目錄
前言
一、單向鏈表
1、基本概念
2、單向鏈表的設計
(1)節點設計
(2)初始化空單向鏈表
(3)、初始化數據節點
(4)數據節點
(5)判斷鏈表是否為空
(6)遍歷鏈表
(7)刪除數據
(8)銷毀整個鏈表
(9)修改數據
前言
????????在軟件的世界里,程序 = 數據結構 + 算法。這句廣為流傳的名言,深刻地揭示了數據結構的核心地位。它是我們組織、存儲和管理數據的藝術,是構建高效、穩定應用程序的基石。而在眾多數據結構中,線性表作為最基礎、最常用的一種,其重要性不言而喻。
????????順序表和單向鏈表,正是線性表兩種最經典的實現方式。它們如同“一體兩面”,代表了計算機中兩種最根本的物理存儲思想:連續的空間與離散的空間。
順序表憑借其底層連續的物理結構,帶來了無與倫比的隨機訪問性能,仿佛一本頁碼清晰的書籍,我們可以根據目錄瞬間翻到任何一頁。然而,這種連續性的代價便是在中間進行插入或刪除時,可能引發大規模的“數據搬遷”,效率堪憂。
單向鏈表則巧妙地利用指針,將離散的內存空間“串聯”起來。它犧牲了隨機訪問的能力,換來了在任意位置高效插入與刪除的靈活性,如同一條環環相扣的鏈條,只需改變節點的指向,即可輕松完成結構的調整。
????????理解二者的內在原理、優缺點以及適用場景,是每一位開發者內功修煉的必經之路。這不僅是為了應對面試官的考問,更是為了在未來的開發中,能夠根據實際需求,做出最合理的技術選型,寫出性能更優、更優雅的代碼。
一、單向鏈表
1、基本概念
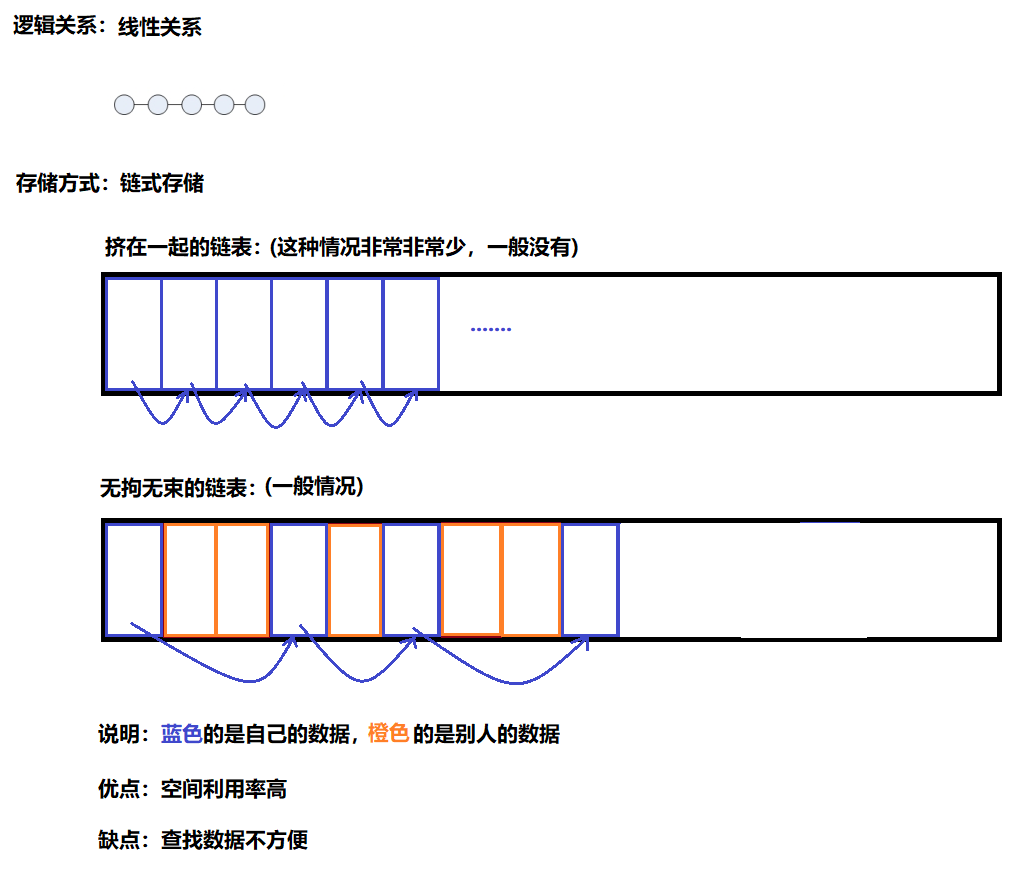
概念:????????
