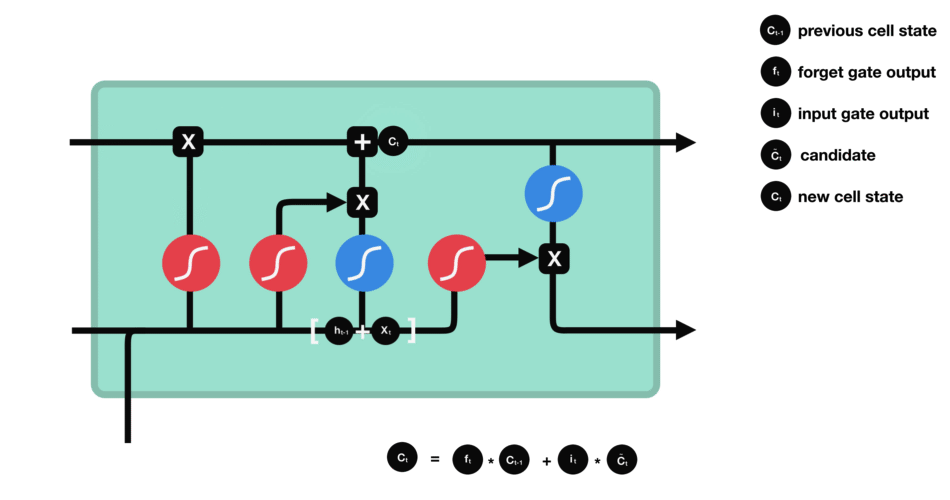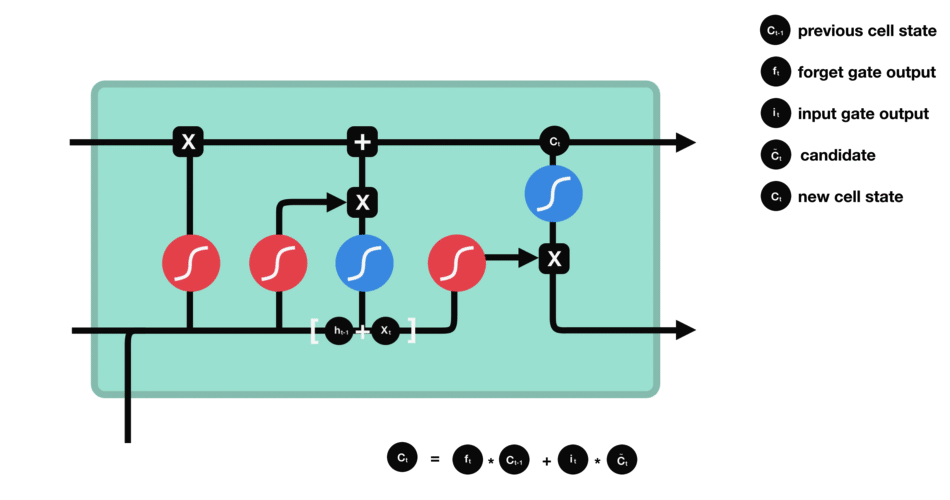
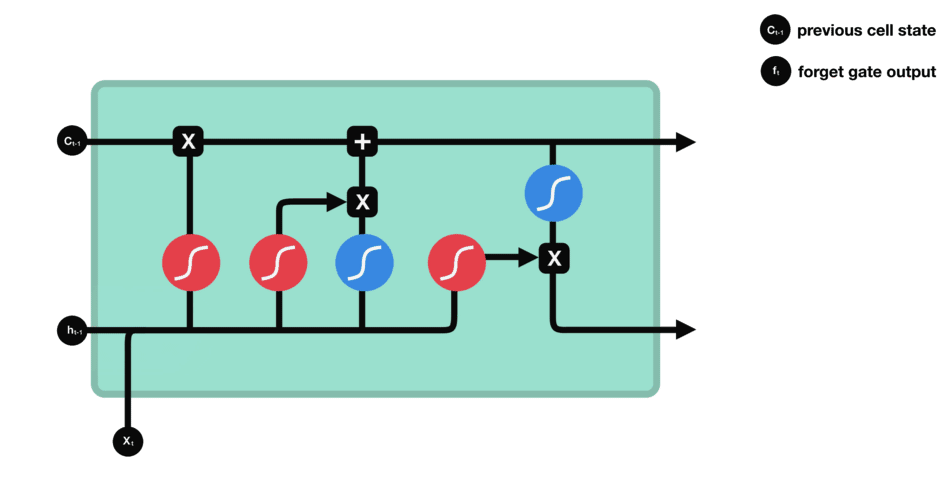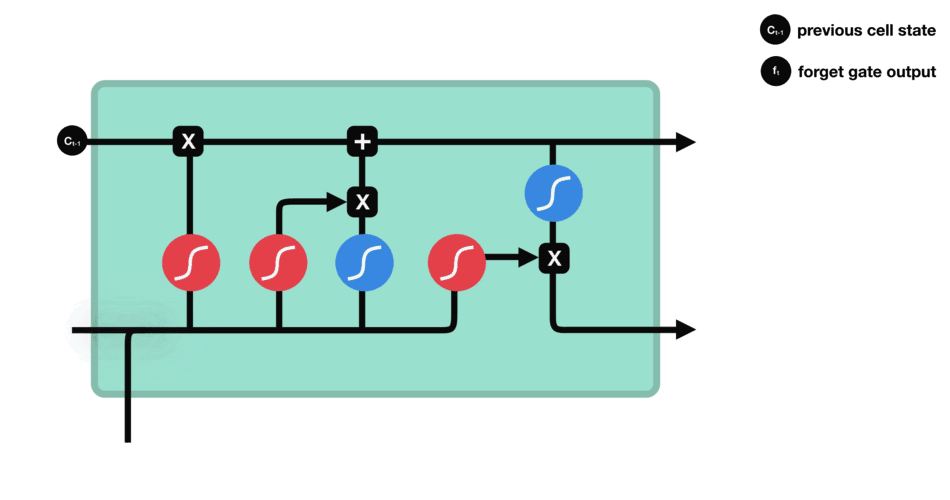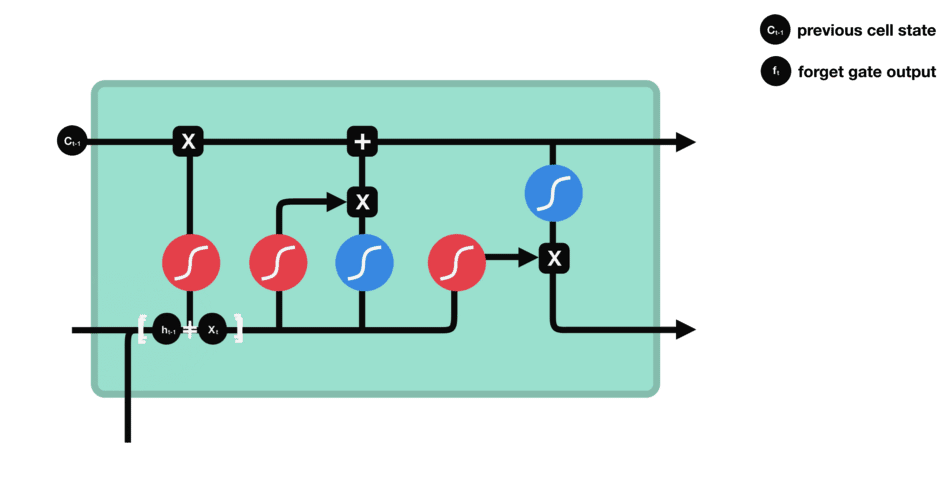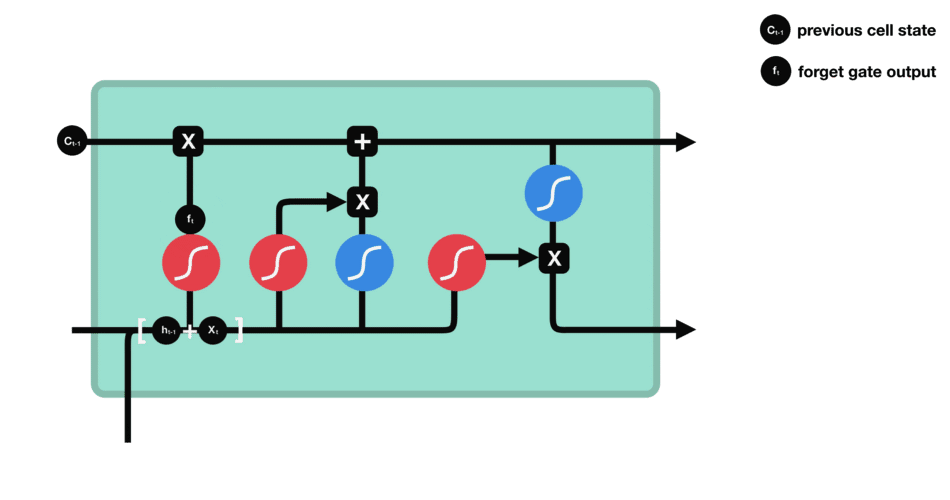
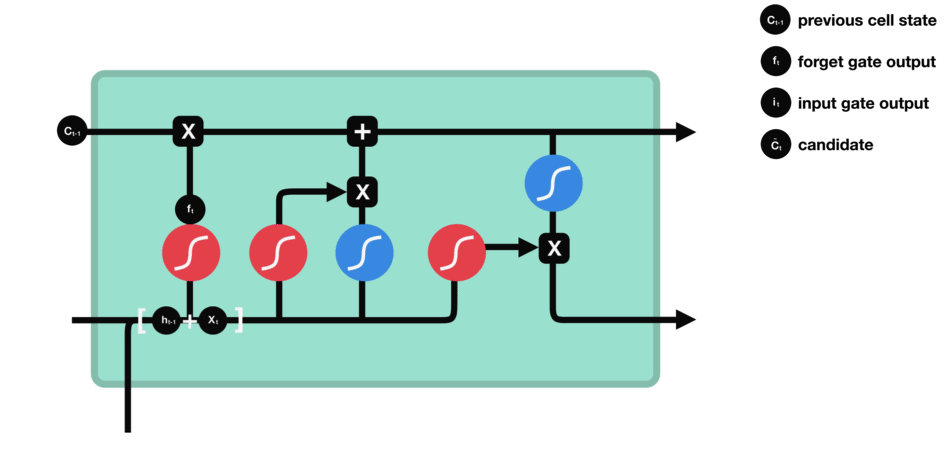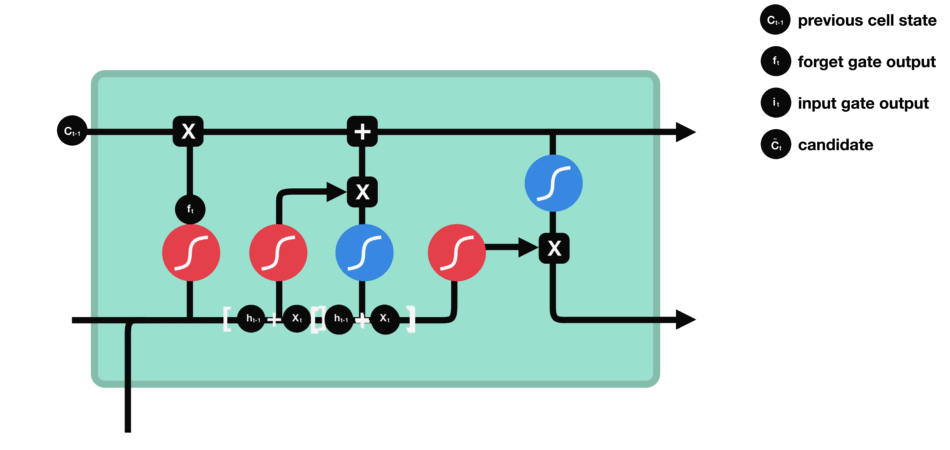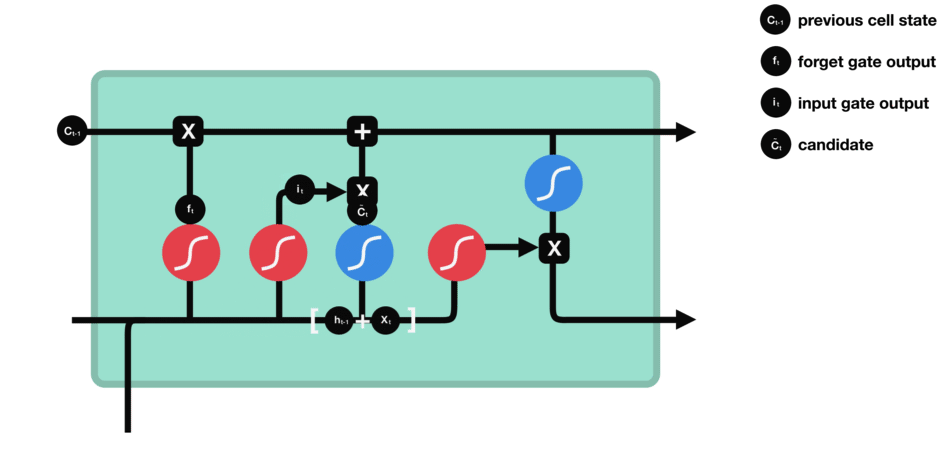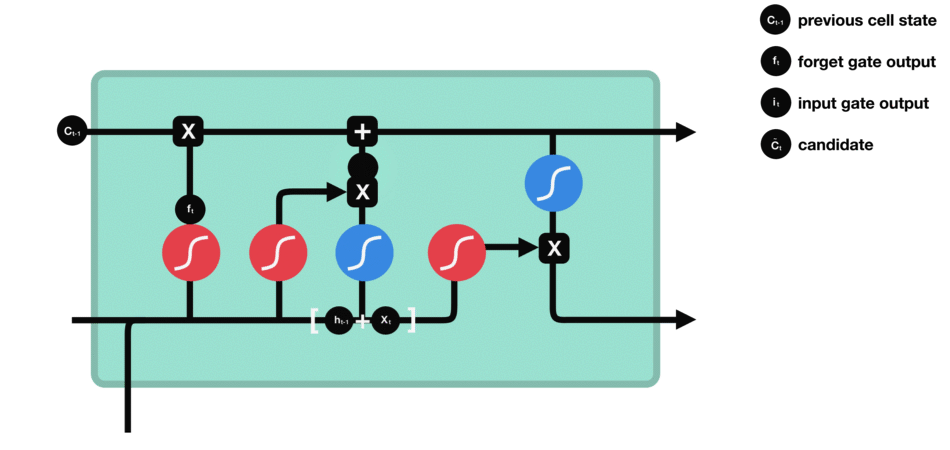
RNN的細胞結構圖如下:
LSTM之所以能夠勝任此任務,源于其為處理序列數據中長程依賴而生的精巧內部結構。一個LSTM單元包含三個關鍵的“門控”機制——遺忘門、輸入門、輸出門,以及一個貫穿始終的**“細胞狀態”(Cell State)**,后者可以看作是模型的“長期記憶”。
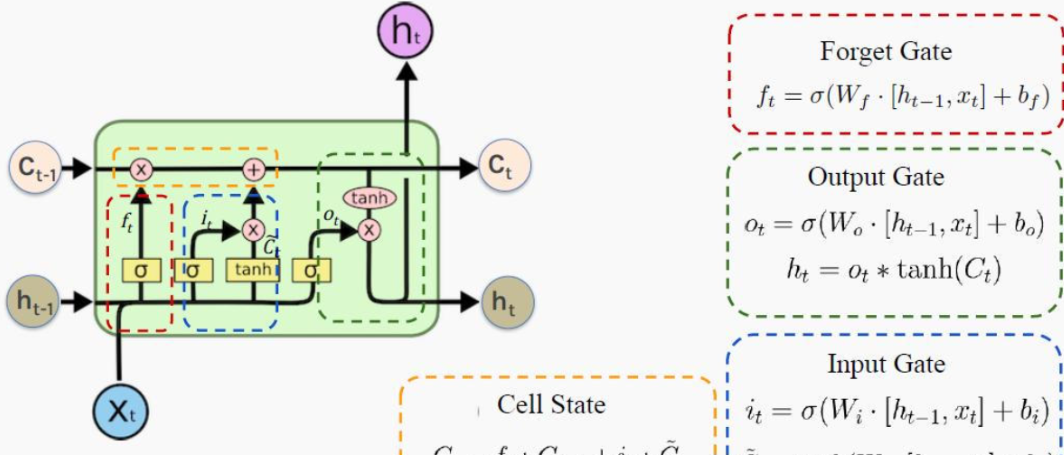
在ETA預測的語境下,這個工作流程可以被生動地解讀:
-
細胞狀態:就像一條傳送帶,攜帶著路線已經過的部分的核心信息(比如“目前整體路況通暢”或“剛剛經歷了一段嚴重擁堵”)向前傳遞。
-
遺忘門:當車輛從擁堵的市區主干道駛入通暢的高速公路時,遺忘門會決定“忘記”之前關于市區擁堵的細節信息,因為它對預測高速路段的通行時間已不再重要。
-
