大家好!今天我們要聊一個在深度學習領域掀起革命的經典網絡——GoogLeNet(又稱Inception v1)。這個由Google團隊在2014年提出的模型,不僅拿下了ImageNet競賽冠軍,更用"網絡中的網絡"設計理念徹底改變了卷積神經網絡(CNN)的架構思路。
一、為什么需要GoogLeNet?
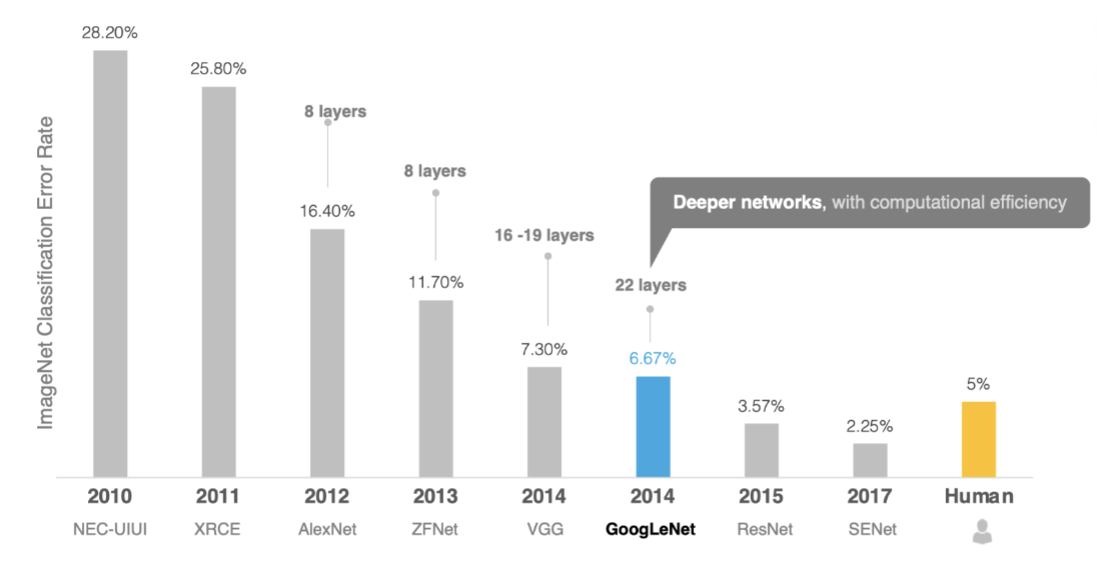
在GoogLeNet之前,主流思路是不斷增加網絡深度(層數)來提升性能。AlexNet(8層)、VGG(16-19層)都是這一思路的代表。但??層數增加帶來三大問題??:
- 1.??計算量爆炸?? 💥 - 參數過多導致訓練和推理速度慢
- 2.??梯度消失?? 📉 - 深層網絡難以訓練,梯度反向傳播時逐漸衰減
- 3.??過擬合風險?? 🎯 - 模型復雜度過高,容易記住訓練數據而非學習泛化特征
GoogLeNet的解決之道是:??“寬”而非“深”??。它通過??Inception模塊??在同一層級上并行提取多尺度特征,大幅提升特征表達能力而不顯著增加計算量。
二、Inception模塊:GoogLeNet的心臟?