????????鏈式存儲的線性表,簡稱鏈表(線性關系+鏈式存儲)
圖解:
說明:
????????既然順序存儲中的數據因為擠在一起而導致需要成片移動,那很容易想到的解決方案是將數據離散的存儲在不同的內存塊中,然后用指針將它們串起來,這種樸素的思路所形成的鏈式線性表,就是所謂鏈表(單向鏈表(單向循環鏈表)、雙向鏈表(雙向循環鏈表))
2、單向鏈表的設計
1、節點設計 2、初始化空單向鏈表(初始化頭節點) 3、初始化數據節點 4、增刪查改單向鏈表// 前提:判斷鏈表是否為空a、增:頭插法、尾插法b、查:遍歷鏈表c、刪:刪除鏈表中的某個數據、銷毀整個鏈表d、改:修改鏈表中的某個數據(1)節點設計
說明:
? ? ? ? 單向鏈表節點包含兩個域,一個數據域一個指針域,數據域存放用戶的數據,指針域指向本節點或指向相鄰下一個節點。
typedef struct node {// 數據域int data; // 指針域struct node* next_p; // 指向相鄰的下一個節點的指針}node_t, *node_p;(2)初始化空單向鏈表
概念:
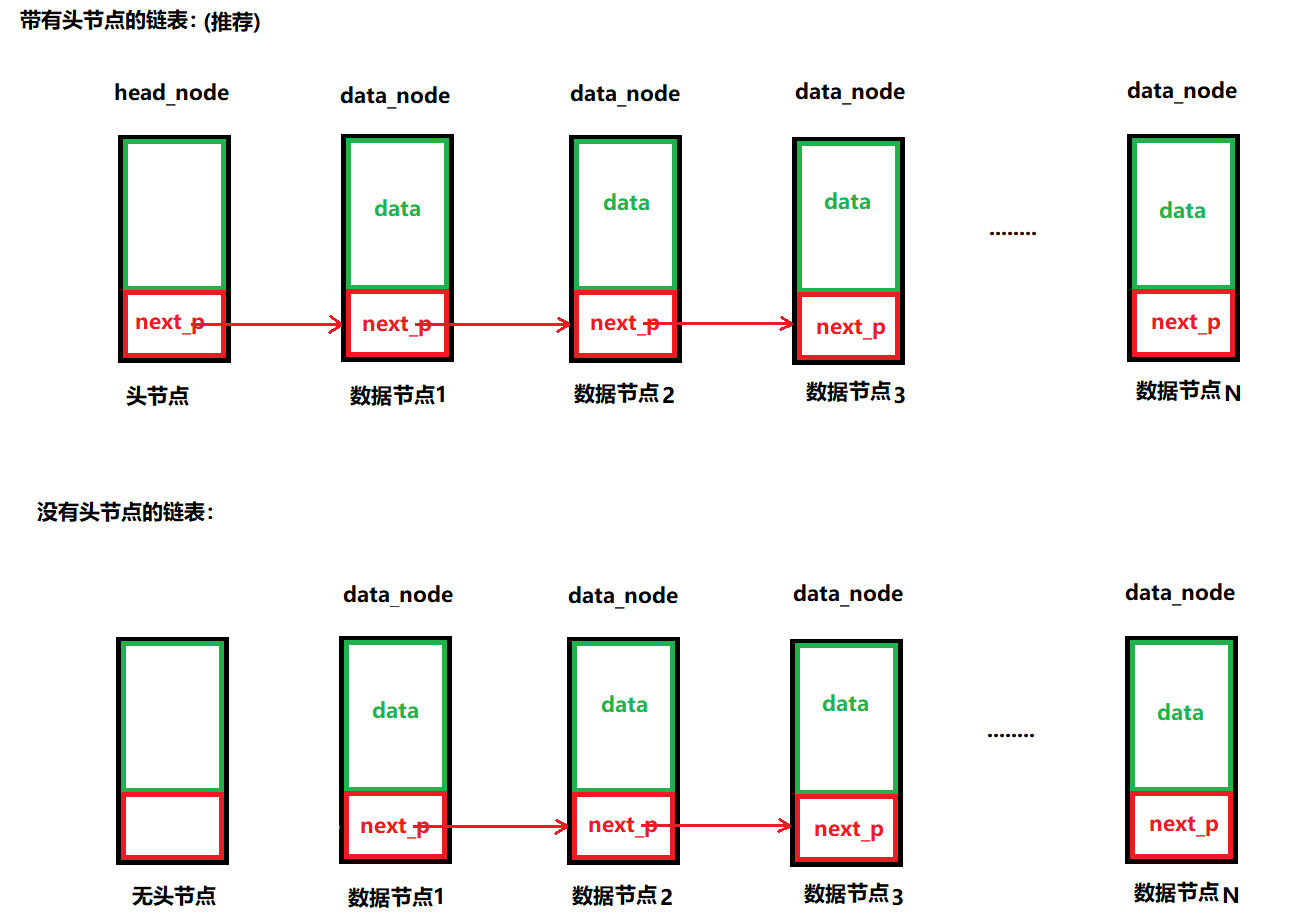
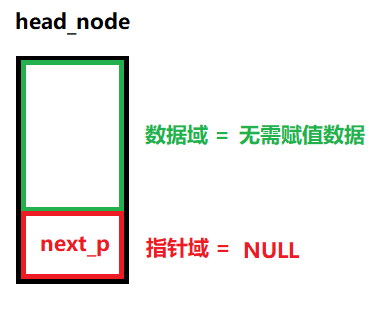
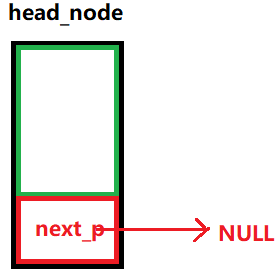
????????首先鏈表有兩種常見的形式,一種是帶有所謂的頭節點的,一種是不帶頭節點的,所謂的頭節點是不存放有效數據的節點,僅僅用來方便操作
圖解:
????????