輸入門:當模型處理到一個新的路段時,輸入門會判斷這個路段的新信息(如實時路況顯示為紅色、限速60km/h)哪些是重要的,并決定將其更新到細胞狀態中。
-
輸出門:基于當前的細胞狀態(長期記憶)和當前路段的輸入,輸出門會計算出對當前路段通行時間的最佳預測,并更新傳遞給下一個時間步的“短期記憶”(隱藏狀態)。
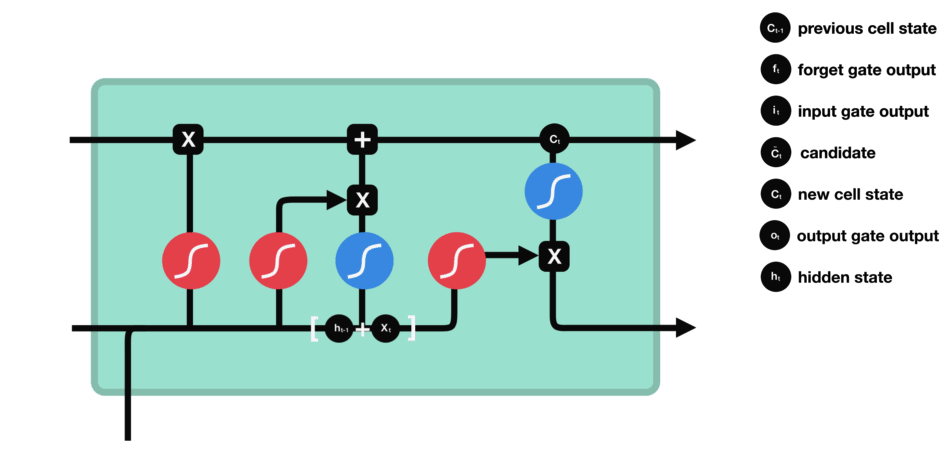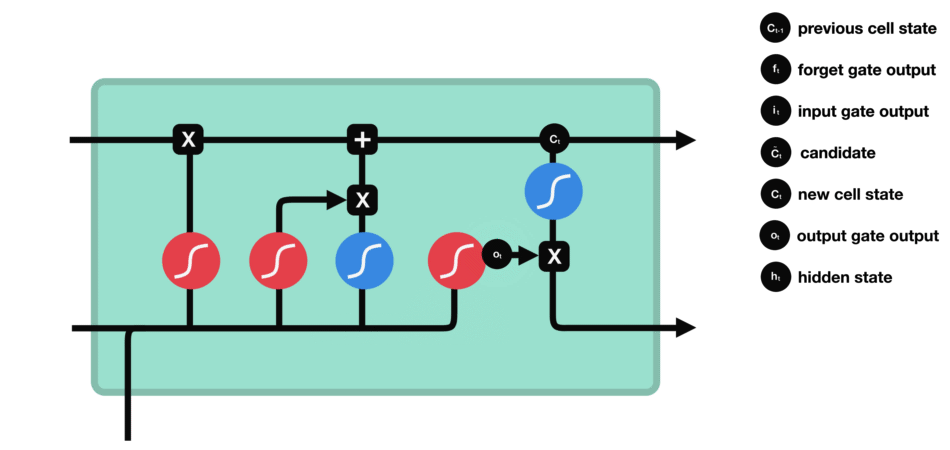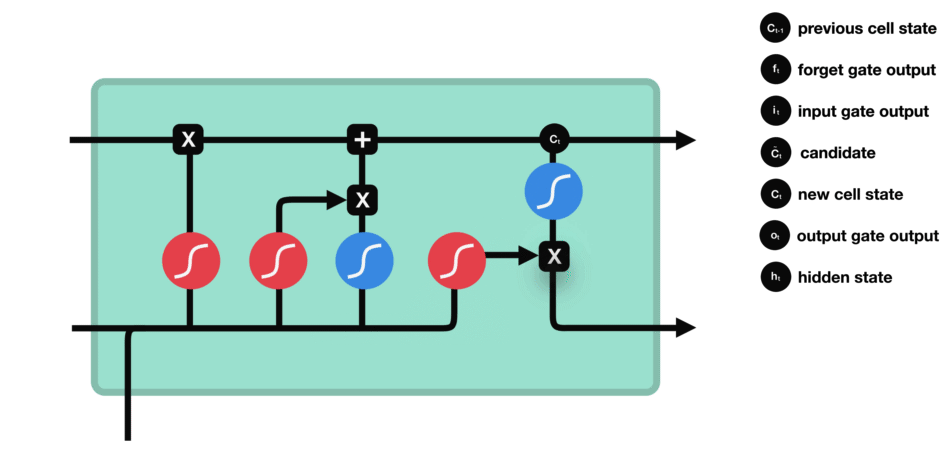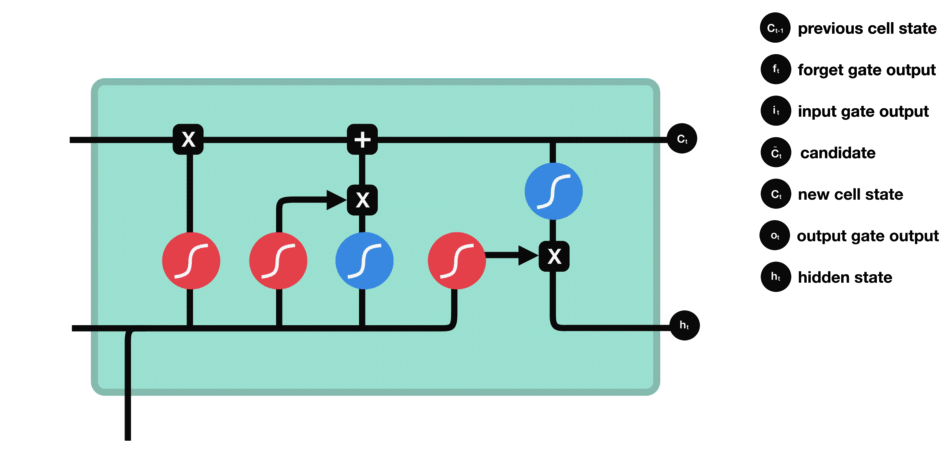
這種機制使得信息能夠在整個路線序列中智能地流動。模型在預測第N個路段時,是基于前面所有N-1個路段的綜合信息動態做出的,從而完美地捕捉了交通的傳導效應。
代碼示例:簡化的LSTM模型預測下一路段通行時間
為了直觀地展示這一思想,下面的代碼使用TensorFlow/Keras構建了一個極其簡化的LSTM模型。它演示了模型如何學習序列模式,即根據前兩個路段的通行時間,來預測第三個路段的通行時間。在真實系統中,輸入特征會是包含數十個維度的高維向量。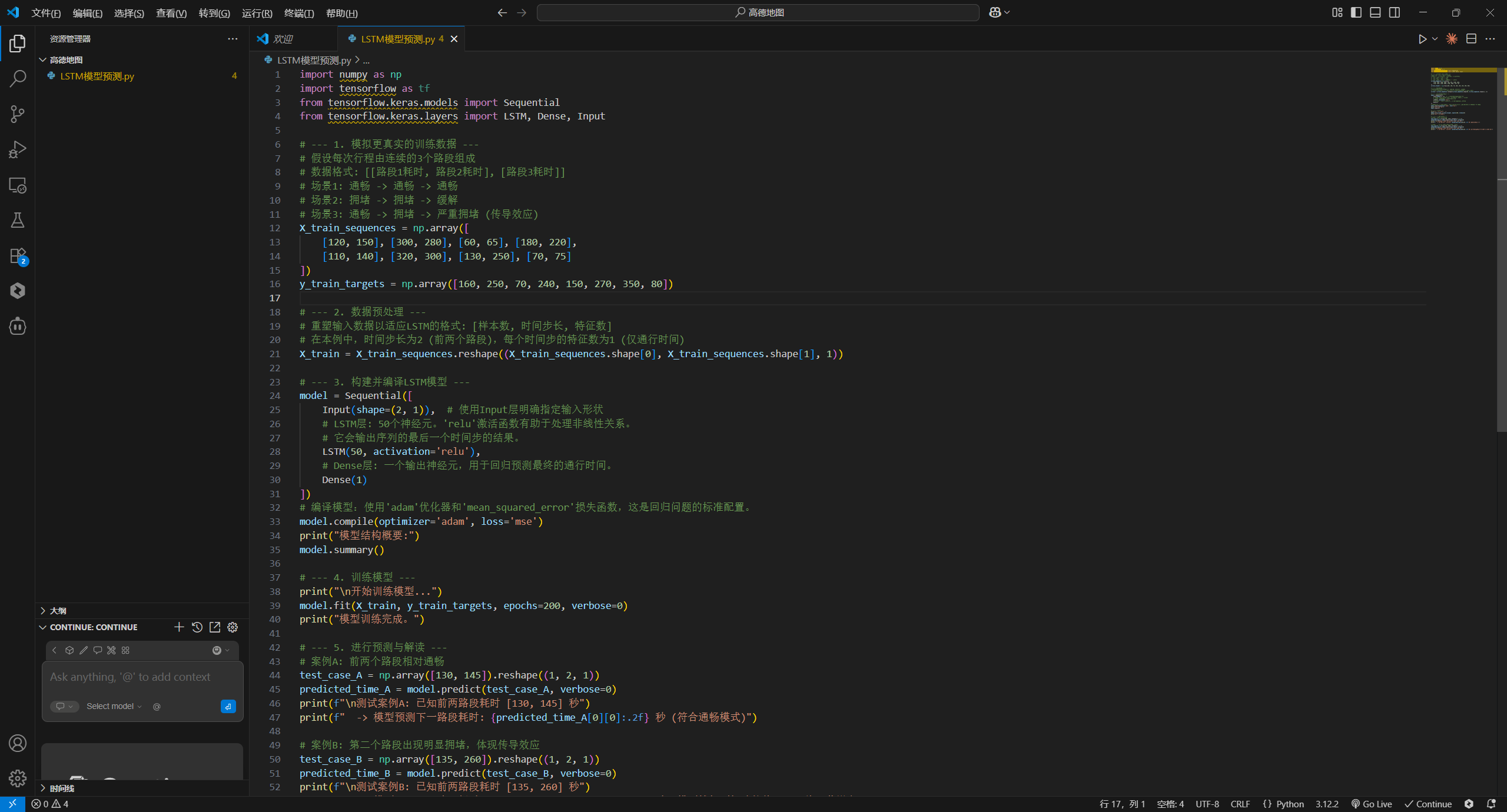
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Input# --- 1. 模擬更真實的訓練數據 ---
# 假設每次行程由連續的3個路段組成
# 數據格式: [[路段1耗時, 路段2耗時], [路段3耗時]]
# 場景1: 通暢 -> 通暢 -> 通暢
# 場景2: 擁堵 -> 擁堵 -> 緩解
# 場景3: 通暢 -> 擁堵 -> 嚴重擁堵 (傳導效應)
