文章目錄
- 1 什么是目標檢測
- 2 目標檢測常見的數據集
- 2.1 目標檢測數據集
- 2.2 目標檢測數據集的標注
- 2.3 目標檢測工具介紹
- 3 數據集的標注
- 3.1 VOC數據集標注
- 3.2 加載數據集
1 什么是目標檢測
希望計算機在視頻或圖像中定位并識別我們感興趣的目標
定位:找到目標在圖像中的位置。

識別:識別矩陣框中的內容

感興趣的目標:不僅是一些常規的目標,也可以是一些非常規的目標或者是抽象的目標。
2 目標檢測常見的數據集
2.1 目標檢測數據集
數據集涉及到輸入和輸出
輸入:圖片
輸出:帶有目標的標注
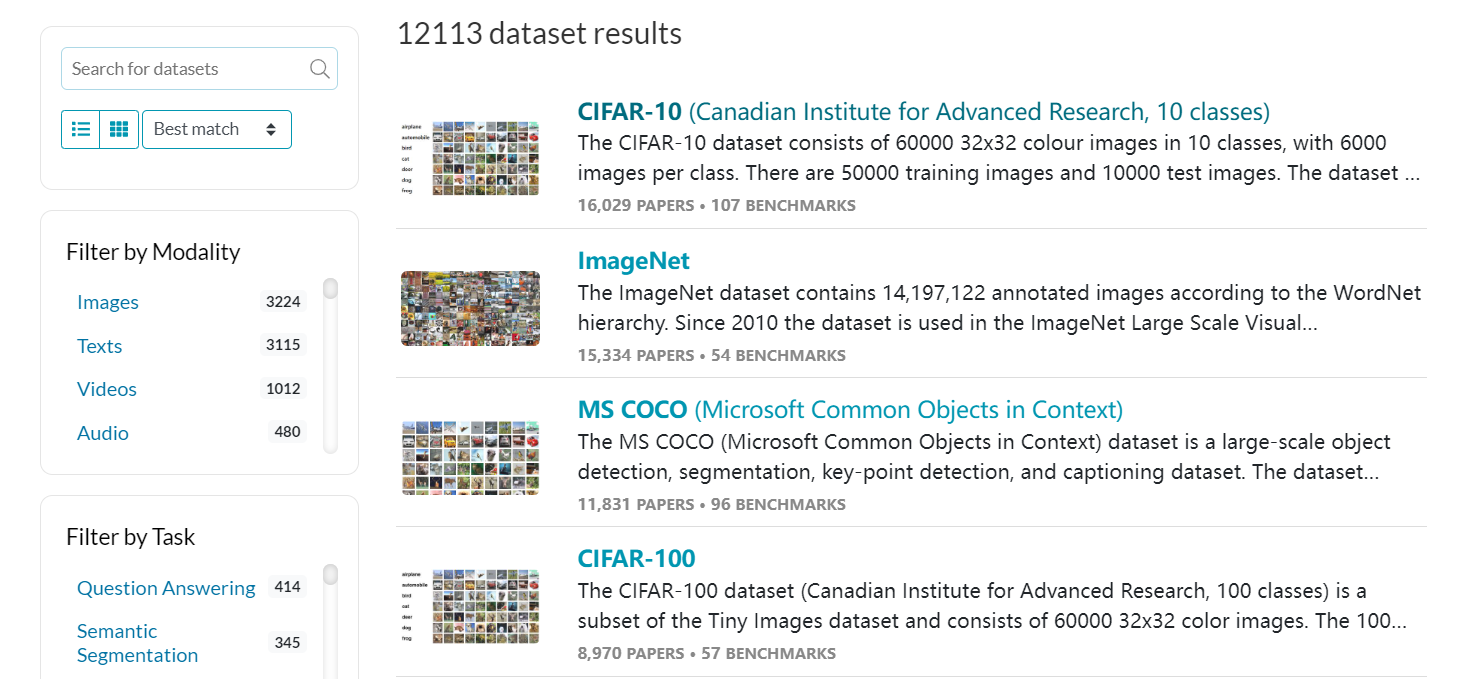
博主提到的數據集網站paperswitchcode停止維護
找到了保存往期的paperwithcode網頁快照,還能使用以前的功能
https://web.archive.org/web/20250616051252/https://paperswithcode.com/
VOC數據集,找了個能用的鏈接,需要登錄Google
https://www.kaggle.com/search?q=voc+in%3Adatasets
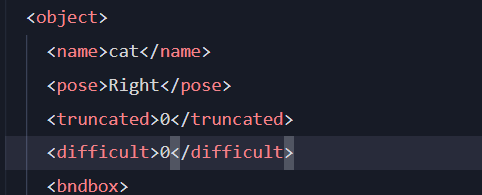