注意:
????????頭節點head_node是可選的,為了方便某些操作,建議大家有頭節點好一些
????????頭節點的指針:head_node的next_p
說明:
????????由于頭節點不存放有效數據的,因此如果空鏈表中帶有頭節點,那么頭指針(head_node的next_p)將永遠不變,這會給以后的鏈表操作帶來些許便捷
圖解:
示例代碼:
/*** @brief 初始化空單向鏈表(初始化頭節點)* @note None* @param None* @retval 成功:返回指向這個頭節點的指針* 失敗:返回NULL */ node_p LINK_LIST_InitHeadNode(void) {// 1、給頭節點申請一個內存空間(堆內存)node_p p = malloc(sizeof(node_t));bzero(p, sizeof(node_t));// 2、將頭節點的next_p指針指向NULLif ( p!= NULL){// 數據域// 指針域p->next_p = NULL; // 防止指針亂指}else{return NULL;}// 3、成功返回頭節點return p; }(3)、初始化數據節點
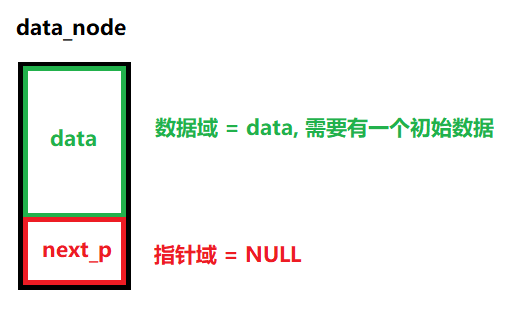
說明:
? ? ? ? 數據節點
圖解:
示例代碼:
????????
/*** @brief 初始化數據節點* @note None* @param data:數據節點中的數據* @retval 成功:返回指向這個數據節點的指針* 失敗:返回NULL */ node_p LINK_LIST_InitDataNode(int data) {// 1、給數據節點申請一個內存空間(堆內存)node_p p = malloc(sizeof(node_t));bzero(p, sizeof(node_t));// 