X_train_sequences = np.array([[120, 150], [300, 280], [60, 65], [180, 220],[110, 140], [320, 300], [130, 250], [70, 75]
])
y_train_targets = np.array([160, 250, 70, 240, 150, 270, 350, 80])# --- 2. 數據預處理 ---
# 重塑輸入數據以適應LSTM的格式: [樣本數, 時間步長, 特征數]
# 在本例中,時間步長為2 (前兩個路段),每個時間步的特征數為1 (僅通行時間)
X_train = X_train_sequences.reshape((X_train_sequences.shape[0], X_train_sequences.shape[1], 1))# --- 3. 構建并編譯LSTM模型 ---
model = Sequential([Input(shape=(2, 1)), # 使用Input層明確指定輸入形狀# LSTM層: 50個神經元。'relu'激活函數有助于處理非線性關系。# 它會輸出序列的最后一個時間步的結果。LSTM(50, activation='relu'),# Dense層: 一個輸出神經元,用于回歸預測最終的通行時間。Dense(1)
])
# 編譯模型:使用'adam'優化器和'mean_squared_error'損失函數,這是回歸問題的標準配置。
model.compile(optimizer='adam', loss='mse')
print("模型結構概要:")
model.summary()# --- 4. 訓練模型 ---
print("\n開始訓練模型...")