1. 原始構想:多尺度特征融合
GoogLeNet中的基礎卷積塊叫作Inception塊,得名于同名電影《盜夢空間》(Inception)。
Inception塊在結構比較復雜。如下圖:
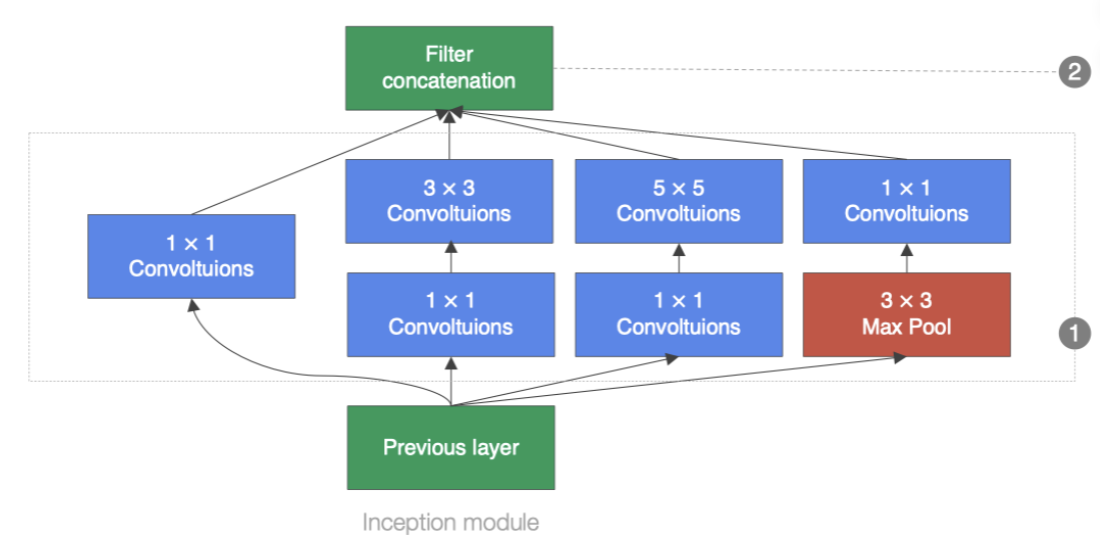
Inception塊里有4條并行線路。
前3條線路使用窗口大小分別為1×1?、3×3 和5×5 的卷積層來抽取不同空間尺寸下的信息,其中中間2個線路會對輸入先做 1×1卷積來減少輸入通道數,以降低模型復雜度。
第4條線路則使用 3×3最大池化層,后接1×1 卷積層來改變通道數。
4條線路都使用了合適的填充來使輸入與輸出的高和寬一致。最后我們將每條線路的輸出在通道
維上連結,并向后進行傳輸。
2. 致命問題:計算量爆炸!
😱 問題來了:5×5卷積的計算量是3×3的2.78倍!直接并行會導致計算成本劇增。
3. 神來之筆:1×1卷積降維
GoogLeNet的解決方案是在??大卷積前插入1×1卷積??進行降維:
# 改進后的Inception分支
branch3 = sequential(conv1x1(in_channels, ch5x5red), # 降維:減少通道數conv5x5(ch5x5red, ch5x5) # 正常卷積
)1×1卷積的三大作用??:
- 1.??通道降維??:減少后續卷積的輸入通道數,降低計算量
- 2.??增加非線性??:配合ReLU激活函數提升模型表達能力
- 3.??跨通道信息整合??:融合不同通道的特征信息
4. 最終Inception模塊結構
四條并行路徑:
- 1.??1×1卷積?? → 直接輸出
- 2.??1×1卷積 + 3×3卷積?? → 先降維再卷積
- 3.??1×1卷積 + 5×5卷積?? → 先降維再卷積
- 4.??3×3最大池化 + 1×1卷積?? → 池化后降維
??關鍵技巧??:所有分支使用適當填充(padding),確保輸出特征圖尺寸一致,便于通道拼接。
三、GoogLeNet整體架構剖析 🧠
GoogLeNet(又稱Inception v1)由??9個Inception模塊??堆疊而成,如下圖:
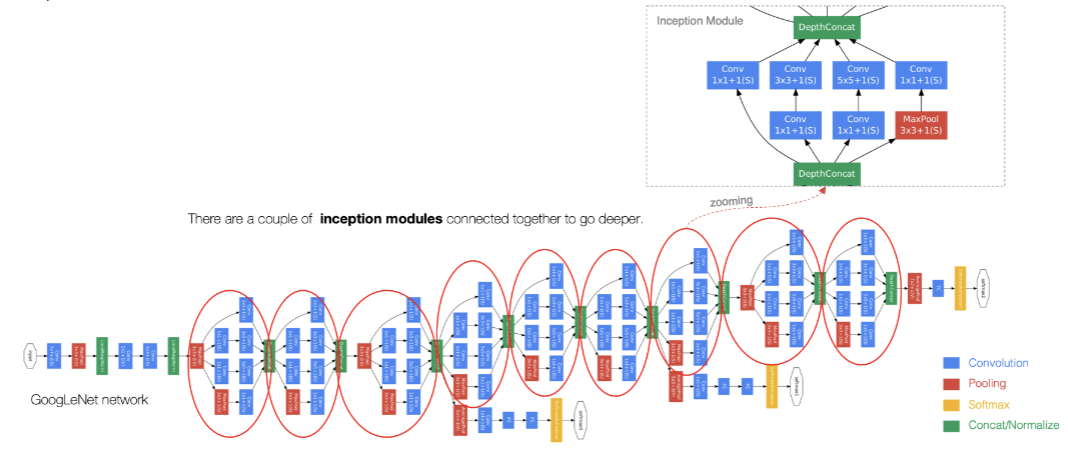
整個網絡架構我們分為五個模塊,每個模塊之間使用步幅為2的 最大池化層來減小輸出高
寬。
Stage 1:基礎特征提取
第一模塊使用一個64通道的7×7 卷積層。
Conv2d(3, 64, kernel=7x7, stride=2) # 輸出112×112×64
MaxPool(3x3, stride=2) # 輸出56×56×64Stage 2:特征細化
第二模塊使用2個卷積層:首先是64通道的1×1 卷積層,然后是將通道增大3倍的 3×3 卷積
層。
Conv2d(64, 64, kernel=1x1) # 保持56×56×64
Conv2d(64, 192, kernel=3x3, padding=1) # 輸出56×56×192
MaxPool(3x3, stride=2) # 輸出28×28×192Stage 3:Inception模塊堆疊(2個)