2、將數據節點的next_p指針指向NULL,并且將傳進來的數據對此節點的數據進行賦值if ( p != NULL){// 數據域p->data = data; // 數據賦值// 指針域p->next_p = NULL; // 防止指針亂指}else{return NULL;}// 3、成功返回數據節點return p;}(4)數據節點
說明:
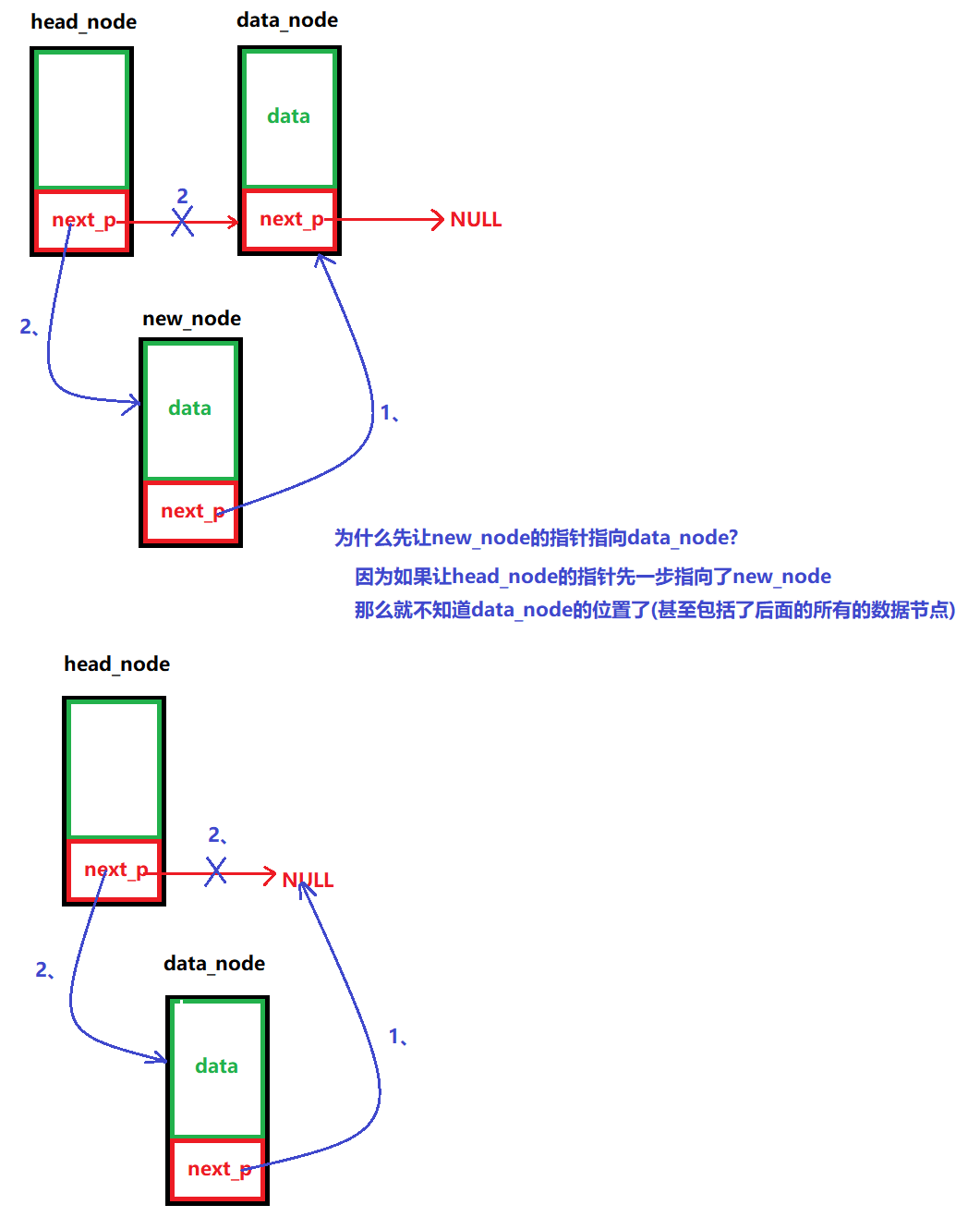
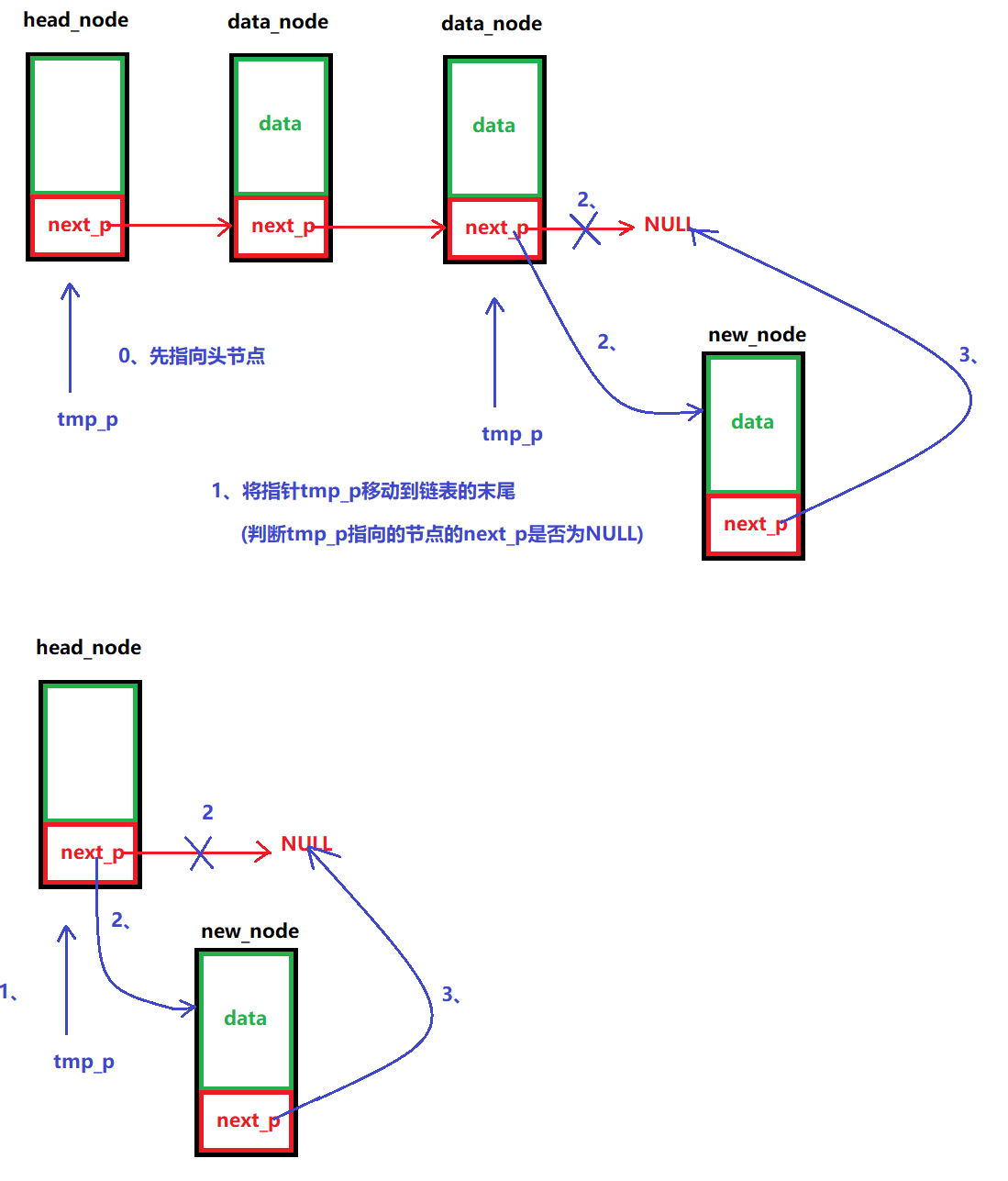
????????將數據節點插入到鏈表中,一種頭插法(鏈表中的頭節點的后面插進去),一種尾插法(鏈表中的最后一個節點后面插入進去)
圖解:
頭插法:
尾插法:
示例代碼:
/*** @brief 插入數據(頭插法)* @note None* @param head_node:頭節點* new_node: 要插入的數據節點* @retval None */ void LINK_LIST_InsertHeadDataNode(node_p head_node, node_p new_node) {// 1、先讓new_node里面的next_p指向data_node (head_node->next_p里面有data_node的地址)new_node->next_p = head_node->next_p;// 2、再讓head_node里面的next_p指向new_nodehead_node->next_p = new_node; }/*** @brief 插入數據(尾插法)* @note None* @param head_node:頭節點 * new_node: 要插入的數據節點* @retval None */ void LINK_LIST_TailInsertDataNode(node_p head_node, node_p new_node) {// 1、設置一個中間指針,將指針指向單向鏈表的末尾節點node_p