model.fit(X_train, y_train_targets, epochs=200, verbose=0)
print("模型訓練完成。")# --- 5. 進行預測與解讀 ---
# 案例A: 前兩個路段相對通暢
test_case_A = np.array([130, 145]).reshape((1, 2, 1))
predicted_time_A = model.predict(test_case_A, verbose=0)
print(f"\n測試案例A: 已知前兩路段耗時 [130, 145] 秒")
print(f" -> 模型預測下一路段耗時: {predicted_time_A[0][0]:.2f} 秒 (符合通暢模式)")# 案例B: 第二個路段出現明顯擁堵,體現傳導效應
test_case_B = np.array([135, 260]).reshape((1, 2, 1))
predicted_time_B = model.predict(test_case_B, verbose=0)
print(f"\n測試案例B: 已知前兩路段耗時 [135, 260] 秒")
print(f" -> 模型預測下一路段耗時: {predicted_time_B[0][0]:.2f} 秒 (模型捕捉到擁堵趨勢,預測值顯著增高)")這個簡單的例子揭示了核心思想:模型的預測結果不僅僅是基于輸入值的簡單平均或線性外推,而是基于它在訓練數據中學到的序列模式。案例B的預測值遠高于案例A,正是因為模型識別出了一個“擁堵正在加劇”的序列模式。在真實世界中,高德的ETA模型會融合路線的全局靜態特征(如總長度、紅綠燈總數)與LSTM對路段序列的動態預測,形成一個端到端的、高度精確的預測系統。
二、 宏觀路網層:基于圖神經網絡的城市交通預測
單次ETA的精準預測解決了“點到點”的微觀問題。然而,要實現真正意義上的智能交通,例如為全城用戶進行最優的擁堵規避,甚至輔助交通管理部門進行信號燈優化和交通疏導,地圖服務就必須具備對整個城市交通網絡進行宏觀預測的能力。城市路網是一種典型的圖(Graph)結構數據——路口是節點,道路是邊。這種數據的拓撲關系復雜且不規則,是典型的非歐幾里得空間數據,這超出了傳統CNN等擅長處理規則網格數據(如圖像)的模型的“能力圈”。
2.1 范式困境:從網格到圖的挑戰
在GNN興起之前,宏觀交通預測的一些嘗試會將城市地圖強行劃分為規則的地理網格,然后統計每個網格內的車輛密度或平均速度,最后用CNN來預測未來每個網格的狀態。這種方法的缺陷是顯而易見的:
- 拓撲信息丟失:它完全破壞了道路網絡內在的連通性。模型無法知道網格A和網格B之間是否有一條高容量的快速路,或者只是一條無法通行的小巷。
- 空間分辨率與計算成本的矛盾:網格劃分得太粗,會丟失大量細節;劃分得太細,則會導致數據極度稀疏和計算量爆炸。
2.2 范式革新:時空圖卷積網絡(STGCN)
圖神經網絡(Graph Neural Network, GNN),特別是圖卷積網絡(Graph Convolutional Network, GCN),為直接在圖結構數據上進行深度學習提供了強大的數學工具。高德地圖等行業先驅,將先進的**時空圖卷積網絡(Spatio-Temporal Graph Convolutional Network, STGCN)**應用于此領域,將交通預測問題置于其最自然的數學表達之上。
STGCN模型的核心是時空一體化建模,它通過精巧設計的網絡層,同時捕捉兩種相互交織的依賴關系:
-
空間依賴性(Spatial Dependency):這是通過圖卷積實現的。圖卷積的核心思想是**“消息傳遞”(Message Passing)或“鄰居聚合”(Neighbor Aggregation)**。對于圖中的每一個節點(路口),其新一層的特征表示,是通過聚合其所有鄰居節點(與之直接相連的路口)的當前特征,并結合自身特征計算得出的。這個過程完美地模擬了物理世界的交通規律:一個路口的擁堵狀況,正是由其所有相鄰路口的車流匯入和流出情況共同決定的。通過堆疊多層圖卷積,一個節點可以感知到其二階、三階乃至更遠鄰居的狀態,從而學習到擁堵在復雜路網中的全局擴散模式。
-
時間依賴性(Temporal Dependency):交通數據在時間維度上具有強烈的模式,如周期性(早晚高峰)、趨勢性(節假日出城潮)。STGCN通過在圖卷積層之間穿插時間卷積模塊來捕捉這些模式。這些模塊通常采用帶門控機制的一維卷積(Gated Temporal Convolution)或GRU等循環單元。模型將過去一段時間(例如,過去60分鐘,每5分鐘一個快照)內所有節點的交通狀態序列作為輸入,時間卷積層能夠學習到交通流量隨時間演變的動態規律。
STGCN網絡整體架構:
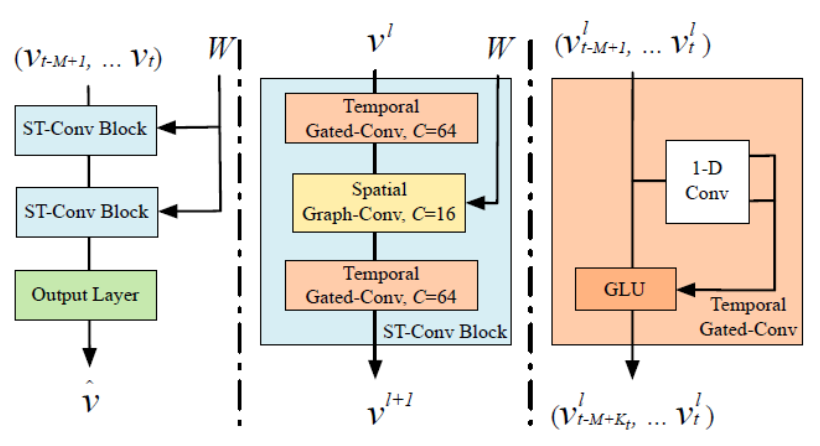
STGCN通過將“時空卷積塊”(一個空間圖卷積層 + 一個時間卷積層)作為基本單元進行堆疊,構建出能夠同時理解“在哪個路口”和“在什么時間”發生的變化將如何影響整個路網未來的時空模型。
尤為關鍵的是,高德地圖在其模型中引入了一個極具價值的、其他競爭者難以獲得的專有數據維度:基于海量用戶實時導航請求計算出的“未來意圖流量”。系統能夠通過分析當前所有正在使用高德導航的車輛規劃的路徑,提前預判在未來5分鐘、10分鐘、15分鐘后,將有多少車輛計劃匯集到某條特定道路上。將這一具有“上帝視角”的預見性特征,與STGCN強大的時空建模能力相結合,使得高德能夠“預見”擁堵的形成,從而更早地為用戶規劃出能夠真正“躲避未來擁堵”的路線,實現了從“被動響應當前擁堵”到“主動預測并規避未來擁堵”的智能化飛躍。
