一、總體認識CPU
1、軟硬件角度
? ? ? ? CPU,全稱就是中央處理器。從硬件上來說,CPU是一個超大規模集成電路,通過電路實現加法、乘法乃至各種各樣的處理邏輯。從軟件來說,CPU就是一個執行各種計算機指令的邏輯機器。
2、計算機指令
????????所謂的計算機指令,其實就是CPU能聽懂的語言,我們可以叫做機器語言。不同的CPU能夠聽懂的語言也是不一樣的。例如,一般的電腦所用的是Intel的CPU,而蘋果手機用的是ARM的CPU。這兩種CPU各自支持的語言,就是兩組不同的計算機指令集。
? ? ? ? 所以,我們在電腦上寫的一個C語言程序,經過編譯、匯編之后形成exe文件,把這個文件復制到手機上一般是沒法正常運行的。而把這臺電腦上的exe文件復制到另一個相同OS的電腦上,是可以正常運行的。
3、存儲程序型計算機
? ? ? ? 一個計算機程序,一般有很多指令組成,但是CPU里不能一直放著所有指令(CPU中主要用于存放當前正在執行或即將執行的指令和數據。),所以計算機程序平時是存儲在存儲器中的(這個存儲器一般稱之為內存或主存)。
二、簡單了解編譯與匯編
1、整體過程
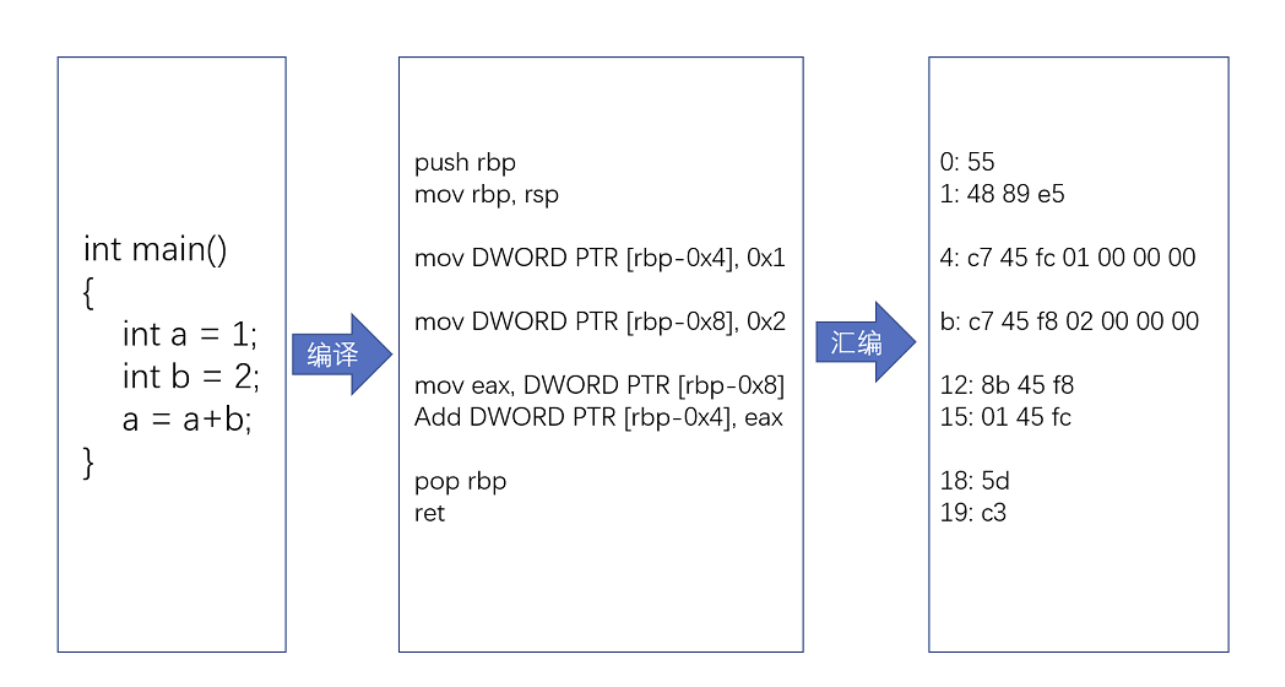
????????平時編寫的代碼,到底是怎么變成一條條計算機指令,最后被 CPU 執行的?以一段C語言程序舉例:
????????