tmp_p = NULL;for (tmp_p = head_node; tmp_p->next_p != NULL; tmp_p = tmp_p->next_p);// 2、讓tmp_p的next_p指向新節點tmp_p->next_p = new_node;// 3、再讓new_node的next_p指向NULLnew_node->next_p = NULL; }(5)判斷鏈表是否為空
說明:
????????如果頭節點的next_p指向的是NULL,那么就可以證明這個鏈表是空的
圖解:
示例代碼:
/*** @brief 判斷鏈表是否為空* @note None* @param head_node:頭節點 * @retval 如果鏈表為空:返回true* 如果鏈表非空:返回false */ bool LINK_LIST_IfEmpty(node_p head_node) {return head_node->next_p == NULL; }(6)遍歷鏈表
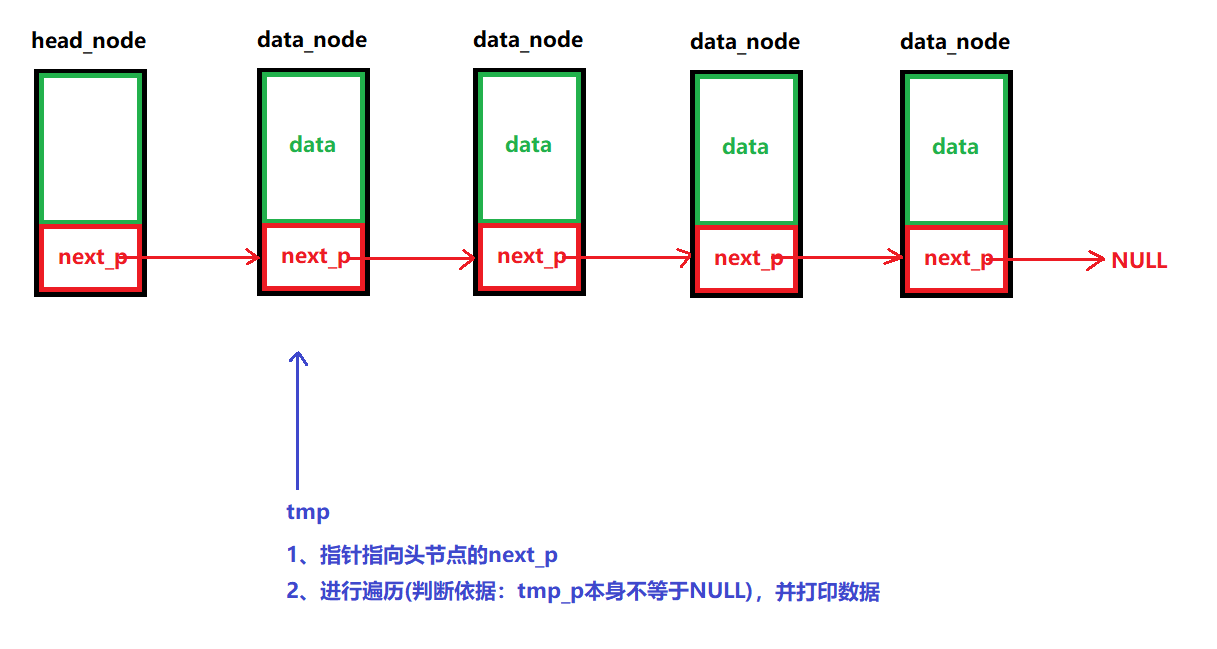
說明:
????????遍歷整個鏈表,并逐個打印里面的數據
圖解:
示例代碼:
/*** @brief 遍歷整個鏈表并打印出里面的數據* @note None* @param head_node:頭節點 * @retval 成功:返回0* 失敗:返回-1 */ int LINK_LIST_ShowListData(node_p head_node) {// 1、判斷鏈表是否為空,是的話,返回-1if (LINK_LIST_IfEmpty(head_node))return -1;// 2、遍歷整個鏈表,并逐個打印里面的數據node_p tmp_p = NULL;int i = 0;printf("======================鏈表中的數據==========================\n");for ( tmp_p = head_node->next_p; tmp_p!