最近,AI 編碼工具層出不窮,幾乎每天都有新概念誕生。而當 GitHub 這樣的行業巨頭攜“Vibe Coding”概念入場時,所有開發者的期待值都被瞬間拉滿。GitHub Spark,一個承諾能用自然語言將你的想法直接變成全棧應用的工具,聽起來就像是未來的敲門磚。

然而,在滿懷希望地深入體驗后,我卻發現現實與理想之間存在著一條巨大的鴻溝。這趟旅程,與其說是對未來的探索,不如說是一次對“大廠產品設計哲學”的深刻反思。

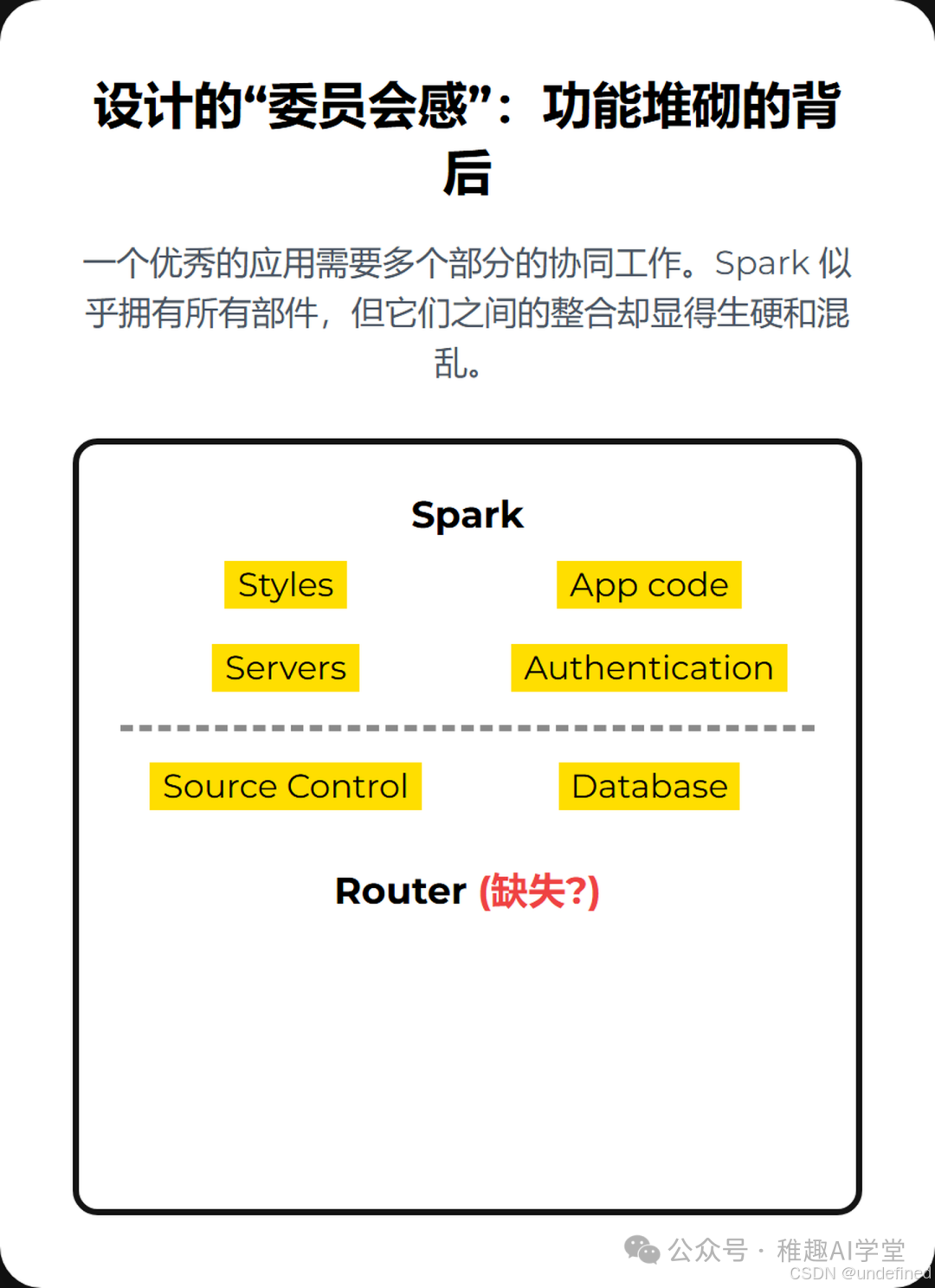
設計的“委員會感”:功能堆砌的背后
一個優秀的應用,無論是代碼層面還是用戶體驗層面,都需要各個部分的和諧統一。這包括清晰的UI(Styles)、穩健的應用邏輯(App code)、可靠的后端服務(Servers)、無縫的認證體系(Authentication)、結構化的數據存儲(Database)、明確的路由規則(Router)以及版本控制(Source Control)。