// test.c
int main()
{int a = 1; int b = 2;a = a + b;
}????????要讓這段程序在一個 Linux 操作系統上跑起來,我們需要把整個程序翻譯成一個匯編語言(ASM,Assembly Language)的程序,這個過程我們一般叫編譯(Compile)成匯編代碼。
????????針對匯編代碼,我們可以再用匯編器(Assembler)翻譯成機器碼(Machine Code)。這些機器碼由“0”和“1”組成的機器語言表示。這一條條機器碼,就是一條條的計算機指令。這樣一串串的 16 進制數字,就是我們 CPU 能夠真正認識的計算機指令。????????
????????在一個 Linux 操作系統上,我們可以簡單地使用 gcc 和 objdump 這樣兩條命令,把對應的匯編代碼和機器碼都打印出來。
$ gcc -g -c test.c
$ objdump -d -M intel -S test.o????????結果如下:
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
int main()
{0: 55 push rbp1: 48 89 e5 mov rbp,rspint a = 1; 4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1int b = 2;b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2a = a + b;12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]15: 01 45 fc add DWORD PTR [rbp-0x4],eax
}18: 5d pop rbp19: c3 ret ????????可以看到,左側有一堆數字,這些就是一條條機器碼;右邊有一系列的 push、mov、add、pop 等,這些就是對應的匯編代碼。一行 C 語言代碼,有時候只對應一條機器碼和匯編代碼,有時候則是對應兩條機器碼和匯編代碼。匯編代碼和機器碼之間是一一對應的。
? ? ? ? 小問題:為什么要經過匯編而不是把代碼直接編譯成機器碼?因為匯編代碼其實就是“給程序員看的機器碼”,也正因為這樣,機器碼和匯編代碼是一一對應的。我們人類很容易記住 add、mov 這些用英文表示的指令,而 8b 45 f8 這樣的指令,由于很難一下子看明白是在干什么,所以會非常難以記憶。所以編譯、匯編的整體過程如下:
? ? ? ? 但其實,這里是有更深層次的原因。將編譯過程劃分為“編譯器 -> 匯編器”兩步,而不是直接從高級語言生成機器碼,主要是出于軟件工程上的考量,即模塊化、可移植性和簡化設計。
????????編譯器和匯編器各自的任務是解耦的:

這樣分工的好處是:

2、簡單解析指令與機器碼
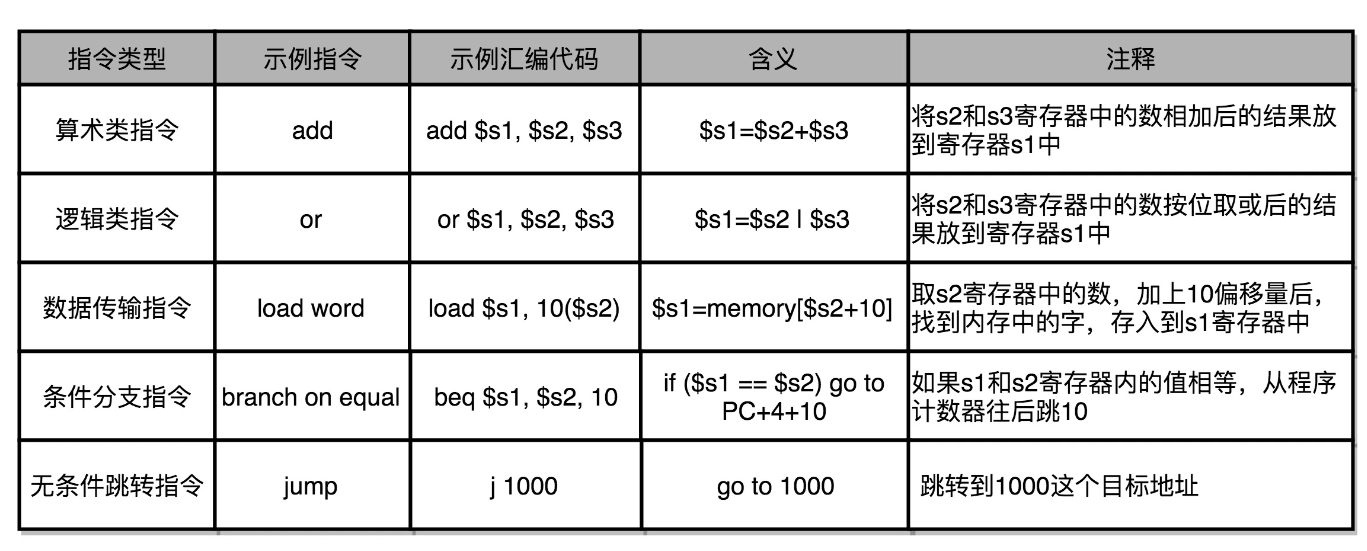
(1)匯編語言的指令分類
①算數類指令
????????我們的加減乘除,在 CPU 層面,都會變成一條條算術類指令。
②數據傳輸類指令
? ? ? ? 給變量賦值、在內存里讀寫數據,用的都是數據傳輸類指令。
③邏輯類指令
? ? ? ? 邏輯上的與或非。