- Inception3a??:輸出28×28×256
(64+128+32+32=256) - ??Inception3b??:輸出28×28×480
(128+192+96+64=480) - ??MaxPool??:輸出14×14×480
Stage 4:深層特征提取(5個Inception)
- 包含Inception4a到4e
- ??核心創新點??:在此階段插入??輔助分類器??
Stage 5:最終分類
Inception5a → Inception5b
GlobalAveragePooling() # 替代全連接層
Dropout(0.4)
Linear(1024, num_classes)🔍 關鍵技術亮點:
- 輔助分類器(Auxiliary Classifiers)??
? ? ? ? ? ? 位置:插入在Inception4a和Inception4d之后
? ? ? ? ? ? 作用:
? ? ? ? ? ? ? ? ? ? ? 緩解梯度消失(反向傳播時提供額外梯度)
? ? ? ? ? ? ? ? ? ? ? 正則化效果(防止過擬合)
? ? ? ? ? ? ? ? ? ? ? 利用中間層特征進行分類
? ? ? ? ? ? ? ? ? ? ? ? ? ? 訓練時:主分類器權重1.0,輔助分類器各0.3
? ? ? ? ? ? ? ? ? ? ? ? ? ? 測試時:??僅保留主分類器
class AuxiliaryClassifier(nn.Module):def __init__(self, in_channels, num_classes):super().__init__()self.avgpool = nn.AdaptiveAvgPool2d((4,4))self.conv = nn.Conv2d(in_channels, 128, kernel_size=1)self.fc1 = nn.Linear(128 * 4 * 4, 1024)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):x = self.avgpool(x)x = self.conv(x)x = x.view(x.size(0), -1)x = F.relu(self.fc1(x))x = self.fc2(x)return x- 全局平均池化(Global Average Pooling)??
替代傳統全連接層:
? ? ? ? ? ? ?對每個特征圖取平均值 → 得到1×1×通道數的輸出
? ? ? ? ? ? ???優勢??:
? ? ? ? ? ? ? ? ? ? ?大幅減少參數量(VGG全連接層占參數90%+)
? ? ? ? ? ? ? ? ? ? ?降低過擬合風險
? ? ? ? ? ? ? ? ? ? ?增強空間平移不變性
四、Inception家族的進化 🚀
GoogLeNet成功后,研究者們持續改進Inception架構:
1. Inception v2/v3
- ??引入批量歸一化(Batch Normalization)??