代碼示例:使用NetworkX構建城市路網圖結構
在應用GNN之前,首要任務是將路網數據結構化為圖。下面的代碼使用流行的networkx庫,演示了這一基礎但至關重要的一步。真實的路網圖將包含數百萬個節點和邊。
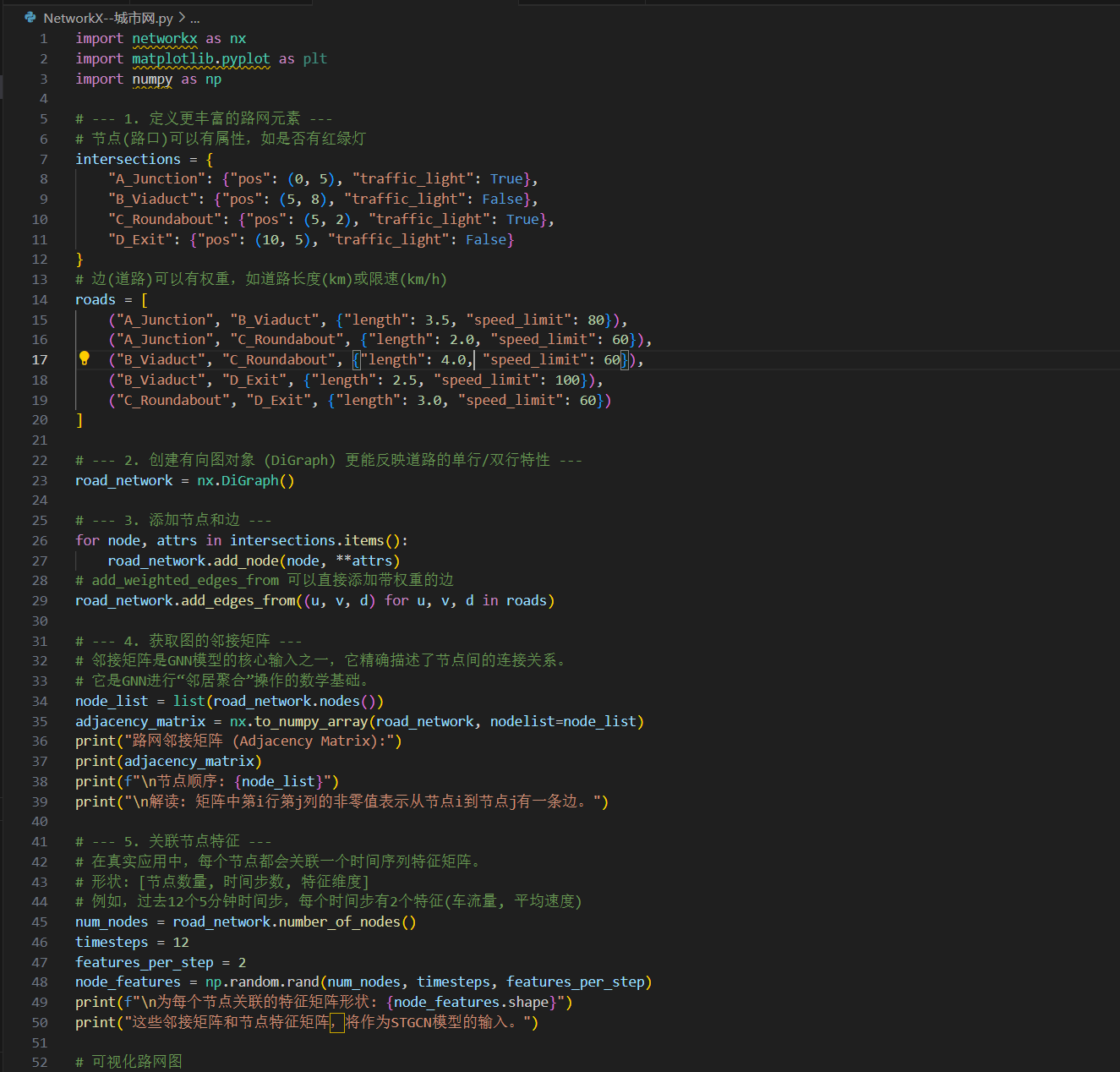
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np# --- 1. 定義更豐富的路網元素 ---
# 節點(路口)可以有屬性,如是否有紅綠燈
intersections = {"A_Junction": {"pos": (0, 5), "traffic_light": True},"B_Viaduct": {"pos": (5, 8), "traffic_light": False},"C_Roundabout": {"pos": (5, 2), "traffic_light": True},"D_Exit": {"pos": (10, 5), "traffic_light": False}
}
# 邊(道路)可以有權重,如道路長度(km)或限速(km/h)
roads = [("A_Junction", "B_Viaduct", {"length": 3.5, "speed_limit": 80}),("A_Junction", "C_Roundabout", {"length": 2.0, "speed_limit": 60}),("B_Viaduct", "C_Roundabout", {"length": 4.0, "speed_limit": 60}),("B_Viaduct", "D_Exit", {"length": 2.5, "speed_limit": 100}),("C_Roundabout", "D_Exit", {"length": 3.0, "speed_limit": 60})
]# --- 2. 創建有向圖對象 (DiGraph) 更能反映道路的單行/雙行特性 ---
road_network = nx.DiGraph()# --- 3. 添加節點和邊 ---
for node, attrs in intersections.items():road_network.add_node(node, **attrs)
# add_weighted_edges_from 可以直接添加帶權重的邊
road_network.add_edges_from((u, v, d) for u, v, d in roads)# --- 4. 獲取圖的鄰接矩陣 ---
# 鄰接矩陣是GNN模型的核心輸入之一,它精確描述了節點間的連接關系。
# 它是GNN進行“鄰居聚合”操作的數學基礎。
node_list = list(road_network.nodes())
adjacency_matrix = nx.to_numpy_array(road_network, nodelist=node_list)
print("路網鄰接矩陣 (Adjacency Matrix):")
print(adjacency_matrix)
print(f"\n節點順序: {node_list}")
print("\n解讀: 矩陣中第i行第j列的非零值表示從節點i到節點j有一條邊。")# --- 5. 關聯節點特征 ---
# 在真實應用中,每個節點都會關聯一個時間序列特征矩陣。
# 形狀: [節點數量, 時間步數, 特征維度]
# 例如,過去12個5分鐘時間步,每個時間步有2個特征(車流量, 平均速度)
num_nodes = road_network.number_of_nodes()
timesteps = 12
features_per_step = 2
node_features = np.random.rand(num_nodes, timesteps, features_per_step)
print(f"\n為每個節點關聯的特征矩陣形狀: {node_features.shape}")
print("這些鄰接矩陣和節點特征矩陣,將作為STGCN模型的輸入。")# 可視化路網圖
# positions = nx.get_node_attributes(road_network, 'pos')
# edge_labels = {(u, v): d['length'] for u, v, d in road_network.edges(data=True)}
# nx.draw(road_network, positions, with_labels=True, node_color='skyblue', node_size=2500, font_weight='bold')
# nx.draw_networkx_edge_labels(road_network, positions, edge_labels=edge_labels)
# plt.title("More Detailed Urban Road Network Graph")
# plt.show()```---三、 Foundational 數據層:基于混合分類模型的軌跡提純
所有上層智能模型——無論是微觀的ETA預測,還是宏觀的交通預測——都建立在一個共同的、不容動搖的基礎之上:高質量、純凈的輸入數據。高德地圖每日處理的軌跡數據規模已達億萬級別,這些由用戶設備上傳的GPS點構成了整個智能體系的“血液”。然而,原始的軌跡數據是混雜的、充滿噪聲的。它不僅包含了駕車用戶的軌跡,還大量混入了步行、騎行、跑步,甚至是地鐵、公交等多種模式的軌跡。如果不能對這些數據進行精確的清洗和分類,將會導致嚴重的**“數據污染”(Data Pollution)**。