在標注的xml文件中,truncated表示能否標注完整(0標注完整),difficult表示是否能夠容易識別(0容易識別)
imagej工具下載鏈接
https://imagej.net/ij/download.html

目標框選

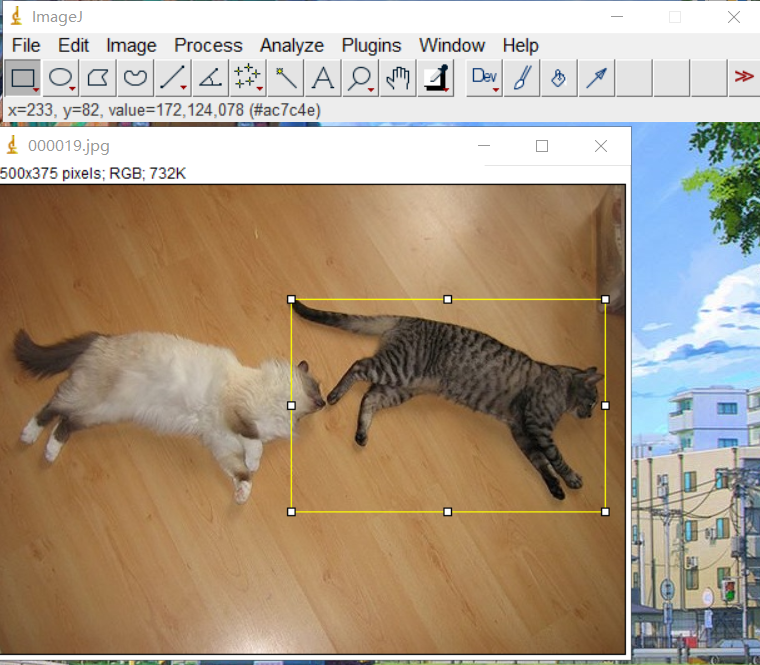
土堆的VOC數據集查看器
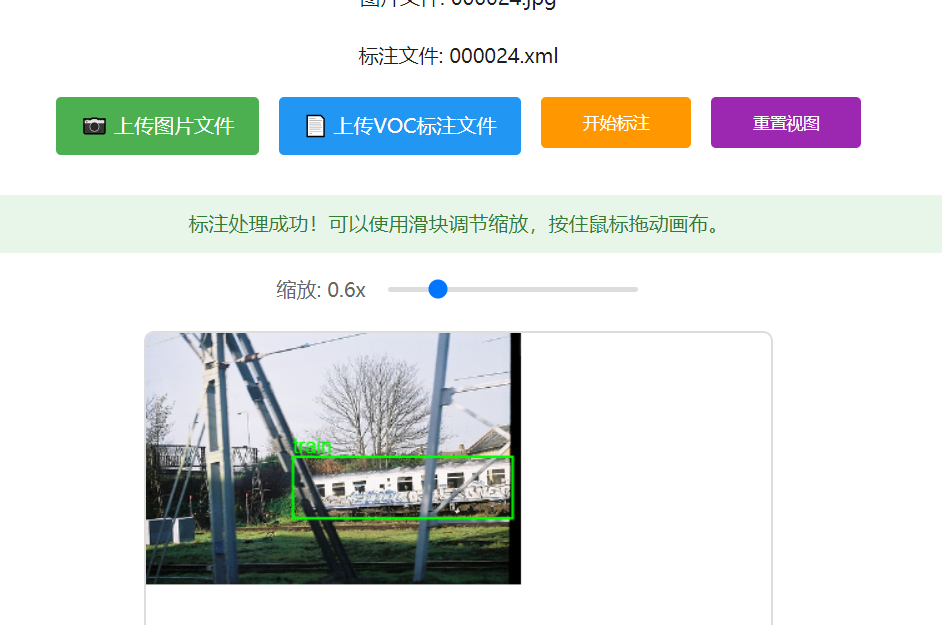
https://xiaotudui.com/tuduilab/voc-dataset-viewer
2.2 目標檢測數據集的標注
YOLO格式的標注,會將x_yolo,y_yolo,width_yolo,hight_yolo進行一個歸一化的處理,將范圍控制在[0,1],(Xcenter/ImageWidth,Ycenter/ImageHight,Width/ImageWidth,Hight/ImageHight)
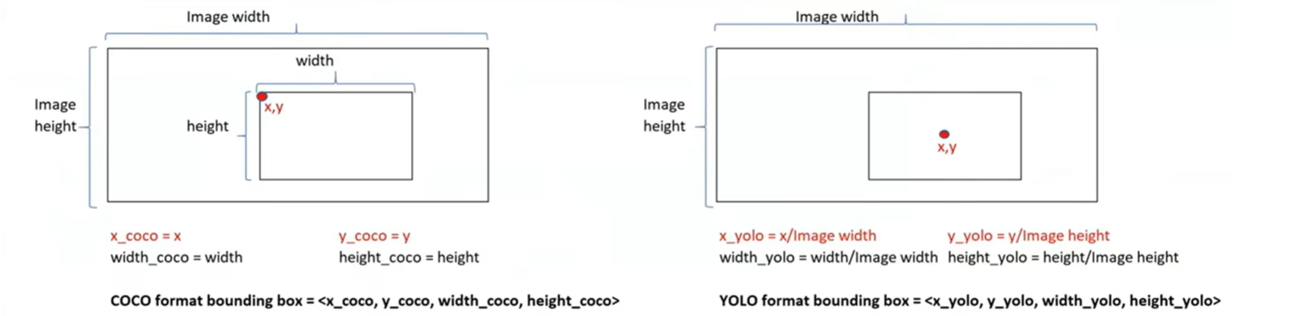
YOLO標注例子

YOLO格式<class_id,x_yolo,y_yolo,width_yolo,hight_yolo>
0 0.5 0.54 0.406 0.5135
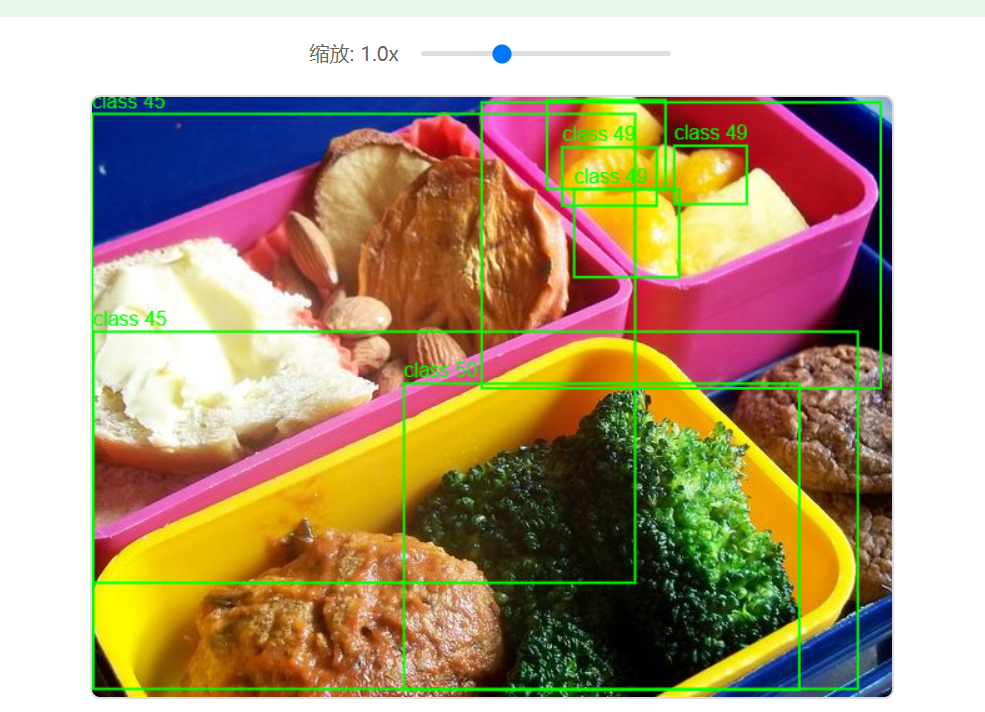