加速訓練收斂,提高穩定性 - 卷積分解技術??:
- 5×5卷積 → 兩個3×3卷積(計算量減少28%)
- 3×3卷積 → 1×3卷積 + 3×1卷積(非對稱分解)
- 更高效的降維方式??
在分支開頭使用并行降維
2. Inception v4
- ??結合殘差連接(ResNet思想)??
解決深層網絡梯度消失問題 - 統一模塊設計??
標準化Inception模塊類型 - Stem模塊優化??
改進初始特征提取部分
3. Xception(Extreme Inception)
- 深度可分離卷積??
將標準卷積分解為:- 逐通道卷積(Depthwise Convolution)
- 逐點卷積(Pointwise Convolution)
- 計算效率提升3-4倍
五、GoogLeNet的優缺點分析 ??
? 顯著優勢:
- 參數效率極高??
500萬參數實現22層深度(AlexNet參數6000萬,僅8層) - ??多尺度特征融合??
Inception并行結構捕獲豐富特征 - ?計算量優化??
1×1卷積降維大幅減少計算成本 - 訓練穩定性提升??
輔助分類器緩解梯度消失問題
? 固有局限:
- 結構復雜??
模塊內多分支設計增加調試難度 - 通道數配置經驗性強??
各路徑通道比例依賴人工經驗 - ?計算資源需求高??
雖參數少,但并行計算需求大(尤其早期硬件)
六、實戰:PyTorch實現GoogLeNet
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super().__init__()# 分支1:1x1卷積self.branch1 = nn.Sequential(nn.Conv2d(in_channels, ch1x1, kernel_size=1),nn.BatchNorm2d(ch1x1),nn.ReLU(inplace=True))# 分支2:1x1卷積 -> 3x3卷積self.branch2 = nn.Sequential(nn.Conv2d(in_channels, ch3x3red, kernel_size=1),nn.BatchNorm2d(ch3x3red),nn.ReLU(inplace=True),nn.Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1),nn.BatchNorm2d(ch3x3),nn.ReLU(inplace=True))# 分支3:1x1卷積 -> 5x5卷積self.branch3 = nn.Sequential(nn.Conv2d(in_channels, ch5x5red, kernel_size=1),nn.BatchNorm2d(ch5x5red),nn.ReLU(inplace=True),nn.Conv2d(ch5x5red, ch5x5, kernel_size=5, padding=2),nn.BatchNorm2d(ch5x5),nn.ReLU(inplace=True))# 分支4:3x3池化 -> 1x1卷積self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),nn.Conv2d(in_channels, pool_proj, kernel_size=1),nn.BatchNorm2d(pool_proj),nn.ReLU(inplace=True))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)return torch.cat([branch1, branch2, branch3, branch4], 1)# 完整GoogLeNet實現代碼見原博客[6](@ref)七、總結與影響 💡
GoogLeNet的革命性貢獻在于:
- ?開創多尺度特征融合范式??
Inception思想影響后續眾多網絡設計 - ??證明參數效率的重要性??
用更少參數實現更好性能成為新追求 - 推動模塊化網絡設計??
網絡由可復用模塊堆疊而成
🌟 ??關鍵啟示??:
在深度學習領域,??結構創新??有時比單純增加深度更能帶來突破。GoogLeNet通過巧妙的Inception模塊設計,實現了“??少即是多??”(Less is More)的哲學,為后續MobileNet、EfficientNet等高效網絡奠定基礎。
時至今日,雖然Transformer等新架構崛起,但Inception的思想精髓——??并行多尺度特征融合??——仍在許多現代網絡中閃耀光芒。理解GoogLeNet,就是理解CNN進化史上的關鍵一躍!
互動時間:你用過GoogLeNet或其變體嗎?在哪些場景下效果顯著?歡迎在評論區分享你的經驗!👇
📢 關注我的CSDN博客,下期將解剖更現代的EfficientNet網絡,教你如何用"復合縮放"打造極致效率的模型!🚀





(三))

)







:二值化、自適應二值化)