④條件分支類指令
? ? ? ? 類似"if/else"編譯形成的指令
⑤無條件跳轉指令
????????寫一些大一點的程序,我們常常需要寫一些函數或者方法。在調用函數的時候,其實就是發起了一個無條件跳轉指令。
(2)機器碼是怎樣生成的
????????不同的 CPU 有不同的指令集,也就對應著不同的匯編語言和不同的機器碼。這里以MIPS指令集為例(MIPS 是一組由 MIPS 技術公司在 80 年代中期設計出來的 CPU 指令集)
????????MIPS 的指令是一個 32 位的整數,高 6 位叫操作碼(Opcode),也就是代表這條指令具體是一條什么樣的指令,剩下的 26 位有三種格式,分別是 R、I 和 J。
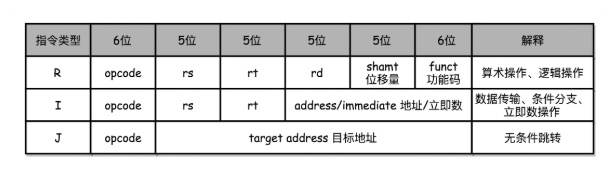
????????R 指令是一般用來做算術和邏輯操作,里面有讀取和寫入數據的寄存器的地址。如果是邏輯位移操作,后面還有位移操作的位移量,而最后的功能碼,則是在前面的操作碼不夠的時候,擴展操作碼表示對應的具體指令的。
????????I 指令,則通常是用在數據傳輸、條件分支,以及在運算的時候使用的并非變量還是常數的時候。這個時候,沒有了位移量和操作碼,也沒有了第三個寄存器,而是把這三部分直接合并成了一個地址值或者一個常數。
????????J 指令就是一個跳轉指令,高 6 位之外的 26 位都是一個跳轉后的地址。
? ? ? ? 以一個簡單的add指令為例:
add $t0, $s2, $s1
? ? ? ? 這個指令的含義是,將s2寄存器和s1寄存器中的值相加,放到t0寄存器中。
????????這條指令對應的?MIPS 指令里 opcode 是 0,rs 代表第一個寄存器 s1 的地址是 17,rt 代表第二個寄存器 s2 的地址是 18,rd 代表目標的臨時寄存器 t0 的地址,是 8。因為不是位移操作,所以位移量是 0。把這些數字拼在一起,就變成了一個 MIPS 的加法指令。
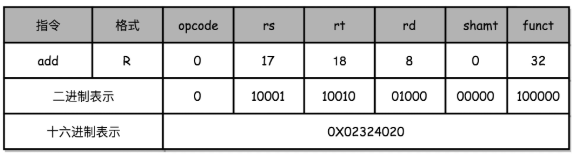
????????為了讀起來方便,我們一般把對應的二進制數,用 16 進制表示出來。在這里,也就是 0X02324020。這個數字也就是這條指令對應的機器碼。
? ? ? ? 小拓展:區分是R、I、J指令主要就是看 前 6 位的 opcode 字段。opcode = 0幾乎是所有 R 型,真正的操作由 funct 字段決定。opcode ≠ 0->I型(區別不同 I 型指令)。opcode = 0x02(j) 或 0x03(jal)->J型。
3、python和java的執行
????????除了 C 這樣的編譯型的語言之外,不管是 Python 這樣的解釋型語言,還是 Java 這樣使用虛擬機的語言,其實最終都是由不同形式的程序,把我們寫好的代碼,轉換成 CPU 能夠理解的機器碼來執行的。只是解釋型語言,是通過解釋器在程序運行的時候逐句翻譯,而 Java 這樣使用虛擬機的語言,則是由虛擬機對編譯出來的中間代碼進行解釋,或者即時編譯成為機器碼來最終執行。
三、CPU執行指令的過程
? ? ? ? 以Intel的CPU為例,里面差不多有幾百億個晶體管。實際上,一條條計算機指令執行起來非常復雜。但是在 CPU 在軟件層面已經為我們做好了封裝。對于我們這些做軟件的程序員來說,我們只要知道,寫好的代碼變成了指令之后,是一條一條順序執行的就可以了。