這種污染的后果是災難性的。試想一個場景:某條主干道因舉辦馬拉松比賽而對機動車臨時封閉。此時,成千上萬的參賽者和觀眾會在這條路上產生密集的步行軌跡。如果系統無法區分這些軌跡的交通方式,它會錯誤地認為這條路“人聲鼎沸、交通繁忙”,甚至可能因為平均速度低而將其判斷為“擁堵”,從而繼續向駕車用戶推薦這條根本無法通行的路線。因此,準確的軌跡分類,是保證所有上層應用真實可靠的生命線,是整個智能體系的“免疫系統”。
3.1 挑戰:標簽稀疏與模式復雜性
軌跡分類面臨兩大核心技術挑戰:
- 真值標簽的極度稀疏:系統在收到一條軌跡時,幾乎無法100%確定其真實的出行方式。雖然可以將用戶的導航模式(如選擇了“駕車導航”)作為一種“弱標簽”或“偽標簽”,但用戶行為具有極大的不確定性。一個用戶可能開著駕車導航步行去取車,或者在到達目的地后忘記關閉導航。依賴這種噪聲巨大的標簽來訓練模型,效果可想而知。
- 出行模式的特征重疊:不同出行模式在某些場景下,其特征會高度相似。例如,在極度擁堵路段蠕行的汽車,其平均速度可能與步行無異;而高速行駛的電動自行車,其速度又可能與在市區低速行駛的汽車相當。外賣騎手在商圈內的復雜穿梭軌跡,在空間形態上也與尋找停車位的汽車軌跡有相似之處。
3.2 范式革新:統計學習與表示學習的互補“組合拳”
為了應對這些嚴峻的挑戰,高德地圖的算法工程師們并未押注于單一模型,而是采用了一套結合了傳統統計學習和前沿深度學習優勢的、互為補充的“組合拳”策略。
3.2.1 基于概率圖模型的貝葉斯分類器
在模型構建的早期探索階段,工程師們首先回歸統計學本質,從軌跡中提取了橫跨五大類的數百維人工統計特征,包括:
- 軌跡概況特征:總時長、總長度、首末點直線距離與軌跡長度比(彎曲度)等。
- 速度特征:最大速度、平均速度、速度標準差、各速度區間的時長占比等。
- 時間特征:推測的紅燈等待總時長、掉頭耗時等。
- 行為特征:掉頭次數、急轉彎次數等。
- 空間特征:軌跡點的空間聚集度(Gini系數)等。
在這些高維特征的基礎上,利用高斯樸素貝葉斯(Gaussian Naive Bayes)分類器進行分類。貝葉斯方法的優勢在于其明確的統計學意義和良好的可解釋性。例如,通過分析特征的概率密度函數,可以清晰地看到,汽車軌跡的“最大速度”特征通常服從一個均值較高(如80km/h)的正態分布,而步行軌跡則服從一個均值極低(如8km/h)的正態分布。
然而,樸素貝葉斯有一個過強的“特征條件獨立”假設(即認為平均速度和停頓比例之間沒有關聯),這與事實不符。為了解決這個問題,工程師們還通過構建更復雜的**貝葉斯網絡(Bayesian Network)**來優化模型。貝葉斯網絡允許定義特征之間的依賴關系,通過學習聯合概率分布來建模,這有效解決了諸如“長距離騎行軌跡因總時長和總長度與駕車相似而被誤判”的棘手問題。
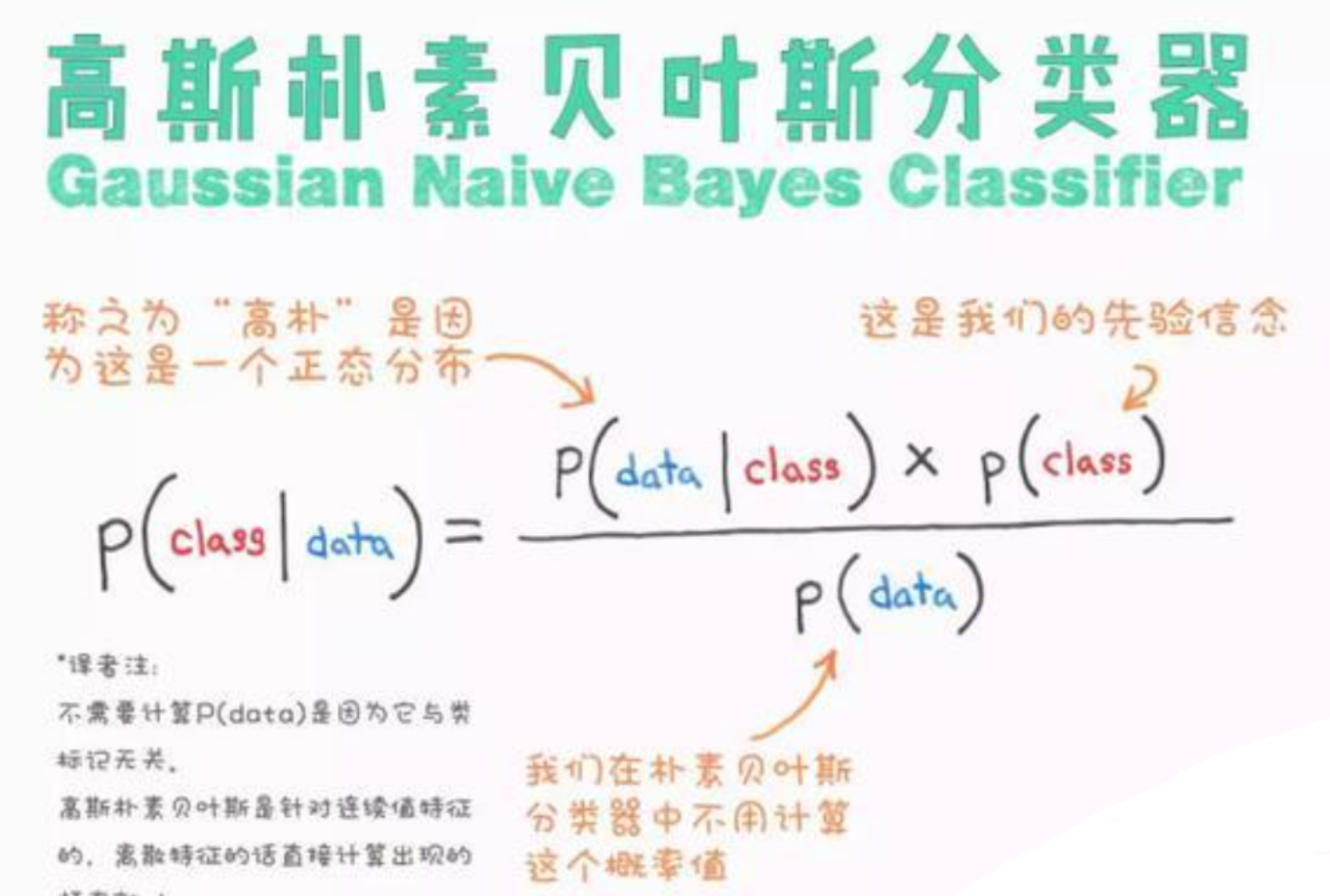
代碼示例1:基于統計特征的貝葉斯分類器
此代碼使用Scikit-learn,演示了如何基于軌跡的宏觀統計特征來訓練一個高斯樸素貝葉斯分類器,這是一個快速且有效的基線模型。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report# --- 1. 模擬更豐富的軌跡統計特征數據 ---
data = {'avg_speed_kmh': [45.2, 5.1, 60.5, 8.3, 30.1, 4.5, 25.8, 55.0, 15.3, 4.8, 18.2],'stop_ratio': [0.1, 0.5, 0.05, 0.6, 0.2, 0.45, 0.25, 0.1, 0.3, 0.55, 0.28],'straightness': [0.95, 0.8, 0.98, 0.7, 0.9, 0.75, 0.92, 0.96, 0.85, 0.65, 0.88], # 軌跡彎曲度'mode': ['driving','walking','driving','walking','driving','walking','driving','driving','cycling','walking','cycling']
}
df = pd.DataFrame(data)# --- 2. 準備特征(X)和標簽(y) ---
X = df[['avg_speed_kmh', 'stop_ratio', 'straightness']]
y = df['mode']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# --- 3. 訓練高斯樸素貝葉斯模型 ---
# 該模型對每個類別,獨立地估計每個特征的均值和方差,然后使用貝葉斯定理進行預測。
model = GaussianNB()
model.fit(X_train, y_train)# --- 4. 評估模型性能 ---
y_pred = model.predict(X_test)