2.3 目標檢測工具介紹
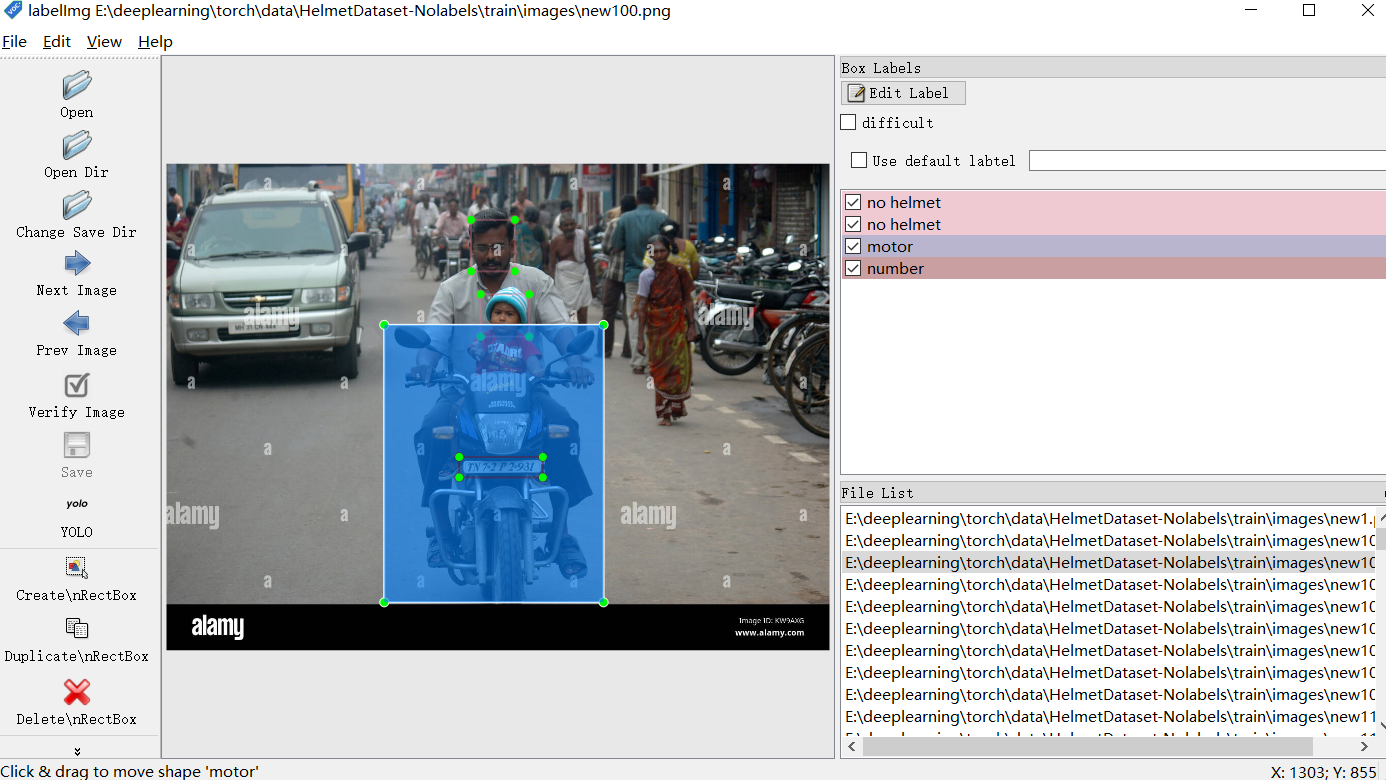
labellmg標注工具的使用
采集自己的數據集
明確任務–檢測沒有不帶頭盔的駕駛員,并檢測出摩托車車牌
抽象出感興趣的目標,摩托車
- 不帶頭盔的人 class id 0 no helmet
- 摩托車 class id 1 motor
- 摩托車車牌 class id 2 number
- 帶頭盔的人 class id 3 with helmet
標注工具,從up網盤下載
Labellmg
修改一下自己所需要的標簽
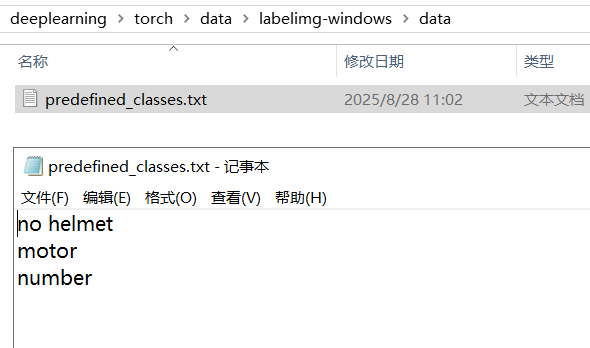
Open Dir打開目錄,Change Save Dir切換保存后的標注路徑,通過create框出感興趣目標,切換YOLO(txt)/VOC(xml)標注格式
labelstudio工具的使用
在python的虛擬環境中安裝labelstudio
pip install -U label-studio

啟動labelstudio
label-studio
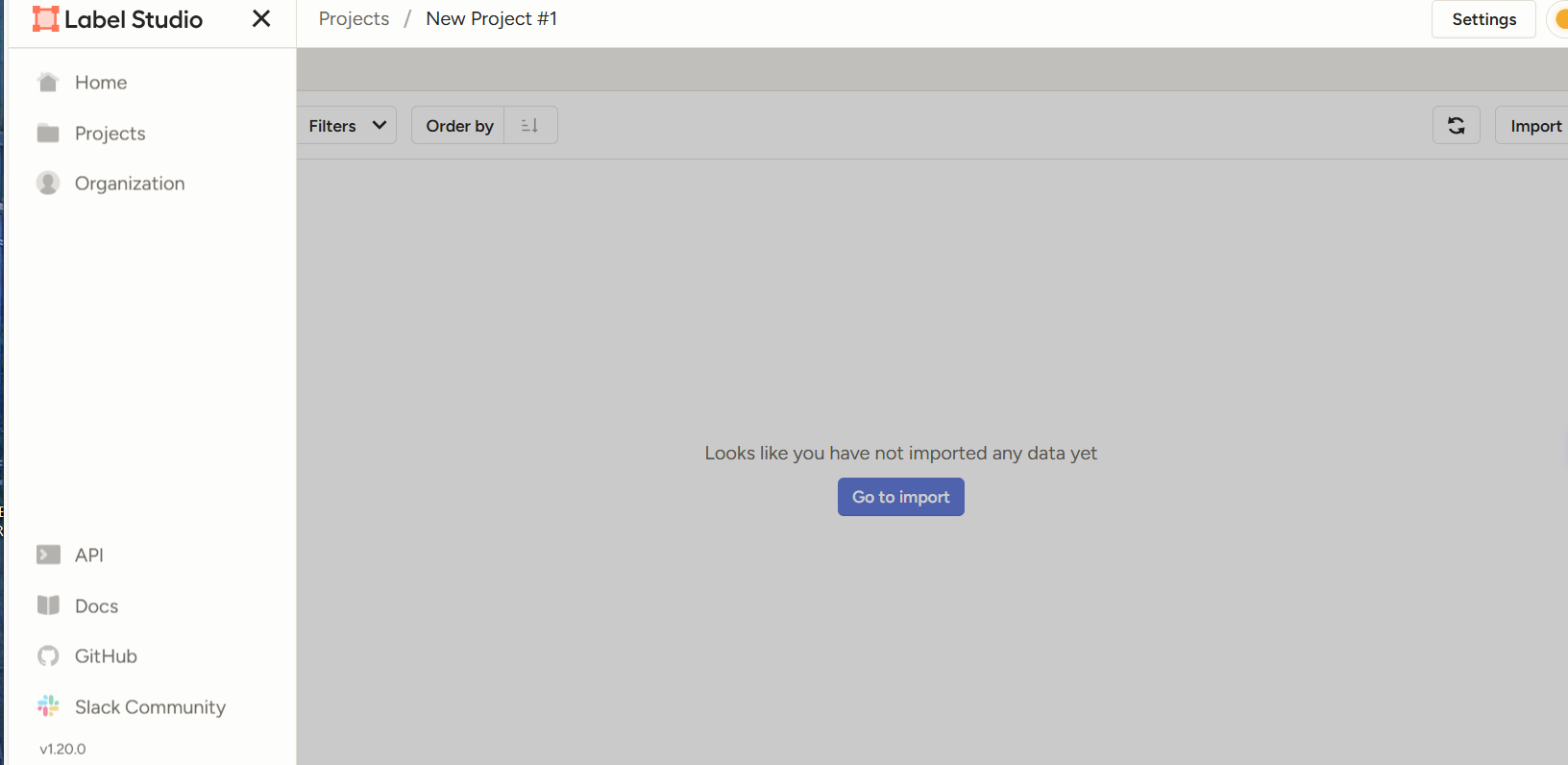
通過導入的形式將未標定的數據集導入到labelstudio中,設置標簽的類別進行標注