????????邏輯上,我們可以認為,CPU 其實就是由一堆寄存器組成的。而寄存器就是 CPU 內部,由多個觸發器(Flip-Flop)或者鎖存器(Latches)組成的簡單電路。(觸發器和鎖存器,其實就是兩種不同原理的數字電路組成的邏輯門。)
????????N 個觸發器或者鎖存器,就可以組成一個 N 位(Bit)的寄存器,能夠保存 N 位的數據。比方說,我們用的 64 位 Intel 服務器,寄存器就是 64 位的。(沒錯,一個寄存器就是這么小,換算成高級語言中相當于一個32位整型或64位長整型。但是寄存器只是用來保存當前正在計算的數據,不像內存需要存儲程序等)
1、CPU的幾種寄存器
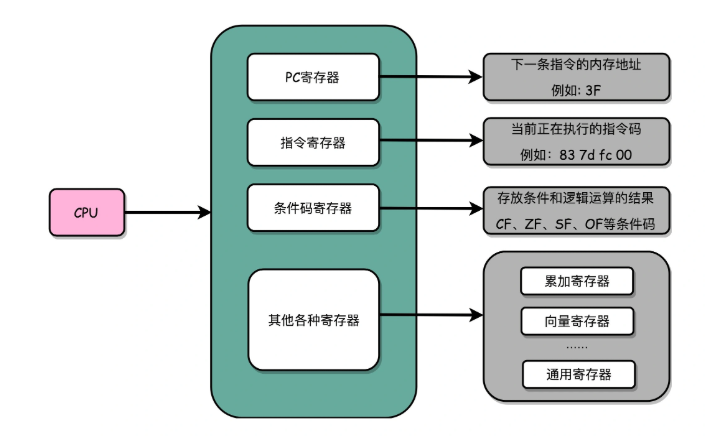
一個 CPU 里面會有很多種不同功能的寄存器。這里介紹三種比較重要、特殊的。
(1)PC寄存器
????????我們也叫指令地址寄存器。顧名思義,它就是用來存放下一條需要執行的計算機指令的內存地址。
(2)指令寄存器
????????用來存放當前正在執行的指令。
(3)條件碼寄存器
????????用里面的一個一個標記位(Flag),存放 CPU 進行算術或者邏輯計算的結果。
(4)其他寄存器
????????除了這些特殊的寄存器,CPU 里面還有更多用來存儲數據和內存地址的寄存器。這樣的寄存器通常一類里面不止一個。我們通常根據存放的數據內容來給它們取名字,比如整數寄存器、浮點數寄存器、向量寄存器和地址寄存器等等。有些寄存器既可以存放數據,又能存放地址,我們就叫它通用寄存器。
2、執行指令(順序)
????????一個程序執行的時候,CPU 會根據 PC 寄存器里的地址,從內存里面把需要執行的指令讀取到指令寄存器里面執行,然后根據指令長度自增,開始順序讀取下一條指令。可以看到,一個程序的一條條指令,在內存里面是連續保存的,也會一條條順序加載。
? ? ? ? 注意:PC寄存器自增(包括后面所說的更新),一般是在CPU的指令周期(取指 → 譯碼 → 執行 → 寫回)的取指階段
CPU 取到當前指令時,就會把 PC 自增(例如 +4)到下一條指令地址。
如果當前指令是跳轉/分支類指令(如
jmp、beq),那么譯碼/執行階段可能會修改 PC 的值(覆蓋掉剛才的 +4)。
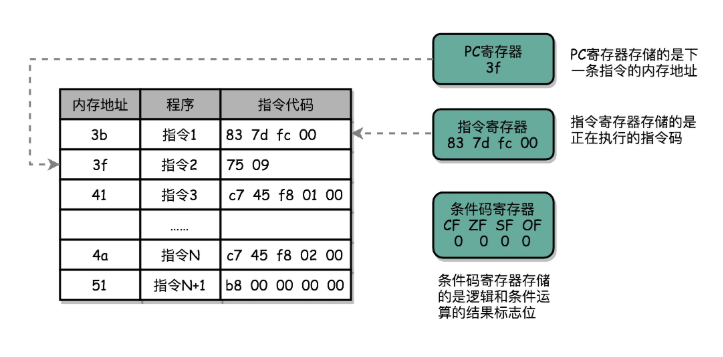
????????而有些特殊指令,比如 J 類指令,也就是跳轉指令,會修改 PC 寄存器里面的地址值。這樣,下一條要執行的指令就不是從內存里面順序加載的了。
3、指令的跳轉——條件語句
????????下面是一個簡單的包含條件判斷if...else...的指令:
// test.c#include <time.h>
#include <stdlib.h>int main()
{srand(time(NULL));int r = rand() % 2;int a = 10;if (r == 0){a = 1;} else {a = 2;} ????????我們用 rand 生成了一個隨機數 r,r 要么是 0,要么是 1。當 r 是 0 的時候,我們把之前定義的變量 a 設成 1,不然就設成 2。