Spark 乍看之下似乎擁有了所有這些部件,但實際體驗下來,卻像是一個由不同部門開會決策、最后強行拼湊起來的產品。各個功能模塊之間缺乏有機的聯系,處處透露著一種“我們有這個功能,但沒想好怎么讓它好用”的尷尬。
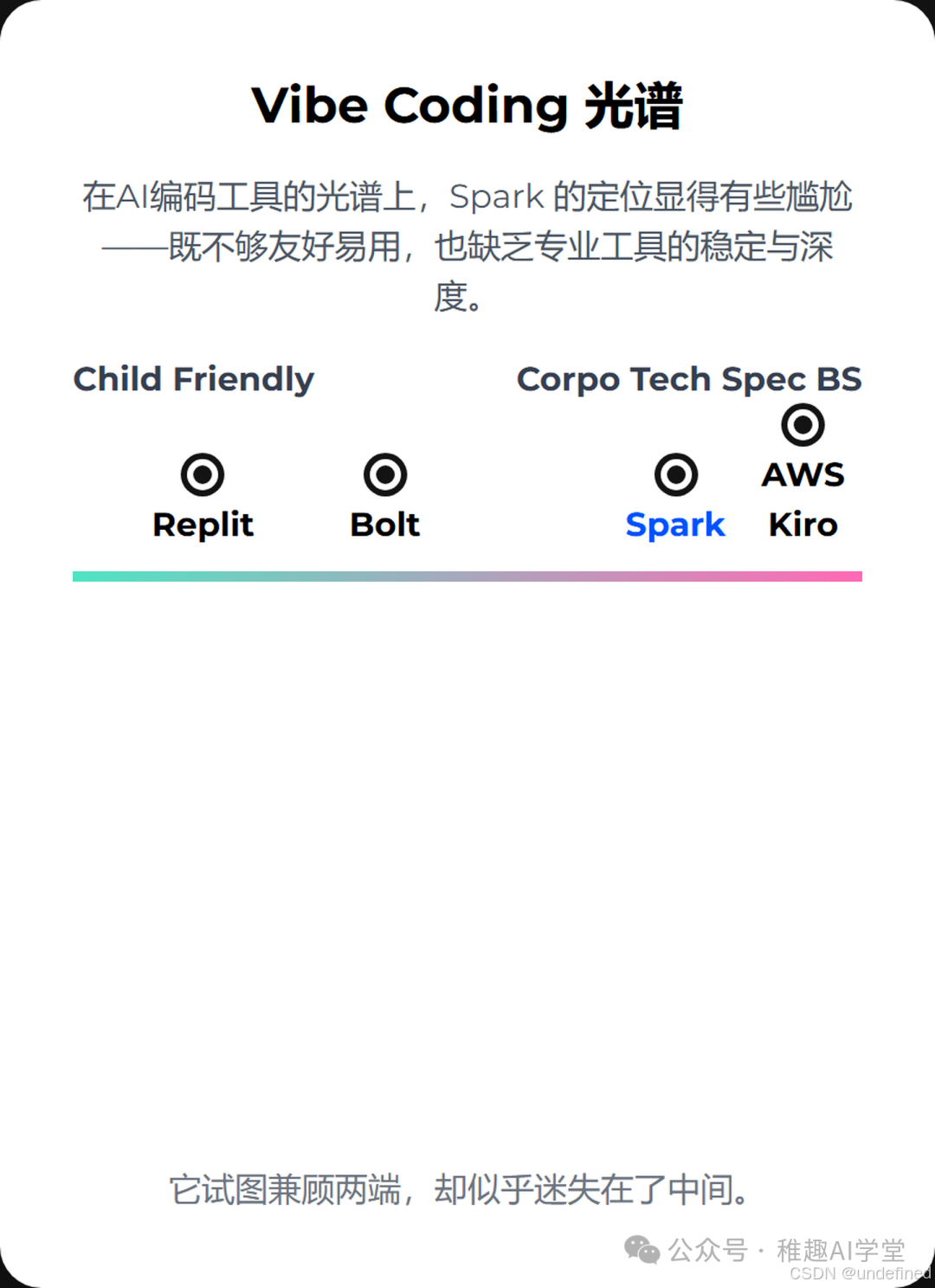
在光譜中迷失:定位模糊的尷尬
如果我們將市面上的AI編碼工具放在一個光譜上,一端是極其“友好易用”,甚至可以讓非程序員快速上手的工具(比如Replit的某些模式);另一端則是追求極致專業、穩定、可控的“企業級技術方案”(比如AWS Kiro)。
Spark 的定位就在這其中顯得尤為尷尬。它既不像前者那樣簡單直觀,能讓人快速獲得成就感;也遠未達到后者在穩定性、性能和可擴展性上的專業水準。它似乎試圖討好所有人,結果卻可能讓兩邊的用戶都感到不適。
通往嚴肅工具之路:一份給Spark的“體檢報告”
那么,要讓 Spark 真正從一個“酷炫的玩具”轉變為開發者信賴的生產力工具,需要做些什么呢?經過一番“折騰”,我總結出了以下幾點至關重要的改進方向:

讓我能在本地運行代碼!?這是開發者的基本人權。一個無法在本地環境輕松調試、掌控的工具,永遠無法成為核心生產力工具。
“大對象”數據模型是災難。?將所有消息歷史記錄存儲為單個JSON對象的做法,在數據結構設計上是極其業余且危險的,這直接導致了實時性和并發性的嚴重問題。
請先修復BUG,再談新功能。?當前版本的 Spark 充滿了各種令人困惑的 Bug 和不穩定的表現。在產品核心體驗尚未打磨好的情況下,任何新功能的增加都只會加劇混亂。
精簡想法,聚焦核心。?Spark 似乎集成了太多“酷炫”但半生不熟的想法。與其做一個功能繁多但處處是坑的“瑞士軍刀”,不如先做好一把鋒利、可靠的主刀。
部署狀態必須透明。?用戶需要一個清晰、明確的指示,來了解當前預覽的應用版本是否已經同步了最新的代碼變更。
真正發揮GitHub的生態優勢。?Spark 最大的潛力在于它背后強大的GitHub生態。它應該更深度、更靈活地與代碼倉庫、認證、部署流程結合,而不是像現在這樣,僅僅是“擁有一個GitHub倉庫”的 superficial 連接。
一個核心的疑問
在整個體驗過程中,一個揮之不去的念頭是:開發這個工具的團隊,真的在日常工作中使用它來構建和維護自己的內部應用嗎?

很多產品的設計缺陷,都源于開發者與真實用戶場景的脫節。如果一個工具的創造者們自己都不是它的重度用戶,那么它很難真正理解并解決用戶的核心痛點。這或許是 Spark 當前面臨的最大挑戰。
總而言之,GitHub Spark 展現了巨大的潛力,它背后的理念和技術整合能力是毋庸置疑的。但就目前的產品形態而言,它更像一個內部技術驗證項目,距離成為一個成熟、可靠、能讓開發者“愛不釋手”的工具,還有很長一段路要走。我們期待著它能聽取社區的聲音,完成一次深刻的蛻變。
寫在最后——如果你覺得這篇文章對你有幫助,記得轉發給更多朋友,AI的快樂要一起分享!也歡迎在評論區曬出你用這個技巧的神操作,萬一你一不 小心就啟發了下一個“AI爆款”呢?
我是AIGC小火龍果,一個努力讓AI不再高冷的產品頑童,主業是把復雜的AI技巧變成你一看就會的小把戲。關注我,與和你一樣有想法的朋友們一起,在AI時代邊玩邊進化!
該內容觀點引自 【Theo - t3?gg】,感謝友友分享,歡迎在評論區留言,本文僅作學習與交流之用,如有任何問題或需要調整,請隨時告知,我會第一時間處理。




)






的詳細分析與實現)




-- 性能優化與調試)

![[新啟航]新啟航激光頻率梳 “光量子透視”:2μm 精度破除遮擋,完成 130mm 深孔 3D 建模](http://pic.xiahunao.cn/[新啟航]新啟航激光頻率梳 “光量子透視”:2μm 精度破除遮擋,完成 130mm 深孔 3D 建模)