=NULL; tmp_p=tmp_p->next_p){printf("鏈表中的第%d的節點, 數據為: %d\n", i, tmp_p->data);i++;}printf("===========================================================\n");// 3、成功返回0return 0; }(7)刪除數據
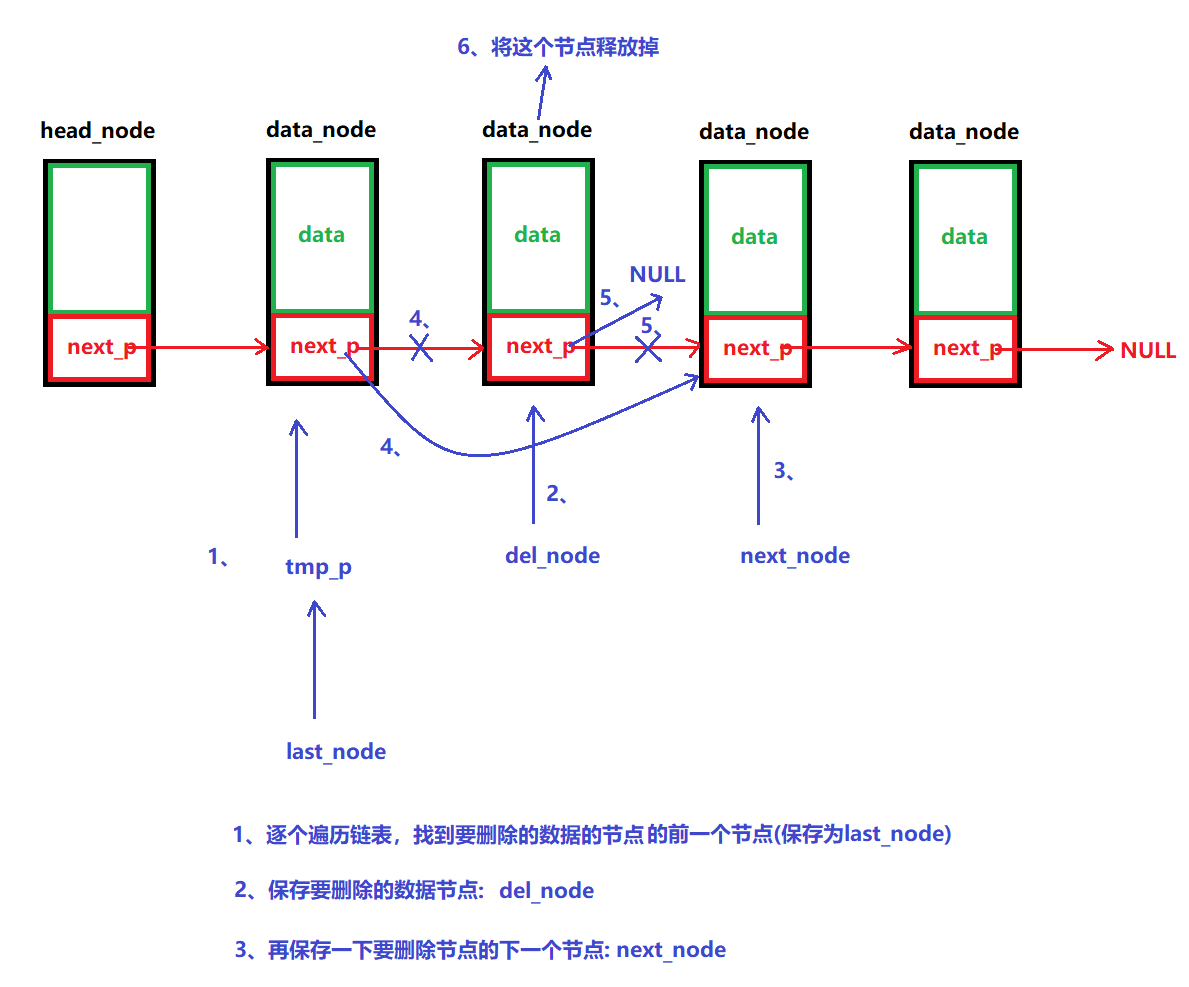
說明:
????????根據數據來刪除鏈表中的節點
圖解:
示例代碼:
/*** @brief 刪除數據* @note 根據數據的值找到鏈表中的節點,并將其刪除* @param head_node:頭節點 * del_data: 要刪除的數據 * @retval 成功:返回0* 失敗:返回-1 */ int LINK_LIST_DelDataNode(node_p head_node, int del_data) {// 1、判斷鏈表是否為空,是的話,返回-1if (LINK_LIST_IfEmpty(head_node))return -1;// 2、移動到要刪除的節點數據那里去node_p tmp_p = NULL;node_p last_node = NULL;node_p del_node = NULL;node_p next_node = NULL;// a、從頭到尾遍歷一遍,找到要刪除的數據for (tmp_p = head_node; tmp_p->next_p!