? ? ? ? 用以下代碼生成匯編代碼:
$ gcc -g -c test.c
$ objdump -d -M intel -S test.o
if (r == 0)3b: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x03f: 75 09 jne 4a <main+0x4a>{a = 1;41: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x148: eb 07 jmp 51 <main+0x51>}else{a = 2;4a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x251: b8 00 00 00 00 mov eax,0x0} ????????可以看到,這里對于 r == 0 的條件判斷,被編譯成了 cmp 和 jne 這兩條指令。
????????cmp 指令比較了前后兩個操作數的值,這里的 DWORD PTR 代表操作的數據類型是 32 位的整數,而[rbp-0x4]則是變量 r 的內存地址。所以,第一個操作數就是從內存里拿到的變量 r 的值。第二個操作數 0x0 就是我們設定的常量 0 的 16 進制表示。cmp 指令的比較結果,會存入到條件碼寄存器當中去。
????????在這里,如果比較的結果是 True,也就是 r == 0,就把零標志條件碼(對應的條件碼是 ZF,Zero Flag)設置為 1。除了零標志之外,Intel 的 CPU 下還有進位標志、符號標志以及溢出標志,用在不同的判斷條件下。
????????cmp 指令執行完成之后,PC 寄存器會自動自增,開始執行下一條 jne 的指令。
????????跟著的 jne 指令,是 jump if not equal 的意思,它會查看對應的零標志位。如果 ZF 為 1,說明上面的比較結果是 TRUE,則繼續往下順序執行;如果是 ZF 是 0,也就是上面的比較結果是 False,會跳轉到后面跟著的操作數 4a 的位置。這個 4a,對應這里匯編代碼的行號,也就是上面設置的 else 條件里的第一條指令。當跳轉發生的時候,PC 寄存器就不再是自增變成下一條指令的地址,而是被直接設置成這里的 4a 這個地址。這個時候,CPU 再把 4a 地址里的指令加載到指令寄存器中來執行。
????????跳轉到執行地址為 4a 的指令,實際是一條 mov 指令,第一個操作數和前面的 cmp 指令一樣,是另一個 32 位整型的內存地址,以及 2 的對應的 16 進制值 0x2。mov 指令把 2 設置到對應的內存里去,相當于一個賦值操作。然后,PC 寄存器里的值繼續自增,執行下一條 mov 指令。
????????這條 mov 指令的第一個操作數 eax,代表累加寄存器,第二個操作數 0x0 則是 16 進制的 0 的表示。這條指令其實沒有實際的作用,它的作用是一個占位符。我們回過頭去看前面的 if 條件,如果滿足的話,在賦值的 mov 指令執行完成之后,有一個 jmp 的無條件跳轉指令。跳轉的地址就是這一行的地址 51。我們的 main 函數沒有設定返回值,而 mov eax, 0x0 其實就是給 main 函數生成了一個默認的為 0 的返回值到累加器里面。if 條件里面的內容執行完成之后也會跳轉到這里,和 else 里的內容結束之后的位置是一樣的。