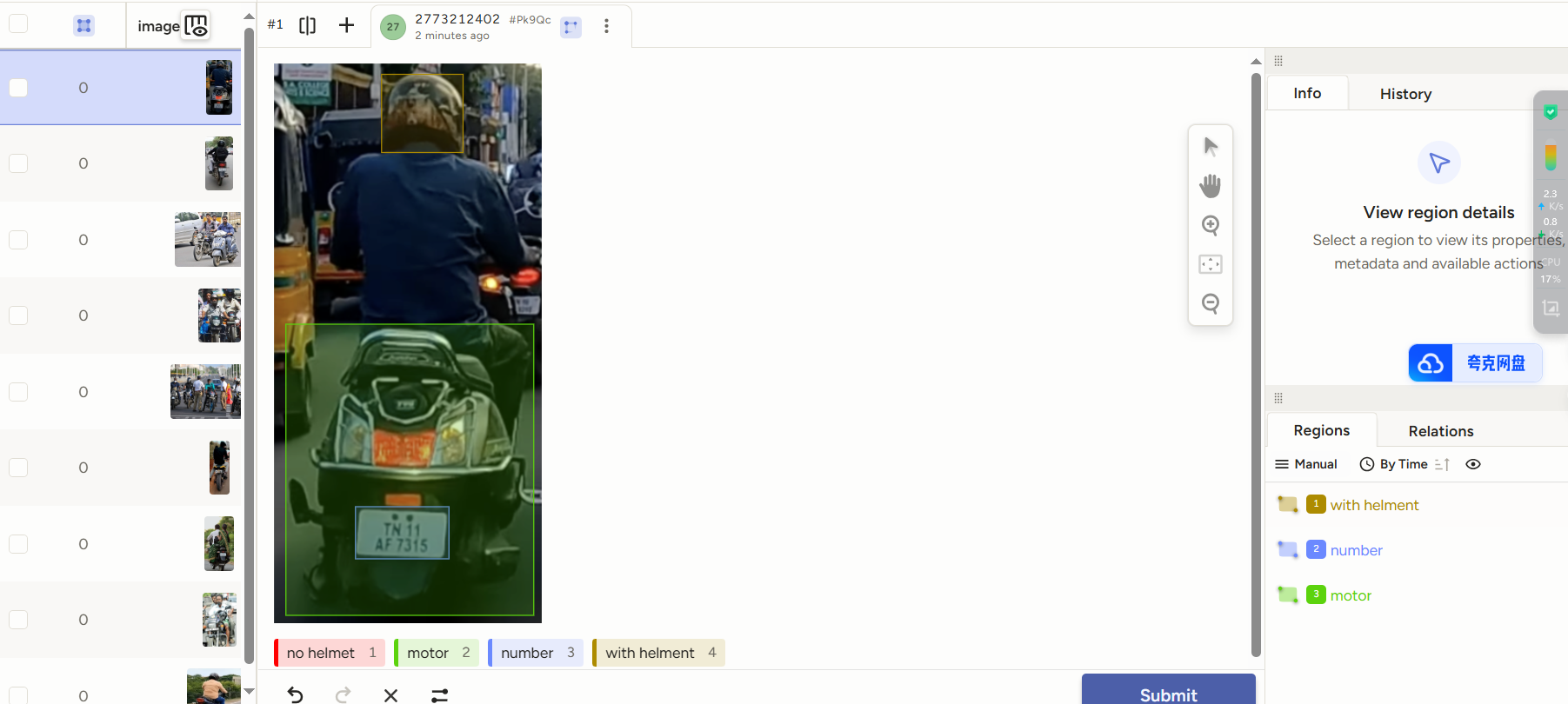
標注完成后的導出格式
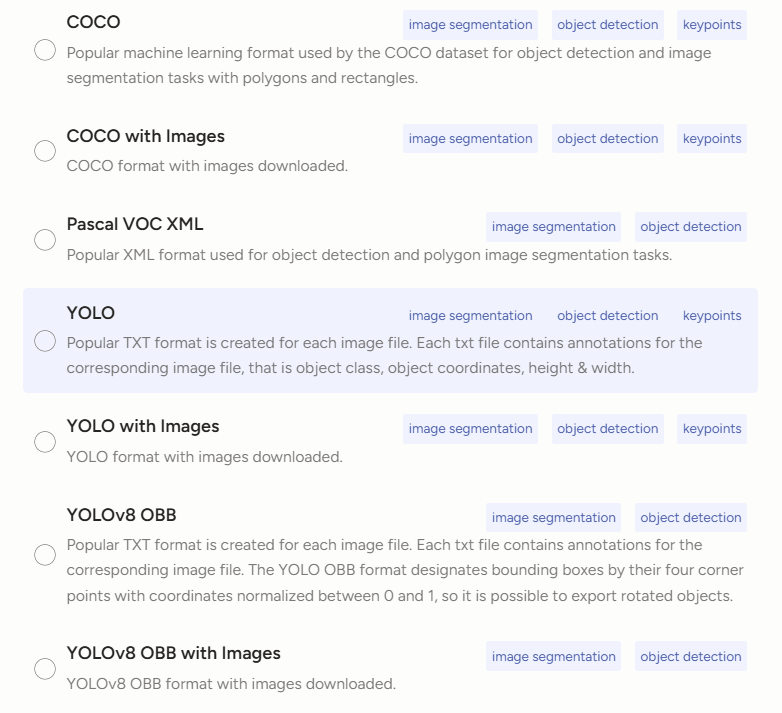
本地的掛載和網盤的掛載適合大批量的數據集
設置-Cloud Storage-Add Source Storage
Absolute local path路徑要和虛擬環境放在一個盤里
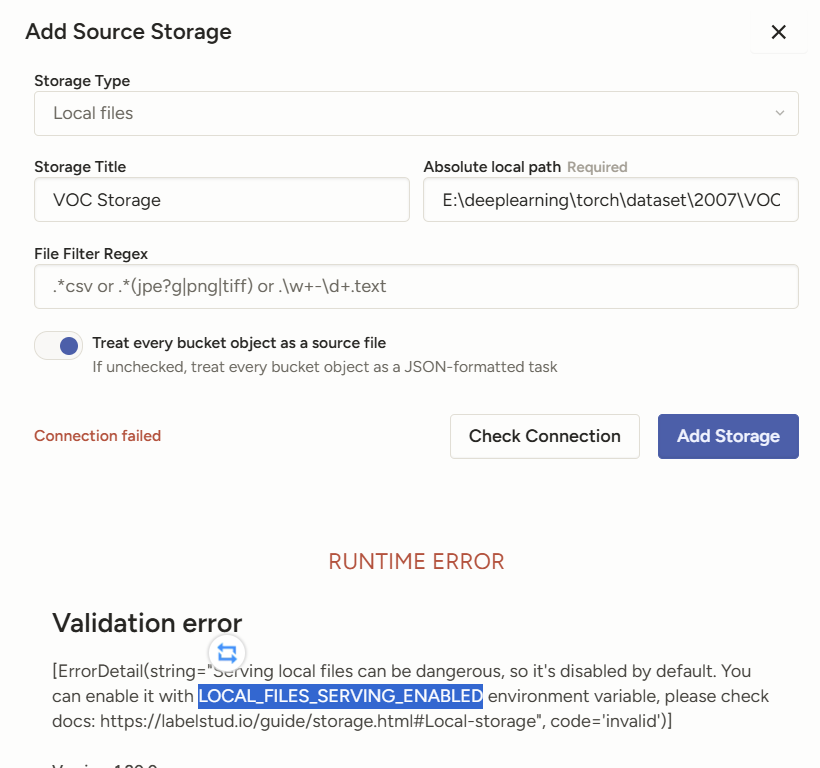
設置環境變量
LOCAL_FILES_SERVING_ENABLED=True

重新啟動繼續導入,點擊Sync Storage同步數據
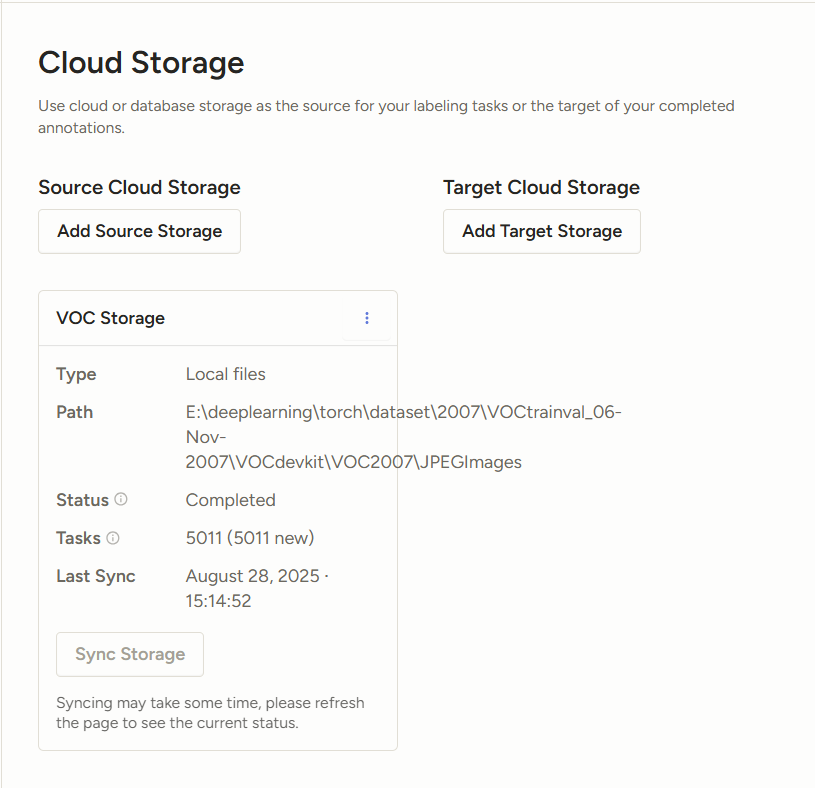
添加標簽
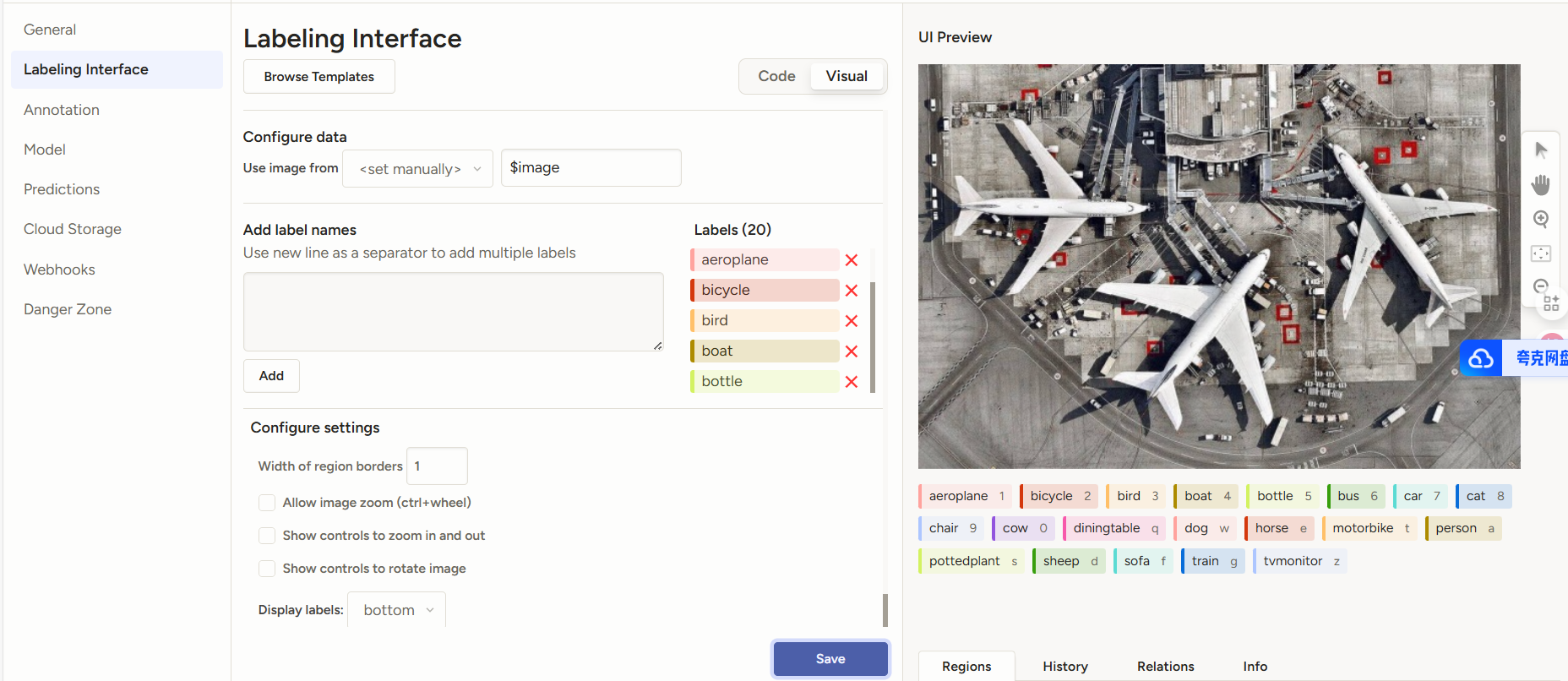
3 數據集的標注
3.1 VOC數據集標注
使用labelimg工具標注,首先修改預定義的類別文件為所需要標注的類別
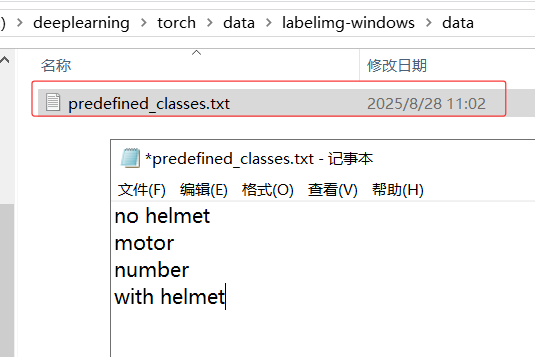
目錄結構train為訓練集,val為驗證集,images為圖片,labels為標注信息
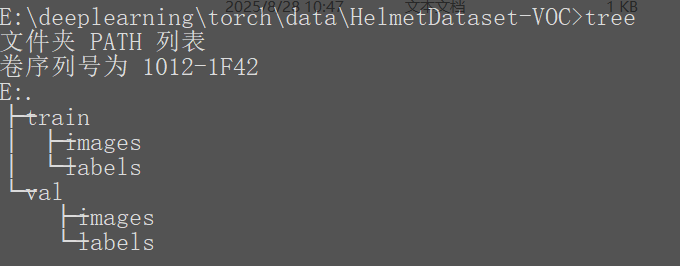
標注的labels信息