=NULL; tmp_p=tmp_p->next_p){// b、判斷要刪除的數據if ( (tmp_p->next_p->data) == del_data){// c、保存刪除數據的上一個節點和下一個節點、及刪除節點last_node = tmp_p;del_node = tmp_p->next_p;next_node = del_node->next_p; break;}}// 3、繞過原鏈表要刪除的節點last_node->next_p = next_node;del_node->next_p = NULL;// 4、釋放要刪除節點的資源free(del_node);// 5、成功返回0return 0;}(8)銷毀整個鏈表
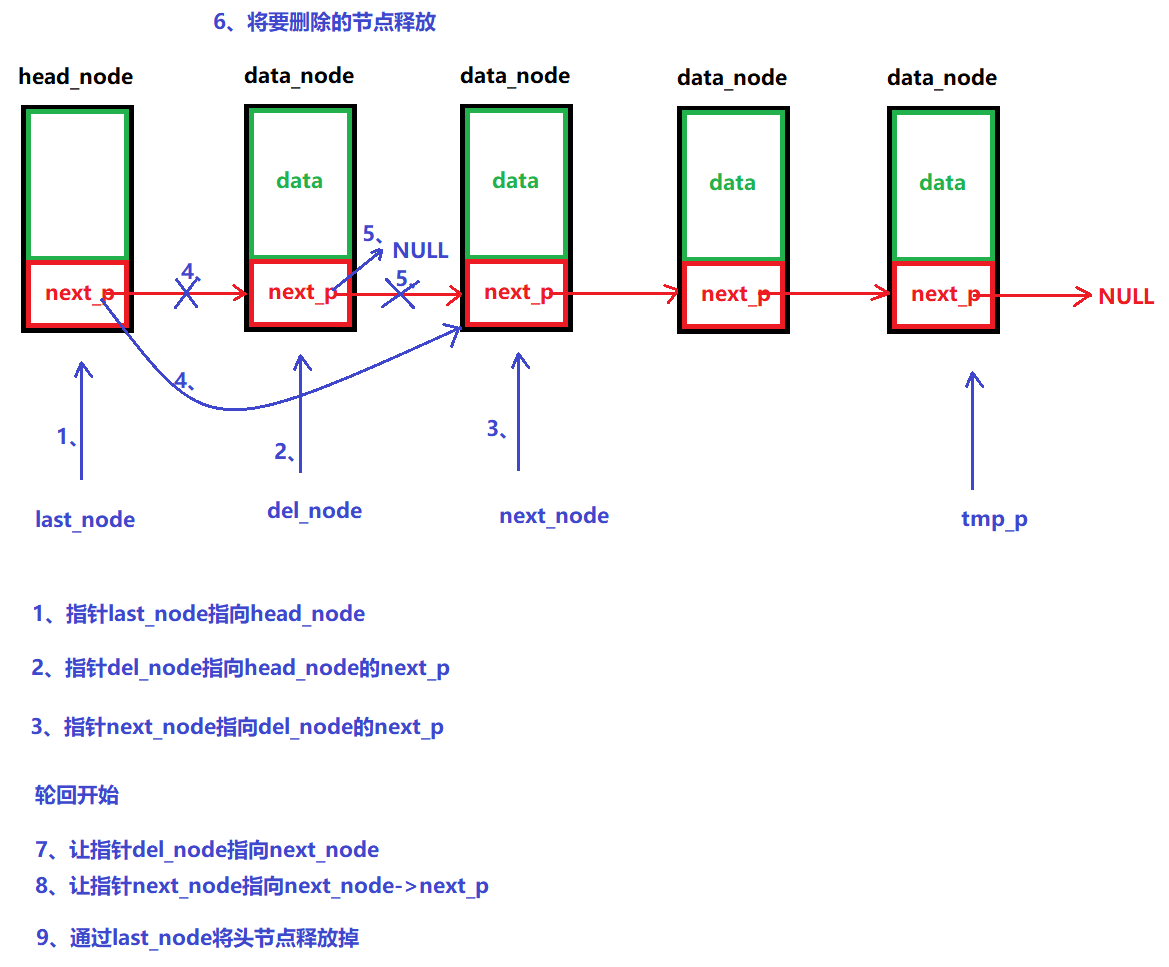
說明:
????????從頭節點開始,將其后面的數據節點一個個刪除,最后再刪除頭節點本身
圖解:
示例代碼:
/*** @brief 銷毀鏈表* @note None* @param head_node:頭節點 * @retval None */ void LINK_LIST_UnInit(node_p head_node) {// 1、如果鏈表為空,那么直接釋放頭節點空間即可if (LINK_LIST_IfEmpty(head_node)){free(head_node);return;}// 2、node_p tmp_p = NULL; // 遍歷node_p last_node = head_node;node_p del_node = head_node->next_p;node_p next_node = del_node->next_p;int num = 0;// 如果鏈表只有一個數據節點if (next_node == NULL){last_node->next_p = next_node;free(del_node);}// 否則else{for (tmp_p = head_node; tmp_p->next_p!