print("模型分類報告:")
print(classification_report(y_test, y_pred))# --- 5. 預測新軌跡 ---
new_trajectory = [[28.5, 0.22, 0.91]] # 特征介于driving和cycling之間
predicted_mode = model.predict(new_trajectory)[0]
predicted_proba = model.predict_proba(new_trajectory)print(f"\n新軌跡 {new_trajectory} 被預測為: {predicted_mode}")
print(f"預測的概率分布: {list(zip(model.classes_, predicted_proba[0]))}")
3.2.2 基于表示學習的CNN分類器
為了突破人工特征的天花板,充分發揮深度學習自動提取層次化特征的強大能力,高德的工程師們提出了一種極具創意的 “軌跡圖像化”(Trajectory-as-an-Image) 方法。該方法的核心思想是將一個本質上是一維時序數據的軌跡,巧妙地 “升維”**并轉換為一張二維圖像,從而將軌跡分類問題轉化為一個計算機視覺領域已經研究得非常透徹的圖像分類問題。
這個轉換過程大致如下:
- 空間投影:將軌跡的所有GPS點(經緯度坐標)進行歸一化處理后,投影到一個固定大小的二維畫布(例如64x64像素)上,形成軌跡的黑白空間形態骨架。
- 動態信息編碼:將軌跡的動態屬性,如每個點的瞬時速度、加速度、方向角(bearing)等,進行歸一化,并將這些值編碼為像素的顏色和亮度。例如,可以使用圖像的RGB三個通道,分別編碼速度、加速度和方向角。這樣,一個高速行駛的直線軌跡點可能顯示為亮紅色,一個低速轉彎的點可能顯示為暗藍色。
通過這種變換,一條軌跡就從一串枯燥的坐標數字,變成了一張蘊含豐富時空信息的“指紋圖”。高速、平滑的駕車軌跡在圖上可能呈現為一條色彩漸變均勻的平滑曲線;而外賣騎手在商圈內的軌跡則可能呈現為一個色彩斑駁、路徑交錯的復雜色塊。
接下來,便可以利用在圖像識別領域取得巨大成功的卷積神經網絡(CNN)(如ResNet, VGG等)來對這些軌跡圖進行分類。CNN的多層卷積核能夠自動、分層次地學習和捕捉軌跡在空間分布上的各種模式:淺層卷積核可能學習到“直線”、“轉角”等基本元素,深層卷積核則能學習到“沿主干道行駛”、“在小范圍內穿梭”等更高級的語義模式。這種端到端的“表示學習”(Representation Learning)方法,完全擺脫了對人工特征的依賴,能夠發現更多人類難以察覺的、隱藏在數據中的分類依據,作為對貝葉斯模型的有力補充和交叉驗證。
代碼示例2:軌跡圖像化方法的概念
下面的偽代碼描述了將軌跡轉換為圖像,以便使用CNN處理的根本思路,展示了信息編碼的核心邏輯。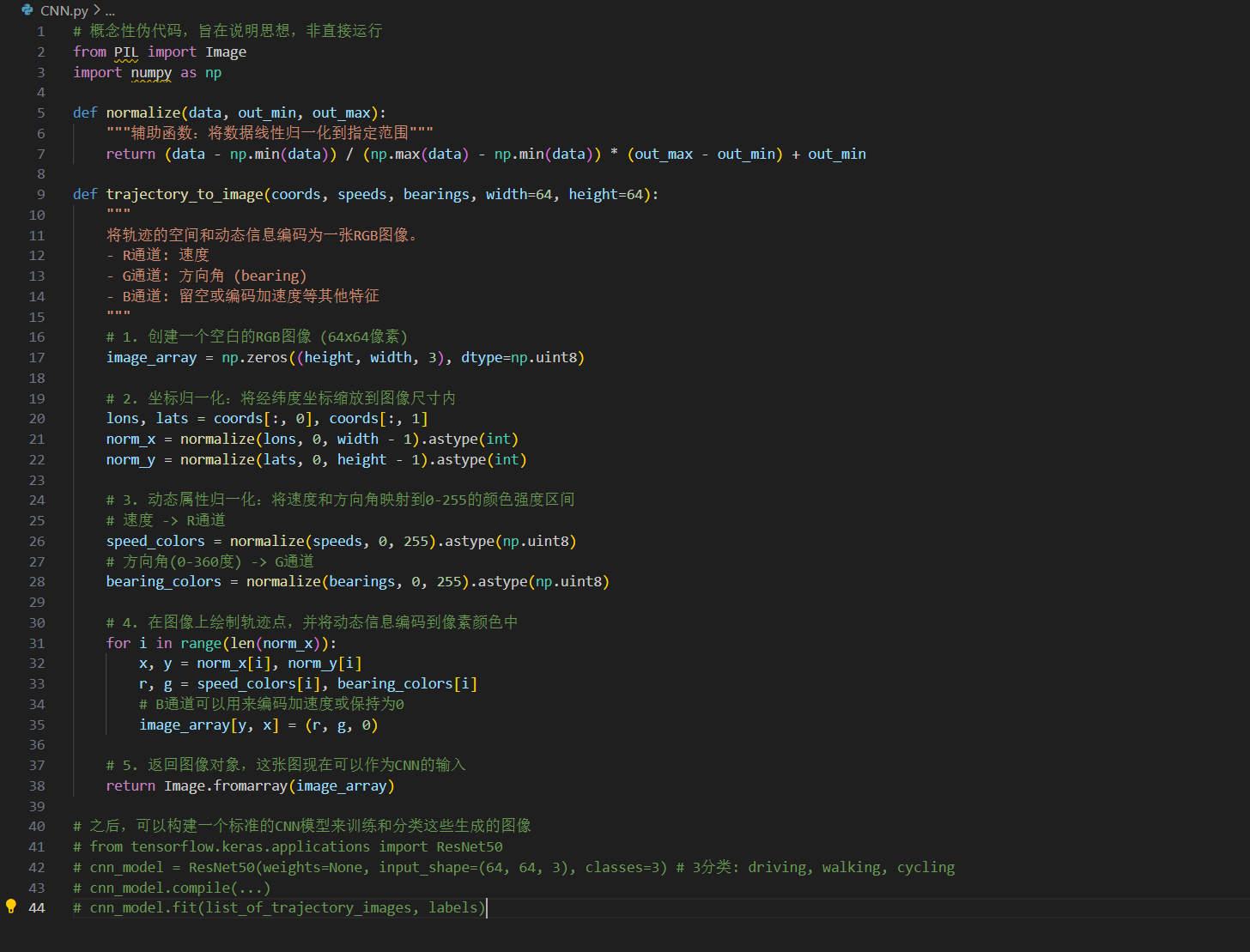
# 概念性偽代碼,旨在說明思想,非直接運行
from PIL import Image
import numpy as npdef normalize(data, out_min, out_max):"""輔助函數:將數據線性歸一化到指定范圍"""return (data - np.min(data)) / (np.max(data) - np.min(data)) * (out_max - out_min) + out_mindef trajectory_to_image(coords, speeds, bearings, width=64, height=64):"""將軌跡的空間和動態信息編碼為一張RGB圖像。- R通道: 速度- G通道: 方向角 (bearing)- B通道: 留空或編碼加速度等其他特征"""# 1. 創建一個空白的RGB圖像 (64x64像素)image_array = np.zeros((height, width, 3), dtype=np.uint8)# 2. 坐標歸一化:將經緯度坐標縮放到圖像尺寸內lons, lats = coords[:, 0], coords[:, 1]norm_x = normalize(lons, 0, width - 1).astype(int)norm_y = normalize(lats, 0, height - 1).astype(int)# 3. 動態屬性歸一化:將速度和方向角映射到0-255的顏色強度區間# 速度 -> R通道speed_colors = normalize(speeds, 0, 255).astype(np.uint8)# 方向角(0-360度) -> G通道bearing_colors = normalize(bearings, 0, 255).astype(np.uint8)# 4. 在圖像上繪制軌跡點,并將動態信息編碼到像素顏色中for i in range(len(norm_x)):x, y = norm_x[i], norm_y[i]r, g = speed_colors[i], bearing_colors[i]# B通道可以用來編碼加速度或保持為0image_array[y, x] = (r, g, 0)# 5. 返回圖像對象,這張圖現在可以作為CNN的輸入return Image.fromarray(image_array)# 之后,可以構建一個標準的CNN模型來訓練和分類這些生成的圖像