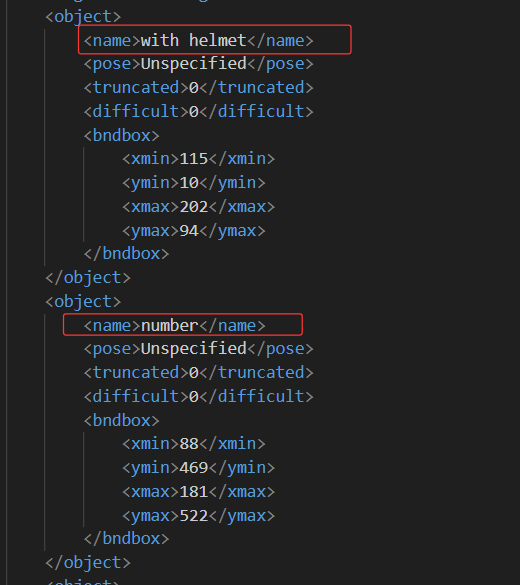
訓練集和驗證集,全部標注完成
3.2 加載數據集
編寫自己數據集
https://docs.pytorch.org/tutorials/beginner/data_loading_tutorial.html
import osimport torch
import xmltodict # 用于將XML數據轉換為Python字典
from PIL import Image # Python圖像處理庫
from torch.utils.data import Dataset # PyTorch數據集基類
from torchvision import transforms # 圖像預處理工具class VOCDataset(Dataset):# VOC數據集初始化def __init__(self, image_dir, label_dir, transform, label_transform):"""初始化VOC格式數據集Args:image_dir: 圖像文件目錄路徑label_dir: 標簽文件目錄路徑transform: 圖像預處理變換label_transform: 標簽預處理變換(代碼中未實際使用)"""self.image_dir = image_dirself.label_dir = label_dirself.transform = transformself.label_transform = label_transformself.imgs = os.listdir(self.image_dir) # 獲取圖像目錄下所有文件名# 定義類別列表self.classes_list = ["no helmet", "motor", "number", "with helmet"]# 返回數據集大小def __len__(self):"""返回數據集中的圖像數量"""return len(self.imgs)# 獲取單個數據項def __getitem__(self, index):"""獲取索引對應的數據項"""# 獲取圖像文件名并構建完整路徑img_name = self.imgs[index]img_path = os.path.join(self.image_dir, img_name)image = Image.open(img_path).convert('RGB') # 打開圖像并轉換為RGB格式# 構建對應的XML標簽文件路徑(將圖像擴展名替換為.xml)label_name = img_name.split('.')[0] + '.xml'label_path = os.path.join(self.label_dir, label_name)# 解析XML標簽文件with open(label_path, "r", encoding="utf-8") as f:label_content = f.read()label_dict = xmltodict.parse(label_content) # 將XML轉換為字典# 提取標注信息objects = label_dict["annotation"]["object"]target = [] # 存儲所有目標的標注信息# 遍歷每個標注對象for obj in objects:obj_name = obj["name"] # 獲取對象類別名稱obj_class_id = self.classes_list.index(obj_name) # 將類別名稱轉換為索引ID# 提取邊界框坐標(注意轉換為浮點數)xmin = float(obj["bndbox"]["xmin"])ymin = float(obj["bndbox"]["ymin"])xmax = float(obj["bndbox"]["xmax"])ymax = float(obj["bndbox"]["ymax"])# 將當前目標的標注信息添加到列表target.extend([obj_class_id, xmin, ymin, xmax, ymax])# 將標注列表轉換為張量target = torch.tensor(target)# 應用圖像預處理變換if self.transform is not None:image = self.transform(image)return image, target # 返回處理后的圖像和標注張量if __name__ == '__main__':image_dir = r'E:\deeplearning\torch\data\HelmetDataset-VOC\train\images'label_dir = r'E:\deeplearning\torch\data\HelmetDataset-VOC\train\labels'# 創建數據集實例train_dataset = VOCDataset(image_dir, label_dir, transforms.Compose([transforms.ToTensor()]), None)print(len(train_dataset)) # 打印數據集大小print(train_dataset[1])




NO.2——Unity6下載與安裝(超詳細))

)








CPU與指令)


)