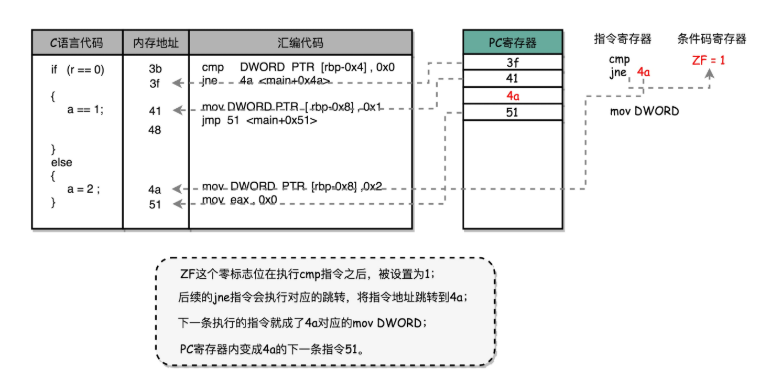
? ? ? ? 指令可以往后跳轉也可以向前跳轉——這就是for/while循環實現的原理。
4、指令的跳轉——循環語句
????????下面是段簡單的c語言for循環指令:
int main()
{int a = 0;for (int i = 0; i < 3; i++){a += i;}
}????????循環自增變量 i 三次,三次之后,i>=3,就會跳出循環。整個程序,對應的 Intel 匯編代碼就是這樣的:
for (int i = 0; i <= 2; i++)b: c7 45 f8 00 00 00 00 mov DWORD PTR [rbp-0x4],0x012: eb 0a jmp 1e {a += i;14: 8b 45 f8 mov eax,DWORD PTR [rbp-0x4]17: 01 45 fc add DWORD PTR [rbp-0x8],eax1a: 83 45 f8 01 add DWORD PTR [rbp-0x4],0x11e: 83 7d f8 02 cmp DWORD PTR [rbp-0x4],0x222: 7e f0 jle 14 24: b8 00 00 00 00 mov eax,0x0}????????對應的循環也是用 1e 這個地址上的 cmp 比較指令,和緊接著的 jle 條件跳轉指令來實現的。主要的差別在于,這里的 jle 跳轉的地址,是在這條指令之前的地址 14,而非 if…else 編譯出來的跳轉指令之后。往前跳轉使得條件滿足的時候,PC 寄存器會把指令地址設置到之前執行過的指令位置,重新執行之前執行過的指令,直到條件不滿足,順序往下執行 jle 之后的指令,整個循環才結束。
? ? ? ? 小拓展:jne和jle
????????在 x86 匯編 里,像 jne、jle 這樣的條件跳轉指令,本身并不會做比較運算,它們只是檢查標志寄存器 (EFLAGS)(這個寄存器叫做條件碼寄存器) 的狀態。而這個狀態一般需要由 cmp 指令 或者 test 指令 先設置。


5、總結
? ? ? ? 對于多條指令,除了簡單地通過 PC 寄存器自增的方式順序執行外,條件碼寄存器會記錄下當前執行指令的條件判斷狀態,然后通過跳轉指令讀取對應的條件碼,修改 PC 寄存器內的下一條指令的地址,最終實現 if…else 以及 for/while 這樣的程序控制流程。
????????雖然我們可以用高級語言,可以用不同的語法,比如 if…else 這樣的條件分支,或者 while/for 這樣的循環方式,來實現不同的程序運行流程,但是回歸到計算機可以識別的機器指令級別,其實都只是一個簡單的地址跳轉而已,也就是一個類似于 goto 的語句。
????????想要在硬件層面實現這個 goto 語句,除了本身需要用來保存下一條指令地址,以及當前正要執行指令的 PC 寄存器、指令寄存器外,我們只需要再增加一個條件碼寄存器,來保留條件判斷的狀態。這樣簡簡單單的三個寄存器,就可以實現條件判斷和循環重復執行代碼的功能。


)





】)







)