=NULL; tmp_p=tmp_p->next_p){// a、刪除節點并釋放其內存last_node->next_p = next_node;free(del_node);printf("num == %d\n", num);num++;// b、輪回繼續del_node = next_node;next_node = next_node->next_p;}// 少刪除了一個節點數據last_node->next_p = next_node;free(del_node);}// 3、釋放頭節點free(head_node); }(9)修改數據
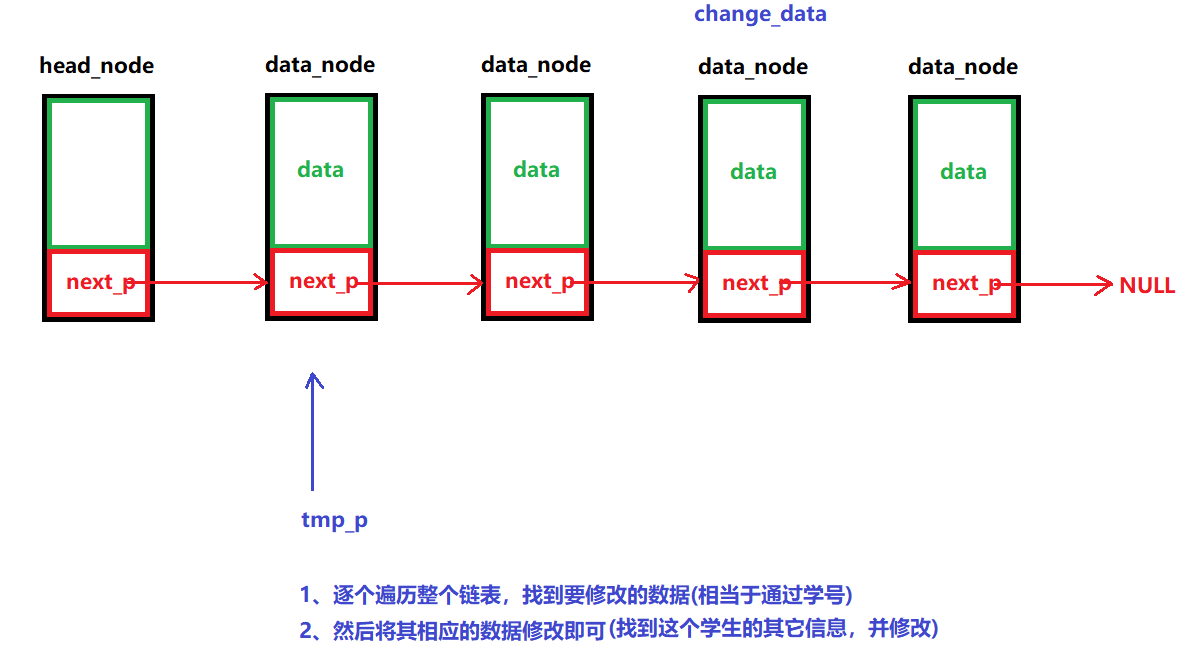
說明:
????????通過數據值,找到鏈表中的節點,并修改里面的數據
圖解:
示例代碼:
/*** @brief 修改數據* @note 根據數據的值來找到鏈表中的節點,對里面的數據進行修改* @param head_node: 頭節點 * data: 要修改的數據* change_data:修改的數據* @retval 成功:返回0* 失敗:返回-1 */ int LINK_LIST_ChangeNodeData(node_p head_node, int data, int change_data) {// 1、如果鏈表為空,那么直接釋放頭節點空間即可if (LINK_LIST_IfEmpty(head_node))return -1;// 2、遍歷整個鏈表,找到數據的節點,并修該節點的相應的數據node_p tmp_p = NULL;// a、遍歷所有可能for (tmp_p = head_node->next_p; tmp_p!=NULL; tmp_p=tmp_p->next_p){// b、找到要修改的數據if ((tmp_p->data) == data) // 根據學號{tmp_p->data = change_data; // 修改這個學生的其它信息break;} }// 3、成功返回0return 0; }














)


(中))