# from tensorflow.keras.applications import ResNet50
# cnn_model = ResNet50(weights=None, input_shape=(64, 64, 3), classes=3) # 3分類: driving, walking, cycling
# cnn_model.compile(...)
# cnn_model.fit(list_of_trajectory_images, labels)
通過這套“傳統+現代”、“統計+表示”的混合分類系統,高德地圖建立起了一道堅固的數據防火墻。它如同一個高精度的、多級串聯的過濾器,確保了流入上層ETA和交通預測模型的數據是純凈可靠的,為整個宏偉的智能體系的穩定性與準確性提供了最堅實的Foundational保障。
四、 交互與決策層:基于大語言模型的空間智能體
在前三個層次,深度學習為高德地圖構建了強大的對物理世界交通系統的 “感知”(通過軌跡分類)和 ** “預測” (通過ETA和交通預測)能力。然而,如何將這些強大但深藏于后臺的能力,以一種更自然、更強大、更符合人類認知習慣的方式提供給用戶,是通往真正“智能”的最后一公里。隨著以GPT為代表的大語言模型(LLM)技術的成熟,人機交互的范式正在經歷一場從圖形界面(GUI)的點擊操作,到自然語言對話式交互的根本性革命。高德地圖敏銳地捕捉到了這一歷史性機遇,將其AI戰略推向了一個全新的高度:構建“空間智能體”(Spatial Agent)**。
4.1 范式困境:從執行指令到理解意圖
傳統的地圖應用,無論功能多么強大,其本質上仍然是一個被動的**“工具”。它忠實地執行用戶通過點擊和輸入框下達的、結構化的、明確的指令(例如,“導航去北京南站”)。但它無法理解用戶更復雜、更模糊、更接近人類日常交流的真實“意圖”**。例如,一個用戶心中模糊的想法可能是:“這個周末天氣不錯,我想在北京找個地方,能讓老人輕松地散散步,又能讓孩子玩得開心,最好人別太多,開車過去一個小時內能到。”
對于傳統地圖,用戶必須自己將這個復雜的意圖“翻譯”成一連串的、獨立的、機械的操作:
- 搜索“公園”,在結果中逐個查看評價和圖片。
- 搜索“親子樂園”,再進行一輪篩選。
- 將幾個備選地點分別設為目的地,查看導航時間。
- 在多個APP之間切換,查詢天氣、開放時間等。
這個過程是繁瑣、低效且充滿心智負擔的。
4.2 范式革新:以LLM為核心的“理解-推理-行動”循環
高德推出的業內首個專精出行生活的智能體“小高老師”,其核心是一個經過海量出行領域數據和指令精調(Instruction Fine-Tuning)的大語言模型。它扮演的不再是被動的工具,而是一個能夠進行復雜任務規劃的**“決策大腦”或“行動中樞”。其工作流程遵循一個在AI Agent領域經典的“理解-推理-行動”(Understand-Reason-Act)**循環。
-
理解(Understand):當接收到用戶用自然語言提出的模糊請求時,智能體的第一步是利用LLM強大的自然語言理解(NLU)和意圖識別能力,將這段話分解為一系列結構化的、可執行的約束條件和子任務。例如,從“周末帶老人小孩去北京玩,清凈點,車程1小時內”,LLM會解析出:
時間=本周末,地點=北京,人群=老人, 小孩,偏好=清凈,交通約束=駕車時長<60分鐘。 -
推理與工具調用(Reason & Act):這是智能體的核心所在。LLM本身并不直接存儲或計算實時路況、POI信息等事實性數據,這樣做會使其信息迅速過時且容易“幻覺”。相反,它被訓練成一個卓越的**“推理引擎”和“任務編排器”。它會根據上一步分解出的子任務,智能地選擇并調用高德后臺封裝好的各種原子能力,這些能力被稱為“工具”(Tools)或API**。
- 這個“工具箱”里應有盡有,其中就包括了前文述及的ETA預測模型、實時路況預測服務、POI檢索引擎、路線規劃引擎,還包括天氣查詢、酒店/門票預訂、用戶評價分析等近百種服務。
- 推理過程是多輪的、動態的。例如,LLM可能會先調用
find_pois(city="北京", keywords=["公園", "親子", "人少"]),得到一個候選列表。然后,它會對列表中的每個地點,循環調用plan_route(origin="用戶當前位置", destination="候選地點", mode="driving")來獲取預估的ETA。如果發現某個地點的ETA超過了60分鐘,它會在內部的“思考”鏈條中將其剔除。它甚至可以進一步調用get_poi_reviews(poi_name, keyword="老人")來分析用戶評價,確認該地是否真的適合老年人。
-
行動與生成(Act & Generate):在經過可能的多輪、復雜的工具調用和內部推理之后,智能體已經收集并篩選了所有必要的信息。最后一步,它會利用LLM強大的自然語言生成(NLG)能力,將所有這些碎片化的、結構化的數據,重新組織、潤色,并以一種邏輯清晰、圖文并茂、極富親和力的多模態方式,向用戶呈現一個完整的、可執行的解決方案。這可能是一個包含每日行程安排、多個備選方案、路線概覽卡片和溫馨提示的完整頁面。
至此,智能體完成了從理解用戶模糊意圖,到規劃復雜任務,再到交付最終行動方案的完整閉環。
代碼示例:空間智能體工作流程的簡化模擬
以下Python代碼通過一個面向對象的框架,更清晰地模擬了智能體接收用戶請求后,如何進行思考、選擇工具、執行并最終生成回復的完整流程。
import numpy as np
import json# --- 1. 模擬后端工具箱 (APIs) ---
class ToolBox:def find_pois(self, city, keywords, user_preference):print(f" [工具調用 find_pois] 參數: city='{city}', keywords='{keywords}', pref='{user_preference}'")# 模擬數據庫查詢all_pois = {"世紀公園": {"tags": ["公園", "親子"], "crowd_level": 8, "suitable_for": ["老人", "小孩"]},"森林公園": {"tags": ["公園", "自然"], "crowd_level": 5, "suitable_for": ["老人"]},"歡樂谷": {"tags": ["樂園", "親子"], "crowd_level": 9, "suitable_for": ["小孩"]}}results = []for name, data in all_pois.items():if all(k in data["tags"] for k in keywords) and data["crowd_level"] < (6 if user_preference == "清凈" else 10):results.append({"name": name, "data": data})return json.dumps(results)def plan_route(self, origin, destination, mode="driving"):print(f" [工具調用 plan_route] 參數: origin='{origin}', dest='{destination}'")# 模擬調用底層的ETA預測模型eta_minutes = np.random.randint(20, 90)return json.dumps({"route_summary": f"從{origin}到{destination}的推薦路線", "eta_minutes": eta_minutes})# --- 2. 智能體核心邏輯 ---
class SpatialAgent:def __init__(self):self.toolbox = ToolBox()# 在真實場景中,這里會是一個與大語言模型交互的客戶端print("空間智能體已初始化。")def llm_reasoning_and_tool_use(self, prompt):# 這是對LLM“思考”過程的高度簡化模擬# Step 1: LLM解析意圖thought = "用戶想在北京找個適合老人和小孩的、人少的公園,且車程要在1小時內。我需要先找POI,再檢查路程。"print(f"[智能體思考] {thought}")# Step 2: LLM決定調用第一個工具tool_call_1 = {"tool_name": "find_pois", "parameters": {"city": "北京", "keywords": ["公園", "親子"], "user_preference": "清凈"}}print(f"[智能體決策] 準備調用工具: {tool_call_1}")poi_results_str = getattr(self.toolbox, tool_call_1["tool_name"])(**tool_call_1["parameters"])poi_results = json.loads(poi_results_str)# Step 3: LLM分析工具返回結果,并進行下一步決策thought = f"find_pois返回了{len(poi_results)}個結果: {[p['name'] for p in poi_results]}。現在我需要逐個檢查它們的車程。"print(f"[智能體思考] {thought}")final_candidates = []for poi in poi_results:tool_call_2 = {"tool_name": "plan_route", "parameters": {"origin": "用戶當前位置", "destination": poi["name"]}}print(f"[智能體決策] 準備調用工具: {tool_call_2}")route_info_str = getattr(self.toolbox, tool_call_2["tool_name"])(**tool_call_2["parameters"])route_info = json.loads(route_info_str)if route_info["eta_minutes"] <= 60:thought = f"'{poi['name']}'的車程是{route_info['eta_minutes']}分鐘,符合要求,加入候選列表。"print(f"[智能體思考] {thought}")final_candidates.append({"poi": poi, "route": route_info})else:thought = f"'{poi['name']}'的車程是{route_info['eta_minutes']}分鐘,超過1小時,排除。"print(f"[智能體思考] {thought}")return final_candidatesdef generate_final_response(self, candidates):# Step 4: LLM基于最終信息,生成自然語言回復if not candidates:return "非常抱歉,根據您的要求(特別是車程1小時內且人少),暫時沒有找到完全匹配的地點。或許放寬一些條件可以有更多選擇哦。"best_choice = candidates[0]response = f"為您精心規劃了周末出行方案!\n\n" \f"🌟 **首選推薦:{best_choice['poi']['name']}**\n" \f" - **特點**: {', '.join(best_choice['poi']['data']['tags'])}. 特別適合{', '.join(best_choice['poi']['data']['suitable_for'])}。\n" \f" - **擁擠度**: 相對較低,可以享受一個寧靜的周末。\n" \f" - **交通**: 從您當前位置出發,預計駕車 **{best_choice['route']['eta_minutes']}分鐘** 即可到達。\n\n" \f"我已經為您準備好了導航路線,隨時可以出發!"return responsedef run(self, user_prompt):print(f"\n--- 開始處理新請求 ---")print(f"用戶請求: '{user_prompt}'")# 核心:調用LLM進行推理和工具使用candidates = self.llm_reasoning_and_tool_use(user_prompt)# 生成最終回復final_response = self.generate_final_response(candidates)print("\n--- 智能體最終回復 ---")print(final_response)print("--- 請求處理完畢 ---\n")# 運行智能體
agent = SpatialAgent()
agent.run("周末想在北京找個適合帶老人和小孩玩的公園,要清凈點,開車別超過一小時")
結論:一個面向未來的整合式智能系統
通過對高德地圖深度學習架構的四個層次的穿透式解構,我們可以清晰地看到一條從數據智能到感知智能,再到認知智能的清晰演進路徑。這四個層次并非孤立的技術模塊,而是一個高度耦合、相互依存、層層遞進的整合式智能系統:
- Foundational 數據層是基石,其軌跡分類的準確性直接決定了上層模型的輸入質量。
- 微觀與宏觀預測層是系統的核心感知引擎,它們利用序列模型和圖模型,分別在個體和群體尺度上,賦予了地圖理解和預測物理世界交通狀態的能力。
- 交互與決策層是智能的最終出口,它利用大語言模型作為“中央大腦”,將底層強大的、但對用戶不可見的感知與預測能力,轉化為能夠理解人類意圖、主動規劃復雜任務并與之進行自然語言對話的、富有智慧的認知能力。
深度學習已經不再是散落在高德地圖各個功能點上的“優化插件”,而是已經成為重構整個導航服務之核的、無處不在的底層操作系統。它不僅在技術層面解決了諸多傳統方法難以逾越的難題,更在產品哲學上推動了一場深刻的變革——地圖服務的目標,不再僅僅是滿足用戶已經明確的出行需求,而是開始主動預測、引導并創造更美好、更便捷、更高效的出行與生活體驗。
未來的地圖,將不再是一個我們低頭查看的、冰冷的二維工具。它將是一個我們與之對話、能夠主動理解我們所處的復雜時空環境、并為我們提供最優決策的認知伙伴(Cognitive Companion)。高德地圖通過其系統性的深度學習架構實踐,不僅為我們展示了這一未來圖景的清晰樣貌,更在堅實地鋪就通往這一未來的道路。
)


)


)












